如何实现 Es 全文检索、高亮文本略缩处理(封装工具接口极致解耦)
如何实现 Es 全文检索、高亮文本略缩处理
- 前言
- 技术选型
- JAVA 常用语法说明
- 全文检索开发
- 高亮开发
- Es Map 转对象使用
- 核心代码 Trans 接口(支持父类属性的复杂映射)
- Trans 接口可优化的点
- 高亮全局配置类如下
- 真实项目落地效果
- 为什么不用 numOfFragments、fragmentSize 参数控制略缩?
- 结语
前言
最近手上在做 Es 全文检索的需求,类似于百度那种,根据关键字检索出对应的文章,然后高亮显示,特此记录一下,其实主要就是处理 Es 数据那块复杂,涉及到高亮文本替换以及高亮字段截取,还有要考虑到代码的复用性,是否可以将转换代码抽离出来,提供给不同结构的索引来使用。
技术选型
像市面上有的 Spring Data,码云上面的 GVP 项目 (EasyEs)等其他封装框架。使用起来确实很方便,但是考虑到由于开源项目的不稳定性且 Es 不同版本间语法差异比较大,还有一方面是公司之前用的一直是 Es 6,后续可能会涉及到 Es 的升级改造,于是决定使用原生的 Api。也就是使用 RestHighLevelClient。
JAVA 常用语法说明
查时间范围内的数据 BoolQuery 里面嵌套一个 RangeQuery 即可在RangeQuery 里面指定时间范围。BoolQuery.must() 各位理解为 Mybatis 中的 eq 方法即可,必须包含的意思。
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery(articleRequest.getSortType());if (StringUtils.isNotEmpty(articleRequest.getBeginTime())) {rangeQuery.gte(articleRequest.getBeginTime());}if (StringUtils.isNotEmpty(articleRequest.getEndTime())) {rangeQuery.lte(articleRequest.getEndTime());}boolQuery.must(rangeQuery);
BoolQuery.should() 方法可以理解为 OR 可包含可不包含,多字段全文检索时应用 shoud。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));
termsQuery 字符精确匹配
QueryBuilders.termsQuery()
字符短句匹配,字符不会进行分词
QueryBuilders.matchPhraseQuery()
分词匹配
QueryBuilders.multiMatchQuery()
分词匹配加高亮对应 EQ(Es 的Sql,我自己给他取的名字!!!!)
GET /articlezzh/_doc/_search
{"from": 0,"size": 20,"query": {"bool": {"must": [{"multi_match": {"query": "你的购物节","fields": ["title","author","body"]}}]}},"highlight": {"pre_tags": ["<em style='color: red'>"],"post_tags": ["</em>"],"fields": {"body":{},"author":{}}}
}
全文检索开发
核心代码如下
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();if (StringUtils.isNotEmpty(articleRequest.getKeyword())) {for (int i = 0; i < articleRequest.getKeys().length; i++) {//根据短句匹配boolQuery.should(QueryBuilders.matchPhraseQuery(articleRequest.getKeys()[i], articleRequest.getKeyword()));}}
