MongoDB中的嵌套List操作
前言
MongoDB区别Mysql的地方,就是MongoDB支持文档嵌套,比如最近业务中就有一个在音频转写结果中进行对话场景,一个音频中对应多轮对话,这些音频数据和对话信息就存储在MongoDB中文档中。集合结构大致如下
{"_id":23424234234324234,"audioId": 2689944,"contextId": "cht000d24ab@dx187d1168a449a4b540","dialogues": [{"ask": "今天是礼拜天?","answer": "是的","createTime": 1697356990966}, {"ask": "你也要加油哈","answer": "奥利给!","createTime": 1697378011483}, {"ask": "下周见","answer": "拜拜!","createTime": 1697378072063}]
}下面简单介绍几个业务中用到的简单操作。
查询嵌套List的长度大小
public Integer getDialoguesSize(Long audioId) {Integer datasSize = 0;List<Document> group = Arrays.asList(new Document("$match",new Document("audioId",new Document("$eq", audioId))), new Document("$match",new Document("dialogues",new Document("$exists", true))), new Document("$project",new Document("datasSize",new Document("$size", "$dialogues"))));AggregateIterable<Document> aggregate = generalCollection.aggregate(group);Document document = aggregate.first();if (document != null) {datasSize = (Integer) document.get("datasSize");}return datasSize;}根据嵌套List中属性查询
下面的代码主要查询指定audioId中的dialogues集合中小于createTime,并且根据limit分页查询,这里用到了MongoDB中的Aggregates和unwind来进行聚合查询,具体使用细节,可以参见MongoDB官方文档
public AIDialoguesResultDTO queryAiResult(Long audioId, Long createTime, Integer limit) {AIDialoguesResultDTO aiDialoguesResultDTO = new AIDialoguesResultDTO();List<Bson> pipeline = Arrays.asList(Aggregates.match(Filters.eq("audioId", audioId)),Aggregates.unwind("$dialogues"),Aggregates.match(Filters.lt("dialogues.createTime", createTime)),Aggregates.sort(Sorts.descending("dialogues.createTime")),Aggregates.limit(limit));AggregateIterable<Document> aggregate = generalCollection.aggregate(pipeline);List<AIDialoguesResult> aiDialoguesResultList = new ArrayList<>();String contextId = Constant.EMPTY_STR;for (Document document : aggregate) {AIDialoguesResult aiDialoguesResult = new AIDialoguesResult();List<String> key = Collections.singletonList("dialogues");aiDialoguesResult.setAnswer(document.getEmbedded(key, Document.class).getString("answer"));aiDialoguesResult.setAsk(document.getEmbedded(key, Document.class).getString("ask"));aiDialoguesResult.setCreateTime(document.getEmbedded(key, Document.class).getLong("createTime"));aiDialoguesResultList.add(aiDialoguesResult);contextId = document.getString("contextId");}if (!CollectionUtils.isEmpty(aiDialoguesResultList)) {aiDialoguesResultList = aiDialoguesResultList.stream().sorted(Comparator.comparingLong(AIDialoguesResult::getCreateTime)).collect(Collectors.toList());}aiDialoguesResultDTO.setCount(aiDialoguesResultList.size());aiDialoguesResultDTO.setContextId(contextId);aiDialoguesResultDTO.setResult(aiDialoguesResultList);return aiDialoguesResultDTO;}当然,我们还有一种比较简单的写法
