使用自己的数据集Fine-tune PaddleHub预训练模型
使用自己的数据Fine-tune PaddleHub预训练模型
果农需要根据水果的不同大小和质量进行产品的定价,所以每年收获的季节有大量的人工对水果分类的需求。基于人工智能模型的方案,收获的大堆水果会被机械放到传送带上,模型会根据摄像头拍到的图片,控制仪器实现水果的自动分拣,节省了果农大量的人力。

下面我们就看看如果采集到少量的桃子数据,如何基于PaddleHub对ImageNet数据集上预训练模型进行Fine-tune,得到一个更有效的模型。桃子分类数据集取自AI Studio公开数据集桃脸识别,该桃脸识别数据集中已经将所有桃子的图片分为2个文件夹,一个是训练集一个是测试集;每个文件夹中有4个分类,分别是B1、M2、R0、S3。

实现迁移学习,包括如下步骤:
- 安装PaddleHub
- 数据准备
- 模型准备
- 训练准备
下面将根据这四个主要步骤,展示如何利用PaddleHub实现finetune。
1. 安装PaddleHub
paddlehub安装可以使用pip完成安装,如下:
# 安装并升级PaddleHub,使用百度源更稳定、更迅速
pip install paddlehub==2.1 -i https://mirror.baidu.com/pypi/simple
2. 数据准备
在本次教程提供的数据文件中,已经提供了分割好的训练集、验证集、测试集的索引和标注文件。如果用户利用PaddleHub迁移CV类任务使用自定义数据,则需要自行切分数据集,将数据集切分为训练集、验证集和测试集。需要三个文本文件来记录对应的图片路径和标签,此外还需要一个标签文件用于记录标签的名称。
├─data: 数据目录 ├─train_list.txt:训练集数据列表 ├─test_list.txt:测试集数据列表 ├─validate_list.txt:验证集数据列表 ├─label_list.txt:标签列表 └─……
训练集、验证集和测试集的数据列表文件的格式如下,列与列之间以空格键分隔。
图片1路径 图片1标签
图片2路径 图片2标签
...
label_list.txt的格式如下:
分类1名称
分类2名称
...
准备好数据后即可使用PaddleHub完成数据读取器的构建,实现方法如下所示:构建数据读取Python类,并继承paddle.io.Dataset这个类完成数据读取器构建。在定义数据集时,需要预先定义好对数据集的预处理操作,并且设置好数据模式。在数据集定义中,需要重新定义__init__,__getitem__和__len__三个部分。示例如下:
import osimport paddle
import paddlehub as hubclass DemoDataset(paddle.io.Dataset):def __init__(self, transforms, num_classes=4, mode='train'): # 数据集存放位置self.dataset_dir = "./work/peach-classification" #dataset_dir为数据集实际路径,需要填写全路径self.transforms = transformsself.num_classes = num_classesself.mode = modeif self.mode == 'train':self.file = 'train_list.txt'elif self.mode == 'test':self.file = 'test_list.txt'else:self.file = 'validate_list.txt'self.file = os.path.join(self.dataset_dir , self.file)with open(self.file, 'r') as file:self.data = file.read().split('\n')[:-1]def __getitem__(self, idx):img_path, grt = self.data[idx].split(' ')img_path = os.path.join(self.dataset_dir, img_path)im = self.transforms(img_path)return im, int(grt)def __len__(self):return len(self.data)将训练数据输入模型之前,我们通常还需要对原始数据做一些数据处理的工作,比如数据格式的规范化处理,或增加一些数据增强策略。
构建图像分类模型的数据读取器,负责将桃子dataset的数据进行预处理,以特定格式组织并输入给模型进行训练。
如下数据处理策略,只做了两种操作:
- 指定输入图片的尺寸,并将所有样本数据统一处理成该尺寸。
- 对所有输入图片数据进行归一化处理。
对数据预处理及加载数据集的示例如下:
import paddlehub.vision.transforms as Ttransforms = T.Compose([T.Resize((256, 256)),T.CenterCrop(224),T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])],to_rgb=True)peach_train = DemoDataset(transforms)
peach_validate = DemoDataset(transforms, mode='val')
3. 模型准备
我们要在PaddleHub中选择合适的预训练模型来Fine-tune,由于桃子分类是一个图像分类任务,这里采用Resnet50模型,并且是采用ImageNet数据集Fine-tune过的版本。这个预训练模型是在图像任务中的一个“万金油”模型,Resnet是目前较为有效的处理图像的网络结构,50层是一个精度和性能兼顾的选择,而ImageNet又是计算机视觉领域公开的最大的分类数据集。所以,在不清楚选择什么模型好的时候,可以优先以这个模型作为baseline。
