LLaMA Adapter和LLaMA Adapter V2
LLaMA Adapter论文地址:
https://arxiv.org/pdf/2303.16199.pdf
LLaMA Adapter V2论文地址:
https://arxiv.org/pdf/2304.15010.pdf
LLaMA Adapter效果展示地址:
LLaMA Adapter 双语多模态通用模型 为你写诗 - 知乎
LLaMA Adapter GitHub项目地址:
https://github.com/OpenGVLab/LLaMA-Adapter
LLaMA Adapter V2 GitHub项目地址(包含在LLaMA-Adapter项目中):
https://github.com/OpenGVLab/LLaMA-Adapter/tree/main/llama_adapter_v2_multimodal7b
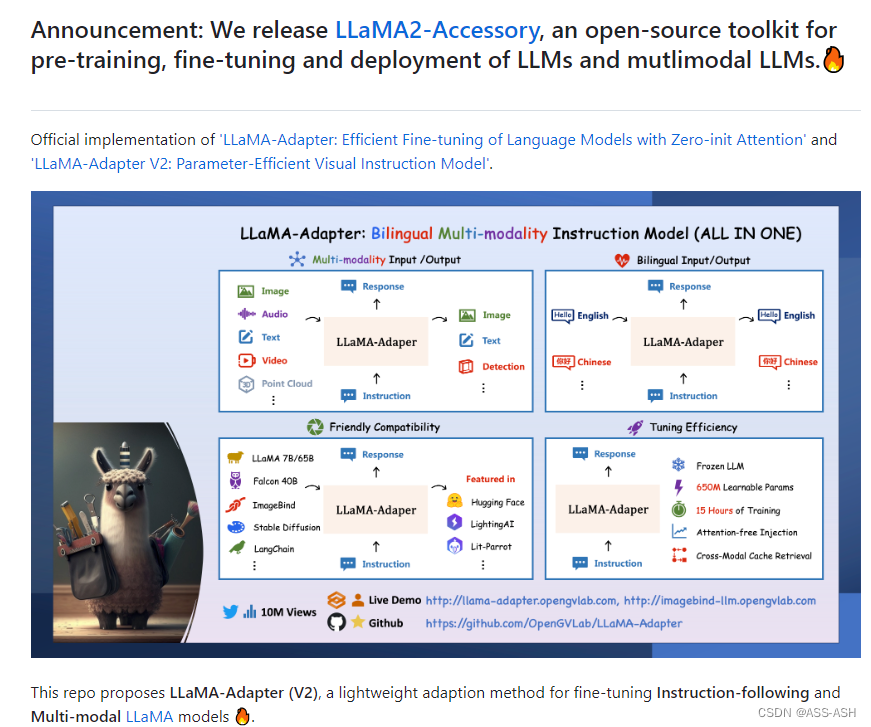
LLaMA-Adapter简介
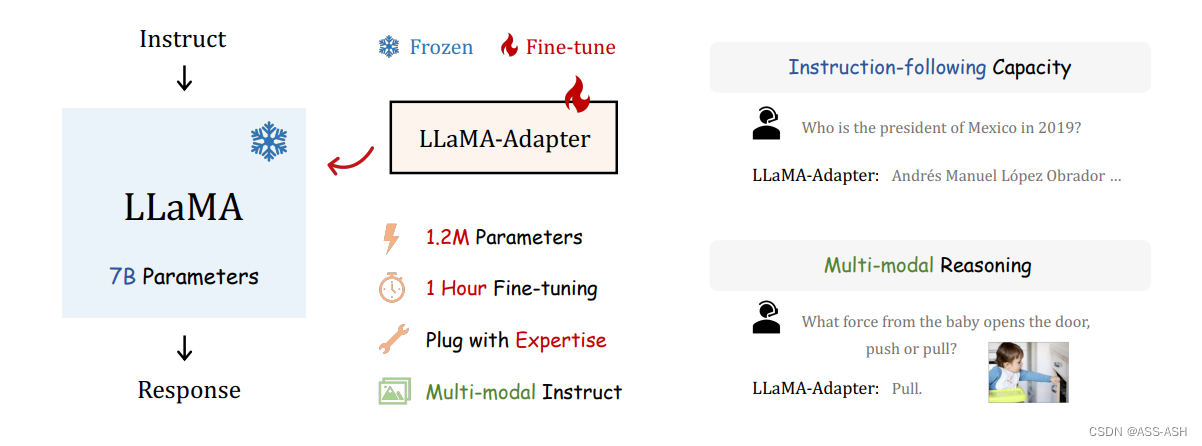
LLaMA-Adapter是一个参数高效的多模态指令模型
论文作者提出了 LLaMA-Adapter,一种轻量级的适应方法,可以有效地将 LLaMA 微调为一个跟随指令的模型。LLaMA-Adapter 使用 52K 个自我指示的样例,在冻结的 LLaMA 7B 模型上只引入了 120 万个可学习参数,在 8 个A100 GPU 上进行微调的成本不到 1 小时。
具体来说,作者采用了一组可学习的适应性提示,并将其预置在较高 Transformer 层的输入文本标记上。
然后,作者提出了一个具有零初始(zero-init)的注意力机制,该机制可以自适应地将新的训练线索注入到 LLaMA 中,同时有效地保留了其预训练的知识。通过有效的训练,LLaMA-Adapter 产生了高质量的反应,与具有完全微调的 7B 参数的 Alpaca 相当。
此外,该方法可以简单地扩展到多模态的输入,例如图像,多模态模型在 ScienceQA 上实现了卓越的推理能力。
特点
LLaMA-Adapter具有如下四个特点:
1、掌握多种模态:
LLaMA-Adapter 能够无缝整合多种输入模态,如图像、音频、文本、视频和3D点云等,并提供图像、文本和检测输出。
2、支持双语功能:
LLaMA-Adapter 具有双语功能,能够支持中英双语输入输出。
3、强大的兼容性:
LLaMA-Adapter 有强大的兼容性,兼容LLaMA,Falcon,ImageBind,StableDiffusion,LangChain等,并且目前已得到HuggingFace和Lightning AI 的大力支持。
4、参数高效:
LLaMA-Adapter 在冻结的语言模型上只引入了650M的参数,在8张A100显卡上只需15小时就能完成训练。此外,LLaMA-Adapter提供无需注意力的多模态注入,并支持跨模态缓存检索。
LLaMA-Adapter V2 论文简略解读
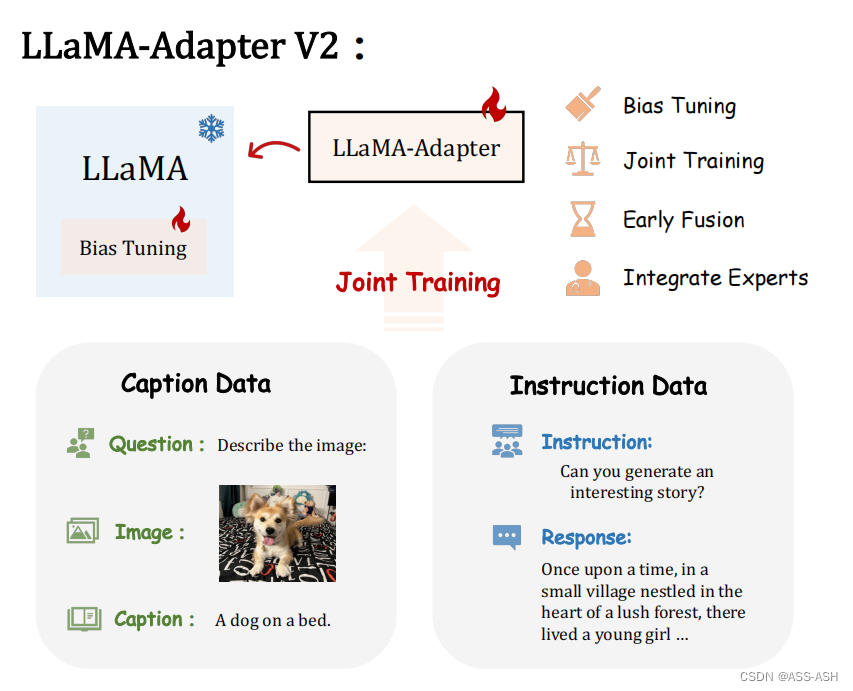
摘要
如何有效地将大型语言模型(LLM)转化为指令跟随器是最近一个热门的研究方向,而训练 LLM 进行多模态推理的探索仍然较少。尽管最近的 LLaMA-Adapter 展示了使用 LLM 处理视觉输入的潜力,但它仍然不能很好地泛化到开放式视觉指令,并且落后于 GPT-4。在本文中,作者提出了LLaMA-Adapter V2,一种参数高效的视觉指令模型。具体来说,作者首先通过解锁更多可学习参数(例如范数、偏差和比例)来增强 LLaMAAdapter,这些参数将指令遵循能力分布到整个 LLaMA 模型中,除了适配器之外。其次,作者提出了一种早期融合策略,仅将视觉标记提供给早期的 LLM 层,有助于更好地整合视觉知识。第三,通过优化不相交的可学习参数组,引入了图像-文本对和指令跟随数据的联合训练范式。该策略有效地缓解了图文对齐和指令跟随这两个任务之间的干扰,仅用小规模的图文和指令数据集就实现了强多模态推理。在推理过程中,作者将额外的专家模型(例如字幕/OCR 系统)合并到 LLaMA-Adapter 中,以进一步增强其图像理解能力,而不会产生训练成本。与原始的 LLaMAAdapter 相比,作者的 LLaMA-Adapter V2 只需在 LLaMA 上引入 14M 参数即可执行开放式多模式指令。新设计的框架也展现出更强的纯语言指令跟随能力,甚至在聊天交互方面表现出色” (Gao 等, 2023, p. 1)
1. 介绍
