Transformer学习笔记
Transformer学习笔记
- 1. 参考
- 2. 模型图
- 3.encoder部分
- 3.1 Positional Encoding
- 3.2 Muti-Head Attention
- 3.3 ADD--残差连接
- 3.4 Norm标准化
- 3.5 单个Transformer Encoder流程图
- 4.decoder部分
- 4.1 mask Muti-Head Attention
- 4.2 Muti-Head Attention
- 5 多个Transformer Encoder和多个Transformer Decoder连接方式
1. 参考
李沐 动手学深度学习 PyTorch版
Transformer论文
李宏毅《机器学习》
Batch Norm详解之原理
李沐 Transformer论文逐段精读【论文精读】
Transformer、GPT、BERT,预训练语言模型的前世今生
2. 模型图
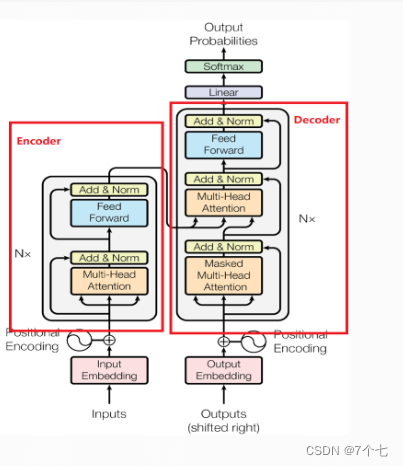
3.encoder部分
3.1 Positional Encoding
为了使模型利用序列的顺序,注入一些关于序列中标记的相对或绝对位置的信息。为此,我们在中的输入嵌入中添加“位置编码
3.2 Muti-Head Attention
首先先是用了Attention机制,key和value是等长的,具体的之前提到过,就不在多解释。
- 注意力机制,自注意力机制学习笔记
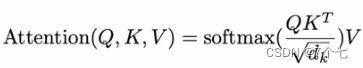
关于dk\sqrt{ d~k~ }d k 的解释:
当dk不大时,除或者不除都没什么影响。对于dk的大值,点积的幅度变大,softmax后最大的将更靠近1,最小的将更靠近0,也就是两极化严重,这样算梯度时梯度变化会过小。
Muti-Head:
作者对此的解释是与其做单个的自注意力函数,不如将q,k,v都投影到低维h次,然后再做h次的注意力函数,将得到h个结果contact一起,为了恢复原样再次进行一次线性变化。
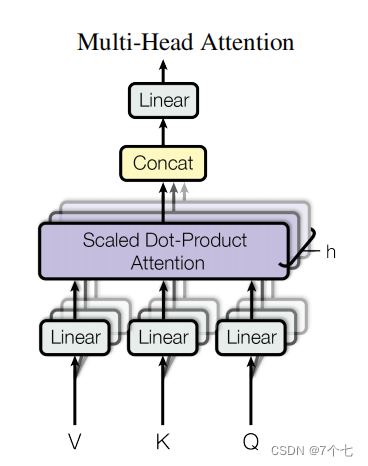
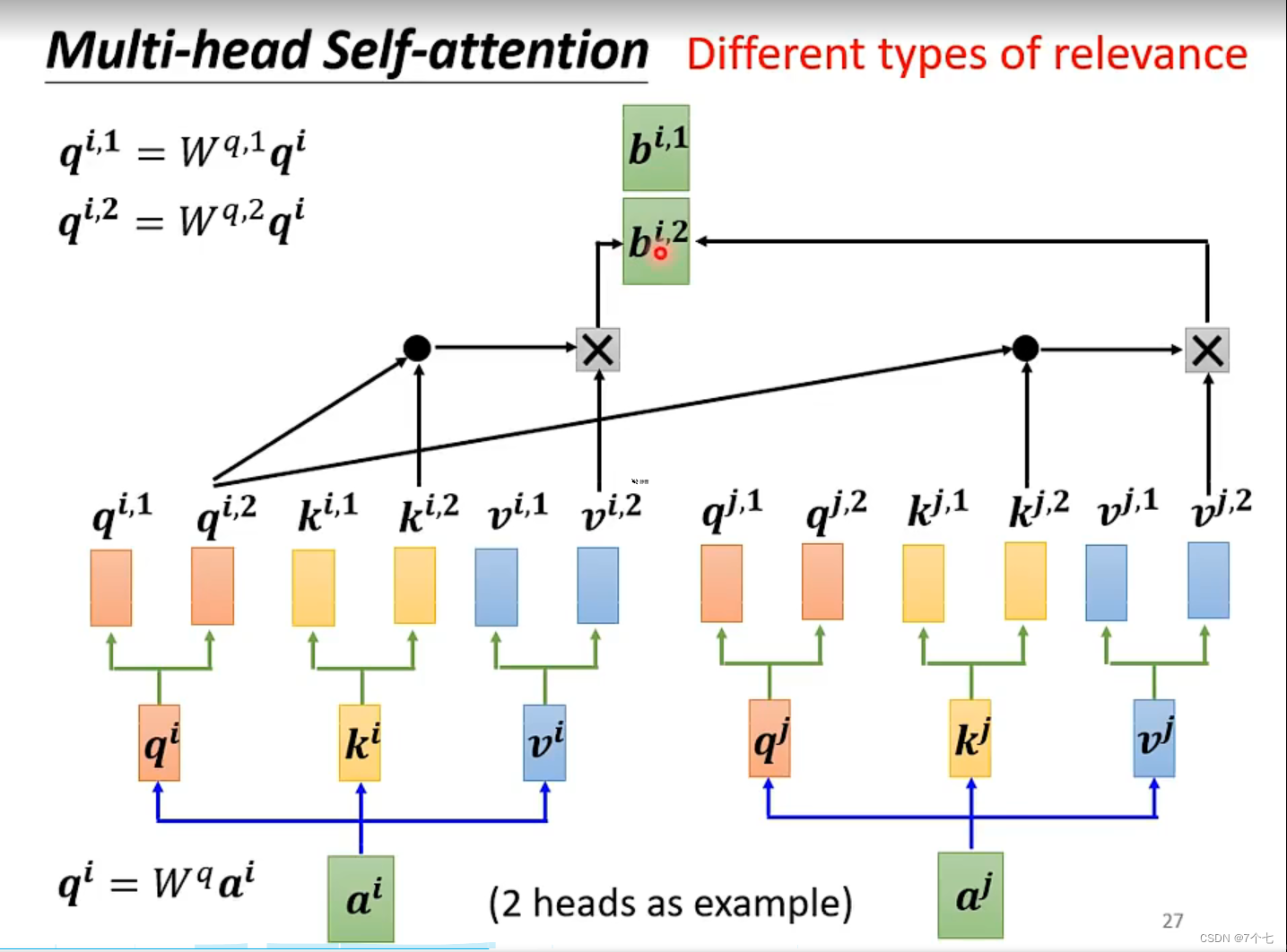