使用PaddleHub,不需要重新手写Resnet50网络,可以通过一行代码实现模型的调用。
#安装预训练模型
! hub install resnet50_vd_imagenet_ssld==1.1.0
import paddlehub as hubmodel = hub.Module(name='resnet50_vd_imagenet_ssld', label_list=["R0", "B1", "M2", "S3"])
4. 训练准备
定义好模型,也准备好数据后,我们就可以开始设置训练的策略。Paddle2.2提供了多种优化器选择,如SGD, Adam, Adamax等。
from paddlehub.finetune.trainer import Trainerimport paddleoptimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt', use_gpu=True)
trainer.train(peach_train, epochs=10, batch_size=16, eval_dataset=peach_validate, save_interval=1)#打印
[2023-02-25 10:08:53,462] [ TRAIN] - Epoch=1/10, Step=10/375 loss=0.9796 acc=0.6250 lr=0.001000 step/sec=1.85 | ETA 00:33:46
[2023-02-25 10:08:54,244] [ TRAIN] - Epoch=1/10, Step=20/375 loss=0.6388 acc=0.7625 lr=0.001000 step/sec=12.78 | ETA 00:19:20
[2023-02-25 10:08:55,029] [ TRAIN] - Epoch=1/10, Step=30/375 loss=0.5733 acc=0.7375 lr=0.001000 step/sec=12.75 | ETA 00:14:31
[2023-02-25 10:08:55,827] [ TRAIN] - Epoch=1/10, Step=40/375 loss=0.2518 acc=0.9062 lr=0.001000 step/sec=12.53 | ETA 00:12:08
[2023-02-25 10:08:56,615] [ TRAIN] - Epoch=1/10, Step=50/375 loss=0.1935 acc=0.9250 lr=0.001000 step/sec=12.69 | ETA 00:10:41
[2023-02-25 10:08:57,428] [ TRAIN] - Epoch=1/10, Step=60/375 loss=0.1949 acc=0.9375 lr=0.001000 step/sec=12.31 | ETA 00:09:45
[2023-02-25 10:08:58,238] [ TRAIN] - Epoch=1/10, Step=70/375 loss=0.1502 acc=0.9563 lr=0.001000 step/sec=12.34 | ETA 00:09:05
[2023-02-25 10:08:59,023] [ TRAIN] - Epoch=1/10, Step=80/375 loss=0.1275 acc=0.9500 lr=0.001000 step/sec=12.73 | ETA 00:08:34
[2023-02-25 10:08:59,807] [ TRAIN] - Epoch=1/10, Step=90/375 loss=0.1811 acc=0.9187 lr=0.001000 step/sec=12.76 | ETA 00:08:09
其中Adam:
learning_rate: 全局学习率。默认为1e-3;parameters: 待优化模型参数。
运行配置
Trainer 主要控制Fine-tune的训练,包含以下可控制的参数:
model: 被优化模型;optimizer: 优化器选择;use_gpu: 是否使用gpu;use_vdl: 是否使用vdl可视化训练过程;checkpoint_dir: 保存模型参数的地址;compare_metrics: 保存最优模型的衡量指标;
trainer.train 主要控制具体的训练过程,包含以下可控制的参数:
train_dataset: 训练时所用的数据集;epochs: 训练轮数;batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;num_workers: works的数量,默认为0;eval_dataset: 验证集;log_interval: 打印日志的间隔, 单位为执行批训练的次数。save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
当Fine-tune完成后,我们使用模型来进行预测,实现如下:
import paddle
import paddlehub as hubresult = model.predict(['./work/peach-classification/test/M2/0.png'])
print(result)# 打印:
[{'M2': 0.99999964}]
以上为加载模型后实际预测结果(这里只测试了一张图片),返回的是预测的实际效果,可以看到我们传入待预测的是M2类别的桃子照片,经过Fine-tune之后的模型预测的效果也是M2,由此成功完成了桃子分类的迁移学习。
相关文章:
使用自己的数据集Fine-tune PaddleHub预训练模型
使用自己的数据Fine-tune PaddleHub预训练模型 果农需要根据水果的不同大小和质量进行产品的定价,所以每年收获的季节有大量的人工对水果分类的需求。基于人工智能模型的方案,收获的大堆水果会被机械放到传送带上,模型会根据摄像头拍到的图片…...

