python的搜索引擎系统设计与实现 计算机竞赛
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 python的搜索引擎系统设计与实现
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:5分
- 创新点:3分
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题简介
随着互联网和宽带上网的普及, 搜索引擎在中国异军突起, 并日益渗透到人们的日常生活中, 在互联网普及之前,
人们查阅资料首先想到的是拥有大量书籍的资料的图书馆。 但是今天很多人都会选择一种更方便、 快捷、 全面、 准确的查阅方式–互联网。
而帮助我们在整个互联网上快速地查找到目标信息的就是越来越被重视的搜索引擎。
今天学长来向大家介绍如何使用python写一个搜索引擎,该项目常用于毕业设计
2 系统设计实现
2.1 总体设计
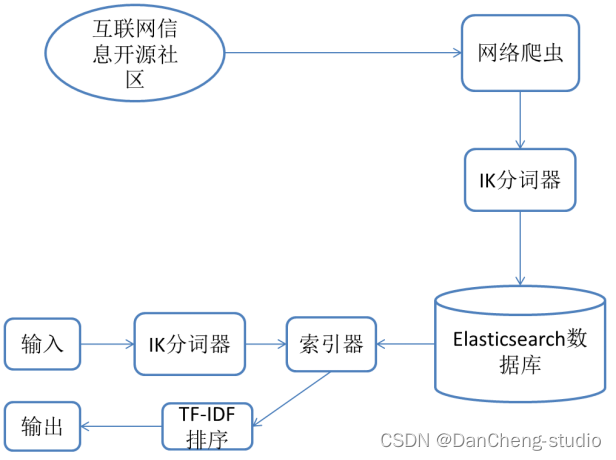
学长设计的系统采用的是非关系型数据库Elasticsearch,因此对于此数据库的查询等基本操作会加以图例的方式进行辅助阐述。在使用者开始进行査询时,系统不可能把使用者输入的关键词与所有本地数据进行匹配,这种检索方式即便建立索引,查询效率仍然较低,而且非常消耗服务器资源。
因此,Elasticsearch将获取到的数据分为两个阶段进行处理。第一阶段:采用合适的分词器,将获取到的数据按照分词器的标准进行分词,第二阶段:对每个关键词的频率以及出现的位置进行统计。
经过以上两个阶段,最后每个词语具体出现在哪些文章中,出现的位置和频次如何,都将会被保存到Elasticsearch数据库中,此过程即为构建倒排索引,需要花费的计算开销很大,但大大提高了后续检索的效率。其中,搜索引擎的索引过程流程图如图

2.2 搜索关键流程
如图所示,每一位用户在搜索框中输入关键字后,点击搜索发起搜索请求,系统后台解析内容后,将搜索结果返回到查询结果页,用户可以直接点击查询结果的标题并跳转到详情页,也可以点击下一页查看其他页面的搜索结果,也可以选择重新在输入框中输入新的关键词,再次发起搜索。
跳转至不同结果页流程图:
浏览具体网页信息流程图:
搜索功能流程图:

2.3 推荐算法
用户可在平台上了解到当下互联网领域中的热点内容,点击文章链接后即可进入到对应的详情页面中,浏览选中的信息的目标网页,详细了解其中的内容。丰富了本搜索平台提供信息的实时性,如图
用户可在搜索引擎首页中浏览到系统推送的可能感兴趣的内容,同时用户可点击推送的标题进入具体网页进行浏览详细内容。流程图如图

