Apache Solr9.3 快速上手
Apache Solr
简介
Solr是Apache的顶级开源项目,使用java开发 ,基于Lucene的全文检索服务器。 Solr比Lucene提供了更多的查询语句,而且它可扩展、可配置,同时它对Lucene的性能进行了优化。
安装
- 下载 : 下载地址
- 解压 :
tar -zxvf solr-9.3.0.tgz -C . - 修改solr启动参数,取消健康检查,否则启动会报警告
cd /opt/solr/solr-9.3.0/bin/vim solr.in.sh- 修改内容
SOLR_ULIMIT_CHECKS=false
启动
solr不推荐使用root账户启动,这点与es也相同,当然可以直接用-force参数,强制启动
./solr start -force
如果需要修改端口,可以通过-p参数指定
./solr start -p 8089 -force
启动成功可以看到日志打印
➜ bin ./solr start -force
Waiting up to 180 seconds to see Solr running on port 8983 [|]
Started Solr server on port 8983 (pid=3786). Happy searching!➜ bin
访问服务器ip:8983,可查看到solr管理界面
http://localhost:8983/solr/#/
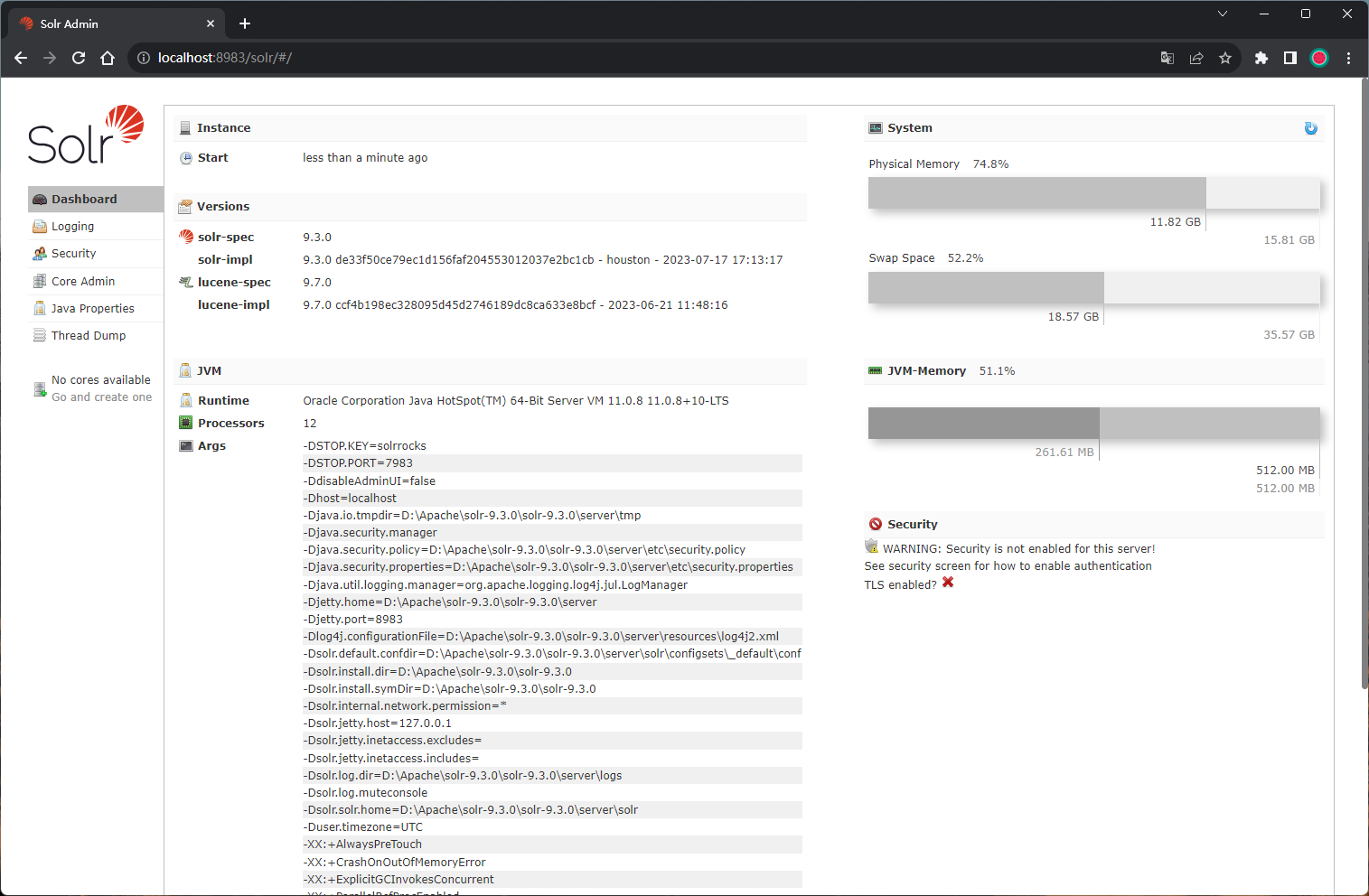
主要概念
core
在es中有索引这个概念,相当于mysql中的表(与mysql中的索引区分开来),而在solr中称之为核心 core, 所以我们可以看到页面上有一个core admin,就是用来管理核心的,个人更喜欢将其称之为索引,与es的概念形成关联记忆。
和数据库一样,solr的数据就是由一个个core组成。
doc
doc全称document, es中也有相同的概念,相当于数据库中的一行数据,一个doc也就表示的一个core中的一条数据
Schema
Schema类似于数据库中的表结构,以schema.xml的文本形式存在于conf目录下,在添加数据到索引中时,需要配置Schema。schema中包含:字段、字段类型、唯一键
分词
举个例子,我们想要搜索查询沙县小吃,那么传统的模糊查询是使用前后模糊匹配,类似 沙县小吃 ,这样的匹配模式,但如果我们的内容只有“沙县”,没有小吃时,就会导致匹配不到我们想要的信息。而分词不同,分词首先就将我们的搜索文本分割成一个个的词组,比如:沙县、小吃,然后分别匹配这些分词在哪个数据中出现的,将其匹配出来,并计算相关度得分。
倒排索引
说明了分词,我们需要继续讲解倒排索引,也叫反向索引,来帮助大家理解solr为什么能实现毫秒级的搜索体验
如下图为普通的正向索引,一句话被对应分割成了一组分词,当我们查询"china"时,会去各个文档的分词组中查询是否存在,这样的做法需要遍历每个文档,数据量较大时,明显就很慢了
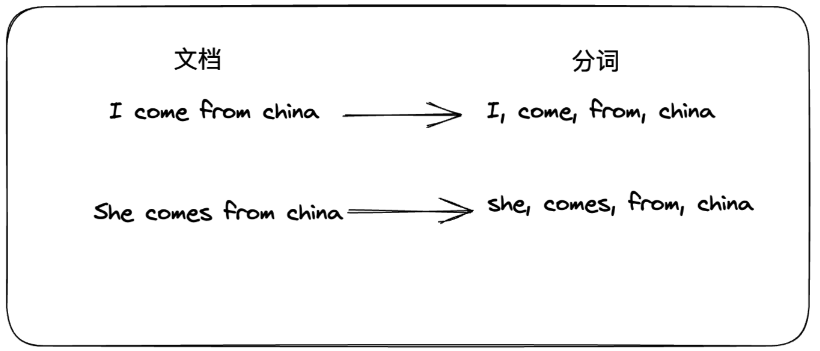
而逆向索引的处理刚好相反,以分词为存储的主键,文档ID为值,这样能直接通过分词查询出哪些文档存在该关键字,通过文档ID是顺序存储的,那么也就意味着是有压缩空间的,具体大家可以参考之前书写的关于ES的分词压缩算法,核心思想类似:浅谈倒排索引的两种压缩算法:FOR算法和RBM算法
倒排索引的存储方式,其核心优势就在于当数量特别大时,其在性能的提高和空间上的节约

