竞赛 深度学习YOLO安检管制物品识别与检测 - python opencv
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 卷积神经网络
- 4 Yolov5
- 5 模型训练
- 6 实现效果
- 7 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习YOLO安检管制误判识别与检测 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
军事信息化建设一直是各国的研究热点,但我国的武器存在着种类繁多、信息散落等问题,这不利于国防工作提取有效信息,大大妨碍了我军信息化建设的步伐。同时,我军武器常以文字、二维图片和实体武器等传统方式进行展示,交互性差且无法满足更多军迷了解武器性能、近距离观赏或把玩武器的迫切需求。本文将改进后的Yolov5算法应用到武器识别中,将武器图片中的武器快速识别出来,提取武器的相关信息,并将其放入三维的武器展现系统中进行展示,以期让人们了解和掌握各种武器,有利于推动军事信息化建设。
2 实现效果
检测展示

3 卷积神经网络
简介
卷积神经网络 (CNN)
是一种算法,将图像作为输入,然后为图像的所有方面分配权重和偏差,从而区分彼此。神经网络可以通过使用成批的图像进行训练,每个图像都有一个标签来识别图像的真实性质(这里是猫或狗)。一个批次可以包含十分之几到数百个图像。
对于每张图像,将网络预测与相应的现有标签进行比较,并评估整个批次的网络预测与真实值之间的距离。然后,修改网络参数以最小化距离,从而增加网络的预测能力。类似地,每个批次的训练过程都是类似的。

相关代码实现
cnn卷积神经网络的编写如下,编写卷积层、池化层和全连接层的代码
conv1_1 = tf.layers.conv2d(x, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_1')
conv1_2 = tf.layers.conv2d(conv1_1, 16, (3, 3), padding='same', activation=tf.nn.relu, name='conv1_2')
pool1 = tf.layers.max_pooling2d(conv1_2, (2, 2), (2, 2), name='pool1')
conv2_1 = tf.layers.conv2d(pool1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_1')
conv2_2 = tf.layers.conv2d(conv2_1, 32, (3, 3), padding='same', activation=tf.nn.relu, name='conv2_2')
pool2 = tf.layers.max_pooling2d(conv2_2, (2, 2), (2, 2), name='pool2')
conv3_1 = tf.layers.conv2d(pool2, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_1')
conv3_2 = tf.layers.conv2d(conv3_1, 64, (3, 3), padding='same', activation=tf.nn.relu, name='conv3_2')
pool3 = tf.layers.max_pooling2d(conv3_2, (2, 2), (2, 2), name='pool3')
conv4_1 = tf.layers.conv2d(pool3, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_1')
conv4_2 = tf.layers.conv2d(conv4_1, 128, (3, 3), padding='same', activation=tf.nn.relu, name='conv4_2')
pool4 = tf.layers.max_pooling2d(conv4_2, (2, 2), (2, 2), name='pool4')flatten = tf.layers.flatten(pool4)
fc1 = tf.layers.dense(flatten, 512, tf.nn.relu)
fc1_dropout = tf.nn.dropout(fc1, keep_prob=keep_prob)
fc2 = tf.layers.dense(fc1, 256, tf.nn.relu)
fc2_dropout = tf.nn.dropout(fc2, keep_prob=keep_prob)
fc3 = tf.layers.dense(fc2, 2, None)
4 Yolov5
我们选择当下YOLO最新的卷积神经网络YOLOv5来进行火焰识别检测。6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布不到50天。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region
proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种
one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。YOLO
一共发布了五个版本,其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
YOLOv5有4个版本性能如图所示:

网络架构图

YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端
在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
Mosaic数据增强
:Mosaic数据增强的作者也是来自YOLOv5团队的成员,通过随机缩放、随机裁剪、随机排布的方式进行拼接,对小目标的检测效果很不错

基准网络
融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。Yolov5中添加了FPN+PAN结构,相当于目标检测网络的颈部,也是非常关键的。


FPN+PAN的结构

这样结合操作,FPN层自顶向下传达强语义特征(High-Level特征),而特征金字塔则自底向上传达强定位特征(Low-
Level特征),两两联手,从不同的主干层对不同的检测层进行特征聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
Head输出层
输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
对于Head部分,可以看到三个紫色箭头处的特征图是40×40、20×20、10×10。以及最后Prediction中用于预测的3个特征图:
①==>40×40×255②==>20×20×255③==>10×10×255

