JDK1.8对HashMap的优化、以及通过源码解析1,8扩容机制
JDK 1.8 对 HashMap 进行了一些优化,主要包括以下几个方面的改进:
-
红黑树:在 JDK 1.8 中,当哈希碰撞(多个键映射到同一个桶)达到一定程度时,HashMap 会将链表转化为红黑树,以提高查找、插入和删除操作的性能。这个改进在处理大规模数据时特别有用,因为红黑树的复杂度为 O(log n)。
-
桶的树化和解树化:HashMap 在桶的树化和解树化过程中进行了优化,以提高性能。桶的树化指的是当链表长度达到一定阈值时,将链表转换为红黑树;而桶的解树化指的是当红黑树的节点数小于一定阈值时,将红黑树恢复成链表。这些优化可以减少树化和解树化的开销。
-
负载因子:在 JDK 1.8 中,负载因子默认值变为 0.75。负载因子表示在什么情况下 HashMap 应该进行扩容,这个值的选择可以影响性能和空间利用率。0.75 是一个折衷的选择,可以降低哈希冲突的可能性,同时也不会浪费太多内存。
-
扩容机制:JDK 1.8 中对 HashMap 的扩容机制进行了优化。在1.8之前,扩容时,会将每个元素都进行重新Hash,再放入到新的桶中。1.8之后是怎么做的呢?
首先我们需要明确,HashMap中的Table是什么。
在HashMap源码中:
/*** The table, initialized on first use, and resized as* necessary. When allocated, length is always a power of two.* (We also tolerate length zero in some operations to allow* bootstrapping mechanics that are currently not needed.)*/transient Node<K,V>[] table;table就是一个数组,每一个元素相当于一个桶,我们通过Node可以遍历出桶中的所有元素。
继续看看HashMap的源码:
先找到put方法:
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
在n = (tab = resize()).length;表示,每一次put都要就行扩容操作。
源码中对resize()的说明:
Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold. Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move with a power of two offset in the new table.
Returns:
the table
初始化或加倍表大小。
如果为空,则根据字段阈值中保持的初始容量目标进行分配。
否则,因为我们使用的是二次幂展开,所以每个bin中的元素必须保持在同一索引处,或者在新表中以二次幂偏移量移动。
当我们的HashMap不为空时,我们就需要判断是否要进行扩容。
那么什么时候需要扩容呢?
在HashMap中定义了一个值:threshold 原文注释:The next size value at which to resize (capacity * load factor).,即现在的容量乘上负载因子(默认0.75)时扩容。
超过阀值一定扩容吗
if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}
可以指导,如果原先的容量已经是大于等于最大容量了,则HahMap不可以再扩,阀值threshold也变为 了小大整数不可以被超越。
如何扩容
当满足所有条件后,终于可以扩容了。
newThr = oldThr << 1; // double threshold
将新的阀值扩展为原先的两倍。在之后的代码中再将threshold更改为newThr即可。
在此之前都是对数值的修改,从这之后才是正式的扩容操作:
首先创建出新的table:
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;
当然,再次之前,老table的值已经保存在了oldTab中:
Node<K,V>[] oldTab = table;
之后是将oldTab数据转移到table的操作:
当oldTab不为空,则遍历oldTab
for (int j = 0; j < oldCap; ++j) {Node<K,V> e; // 从旧哈希表中获取当前索引位置的节点if ((e = oldTab[j]) != null) { // 如果节点不为空oldTab[j] = null; // 将旧哈希表中当前索引位置置为空便于垃圾回收// 如果节点没有下一个节点,将其直接放入新哈希表if (e.next == null)//最后一个节点newTab[e.hash & (newCap - 1)] = e;//目的是为将e散列,减少hash冲突,从而减少计算// 如果节点属于树节点(红黑树节点),调用split方法进行处理else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // 保持节点顺序Node<K,V> loHead = null, loTail = null; // 低位链表的头和尾Node<K,V> hiHead = null, hiTail = null; // 高位链表的头和尾Node<K,V> next;do {next = e.next;// 根据节点的哈希值与旧容量的与运算结果,将节点分到低位或高位链表if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 将低位链表的头部节点放入新哈希表if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 将高位链表的头部节点放入新哈希表if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}
}接下来我们对可能对可能发生的三种情况进行说明
e.next == null时,可以看到只有一步操作:newTab[e.hash & (newCap - 1)] = e;,将e的值通过e的哈希值与新容量的与操作从而得到e在新table中的位置,这个目的是为了让值更加的零散、而不是保持在原来的位置。(由于值的数量是增多的,如果还是继续保留在原来的位置,那么哈希碰撞是难以避免的)e instanceof TreeNode时,表示这个桶是TreeNode类型的,是一个红黑链表(红黑数组的特性在我的博客中也有提到:红黑树与B+树),红黑树split拆分操作的目的是防止红黑树变得过深,要把一颗红黑树拆成两棵,并继续分散塞到新Table中去。- else中,则表示这个节点是链表节点,和红黑树的split类似,这个操作也是为了链表过深,从而拆成了lo和hi两段。
- 并发性能:JDK 1.8 通过引入分段锁(Segment)来提高 HashMap 在多线程环境下的并发性能。每个 Segment 就是一个独立的 HashMap,只锁定其中一个 Segment 而不是整个 HashMap,这减少了锁的争用,提高了并发性能。
这些优化使得 JDK 1.8 中的 HashMap 在处理大规模数据和多线程环境下表现更好,同时也减少了哈希碰撞的影响,提高了性能和稳定性。然而,需要注意的是,具体的实现可能因不同的 JDK 版本而有所不同,因此在选择和使用 HashMap 时需要考虑 JDK 版本的影响。
相关文章:

JDK1.8对HashMap的优化、以及通过源码解析1,8扩容机制
JDK 1.8 对 HashMap 进行了一些优化,主要包括以下几个方面的改进: 红黑树:在 JDK 1.8 中,当哈希碰撞(多个键映射到同一个桶)达到一定程度时,HashMap 会将链表转化为红黑树,以提高查找…...

Linux串口断帧处理
报文格式 1 Byte 4 Byte N Byte 4 Byte 1 Byte 0x02 报文长度 报文 CRC16 0x03 1. 每条报文以 STX(0x02)起始符开始,以 ETX(0x03)终止符结束。 2. 报文正文长度采用 4 字节的 10 进制字符串标识,如报文正…...
springboot集成kafka
1、引入依赖 <dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.8.6</version></dependency> 2、配置 server:port: 9099 spring:kafka:bootstrap-servers: 192.1…...

近期总结2023.10.16
规律 1.两数相减,相加的最大,最小值 2.由最初的状态递推 3.无强制顺序,排序,不能排序,则与顺序有关 4.对于一段等差数列,不用一段一段的算局部整体,可以从整体一步步加差值 5.需要从一段式子推到结果困难&…...

【EI会议征稿】第二届可再生能源与电气科技国际学术会议(ICREET 2023)
第二届可再生能源与电气科技国际学术会议(ICREET 2023) 2023 2nd International Conference on Renewable Energy and Electrical Technology 2020年中国可再生能源发电规模显著扩大,风力和太阳能发电均呈迅速增长趋势。中国大力推进能源低碳化,减少温…...

让ChatGPT等模型学会自主思考!开创性技术“自主认知”框架
ChatGPT、百度文心一言、Bard等大语言模型展现出了超强的创造能力,加速了生成式AI的应用进程。但AI模型只能基于训练数据执行各种任务,无法像人类一样利用生活知识、过往经验用于复杂的推理和决策。 例如,在玩游戏时,人类可以利用…...

Jmeter脚本参数化和正则匹配
我们在做接口测试过程中,往往会遇到以下几种情况 每次发送请求,都需要更改参数值为未使用的参数值,比如手机号注册、动态时间等 上一个接口的请求体参数用于下一个接口的请求体参数 上一个接口的响应体参数用于下一个接口的请求体参数&#…...

vue 请求代理 proxy
目录 为什么需要配置代理 什么是同源策略 如何配置代理 请求代理的原理 举例说明 为什么需要配置代理 因为浏览器的同源策略,当向和本地 devServer 服务器不同源的地址发送请求, 会违反浏览器的同源策略,导致发送失败,所以需…...

使用Spring Boot构建稳定可靠的分布式爬虫系统
摘要:本文将介绍如何使用Spring Boot框架构建稳定可靠的分布式爬虫系统。我们将从系统设计、任务调度、数据存储以及容灾与故障恢复等方面进行详细讲解,帮助读者理解并实践构建高效的分布式爬虫系统。 1. 引言 随着互联网的快速发展,爬虫系…...
分享一个查询OpenAI Chatgpt key余额查询的工具网站
OpenAI Key 余额查询工具 欢迎使用 OpenAI Key 余额查询工具网站!这个工具可以帮助您轻松地验证您的 OpenAI API 密钥,并查看您的余额。 http://tools.lbbit.top/check_key/ 什么是 OpenAI Key 余额查询工具? OpenAI Key 余额查询工具是一…...