创建Core
通过管理画面http://ip:8983/solr的core Admin模块进行创建会失败,提示在新创建的core目录\conf\下找不到solrconfig.xml和managed-schema.xml,所以我们采用命令行的方式来创建Core。
PS D:\Apache\solr-9.3.0\solr-9.3.0\bin> .\solr.cmd create -c core_test1
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.To turn off: bin\solr config -c core_test1 -p 8983 -action set-user-property -property update.autoCreateFields -value falseCreated new core 'core_test1'
PS D:\Apache\solr-9.3.0\solr-9.3.0\bin>
- Overview: 概览,一些核心/索引的统计信息
- Analysis: 分词查询,如果想知道某个查询词会被分词成什么样,可在这里操作,类似es中的_analyze语句
- DataImport: 数据同步,分为增量同步和全量同步
- Documents: 数据新增或更新、删除,新增和更新用的都是/update,id存在则更新,不存在则新增
- Files: 配置文件信息,也提供了上传或下载文件到solr服务的功能,可以通过此自定义查询组件
- Ping: 用于测试与solr服务器之前的连接是否正常
- Plugins/Stats:插件管理页面,可以查看、启用、禁用已经安装了的solr插件
- Query:查询页面,提供在线查询solr数据的页面
- Replication:管理solr分片配置
- Schema:管理solr索引结构
- Segments info:查看solr索引的段信息,了解索引大小、文档数量、字段等信息
配置solr字段
添加字段有2种方法,可以通过web页面添加,也可以直接修改schema文件添加。
| 属性 | 说明 | 取值 | 默认值 |
|---|---|---|---|
| stored | 是否存储,一个字段是否被存储,取决于你是否想在solr的查询结果中得到它,也就是说你是否想在查询结果中看到它,它将会消耗cpu和io和磁盘空间等资源。 | true/false | true |
| indexed | 字段是否创建索引,索引的字段是在搜索的时候可以用它来查询或排序,在lucene中,被索引的字段将会建立倒排表。 | true/false | true |
| uninvertible | 如果为 true,则表示一个 indexed=“true” docValues=“false” 字段在查询时可以用“un-inverted”构建大内存数据结构以代替 DocValues。 出于历史原因,默认为 true,但强烈建议用户将其设置 false 以保持稳定性,并据需要使用 docValues=“true”。 | true/false | true |
| docValues | 字段的值是否放在面向列的 DocValues 结构中 | true/false | false |
| multiValued | 设置为true表示此字段可以存储多个值,意思是这个字段在一个文档中可以存储多个值的内容。 | true/false | false |
| required | 是否必须。如果为 true,则 Solr 拒绝任何添加没有此字段的文档。 | true/false | false |
| default | 字段的默认值,经常用在字段是必须的,但是有时候又无法提供的情况,solr就会用默认值替代。如: <field name="recordTime" type="date" indexed="true" stored="true" required="true" default="NOW+8HOUR"/> 标示recordTime如果没有提供,用当前的时间+8个小时作为recordTime的时间,加8小时是因为solr默认时区是0时区,按照中国北京时间(东8区)算,需要加上8个小时。 |
修改managed-schema
在core的conf下的managed-schema文件中增加字段配置
<!-- 自定义的字段,id已经存在不需要设置 -->
<field name="dd" type="string" indexed="true" stored="true"/>
<field name="age" type="pint" indexed="true" stored="true" />
<field name="description" type="text_ik" indexed="true" stored="true" />
<field name="createTime" type="pdate" indexed="true" stored="true" />
<field name="updateTime" type="pdate" indexed="true" stored="true" />

