配置Hive使用Spark执行引擎
配置Hive使用Spark执行引擎
- Hive引擎
- 概述
- 兼容问题
- 安装Spark
- Spark配置
- Hive配置
- HDFS上传Spark的jar包
- 执行测试
- 速度对比
Hive引擎
概述
在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark
MapReduce引擎:
早期版本Hive使用MapReduce作为执行引擎。MapReduce是Hadoop的一种计算模型,它通过将数据划分为小块并在集群上并行处理来完成计算任务。在MapReduce引擎中,Hive将HiveQL查询转换为一系列Map和Reduce阶段的操作,然后由Hadoop的MapReduce框架执行。
Tez引擎:
从Hive 0.13版本开始,引入了Tez作为新的执行引擎。Tez是Hadoop上的一种高性能的数据处理框架,它提供了更低的延迟和更高的吞吐量。Tez引擎通过以更高效的方式执行HiveQL查询,比传统的MapReduce引擎更快速。Tez引擎将HiveQL查询转换为一种称为有向无环图(Directed Acyclic Graph, DAG)的形式,然后通过并行执行任务来实现查询。
Spark引擎:
将Spark作为Hive的执行引擎,以替代Hive默认的MapReduce执行引擎。通过将Spark作为执行引擎,Hive能够利用Spark的并行处理能力和内存计算优势,从而提高查询性能和处理速度。
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法
Spark on Hive:Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法
使用Spark作为Hive的执行引擎可以带来以下好处:
更快的执行速度:Spark具有内存计算的能力,可以在执行过程中缓存数据,加快查询速度更高的交互性:Spark支持迭代式查询和实时数据处理,适用于需要更快响应时间的应用场景更好的资源管理:Spark可以与其他Spark应用程序共享资源,实现更好的资源管理和利用
兼容问题
通常Hive与Spark间存在兼容性,需处理该兼容问题
在Hive解压目录,查看Hive支持的Spark版本
当前Hive版本使用的Spark版本为2.3.0
[root@node01 hive]# ls lib/spark-*
lib/spark-core_2.11-2.3.0.jar lib/spark-launcher_2.11-2.3.0.jar lib/spark-network-shuffle_2.11-2.3.0.jar lib/spark-unsafe_2.11-2.3.0.jar
lib/spark-kvstore_2.11-2.3.0.jar lib/spark-network-common_2.11-2.3.0.jar lib/spark-tags_2.11-2.3.0.jar
解决方案:
1.下载与当前Hive版本使用的Spark版本2.重新编译Hive,使其支持更高的Spark版本
安装Spark
下载Spark
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.4.0/spark-3.4.0-bin-without-hadoop.tgz
解压及重命名
tar -zxvf spark-3.4.0-bin-without-hadoop.tgzmv spark-3.4.0-bin-without-hadoop spark
Spark配置
在Spark中配置spark-env.sh
修改文件名
mv conf/spark-env.sh.template conf/spark-env.sh
vim conf/spark-env.sh,添加配置
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
配置SPARK_HOME环境变量
# Spark
export SPARK_HOME=/usr/local/program/spark
export PATH=$PATH:$SPARK_HOME/bin
使配置生效
source /etc/profile
Hive配置
注意:在Hive正常运行的基础之上进行如下额外配置
在hive中创建spark配置文件
vim conf/spark-defaults.conf
参数代表:在执行任务时,会根据如下参数执行
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:9000/spark/history
spark.executor.memory 1g
spark.driver.memory 1g
在HDFS创建目录,用于存储历史日志
hadoop fs -mkdir -p /spark/history
HDFS上传Spark的jar包
为什么要HDFS上传Spark的jar包?
-
使用的是
spark-3.4.0-bin-without-hadoop.tgz版本,不带hadoop和hive相关依赖 -
Hive任务由Spark执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点
-
因此需要将Spark的依赖上传到HDFS集群路径,让集群中任何一个节点都能获取到
hadoop fs -mkdir -p /spark/jarshadoop fs -put spark/jars/* /spark/jars
修改hive-site.xml文件
<!--Spark依赖位置 注意:端口号9000必须和namenode的端口号一致 -->
<property><name>spark.yarn.jars</name><value>hdfs://node01:9000//spark/jars/*</value>
</property><!--Hive执行引擎-->
<property><name>hive.execution.engine</name><value>spark</value>
</property><!--Hive和Spark连接超时时间-->
<property><name>hive.spark.client.connect.timeout</name><value>10000ms</value>
</property>
执行测试