大型语言模型 (LLM) [75] 因其理解、推理和生成人类语言的非凡能力而在 AI 社区中引起了极大的关注。为了使 LLM 的回答更加生动和令人信服,最近的工作 探索了将 LLM 转化为指令遵循模型。例如,Stanford Alpaca [62] 使用从 OpenAI 的 InstructGPT 模型 [48] 生成的指令示例将 LLaMA [63] 微调为指令跟随模型。 Alpaca 的后续工作通过利用更高质量的指令数据(例如 ShareGPT [1] 和 GPT-4 [50] 生成的数据)进一步扩展了 LLaMA。与 Alpaca 和 Vicuna [7] 采用的全微调范式相比,LLaMA-Adapter [72] 引入了对冻结的 LLaMA 进行零初始化关注的轻量级适配器,用于参数有效的微调,以及多模态知识注入。尽管取得了重大进展,但上述方法仍然无法执行更高级的多模态指令,例如像 GPT-4 [47] 这样的视觉理解。” (Gao 等, 2023, p. 1)
最近,MiniGPT-4 [78] 和 LLaVA [38] 等研究引发了新一波研究,将纯语言指令模型扩展为多模式模型,以类似于 LLaMA 的方式赋予 LLM 视觉推理能力-适配器。 MiniGPT-4 通过对 1.34 亿个图像文本对进行预训练来连接冻结视觉编码器和 LLM,然后通过在对齐良好的图像文本数据集上进一步微调来提高模型的性能。 LLaVA 还利用图像-文本对来对齐视觉模型和 LLM。与 MiniGPT4 不同,LLaVA 在 GPT-4 生成的 150K 高质量多模态指令数据上对整个 LLM 进行微调。虽然这些方法展示了令人印象深刻的多模态理解能力,但它们需要更新数十亿个模型参数并精心收集大量多模态训练数据,这些数据要么由人类注释,要么从 OpenAI API 的响应中提取。 (Gao 等, 2023, p. 2)
在本文中,作者的目标是设计一个参数有效的视觉指令模型。作者在流行的参数高效 LLaMA-Adapter 的基础上开发了作者的新方法,作者将其称为 LLaMA-Adapter V2。 LLaMA-Adapter 最初是作为指令跟随模型开发的,并且可以通过将视觉特征纳入适应提示中轻松转换为视觉指令模型。然而,由于缺乏多模态指令调整数据,LLaMAAdapter 的多模态版本作为传统视觉语言模型受到限制。例如,在 COCO Caption [6] 上训练的 LLaMA-Adapter 只能在给出特定提示时生成简短的图像标题,例如“为此图像生成标题”。模型不能适应开放式多模态指令,例如复杂的视觉推理和视觉问答任务” (Gao 等, 2023, p. 2)
虽然作者目前没有利用多模式指令数据,但仍然可以为 LLaMA-Adapter 执行多模式指令调整。作者首先使用冻结的指令跟随 LLaMA-Adapter 模型作为起点,并通过优化图像-文本对上的视觉投影层来改进它,以确保正确的视觉-语言对齐。然而,作者观察到视觉特征往往主导适应提示,导致指令遵循能力迅速恶化。” (Gao 等, 2023, p. 2)
为了应对这一挑战,作者提出了一种简单的视觉知识早期融合策略,解决了图像文本对齐和语言指令调整这两个任务之间的干扰。在 LLaMA-Adapter 中,动态视觉提示被合并到最后 L 层的静态适配提示中。然而,在 LLaMAAdapter V2 中,作者仅将动态视觉提示分发到前 K 层,其中 K < N - L,N 表示 Transformer 层的总数。因此,图像文本对齐不再破坏模型的指令跟随能力。通过这种策略,即使在没有高质量多模态指令数据的情况下,作者也可以通过使用不相交参数与图像字幕数据和指令跟随数据进行联合训练来实现卓越的视觉指令学习。此外,作者通过解锁更多可学习的参数(例如归一化、层偏差和比例)来增强 LLaMA-Adapter,作者将其称为线性层的偏差调整。通过增加模型的可调容量,作者可以在整个 LLM 中传播 instructionfollowing 知识。值得注意的是,这些参数只占整个模型的大约 0.04%,确保 LLaMA-Adapter V2 仍然是一种参数高效的方法。”
为了应对这一挑战,作者提出了一种简单的视觉知识早期融合策略,解决了图像文本对齐和语言指令调整这两个任务之间的干扰。在 LLaMA-Adapter 中,动态视觉提示被合并到最后 L 层的静态适配提示中。然而,在 LLaMA-Adapter V2 中,作者仅将动态视觉提示分发到前 K 层,其中 K < N - L,N 表示 Transformer 层的总数。因此,图像文本对齐不再破坏模型的指令跟随能力。通过这种策略,即使在没有高质量多模态指令数据的情况下,作者也可以通过使用不相交参数与图像字幕数据和指令跟随数据进行联合训练来实现卓越的视觉指令学习。此外,作者通过解锁更多可学习的参数(例如归一化、层偏差和比例)来增强 LLaMA-Adapter,作者将其称为线性层的偏差调整。通过增加模型的可调容量,作者可以在整个 LLM 中传播 instructionfollowing 知识。值得注意的是,这些参数只占整个模型的大约 0.04%,确保 LLaMA-Adapter V2 仍然是一种参数高效的方法。” (Gao 等, 2023, p. 2)
