【数据结构】快排的详细讲解
目录:
介绍
一,递归快排确定基准值
二,递归遍历
三,非递归的快排
四,快排的效率
介绍
快排是排序算法中效率是比较高的,快排的基本思想是运用二分思想,与二叉树的前序遍历类似,将数据划分,每次划分确定1个基准值(就是已经确定好有序后位置的数据),以升序为例,基准值左面的数据都比此值小,右面的数据都比此值大,然后以基准值为分界线,经过不断划分,最终基准值的个数达到n,数据即有序,因此,递归运用是不二选法,也可运用非递归,但是比较麻烦。
一,递归快排确定基准值
确定基准值的方法常用的有三种,普通法,挖坑法,前后指针法。
1,普通法,具体思想图如下(以升序为例):

上面说过,基准值的确定过程要保证左面的数据都比此值小或大,右面的数据都要比此值大或小,因此,此基准值就确定了在整个数据中的位置。以升序为例,我们可以从开头和末尾遍历数据,比开头(以首元素为基准)元素大的放在最后,比开头元素小的数据放在前面,最终当两者相遇后再与开头元素交换即可确定基准值(注意:此步骤有细节,具体后面会说明)。如下图:
基准值过程图

现在有个注意要素套提一下,当上图中的前面L和后面R相遇时,如何保证此值一定比首元素小呢?这里我们需要控制好L的走向即可,即让R先走,当遇见比首元素小时退出,然后让L走,最后让两者进行交换,这样一来无论出现什么情况,当L与R相遇时对应的数据将一定比首元素(即以第一个元素为基准)小,此步骤称为预排序。
基准值的确定代码如下:
void Swap(int* x1, int* x2) {
int t = *x1;
*x1 = *x2;
*x2 = t;
}int PartSort1(int* a, int begin, int end) {
int key = begin;
while (begin < end) {
//注意此步骤,end必须先开始(即当左边开始行走右边一定有比key小的值),
//因为要控制最后的begin最终比key(开头元素)小,因此,右边必须先走.
while (begin < end && a[end] >= a[key]) {
end--;
}