带组态物联网平台源码 代码开源可二次开发 web MQTT Modbus
物联网IOT平台开发辅助文档 技术栈:JAVA [ springmvc / spring / mybatis ] 、Mysql 、Html 、 Jquery 、css 使用协议和优势: TCP/IP、HTTP、MQTT 通讯协议 1.1系统简介 IOT通用物联网系统平台带组态,是一套面向通用型业务数据处理的系统…...

计算机网络的发展历程
计算机网络的历史可以追溯到20世纪60年代。那个时候,计算机还非常昂贵,只有少数大型机可以被用于处理重要任务。这些大型机通常被安装在大型企业、政府机构和大学中。由于这些机器非常昂贵,许多企业、机构和大学只能通过终端连接来访问它们。…...

【华为OD机试模拟题】用 C++ 实现 - 不含 101 的数(2023.Q1)
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...

面试题-下单后位置信息上报的方案
面试题:外卖下单后每10min上报位置事件的具体实现方案。需要考虑哪些点。存储方案:考虑到数据量很大,需要快速响应查询请求,建议使用分布式存储方案,如 HBase、MongoDB 等。这些分布式存储系统可以水平扩展,…...
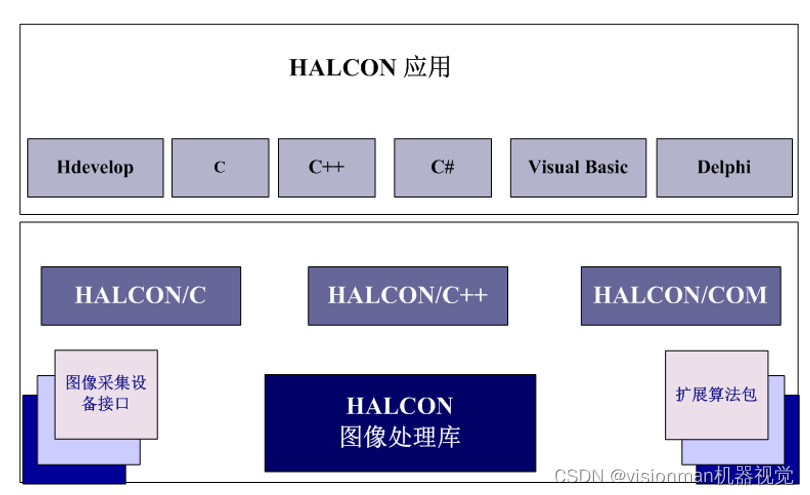
视觉人培训团队把它称之为,工业领域人类最伟大的软件创造,它的名字叫Halcon
目前为止,世界上综合能力强大的机器视觉软件,,它的名字叫Halcon。 视觉人培训团队把它称之为,工业领域人类最伟大的软件创造,它的名字叫Halcon。 持续不断更新最新的图像技术,软件综合能力持续提升。 综…...
干了2年的手工点点点,感觉每天浑浑噩噩,我的自动化测试之路...
作为一个测试人员,从业年期从事手工测试的工作是没有太多坏处的,当然,如果一直点来点去那么确实自身得不到提高,这时候选择学习自动化测试是一件很有必要的事情,一来将自己从繁重的重复工作中解放出来,从事…...
嵌入式系统硬件设计与实践(学习方法)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 刚读书的时候,对什么是嵌入式,其实并不太清楚。等到自己知道的时候,已经毕业很多年了。另外对于计算机毕业的学…...
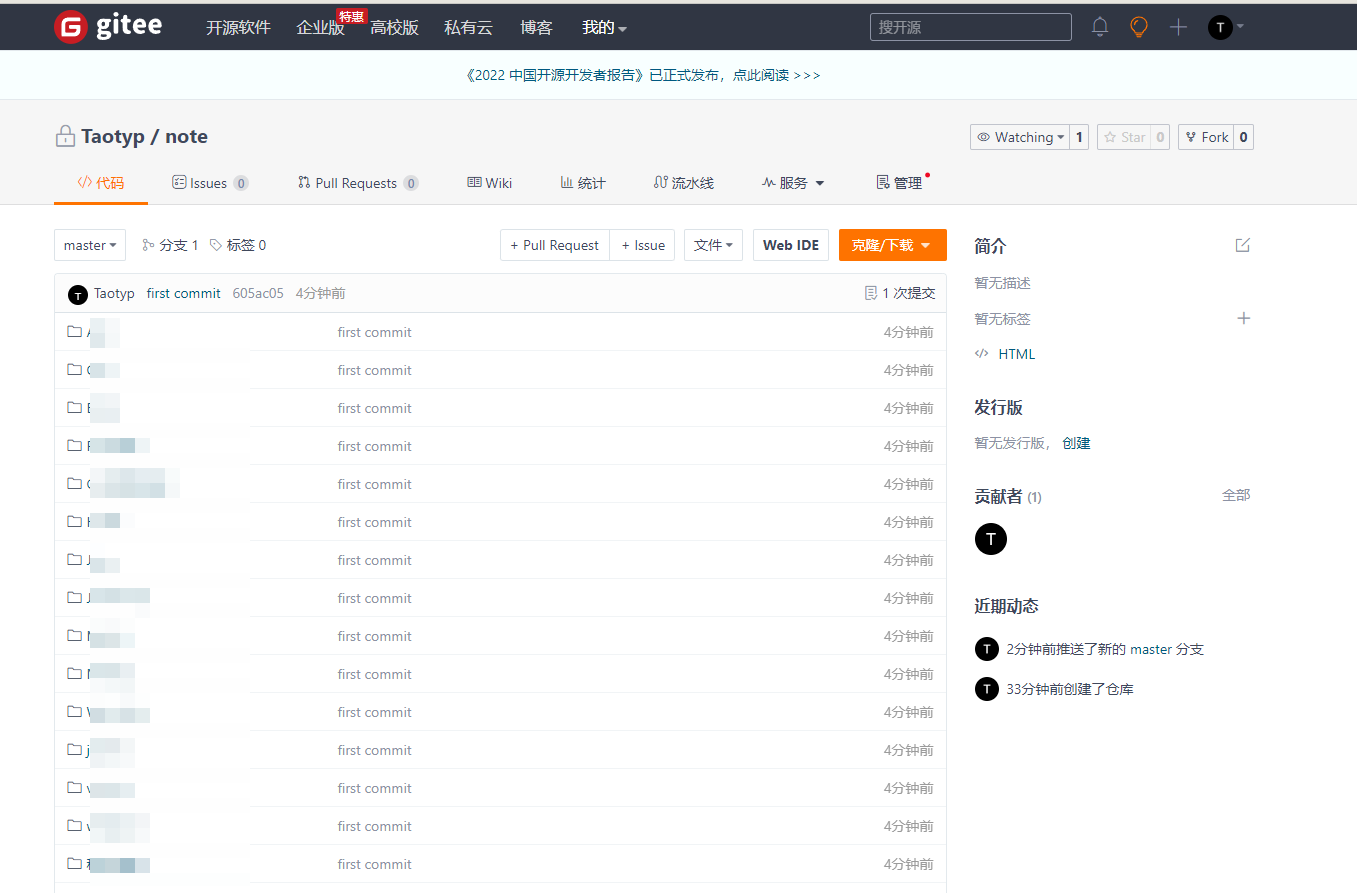
如何拥有自己的Gitee代码仓库
本教程适用码云代码托管平台 https://gitee.com/ 首先在电脑上安装Git(哔站有安装Git教程)和注册gitee账号后再来阅读此教程 1、在设置页面中点击 SSH公钥 2、点击 怎样生成公钥 3、点击公钥管理 4、点击 生成\添加SSH公钥 5、打开终端 输入如图红框中的…...