添加后到“Core Admin”中刷新一下核即可
添加数据
现在core已经建好了,但是里面还没有数据,这里我们使用json添加以便快速演示(支持 JSON,、CSV、XML等格式),一般生产环境下都是从数据库访问。
准备json数据:
{"id": "11","age": 40,"name": "李白","description": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"},
{"id": "12","age": 31,"name": "杜甫","description": "唐代伟大的现实主义文学作家,唐诗思想艺术的集大成者"}
找到该core的Documents菜单,选择文档类型未JSON,把刚才准备的数据粘贴进来,确认无误提交
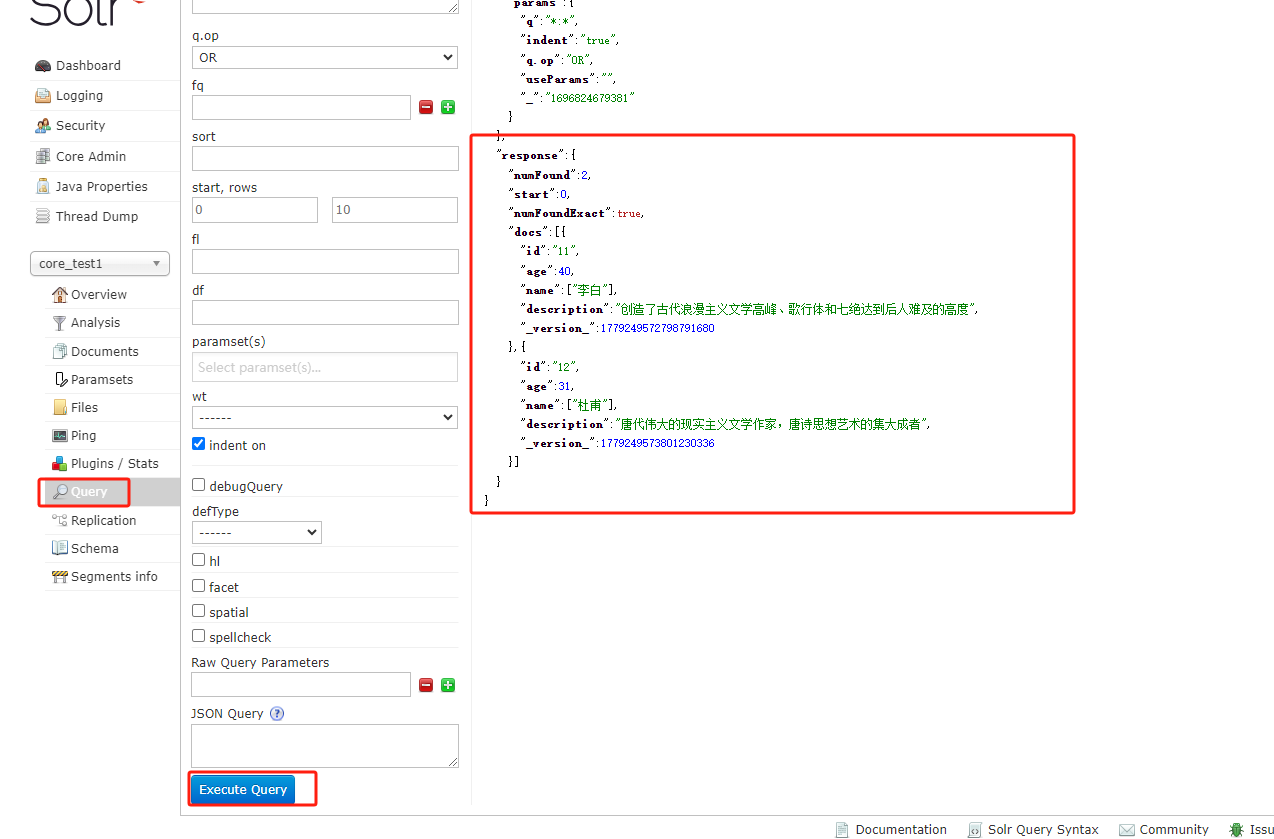
查询
现在验证一下查询一下
安装中文分词器
下载地址
将ik-analyzer-8.5.0.jar放入solr目录下