//当走左边时,最终会Swap(a + end, a + begin);交换后begin的最终比key小
while (begin < end && a[begin] <= a[key]) {
begin++;
}
Swap(a + end, a + begin);
}
Swap(a + key, a + begin);
return begin;
}
2,挖坑法,原理图如下(以升序为例):
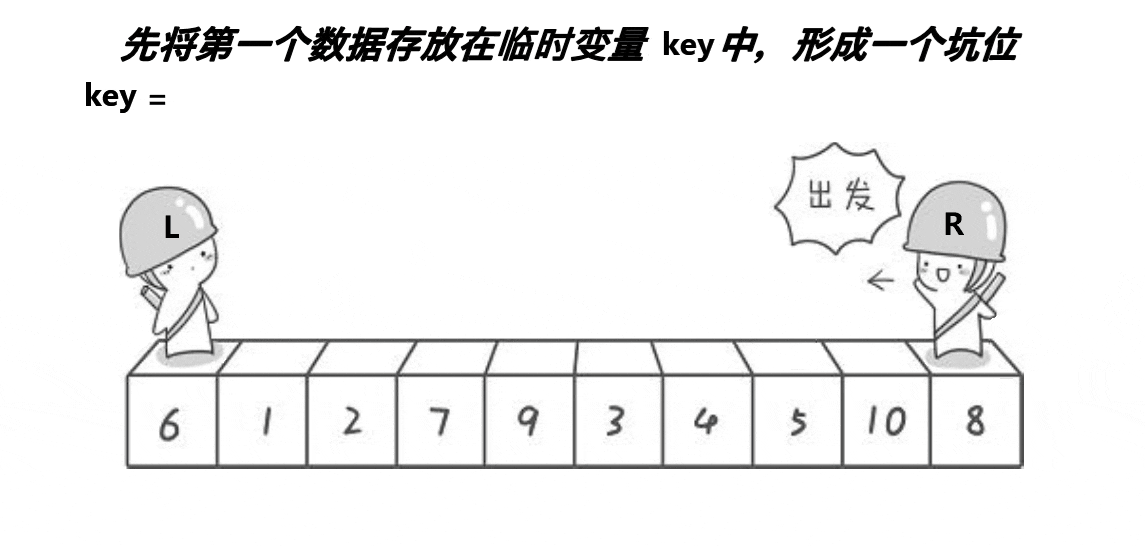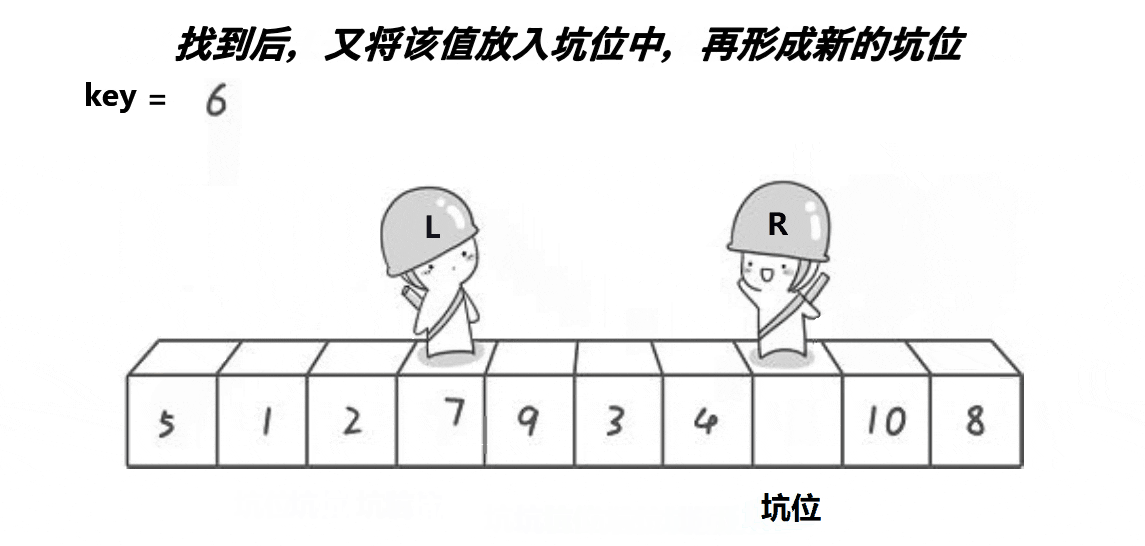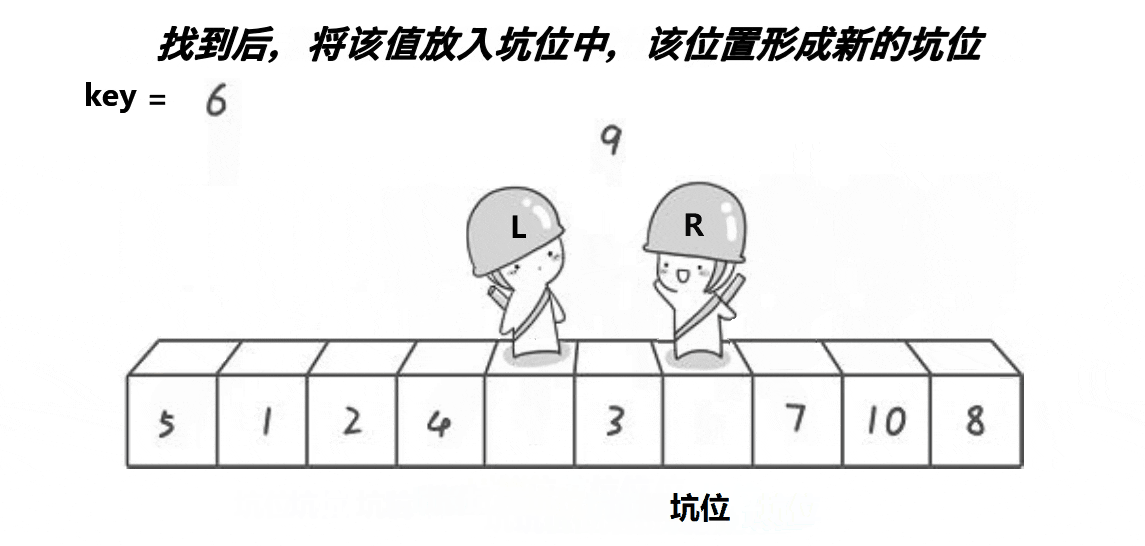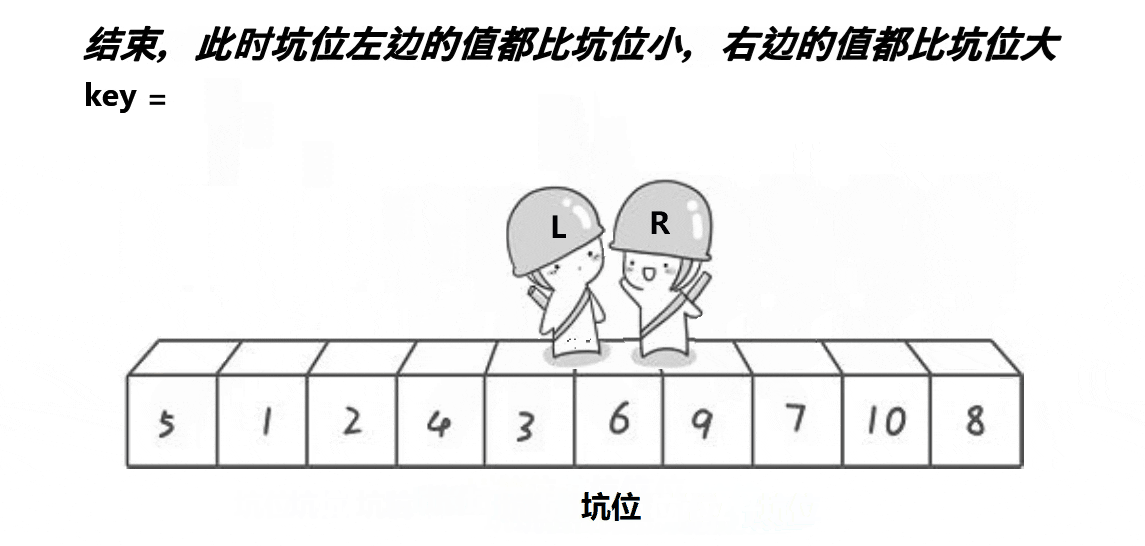
挖坑发大致思想与普通法一样,不同的是挖坑发有了坑位。挖坑发是先将首元素保存,将此位置形成坑位(其实坑位上有数据,但坑位的数据不影响,为了方便理解,所以在上图中的坑位就没写上去),然后开始首尾遍历(尾要先遍历,原理同上),比key大的元素放在后面,比key小的元素放在前面,一旦不满足此情况,这个数据将给到位置L或位置R,原本的位置将会形成坑位,直到两者相遇为止,结束遍历,最后把key的值放入坑位即可。代码如下:
int PartSort2(int* a, int begin, int end) {
int key = a[begin];
int hole = begin;//开头先形成坑位
while (begin < end) {
// 右边先走(原理与PartSort1原理一样),找小,填到左边的坑,右边形成新的坑位
while (begin < end && a[end] >= key) {
end--;
}
a[hole] = a[end];
hole = end;
// 左边再走,找大,填到右边的坑,左边形成新的坑位
while (begin < end && a[begin] <= key) {
begin++;
}
a[hole] = a[begin];
hole = begin;
}
a[hole] = key;
return hole;
}