hive (default)> create table tb_user(id int,name string,age int);hive (default)> insert into tb_user values(2,'hive',20);
查看Yarn控制台:
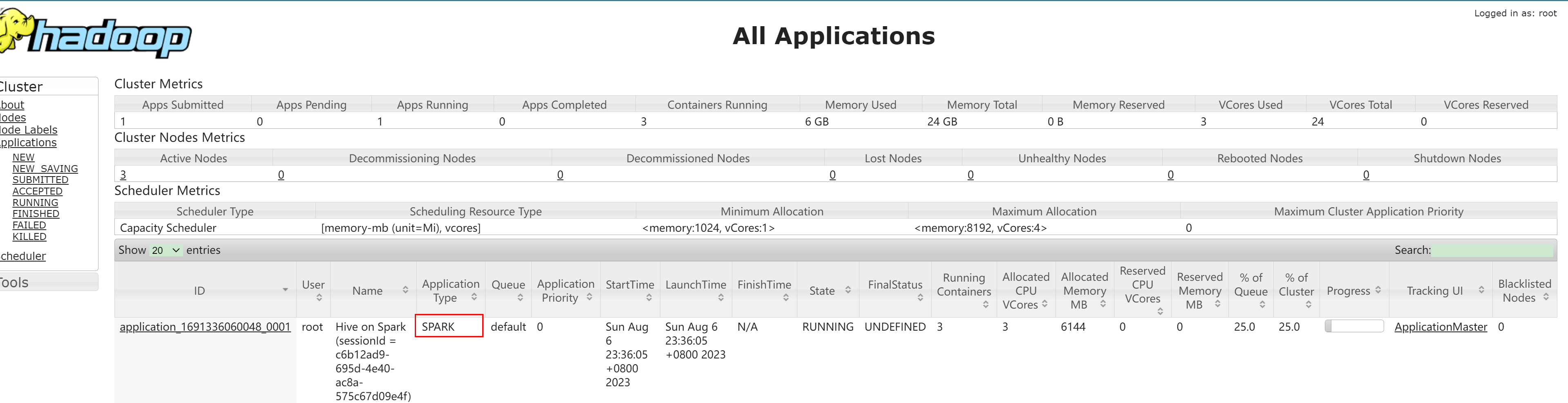
注意:
1.yarn的容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,防止大部分资源都被Application Master占用,导致Map/Reduce Task无法执行
2.如果资源不够,可能造成同一时刻只能运行一个Job的情况。
3.通过
hadoop/etc/hadoop/capacity-scheduler.xml参数控制,默认值是0.1,即每个资源队列上Application Master最多可使用的资源为该队列总资源的10%
配置示例:
<property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.5</value>
</property>
速度对比
MapReduce引擎:
2023-08-07 20:11:22,834 INFO [2704e498-c1b3-4dd5-8658-1f0a1393a3bb main] ql.Driver (SessionState.java:printInfo(1227)) - MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.51 sec HDFS Read: 16233 HDFS Write: 276 SUCCESS
2023-08-07 20:11:22,834 INFO [2704e498-c1b3-4dd5-8658-1f0a1393a3bb main] ql.Driver (SessionState.java:printInfo(1227)) - Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.51 sec HDFS Read: 16233 HDFS Write: 276 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 510 msec
2023-08-07 20:11:22,834 INFO [2704e498-c1b3-4dd5-8658-1f0a1393a3bb main] ql.Driver (SessionState.java:printInfo(1227)) - Total MapReduce CPU Time Spent: 3 seconds 510 msec
2023-08-07 20:11:22,834 INFO [2704e498-c1b3-4dd5-8658-1f0a1393a3bb main] ql.Driver (Driver.java:execute(2531)) - Completed executing command(queryId=root_20230807200946_06634674-a1f5-4cfa-ae34-166bfda3d90e); Time taken: 92.685 seconds
OK
2023-08-07 20:11:22,834 INFO [2704e498-c1b3-4dd5-8658-1f0a1393a3bb main] ql.Driver (SessionState.java:printInfo(1227)) - OK
2023-08-07 20:11:22,834 INFO [2704e498-c1b3-4dd5-8658-1f0a1393a3bb main] ql.Driver (Driver.java:checkConcurrency(285)) - Concurrency mode is disabled, not creating a lock manager
col1 col2 col3
Time taken: 96.059 seconds
Yarn引擎:
--------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-0 ........ 0 FINISHED 1 1 0 0 0
Stage-1 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 10.24 s
--------------------------------------------------------------------------------------
由此可大概粗略得知:
在Hive执行引擎中,Yarn引擎的执行效率大概是MapReduce引擎的10倍。
注意:
具体的性能差异取决于多种因素,如数据量的大小、查询的复杂程度、集群的配置等。
相关文章:
配置Hive使用Spark执行引擎
配置Hive使用Spark执行引擎 Hive引擎概述兼容问题安装SparkSpark配置Hive配置HDFS上传Spark的jar包执行测试速度对比 Hive引擎 概述 在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark MapReduce引擎: 早…...
)
基于FPGA的视频接口之千兆网口(五应用)
简介 相信网络上对于FPGA驱动网口的开发板、博客、论坛数不胜数,为何博主需要重新手敲一遍呢,而不是做一个文抄君呢!因为目前博主感觉网络上描述的多为应用层上的开发,非从底层开始说明,本博主的思虑还是按照老规矩,按照硬件、底层、应用等关系,使用三~四篇文章,来详细…...
车载开发所学内容,有哪些?程序员的转岗位需求
一、高速发展的行业前景 随着全球智能汽车市场的飞速发展,车载开发行业的前景可谓一片光明。各国政府对于自动驾驶和智能交通系统的政策支持,为行业带来了前所未有的机遇。此外,人工智能、大数据、云计算等前沿技术的不断突破,为…...
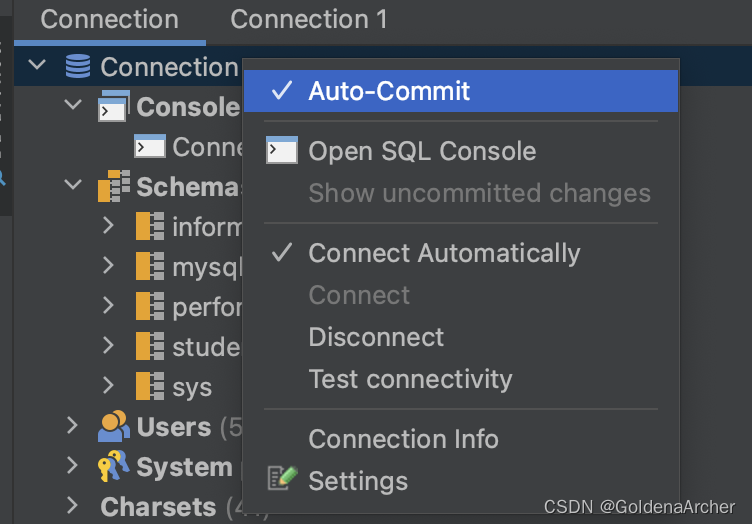
VSCode Intellij IDEA CE 数据库连接
VSCode & Intellij IDEA CE 数据库连接 大概记一下现在正在用的几个工具/插件 VSCode VSCode 里面的工具我下载了很多,如果只是链接 MySQL 的话,可能用 Jun Han 这位大佬的 MySQL 就好了: 使用这个插件直接打开 .sql 文件单击运行就能…...