-
相关代码
class Detect(nn.Module):stride = None # strides computed during build onnx_dynamic = False # ONNX export parameterdef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].deviceif check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')else:yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()anchor_grid = (self.anchors[i].clone() * self.stride[i]) \.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()return grid, anchor_grid
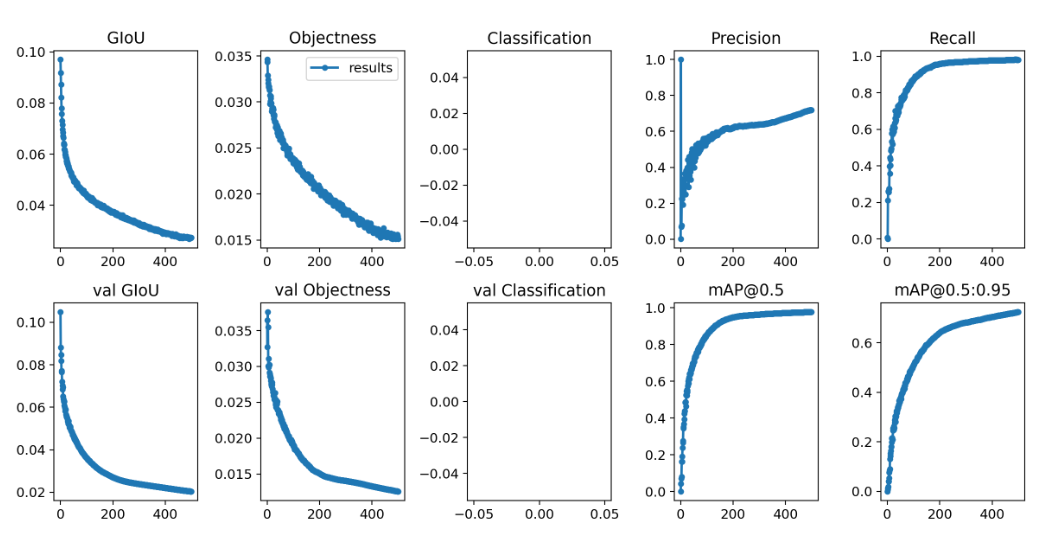
5 模型训练
训练效果如下
相关代码
#部分代码
def train(hyp, opt, device, tb_writer=None):print(f'Hyperparameters {hyp}')log_dir = tb_writer.log_dir if tb_writer else 'runs/evolve' # run directorywdir = str(Path(log_dir) / 'weights') + os.sep # weights directoryos.makedirs(wdir, exist_ok=True)last = wdir + 'last.pt'best = wdir + 'best.pt'results_file = log_dir + os.sep + 'results.txt'epochs, batch_size, total_batch_size, weights, rank = \opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.local_rank# TODO: Use DDP logging. Only the first process is allowed to log.# Save run settingswith open(Path(log_dir) / 'hyp.yaml', 'w') as f:yaml.dump(hyp, f, sort_keys=False)with open(Path(log_dir) / 'opt.yaml', 'w') as f:yaml.dump(vars(opt), f, sort_keys=False)# Configurecuda = device.type != 'cpu'init_seeds(2 + rank)with open(opt.data) as f:data_dict = yaml.load(f, Loader=yaml.FullLoader) # model dicttrain_path = data_dict['train']test_path = data_dict['val']nc, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names']) # number classes, namesassert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check# Remove previous resultsif rank in [-1, 0]:for f in glob.glob('*_batch*.jpg') + glob.glob(results_file):os.remove(f)# Create modelmodel = Model(opt.cfg, nc=nc).to(device)# Image sizesgs = int(max(model.stride)) # grid size (max stride)imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples# Optimizernbs = 64 # nominal batch size# default DDP implementation is slow for accumulation according to: https://pytorch.org/docs/stable/notes/ddp.html# all-reduce operation is carried out during loss.backward().# Thus, there would be redundant all-reduce communications in a accumulation procedure,# which means, the result is still right but the training speed gets slower.# TODO: If acceleration is needed, there is an implementation of allreduce_post_accumulation# in https://github.com/NVIDIA/DeepLearningExamples/blob/master/PyTorch/LanguageModeling/BERT/run_pretraining.pyaccumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizinghyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decaypg0, pg1, pg2 = [], [], [] # optimizer parameter groupsfor k, v in model.named_parameters():if v.requires_grad:if '.bias' in k:pg2.append(v) # biaseselif '.weight' in k and '.bn' not in k:pg1.append(v) # apply weight decayelse:pg0.append(v) # all elseif opt.adam:optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentumelse:optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decayoptimizer.add_param_group({'params': pg2}) # add pg2 (biases)print('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))del pg0, pg1,
6 实现效果