高亮开发
里面可以指定高亮的字段,以及高亮前缀,尾缀,API的调用,直接 copy 就行。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().highlighter(new HighlightBuilder().requireFieldMatch(false).field("author").field("title").field("body").field("attachments.filename").preTags(EsConstant.HIGHT_PREFIX).postTags(EsConstant.HIGHT_END)//noMatchSize//返回全部内容,方便后续的截取字符串操作.fragmentSize(800000).numOfFragments(0))//过滤数据(最少满足一个 should 条件的数据才会被展示,否则过滤).query(boolQuery.minimumShouldMatch(1)).from(articleRequest.getPage() - 1).size(articleRequest.getSize());
Es Map 转对象使用
由于索引结构是已 ArticleResponse 格式存储的,查询的时候也需将的得到 SourceAsMap 转换成 ArticleResponse 格式,核心逻辑我都封装到 Trans 接口了。利用反射实现的,当然也可以用其他技术实现,例如 MapStruct 在编译期间就自动生成对应的 get、set 方法,比反射效率高点,毕竟反射是运行期间的属性映射!!!!
SearchHits hits = restHighLevelClient.search(new SearchRequest().indices(indexname).source(searchSourceBuilder)).getHits();for (SearchHit hit : hits) {result.add(new ArticleResponse().trans(hit.getSourceAsMap(),hit.getHighlightFields(),Collections.singletonList("attachments.filename")));
使用的话只需让 ArticleResponse 类实现 Trans 接口,即可调用里面的 trans 方法。
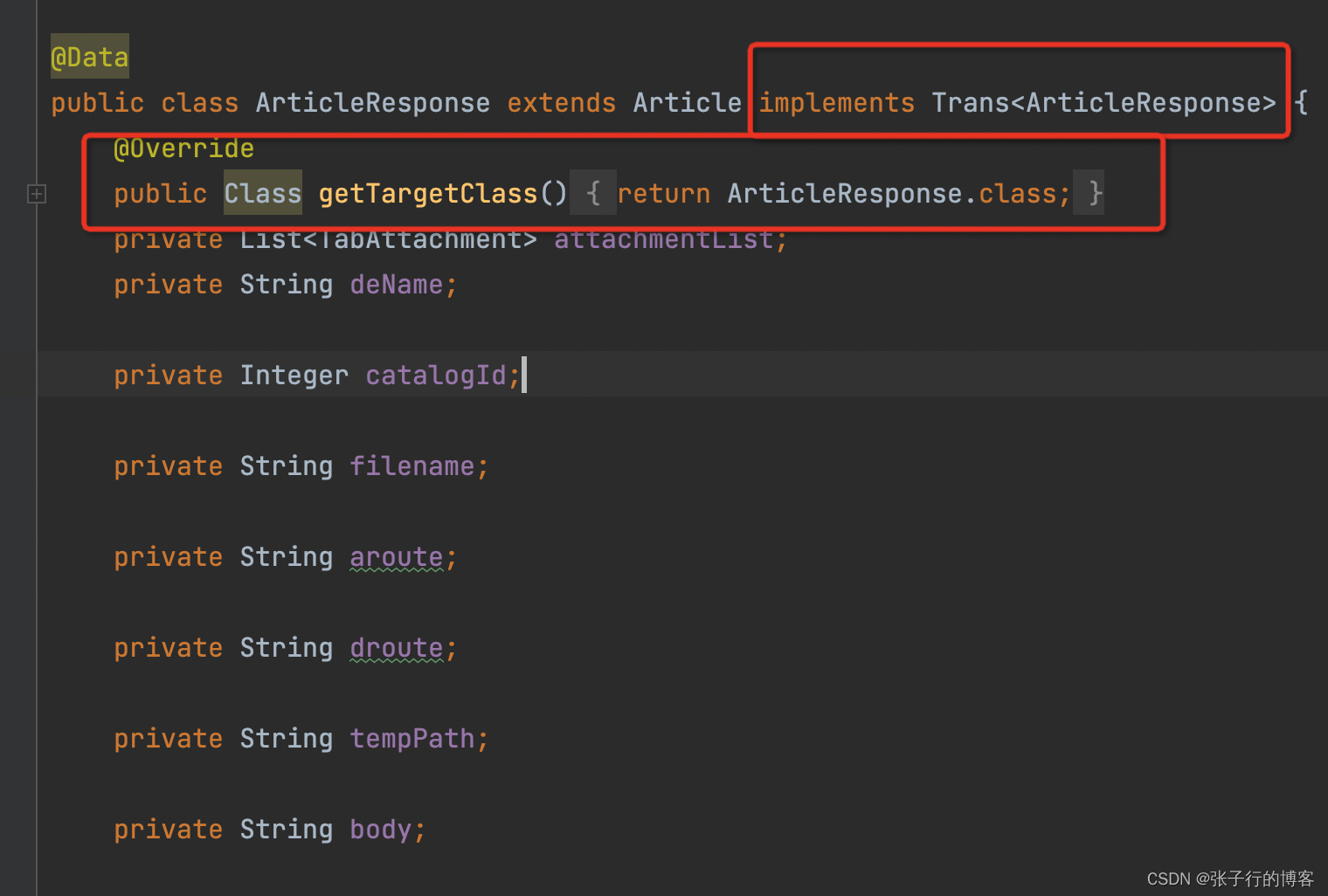
核心代码 Trans 接口(支持父类属性的复杂映射)
主要逻辑就是挨个拿到本身、然后递归获取父类的所有字段名称、字段类型放到一个 Map(nameTypeMap) 中,然后遍历 SourceAsMap 挨个进行字段类型匹配校验,如果是 String 类型直接进行反射填充属性。
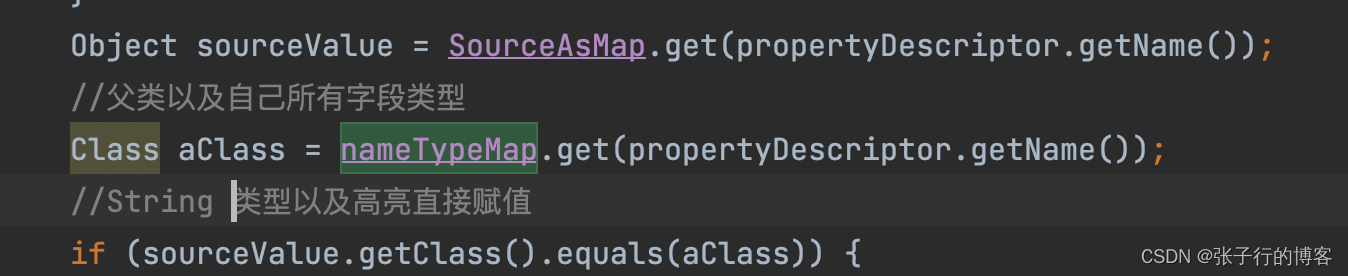
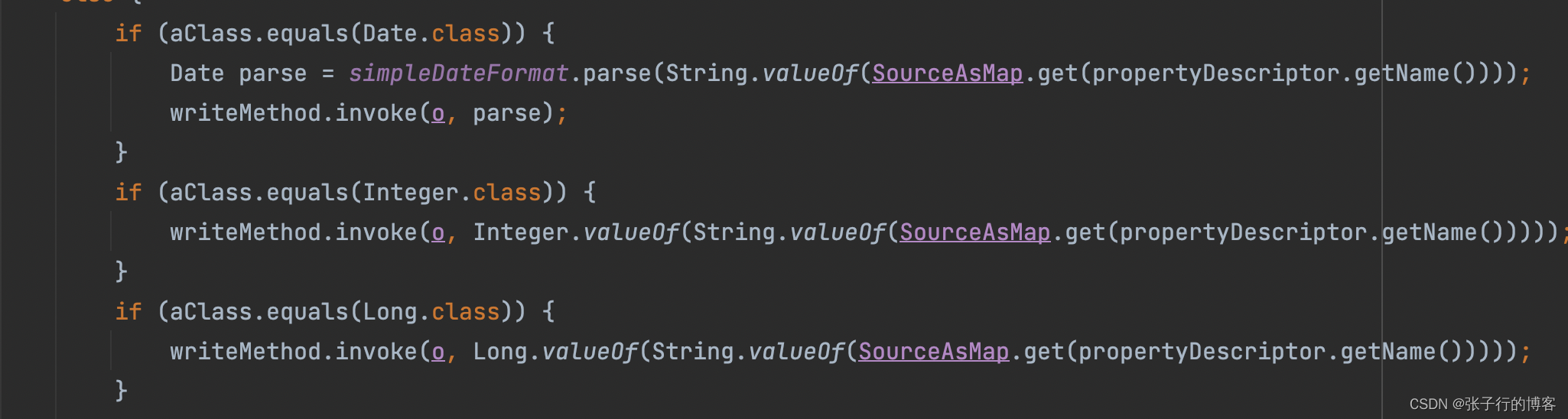
非 String 类型,进行类型转换然后再进行属性填充。
以及高亮字段文本略缩的处理,主要就是用了下 Jsoup 中去除 Html 标签的 Api,本来想着让前端自己去找插件看能不能处理下的,无奈说处理不了,想了个取巧的方法,高亮标签我用特殊字符,然后去除所有的 html 标签后,我的特殊字符还存在,之后将特殊字符再次替换回高亮 Html 标签,这样就得到了只存在我自定义高亮 Html 标签的一段文本了,同时高亮标签里面我塞了一个 id,之后根据高亮标签中的 id 截取字符即可,即可实现文本略缩的效果,同事直呼秒啊哈哈哈哈