直流无刷电机开发应用
下面的链接是笔者在研究无刷电机的过程中,找到的业内无刷电机驱动龙头企业,峰岹科技的各类无刷电机应用设计参考,比较有学习和借鉴意义。 应用手册 - 峰岹科技...

c 语言基础题目:PTA L1-030 一帮一
“一帮一学习小组”是中小学中常见的学习组织方式,老师把学习成绩靠前的学生跟学习成绩靠后的学生排在一组。本题就请你编写程序帮助老师自动完成这个分配工作,即在得到全班学生的排名后,在当前尚未分组的学生中,将名次最靠前的学…...

网工内推 | base郑州,上市公司,最高15薪,五险一金全额缴
01 四方达 招聘岗位:网络工程师 职责描述: 1、负责公司数据中心(机房)的管理与运维工作。 2、负责公司服务器、路由器、防火墙、交换机等设备的管理、以及网络平台的运行监控和维护; 3、负责公司服务器运维管理工作、…...
求后缀表达式的值
后缀表达式的值 【题目描述】 从键盘读入一个后缀表达式(字符串),只含有0-9组成的运算数及加()、减(—)、乘(*)、除(/)四种运算符。每个运算数之间…...
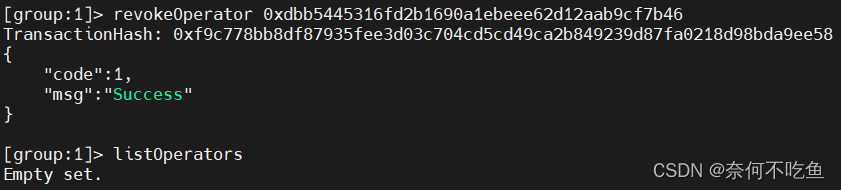
【FISCO-BCOS】十七、角色的权限控制
目录 一、角色定义 二、账户权限控制 1.委员新增、撤销与查询 2.委员权重修改 3.委员投票生效阈值修改 4. 运维新增、撤销与查询 一、角色定义 分为治理方、运维方、监管方和业务方。考虑到权责分离,治理方、运维方和开发方权责分离,角色互斥。 治理…...

vue怎样封装接口
Vue可以使用axios来发送HTTP请求,通过封装axios可以实现接口的统一管理和调用。下面是一个简单的封装接口的示例。 安装axios 在项目中安装axios依赖,可以使用npm或者yarn命令进行安装。 npm install axios --save创建api.js文件 在项目中创建一个ap…...