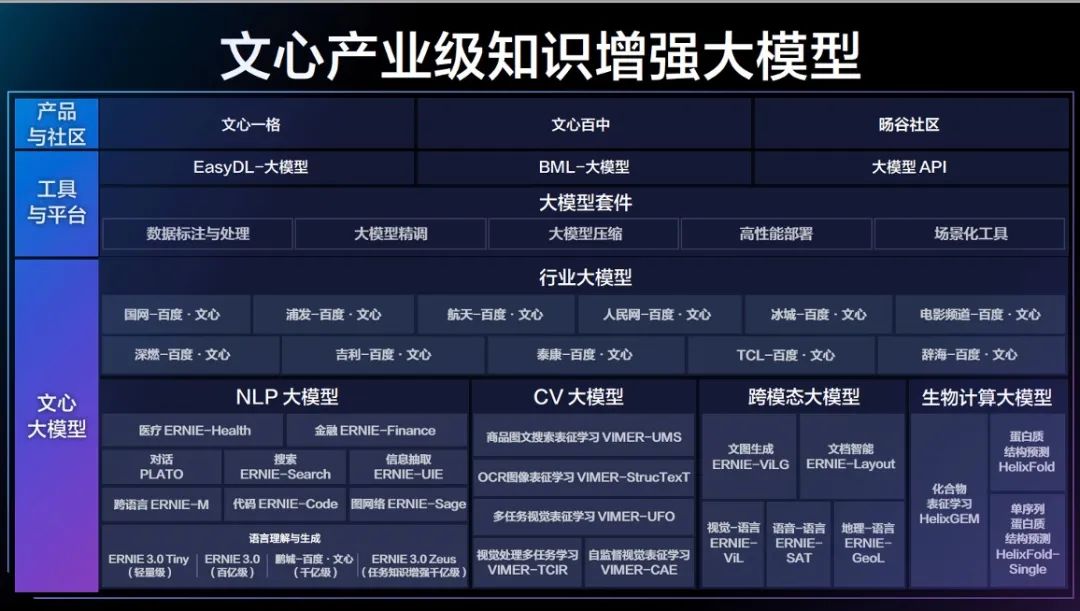
通用信息抽取技术UIE产业案例解析,Prompt 范式落地经验分享!
想了解用户的评价究竟是“真心夸赞”还是“阴阳怪气”?想快速从多角色多事件的繁杂信息中剥茧抽丝提取核心内容?想通过聚合相似事件准确地归纳出特征标签?……想了解UIE技术在产业中的实战落地经验?通用信息抽取技术 UIE 产业案例…...
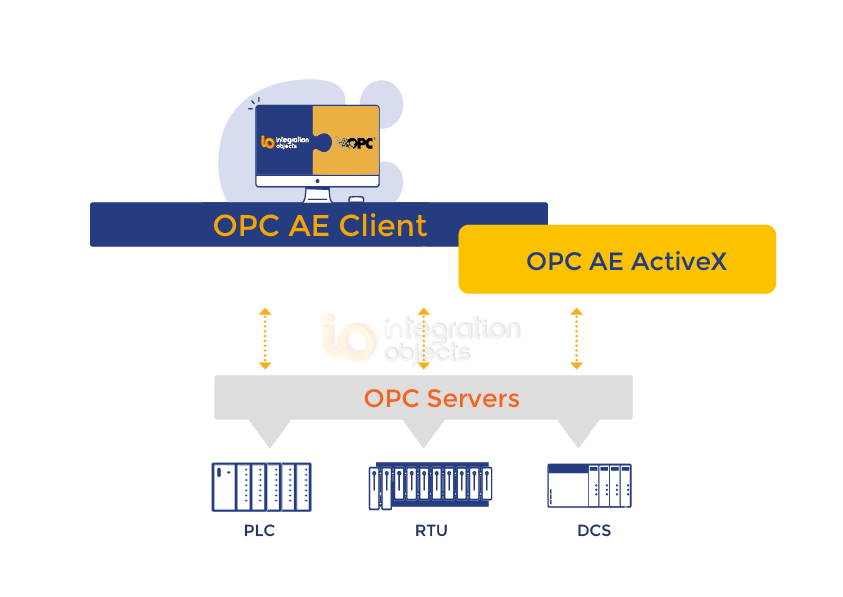
integrationobjects/OPC AE Client ActiveX Crack
使用 OPC AE 客户端 ActiveX 进行快速 OPC 警报和事件客户端编程! OPC AE Client ActiveX包括多个 OPC ActiveX 控件,可以轻松嵌入到最流行的 OLE 容器中。这允许用户与任何 OPC AE 服务器连接并实时检索警报和事件。 这种易于使用的 OPC AE ActiveX 简化…...
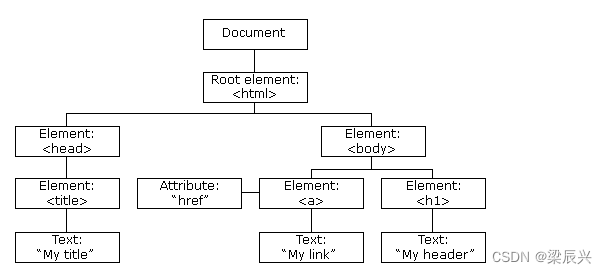
JavaScript HTML DOM 简介