/*** map 转对象* author:zzh*/
public interface Trans<T> {SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");Class getTargetClass();/*** 逻辑写的太多了,可以搞几个抽象类抽分功能** @param SourceAsMap 原始数据* @param highlightFieldsSource 高亮数据* @param highLightFields 高亮字段*/default Object trans(Map<String, Object> SourceAsMap, Map<String, HighlightField> highlightFieldsSource, List<String> highLightFields) throws IntrospectionException, InstantiationException, IllegalAccessException {Object o = getTargetClass().newInstance();Class tclass = getTargetClass();HashMap<String, Class> nameTypeMap = new HashMap<>();//找到父类的所有字段do {Arrays.stream(tclass.getDeclaredFields()).forEach(field -> {field.setAccessible(true);//key:字段名称,value:字段类型nameTypeMap.put(field.getName(), field.getType());});tclass = tclass.getSuperclass();} while (!tclass.equals(Object.class));PropertyDescriptor[] propertyDescriptors = Introspector.getBeanInfo(o.getClass()).getPropertyDescriptors();Arrays.stream(propertyDescriptors).forEach(propertyDescriptor -> {if (!"targetClass".equals(propertyDescriptor.getName()) && !Objects.isNull(SourceAsMap.get(propertyDescriptor.getName()))) {try {Method writeMethod = propertyDescriptor.getWriteMethod();if (null != writeMethod) {if (!Modifier.isPublic(writeMethod.getDeclaringClass().getModifiers())) {writeMethod.setAccessible(true);}Object sourceValue = SourceAsMap.get(propertyDescriptor.getName());//父类以及自己所有字段类型Class aClass = nameTypeMap.get(propertyDescriptor.getName());//String 类型以及高亮直接赋值if (sourceValue.getClass().equals(aClass)) {HighlightField highlightObject = highlightFieldsSource.get(propertyDescriptor.getName());//如果高亮字段是 body,为了避免高亮文本处于文章末尾搜索页显示不到的问题,因此采用截取字符串将高亮字段偏移至前面if (EsConstant.HIGHT_FILED.equals(propertyDescriptor.getName()) && null != highlightObject) {String highlightString = highlightObject.getFragments()[0].toString();//去除所有 html 标签,并将自定义高亮前缀替换 span 标签,这样就实现了只保留高亮标签的目的了highlightString = Jsoup.parse(highlightString).body().text().replaceAll(EsConstant.HIGHT_PREFIX, EsConstant.HIGHT_PREFIX_HTML).replaceAll(EsConstant.HIGHT_END, EsConstant.HIGHT_END_HTML);//高亮字段前 50 个字到文章末尾highlightString = highlightString.substring((highlightString.indexOf(EsConstant.HIGHT_HTML_ID) - EsConstant.HIGHT_SIZE) < 0? 0 : (highlightString.indexOf(EsConstant.HIGHT_HTML_ID) - EsConstant.HIGHT_SIZE));writeMethod.invoke(o, highlightObject != null ? highlightString : SourceAsMap.get(propertyDescriptor.getName()));} else if (EsConstant.HIGHT_FILED.equals(propertyDescriptor.getName()) && null == highlightObject) {//非高亮的 body 字段,也去除下 Html 标签writeMethod.invoke(o, Jsoup.parse(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))).body().text());} else {//非 body 的其他高亮字段正常替换高亮文本writeMethod.invoke(o, highlightObject != null ? highlightObject.getFragments()[0].toString().replaceAll(EsConstant.HIGHT_PREFIX, EsConstant.HIGHT_PREFIX_HTML).replaceAll(EsConstant.HIGHT_END, EsConstant.HIGHT_END_HTML) : SourceAsMap.get(propertyDescriptor.getName()));}}/*** 