存放于 *solr-9.1.0\server\solr-webapp\webapp\WEB-INF\lib* 目录下
编辑 D:\Apache\solr-9.3.0\solr-9.3.0\server\solr\core_test1\conf\managed-schema.xml
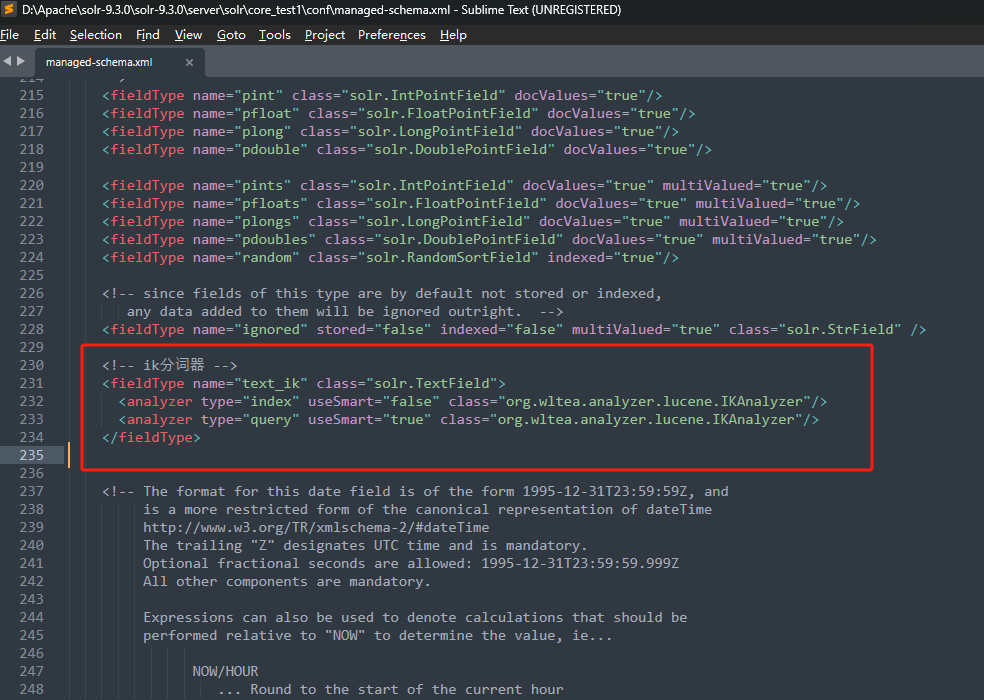
查询
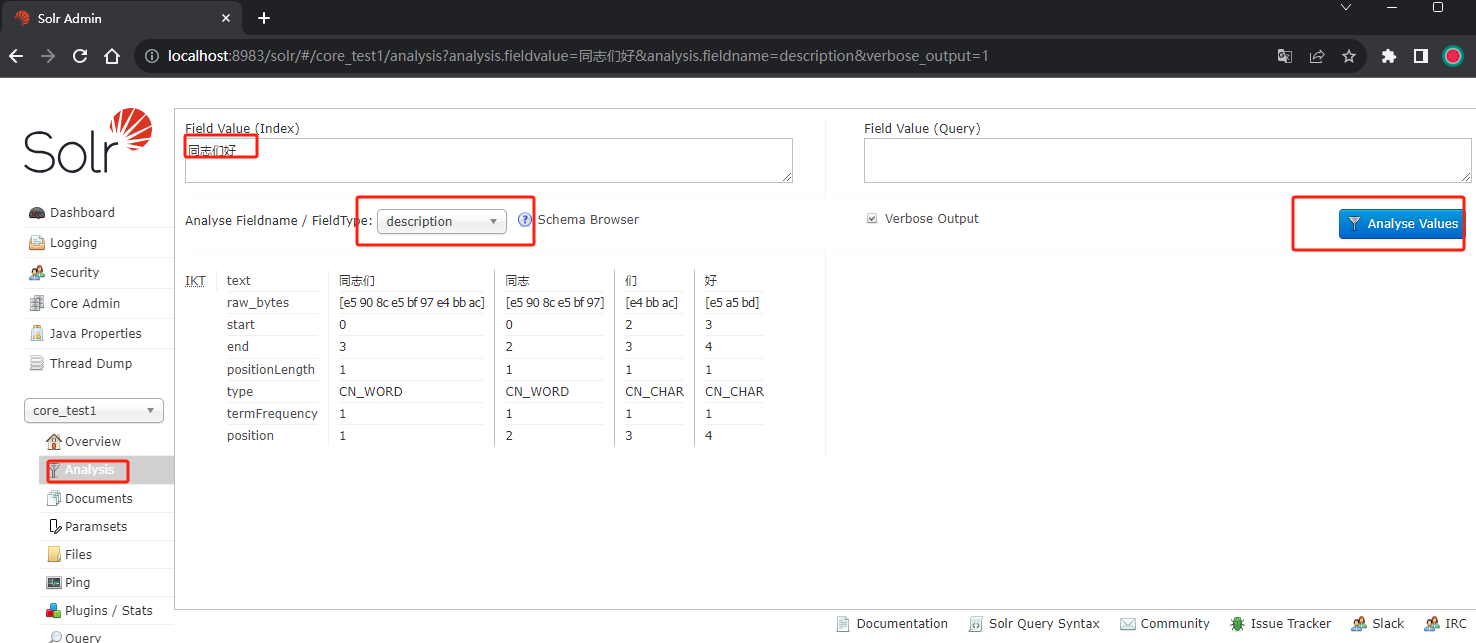
到core的分词菜单中验证一下description字段是否按中文分词了,可以看到一件按照中文的分词习惯进行了分词。
相关文章:
Apache Solr9.3 快速上手
Apache Solr 简介 Solr是Apache的顶级开源项目,使用java开发 ,基于Lucene的全文检索服务器。 Solr比Lucene提供了更多的查询语句,而且它可扩展、可配置,同时它对Lucene的性能进行了优化。 安装 下载 : 下载地址解压 : tar -zxv…...

