【ElasticSearch】深入探索 DSL 查询语法,实现对文档不同程度的检索,以及对搜索结果的排序、分页和高亮操作
文章目录
- 前言
- 一、Elasticsearch DSL Query 的分类
- 二、全文检索查询
- 2.1 `match` 查询
- 2.2 `multi_match` 查询
- 三、精确查询
- 3.1 term 查询
- 3.2 range 查询
- 四、地理坐标查询
- 4.1 geo_bounding_box 查询
- 4.2 geo_distance 查询
- 五、复合查询
- 5.1 function score 查询
- 5.2 boolean 查询
- 六、对搜索结果的处理
- 6.1 对搜索结果进行排序
- 6.2 对搜索结果进行分页
- 6.3 对搜索结果中的搜索关键字高亮处理
前言
Elasticsearch(简称ES)是一个强大的开源搜索和分析引擎,广泛应用于各种应用程序中,从企业级搜索引擎到日志和指标分析。其强大之处在于其灵活的数据模型和丰富的查询语言,使得用户能够轻松地进行全文检索、精确查询、地理坐标查询等操作。
本文将深入探讨Elasticsearch的DSL(Domain Specific Language)查询,分为多个部分进行介绍。首先,我们会了解Elasticsearch DSL Query的分类,然后深入研究全文检索查询、精确查询、地理坐标查询以及复合查询等不同类型的查询。
每一节都会提供详细的语法和实际示例,以便读者能够更好地理解和运用Elasticsearch中强大的查询功能。最后,我们将介绍对搜索结果进行排序、分页以及搜索关键字高亮处理等实用的处理技巧,以完善搜索体验。
让我们开始深入探讨Elasticsearch DSL Query,发现如何利用其强大的功能来提升搜索和分析的效果。
一、Elasticsearch DSL Query 的分类
Elasticsearch 提供了强大而灵活的DSL(领域特定语言)查询,用于定义对索引库中文档的不同类型查询。下面将详细介绍一些常见的 DSL查询类型:
1. 查询所有 - match_all
查询所有文档,通常用于测试或获取整个索引的文档。
{"query": {"match_all": {}}
}
2. 全文检索查询
match查询
利用分词器对用户输入的内容进行分词,然后在索引中匹配分词后的词语。
{"query": {"match": {"field_name": "search_text"}}
}
multi_match查询
在多个字段上执行全文检索查询。
{"query": {"multi_match": {"query": "search_text","fields": ["field1", "field2"]}}
}
3. 精确查询
ids查询
根据文档ID查询文档。
{"query": {"ids": {"values": ["doc_id1", "doc_id2"]}}
}
term查询
根据精确词条值查找数据,适用于 keyword、数值、日期、boolean等类型字段。