public AIDialoguesResultDTO queryAiResultBackupVersion(Long audioId, Long createTime, Integer limit) {Bson query = and(eq("audioId", audioId));AITextResult aiTextResult = mongoDao.findSingle(query, AITextResult.class);AIDialoguesResultDTO aiDialoguesResultDTO = new AIDialoguesResultDTO();if (Objects.isNull(aiTextResult)) {aiDialoguesResultDTO.setResult(Collections.emptyList());aiDialoguesResultDTO.setCount(0);aiDialoguesResultDTO.setContextId("");}List<AIDialoguesResult> aiDialoguesResultList = aiTextResult.getDialogues();if (CollectionUtils.isEmpty(aiDialoguesResultList)) {return aiDialoguesResultDTO;}Long finalCreateTime = createTime;List<AIDialoguesResult> afterFilterAiDialoguesResultList =aiDialoguesResultList.stream().filter(t -> t.getCreateTime()< finalCreateTime).sorted(Comparator.comparingLong(AIDialoguesResult::getCreateTime).reversed()).limit(limit).collect(Collectors.toList());if (CollectionUtils.isEmpty(afterFilterAiDialoguesResultList)) {aiDialoguesResultDTO.setCount(0);} else {aiDialoguesResultDTO.setCount(afterFilterAiDialoguesResultList.size());}afterFilterAiDialoguesResultList = afterFilterAiDialoguesResultList.stream().sorted(Comparator.comparingLong(AIDialoguesResult::getCreateTime)).collect(Collectors.toList());aiDialoguesResultDTO.setResult(afterFilterAiDialoguesResultList);aiDialoguesResultDTO.setContextId(aiTextResult.getContextId());return aiDialoguesResultDTO;}上面这种写法比较直接,就是直接audioId进行匹配查询, 然后将当前文档中的dialogues全部加载到内存中,然后在内存中进行排序,分页返回,显然如果dialogues集合长度很大,对内存占用会比较高。
嵌套List的增量追加
对于dialogues数组,如果我们要向dialogues追加元素,我们可以把audioId对应的dialogues全部取出来,然后在List后面追加一个元素,大致代码如下
public void saveAiResult(SaveAIResultDTO saveAIResultDTO) {Long audioId = saveAIResultDTO.getAudioId();Bson filter = Filters.eq("audioId", audioId);AITextResult aiTextResult = mongoDao.findSingle(filter, AITextResult.class);if (Objects.isNull(aiTextResult)) {aiTextResult = AITextResult.buildAiTextResult(saveAIResultDTO);mongoDao.saveOrUpdate(aiTextResult);return;}List<AIDialoguesResult> aiDialoguesResults = aiTextResult.getDialogues();AIDialoguesResult aiDialoguesResult = new AIDialoguesResult();aiDialoguesResult.setCreateTime(new Date().getTime());aiDialoguesResult.setAsk(saveAIResultDTO.getAsk());aiDialoguesResult.setAnswer(saveAIResultDTO.getAnswer());aiDialoguesResults.add(aiDialoguesResult);aiTextResult.setDialogues(aiDialoguesResults);mongoDao.saveOrUpdate(aiTextResult);}上面这种写法本身没有什么问题,但是如果dialogues集合大小比较大,每次追加都将dialogues全部取出来进行追加操作,可能比较占用内存,我们可以利用MongoDB中的push操作,直接追加
public void saveAiResultIncremental(SaveAIResultDTO saveAIResultDTO) {Long audioId = saveAIResultDTO.getAudioId();Document query = new Document("audioId", audioId);Bson projection = Projections.fields(Projections.include("contextId"), Projections.excludeId());FindIterable<Document> result = generalCollection.find(query).projection(projection);AITextResult aiTextResult;if (!result.iterator().hasNext()) {aiTextResult = AITextResult.buildAiTextResult(saveAIResultDTO);mongoDao.saveOrUpdate(aiTextResult);return;}AIDialoguesResult aiDialoguesResult = new AIDialoguesResult();aiDialoguesResult.setCreateTime(new Date().getTime());aiDialoguesResult.setAsk(saveAIResultDTO.getAsk());aiDialoguesResult.setAnswer(saveAIResultDTO.getAnswer());Bson update = push("dialogues", aiDialoguesResult);Bson filter = Filters.eq("audioId", audioId);generalCollection.updateOne(filter, update);}总结
既然选择了MongoDB,就不能继续沿用Mysql的查询风格,要学会利用MongoDB的特性,否则往往达不到预期效果。
相关文章:

MongoDB中的嵌套List操作
前言 MongoDB区别Mysql的地方,就是MongoDB支持文档嵌套,比如最近业务中就有一个在音频转写结果中进行对话场景,一个音频中对应多轮对话,这些音频数据和对话信息就存储在MongoDB中文档中。集合结构大致如下 {"_id":234…...
【C#】什么是并发,C#常规解决高并发的基本方法
给自己一个目标,然后坚持一段时间,总会有收获和感悟! 在实际项目开发中,多少都会遇到高并发的情况,有可能是网络问题,连续点击鼠标无反应快速发起了N多次调用接口, 导致极短时间内重复调用了多次…...
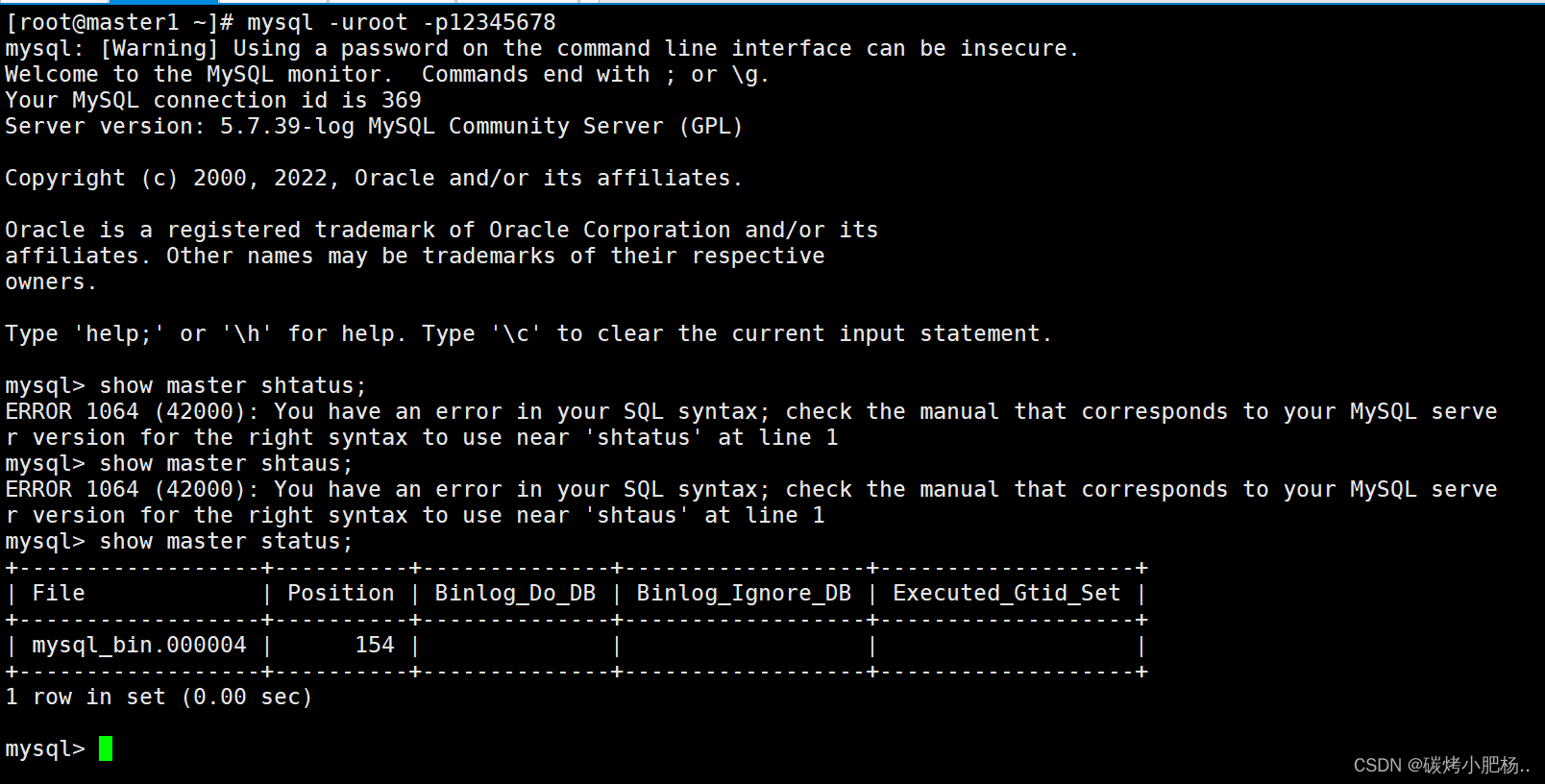
MySQL双主一从高可用
MySQL双主一从高可用 文章目录 MySQL双主一从高可用环境说明1.配置前的准备工作2.配置yum源 1.在部署NFS服务2.安装主数据库的数据库服务,并挂载nfs3.初始化数据库4.配置两台master主机数据库5.配置m1和m2成为主数据库6.安装、配置keepalived7.安装部署从数据库8.测…...