这样操作的原因是希望在h次投影机会中能够学到不同的取法能够适用于不同模式所需要的相似函数。
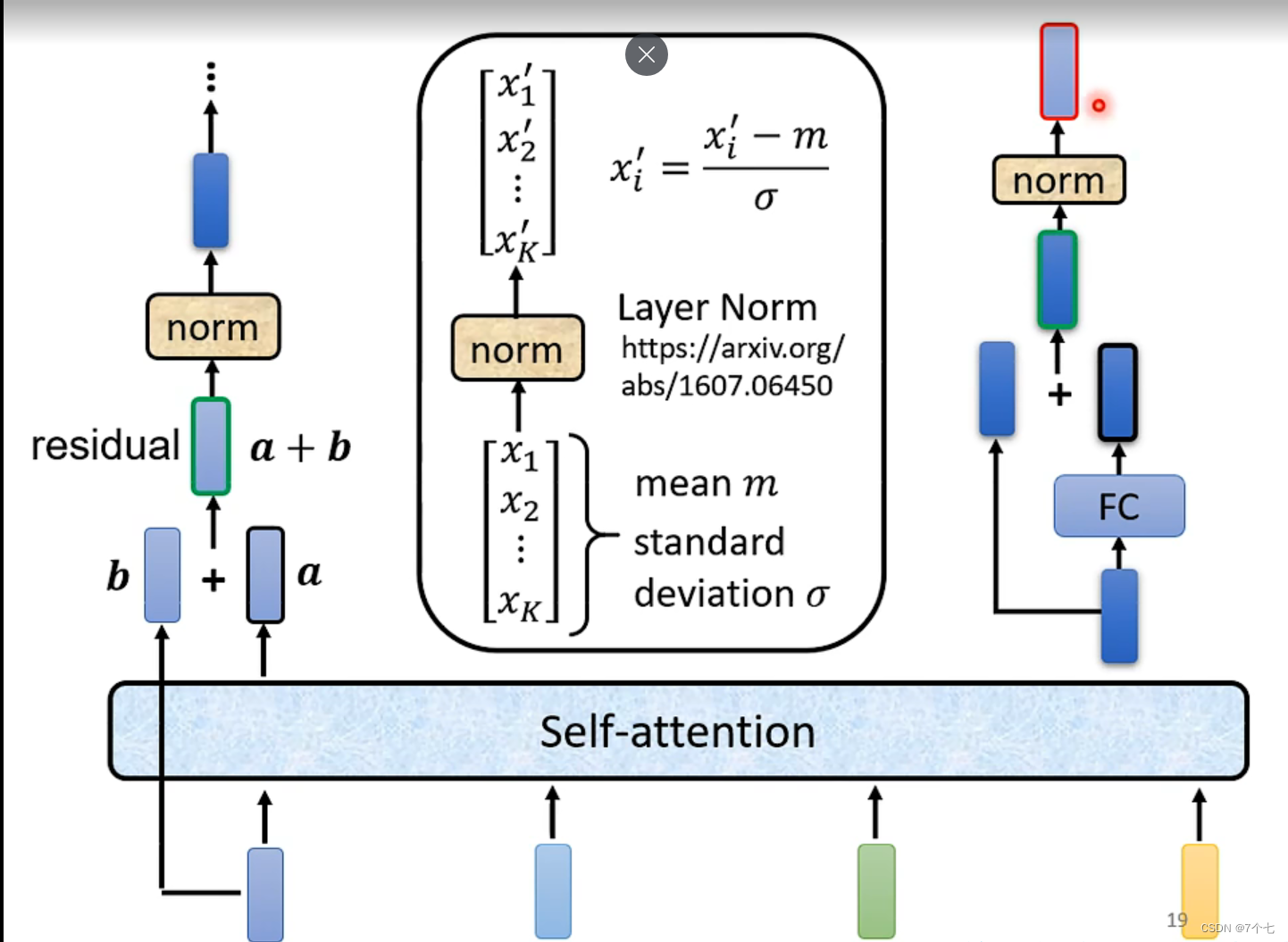
3.3 ADD–残差连接
这里加入了一个残差连接,论文原文中的公式为 LayerNorm(X + SubLayer(X))。至于残差连接的作用可以查阅下面文章
- resnet中的残差连接,你确定真的看懂了?
3.4 Norm标准化
Transformer里面用的是layerNorm而不是batchNorm,下面是batchNorm和layerNorm区别。假设只考虑二维输入情况下
- batchNorm,将不同batch的同一特征进行均值为0方差为1标准化(也可以均值为x,方差为y,这是可学习的)
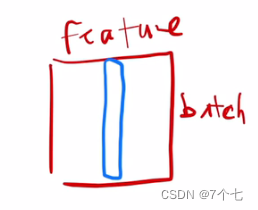
- layerNorm则对应同一样本来进行变换

拓展到batch,seq,feature上后,batchNorm是对不同batch,不同的seq,同一feature进行Norm,蓝色部分
而layerNorm是对不同seq,不同的feature,同一样本进行Norm(黄色)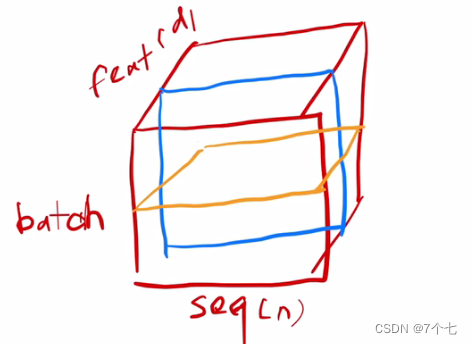
而之所以用layerNorm而不是batchNorm,解释原因是
每个样本seq长度不一定都是相同的,可能如下
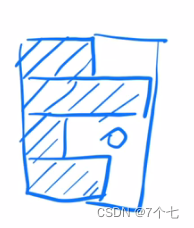
而且如果突然遇到特别长的seq,则之前的全局的均值和方差就不太适用,反观layerNorm,他是对每个样本自己来计算均值和方差