按关键字搜索淘宝商品API接口获取商品销量、优惠价、商品标题等参数示例
关键词搜索商品接口的作用是提供搜索功能,让用户根据关键词在电商平台上搜索商品,并根据搜索条件和偏好获取相关的商品列表和推荐结果,提高用户购物体验和准确度。对于电商平台而言,这个接口也能帮助用户发现更多商品、提升销量和…...

【外汇天眼】价格波动的节奏感:优化止盈方法!
止盈,依然是一种经验,而不是一种技术。它涉及到价格波动的灵活应对,以确保我们不会错失潜在的盈利,同时也不会让盈利被逆市波动所侵蚀。以下是关于如何有效实施止盈策略的一些建议: 首先,我们要明确&#…...
VMvare虚拟机安装国产麒麟V10桌面操作系统
一、系统下载 进入银河麒麟官网:https://www.kylinos.cn/ 选择桌面操作系统,然后进入操作系统版本选择页面,选择银河麒麟桌面操作系统V10 选择后,进入系统介绍页面,然后点击申请试用 点击后进入申请页面…...
Golang--channel+waitGroup控制并发量
文章目录 channelwaitGroup控制并发量前言示例 channelwaitGroup控制并发量 前言 golang的goroutine非常轻量级,同时启动数万协程都没问题。如果不对并发量进行控制,比如同时产生数百万的协程,会压垮服务器通过控制channel缓冲区的大小&…...