类型不一致强转,这里可以搞个策略模式优化优化*/else {if (aClass.equals(Date.class)) {Date parse = simpleDateFormat.parse(String.valueOf(SourceAsMap.get(propertyDescriptor.getName())));writeMethod.invoke(o, parse);}if (aClass.equals(Integer.class)) {writeMethod.invoke(o, Integer.valueOf(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))));}if (aClass.equals(Long.class)) {writeMethod.invoke(o, Long.valueOf(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))));}if (aClass.equals(List.class)) {//获取指定属性的 ListArrayList<Map<String, Object>> oraginSources = (ArrayList<Map<String, Object>>) SourceAsMap.get(propertyDescriptor.getName());//复杂对象高亮字段映射if (null != oraginSources && 0 != highlightFieldsSource.size()) {for (int i = 0; i < oraginSources.size(); i++) {for (int j = 0; j < highLightFields.size(); j++) {try {if (highlightFieldsSource.containsKey(highLightFields.get(j))) {oraginSources.get(i).put(highLightFields.get(j).split("\\.")[1],highlightFieldsSource.get(highLightFields.get(j)).getFragments()[j].toString().replaceAll(EsConstant.HIGHT_PREFIX, EsConstant.HIGHT_PREFIX_HTML).replaceAll(EsConstant.HIGHT_END, EsConstant.HIGHT_END_HTML));}} catch (Exception e) {e.printStackTrace();}}}}writeMethod.invoke(o, oraginSources);}if (aClass.equals(int.class)) {writeMethod.invoke(o, Integer.parseInt(String.valueOf(SourceAsMap.get(propertyDescriptor.getName()))));}}} else throw new RuntimeException(propertyDescriptor.getName() + "~ writeMethod is null!!!!!");} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();} catch (Exception e) {e.printStackTrace();}}});return o;}}Trans 接口可优化的点
- 优化点一:策略模式扩展多数据类型转换那部分的代码,这里就不贴出来了。
- 优化点二:支持多高亮字段略缩处理,也就是将这行代码改成 List 集合判断,但是我感觉没必要,一个字段略缩就够用了。
EsConstant.HIGHT_FILED.equals(propertyDescriptor.getName())
- 配置文件也可以用策略模式,或者利用 Spi 机制动态加载。(针对项目要开源的情况下说的),这块的内容可以看我以往写过的 Spi 文章。
- 可以搞个文章内容里面涉及到关键字的地方就略缩一下,举个例子,查(地瓜)的时候,返回的数据是这样的( …地瓜…地瓜),而现在的效果是(地瓜…),希望别让我改!!!!我觉得我现在这样也够用了。
- 代码逻辑再次解耦,可以利用抽象类的性质,按照功能细分职责,毕竟很多框架源码就是这么干的,一堆的抽象类封装通用逻辑
高亮全局配置类如下
为了方便后期维护,将用到的配置封装了一下,大家可自行替换用 Nacos 配置中心也好,还是用枚举类也好,修改一下代码即可
public class EsConstant {//高亮前缀唯一 id,可自行定义public static String HIGHT_PREFIX = "zzhSatat";//高亮尾缀唯一 id,可自行定义public static String HIGHT_END = "zzhEnd";//高亮尾缀public static String HIGHT_END_HTML = "</span>";//高亮标签 id,可自行定义public static String HIGHT_HTML_ID = "zzh";//截取高亮字段前字符串长度public static int HIGHT_SIZE = 50;//高亮前缀public static String HIGHT_PREFIX_HTML = "<span style='color:red',id='" + HIGHT_HTML_ID + "'>";//略缩字段public static String HIGHT_FILED = "body";
}
真实项目落地效果
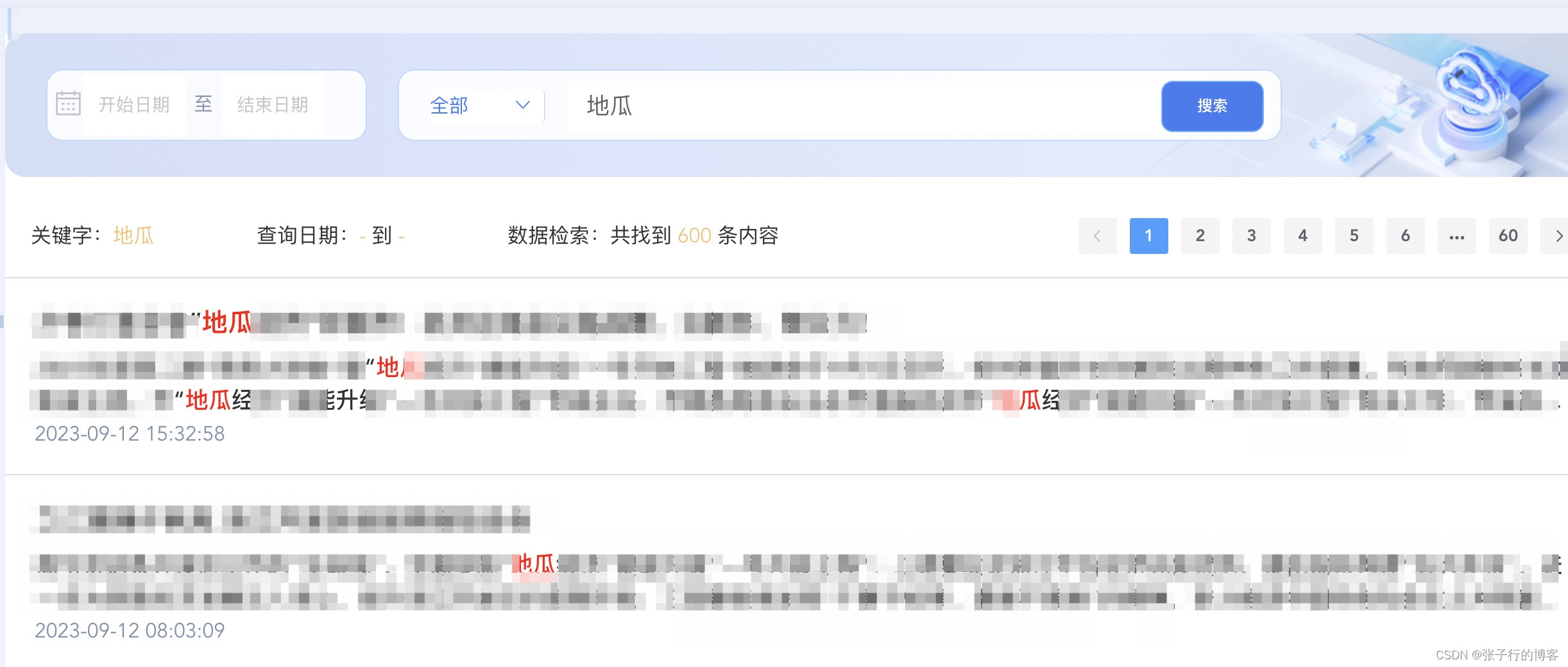
复杂对象高亮字段替换效果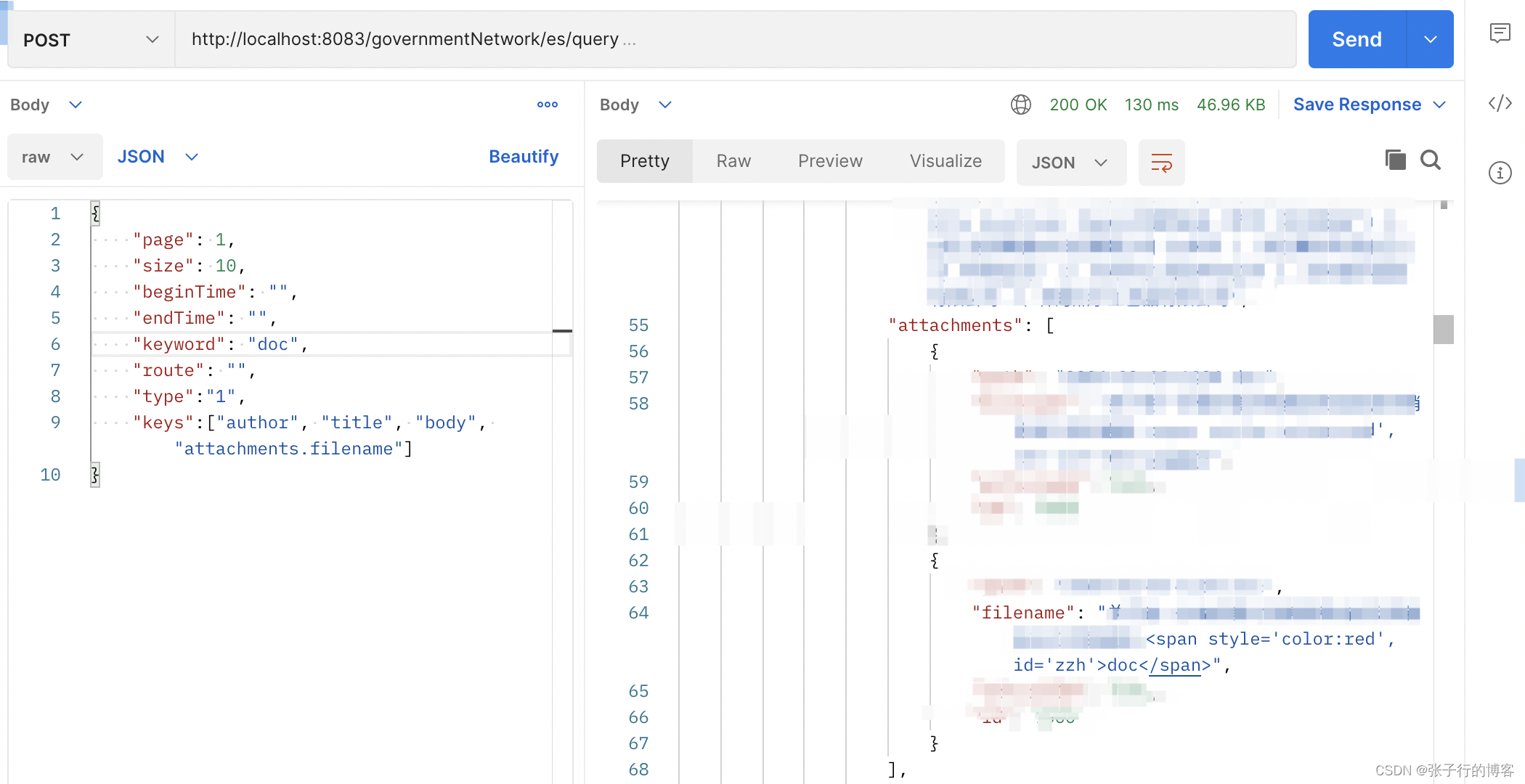
为什么不用 numOfFragments、fragmentSize 参数控制略缩?
数据库中的文章内容直接存的 Html 页面,用这俩参数截取字符串的话,截取到的文本会含残缺的 Html 标签,效果直接 Pass,当然对于纯文本类型的字段可以用这俩个参数进行控制,不用写截取字符串的逻辑!
结语
🌸🌸勿忘初心,鼎力前行🌸🌸
🌸🌸如果您觉得文章对您有帮助的话
🌸🌸不妨点个免费的赞或者关注
🌸🌸这将成为我前进的最大动力
🌸🌸微信公众号刚刚起步,后续创作更多精品内容提供给大家