7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛 深度学习YOLO安检管制物品识别与检测 - python opencv
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络4 Yolov55 模型训练6 实现效果7 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习YOLO安检管制误判识别与检测 ** 该项目较为新颖,适合作为竞赛课题方向&…...

【华为OD机试python】斗地主之顺子【2023 B卷|100分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 在斗地主扑克牌游戏中, 扑克牌由小到大的顺序为:3,4,5,6,7,8,9,10,J,Q,K,A,2, 玩家可以出的扑克牌阵型有:单张、对子、顺子、飞机、炸弹等。 其中顺子的出牌规则为:由至少5张由小到大…...

ant design DatePicker禁用之前的时间
1、代码 <DatePicker fieldProps{disabledDate: (current: any) > {return current < moment().startOf(day);}}/>2、效果...

C语言---预处理详解
1.预定义符号 在C语言中有一些内置的预定义符号 __FILE__ __LINE__ __DATE__ __TIME__ __STDC__//进行编译的源文件 //文件当前的行号 //文件被编译的日期 //文件被编译的时间 //如果编译器遵循ANSI C,其值为1,否则未定义 编译器在__STDC__报错,说明,v…...

数组和对象有什么区别?
数组(Array)和对象(Object)是两种不同的数据结构,它们在使用和表示数据上有一些区别。 1:数组(Array): 有序集合:数组是一个有序的数据集合,每个…...
实现和解析)
顺序表(第二节)实现和解析
目录 1.顺序表中的头文件 (每一种函数方法) 2.关于typedef 的用法 3.初始化和销毁表 3.1初始化表 3.2销毁表 4.打印表 5.自动扩容表!!!(重点) 6.头部插入表和尾部插入表 6.1尾部插入表 …...
:MapReduce中的压缩)
Hadoop3教程(二十一):MapReduce中的压缩
文章目录 (123)压缩概述在Map阶段启用在Reduce阶段启用 (124)压缩案例实操如何在Map输出端启用压缩如何在Reduce端启用压缩 参考文献 (123)压缩概述 压缩也是MR中比较重要的一环,其可以应用于M…...
04、RocketMQ -- 核心基础使用
目录 核心基础使用1、入门案例生产者消费者 2、消息发送方式方式1:同步消息方式2:异步消息方式3:一次性消息管控台使用过程中可能出现的问题 3、消息消费方式集群模式(默认)广播模式 4、顺序消息分析图:代码…...

mysql中date/datetime类型自动转go的时间类型time.Time
在DSN中需要加入parseTimetrue&&locLocal,或 charsetutf8mb4&locAsia%2FShanghai&parseTimetrue。 package main_testimport ("database/sql""fmt""testing""time"_ "github.com/go-sql-driver/mysq…...
)
MATLAB算法实战应用案例精讲-【图像处理】机器视觉(基础篇)
目录 前言 几个高频面试题目 如何选择合适的面扫相机 如何选择光学滤波器 知识储备...

LDAP协议工作原理
LDAP,全称Lightweight Directory Access Protocol,译为轻量目录访问协议,是一个在互联网中广泛使用的协议,主要用于实现网络中的信息查找和检索。在身份认证方面,LDAP起着重要的作用。 LDAP的工作原理主要包括以下几个…...