【LeetCode刷题(数据结构与算法)】:二叉树的后序遍历
给你一棵二叉树的根节点root 返回其节点值的后序遍历 示例 1: 输入:root [1,null,2,3] 输出:[3,2,1] 示例 2: 输入:root [] 输出:[] 示例 3: 输入:root [1] 输出:[1]…...
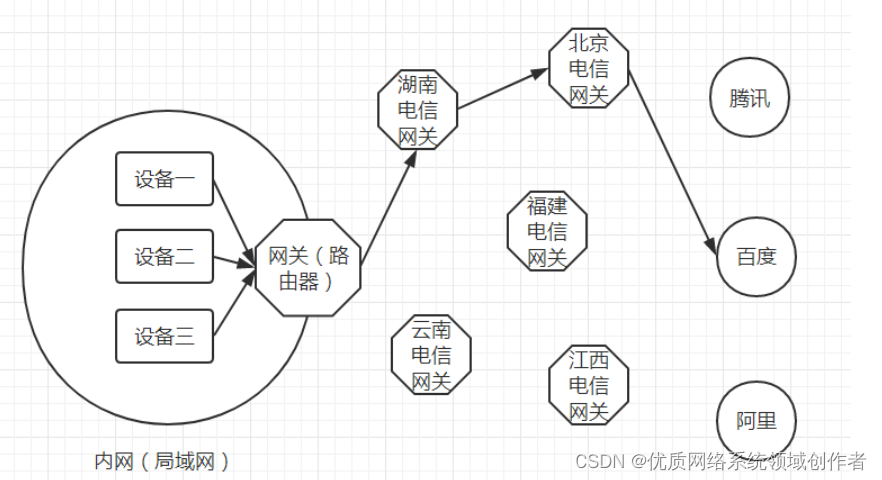
内网、外网、宽带、带宽、流量、网速之间的区别与联系
一.带宽与宽带的区别是什么? 带宽是量词,指的是网速的大小,比如1Mbps的意思是一兆比特每秒,这个数值就是指带宽。 宽带是名词,说明网络的传输速率速很高 。宽带的标准各不相同,最初认为128kbps以上带宽的就…...
打造类ChatGPT服务,本地部署大语言模型(LLM),如何远程访问?
ChatGPT的成功,让越来越多的人开始关注大语言模型(LLM)。如果拥有了属于自己的大语言模型,就可以对其进行一些专属优化。例如:打造属于自己的AI助理,或是满足企业自身的业务及信息安全需求。 所以ÿ…...

linux平台的无盘启动开发
by fanxiushu 2023-10-15 转载或引用请注明原始作者。 前一章节介绍的是linux平台下的虚拟磁盘驱动开发过程,主要讲述了 基于block的磁盘和基于SCSI接口的磁盘。 本文介绍的内容正是基于上文中的SCSI接口的虚拟磁盘实现的无盘启动。 同样的,linux系统下也…...
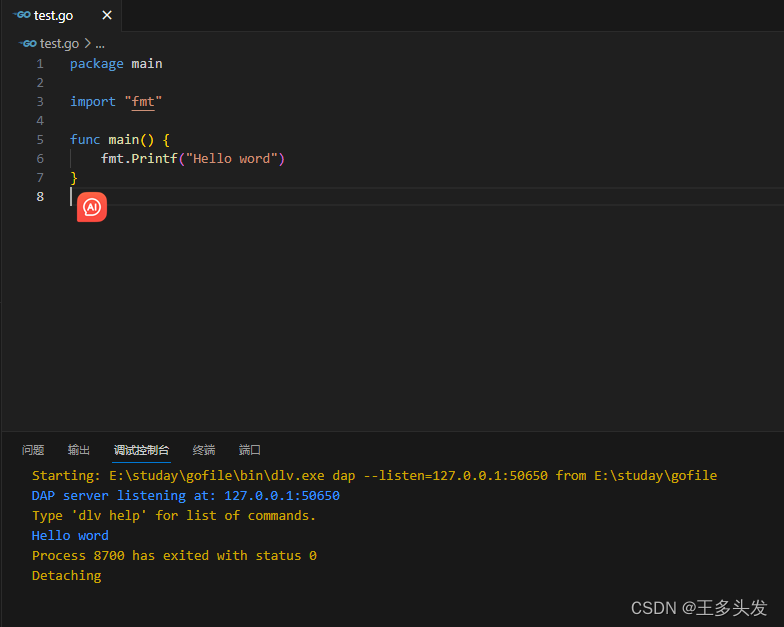
【GO入门】环境配置及Vscode配置
1 GO环境配置 欢迎来到Go的世界,让我们开始探索吧! Go是一种新的语言,一种并发的、带垃圾回收的、快速编译的语言。它具有以下特点: 它可以在一台计算机上用几秒钟的时间编译一个大型的Go程序。Go为软件构造提供了一种模型&…...
家政服务小程序,家政维修系统,专业家政软件开发商;家政服务小程序,家政行业软件开发
家政服务小程序,家政维修系统,专业家政软件开发商; 家政服务小程序,家政行业软件开发解决方案,家政软件经验丰富实践,系统高度集成,提供师傅端、用户端、… 家政服务app开发架构有 1、后台管理端…...