3,前后指针法(prev是前指针,cur是后指针,此指针是位置指针,不是我们所常说的指针型),原理图如下:
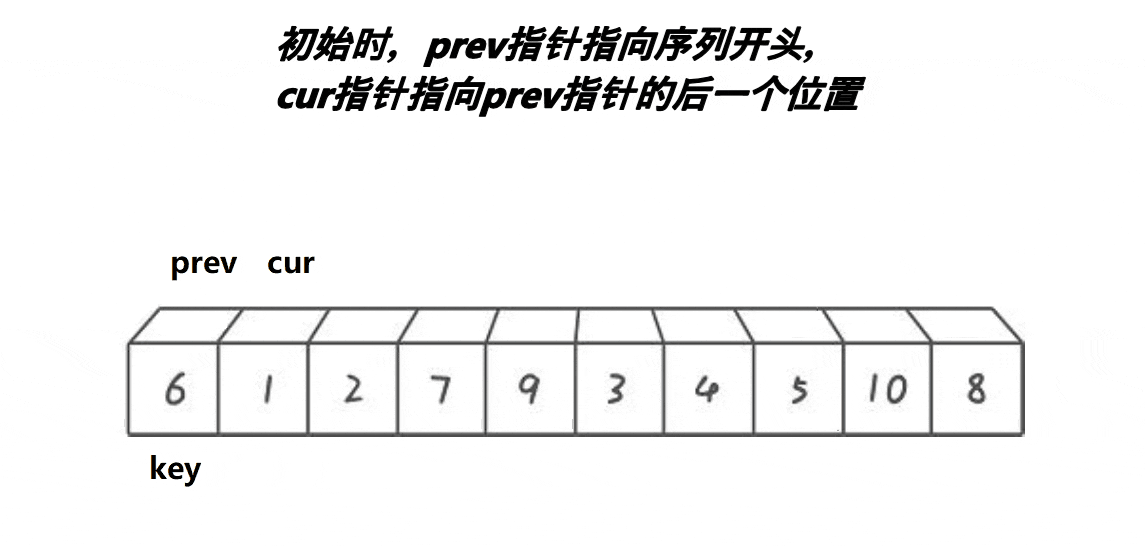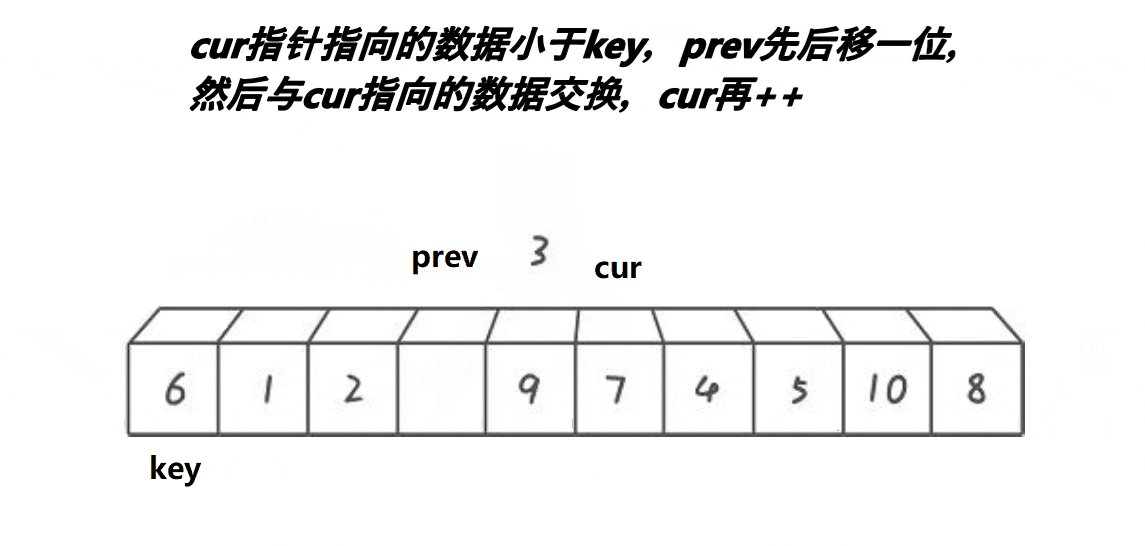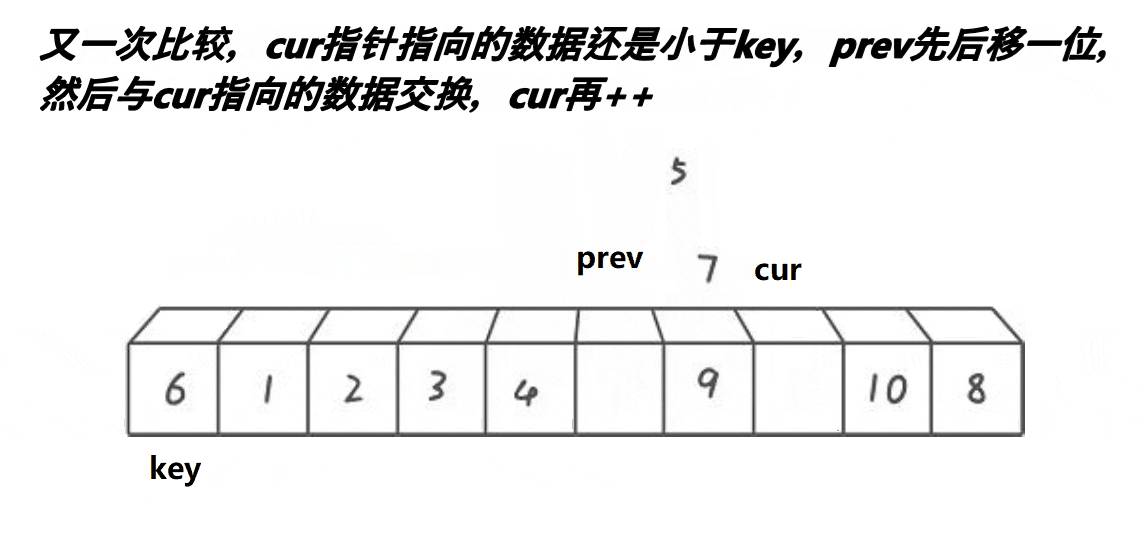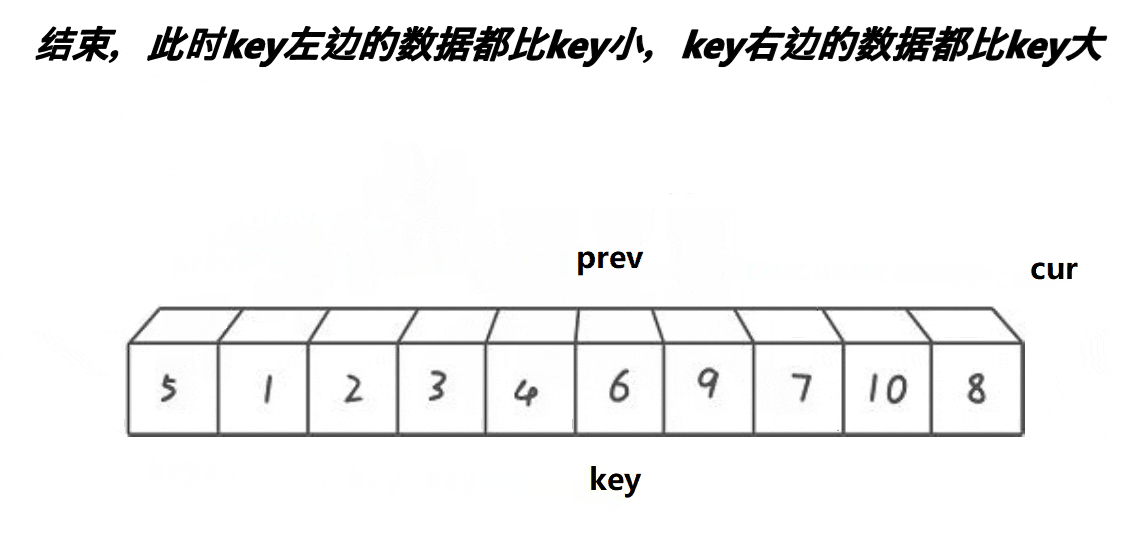
前后指针法跟上面两种方法有很大不同,如上,以第一个元素为基准,即定义key值为首元素,cur往前遍历,prev随之跟上cur的步伐,当prev遇到的数据比key小,prve向前移动;当prev遇到的数据比key大,prev停止移动,此时,cur不断向前移动,一旦找到比key小的数据就会跟prev指向的数据进行交换,最后,当cur遍历完整个数据后cur与key会进行交换,确定此时key所对应的值比左边数据大,比右边数据小。代码如下:
void Swap(int* x1, int* x2) {
int t = *x1;
*x1 = *x2;
*x2 = t;
}
int PartSort3(int* a, int begin, int end) {
int front = begin + 1;
int back = begin;
while (front <= end) {
if (a[front] <= a[begin]) {
back++;
Swap(a + back, a + front);
}
front++;
}
//因为后指针控制,所以当程序结束后back所指向的数据都比keyi所指向的数据小
Swap(a + begin, a + back);
return back;
}
总:以上三种遍历确定基准值的方法在快排称为预排序,每一趟预排序都可确定数据中一个元素的排序位置,每当确定一个数据后相对位置后,我们只需要不断以上次遍历时确定的基准值为界,递归遍历数据,即可确定最终确定序列。
二,递归遍历
当我们明白如何确定基准值后,接下来就是程序的结构搭建了,上面说过,快排递归跟二叉树的前序遍历一样,并且还需要以基准值为分界线,不断确定基准值,具体思路导图如下:

当确定好基准值key后,以区间[begin, key - 1]和区间[key + 1, end]进行划分(begin是要进行遍历时,开头元素的坐标,end是要遍历时,结尾元素的坐标,如上图),以次区间不断进行与二叉树前序遍历相同的递归,根据上图所示,很明显,当begin>=end时结束下一层递归。代码如下:
void QuickSort(int* a, int begin, int end)
{
//即当不存在区间时结束,即就排好了一个数
if (begin >= end)
return;
//运用普通法PartSort1,此算法是返回一个顺序表中中间值的坐标,在坐标左边都小于此数,在坐标的右边都大于此数
int keyi = PartSort1(a, begin, end);//也可用挖坑法和前后指针法
// 区间递归: 以keyi为界,左[begin, keyi-1],右[keyi+1, end],一直缩小,最终会逐渐会缩小成有序
QuickSort(a, begin, keyi - 1);//在keyi的左面进行遍历
QuickSort(a, keyi + 1, end);//在keyi的右面进行遍历
}
下面是总代码:
#include <stdio.h>
void Swap(int* x1, int* x2) {int t = *x1;*x1 = *x2;*x2 = t;
}
int PartSort1(int* a, int begin, int end) {int key = begin;while (begin < end) {//注意此步骤,end必须先开始(即当左边开始行走右边一定有比key小的值),//因为要控制最后的begin最终比key(开头元素)小,因此,右边必须先走.while (begin < end && a[end] >= a[key]) {end--;}//当走左边时,最终会Swap(a + end, a + begin);交换后begin的最终比key小while (begin < end && a[begin] <= a[key]) {begin++;}Swap(a + end, a + begin);}Swap(a + key, a + begin);return begin;
}
void QuickSort(int* a, int begin, int end)
{//即当不存在区间时结束,即就排好了一个数if (begin >= end)return;//PartSort1算法是返回一个顺序表中中间值的坐标,在坐标左边都小于此数,在坐标的右边都大于此数int keyi = PartSort1(a, begin, end);// 区间递归: 左[begin, keyi-1] keyi 右[keyi+1, end],一直缩小,最终会逐渐会缩小成排序QuickSort(a, begin, keyi - 1);//在keyi的左面进行遍历QuickSort(a, keyi + 1, end);//在keyi的右面进行遍历
}
void Print(int* a, int n) {for (int i = 0; i < n; i++) {fprintf(stdout, "%d ", a[i]);}puts("");
}
void TestQuickSort()
{int a[] = { 6,1,2,7,9,3,4,5,10,8 };QuickSort(a, 0, sizeof(a) / sizeof(int) - 1);Print(a, sizeof(a) / sizeof(int));
}
int main() {TestQuickSort();return 0;
}运行图:
三,非递归的快排
运用非递归,大多数要运用栈结构,因为递归本身其实就是不断入栈和出栈,递归过程跟栈结构一样,进入递归就是入栈,出函数就是出栈,都是先进后出。快排的非递归实现,我们也可用栈来实现。根据前面递归的运用,递归是不断进行区间分割,我们可将此区间放入栈中,然后进行不断循环遍历,每当遍历时就将区间放入栈中,一旦用完此区间就释放,跟递归中函数栈帧的创建与销毁一样。非递归结构代码如下:
1,栈的建立
typedef struct stack {
int* Data;
int Capacity;
int Top;
}Stack;
//以下三个是要运用栈结构的算法
void StackInit(Stack* S);
void StackPop(Stack* S);
void StackPush(Stack* S, int X);
//栈功能的实现
void StackInit(Stack* S) {//初始化栈
assert(S);
S->Data = 0;
S->Capacity = 0;
S->Top = -1;
}
void StackPop(Stack* S) {//出栈
assert(S || S->Data || S->Top != -1);
S->Top--;
}
void StackPush(Stack* S, int X) {//入栈
assert(S);
if (!S->Data) {
S->Data = (int*)malloc(sizeof(int) * 4);
assert(S->Data);
S->Capacity = 4;
}
else if (S->Top == S->Capacity - 1) {
S->Data = (int*)realloc(S->Data, (sizeof(int) * S->Capacity) * 2);
assert(S->Data);
S->Capacity *= 2;
}
S->Data[++S->Top] = X;
}
2,非递归的结构
void QuickSort(int* a, int left, int right) {
//创建栈结构S,以栈来模仿递归过程
Stack* S = (Stack*)malloc(sizeof(Stack));
StackInit(S);
StackPush(S, right);
StackPush(S, left);
while (S->Top != -1) {
//确定左右区间,每当遍历完一次时要及时更换,即从栈中去除操作
int begin = S->Data[S->Top];
StackPop(S);
int end = S->Data[S->Top];
StackPop(S);
//用指定好的区间进行预排序,即一次遍历
int key = PartSort1(a, begin, end);
//进行左区间的遍历
if (end - 1 > begin) {
//注意栈结构先进后出的特点,要先把end装进去
StackPush(S, end - 1);
StackPush(S, begin);
}
//进行右区间的遍历
if (begin + 1 < end) {
//同理,要先把end装进去
StackPush(S, end);
StackPush(S, begin + 1);
}
}
free(S);
//注意,不能在此算法内这样写,因为这是的a是首元素地址,即指针,sizeof(a)为地址的大小
//Print(a, sizeof(a) / sizeof(int));
}
以上是非递归过程中的逻辑代码,除此两大步,其它的逻辑运用与递归无任何区别,总代码如下:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef struct stack {int* Data;int Capacity;int Top;
}Stack;//以下三个是要运用栈结构的算法
void StackInit(Stack* S);
void StackPop(Stack* S);
void StackPush(Stack* S, int X);
//栈功能的实现
void StackInit(Stack* S) {//初始化栈assert(S);S->Data = 0;S->Capacity = 0;S->Top = -1;
}
void StackPop(Stack* S) {//出栈assert(S || S->Data || S->Top != -1);S->Top--;
}
void StackPush(Stack* S, int X) {//入栈assert(S);if (!S->Data) {S->Data = (int*)malloc(sizeof(int) * 4);assert(S->Data);S->Capacity = 4;}else if (S->Top == S->Capacity - 1) {S->Data = (int*)realloc(S->Data, (sizeof(int) * S->Capacity) * 2);assert(S->Data);S->Capacity *= 2;}S->Data[++S->Top] = X;
}
void Swap(int* x1, int* x2) {int t = *x1;*x1 = *x2;*x2 = t;
}
int PartSort1(int* a, int begin, int end) {int key = begin;while (begin < end) {//注意此步骤,end必须先开始(即当左边开始行走右边一定有比key小的值),//因为要控制最后的begin最终比key(开头元素)小,因此,右边必须先走.while (begin < end && a[end] >= a[key]) {end--;}//当走左边时,最终会Swap(a + end, a + begin);交换后begin的最终比key小while (begin < end && a[begin] <= a[key]) {begin++;}Swap(a + end, a + begin);}Swap(a + key, a + begin);return begin;
}