【Jetpack Compose】BOM是什么?
前言 本篇旨在帮助小伙伴们了解和使用Compose中BOM相关的知识,在Compose的开发过程中更加便捷、统一的管理相关依赖信息。 BOM基础知识 Compose推出的BOM为物料清单的意思,BOM全称为Bill Of Materials,Compose推出BOM的意义旨在通过指定的…...
多域名SSL数字证书是什么呢
多域名SSL数字证书是众多SSL数字证书中最灵活的一款SSL证书产品。一般一张SSL证书只能保护一个域名,即使能保护多个域名站点,证书保护的域名类型也有限制(通配符SSL数字证书)。多域名SSL数字证书既能用一张SSL证书保护多个域名网站,又不限制域…...

杭电oj--求奇数的乘积
Problem Description 给你n个整数,求他们中所有奇数的乘积。 Input 输入数据包含多个测试实例,每个测试实例占一行,每行的第一个数为n,表示本组数据一共有n个,接着是n个整数,你可以假设每组数据必定至少存…...
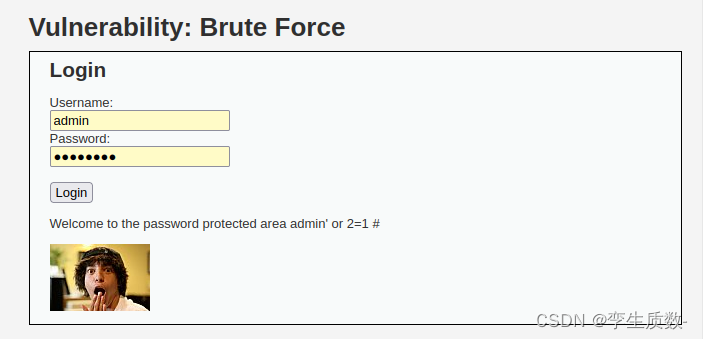
E053-web安全应用-Brute force暴力破解初级
课程分类: web安全应用 实验等级: 中级 任务场景: 【任务场景】 小王接到磐石公司的邀请,对该公司旗下的网站进行安全检测,经过一番检查发现该论坛的后台登录页面上可能存在万能密码漏洞,导致不知道账号密码也能登录后台&am…...

外汇天眼;VT Markets 赞助玛莎拉蒂MSG Racing电动方程式世界锦标赛
随着国际汽联电动方程式世界锦标赛第十赛季的到来,外汇经纪商 VT Markets 和玛莎拉蒂 MSG Racing 宣布了一项为期多年的全球合作。 外汇天眼温馨提醒:在做外汇交易之前,一定要审核清楚外汇平台的资质以及官网信息,以防上当受骗&am…...
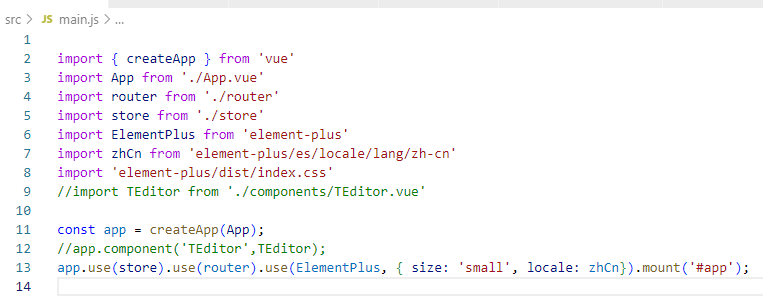
使用vscode + vite + vue3+ element3 搭建vue3脚手架
技术栈 开发工具:VSCode 代码管理:Git 前端框架:Vue3 构建工具:Vite 路由:vue-router 状态管理:vuex AJAX:axios UI库:element-ui 3 数据模拟:mockjs css预处理…...

竞赛 深度学习+opencv+python实现车道线检测 - 自动驾驶
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 YOLOV56 数据集处理7 模型训练8 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &am…...

spring boot 下载resources下的静态文件为流格式
废话不多说,直接上代码 一、下载逻辑 public void downAppApk(HttpServletResponse response){ClassPathResource classPathResource new ClassPathResource("app/xxxxxx.apk");if (!classPathResource.exists()) {throw new BusinessException("安…...

HTML渲染过程
整个渲染过程: 将 URL 对应的各种资源,通过浏览器渲染引擎的解析,输出可视化的图像。 基本概念: HTML 解释器:解析html语言、将html文本翻译成dom树; CSS 解释器:解析css语言,给…...