文章目录JavaScript HTML DOM 简介HTML DOM (文档对象模型)HTML DOM 树查找 HTML 元素通过 id 查找 HTML 元素通过标签名查找 HTML 元素通过类名找到 HTML 元素下面我们将学到如下内容JavaScript HTML DOM 简介 通过 HTML DOM,可访问 JavaScript HTML 文档的所有元素…...
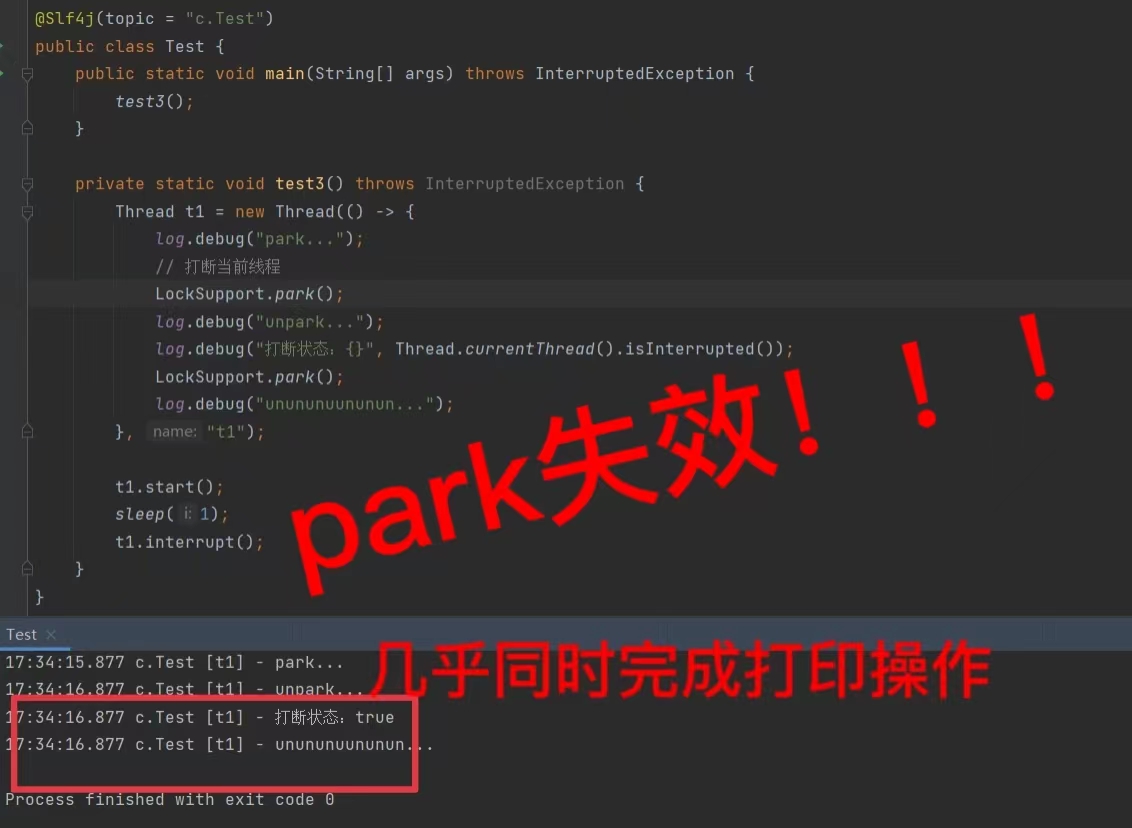
interrupt多线程设计模式
1. 两阶段终止-interrupt Two Phase Termination 在一个线程T1中如何“优雅”终止线程T2?这里的【优雅】指的是给T2一个料理后事的机会。 错误思路 ● 使用线程对象的stop()方法停止线程(强制杀死) —— stop()方法…...
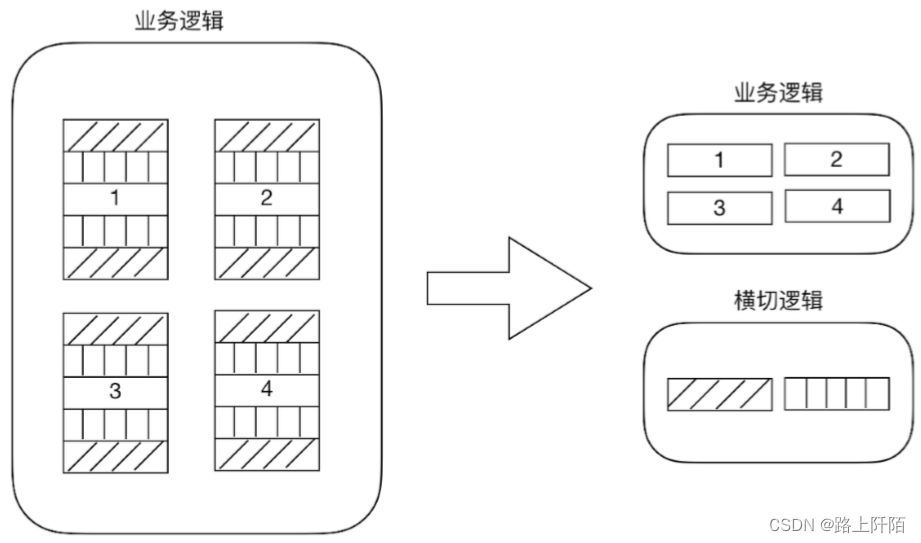
Spring IoC 和 Spring AOP
Spring IoC Ioc(Inversion of control:即控制反转)是一种设计思想,而不是一种具体的技术实现。IoC的思想就是将原本在程序中手动创建对象的控制权交给Spring框架来管理。 不过, IoC 并非 Spring 特有,在其…...