void QuickSort(int* a, int left, int right) {//创建栈结构S,以栈来模仿递归过程Stack* S = (Stack*)malloc(sizeof(Stack));StackInit(S);StackPush(S, right);StackPush(S, left);while (S->Top != -1) {//确定左右区间,每当遍历完一次时要及时更换,即从栈中去除操作int begin = S->Data[S->Top];StackPop(S);int end = S->Data[S->Top];StackPop(S);//用指定好的区间进行预排序,即一次遍历int key = PartSort1(a, begin, end);//进行左区间的遍历if (end - 1 > begin) {//注意栈结构先进后出的特点,要先把end装进去StackPush(S, end - 1);StackPush(S, begin);}//进行右区间的遍历if (begin + 1 < end) {//同理,要先把end装进去StackPush(S, end);StackPush(S, begin + 1);}}free(S);//注意,不能在此算法内这样写,因为这是的a是首元素地址,即指针,sizeof(a)为地址的大小//Print(a, sizeof(a) / sizeof(int));
}
void Print(int* a, int n) {for (int i = 0; i < n; i++) {fprintf(stdout, "%d ", a[i]);}puts("");
}
int main() {int a[] = { 0,5,7,9,3,4,1,6,2,8 };QuickSort(a, 0, sizeof(a) / sizeof(int) - 1);Print(a, sizeof(a) / sizeof(int));return 0;
}运行图:
四,快排的效率
1,快排的效率分析
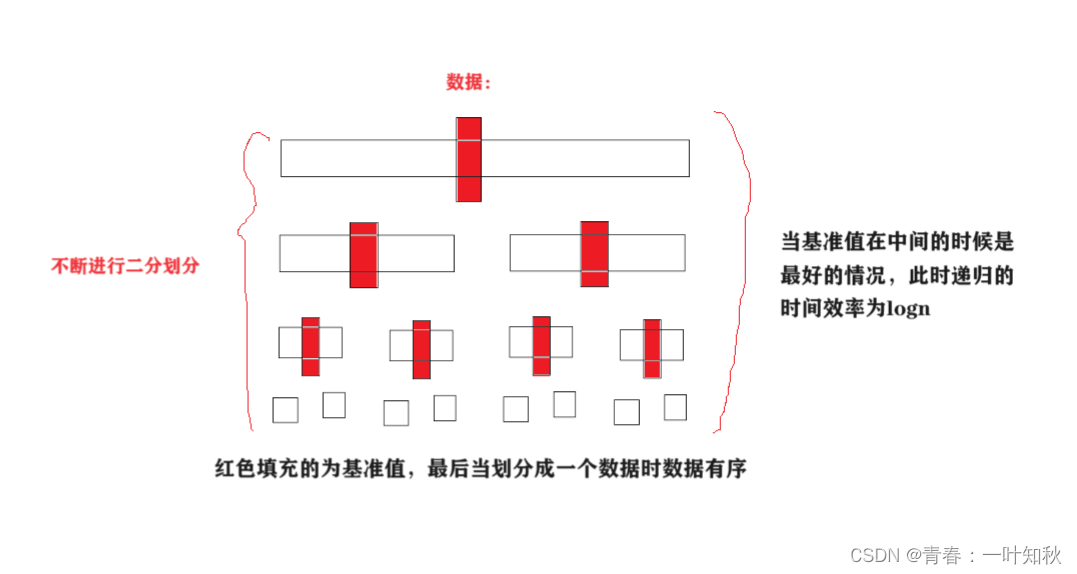
快排效率在平常说是效率比较高的,大致根据二叉树原理计算,快排时间复杂度为O(nlogn),空间复杂度为O(logn),但这只是对于大多时候,其实快排的时间效率是很不确定的,快排的效率跟数据的原有序列有关,序列越接近有序,快排效率越低。我们先观察以下图:
快排效率最好情况
快排效率最坏情况
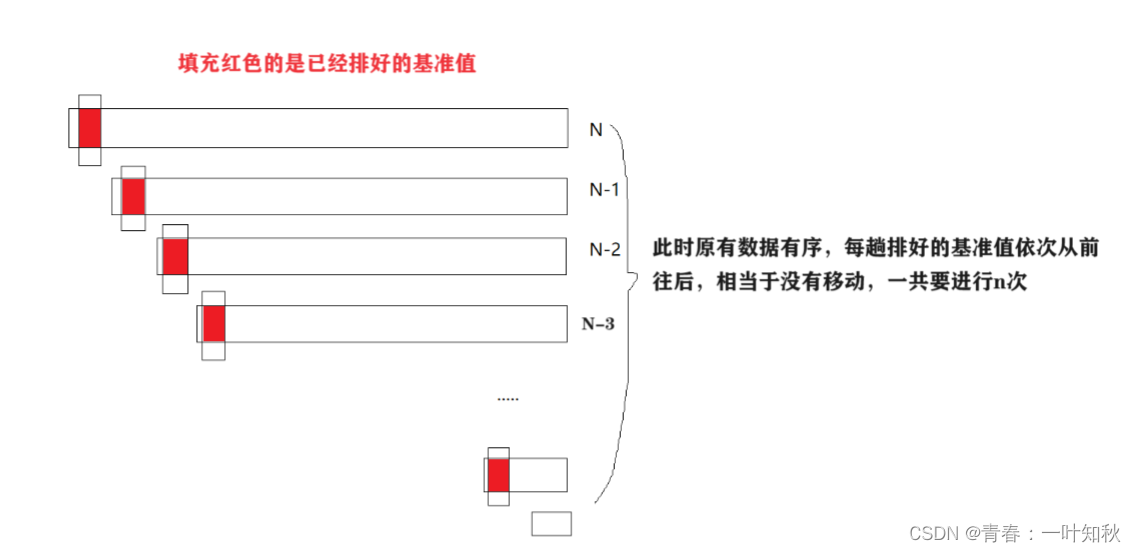
可知,快排预排序的时间效率在区间[logn,n],当原有序列越有序时,无论是递归还是非递归时间效率都很低,有序时效率最低,而遍历元素的时间复杂度不变,一直是O(n),因此快排的时间效率在区间[nlogn,n^2]。
2,三数取中
当快排在有序时(升序为例),数据会靠近左边进行排序,而要想提高快排的效率,就必须尽量让基准值尽量往中间靠拢,但这样很难控制,因为这与数据原有的序列有关。虽然说我们不能直接控制,但是我们可控制最坏情况来进而控制时间效率,即序列有序时的情况。
通常,我们是选取首元素为基准值的,因此,只要控制好首元素不为基准值的情况即可,也就是三数取中。
三数取中是将判断首元素,尾元素,中间元素三者之间的大小,将中间大的数据与首元素交换,使首元素不可能为基准值。代码如下:
int GetMidi(int* a, int left, int right)
{
int mid = (left + right) / 2;//中间数mid
//下面比较 left mid right 三者之间大小,将中间大的数据的下标返回过去
//先人left与mid比较,然后进一步判断right
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right]) // mid是最大值
{
return left;
}
else
{
return right;
}
}
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right]) // mid是最小
{
return left;
}
else
{
return right;
}
}
}
具体思想就是先两两比较,然后进一步与第三者比较,上面代码中选举了left与mid两者之间比较,然后再跟第三者right比较,满足中间大的数据返回其下标。
3,改善后算法的运用
有了三数取中,快排将不会出现最坏情况,虽说有可能会出现次坏情况,但基本是不可能的,因为这种情况很是要求原序列的次序和三数取中的交换,因次,如若在算法中加上三数取中后算法的时间复杂度基本为O(nlogn)。下面是改进后运用的代码:
int GetMidi(int* a, int left, int right)
{
int mid = (left + right) / 2;//中间数mid
//下面比较 left mid right 三者之间大小,将中间大的数据的下标返回过去
//先人left与mid比较,然后进一步判断right
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right]) // mid是最大值
{
return left;
}
else
{
return right;
}
}
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right]) // mid是最小
{
return left;
}
else
{
return right;
}
}
}
void Swap(int* x1, int* x2) {
int t = *x1;
*x1 = *x2;
*x2 = t;
}
//普通法
int PartSort1(int* a, int begin, int end) {
//运用三数取中,与每次预排序的区间首元素交换,防止出现最坏情况
int midi = GetMidi(a, begin, end);
Swap(a + begin, a + midi);
//以下代码正常不变
int key = begin;
while (begin < end) {
//注意此步骤,end必须先开始(即当左边开始行走右边一定有比key小的值),
//因为要控制最后的begin最终比key(开头元素)小,因此,右边必须先走.
while (begin < end && a[end] >= a[key]) {
end--;
}
//当走左边时,最终会Swap(a + end, a + begin);交换后begin的最终比key小
while (begin < end && a[begin] <= a[key]) {
begin++;
}
Swap(a + end, a + begin);
}
Swap(a + key, a + begin);
return begin;
}
//挖坑发
int PartSort2(int* a, int begin, int end) {
//运用三数取中,与每次预排序的区间首元素交换,防止出现最坏情况
int midi = GetMidi(a, begin, end);
Swap(a + begin, a + midi);
//以下代码正常不变
int key = a[begin];
int hole = begin;//开头先形成坑位
while (begin < end) {
// 右边先走(原理与PartSort1原理一样),找小,填到左边的坑,右边形成新的坑位
while (begin < end && a[end] >= key) {
end--;
}
a[hole] = a[end];
hole = end;
// 左边再走,找大,填到右边的坑,左边形成新的坑位
while (begin < end && a[begin] <= key) {
begin++;
}
a[hole] = a[begin];
hole = begin;
}
a[hole] = key;
return hole;
}
//前后指针法
int PartSort3(int* a, int begin, int end) {
//运用三数取中,与每次预排序的区间首元素交换,防止出现最坏情况
int midi = GetMidi(a, begin, end);
Swap(a + begin, a + midi);
//以下代码正常不变
int front = begin + 1;
int back = begin;
while (front <= end) {
if (a[front] <= a[begin]) {
back++;
Swap(a + back, a + front);
}
front++;
}
//因为后指针控制,所以当程序结束后back所指向的数据都比keyi所指向的数据小
Swap(a + begin, a + back);
return back;
}
在以上中,除了预排序算法需要改进,其它的都不用动即可实现高效的快排。最后,跟大家再次强调一下快排的效率,快排在大多数情况下确实效率很高,但快排的效率受原数据的序列影响比较大,当序列越接近有序时,快排的效率可能还没有其它算法高,在以后的运用中要不要用快排还需根据原数据的情况而定。
相关文章:
【数据结构】快排的详细讲解
目录: 介绍 一,递归快排确定基准值 二,递归遍历 三,非递归的快排 四,快排的效率 介绍 快排是排序算法中效率是比较高的,快排的基本思想是运用二分思想,与二叉树的前序遍历类似,…...
蓝牙资讯|三星推迟发布智能戒指Galaxy Ring,智能穿戴小型化是大趋势
根据外媒 The Elec 报道,Galaxy Ring这款戒指主要面向健康和 XR 头显市场,该智能戒指可能被延期至 2024 年第三季度后发布。 外媒声称三星 Galaxy Ring 的上市周期,主要取决医疗认证的相关审批时间,三星计划将在 2024 年第三季度…...