BetterDiscord Installer完全指南:如何一键安装和优化Discord插件
BetterDiscord Installer完全指南:如何一键安装和优化Discord插件 【免费下载链接】Installer A simple standalone program which automates the installation, removal and maintenance of BetterDiscord. 项目地址: https://gitcode.com/gh_mirrors/ins/Instal…...
:仅3款消费级卡达标,87%私有云环境需重构PCIe拓扑)
DeepSeek企业级部署GPU清单(2024Q3权威更新):仅3款消费级卡达标,87%私有云环境需重构PCIe拓扑
更多请点击: https://intelliparadigm.com 第一章:DeepSeek企业级GPU资源需求的演进逻辑与基准定义 随着DeepSeek系列大模型从开源轻量级版本(如DeepSeek-Coder-1.3B)向千亿参数级企业级推理与微调平台(如DeepSeek-VL…...

具身智能商业化提速:天问机器人六大业务板块数据全景扫描
具身智能商业化提速:天问机器人六大业务板块数据全景扫描 行业数据观察 | 2026年6月15日 武汉光谷报道 当大模型从云端"落地"到机器人身上,当人形机器人从实验室走进商场、景区、学校——2026年的具身智能产业,正在经历从"技…...

AI从业者的理财攻略:如何用AI技术实现被动收入
AI时代,软件测试从业者的新理财机遇在人工智能技术飞速发展的当下,软件测试行业正经历着深刻变革。传统的手工测试逐渐被自动化测试、AI驱动的测试所取代,这既给软件测试从业者带来了挑战,也创造了新的机遇。对于软件测试从业者而…...

北光恒电:安捷伦6812B/6813B电源不开机、输出不正常故障排查
安捷伦6812B/6813B电源作为高精度交流电源/功率分析仪,广泛应用于电源测试、UPS测试、航空电子ATE等场景,凭借稳定性能成为实验室和生产线上的核心设备。长期使用或操作不当,不开机、输出不正常等故障频发,影响测试效率。常见故障…...

Perplexity地理信息查询性能断崖式下跌?20年GIS架构师曝出隐藏瓶颈:HTTP/2连接复用失效+TLS 1.3握手阻塞链
更多请点击: https://codechina.net 第一章:Perplexity地理信息查询性能断崖式下跌现象全景透视 近期多个生产环境观测到,Perplexity模型在处理含经纬度坐标、行政区划嵌套(如“北京市朝阳区三里屯街道附近500米内POI”ÿ…...

别再死磕原生OpenStack了!华为云Stack HCS 8.0的极简部署与高可用设计,真香!
华为云Stack HCS 8.0:企业私有云部署的革命性突破 当企业IT架构师面对私有云平台选型时,部署复杂性和系统可靠性往往成为最令人头疼的两大难题。原生OpenStack以其高度灵活性和开源特性吸引了大量技术团队,但随之而来的却是漫长的部署周期、繁…...

阿西米尼常见副作用血小板减少及高血压的临床特征与管理
血小板减少与高血压是阿西米尼治疗慢性髓性白血病时患者报告频率最高的两项不良反应。两项副作用虽极少直接危及生命,却实实在在地影响着患者的日常功能与长期治疗依从性。ASCEMBL三期临床试验及其长期扩展研究的完整安全性数据,为这两项副作用勾勒出了精…...

STM32F030硬件I2C避坑指南:Timing值、滤波器配置与NBYTES重加载模式详解
STM32F030硬件I2C避坑指南:Timing值、滤波器配置与NBYTES重加载模式详解 1. 深入理解I2C_Timing寄存器的计算逻辑 许多开发者在使用STM32F030硬件I2C时,往往直接套用CubeMX生成的默认值或网络上的示例代码,却对I2C_Timing寄存器的底层计算原理…...
)
学术论文翻译翻车重灾区!Perplexity翻译查询功能如何通过引用锚点保留+LaTeX公式智能隔离实现零失真输出(仅限Pro+订阅用户可见的隐藏模式)
更多请点击: https://intelliparadigm.com 第一章:学术论文翻译翻车重灾区的底层归因分析 学术论文翻译失准并非偶然现象,其背后存在系统性语言学、认知科学与工程实践三重张力。当非母语研究者依赖通用大模型或词典式工具进行技术文本转译时…...