#力扣:2894. 分类求和并作差@FDDLC
2894. 分类求和并作差 - 力扣(LeetCode) 一、Java class Solution {public int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn/m*m)/2;} } 二、C class Solution { public:int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn…...
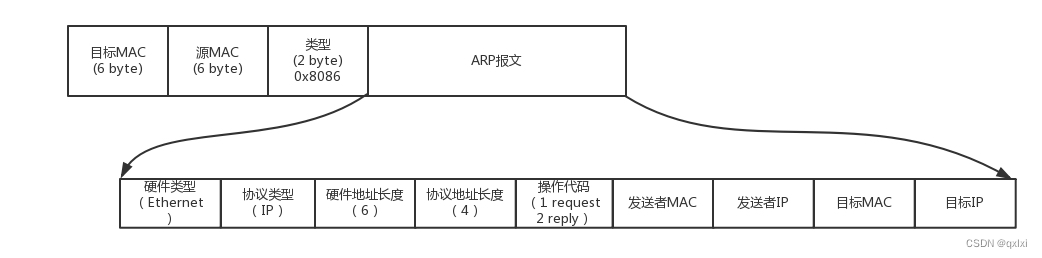
【网络协议】聊聊从物理层到MAC层 ARP 交换机
物理层 物理层其实就是电脑、交换器、路由器、光纤等。组成一个局域网的方式可以使用集线器。可以将多台电脑连接起来,然后进行将数据转发给别的端口。 数据链路层 Hub其实就是广播模式,如果A电脑发出一个包,B、C电脑也可以收到。那么数据…...
WordPress插件 WP-PostViews 汉化语言包
WP-PostViews汉化语言包 WP-PostViews是一款很受欢迎的文章浏览次数统计插件,记录每篇文章展示次数、根据展示次数显示历史最热或最衰的文章排行、展示范围可以是全部文章和页面,也可以是某些目录下的文章和页面。本文还介绍了一些隐藏的功能࿰…...
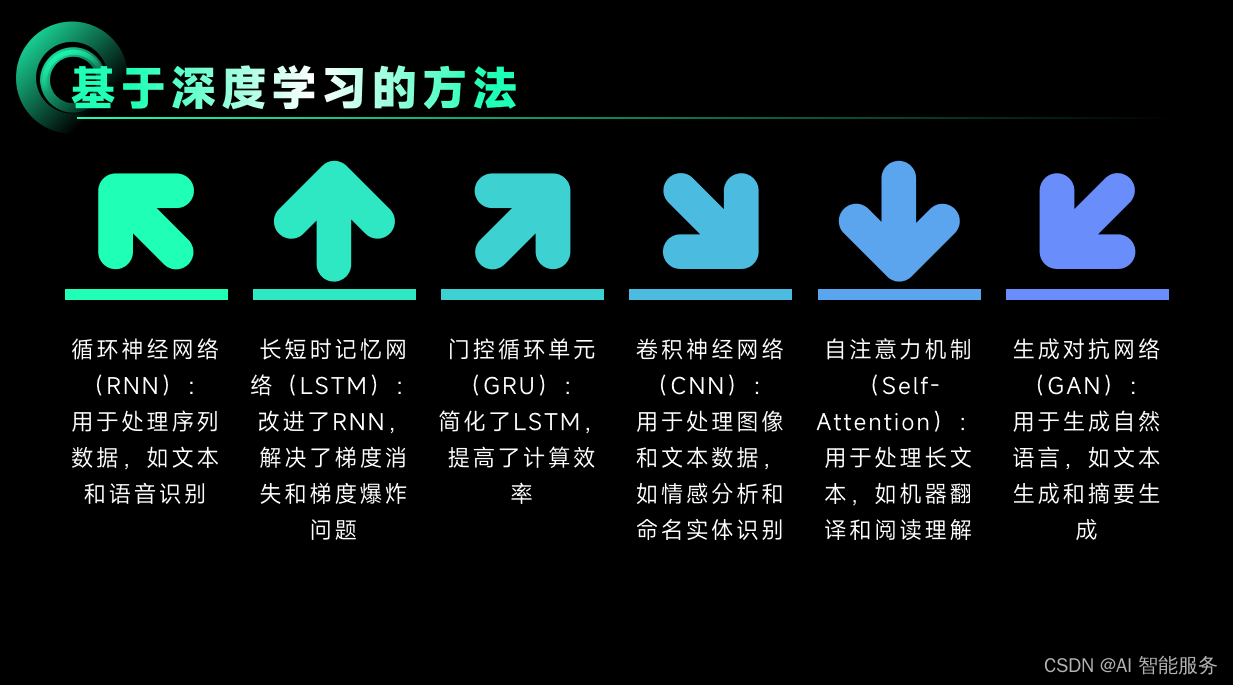
基础课2——自然语言处理
1.概念 自然语言处理(Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。 自然语言处理的主要研究方向包括: 语言学研究&…...