移动端tree树
注意: 这是uniapp的写法,vue想用的话需要改造一下,里边的view和text,vue不能用,改成div,span即可。 样式rpx也要改成px tree树组件(QQ群:旧群没了,新群:801142650) - …...

SpringTask ----定时任务框架 ----苍穹外卖day10
目录 SpringTask 需求分析 快速入门 使用步骤 编辑业务开发 SpringTask 定时任务场景特化的框架 需求分析 快速入门 使用cron表达式来使用该框架 使用步骤 添加注解 自定义定时任务类 重点在于以下cron表达式的书写,精确表达触发的间隔 业务开发 主task方法 time使用(-…...

Fuzz测试:发现软件隐患和漏洞的秘密武器
0x01 什么是模糊测试 模糊测试(Fuzz Testing)是一种广泛用于软件安全和质量测试的自动化测试方法。它的基本思想是向输入参数或数据中注入随机、不规则或异常的数据,以检测目标程序或系统在处理不合法、不正常或边缘情况下的行为。模糊测试通…...
无为WiFi的一批服务器
我们在多个地区拥有高速服务器,保证网速给力,刷片无压力 嘿嘿 <?phpinclude("./includes/common.php"); $actisset($_GET[act])?daddslashes($_GET[act]):null; $urldaddslashes($_GET[url]); $authcodedaddslashes($_GET[authcode]);he…...

SpringBoot3.0——踩坑
SpringBoot3.0后有一些改动 JDK要17以上lombok <dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.20</version> </dependency>servlet <dependency><groupId>ja…...