还有一种解释是layerNorm在梯度方面表现的比batchNorm较好,这里李沐老师没有细说。
3.5 单个Transformer Encoder流程图
4.decoder部分
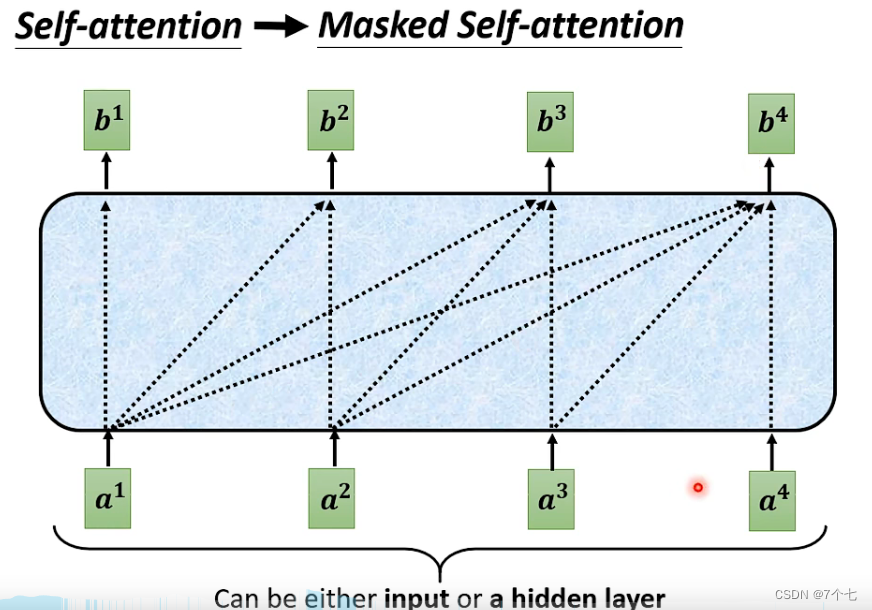
4.1 mask Muti-Head Attention
mask主要是为了避免在t时间时看到t+1后的东西,比如输出预测的时候,我们是按照上一个输出来预测下一个输出,这个输出之后的东西在实际情况下是不可知的。而attention机制要求看到全局数据,于是这里加了mask,实际上是将那些不能见的数据换成一个非常大的负数,这些数在进入softmax指数运算时会趋向0。
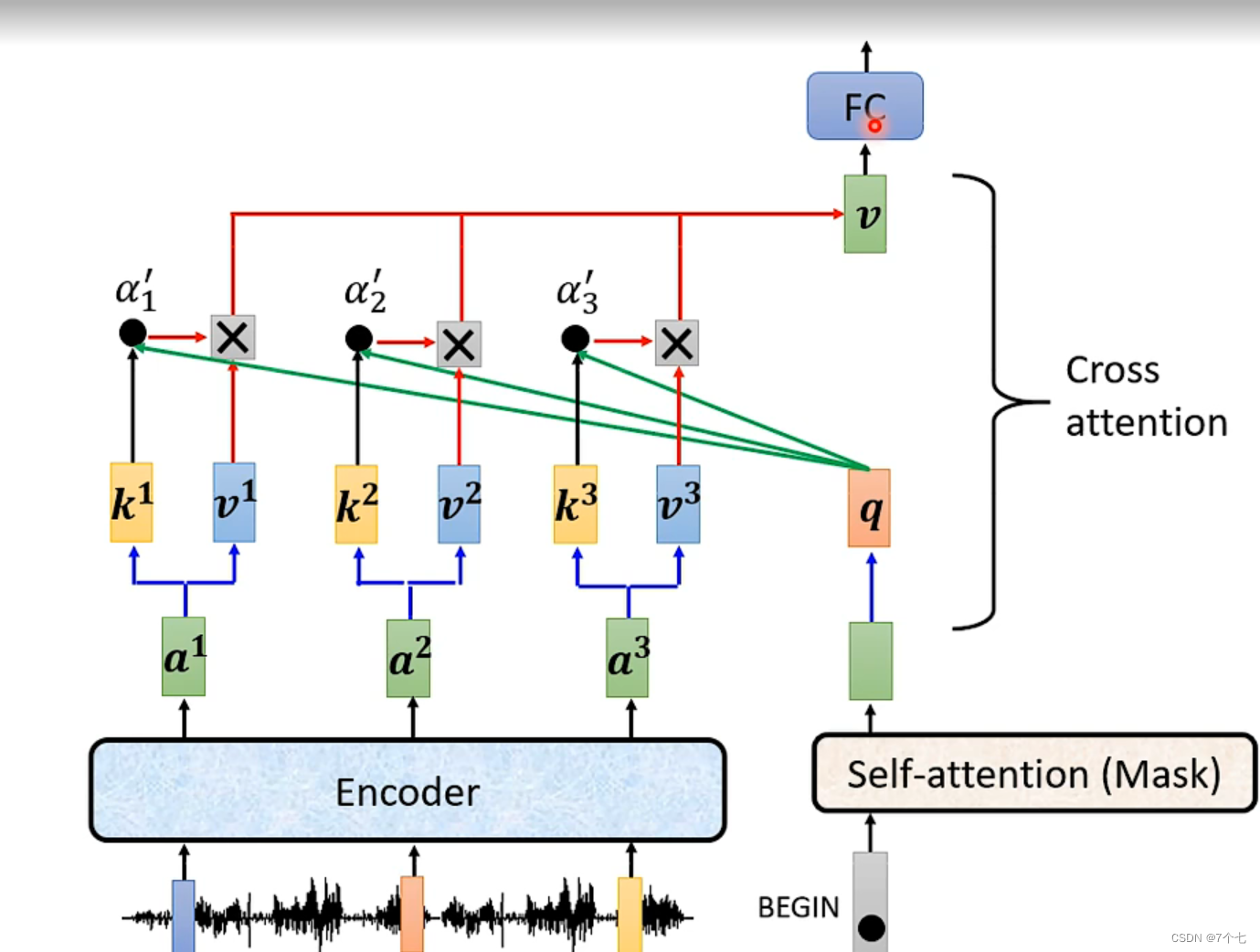
4.2 Muti-Head Attention
decoder的 Attention不是self Attention了,是cross Attention,key和value来自编码器的输出,query来自decoder中的mask Muti-Head Attention的输出。
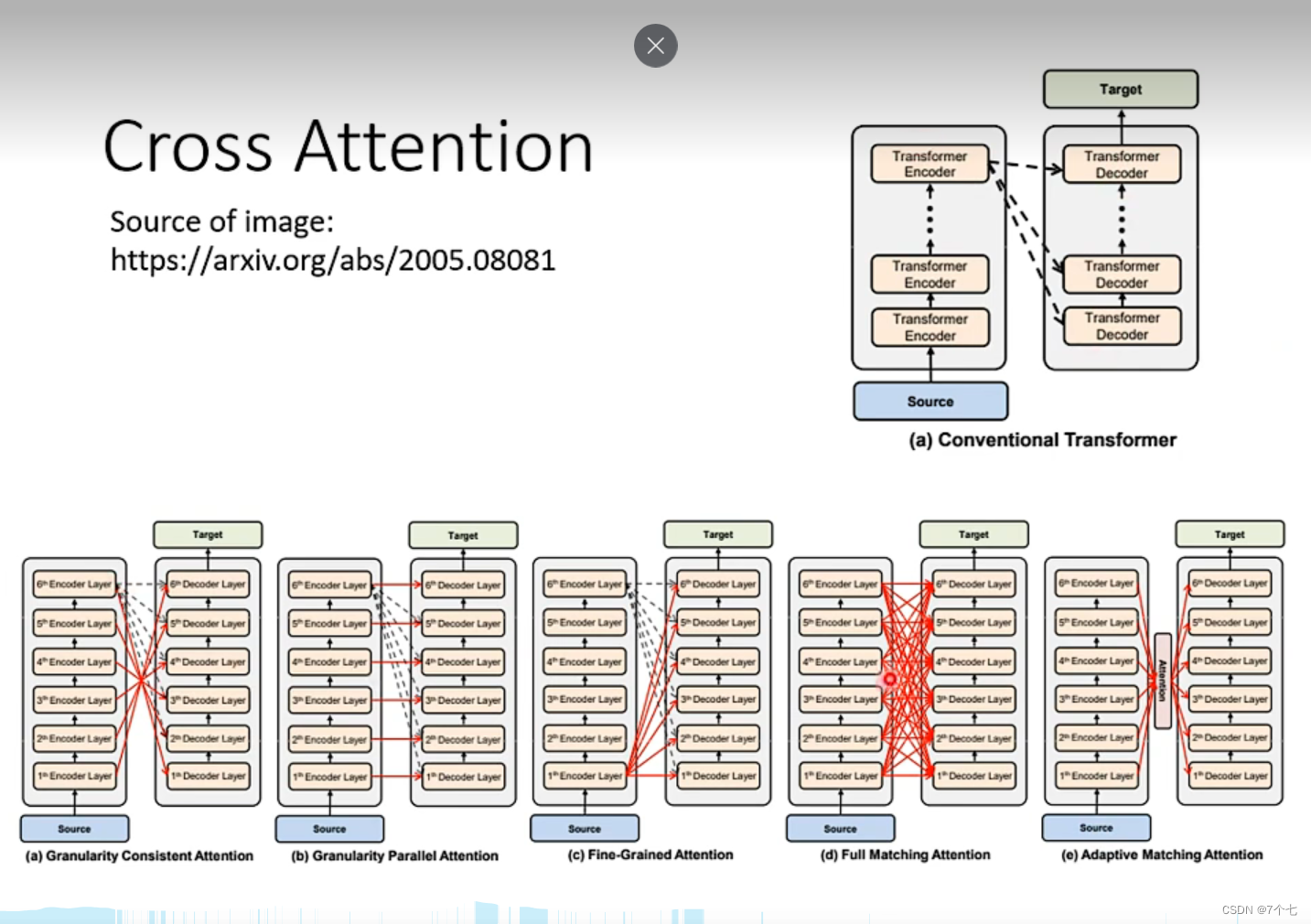
5 多个Transformer Encoder和多个Transformer Decoder连接方式
这里的连接方式有很多种,原论文用的是方式(a)
相关文章:
Transformer学习笔记
Transformer学习笔记1. 参考2. 模型图3.encoder部分3.1 Positional Encoding3.2 Muti-Head Attention3.3 ADD--残差连接3.4 Norm标准化3.5 单个Transformer Encoder流程图4.decoder部分4.1 mask Muti-Head Attention4.2 Muti-Head Attention5 多个Transformer Encoder和多个Tra…...
vue-cli引入wangEditor、Element,封装可上传附件的富文本编辑器组件(附源代码直接应用,菜单可调整)
关于Element安装引入,请参考我的另一篇文章:vue-cli引入Element Plus(element-ui),修改主题变量,定义全局样式_shawxlee的博客-CSDN博客_chalk variables 1、安装wangeditor npm i wangeditor --savewangE…...