最后,作者引入了额外的专家模型(例如,字幕、检测和 OCR 系统)来增强 LLaMA-Adapter V2 的图像理解能力,使作者的方法有别于依赖海量图像文本的其他方法,例如 MiniGPT-4 和 LLaVA对训练数据。通过与这些专业专家合作,作者的框架获得了更高的灵活性,并允许插入各种专家来完成各种各样的任务,而无需对大量视觉语言数据进行预训练。” (Gao 等, 2023, p. 2)
图 1 和图 4 分别说明了作者的 LLaMA-Adapter V2 的整个训练和生成管道。作者的主要贡献总结如下:
(1)更强的语言指令模型。凭借参数高效的调优策略和高质量的语言指令数据,LLaMA-Adapter V2 在语言指令跟随性能方面超越了其前身 LLaMA-Adapter。此外,LLaMA-Adapter V2 能够进行多轮对话,展示了其作为语言教学模型的更强能力。
(2)平衡的视觉指令调整。作者提出了一种简单的早期融合策略来解决图像文本对齐和指令跟随学习目标之间的干扰。因此,作者将 LLaMA-Adapter V2 转换为视觉指令模型,而不需要多模态指令训练数据。
(3)专家系统的集成。作者采用模块化设计,可以将不同的专家模型集成到作者的框架中,以增强 LLM 的图像理解能力,而不是对大量图像文本对进行端到端预训练。” (Gao 等, 2023, p. 2)
2. Related Work
(1)Instruction-following Language Models 大型语言模型 (LLM) 使用自回归 Transformer 模型在广泛的文本语料库上进行预训练以预测后续标记。他们在自我监督 [53]、多任务 [54] 和少样本学习者 [4] 方面表现出了强大的能力。最近,InstructGPT [48] 和 FLAN [8, 66] 表明,LLM 可以通过在教学数据集上进行微调来转换为指令跟随模型。为了促进指令跟随示例的生成,Self-Instruct [65] 采用了一种半自动、迭代引导算法,该算法扩展了有限的手动编写指令种子集,并使用现成的 LLM 逐步扩展任务集合. Alpaca [62] 应用 Self-Instruct 策略生成 52K 高质量指令跟随演示,并对开源 LLaMA [63] 模型进行微调,最终获得一个指令跟随语言模型,表现出许多类似于 OpenAI 文本的行为-达芬奇-003。受到 Alpaca 成功的启发,Vicuna [7] 和 GPT-4-LLM [50] 进一步表明,可以通过微调用户共享的 ChatGPT 对话或由GPT-4 API。然而,Alpaca、Vicuna 和 GPT4-LLM 都对 LLM 的全部参数进行了微调,导致无法承受的 GPU 内存使用和训练成本。相比之下,LoRA [26] 和 LLaMA-Adapter [72] 验证了参数有效的微调方法可以在 LLM 的监督微调期间潜在地取代完整的参数更新。在本文中,LLaMA-Adapter V2 更进一步,构建了一个参数有效的 zeroshot 视觉指令模型,该模型重用了 LLaMA-Adapter 的指令跟随能力。” (Gao 等, 2023, p. 3)
(2)Parameter-efficient Fine-tuning 预训练微调范式已被证明在视觉识别、语言理解、文本生成和文本描述的图像合成等各种任务中非常有效。然而,随着模型大小继续呈指数增长,微调庞大模型中的每个参数变得越来越不切实际。相比之下,参数效率微调 (PEFT) 方法 [12,49] 冻结了基础模型的大部分参数,只优化了其中的一小部分。许多成功的 PEFT 方法被提出用于采用流行的预训练模型,例如 BERT [11]、GPT [4、53、54]、ViT [13]、CLIP [52] 和 Stable Diffusion [55] 到各种下游任务。一般来说,这些 PEFT 方法可以分为三类,即前缀调整(例如 [35,76])、重新参数化(例如 [10,26,43])和适配器(例如 [15,24,74])。在本文中,作者介绍了 LLaMA-Adapter V2,这是一种优雅而高效的前缀调整和适配器技术的结合。通过利用早期融合策略和偏差调整,LLaMA-Adapter V2 将视觉特征注入大型语言模型,产生令人印象深刻的多模态指令遵循性能,整个 LLaMA 的参数仅为 0.04%” (Gao 等, 2023, p. 3)
3 LLaMA-Adapter