{"query": {"term": {"field_name": "exact_value"}}
}
range查询
根据范围查询,适用于数值、日期等类型的范围查询。
{"query": {"range": {"field_name": {"gte": "start_value","lte": "end_value"}}}
}
4. 地理查询
geo_distance查询
根据经纬度查询指定距离范围内的文档。
{"query": {"geo_distance": {"distance": "10km","location": {"lat": 40.73,"lon": -73.98}}}
}
geo_bounding_box查询
根据指定的矩形框查询文档。
{"query": {"geo_bounding_box": {"location": {"top_left": {"lat": 40.73,"lon": -74.1},"bottom_right": {"lat": 40.01,"lon": -71.12}}}}
}
5. 复合查询
bool查询
通过组合多个查询条件,支持must、must_not、should等逻辑。
{"query": {"bool": {"must": [{ "match": { "field1": "value1" } },{ "range": { "field2": { "gte": 10, "lte": 20 } } }],"must_not": [{ "term": { "field3": "value2" } }],"should": [{ "match": { "field4": "value3" } }]}}
}
function_score查询
根据某个函数计算的分数对查询结果进行打分,用于加权不同的查询条件。
{"query": {"function_score": {"query": { "match": { "field": "search_text" } },"functions": [{"filter": { "range": { "field2": { "gte": 10, "lte": 20 } } },"weight": 2}],"score_mode": "multiply"}}
}
以上是一些常见的 Elasticsearch DSL查询类型,在使用的时候可以根据具体需求灵活组合这些查询条件来实现复杂的搜索和过滤功能。下面是针对于这些不同查询的详细说明以及查询演示。
二、全文检索查询
全文检索查询是通过对用户输入的内容进行分词,然后在索引中匹配分词后的词语,实现更灵活的文本搜索。在Elasticsearch中,常用的关键词是 match 和 multi_match。
2.1 match 查询
match查询会根据一个字段进行查询,适用于单一字段的全文检索。在实际应用中,可以使用 copy_to 将多个字段的值合并到一个字段,从而实现类似 multi_match 的查询效果。
例如,针对 hotel 索引库的全文检索查询:
GET /hotel/_search
{"query": {"match": {"all": "如家"}}
}
这里假设 all 字段是通过 copy_to 包含了多个字段的内容,如:“brand”、“business”、“name”。查询结果如下:
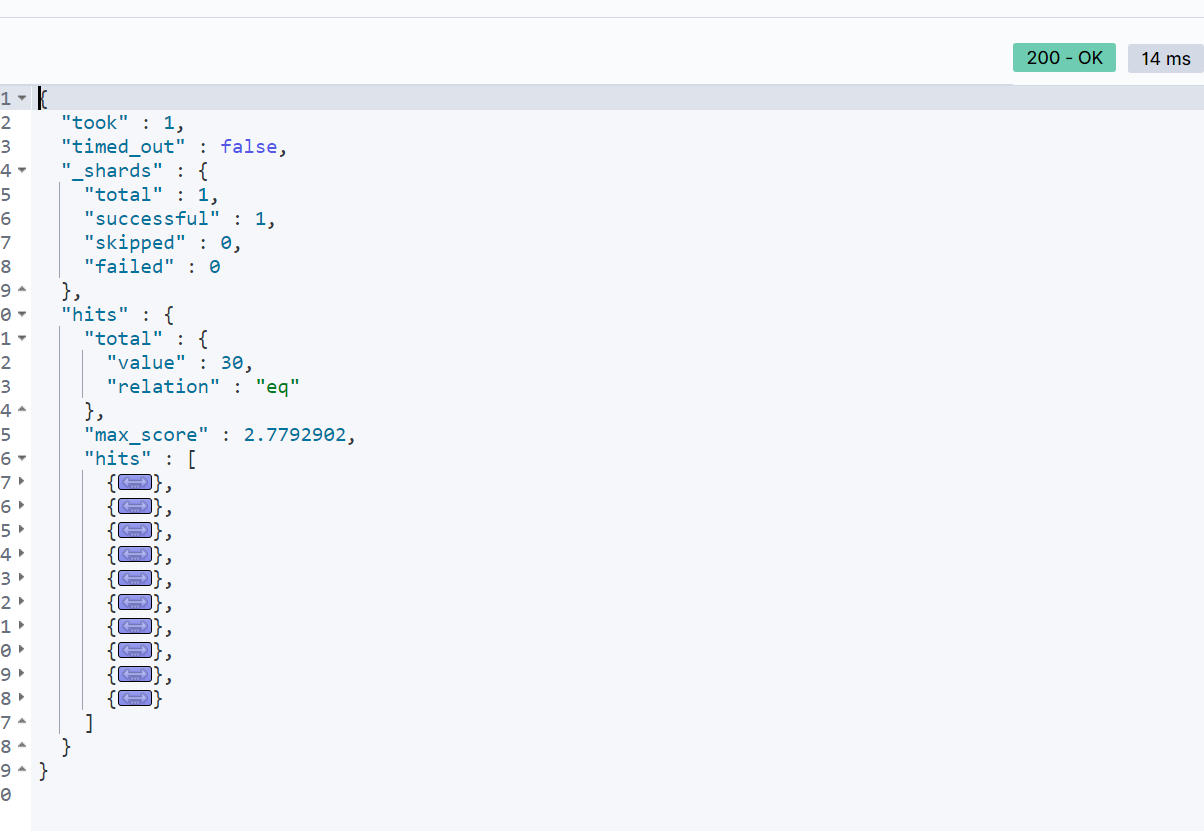
2.2 multi_match 查询
multi_match查询允许根据多个字段进行全文检索查询,但需要注意,参与查询的字段越多,查询效率可能越低。
例如,使用 multi_match 查询:
GET /hotel/_search
{"query": {"multi_match": {"query": "如家","fields": ["brand", "business", "name"]}}
}
在这个例子中,参与查询的字段同样是:“brand”、“business”、 “name”。查询结果如下:
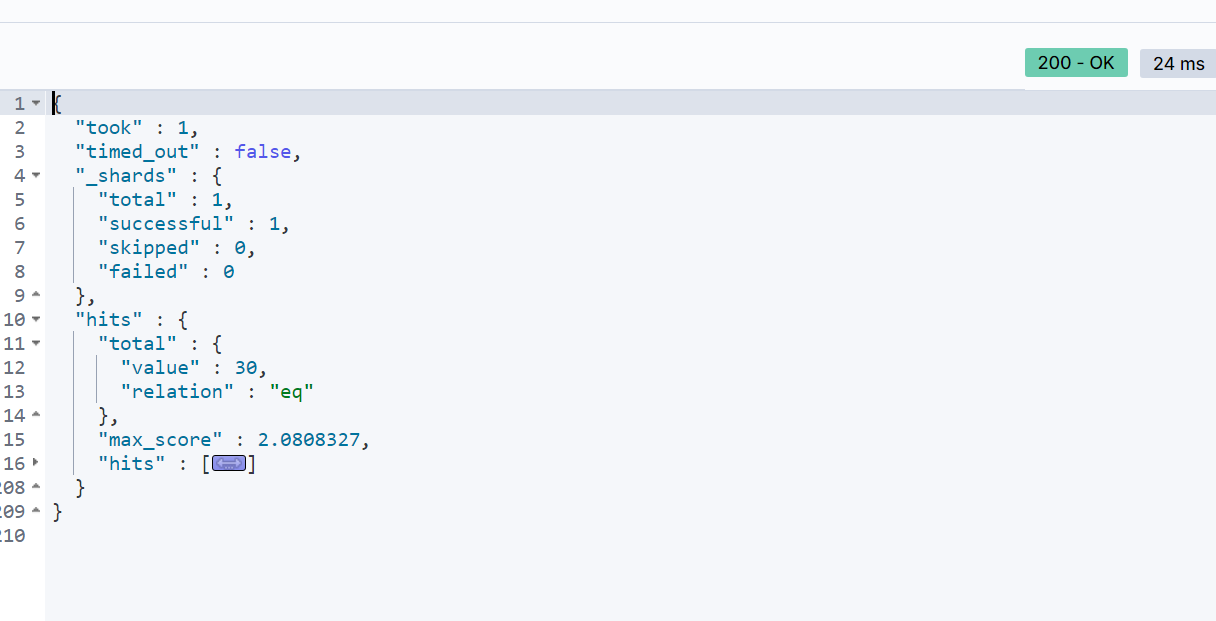
可以观察到,match 和 multi_match 的查询结果是相同的。在实际应用中,选择使用哪种方式要根据具体需求和性能考虑来决定。
三、精确查询
精确查询是搜索引擎中常用的查询方式,特别适用于针对关键字、数值、日期、boolean等类型字段的精准检索。在酒店订购网站等应用中,用户通常希望根据特定的条件,如城市、星级、品牌、价格范围等,进行准确的信息检索。
下面将介绍在 Elasticsearch 中如何使用 term 和 range 进行精确查询。
3.1 term 查询
term 查询用于根据词条的精确值进行查询。例如,在酒店订购网站中,用户希望查找位于上海的所有酒店,可以使用以下 DSL 语句:
GET /hotel/_search
{"query": {"term": {"city": {"value": "上海"}}}
}
查询结果:

上述查询返回了所有城市为上海的酒店信息。然而,要注意的是,term 查询对查询关键字的精确匹配要求较高。如果将查询的值更改为 “上海北京”,将找不到匹配的结果:
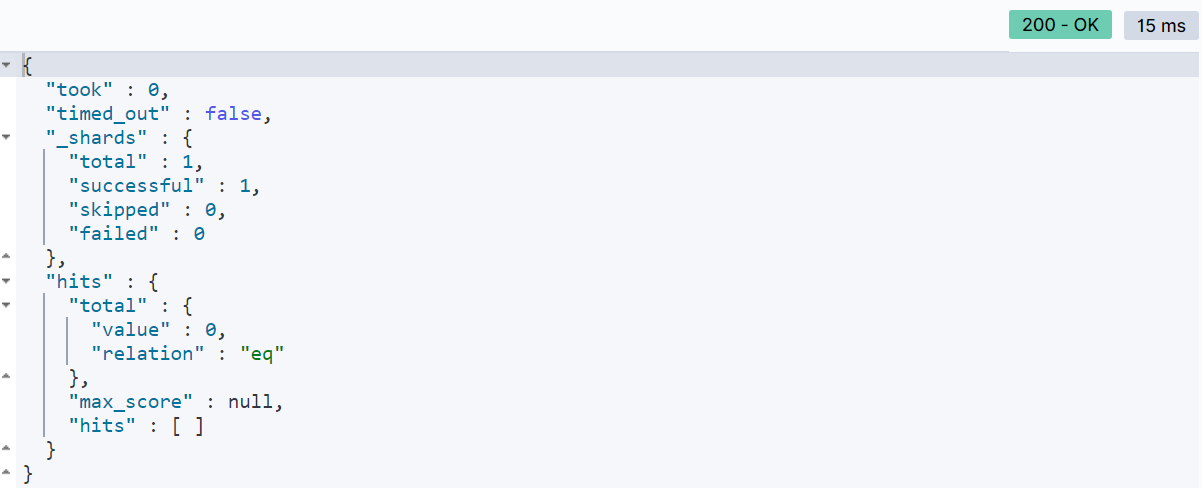
因此,在使用 term 查询时,务必确保查询的关键字是准确的。
3.2 range 查询
range 查询用于根据值的范围进行查询,特别适用于数值型字段,比如价格范围。例如,用户希望查找价格在 100 到 200 之间的酒店,可以使用以下 DSL 语句:
GET /hotel/_search
{"query": {"range": {"price": {"gte": 100,"lte": 200}}}
}
查询结果:
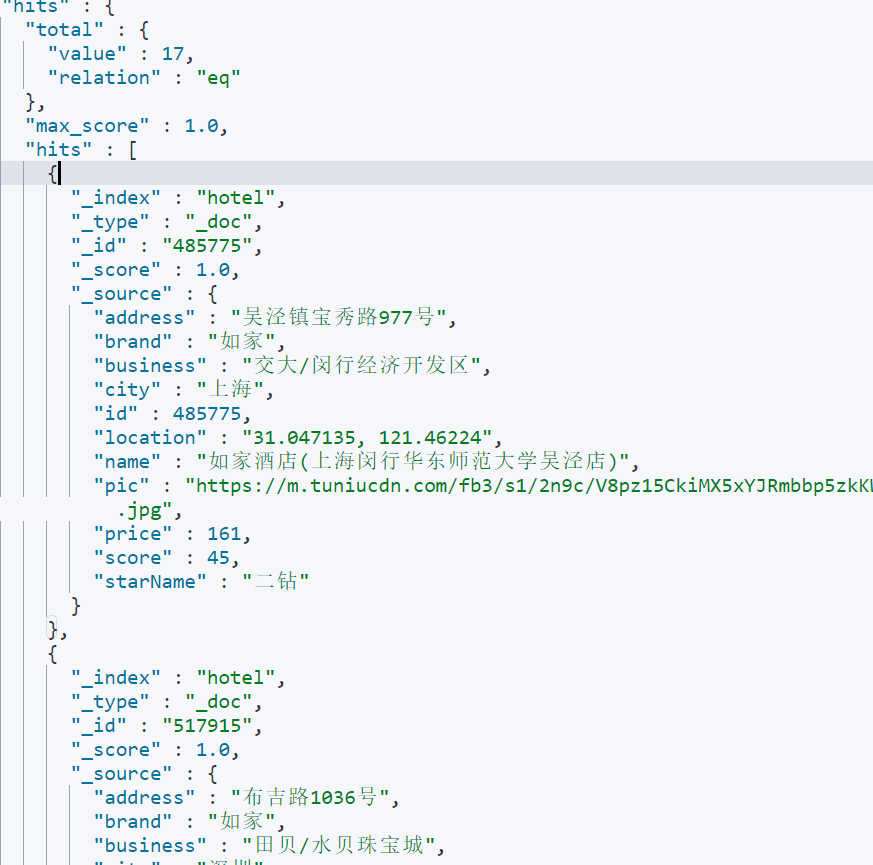
在上述查询中,使用了 gte 表示大于等于某个值,而 lte 表示小于等于某个值。通过这样的查询,可以精确地获取符合价格范围的酒店信息。