移动办公时代,数智化平台如何赋能企业管理升级?
在传统的办公模式下,企业组织办公不仅时效低,周期长、成本高,且各办公系统相互独立。随着社会经济的发展,人们的工作生活变得多样化,对于办公的需求也越来越多,存在明显弊端的传统办公模式已不能满足企业对…...

2023“拼夕夕”为什么可以凭借简单的拼团做这么大?
2023“拼夕夕”为什么可以凭借简单的拼团做这么大? 2023-02-24 梦龙 大家好,我是你们熟悉而又陌生的好朋友梦龙,一个创业期的年轻人 大家都知道,拼夕夕背后的商业模式是拼团,但是大家知道为什么简单的拼团可以让拼夕…...
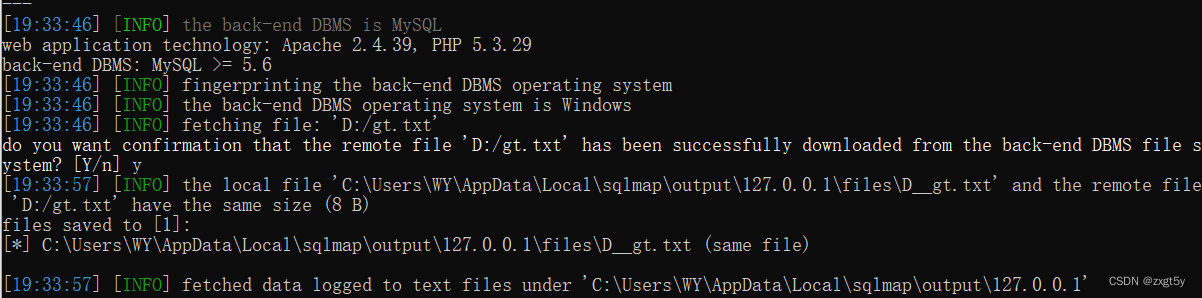
sqlmap工具
sqlmap Sqlmap是一个开源的渗透测试工具,可以用来自动化的检测,利用SQL注入漏洞,获取数据库服务器的权限。目前支持的数据库有MySQL、Oracle、PostgreSQL、Microsoft SQL Server、Microsoft Access等大多数据库 Sqlmap采用了以下5种独特的SQ…...
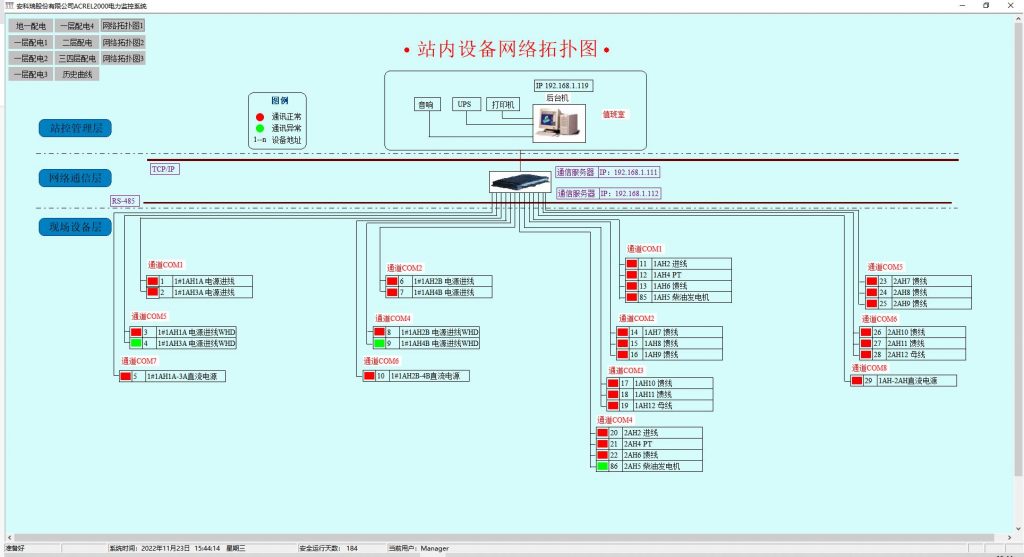
高/低压供配电系统设计——安科瑞变电站电力监控系统的应用
摘 要:在电力系统的运行过程中,变电站作为整个电力系统的核心,在保证电力系统可靠的运行方面起着至关重要的作用,基于此需对变电站监控系统的特点进行分析,结合变电站监控系统的功能需求,对变电站电力监控系…...
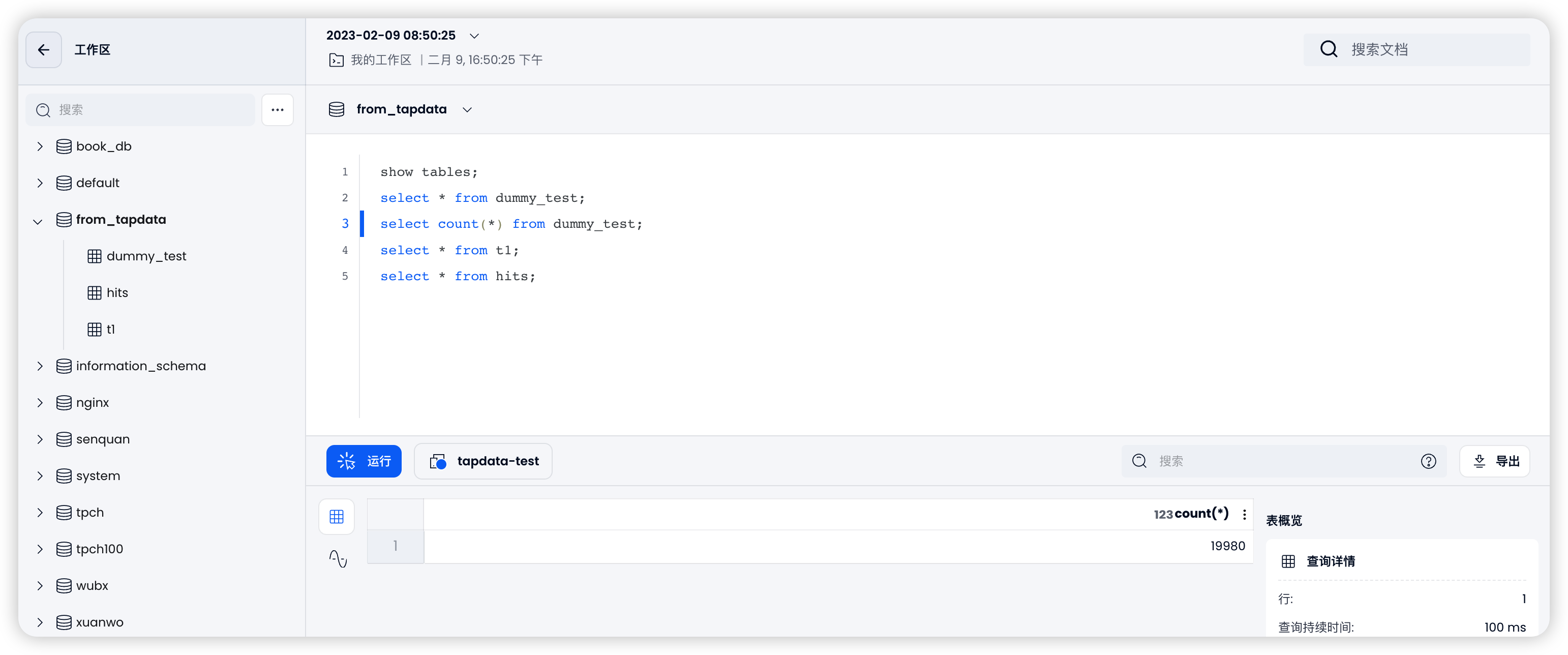
Tapdata 和 Databend 数仓数据同步实战
作者:韩山杰https://github.com/hantmacDatabend Cloud 研发工程师基础架构在云计算时代也发生着翻天地覆的变化,对于业务的支持变成了如何能利用好云资源实现降本增效,同时更好的支撑业务也成为新时代技术人员的挑战。 本篇文章通过…...
单核CPU, 1G内存,也能做JVM调优吗?
最近,笔者的技术群里有人问了一个有趣的技术话题:单核CPU, 1G内存的超低配机器,怎么做JVM调优?这实际上是两个问题。单核CPU的超低配机器,怎么充分利用CPU?单核CPU, 1G内存的超低配机器,怎么做J…...