taobao.top.oaid.merge( OAID订单合并 )
¥开放平台免费API必须用户授权 基于OAID(收件人ID, Open Addressee ID)做订单合并,确保相同收件人信息的订单合并到相同组。 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 请…...

Python自动获取海量ip,再也不用愁被封啦~
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本次网站: 本文所有模块\环境\源码\教程皆可点击文章下方名片获取此处跳转 开发环境: python 3.8 运行代码 pycharm 2022.3 辅助敲代码 模块使用: import parsel >>> pip install parsel…...

XLua学习笔记 { }
Lua调用C# 通过生成的适配代码进行调用 把在白名单上和打上[LuaCallCSharp]标签的C#类转换成Lua的table,然后注册C#类的方法和属性到table中。性能好,但占用安装包的内存大 通过反射机制进行调用 性能差,在运行的时候才去查找C#的方法&#…...

推荐程序员收藏的几个技术社区以及工具网站
常用技术社区 1、GitHub 网站地址:https://github.com/ 全球最大的开源社区,这点我想大家都清楚。但是今年被微软收购,之前很多的人在那说可能以后GitHub就会变样,但是事实并非如此,目前还没有收到什么信息,…...
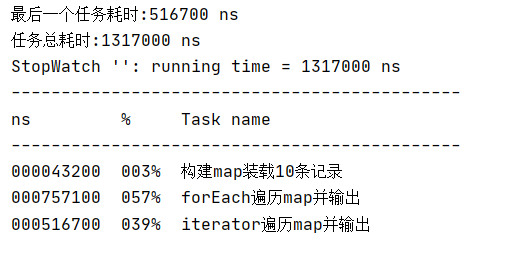
StopWatch计时器
前言 开发中,为了评估性能,我们通常会使用System.currentTimeMillis() 去计算程序运行耗时 long startTimeSystem.currentTimeMillis();//业务代码... long endTimeSystem.currentTimeMillis(); System.out.println("耗时:" (endTime-startT…...
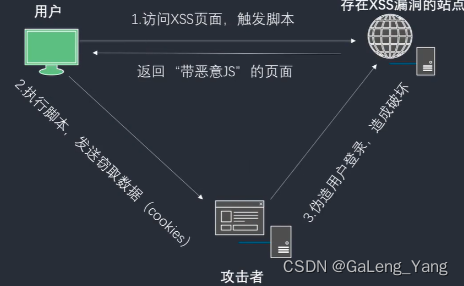
常见web安全漏洞-暴力破解,xss,SQL注入,csrf
1,暴力破解 原理: 使用大量的认证信息在认证接口进行登录认证,知道正确为止。为提高效率一般使用带有字典的工具自动化操作 基于表单的暴力破解 --- 若用户没有安全认证,直接进行抓包破解。 验证码绕过 on server ---验证码校验在…...