Typescript 笔记:函数
1 函数定义 function function_name() {// 执行代码 }2 函数返回值 function function_name():return_type { // 语句return value; } return_type 是返回值的类型。 return 关键词后跟着要返回的结果。 返回值的类型需要与函数定义的返回类型(return_type)一致。 3 函数…...
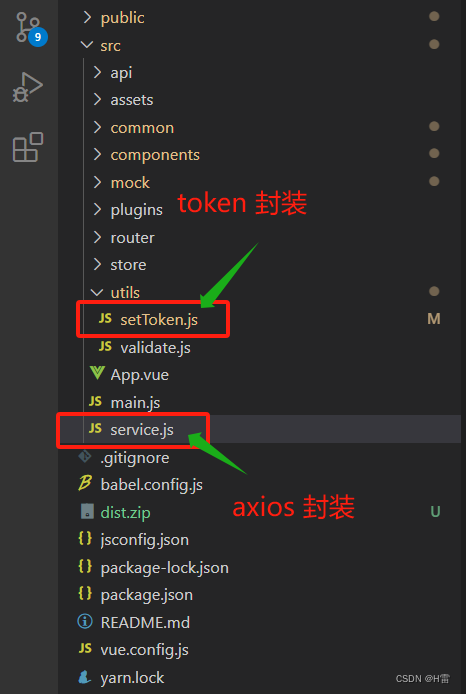
Axios 封装
请注意以下文件夹: utils下的setToken.js 是token封装(封装 Token-CSDN博客),service.js 是axios封装。 Axios封装: 1.安装axios 在项目终端下 输入: npm install axios --save 2.在main.js全局引入axios import axios from axiosVue.prototype.$axios =axios //挂…...
Javascript的垃圾回收机制)
CocosCreator 面试题(一)Javascript的垃圾回收机制
JavaScript的垃圾回收机制是一种自动管理内存的机制,它负责检测和回收不再使用的内存,以便释放资源并提高性能。 标记清除(Mark and Sweep):这是JavaScript最常用的垃圾回收算法。它的工作原理是通过标记活动对象&…...

【计算机网络】UDP协议编写群聊天室----附代码
UDP构建服务器 x 预备知识 认识UDP协议 此处我们也是对UDP(User Datagram Protocol 用户数据报协议)有一个直观的认识; 后面再详细讨论. 传输层协议无连接不可靠传输面向数据报 网络字节序 我们已经知道,内存中的多字节数据相对于内存地址有大端和小端之分, 磁盘文件中的…...

Java架构师高并发架构设计
目录 1 导学2 什么是高并发问题3 高并发处理之道4 akf扩展立方体5 细化理念应对高并发5 总结1 导学 本章的主要内容是大型系统架构设计的难点之一,高并发架构设计相关的知识落到实际项目上,就是订单系统的高并发架构设计。我们首先会去学习到底何为高并发问题,先把问题搞清楚…...
)
【客观赋权法1】熵权法(MATLAB全代码)
熵权法(entropy weight method, EWM) 1 原理2 MATLAB代码3 案例参考赋权法(Weighting Method) 是一种常用的数据处理方法,它可以将不同变量之间的重要性进行区分,并赋予它们不同的权重,以反映它们对整体的贡献程度。 指标在评估体系中的重要程度可以用 指标权重系数表示…...

“注释: 爱恨交织的双重标准?解析注释在代码开发中的作用。”
文章目录 每日一句正能量前言观点和故事程序员不写注释的原因是什么如何才能写出漂亮的注释后记 每日一句正能量 水与水之间有距离,但地心下直相牵,人与人之间有距离,但心里时刻挂念,发条短信道声晚安,梦里我们相见。 …...

一种基于局部适应度景观的进化规划的混合策略
文章目录 标题摘要结论研究背景研究内容、成果常用基础理论知识潜在研究点文献链接标题 A Mixed Strategy for Evolutionary Programming Based on Local Fitness Landscape 摘要 进化规划(EP)的性能受到许多因素的影响(如突变操作符和选择策略)。虽然传统的高斯突变算子…...