🌸🌸有任何技术问题,欢迎加我微信交流
相关文章:

如何实现 Es 全文检索、高亮文本略缩处理(封装工具接口极致解耦)
如何实现 Es 全文检索、高亮文本略缩处理 前言技术选型JAVA 常用语法说明全文检索开发高亮开发Es Map 转对象使用核心代码 Trans 接口(支持父类属性的复杂映射)Trans 接口可优化的点高亮全局配置类如下真实项目落地效果为什么不用 numOfFragments、fragm…...
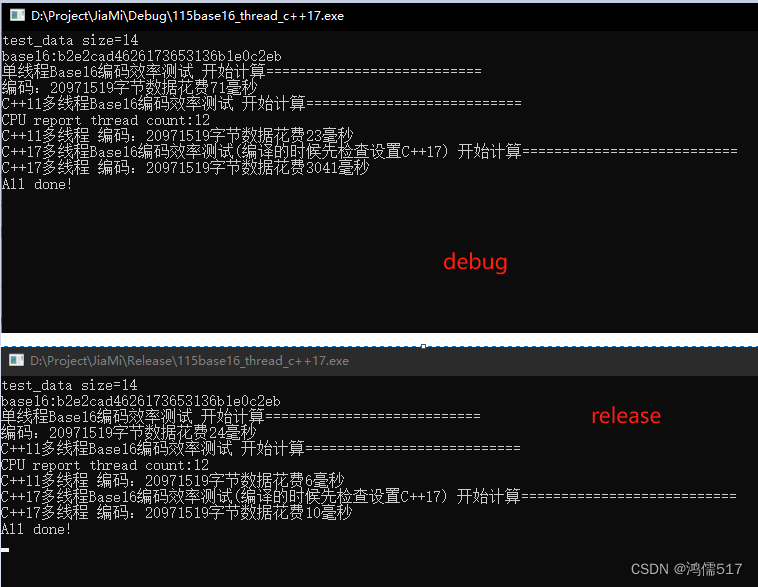
C++多线程编程(第四章 案例1,C++11和C++17 多核并行计算样例)
目录 4.1手动实现多核base16编码4.1.1 实现base16编码4.1.2无多线程代码4.1.3 C 11多线程代码4.1.4 C 17多线程并发4.1.5 所有测试代码汇总 4.1手动实现多核base16编码 4.1.1 实现base16编码 二进制转换为字符串 一个字节8位,拆分为两个4位字节(最大值…...