有趣的GPT指令
1 从现在开始,你的回答必须把所有字替换emoji,并保持原来的含义。你不能使用任何汉字或英文。如果有不适当的词语,将它们替换成对应的emoji。下面是一个例子: 原文:爷吐啦 翻译:👴ὃ…...

小样本学习--(1)概论
目录 一、概述 二、小样本学习的数据集 1、Omniglot 2、MiniimageNet 三、孪生网络 四、三元组损失函数 一、概述 小样本学习用于处理训练数据集中样本数量少的情况,一般来说,小样本学习流程是这样的,从一个多种类少量样本的巨大数据集…...
数据结构之手撕顺序表(讲解➕源代码)
0.引言 在本章之后,就要求大家对于指针、结构体、动态开辟等相关的知识要熟练的掌握,如果有小伙伴对上面相关的知识还不是很清晰,要先弄明白再过来接着学习哦! 那进入正题,在讲解顺序表之前,我们先来介绍…...

小微企业是怎样从客户管理系统中获益的?
大企业普遍拥有成熟的客户管理系统,而对小微企业而言,客户管理系统的重要性更为突出。这是因为小微企业管理相对薄弱,资源有限,人力资金需要更加精细化的管理。那么,小微企业如何从客户管理系统中获益? 一…...

mysql整库备份表结构和数据
命令 mysqldump -P 端口 -h 主机 -u 用户名 -p 数据库 > xxxxbak.sql 将导出数据库的表结构及数据(建表语句和insert语句) 举例 mysqldump -P 3306 -h 100.120.56.23 -u my_username-p sys > system-230510.sql...
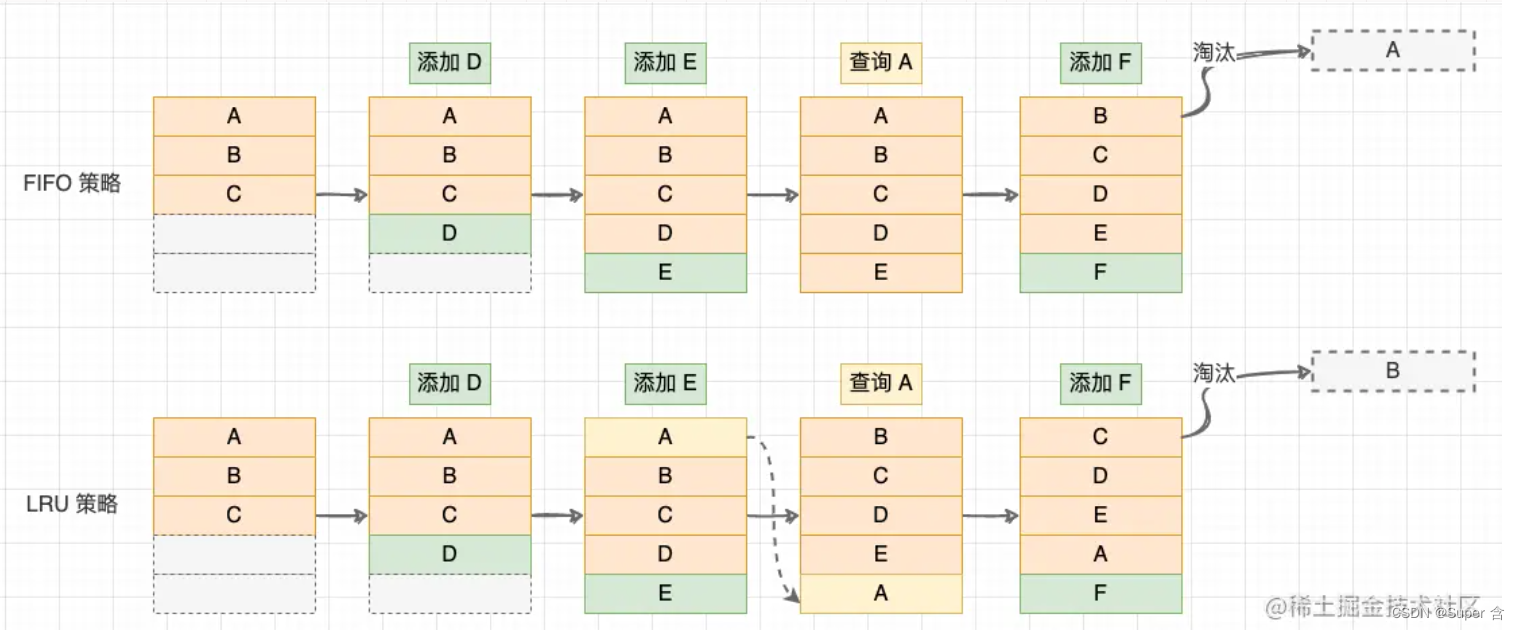
LinkedHashMap与LRU缓存
序、慢慢来才是最快的方法。 背景 LinkedHashMap 是继承于 HashMap 实现的哈希链表,它同时具备双向链表和散列表的特点。事实上,LinkedHashMap 继承了 HashMap 的主要功能,并通过 HashMap 预留的 Hook 点维护双向链表的逻辑。 1.缓存淘汰算法…...