HarmonyOS 6 Chip 组件:不显示后缀图标使用文档
文章目录概述源码隐藏后缀图标核心实现原理1. 核心控制字段2. 双重隐藏条件3. 冗余回调说明组件配置解析总结概述 Chip组件后缀图标包含两类:系统默认关闭图标、自定义suffixIcon后缀图标。 通过组件配置项可统一关闭后缀图标展示,实现仅前缀图标文字的…...

3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南
3步解锁Beyond Compare 5专业版:Python密钥生成器终极指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期而烦恼吗?想免费使用这款强…...

工业设备数据采集太难?这款.NET8边缘网关,轻松搞定多协议对接
🌈前言如今工业数字化、智能化转型脚步越来越快,工厂现场各类 PLC、仪表、传感器设备型号繁杂,通信协议五花八门,设备数据采集难、协议对接繁琐、多设备统一管控麻烦,一直是很多制造企业、工控从业者头疼的实际问题。市…...
)
RAG 检索增强生成(全链路)
目录一、什么是RAG(Retrieval-augmented Generation)二、核心流程三、从零实战1. 环境准备2. 准备你的资料3. 代码4. 运行结果四、RAG全链路1. 文档切分(切块)2. Embedding 向量化3. 向量库存储4. 语义检索5. LLM生成回答必备5个工具(全免费&…...

蚂蚁面试实录:手撕多头注意力到LoRA配置的九个坑
面试开场:写代码,别背公式蚂蚁AI应用开发岗面试一开始,面试官没有让我复述Transformer定义,而是直接说:“用PyTorch手写一个Multi-Head Attention,讲清楚Q、K、V的维度变化。”这种考察方式在蚂蚁很常见&am…...

索尼IMX811如何重塑工业视觉与专业影像的边界
突破像素极限,定义成像新高度在影像技术飞速发展的今天,高分辨率始终是专业领域不懈追求的目标。索尼半导体解决方案公司重磅推出的IMX811中画幅CMOS图像传感器,以2.47亿有效像素的惊人规格,为行业带来了颠覆性的突破。这款传感器…...

老旧小区门禁改造:业主权益与合规指引
一、费用来源与使用规范小区门禁改造并非全部由业主自费承担,可按合规渠道统筹资金,优先使用公共补贴与专项维修资金。资金使用优先级:政府老旧小区改造财政补贴>住宅专项维修资金>业主自筹财政补贴:老旧小…...

Seraphine终极指南:英雄联盟免费智能助手,5分钟提升排位胜率15%
Seraphine终极指南:英雄联盟免费智能助手,5分钟提升排位胜率15% 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为英雄联盟排位赛中的战绩查询和BP决策烦恼吗?Seraphin…...

淮南家长必看:淮南哪里学少儿编程靠谱?原来这样选才不踩坑。
说实话,很多淮南家长送孩子学编程,心里是没底的。因为编程不像钢琴、画画,能当场弹一首或画一张给你看。孩子到底学了啥、学得怎么样,家长往往两眼一抹黑。今天我不推荐任何一家机构,只跟你分享三个普通人一眼就能看懂…...

Delft3D建模、水动力模拟方法及地表水环境影响评价:岸线绘制与导入、非结构化计算网格生成、水下地形数据处理等前处理操作;水动力与污染物对流扩散模拟的参数设置、边界条件设定及模型率定验证
查看原文>>>https://mp.weixin.qq.com/s/_CiPDK_oXaAGxVfu2qk6ew 前言 本文以地表水数值模拟软件Delft3D 4.03.00操作为主要内容,强调地表水水动力建模、基础资料的获取、边界条件设定、模型率定和验证、数据分析和处理等关键环节。通过对案例模型的实操…...