获取远程仓库的信息和远程分支的信息
前记: git svn sourcetree gitee github gitlab gitblit gitbucket gitolite gogs 版本控制 | 仓库管理 ---- 系列工程笔记. Platform:Windows 10 Git version:git version 2.32.0.windows.1 Function:获取远程仓库的信息和远…...
QT学习day1
一、思维导图 二、作业:实现登录界面 #include "widget.h" #include<QDebug> #include<QIcon>Widget::Widget(QWidget *parent): QWidget(parent) {/**********************窗口******************///设置窗口图标this->setWindowTitle…...

unity面试八股文 - 框架设计与资源管理
Unity项目框架是如何设计的?有哪些原则 在设计Unity项目框架时,通常会遵循一些基本的原则和步骤。以下是主要的一些原则: 模块化:每个功能都应该被作为一个独立的模块来处理,这样可以方便修改和维护。 低耦合&#x…...

智能网关IOT 2050采集应用
SIMATIC IOT2050 是西门子公司新推出的应用于企业数字化转型的智能边缘计算和云连接网关。 它将云、公司内 IT 和生产连接在一起,专为直接在生产环境中获取、处理和传输数据的工业 IT 解 决方案而设计。例如,它可用于将生产 过程与基于云的机器和生产数据…...
iOS代码混淆-从入门到放弃
目录 1. 什么是iOS代码混淆? 2. iOS自动代码混淆的方法是什么? 3. iOS代码混淆的作用是什么? 4. 怎么样才能做到更好的iOS代码混淆? 总结 参考资料 1. 什么是iOS代码混淆? 代码混淆是指将程序中的方法名、属…...
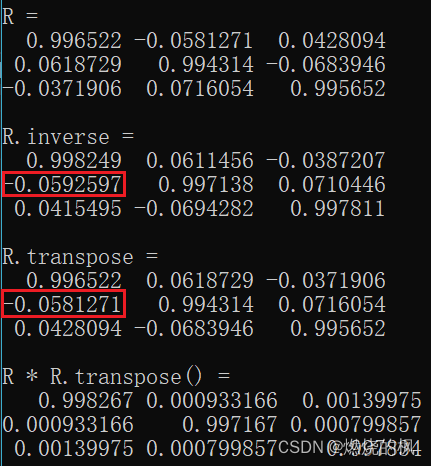
基于Eigen的位姿转换
位姿中姿态的表示形式有很多种,比如:旋转矩阵、四元数、欧拉角、旋转向量等等。这里基于Eigen实现四种数学形式的相互转换功能。本文利用Eigen实现上述四种形式的相互转换。我这里给出一个SE3(4*4)(先平移、再旋转)的构建方法&…...

Jmeter之Bean shell使用详解
一、什么是Bean Shell BeanShell是一种完全符合Java语法规范的脚本语言,并且又拥有自己的一些语法和方法;BeanShell是一种松散类型的脚本语言(这点和JS类似); BeanShell是用Java写成的,一个小型的、免费的、可以下载的、嵌入式的Java源代码解释器,具有对象脚本语言特性,非常精…...

TCP/IP(八)TCP的连接管理(五)四次握手
一 tcp连接断开 每一个TCP报文的超时重传都由一个特定的内核参数来控制 ① 四次握手的过程 遗留: 谁先发送FIN包,一定是client吗? --> upload和download补充: 主动和被动断开连接的场景 "四次握手过程描述" F --> FIN --> F…...

MyBatis-Plus主键生成策略[MyBatis-Plus系列] - 第491篇
历史文章(文章累计490) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 …...

Spring——和IoC相关的特性
目录 IoC中Bean的生命周期 实例化(Instantiation) 属性注入(Populate Properties) 初始化(Initialization) 使用(Bean in Use) 销毁(Destruction) Laz…...

在 TensorFlow 中调试
如果调试是消除软件错误的过程,那么编程一定是添加错误的过程。Edsger Dijkstra。来自 https://www.azquotes.com/quote/561997 一、说明 在这篇文章中,我想谈谈 TensorFlow 中的调试。 在之前的一些帖子(此处、此处和此处)中&…...