总的来说,精确查询在搜索引擎中是非常常用且实用的功能,通过合理使用 term 和 range 查询,可以满足用户对于准确信息检索的需求。
四、地理坐标查询
地理坐标查询是 Elasticsearch 中常见的功能之一,特别适用于需要根据地理位置信息进行搜索的场景,如查询附近的酒店、出租车、或者附近的人。下面介绍两种常用的地理坐标查询方式:geo_bounding_box 和 geo_distance。
4.1 geo_bounding_box 查询
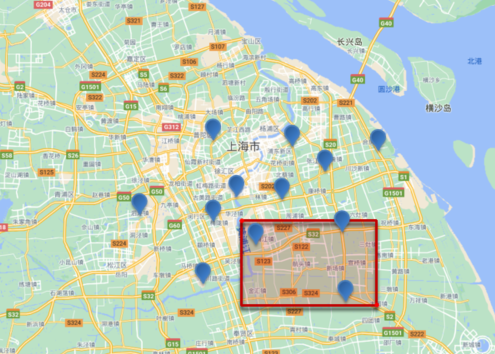
geo_bounding_box 查询用于查询 geo_point 值在某个矩形范围内的所有文档。以下是一个示例:
GET /indexName/_search
{"query": {"geo_bounding_box": {"FIELD": {"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right": {"lat": 30.9,"lon": 121.7}}}}
}
在这个例子中,通过指定矩形的左上角和右下角的经纬度,可以查询所有位置在这个矩形范围内的文档。
搜索范围示意图,形状为矩形:
4.2 geo_distance 查询
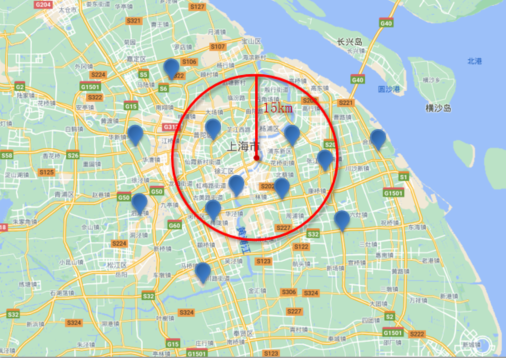
geo_distance 查询用于查询到指定中心点距离小于某个距离值的所有文档。以下是一个示例:
GET /indexName/_search
{"query": {"geo_distance": {"distance": "15km","FIELD": "31.21,121.5"}}
}
在这个例子中,通过指定中心点的经纬度和距离值,可以查询所有距离中心点小于 15 公里的文档。
搜索范围示意图,形状为圆:
通过这两种方式,可以在地理坐标信息中实现灵活而精确的查询,满足用户在不同应用场景下的位置搜索需求。
五、复合查询
复合(compound)查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑,例如:
-
function score: 算分函数查询,可以控制文档相关性算分,控制文档排名,类似于百度搜索结果中一些顶置的广告。 -
Boolean Query:布尔查询,一个或多个查询子句的组合,子查询的组合方式有:- must:必须匹配每个子查询,类似“与”。
- should:选择性匹配子查询,类似“或”。
- must_not:必须不匹配,不参与算分,类似“非”。
- filter:必须匹配,不参与算分。
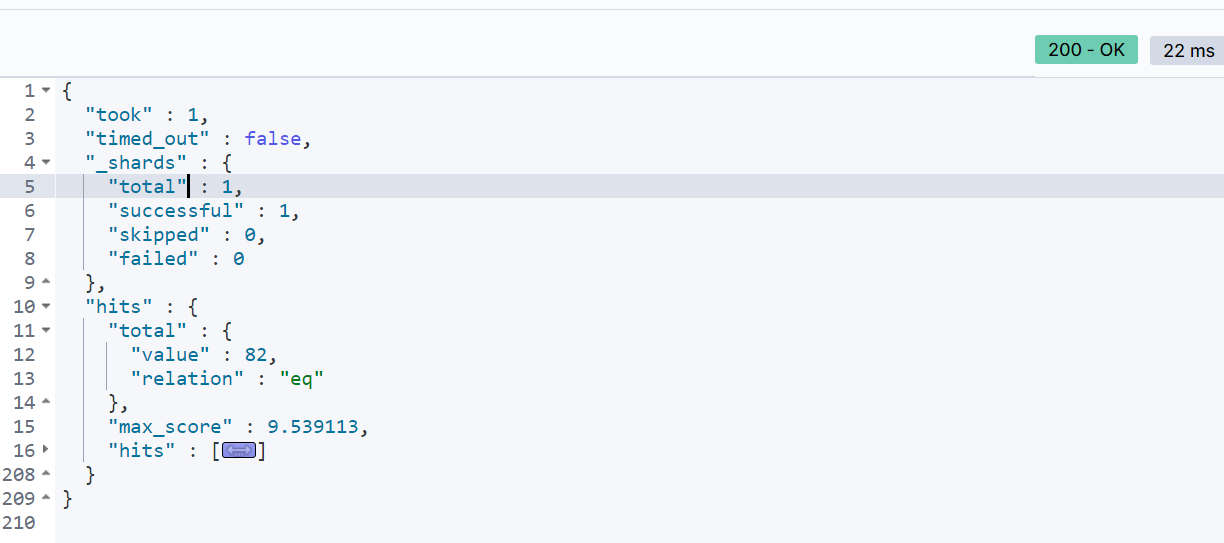
5.1 function score 查询
假设,现在文档中有一些是广告,我们希望这些广告在查询结果中是最靠前的,因此可以使用 function score 查询来修改特定文档的打分,例如,给“如家”这个品牌的酒店排名靠前一定:
为了实现这个目标,我们需要提供以下三个要素:
-
哪些文档需要算分加权?