2023大联盟6比赛总结
比赛链接 反思 A 为什么打表就我看不出规律!!! 定式思维太严重了T_T B 纯智障分块题,不知道为什么 B 100 B100 B100 比理论最优 B 300 B300 B300 更优(快了 3 倍),看来分块还是要学习一…...
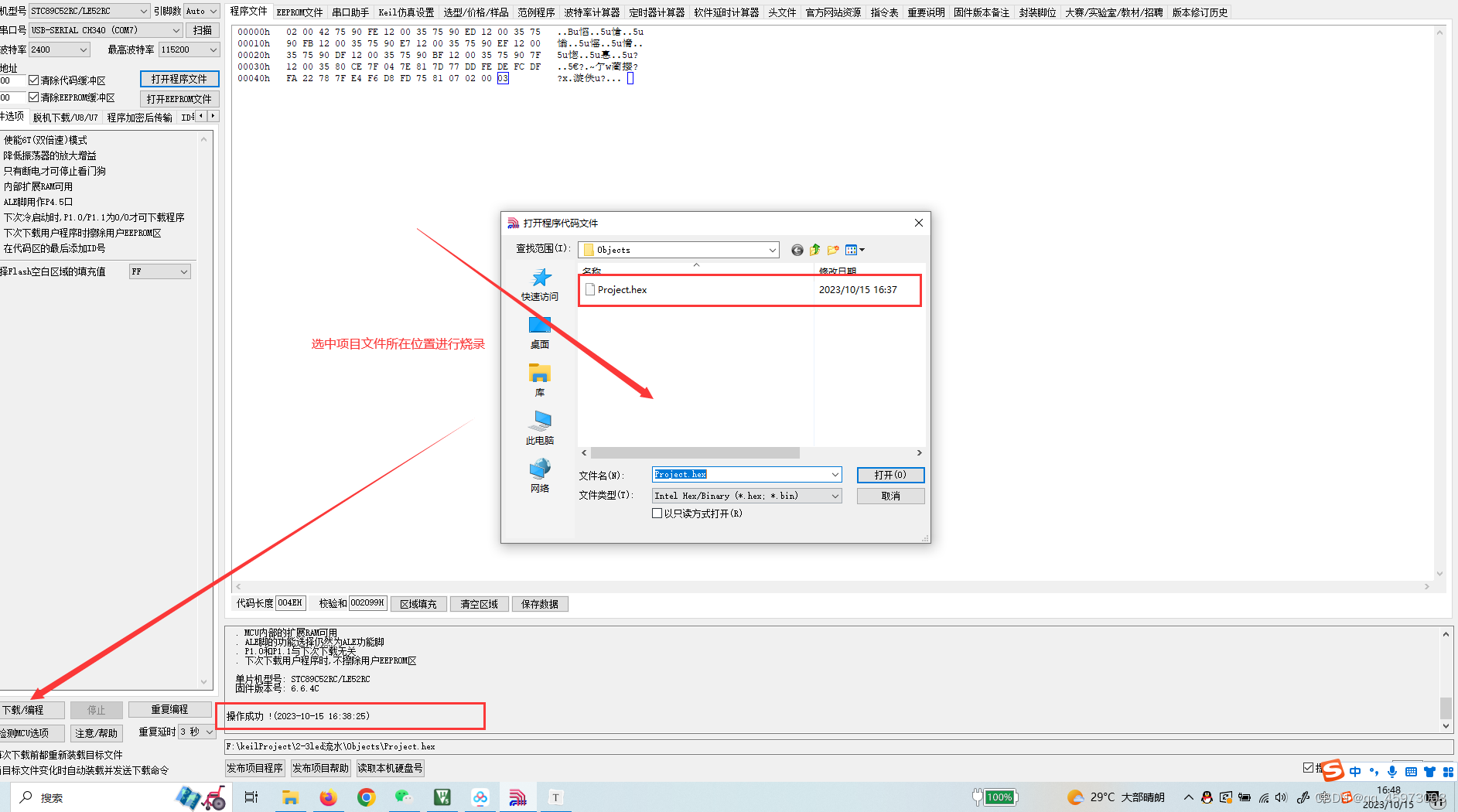
05_51单片机led流水线的实现
1:step创建一个新的项目并将程序烧录进入51单片机 以下是51单片机流水线代码的具体实现 #include <REGX52.H>void Delay500ms() //11.0592MHz {unsigned char i, j, k;i 4;j 129;k 119;do{do{while (--k);} while (--j);} while (--i); }void main(){while(1){P1 0…...
Java系列 | 如何讲自己的JAR包上传至阿里云maven私有仓库【云效制品仓库】
什么是云效 云效是云原生时代一站式 BizDevOps 平台,产研数字化同行者,支持公共云、专有云和混合云多种部署形态,通过云原生新技术和研发新模式,助力创新创业和数字化转型企业快速实现产研数字化,打造“双敏”组织&…...

小程序技术加速信创操作系统国产化替换
随着信息技术的不断发展,信息技术应用创新(简称“信创”)已经成为了当今企业数字化转型的重要趋势之一。信创是指在信息技术领域,以自主可控的国产软硬件产品和服务为核心,构建起一套完整的信息技术生态体系࿰…...
免费:实时 AI 编程助手 Amazon CodeWhisperer
点 ,一起程序员弯道超车之路 现已正式推出实时 AI 编程助手 Amazon CodeWhisperer,包括 CodeWhisperer 个人套餐,所有开发人员均可免费使用。最初于去年推出的预览版 CodeWhisperer 让开发人员能够保持专注、高效,帮助他们快速、安…...

面试准备-深入理解计算机系统-信息的表示与处理1
浮点运算是不可结合的(由于表示的精度有限)。比如(3.141e20)-1e20是0.0而3.14(1e20-1e20)是3.14。整数虽然只能编码一个较小的取值范围,但是是准确的;浮点数虽然能编码更大的范围,但是是近似的。 二进制转十六进制转换…...