Springboot的自动装配原理和文件上传FastDFS
Spring Boot的自动装配原理: Spring Boot的自动装配原理是基于约定大于配置的原则,它通过扫描类路径下的各种文件以及类的注解信息来自动配置应用程序的各种组件和功能。Spring Boot会根据约定的规则自动配置相应的Bean,这些Bean都是单例的&…...

【数据库开发】DQL操作和多表设计
数据库开发 一、数据库操作-DQL 1.概述 用来查询数据库表中的记录,查询操作分为两部分,单表操作和多表操作,针对于查询而言(相较于增删改更加的灵活)基于目标分析条件转换为SQL语句 2.语法 SELECT 字段列表 FROM表…...

用PyTorch轻松实现二分类:逻辑回归入门
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
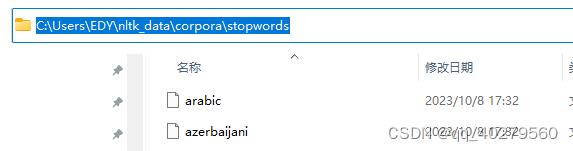
[nltk_data] Error loading stopwords: <urlopen error [WinError 10054]
报错提示: >>> import nltk >>> nltk.download(stopwords) 按照提示执行后 [nltk_data] Error loading stopwords: <urlopen error [WinError 10054] 找到路径C:\\Users\\EDY\\nltk_data,如果没有nltk_data文件夹,在…...

基于Spring Boot的网上租贸系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

通过IP地址管理提升企业网络安全防御
在今天的数字时代,企业面临着越来越多的网络安全威胁。这些威胁可能来自各种来源,包括恶意软件、网络攻击和数据泄露。为了提高网络安全防御,企业需要采取一系列措施,其中IP地址管理是一个重要的方面 1. IP地址的基础知识 首先&a…...
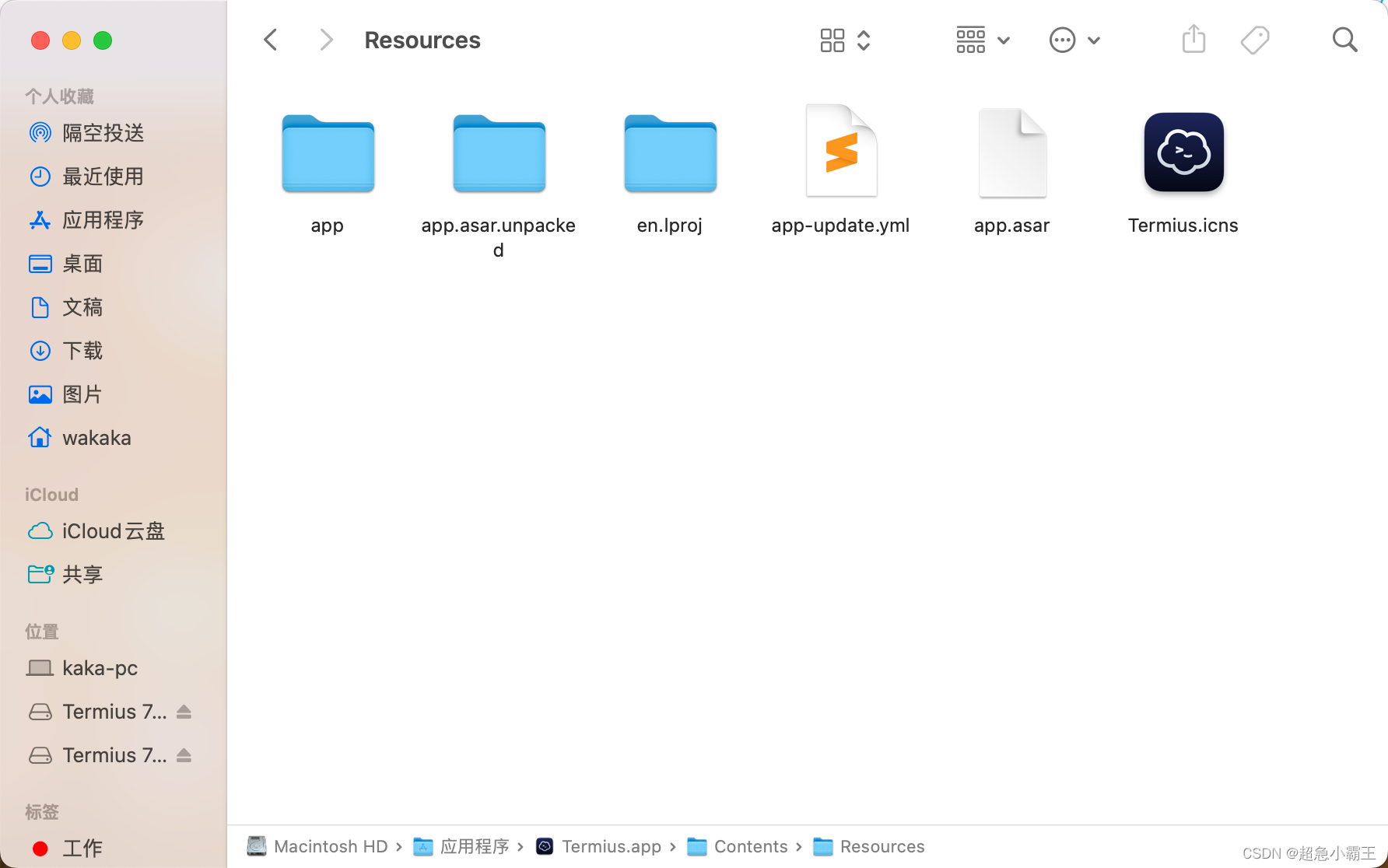
termius mac版无需登录注册直接永久使用
1. 下载地址:termius下载 2. 解压安装 3. 当出现 “termius”已损坏,无法打开 则输入以下命令即可:sudo xattr -r -d com.apple.quarantine /Applications/Termius.app 最后去 系统设置-> 隐私与安全性-> 仍要打开 4. 删除app-update.yml文件&…...

TPU编程竞赛|Stable Diffusion大模型巅峰对决,第五届全球校园人工智能算法精英赛正式启动!
目录 赛题介绍 赛题背景 赛题任务 赛程安排 评分机制 奖项设置 近日,2023第五届全球校园人工智能算法精英赛正式开启报名。作为赛题合作方,算丰承办了“算法专项赛”赛道,提供赛题「面向Stable Diffusion的图像提示语优化」,…...

微信小程序 rpx 转 px
前言 略 rpx 转 px let query wx.createSelectorQuery(); query.selectViewport().boundingClientRect(function(res){let rpx2Px 1 * (res.width/750);console.log("1rpx " rpx2Px "px"); }); query.exec();参考 https://blog.csdn.net/qq_39702…...