《计算机应用研究》投稿经历和时间节点
记录四川计算机研究院《计算机应用研究》期刊投稿经历和时间节点。 日期状态周期2022.11.09上传稿件当天显示编辑部已接收稿件,开始初审2022.11.09 – 2022.11.15初审6天2022.11.15 – 2022.12.21外审36天2022.12.21收到退修意见(邮件形式)编…...
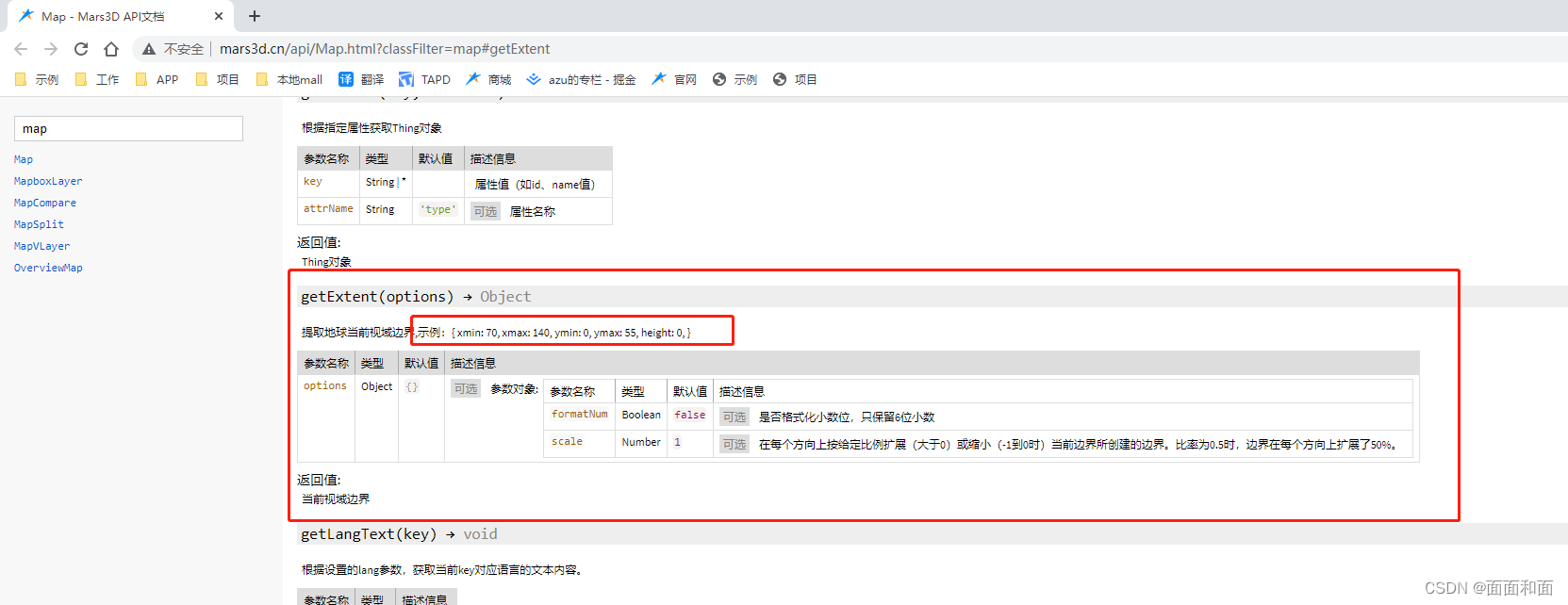
mars3d获取视窗的范围
期望效果 :1.我现在想获取到当前视窗的地图范围,请问有什么⽅法可以拿到吗 2.⽐如当前视窗地图范围的边界点,每个边界点的经纬度 回复:1.mars3d的API⽂档中有相关的⽅法 2.具体使⽤可以参考⽂档地址:http://mars3d.cn/api/Map.htm…...
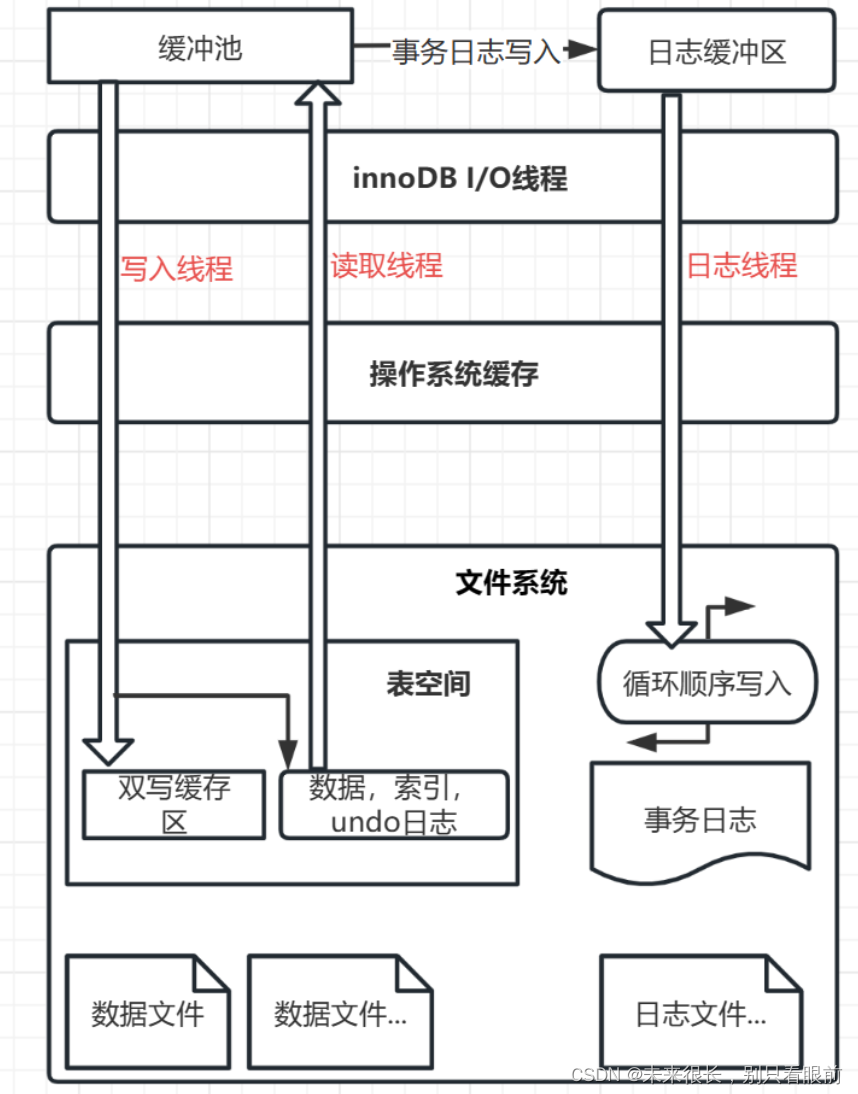
《高性能MySQL》读书笔记(上)
目录 MySQL的架构 MySQL中的锁 MySQL中的事务 事务特性 隔离级别 事务日志 多版本并发控制MVCC 影响MySQL性能的物理因素 InnoDB缓冲池 MySQL常用的数据类型以及优化 字符串类型 日期和时间类型 数据标识符 MySQL的架构 默认情况下,每个客户端连接都…...