前端【响应式图片处理】之 【picture标签】
目录 🌟前言🌟目前最常见的解决方案🌟新的解决方案<picture>🌟<picture>的工作原理🌟<picture> 兼容性解决方案🌟写在最后 🌟前言 哈喽小伙伴们,前端开发过程中经…...

js实现链式调用,查询和处理数据
实现一个 query 方法,实现对数据的链式查询和处理 要求如下 query 传入参数为原始数据(数组格式,每个元素都是对象) 通过进行链式调用对数据执行操作,支持的方法有where(predicate): 根据参数的条件进行筛选࿰…...
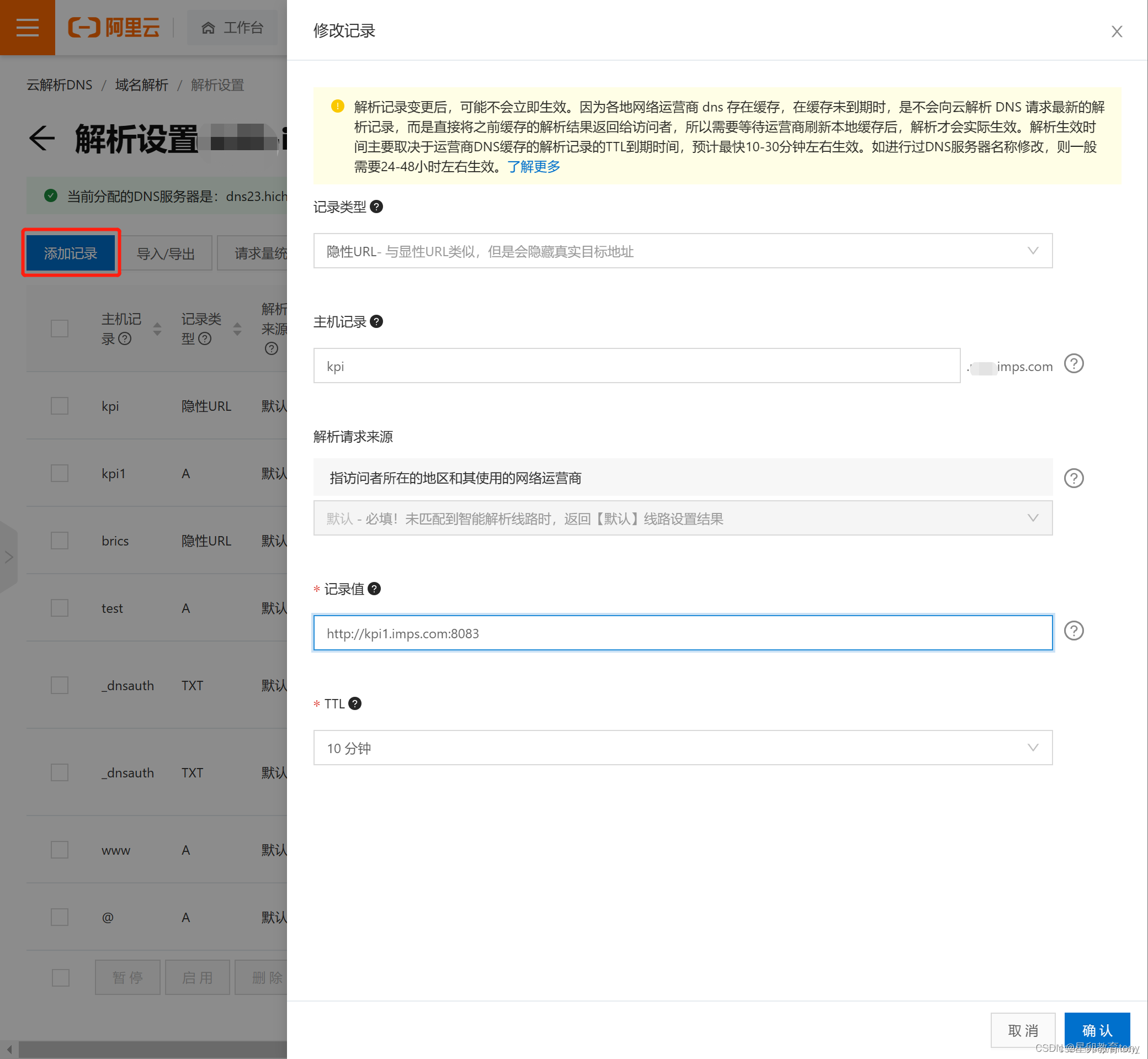
阿里云 腾讯云 配置二级域名并解析指向非80端口操作指南
目标:主域名 imps.com 已完成配置,新增配置 kpi.imps.com 等二级域名并指向 8083 端口。 (此操作需要主域名已经通过备案3天后,最好指向的IP地址网站也通过了备案申请,否则会提示域名没有备案。) 操作流程…...