机器学习之旅-从Python 开始
导读你想知道如何开始机器学习吗?在这篇文章中,我将简要概括一下使用 Python 来开始机器学习的一些步骤。Python 是一门流行的开源程序设计语言,也是在人工智能及其它相关科学领域中最常用的语言之一。机器学习简称 ML,是人工智能…...
——第103天:Pyecharts绘制多种炫酷水球图参数说明+代码实战)
100天精通Python(可视化篇)——第103天:Pyecharts绘制多种炫酷水球图参数说明+代码实战
文章目录 专栏导读一、水球图介绍1. 水球图是什么?2. 水球图的应用场景二、水球图类配置选项1. 导包2. Liquid类3. add函数三、水球图实战1. 基础水球图2. 矩形水球图3. 圆棱角矩形水球图4. 三角形水球图5. 菱形水球图6. 箭头型水球图7. 修改数据精度8. 设置无边框9. 多个并排…...
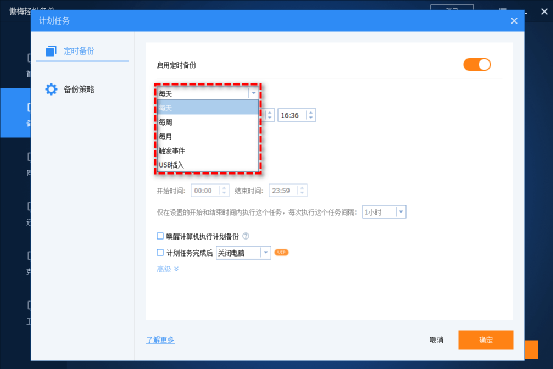
好用的文件备份软件推荐!
为什么需要文件备份软件? 在我们使用计算机的日常工作生活中,可能会遇到各种不同类型的文件,例如文档、Word文档、Excel表格、PPT演示文稿、图片等,这些数据中可能有些对我们来说很重要,但是可能会因为一些意外状况…...
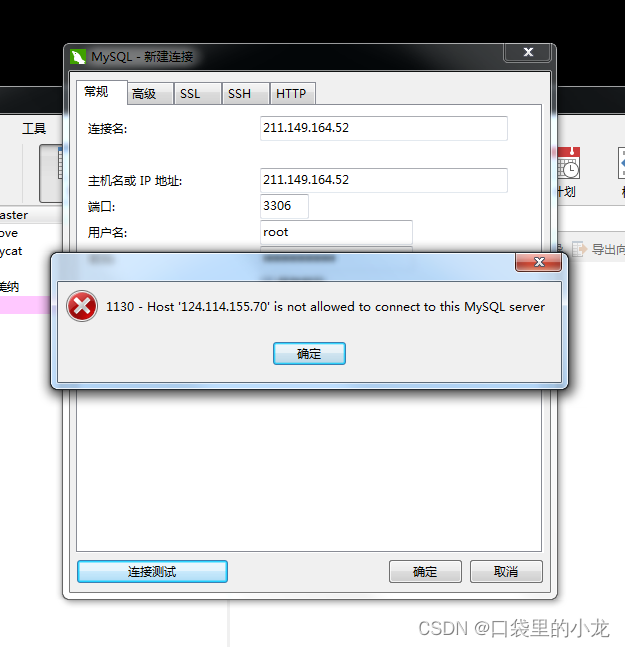
1130 - Host ‘192.168.10.10‘ is not allowed to connect to this MysOL server
mysql 远程登录报错误信息:1130 - Host 124.114.155.70 is not allowed to connect to this MysOL server //需要在mysql 数据库目录下修改 use mysql; //更改用户的登录主机为所有主机,%代表所有主机 update user set host% where userroot; //刷新权…...

ChatGPT和Gemini聊天记录导出
AI对话记录导出技术演进:从碎片化到结构化管理的范式突破 一、技术革命带来的新痛点:AI对话资产的管理困境 在生成式AI技术日臻成熟的今天,开发者与AI的交互频率呈指数级增长。以ChatGPT日均处理30亿次查询、Gemini日均生成内容超2亿次的数…...

python网上书店系统vue
目录技术栈选择前端模块划分后端API设计关键实现细节开发流程示例代码片段项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术栈选择 前端采用Vue 3(Composition API) TypeScript Vite构建工具&#…...
)
告别计划外停机:用Python+CNN+SVR实战轴承寿命预测(附PHM2012数据集代码)
工业设备智能运维实战:PythonCNNSVR实现轴承寿命精准预测 轴承作为旋转机械的核心部件,其健康状态直接影响生产线稳定性。传统定期维护常陷入"过度维护"或"维护不足"的两难境地——前者增加停机成本,后者可能引发连锁故障…...

从零到图像显示:用海康MVS SDK写一个最简单的C++相机采集程序
从零到图像显示:用海康MVS SDK写一个最简单的C相机采集程序 第一次接触工业相机开发时,最让人头疼的往往不是复杂的算法,而是如何让相机简单地显示一张图像。本文将带你用最直接的方式,在30分钟内完成从设备连接到实时显示的完整流…...

Gemini 辅助做创意写作:故事大纲、角色设定、世界观构建的 AI 协作
很多作者在创作卡壳时,其实不是“没有灵感”,而是缺一套可迭代的设计流程:大纲松散、角色像说明书、世界观看似宏大却前后不一致。2026 年的写作新趋势,是把 Gemini 当作“创作协作伙伴”而不是“代写引擎”,让它参与结…...

TAMEn系统:触觉视觉数据采集的模块化解决方案
1. TAMEn系统概述:触觉视觉数据采集的革命性方案在机器人操作领域,接触丰富的任务(如柔性物体处理、精密装配)一直面临着数据采集的挑战。传统视觉系统难以捕捉细微的接触信号(如初始滑动、局部变形)&#…...

Docker多阶段构建与镜像优化实战
Docker多阶段构建与镜像优化实战:从1GB到50MB的瘦身之旅 🐳 镜像太大?构建太慢?安全隐患太多?本文通过真实 Node.js + Python 项目,手把手教你用多阶段构建把 Docker 镜像从 1GB 压缩到 50MB,附带完整的优化策略和踩坑指南。 一、为什么你的 Docker 镜像这么大? 很多…...

spawnfile:轻量级进程编排工具,提升本地开发与测试效率
1. 项目概述:一个被低估的进程管理利器如果你在Linux或macOS环境下做过开发,尤其是需要频繁启动、停止、监控一堆后台服务(比如微服务架构下的多个组件),那你一定对进程管理工具不陌生。从最基础的nohup加&&#x…...

鸣潮自动化工具ok-ww终极指南:3步配置解放双手的智能助手
鸣潮自动化工具ok-ww终极指南:3步配置解放双手的智能助手 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves 你是否厌倦了…...

Ctool架构深度解析:模块化开发工具集的高效实现方案
Ctool架构深度解析:模块化开发工具集的高效实现方案 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool 在程序开发过程中,开发者经常需要在…...