05-代理模式
代理模式 代理模式使用代理对象来代替真实对象的访问,在不修改原有对象的前提下,提供额外的操作,扩展目标对象的功能。代理模式分为静态代理和动态代理。 静态代理 手动为目标对象中的方法进行增强,通过实现相同接口重写方法进…...

RocketMQ源码分析之消费队列、Index索引文件存储结构与存储机制-上篇
RocketMQ 存储基础回顾: 源码分析RocketMQ之CommitLog消息存储机制 本文主要从源码的角度分析 Rocketmq 消费队列 ConsumeQueue 物理文件的构建与存储结构,同时分析 RocketMQ 索引文件IndexFile 文件的存储原理、存储格式以及检索方式。RocketMQ 的存储…...
基于Java的浏览器的设计与实现毕业设计
技术:Java等摘要:当今世界是一个以计算机网络为核心的信息时代,互联网为人们快速获取、发布和传递信息提供了便捷,而浏览器作为互联网上查找信息的重要工具,给人们提供了巨大而又宝贵的信息财富,受到了大家…...
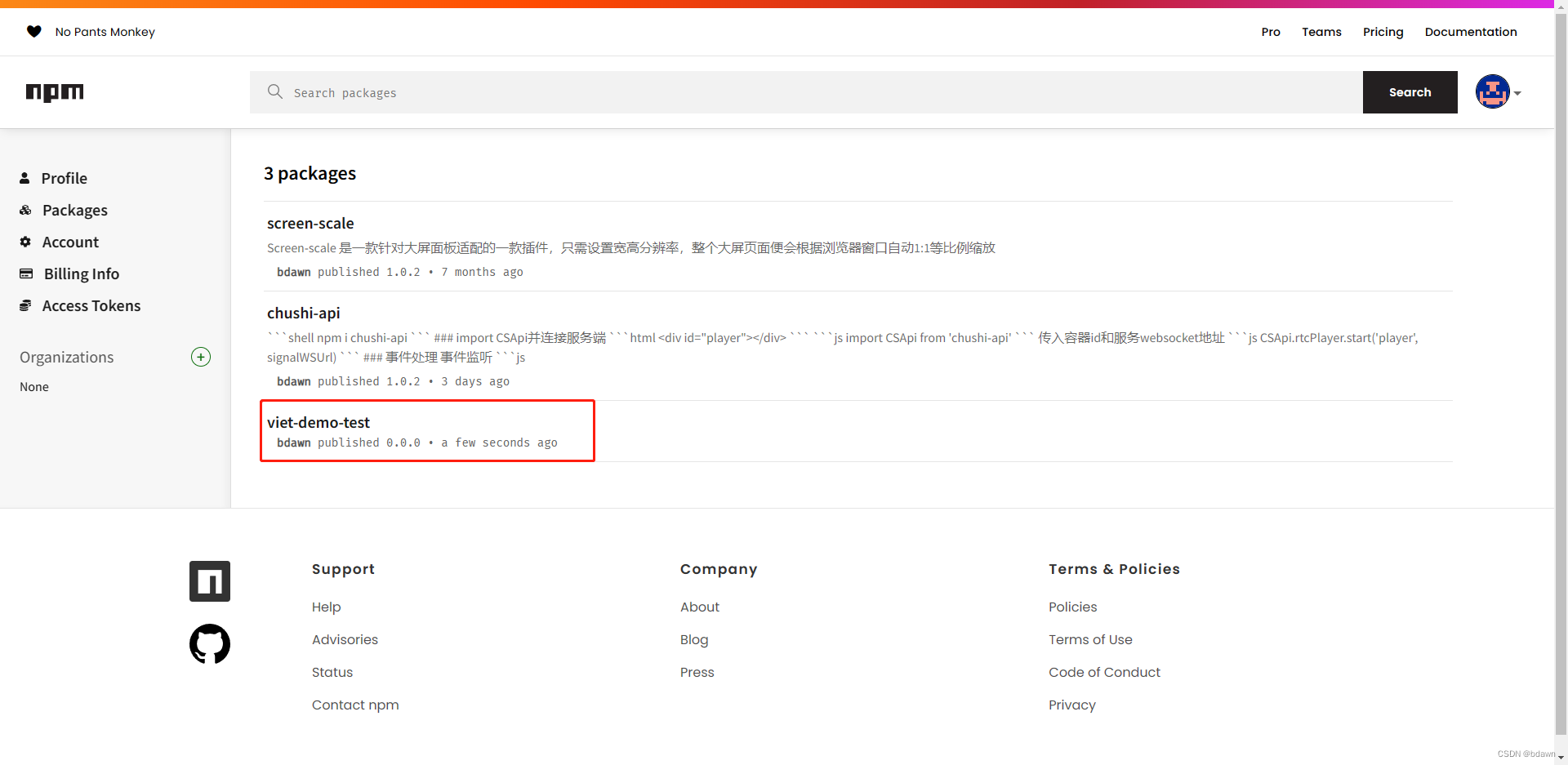
手把手教你使用vite打包自己的js代码包并推送到npm
准备 要有npm账号,没有的铁子去npm官网注册一个,又不要钱。 使用vite创建项目 一行代码搞定 npm create vite viet-demo框架选择Others 模板选择library 选择ts 这样项目就创建完了 这个项目默认有一个函数,用来记录按钮的点击次数并…...