Python数据攻略-Mongodb数仓无法写入方法汇总
Mongodb作为一个非结构化的NoSQL数据库,能存储各种复杂和多变的数据格式,如JSON。这使得Mongodb在实时数据分析和高性能查询中具有优势。 在使用Mongodb的过程中,可能会遇到写入失败的问题。常见的几种情况包括无法建立连接、认证失败和存储限制。 文章目录 诊断问题日志分…...
用什么工具来画UML?
2023年10月9日,周一晚上 目录 我的决定 关于rational rose UML工具有哪些 相关资料 我的决定 我决定用plantUML、draw.io或starUML就可以了 其实没必要在意工具, 重要的是能把图画出来、把图画好画规范, 重要的是知道怎么去画图、把意…...

HunyuanVideo-Foley 企业级架构设计:基于Agent的分布式音效生成调度系统
HunyuanVideo-Foley 企业级架构设计:基于Agent的分布式音效生成调度系统 1. 引言:音效生成的企业级挑战 想象一下这样的场景:一家大型视频平台每天需要为上万条视频自动生成匹配的音效。传统单机方案面临三大难题:生成速度跟不上…...

基于IEEE39节点系统的风力发电机组并网改造与稳定性研究
基于IEEE39节点系统的风力发电机组并网改造与稳定性研究 摘要 随着可再生能源在电力系统中占比的不断提升,风电并网技术已成为电力系统领域的研究热点。本文针对IEEE39节点标准测试系统,将其工作频率从60Hz改造为50Hz,并将30、32、34、37号节点的同步发电机分别替换为不同…...
)
Flutter项目打包未签名ipa的保姆级教程(含Xcode配置与常见错误解决)
Flutter项目打包未签名ipa的保姆级教程(含Xcode配置与常见错误解决) 当你完成了一个Flutter应用的开发,准备将其交付给第三方进行签名或部署到CI/CD流水线时,生成一个未签名的ipa文件是必经之路。对于刚接触iOS打包的Flutter开发者…...

Rocky Linux 9.4 Minimal安装后必做的10件事:安全加固、性能优化与开发环境搭建
Rocky Linux 9.4 Minimal安装后必做的10件事:安全加固、性能优化与开发环境搭建 当你完成Rocky Linux 9.4 Minimal的安装,面对那个极简的命令行界面时,可能会感到一丝茫然。这个"裸"系统虽然轻量,但距离生产环境或高效开…...

Omni-Vision Sanctuary 网络协议分析辅助:可视化网络数据包与流量模式识别
Omni-Vision Sanctuary 网络协议分析辅助:可视化网络数据包与流量模式识别 1. 网络数据可视化的新思路 网络工程师每天面对海量的数据包和流量日志,传统的分析工具往往需要依赖复杂的命令行操作和专业图表解读。而Omni-Vision Sanctuary模型为我们提供…...

惊艳展示:MedGemma医学影像分析系统,自然语言提问生成专业报告
惊艳展示:MedGemma医学影像分析系统,自然语言提问生成专业报告 1. 引言:当AI能“看懂”医学影像,并“说”出专业见解 想象一下,你手里有一张肺部X光片,但你不是放射科医生。你看着那些黑白影像和复杂的结…...

基于python的演唱会抢票系统
目录同行可拿货,招校园代理 ,本人源头供货商核心功能模块技术实现要点扩展功能设计异常处理方案项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 核心功能模块 用户管理模块 注册/登录功…...

InSpec插件生态系统:扩展框架功能的完整教程
InSpec插件生态系统:扩展框架功能的完整教程 【免费下载链接】inspec InSpec: Auditing and Testing Framework 项目地址: https://gitcode.com/gh_mirrors/in/inspec InSpec作为一款强大的合规性测试框架,其真正的威力在于其可扩展的插件生态系统…...
)
vue路由跳转打开新窗口并携带参数(vue2/vue3)
概要 在一些需求中经常遇到跳转页面,但是产品让跳转页面的同时打开一个新窗口方便用户进行对比数据,接下来就是跳转页面打开新窗口的方法 vue2的写法 const routeUrl this.$router.resolve({path: "/页面路由",query: { id: xx参数 },});wi…...

React Native Keyboard Controller部署指南:生产环境最佳配置
React Native Keyboard Controller部署指南:生产环境最佳配置 【免费下载链接】react-native-keyboard-controller Keyboard manager which works in identical way on both iOS and Android 项目地址: https://gitcode.com/gh_mirrors/re/react-native-keyboard-…...