- 品牌为如家的酒店。
-
算分函数是什么?
weight。
-
加权模式是什么?
- 乘积。
查询 DSL 语句如下:
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"all": "上海"}},"functions": [{"filter": {"term": {"brand": "如家"}},"weight": 10}],"boost_mode": "multiply"}}
}
说明:
query:原始查询条件,搜索文档并根据相关性打分(query score)。filter:过滤条件,符合条件的文档才会被重新算分。weight:算分函数,算分函数的结果称为 function score ,将来会与 query score 运算,得到新算分。常见的算分函数有:weight:给一个常量值,作为函数结果(function score)。field_value_factor:用文档中的某个字段值作为函数结果。random_score:随机生成一个值,作为函数结果。script_score:自定义计算公式,公式结果作为函数结果。
boost_mode:加权模式,定义 function score 与 query score 的运算方式,包括:multiply:两者相乘。默认就是这个。replace:用 function score 替换 query score。- 其它:
sum、avg、max、min。
查询结果:
5.2 boolean 查询
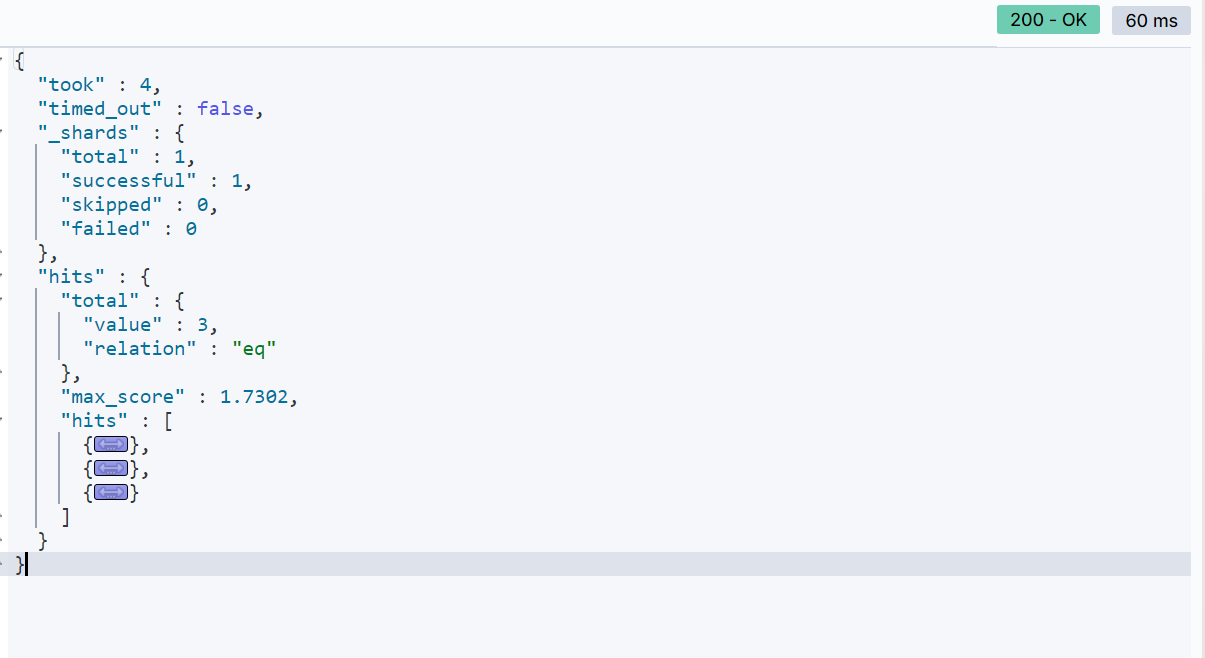
例如,现在有一个查询需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围 10km 范围内的酒店。
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": {"price": {"gte": 400}}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}}]}}
}
说明:
must:必须匹配每个子查询,类似“与”。must_not:必须不匹配,不参与算分,类似“非”。filter:必须匹配,不参与算分。
搜索结果:
通过这个例子,我们可以看到如何使用布尔查询来组合多个条件,实现更精确的搜索。
六、对搜索结果的处理
6.1 对搜索结果进行排序
ElasticSearch 支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword 类型、数值类型、地理坐标类型、日期类型等。
示例一:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序
评价是 score 字段,价格是 price 字段,按照顺序添加两个排序规则即可。
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": "desc"},{"price": "asc"}]
}
示例二:实现对酒店数据按照到(121.507712,31.224612)的位置坐标的距离升序排序
获取经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/。
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 31.224612,"lon": 121.507712},"order": "asc","unit": "km"}}]