Tomcat源码分析-关于tomcat热加载的一些思考
在前面的文章中,我们分析了 tomcat 类加载器的相关源码,也了解了 tomcat 支持类的热加载,意味着 tomcat 要涉及类的重复卸装/装载过程,这个过程是很敏感的,一旦处理不当,可能会引起内存泄露 卸载类 我们知…...
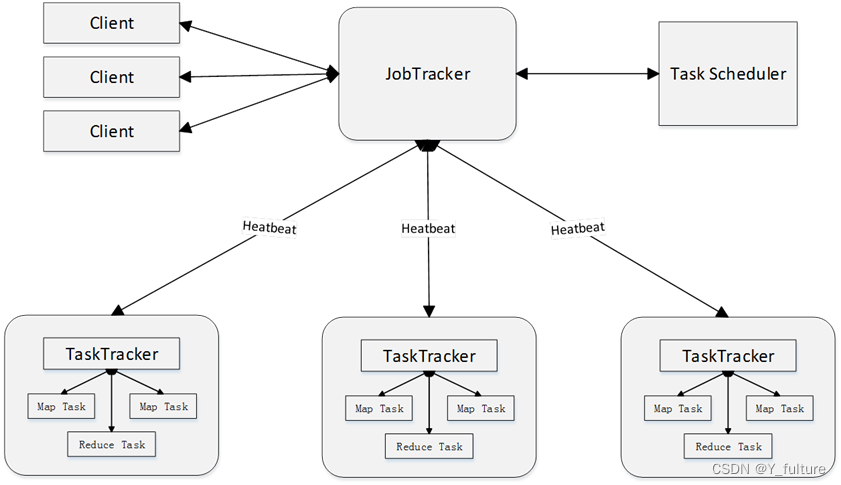
DataWhale 大数据处理技术组队学习task4
五、分布式并行编程模型MapReduce 1. 概述 1.1 分布式并行编程 背景:摩尔定律已经开始逐渐失效,提升数据处理计算能力刻不容缓。传统的程序开发与分布式并行编程 传统的程序开发:以单指令、单数据流的方式顺序执行,虽然这种方式…...

Oracle 12C以上统计信息收集CDB、PDB执行时间不一致问题
文章目录前言一、统计信息窗口期调查二、时区调查三、查询alert记录四、why Database Statistic Collection Job is running two times inside a Maintenance Window?五、Default Scheduler Timezone Value In PDB$SEED Different Than CDB六、总结前言 在实际工作中发现一个…...
用Python获取弹幕的两种方式(一种简单但量少,另一量大管饱)
前言 弹幕可以给观众一种“实时互动”的错觉,虽然不同弹幕的发送时间有所区别,但是其只会在视频中特定的一个时间点出现,因此在相同时刻发送的弹幕基本上也具有相同的主题,在参与评论时就会有与其他观众同时评论的错觉。 在国内…...

算法训练营 day55 动态规划 买卖股票问题系列3
算法训练营 day55 动态规划 买卖股票问题系列3 最佳买卖股票时机含冷冻期 309. 最佳买卖股票时机含冷冻期 - 力扣(LeetCode) 给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格 。 设计一个算法计算出最大利润。在满足以下…...

量子计算中的Jacobi-Davidson方法原理与应用
1. 量子计算中的Jacobi-Davidson方法概述量子计算为解决复杂量子系统的基态和激发态能量计算问题提供了新的可能性。在经典计算中,Jacobi-Davidson(JD)方法因其高效的子空间迭代特性而广受推崇。当我们将这一方法移植到量子计算框架下时,它展现出了更强大…...

机器学习与模拟退火算法优化TPMS结构材料力学性能
1. 项目概述与核心价值在材料科学与先进制造领域,三周期极小曲面(Triply Periodic Minimal Surfaces, TPMS)结构正掀起一场设计革命。这类结构以其在三维空间内周期性重复、且具有极小表面积的特点,展现出传统实体材料难以企及的优…...

医疗AI公平性评估:从数据复杂性到系统任意性的三支柱分析框架
1. 项目概述:当医疗AI遇上公平性拷问在医疗健康领域,机器学习模型正从实验室的“概念验证”阶段,大步迈向临床决策支持的“实战”前线。无论是预测糖尿病风险,还是辅助诊断心脏病,这些算法模型的核心承诺是:…...

SuperCam:从源头减量的超像素传感器,重塑边缘视觉感知范式
1. 项目概述:为什么我们需要一种直接输出超像素的传感器?在计算机视觉领域,我们早已习惯了与像素打交道。无论是手机拍照、视频监控,还是自动驾驶的感知模块,其底层数据都源于一个由数百万乃至上亿个正方形像素点构成的…...

【Claude学术写作辅助应用】:教育部新文科AI赋能白皮书唯一推荐工具,附12所双一流高校实证数据
更多请点击: https://intelliparadigm.com 第一章:Claude学术写作辅助应用的政策定位与战略价值 Claude作为新一代大语言模型,在学术写作辅助领域已超越工具属性,成为支撑国家科研诚信建设、高等教育数字化转型与国际学术话语权提…...

WxJava 微信开发包 - 新手入门指南
WxJava 微信开发包 - 新手入门指南项目概览项目名称Binary Wang/WxJavaStarsGVP ⭐⭐⭐⭐⭐组织Binary Wang语言Java标签GVP, Java, 微信开发, 微信公众号, 微信支付项目简介WxJava 是一个基于 Java 的微信开发工具包,支持微信公众号、微信支付、小程序、企业微信等…...

感知机为什么必须加偏置?从数学本质到工程落地全解析
1. 为什么感知机神经元必须带偏置输入?——从数学本质到工程实践的全链路拆解“Why Perceptron Neurons Need Bias Input?” 这个标题看似简单,实则直击人工神经网络最基础却最容易被忽略的底层设计逻辑。我在带高校AI实验课、指导工业界图像分类项目落…...
)
别再让‘自己’说话了:用ZEGO SDK搞定RTC通话中的回声消除(附实战避坑清单)
从工单到解决方案:ZEGO SDK回声消除实战指南 1. 回声问题排查:从用户反馈到技术定位 "为什么每次通话对方都能听到自己的声音?"——这是开发者后台最常见的一类工单。不同于理论探讨,真实场景中的回声问题往往伴随着模糊…...

收藏!2026 程序员破局:Java 寒冬已至,大模型才是真风口
凌晨一点半,手机屏幕突然亮起,是做Java后端开发的发小发来的消息,字里行间全是慌乱与不甘:“刚收到公司裁员通知,名单已经定死了,我真的懵了——部门里干了五年的资深老程都没保住,我这三年经验…...

免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力
免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/…...