想要精通算法和SQL的成长之路 - 连续的子数组和
想要精通算法和SQL的成长之路 - 连续的子数组和 前言一. 连续的子数组和1.1 最原始的前缀和1.2 前缀和 哈希表 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 连续的子数组和 原题链接 1.1 最原始的前缀和 如果这道题目,用前缀和来算,我们的思路…...
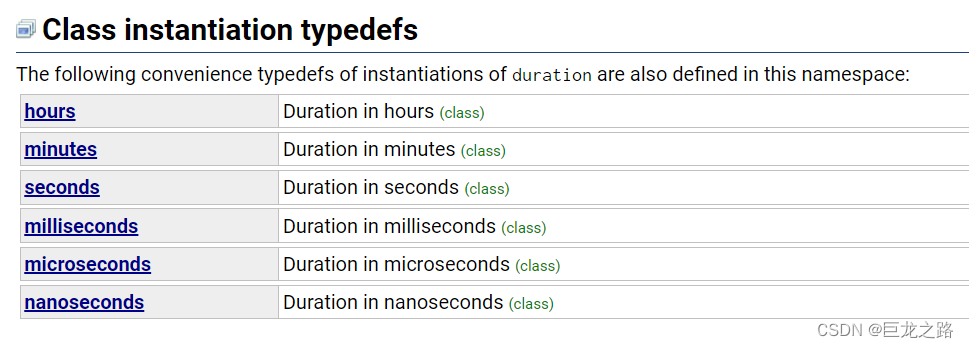
【C++】头文件chrono
2023年10月16日,周一晚上 当前我只是简单的了解了一下chrono 以后可能会深入了解chrono并更新文章 目录 功能原理头文件chrono中的一些类头文件chrono中的数据类型一个简单的示例程序小实验:证明a的效率比a高 功能 这个chrono头文件是用来处理时间的…...

Python学习六
前言:相信看到这篇文章的小伙伴都或多或少有一些编程基础,懂得一些linux的基本命令了吧,本篇文章将带领大家服务器如何部署一个使用django框架开发的一个网站进行云服务器端的部署。 文章使用到的的工具 Python:一种编程语言&…...

Springboot 集成 WebSocket
WebSocket是一种在单个TCP连接上进行全双工通信的协议。WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接…...
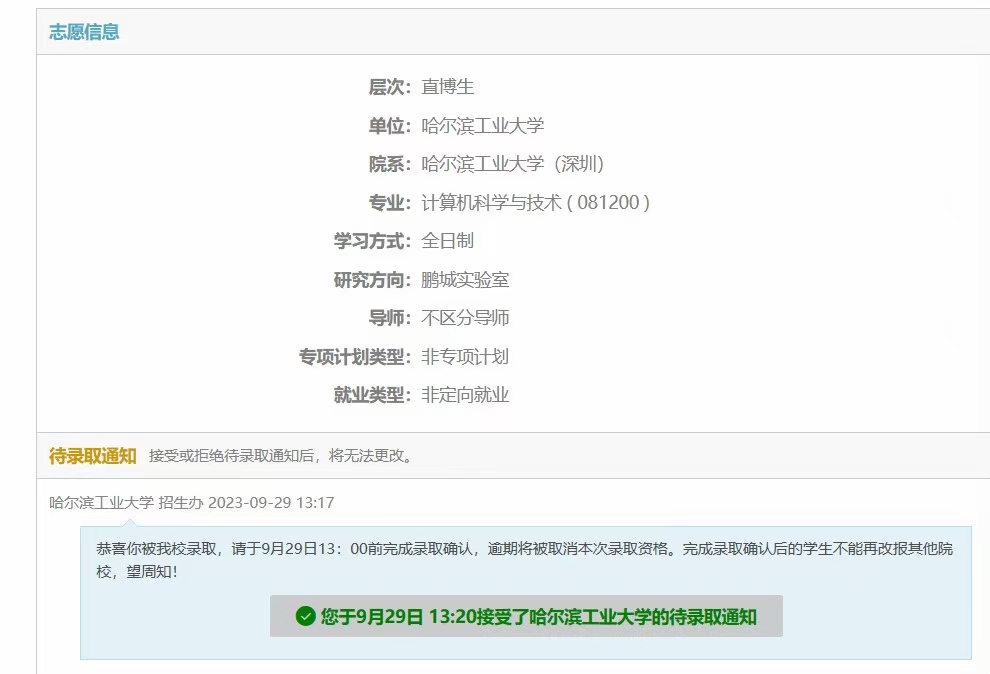
谨以此篇,纪念我2023年曲折的计算机保研之路
目录 阶段一:迷茫阶段二:准备个人意愿保研材料准备套磁老师5.1日 浙大线上编程测试5.8日 浙大线上面试 —— 一面5.17日 浙大线上面试——二面5.29日 实验室面试结果5.27日 南开线上面试6.20日 华师电话面试 阶段三:旅途北航CS(6.…...
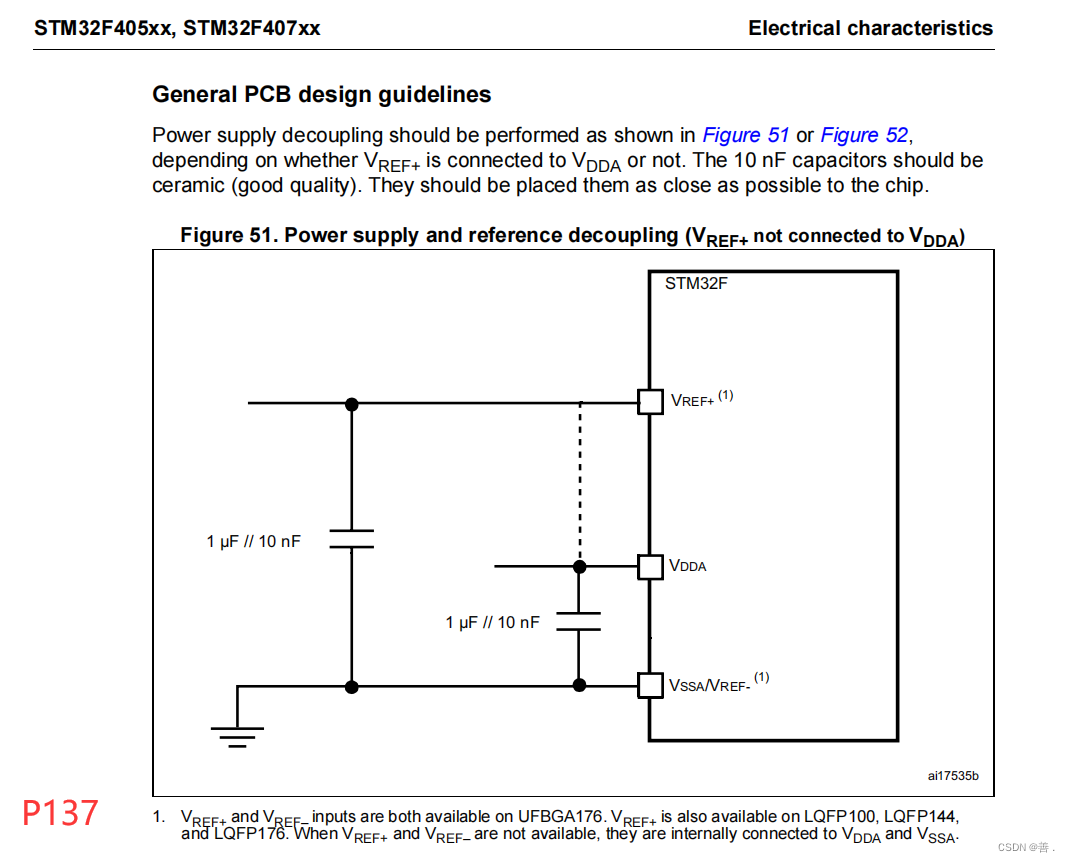
VSS、VDD、VBAT、VSSA
引言 在学习设计TM32时,发现芯片除了GPIO引脚外还会引出许多引脚,以STM32F407ZGT6为例除了GPIO引脚还会有以下引脚 如VSS、VDD、VBAT、VSSA、NRST、VREF、VDDA、VCAP_1、VCAP_2、PDR_ON这些引脚。他们有何作用,电路设计中应如何连接&#x…...