(1)初始化注意力。作为一种使 LLaMA 获得指令跟随能力的参数高效微调解决方案,LLaMA-Adapter [72] 冻结了整个 LLaMA 模型 [63],并仅引入了一个具有 1.2M 参数的额外轻量级适配器模块。适配器层用于 LLaMA 的较高 Transformer 层,并将一组可学习的软提示连接起来作为单词标记的前缀。为了将新适应的知识整合到冻结的 LLaMA 中,LLaMAAdapter 提出了一种零初始化的注意机制,该机制可以通过学习一个由零初始化的门控因子来自适应地控制适应提示对词标记的贡献。门控幅度在训练过程中逐渐增加,从而逐渐注入.
(2)简单的多模式变体。除了使用纯语言指令进行微调外,LLaMA-Adapter 还可以结合图像和视频输入进行多模态推理。例如,在处理图像时,LLaMAAdapter 使用预训练的视觉编码器(如 CLIP [52])来提取多尺度视觉特征。然后将这些特征聚合成一个全局特征,并通过可学习的投影层传递,以将视觉语义与语言嵌入空间对齐。之后,将全局视觉特征逐元素添加到 Transformer 较高层的每个适配提示中。这允许 LLaMA-Adapter 基于文本和视觉输入生成响应,从而在 ScienceQA 基准 [41] 上具有竞争力的表现。” (Gao 等, 2023, p. 4)
(3)开放式多模态推理。作者首先从 LLaMA-Adapter 开始,该适配器在语言指令数据上进行了预训练,以利用其现有的指令遵循功能。然后,作者通过在 COCO Caption [6] 数据集上微调其适配器模块和视觉投影层来进行实验。然而,作者发现新学习的视觉线索往往支配适应提示,压倒固有的指令遵循特征。因此,作者提出了 LLaMAAdapter V2,一种参数高效的视觉指令模型,以充分释放 LLaMA 的多模态潜力。” (Gao 等, 2023, p. 4)
4. LLaMA-Adapter V2
4.1.线性层的偏差调整
LLaMA-Adapter 在冻结的 LLaMA 模型上采用可学习的适应提示和零初始化注意机制,从而可以有效地整合新知识。但是,参数更新受限于自适应提示和门控因子,没有修改LLMs的内部参数,这限制了它进行深度微调的能力。鉴于此,作者提出了一种偏差调整策略,除了适应提示和门控因素之外,进一步将指令提示融合到 LLaMA 中。具体来说,为了自适应地处理指令跟随数据的任务,作者首先解冻 LLaMA 中的所有规范化层。对于 Transformer 中的每个线性层,作者添加一个偏差和一个比例因子作为两个可学习的参数。作者将某个线性层的输入和预训练权重分别表示为 x 和 W。在 LLaMA-Adapter V2 中,作者使用偏置 b 和尺度 s 修改线性层为
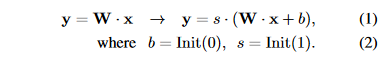
与零初始化注意力类似,作者分别用零和一初始化偏差和比例因子,以稳定早期阶段的训练过程。通过结合偏置调整策略和高质量指令数据 [50],LLaMA-Adapter V2 获得了卓越的指令跟随能力。值得注意的是,新增参数的数量仅占整个 LLaMA 的 0.04%(∼5M),表明 LLaMA-Adapter V2 仍然是一种参数高效的方法。” (Gao 等, 2023, p. 5)
讨论。作者的偏差调整策略与先前的参数有效方法有相似之处,例如用于 BERT 微调的BitFit [70] 和用于视觉提示调整的 SSF [36] [28]。然而,BitFit 和 SSF 都是为具有 8000 万个参数规模的理解任务而设计的,而作者的偏差调整证明了它在 70 亿到 650 亿个参数的大型语言模型(例如 LLaMA 和 GPT-3)上的效率。此外,作者的偏差调整策略是输入不可知的,这与使用低秩转换添加输入感知偏差的低秩适应 (LoRA) 不同,进一步降低了微调成本” (Gao 等, 2023, p. 5)
4.2.使用不相交参数进行联合训练
作者的目标是同时赋予 LLaMA-Adapter V2 生成长语言响应和多模态理解的能力。如图 2 所示,作者提出了 LLaMA-Adapter V2 的联合训练范例,以利用图像文本字幕数据和纯语言指令示例。由于 500K 图像文本对和 50K 指令数据之间的数据量差异,天真地将它们组合起来进行优化会严重损害 LLaMA-Adapter 的指令跟随能力,正如第 1 节中所讨论的那样。因此,作者的联合训练策略优化了 LLaMA-Adapter V2 中不相交的参数组,分别用于图像文本对齐和指令跟踪。具体来说,只有视觉投影层和带门控的早期零初始化注意力针对图文字幕数据进行训练,而后期适应提示与零门控、未冻结范数、新添加的偏差和比例因子(或可选的低秩适应[25])被用于从指令跟随数据学习。这种不相交的参数优化自然地解决了图文理解和指令跟随之间的干扰问题,这有助于 LLaMA-Adapter V2 的紧急视觉指令跟随能力。