}
6.2 对搜索结果进行分页
ElasticSearch 默认情况下只返回 top 10 的数据。而如果要查询更多数据就需要修改分页参数了。ElasticSearch 中通过修改 from、size 参数来控制要返回的分页结果。
基本语法如下:
GET /hotel/_search
{"query": {"match_all": {}},"from": 990, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}
示例:使用 match_all 查询,然后对结果进行分页
GET /hotel/_search
{"query": {"match_all": {}},"from": 0,"size": 5
}
搜索结果,现在就只展示5条结果了:
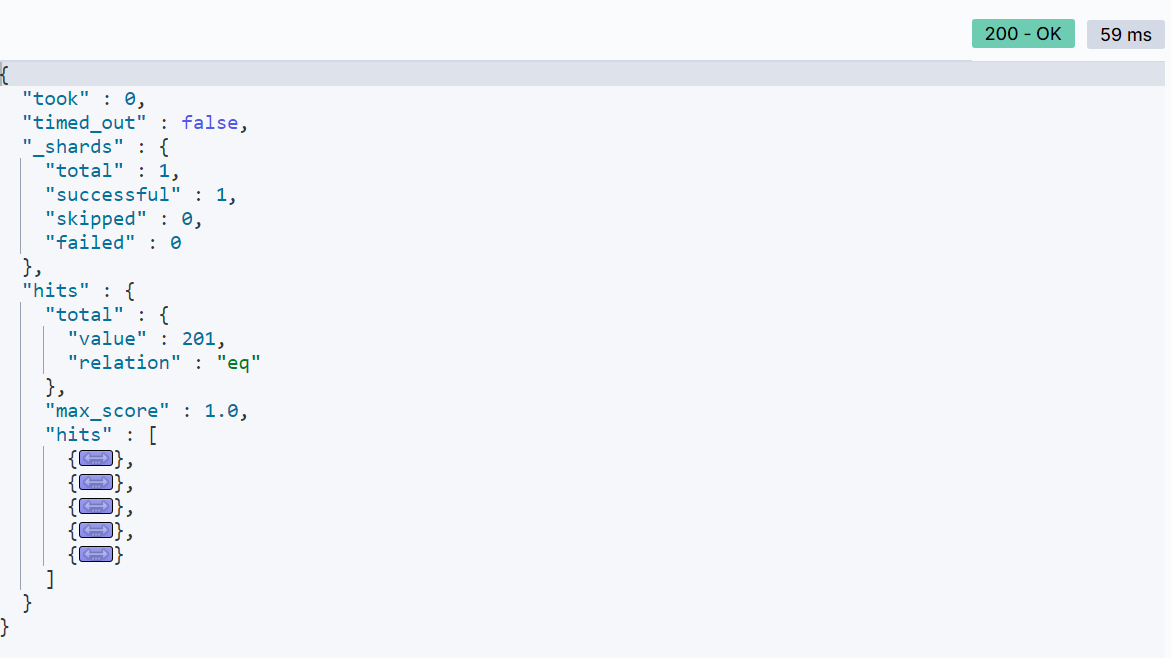
深度分页问题:
ES是分布式的,所以会面临深度分页问题。例如按 price 排序后,获取 from = 990,size =10 的数据:
- 首先在每个数据分片上都排序并查询前1000条文档。
- 然后将所有节点的结果聚合,在内存中重新排序选出前1000条文档。
- 最后从这1000条中,选取从990开始的10条文档。
如果搜索页数过深,或者结果集(from + size)越大,对内存和 CPU 的消耗也越高。因此 ES 设定结果集查询的上限是10000。
深度分页解决方案:
针对深度分页,ES提供了两种解决方案:
- **search after:**分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- **scroll:**原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
6.3 对搜索结果中的搜索关键字高亮处理
高亮处理,就是在搜索结果中把搜索关键字突出显示。
原理:
- 将搜索结果中的关键字用标签标记出来。
- 在页面中给标签添加 CSS 样式。
语法:
GET /hotel/_search
{"query": {"match": {"FIELD": "TEXT"}},"highlight": {"fields": {"FIELD": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
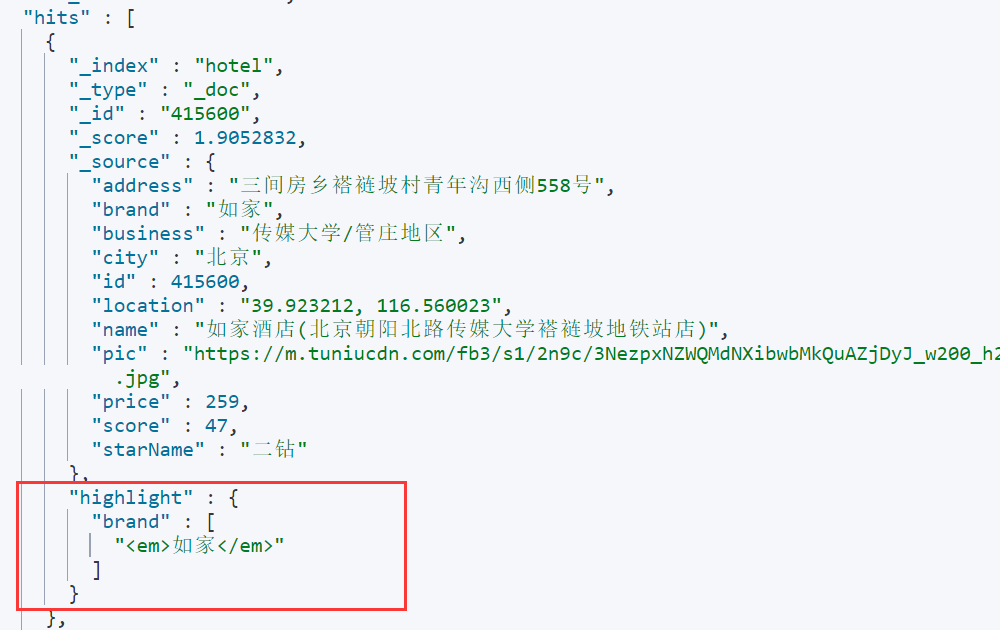
示例:对搜索的品牌名称进行高亮处理
GET /hotel/_search
{"query": {"match": {"brand": "如家"}},"highlight": {"fields": {"brand": {"pre_tags": "<em>","post_tags": "</em>"}}}
}
搜索结果:
以上便是对ElasticSearch搜索结果进行排序、分页和关键字高亮处理的一些示例和基本操作。
相关文章:
【ElasticSearch】深入探索 DSL 查询语法,实现对文档不同程度的检索,以及对搜索结果的排序、分页和高亮操作
文章目录 前言一、Elasticsearch DSL Query 的分类二、全文检索查询2.1 match 查询2.2 multi_match 查询 三、精确查询3.1 term 查询3.2 range 查询 四、地理坐标查询4.1 geo_bounding_box 查询4.2 geo_distance 查询 五、复合查询5.1 function score 查询5.2 boolean 查询 六、…...