菜单子节点的写法
菜单子节点的写法 1.测试数据2.实现代码3.获取父ID层级 1.测试数据 1.表结构SQL CREATE TABLE test (id int DEFAULT NULL,u_id int DEFAULT NULL,p_u_id int DEFAULT NULL ) ENGINEInnoDB DEFAULT CHARSETutf8mb4 COLLATEutf8mb4_general_ci;2.数据SQL INSERT INTO test (i…...

系统架构设计:9 论软件系统架构评估及其应用
目录 一 架构评估的意义 1 性能 2 可用性 3 安全性 4 可修改性 5 易用性...
javaee SpringMVC中json的使用
jsp <%--Created by IntelliJ IDEA.User: 呆萌老师:QQ:2398779723Date: 2019/12/6Time: 15:55To change this template use File | Settings | File Templates. --%> <% page contentType"text/html;charsetUTF-8" language"java" %> <%St…...

【系统架构】软件架构的演化和维护
导读:本文整理关于软件架构的演化和维护知识体系。完整和扎实的系统架构知识体系是作为架构设计的理论支撑,基于大量项目实践经验基础上,不断加深理论体系的理解,从而能够创造新解决系统相关问题。 目录 1、软件架构演化和定义 …...

一盏茶的功夫帮你彻底搞懂JavaScript异步编程从回调地狱到async/await
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 📘 1. 引言 📘 2. 使用方法 📘 3. 实现原理 📘 4. 写到最后…...
前后端分离计算机毕设项目之基于SpringBoot的无人智慧超市管理系统的设计与实现《内含源码+文档+部署教程》
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ 🍅由于篇幅限制,想要获取完整文章或者源码,或者代做&am…...
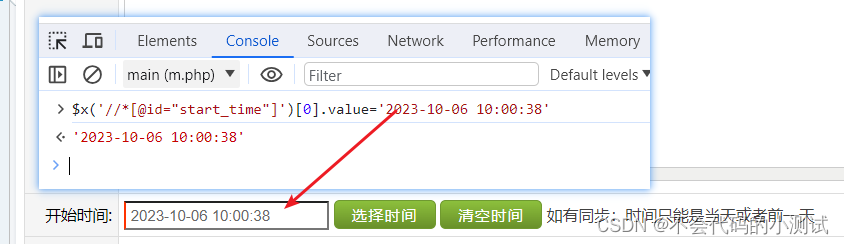
从0开始python学习-31.selenium 文本输入框、下拉选择框、文件上传、时间插件选择元素定位
目录 1. 纯文本输入框 2. 存在默认值的文本输入 3. 下拉选择框 4. 输入后下拉选择框 5. 文件上传 6. 时间插件 1. 纯文本输入框 driver.find_element(By.XPATH,/html/body/div[2]/td[2]/input).send_keys(测试名称) 2. 存在默认值的文本输入 注意: 1. 这种存…...

MyCat-web安装文档:安装Zookeeper、安装Mycat-web
安装Zookeeper A. 上传安装包 zookeeper-3.4.6.tar.gzB. 解压 #解压到当前目录,之后会生成一个安装后的目录 tar -zxvf zookeeper-3.4.6.tar.gz#加上-c 代表解压到指定目录 tar -zxvf zookeeper-3.4.6.tar.gz -C /usr/local/C. 在安装目录下,创建数据…...
Ajax跨域访问,访问成功但一直走error不走success的的问题解决
Ajax跨域访问,访问成功但一直走error不走success的的问题解决 通过搜索各种资料,终于解决啦,废话不多说了,还是老规矩直接上代码: 我这里用了jsonp,有想了解的点击 : jsonp 前端代码: $.ajax({type:post…...