讨论。在作者的联合训练策略的帮助下,LLaMA-Adapter V2 不需要像 MiniGPT-4 [78] 和 LLaVA [38] 这样的高质量多模态指令数据,而只需要图像文本对和指令跟随数据,如表 1 所示。 1. 如图 2 所示,字幕数据扩展了 LLM 的图像理解和简短答案,而仅语言指令数据用于保留 LLaMA 生成详细长句的能力。凭借这种互补性,LLaMA-Adapter V2 仅通过小规模图像文本和指令跟随数据实现了卓越的多模态推理,而无需高质量的多模态指令数据。” (Gao 等, 2023, p. 6)
4.3 视觉知识的早期融合
为了避免视觉和语言微调之间的干扰,作者提出了一种简单的早期融合策略,以防止输入视觉提示和适应提示之间的直接交互。在 LLaMA-Adapter 中,输入的视觉提示由具有可学习视觉投影层的冻结视觉编码器顺序编码,然后在每个插入层添加到自适应提示。在 LLaMA-Adapter V2 中,作者将编码的视觉标记和自适应提示注入不同的 Transformer 层,而不将它们融合在一起,如图 3 所示。对于数据集共享的自适应提示,作者遵循 LLaMA-Adapter,将它们插入到最后 L 层(例如,L=30)。对于输入的视觉提示,作者直接将它们与单词标记连接起来,这是具有零初始化注意力的 Transformer 层,而不是将它们添加到自适应提示中。与提出的联合训练一起,这种简单的视觉标记早期融合策略可以有效地解决两类微调目标之间的冲突。这有助于参数高效的 LLaMA-Adapter V2 具有卓越的多模态推理能力。” (Gao 等, 2023, p. 6)