使用wireshark解密ipsec ISAKMP包
Ipsec首先要通过ikev2协议来协商自己后续协商所用的加解密key以及用户数据的esp包用的加解密包。 ISAKMP就是加密过的ike-v2的加密包,有时候我们需要解密这个包来查看协商数据。如何来解密这样的包? 首先导出strongswan协商生成的各种key. 要能导出这些key&#…...

算法进阶-搜索
算法进阶-搜索 题目描述:给定一张N个点M条边的有向无环图,分别统计从每个点除法能够到达的点的数量 **数据规模:**1 < n < 3e4 **分析:**这里我们可以使用拓扑排序根据入边对所有点进行排序,排序后我们按照逆序&…...
时空智友企业流程化管控系统 sessionid泄露漏洞 复现
文章目录 时空智友企业流程化管控系统 sessionid泄露漏洞 复现0x01 前言0x02 漏洞描述0x03 影响平台0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 时空智友企业流程化管控系统 sessionid泄露漏洞 复现 0x01 前言 免责声明:请勿利用文章内的相关技术从…...

QT编程,QMainWindow、事件
目录 1、QMainWindow 2、事件 1、QMainWindow QMenuBar:菜单栏 QMenu: 菜单 QAction: 动作 QToolBar: 工具栏 QStatusBar: 状态栏 setWindowTitle("主窗口"); //: 前缀 文件名 setWindowIcon(QIcon(":/mw_images/10.png")); resize(640, 4…...
人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用
大家好,我是微学AI ,今天给大家介绍一下人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用,随着人工智能(AI)和深度学习技术的发展,大模型已经开始渗透到各个领域,包括数学教育。本文将详细介绍基于大模型在数学…...
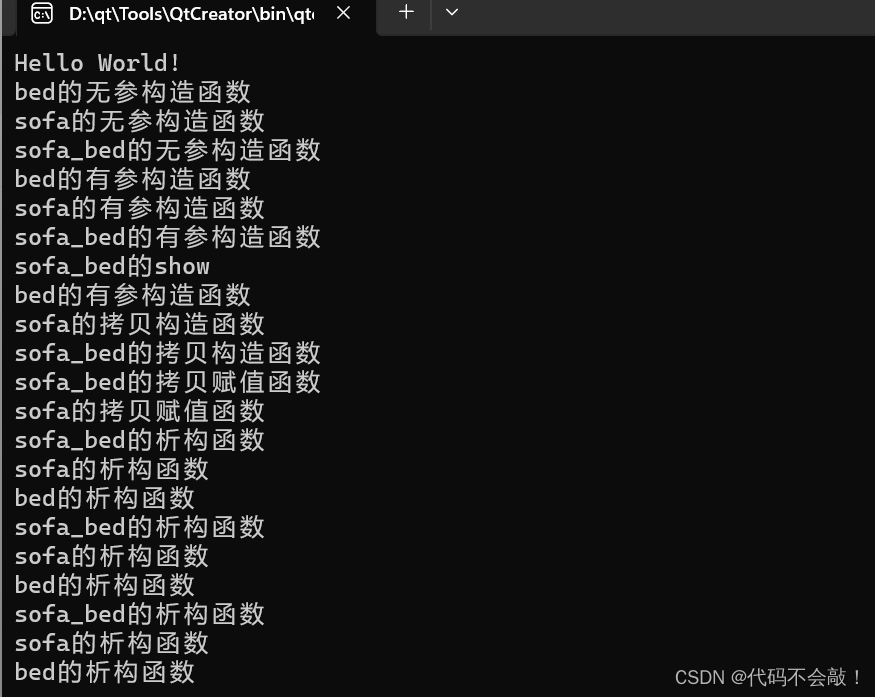
C++学习day5
目录 作业: 1> 思维导图 2> 多继承代码实现沙发床 1>思维导图 2> 多继承代码实现沙发床 #include <iostream>using namespace std; //创建沙发类 class sofa { private:string sitting; public:sofa(){cout << "sofa的无参构造函数…...

1.软件开发-HTML结构-元素剖析
元素的嵌套 代码注释 ctrl/ URL url 统一资源定位符 一个给定的独特资源在web上的地址 URI...
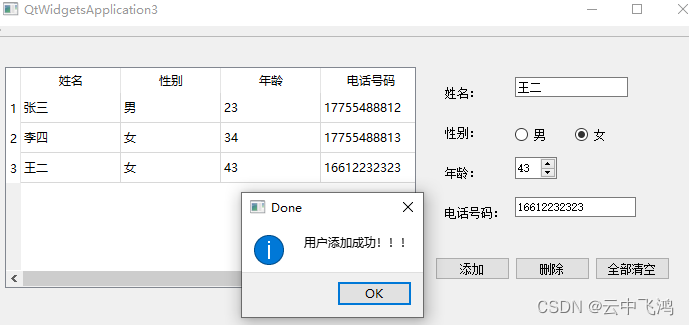
QTableWidget 表格增删数据
QTableWidgetQTableWidgetQTableWidget部分使用方法,如在表格中插入或删除一行数据以及清空表格数据等。在添加数据时,设置了条件判断如正则表达式,若用户输入的数据不合法,则添加失败并提示用户错误的地方,便于用户修…...