水星 Mercury MIPC251C-4 网络摄像头 ONVIF 与 PTZ 云台控制
概况 最近在 什么值得买 上发现一款水星的网络摄像头, 除了支持云台/夜视功能之外, 还标明支持 onvif 协议. 所以想着买来接入到 HomeAssistat 作为监控使用.可到手之后发现事情并没有那么简单, 记录如下. 接入 HomeAssistant 按照 HA 的文档 ONVIF Camera 接入无非就是配置文件…...
Reactor 模式网络服务器【I/O多路复用】(C++实现)
前导:本文是 I/O 多路复用的升级和实践,如果想实现一个类似的服务器的话,需要事先学习 epoll 服务器的编写。 友情链接: 高级 I/O【Linux】 I/O 多路复用【Linux/网络】(C实现 epoll、select 和 epoll 服务器&#x…...
2019年[海淀区赛 第2题] 阶乘
题目描述 n的阶乘定义为n!n*(n -1)* (n - 2)* ...* 1。n的双阶乘定义为n!!n*(n -2)* (n -4)* ...* 2或n!!n(n - 2)*(n - 4)* ...* 1取决于n的奇偶性,但是阶乘的增长速度太快了,所以我们现在只想知道n!和n!!末尾的的个数 输入格式 一个正整数n ÿ…...

GLB纹理提取工具:原理、应用与Python实现详解
1. 项目概述与核心价值最近在折腾一些3D模型处理的工作流,特别是涉及到Web端展示的glTF/GLB格式时,遇到了一个不大不小但很烦人的问题:如何高效地从打包好的GLB文件中,把里面嵌入的纹理图片(Texture)给单独…...

LangGraph大模型脚手架实战:揭秘6种爆款智能体设计模式,玩转生产级Agent开发!
最近Herness大火,我就在反思,我们在日常进行智能体开发的过程中,是否也在做类似的事,我们用过claude code sdk、codex sdk、copilot cli等通用agent做封装,也用过dify或者coze搭工作流,也用过langchain做过…...

TINA-TI仿真实战:从运放振铃到电源设计的电路调试指南
1. 为什么我们需要TINA-TI仿真软件 作为一个在硬件设计领域摸爬滚打多年的工程师,我见过太多因为电路设计问题导致的返工案例。记得有一次,我们团队花了两周时间手工焊接的样机,上电后运放输出端出现了严重的振铃现象,不得不全部拆…...
)
从PCB走线到天线:手把手教你搞定Sx1262射频前端阻抗匹配(附常见错误排查)
从PCB走线到天线:手把手教你搞定Sx1262射频前端阻抗匹配(附常见错误排查) 在LoRa终端硬件开发中,射频前端的阻抗匹配往往是决定通信质量的关键因素。许多工程师在完成Sx1262芯片外围电路设计后,常会遇到通信距离不理想…...

从微波炉到激光加工:手把手教你用COMSOL搞定4种电磁加热的仿真设置
从微波炉到激光加工:COMSOL电磁加热仿真实战指南 电磁加热技术早已渗透进现代工业与生活的每个角落——从家用微波炉的磁控管震荡,到新能源汽车电池的感应焊接,再到精密医疗器械的激光切割。这些看似迥异的应用背后,都遵循着相同…...

告别并行接口:手把手教你用Stm32F4的SPI高效读取AD7606八通道数据
告别并行接口:手把手教你用Stm32F4的SPI高效读取AD7606八通道数据 在嵌入式系统设计中,AD7606作为一款高性能八通道16位ADC芯片,常被用于电力监测、工业控制等需要多通道高精度采样的场景。传统方案往往依赖其并行接口实现数据读取ÿ…...

D3D8to9终极指南:3步让老游戏在现代Windows上完美运行![特殊字符]
D3D8to9终极指南:3步让老游戏在现代Windows上完美运行!🚀 【免费下载链接】d3d8to9 A D3D8 pseudo-driver which converts API calls and bytecode shaders to equivalent D3D9 ones. 项目地址: https://gitcode.com/gh_mirrors/d3/d3d8to9…...

Mac窗口置顶神器Topit:3步解决多窗口遮挡难题,工作效率提升150%
Mac窗口置顶神器Topit:3步解决多窗口遮挡难题,工作效率提升150% 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 在Mac上进行多任务处理时…...

从课堂到代码:三大数学可视化工具实战解析
1. 数学可视化工具的选择困境 第一次接触数学可视化工具时,我被各种选项搞得眼花缭乱。作为数学老师,我需要一个能让学生快速上手的工具;作为编程爱好者,我又希望它能支持更复杂的算法可视化。经过多年实践,我发现Desm…...

RSLinx OPC Server配置避坑指南:解决IP网段、Topic配置与标签读取的常见问题
RSLinx OPC Server实战排障手册:从IP冲突到标签解析的深度解决方案 当工业自动化系统遇上OPC Server通讯故障,工程师的调试时间往往以小时为单位流失。不同于基础配置教程,本文将直击RSLinx OPC Server部署中的七大高发故障场景,…...