4.4.与专家集成
最近的视觉指令模型,如 MiniGPT4 [78] 和 LLaVA [38] 需要大规模的图像文本训练来连接视觉模型和 LLM。相比之下,作者的 LLaMA-Adapter V2 对更小规模的常见图像字幕数据 [6] 进行了微调,使其数据效率更高。然而,作者的方法的图像理解能力相对较弱,导致偶尔出现不准确或无关的响应。作者建议集成字幕、OCR 和搜索引擎等专家系统,以补充 LLaMA-Adapter V2 额外的视觉推理能力,而不是收集更多的图像文本数据或采用更强大的多模态模块。如图 4 所示,作者利用字幕、检测和 OCR 等专家系统来增强 LLaMA-Adapter V2 的视觉指令遵循能力。
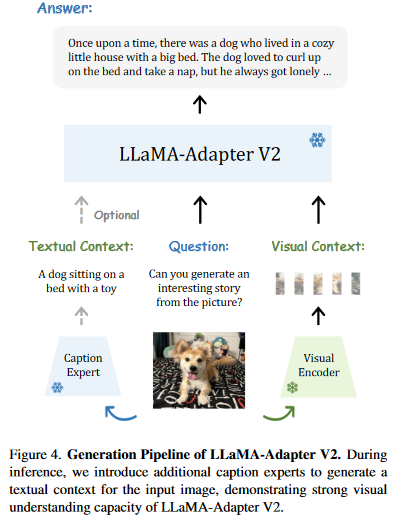
给定一张输入图像,作者使用预训练的视觉编码器对其视觉上下文进行编码,并要求专家系统生成标题作为文本上下文。在作者的默认实现中,作者采用在 COCO Caption [6] 上预训练的 LLaMA-Adapter 作为专家系统,因为它可以生成简短而准确的图像描述。然而,值得注意的是,任何图像到文本模型甚至搜索引擎都可以作为这里的专家系统。作者的方法使作者能够根据手头的特定下游任务轻松地在不同的专家系统之间切换。” (Gao 等, 2023, p. 7)
5. 结论
在这项工作中,作者提出了 LLaMA-Adapter V2,一种参数高效的视觉指令调整系统。通过对图像文本对和指令跟随数据的联合训练,作者观察到 LLaMA-Adapter V2 可以将预训练的 LLM 转换为零镜头视觉指令模型。借助简单的偏置调整策略和视觉特征的早期融合,LLaMA-Adapter V2 的零样本视觉指令跟随能力通过减轻图像-文本对和指令跟随数据之间的干扰进一步提高。同时,LLaMA-Adapter V2 实现了更强的语言指令跟随性能,甚至具备聊天机器人般的多轮对话能力。针对 LLaMAAdapter V2 图像描述不准确的问题,作者集成了 OCR 和 Image captioner 等专业视觉系统,以提供更准确的图像相关信息。虽然 LLaMA-Adapter V2 可以结合专家视觉系统并以零样本的方式执行视觉指令跟随,但它在视觉理解能力方面仍然落后于 LLaVA,并且容易受到专家系统提供的不准确信息的影响。未来,作者计划探索更多专家系统的集成,并使用多模态指令数据集或其他 PEFT 方法(例如 LoRA)对 LLaMA-Adapter V2 进行微调,以进一步增强其视觉指令跟随能力。” (Gao 等, 2023, p. 11)
相关文章:
LLaMA Adapter和LLaMA Adapter V2
LLaMA Adapter论文地址: https://arxiv.org/pdf/2303.16199.pdf LLaMA Adapter V2论文地址: https://arxiv.org/pdf/2304.15010.pdf LLaMA Adapter效果展示地址: LLaMA Adapter 双语多模态通用模型 为你写诗 - 知乎 LLaMA Adapter GitH…...