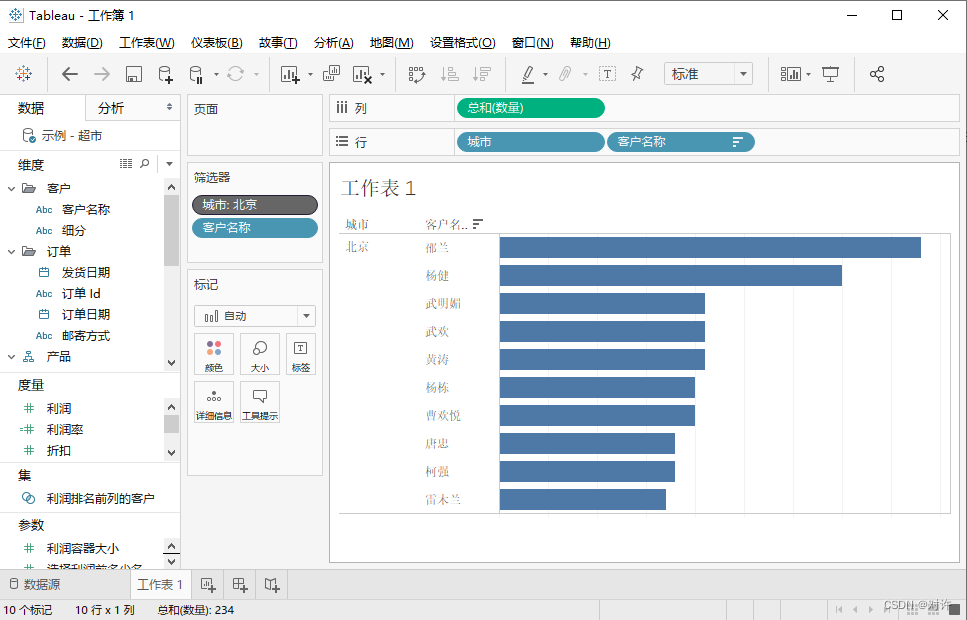
Tableau:商业智能(BI)工具
Tableau入门 1、Tableau概述2、Tableau Desktop2.1、初识Tableau Desktop2.2、Tableau工作区2.3、数据窗格与分析窗格2.4、功能区和标记卡2.4.1、列和行功能区2.4.2、标记卡2.4.3、筛选器功能区2.4.4、页面功能区2.4.5、附加功能区、图例、控件 3、Tableau视图4、Tableau工作簿…...

【gmail注册教程】手把手教你注册Google邮箱账号
手把手教你注册Google邮箱账号 写在前面: 要注意,注册Google邮箱必须要确保自己能够 科学上网,如果暂时做不到,请先进行相关学习。使用的手机号是大陆(86)的。 在保证自己能够科学上网后,在浏…...

docker版jxTMS使用指南:数据采集系统的高可用性
本文讲解4.6版jxTMS中数据采集系统的高可用性,整个系列的文章请查看:4.6版升级内容 docker版本的使用,请查看:docker版jxTMS使用指南 4.0版jxTMS的说明,请查看:4.0版升级内容 4.2版jxTMS的说明ÿ…...

vue如何禁止通过页面输入路径跳转页面
要禁止通过页面输入路径跳转页面,你可以使用Vue Router的导航守卫(navigation guards)来拦截导航并阻止不希望的跳转。 下面是一种常见的方法,你可以在全局导航守卫(global navigation guards)中实现这个功…...

mac,linux环境的基础工具安装【jdk,tomcat】
安装 一 linux环境一)、JDK安装卸载: 二)、 tomcat 安装1、[下载](https://mirrors.bfsu.edu.cn/apache/tomcat/tomcat-8/v8.5.63/bin/apache-tomcat-8.5.63.tar.gz)后,在目录 /usr/local/tomcat下,解压缩2、配置tomca…...
chrome窗口
chrome 窗口的层次: 父窗口类名:Chrome_WidgetWin_1 有两个子窗口: Chrome_RenderWidgetHostHWNDIntermediate D3D Window // 用于匹配 Chrome 窗口的窗口类的前缀。 onst wchar_t kChromeWindowClassPrefix[] L"Chrome_WidgetWin_…...

某快递公司Java一面
1.平衡二叉树和红黑树的区别? 平衡二叉树是一种二叉搜索树,其左子树和右子树的高度差不超过1,以确保在最坏情况下的查找效率是O(log n)。而红黑树是一种自平衡二叉搜索树,通过引入颜色标记(红色和黑色)来维…...

【C++ Primer Plus学习记录】指针——声明和初始化指针
指针用于存储值的地址,因此,指针名表示的地址。*运算符被称为间接值或解除引用运算符,将其应用于指针,可以得到该地址处存储的值。 例如,假设manly是一个指针,则manly表示的是一个地址,而*manl…...

切换至root用户时,命令提示符颜色为白色,如何修改?
当我切换至root用户时,发现命令提示符里的内容全部为白色,如图所示: 这让人看着不愉快,上网先搜索下解决方案:【切换到 root 账户字体全是白的,怎么改颜色啊】- 百度贴吧,但是这个解决方案只是…...

设计模式——17. 状态模式
1. 说明 状态模式(State Pattern)是一种行为设计模式,它允许一个对象在其内部状态发生改变时改变其行为。状态模式将对象的状态封装成不同的状态对象,并将状态切换时的行为委托给当前状态对象。这样,对象在不同状态下具有不同的行为,而无需在对象本身中使用大量的条件语…...
的软件开发)
系统架构设计:14 论软基于架构的软件设计方法(ABSD)的软件开发
目录 1 基于架构的软件设计(ABSD) 2 基于架构的软件开发过程 2.1 架构需求过程 2.2 架构设计过程</...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

树莓派工业GPIO接口板:电气隔离与电平转换实战指南
1. 项目概述:为什么需要一块工业级GPIO接口板?如果你用树莓派做过一些硬件项目,尤其是涉及到控制继电器、电机或者连接工业设备(比如PLC、变频器)时,大概率踩过这样的坑:直接用树莓派的GPIO引脚…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...