搭建Atlas2.2.0 集成CDH6.3.2 生产环境+kerberos
首先确保环境的干净,如果之前有安装过清理掉相关残留 确保安装atlas的服务器有足够的内存(至少16G),有必要的hadoop角色 HDFS客户端 — 检索和更新Hadoop使用的用户组信息(UGI)中帐户成员资格的信息。对调…...

告别无效熬夜!10 款 AI 毕业论文工具实测,解锁高效通关路径
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 打开 Word 文档盯着空白页面发呆,开题报告改了五版还是被导师打回,文献综述翻遍知网也理不…...

深入RKMedia:拆解Rockchip RV1126多媒体框架,看它如何封装RGA/MPP/RKNN
深入解析RKMedia:Rockchip RV1126多媒体框架的设计哲学与实现细节 在嵌入式多媒体处理领域,Rockchip的RV1126平台凭借其出色的能效比和丰富的硬件加速单元,成为智能视觉终端设备的首选方案之一。而RKMedia作为连接应用层与底层硬件的关键中间…...

从0到1:产品经理如何构建高效的产品管理体系
现如今,在数字化浪潮把全球都给席卷的这种状况之下,产品已然变成了企业竞争的核心载体。对于一个优秀的产品来讲,其背后通常是没办法离开一套科学且高效的产品管理体系的。产品管理,它作为连接用户需求、商业目标以及技术实现的枢…...

SeekStorm PDF文档搜索指南:从文件解析到全文索引的完整流程
SeekStorm PDF文档搜索指南:从文件解析到全文索引的完整流程 【免费下载链接】SeekStorm SeekStorm: vector & lexical search - in-process library & multi-tenancy server, in Rust. 项目地址: https://gitcode.com/gh_mirrors/se/SeekStorm Seek…...

Fansly下载器完整指南:3分钟掌握免费离线下载技巧
Fansly下载器完整指南:3分钟掌握免费离线下载技巧 【免费下载链接】fansly-downloader Easy to use fansly.com content downloading tool. Written in python, but ships as a standalone Executable App for Windows too. Enjoy your Fansly content offline anyt…...

ReTerraForged终极指南:5步打造专业级Minecraft地形生成体验
ReTerraForged终极指南:5步打造专业级Minecraft地形生成体验 【免费下载链接】ReTerraForged TerraForged for modern MC versions 项目地址: https://gitcode.com/gh_mirrors/re/ReTerraForged ReTerraForged是一款专为现代Minecraft版本设计的革命性地形生…...

汽车供应链客户定位方法拆解:复杂B2B能力如何被客户看懂
从B2B表达方法看,汽车供应链客户定位可以理解为一个“客户判断结构化”的问题。企业不是简单输出自我介绍,而是要把技术能力、项目经验、质量体系、协同机制与证据材料,转化为客户不同角色都能使用的判断信息。很多汽车供应商在做客户定位时&…...

魔百盒CM311-1s刷机后体验:安卓9.0固件到底香不香?附5621DS无线实测
魔百盒CM311-1s刷机实战:安卓9.0系统深度评测与无线性能揭秘 当手中的魔百盒CM311-1s遇上安卓9.0系统,这场硬件与软件的碰撞会擦出怎样的火花?作为一款搭载S905L3B芯片的电视盒子,其原生系统往往受限于运营商定制化限制࿰…...

别再死记硬背了!COBOL中COMP、COMP-3、COMP-5数据类型的区别与实战赋值避坑指南
COBOL数值类型实战手册:COMP家族的内存布局与精准赋值策略 在金融核心系统维护中,我曾目睹过因COMP-3类型使用不当导致整月利息计算误差达六位数的生产事故。这种"古董级"数据类型的独特设计,至今仍在每秒处理数百万交易的银行系统…...

基于STM32的智能空调控制器设计:从环境感知到PID控制
1. 项目概述:从传统遥控到智能感知的跨越几年前,我还在为一个老旧的壁挂式空调发愁。每次回家,都得在闷热的房间里摸索遥控器,或者忍受着固定风向的直吹。后来接触了智能家居,发现市面上的智能空调要么价格昂贵&#x…...