高压放大器在软体机器人领域的应用
软体机器人是一种新型机器人技术,与传统的硬体机器人有着很大的不同。软体机器人通常由柔软的材料制成,具有高度的柔韧性和灵活性,并且可以实现多种形状和动作。但是,软体机器人的发展面临很多技术挑战,其中之一就是控…...

《Linux C/C++服务器开发实践》之第4章 TCP服务器编程
《Linux C/C服务器开发实践》之第4章 TCP服务器编程 4.1 套接字的基本概念4.2 网络程序的架构4.3 IP地址的格式转换4.1.c 4.4 套接字的类型4.5 套接字地址4.5.1 通用socket地址4.5.2 专用socket地址4.5.3 获取套接字地址4.2.c 4.6 主机字节序和网络字节序4.3.c 4.7 协议族和地址…...

HCIA---静态路由扩展配置
静态的扩展配置: 1、负载均衡:当访问相同目标,具有多条开销相似路径时;可以让设备将流量拆分后延多条路径同时传输;起到带宽叠加的作用; 2、环回接口-- 创建后,可用于路由器测试TCP/IP协议组件…...
OCP Java17 SE Developers 复习题04
答案 F. Line 5 does not compile. This question is checking to see whether you are paying attention to the types. numFish is an int, and 1 is an int. Therefore, we use numeric addition and get 5. The problem is that we cant store an int in a String variab…...
spark中使用flatmap报错:TypeError: ‘int‘ object is not subscriptable
1、背景描述 菜鸟笔者在运行下面代码时发生了报错: from pyspark import SparkContextsc SparkContext("local", "apple1012")rdd sc.parallelize([[1, 2], 3, [7, 5, 6]])rdd1 rdd.flatMap(lambda x: x) print(rdd1.collect())报错描述如…...
-每天了解一点)
node.js知识系列(5)-每天了解一点
目录 21. RESTful API 设计中的 HTTP 动词22. 中间件链和回调地狱23. Express.js 的 ORM 经验24. 错误处理中间件和 HTTP 状态码25. 事件循环(Event Loop)在异步编程中的作用26. Node.js 缓存机制27. Node.js 全局对象28. 性能分析和调优经验29. Express…...
修改IP地址)
Linux服务器(银河麒麟、CentOS 7+、CentOS 7+ 等)修改IP地址
打开终端或控制台,以root或具有sudo权限的用户身份登录。根据你的Linux发行版和网络管理工具的不同,相应的命令可能略有不同。使用以下命令编辑网络配置文件,例如eth0网卡的配置文件: 注意:ifcfg-eth0 可能会有不同的命…...
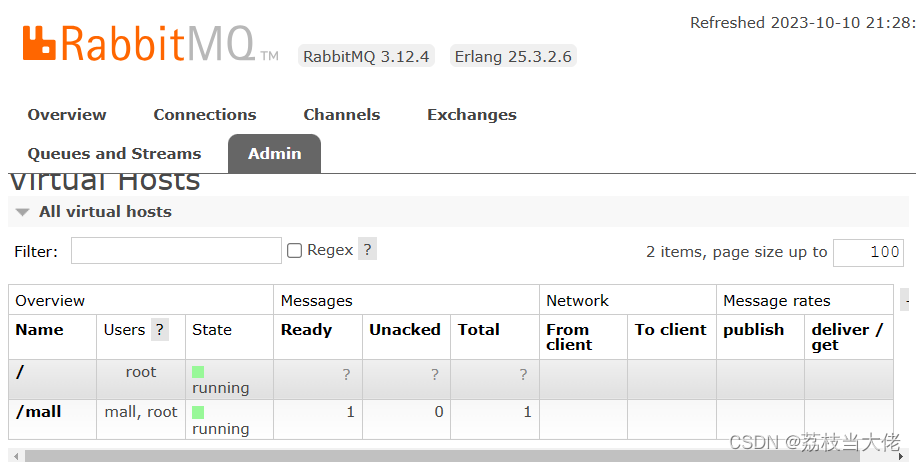
Mall脚手架总结(四) —— SpringBoot整合RabbitMQ实现超时订单处理
前言 在电商项目中,订单因为某种特殊情况被取消或者超时未支付都是比较常规的用户行为,而实现该功能我们就要借助消息中间件来为我们维护这么一个消息队列。在mall脚手架中选择了RabbitMQ消息中间件,接下来荔枝就会根据功能需求来梳理一下超时…...
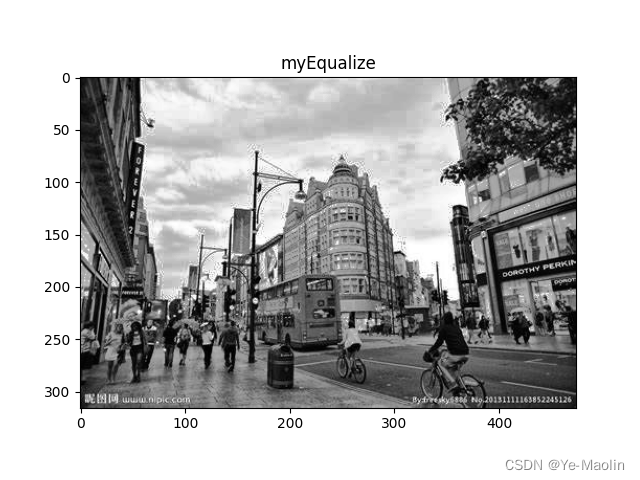
python实现图像的直方图均衡化
直方图均衡化是一种用于增强图像对比度的图像处理技术。它通过重新分配图像中的像素值,使得图像的像素值分布更加均匀,增强图像的对比度,从而改善图像的视觉效果。 直方图均衡化的过程如下: 灰度转换:如果图像是彩色…...
哪种烧录单片机的方法合适?
哪种烧录单片机的方法合适? 首先,让我们来探讨一下单片机烧录的方式。虽然单片机烧录程序的具体方法会因为单片机型号、然后很多小伙伴私我想要嵌入式资料,通宵总结整理后,我十年的经验和入门到高级的学习资料,只需一…...
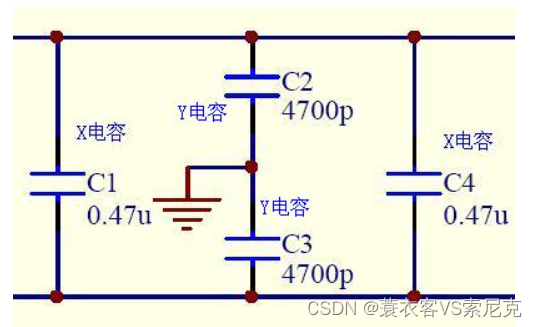
安规电容总结
安规电容 顾名思义:电容即使失效后,也不会漏电或者放电伤人,要符合安全规定 多数高压认证产品都需要。 上图: X电容: Y电容: 区别: 电路示意:...
MyCat分片垂直拆分
场景 在业务系统中 , 涉及以下表结构 , 但是由于用户与订单每天都会产生大量的数据 , 单台服务器的数据 存储及处理能力是有限的 , 可以对数据库表进行拆分 , 原有的数据库表如下。 现在考虑将其进行垂直分库操作,将商品相关的表拆分到一个数据库服务器&#…...