【Rust基础③】方法method、泛型与特征
文章目录 6 方法 Method6.1 定义方法self、&self 和 &mut self 6.2 自动引用和解引用6.3 关联函数 7 泛型和特征7.1 泛型 Generics7.1.1 结构体中使用泛型7.1.2 枚举中使用泛型7.1.3 方法中使用泛型为具体的泛型类型实现方法 7.1.4 const 泛型 7.2 特征 Trait7.2.1 为类…...

3PEAK思瑞浦 TPA1811-S5TR SOT23-5 精密运放
特性 供电电压:4伏至30伏 低功耗:在25C时为55A(典型值) 低偏置电压:8V在25C(最大值) 零漂:0.01V/C 轨到轨输出 增益带宽积:500kHz 斜率:0.3V/us...

Perplexity开发者文档结构逆向工程:通过17个真实HTTP响应头+OpenAPI Schema反推隐藏端点与beta功能开关
更多请点击: https://intelliparadigm.com 第一章:Perplexity开发者文档查询 Perplexity 提供了一套面向 AI 应用开发者的 RESTful API 文档体系,其开发者中心(developer.perplexity.ai)支持结构化检索、版本过滤与实…...

英雄联盟回放播放器终极指南:用ROFL-Player解锁你的游戏记忆
英雄联盟回放播放器终极指南:用ROFL-Player解锁你的游戏记忆 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟…...

基于OpenClaw构建AI智能体:从RAG到自动化工作流的实战指南
1. 项目概述:一个开源AI应用案例的“藏宝图”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫awesome-openclaw-usecases-zh。光看名字,就能拆解出几个关键信息:“awesome”系列(意味着是精选合集…...

[实战指南+数据解析] DEAP数据集:基于EEG、生理与视频信号的多模态情感计算入门
1. DEAP数据集入门:多模态情感计算的钥匙 第一次接触DEAP数据集时,我被它丰富的多模态数据震撼到了。这个数据集就像情感计算领域的"瑞士军刀",包含了EEG脑电波、皮肤电导等生理信号,还有22名参与者的面部视频记录。最特…...

AI驱动的智能监控:从时序异常检测到自动化运维实战
1. 项目概述:AI驱动的系统守护者最近在折腾一个服务器监控项目时,发现了一个挺有意思的开源工具,叫bhusingh/ai-watchdog。这个名字直译过来就是“AI看门狗”,听起来就很有画面感。它本质上是一个利用人工智能技术来监控系统、预测…...

如何利用Google Cloud服务加速OR-Tools大规模优化求解:完整实践指南
如何利用Google Cloud服务加速OR-Tools大规模优化求解:完整实践指南 【免费下载链接】or-tools Googles Operations Research tools: 项目地址: https://gitcode.com/gh_mirrors/or/or-tools OR-Tools是Google开发的强大运筹学工具库,能够高效解决…...

【AI面试临阵磨枪-56】大模型服务部署:Docker、K8s、GPU 调度、推理加速
一、 面试题目在生产环境中部署大模型服务时,你是如何结合 Docker 和 K8s 实现高效治理的?特别是在 GPU 调度(如共享、切分) 和 推理加速(如 vLLM, TensorRT-LLM) 方面有哪些实战经验?二、 知识…...

OpencvSharp 算子学习教案之 - Cv2.Accumulate
OpencvSharp 算子学习教案之 - Cv2.Accumulate 大家好,Opencv在很多工程项目中都会用到,而OpencvSharp则是以C#开发与实现的Opencv操作库,对.NET开发人员友好,但很多API的中文资料、应用场景及常见坑点等缺乏系统性归纳ÿ…...

Linux 网络虚拟化深度解析:从 veth 设备对到容器网络实战
第一部分:veth 设备对 —— 虚拟世界的 "网线" 1.1 什么是 veth 设备对? veth(Virtual Ethernet)设备对,可以理解为软件模拟的一对 "虚拟网卡",它们总是成对出现,就像用一…...