英语——语法——从句——状语从句——笔记
一、概念 状语从句(Adverbial Clause)是指句子用作状语时,起副词作用的句子。状语从句中的从句可以修饰谓语。 状语从句根据其作用可分为时间、地点、原因、条件、目的、结果、让步、方式和比较等九 种状语从句。状语从句一般由连词(从属连词…...

Linux 学习的六个过程
Linux 上手难,学习曲线陡峭,所以它的学习过程更像一个爬坡模式。这些坡看起来都很陡,但是一旦爬上一阶,就会一马平川。 1、抛弃旧的思维习惯,熟练使用 Linux 命令行 在 Linux 中,无论我们做什么事情&…...

『heqingchun-ubuntu系统下安装nvidia显卡驱动3种方法』
ubuntu系统下安装nvidia显卡驱动3种方法 一、安装依赖 1.更新 sudo apt updatesudo apt upgrade -y2.基础工具 sudo apt install -y build-essential python图形界面相关 sudo apt install -y lightdm注:在弹出对话框选择"lightdm" 二、第一种:使用…...

[paddle]paddleseg中eiseg加载模型参数的模型下载地址
图片标注 以下内容为2D图片标注模型下载及EISeg2D图片标注流程,具体如下: 模型准备 在使用EISeg前,请先下载模型参数。EISeg开放了在COCOLVIS、大规模人像数据、mapping_challenge,Chest X-Ray,MRSpineSegÿ…...

GEO优化实操框架:GEO优化的正确姿势是“带着答案去找客户”
如果你是B2B企业的老板或市场负责人,你一定听过这句话: “我们网上曝光是不少,但来的询盘都不对——问价格的比问方案的还多,还有不少是学生做调研的。” 这不是你一个人遇到的问题。这是传统SEO和竞价广告的天然缺陷——你只能“…...
)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码) 在嵌入式系统开发中,电压采样是基础却至关重要的环节。许多工程师在使用STM32或DSP内置ADC时,常会遇到精度不足、抗干扰能力差、无法测量差分信…...

从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧
从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧 在射频模块或高精度ADC供电设计中,电源的纯净度直接决定系统性能上限。当输出电压纹波超出ADC的LSB范围,或EMI噪声耦合到敏感信号链时,工程师往往需要重新审视D…...

Nix构建确定性AI编程环境:解决Cursor编辑器依赖冲突难题
1. 项目概述:当代码编辑器遇上Nix的确定性魔法 最近在折腾开发环境时,我遇到了一个老生常谈但又无比头疼的问题:团队里新来的同事怎么也跑不起来我本地运行得好好的一个代码辅助工具链。依赖版本冲突、系统库路径不对、甚至是因为他用的macO…...

实战指南:用UABEA高效解析Unity资源结构的5个关键要点
实战指南:用UABEA高效解析Unity资源结构的5个关键要点 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity开发的世界里,资源管理往往是项目优化中最棘手的一环。你是否曾经…...

AI助手API开发资源全指南:从入门到实战的宝藏清单
1. 项目概述:一个为AI助手API开发者量身打造的“藏宝图”如果你正在或打算基于OpenAI的Assistant API、Anthropic的Claude API,或是其他主流AI平台的助手接口来构建应用,那么你大概率会遇到一个经典困境:官方文档虽然详尽…...

脉冲神经网络与神经形态计算的能效优化实践
1. 脉冲神经网络与神经形态计算基础脉冲神经网络(SNN)作为第三代神经网络模型,其核心在于模拟生物神经系统的信息处理机制。与传统人工神经网络(ANN)相比,SNN具有三个本质区别:首先,…...

基于语义搜索的AI代码理解工具copaw-code深度解析
1. 项目概述:一个面向代码搜索与理解的AI工具 最近在GitHub上看到一个挺有意思的项目,叫 QSEEKING/copaw-code 。乍一看这个标题,可能会有点摸不着头脑,“copaw”是什么?但结合“code”和项目托管在QSEEKING这个组织…...

WipperSnapper+Adafruit IO:无代码物联网开发实战,从传感器到云端自动化
1. 项目概述与核心价值如果你和我一样,在物联网(IoT)项目初期,常常被复杂的嵌入式编程、网络协议和云平台对接搞得焦头烂额,那么今天分享的这个实战项目,或许能让你眼前一亮。我们这次不谈复杂的代码&#…...

构建个人技能库:用GitHub+Markdown打造开发者的第二大脑
1. 项目概述:从“我的Copaw技能”看个人技能库的构建与管理最近在GitHub上看到一个挺有意思的项目,叫“my-copaw-skill”。这个项目名本身就很有故事感,“Copaw”这个词,我猜是“Code”和“Paw”(爪子)的结…...