MongoDB bin目录没有mongo.exe命令
MongoDB从6.0版本开始就取消了在Bin目录中加入Compass连接工具,需要大家自行安装。 可以定位到我的文章 链接地址 点击右侧目录的 标题三:MongoDB Compass连接MongoDBMongoDB Compass的安装方法哦~...
Zookeeper分布式一致性协议ZAB源码剖析
文章目录 1、ZAB协议介绍2、消息广播 1、ZAB协议介绍 ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。 Zookeeper 是一个为分布式应用提供高效且可靠的分布式协调服务。在解决分布式一致性方面,Zookeeper 并…...

微软 AR 眼镜新专利:包含热拔插电池
近日,微软在增强现实(AR)领域进行深入的研究,并申请了一项有关于“热插拔电池”的专利。该专利于2023年10月5日发布,描述了一款采用模块化设计的AR眼镜,其热插拔电池放置在镜腿部分,可以直接替代…...

软件TFN 2K的分布式拒绝攻击(DDos)实战详解
写在前头 本人写这篇博客的目的,并不是我想成为黑客或者鼓励大家做损坏任何人安全和利益的事情。因科研需要,我学习软件TFN 2K的分布式拒绝攻击,只是分享自己的学习过程和经历,有助于大家更好的关注到网络安全及网络维护上。 需要…...
计算机网络第四章——网络层(末)
赌书消得泼茶香当时只道是寻常 文章目录 概述:组播机制是让源计算机一次发送的单个分组可以抵达用一个组地址标识的若干目标主机,并被它们正确接收,组播仅应用于UDP 因特网中的IP组播也使用组播组的概念,每个组都有一个特别分配的…...

Newman基本使用
目录 简介 安装 使用 官网 运行 输出测试报告文件 htmlextra 使用 简介 Newman 是 Postman 推出的一个 nodejs 库,直接来说就是 Postman 的json文件可以在命令行执行的插件。 Newman 可以方便地运行和测试集合,并用之构造接口自动化测试和持续集成…...

左值引用右值引用
文章目录 左值和右值什么是左值什么是右值左值引用与右值引用的比较左值引用总结右值引用的总结: 右值引用使用场景和意义左值引用的使用场景左值引用的短板 右值引用和移动语义解决上面的问题不仅仅有移动构造还有移动赋值 右值引用引用左值及其一些更深入的使用场…...

3分钟快速上手Inter字体:免费开源字体如何提升你的数字产品体验
3分钟快速上手Inter字体:免费开源字体如何提升你的数字产品体验 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为屏幕显示设计的开源无衬线字体,凭借其出色的可读性和多语言…...

手把手教你用网络分析仪调试CGH40010F:从S参数异常反推管子损坏原因与状态
深度解析CGH40010F氮化镓功率管故障诊断:从S参数异常到失效机理 在射频功率放大器设计中,CGH40010F作为一款经典的氮化镓(GaN)功率晶体管,因其高功率密度和高效率特性被广泛应用于基站、雷达等场景。然而在实际工程调试中,工程师们…...
)
告别C盘焦虑!保姆级教程:在D盘为VS2013安个家(附阿里云/百度网盘下载)
告别C盘焦虑!VS2013高效安装与磁盘管理全指南 对于刚接触编程的新手来说,Visual Studio 2013(简称VS2013)是一个功能强大且友好的开发环境。然而,许多用户在安装过程中常常忽略了一个关键问题——安装路径的选择。本文…...

Auto-Lianliankan:基于Python图像识别的连连看自动化终极方案
Auto-Lianliankan:基于Python图像识别的连连看自动化终极方案 【免费下载链接】Auto-Lianliankan 基于python图像识别实现的连连看外挂,可实现QQ连连看秒破 项目地址: https://gitcode.com/gh_mirrors/au/Auto-Lianliankan 你是否曾经在玩连连看游…...

从CentOS 7/8老用户视角:快速上手CentOS 9 Stream的3个界面变化与5个安装配置新坑
从CentOS 7/8老用户视角:快速上手CentOS 9 Stream的3个界面变化与5个安装配置新坑 作为一名长期与CentOS打交道的系统管理员,第一次接触CentOS 9 Stream时,那种"熟悉又陌生"的感觉尤为明显。表面上看,它延续了红帽系一贯…...
)
EEGLab新手避坑:手把手教你搞定EEG数据的Marker、分段与Epoch提取(附完整代码)
EEGLab新手避坑指南:Marker设置、数据分段与Epoch提取全流程解析 在脑电信号处理领域,EEGLab作为MATLAB环境下最常用的开源工具包,其强大的功能和灵活的扩展性深受研究者青睐。但对于刚接触EEGLab的研究生和初级用户来说,从原始EE…...

从PyTorch到RV1126:ResNet50边缘AI模型完整部署实战指南
1. 项目概述:从边缘AI的“芯”需求到RV1126的实战定位最近几年,边缘计算的火热程度有目共睹,尤其是在安防监控、智能门禁、工业质检这些对实时性、隐私性和成本都极其敏感的领域。大家不再满足于把海量视频流、图像数据一股脑儿往云端传&…...

Java 面试高频题:通知平台整体架构一般怎么拆?
消息实时通知平台架构总览怎么搭?一次讲清渠道、模板、推送、回执、偏好与治理闭环 大家好,我是一名有 4 年工作经验的 Java 后端开发。 从第129天开始,我连续围绕消息实时通知系统写了整体设计、渠道抽象、模板中心、实时推送、异步投递、偏…...

蓝桥杯嵌入式省赛串口通信实战:用STM32G431RBT6和CubeMX搞定数据收发与LCD显示
蓝桥杯嵌入式省赛串口通信实战:STM32G431RBT6与CubeMX高效开发指南 对于备战蓝桥杯嵌入式省赛的选手而言,串口通信与LCD显示的联动实现往往是比赛中的关键得分点。本文将围绕STM32G431RBT6开发板,通过CubeMX和Keil MDK5工具链,深入…...

小红书无水印下载全攻略:如何用XHS-Downloader高效保存优质内容
小红书无水印下载全攻略:如何用XHS-Downloader高效保存优质内容 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户…...