2.4 数据流的实现
学长设计的系统的数据来源主要是从发布互联网专业领域信息的开源社区上爬虫得到。
再经过IK分词器对获取到的标题和摘要进行分词,再由Elasticsearch建立索引并将数据持久化。
用户通过输入关键词,点击检索,后台程序对获得的关键词再进行分词处理,再到数据库中进行查找,将满足条件的网页标题和摘要用超链接的方式在浏览器中显示出来。
3 实现细节
3.1 系统架构
搜索引擎有基本的五大模块,分别是:
- 信息采集模块
- 信息处理模块
- 建立索引模块
- 查询和 web 交互模块
学长设计的系统目的是在信息处理分析的基础上,建立一个完整的中文搜索引擎。
所以该系统主要由以下几个详细部分组成:
- 爬取数据
- 中文分词
- 相关度排序
- 建立web交互。
3.2 爬取大量网页数据
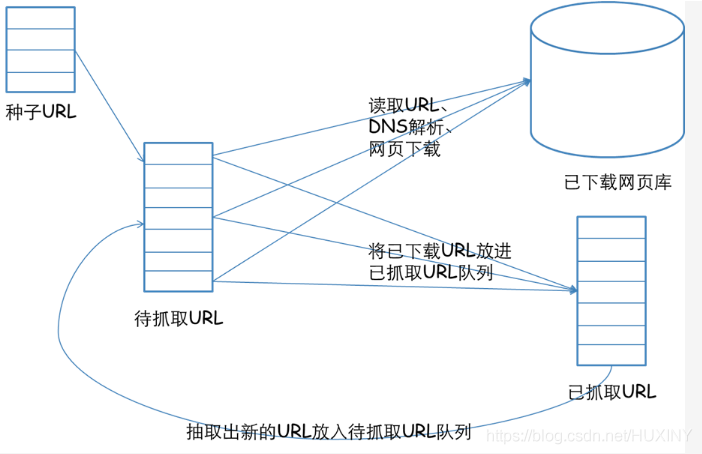
爬取数据,实际上用的就是爬虫。
我们平时在浏览网页的时候,在浏览器里输入一个网址,然后敲击回车,我们就会看到网站的一些页面,那么这个过程实际上就是这个浏览器请求了一些服务器然后获取到了一些服务器的网页资源,然后我们看到了这个网页。
请求呢就是用程序来实现上面的过程,就需要写代码来模拟这个浏览器向服务器发起请求,然后获取这些网页资源。那么一般来说实际上获取的这些网页资源是一串HTML代码,这里面包含HTML标签,还有一
我们写完程序之后呢就让它一直运行着,它就能代替我们浏览器来向服务器发送请求,然后一直不停的循环的运行进行批量的大量的获取数据了,这就是爬虫的一个基本的流程。
一个通用的网络爬虫的框架如图所示:
这里给出一段爬虫,爬取自己感兴趣的网站和内容,并按照固定格式保存起来:
# encoding=utf-8
# 导入爬虫包
from selenium import webdriver
# 睡眠时间
import time
import re
import os
import requests
# 打开编码方式utf-8打开
# 睡眠时间 传入int为休息时间,页面加载和网速的原因 需要给网页加载页面元素的时间def s(int):time.sleep(int)
# html/body/div[1]/table/tbody/tr[2]/td[1]/input
# http://dmfy.emindsoft.com.cn/common/toDoubleexamp.do
if __name__ == '__main__':#查询的文件位置# fR = open('D:\\test.txt','r',encoding = 'utf-8')# 模拟浏览器,使用谷歌浏览器,将chromedriver.exe复制到谷歌浏览器的文件夹内chromedriver = r"C:\\Users\\zhaofahu\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe"# 设置浏览器os.environ["webdriver.chrome.driver"] = chromedriverbrowser = webdriver.Chrome(chromedriver)# 最大化窗口 用不用都行browser.maximize_window()# header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}# 要爬取的网页neirongs = [] # 网页内容response = [] # 网页数据travel_urls = []urls = []titles = []writefile = open("docs.txt", 'w', encoding='UTF-8')url = 'http://travel.yunnan.cn/yjgl/index.shtml'# 第一页browser.get(url)response.append(browser.page_source)# 休息时间s(3)# 第二页的网页数据#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()#s(3)#response.append(browser.page_source)#s(3)# 第三页的网页数据#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()#s(3)#response.append(browser.page_source)
# 3.用正则表达式来删选数据
reg = r'href="(//travel.yunnan.cn/system.*?)"'
# 从数据里爬取data。。。
# 。travel_urls 旅游信息网址
for i in range(len(response)):
travel_urls = re.findall(reg, response[i])
# 打印出来放在一个列表里for i in range(len(travel_urls)):url1 = 'http:' + travel_urls[i]urls.append(url1)browser.get(url1)content = browser.find_element_by_xpath('/html/body/div[7]/div[1]/div[3]').text# 获取标题作为文件名b = browser.page_sourcetravel_name = browser.find_element_by_xpath('//*[@id="layer213"]').texttitles.append(travel_name)print(titles)print(urls)for j in range(len(titles)):writefile.write(str(j) + '\t\t' + titles[j] + '\t\t' + str(urls[j])+'\n')s(1)browser.close()##
3.3 中文分词
中文分词使用jieba库即可
jieba 是一个基于Python的中文分词工具对于一长段文字,其分词原理大体可分为三步:
1.首先用正则表达式将中文段落粗略的分成一个个句子。
2.将每个句子构造成有向无环图,之后寻找最佳切分方案。
3.最后对于连续的单字,采用HMM模型将其再次划分。
jieba分词分为“默认模式”(cut_all=False),“全模式”(cut_all=True)以及搜索引擎模式。对于“默认模式”,又可以选择是否使用
HMM 模型(HMM=True,HMM=False)。
3.4 相关度排序
上面已经根据用户的输入获取到了相关的网址数据。
获取到的数据中rows的形式如下
[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3…),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3…)]
列表的每个元素是一个元组,每个元素的内容是urlid和每个关键词在该文档中的位置。
wordids形式为[wordid1, wordid2, wordid3…],即每个关键词所对应的单词id
我们将会介绍几种排名算法,所谓排名也就是根据各自的规则为每个链接评分,评分越好。并且最终我们会将几种排名算法综合利用起来,给出最终的排名。既然要综合利用,那么我们就要先实现每种算法。在综合利用时会遇到几个问题。
1、每种排名算法评分机制不同,给出的评分尺度和含义也不尽相同
2、如何综合利用,要考虑每种算法的效果。为效果好的给与较大的权重。
我们先来考虑第一个问题,如何消除每种评分算法所给出的评分尺度和含义不相同的问题。
第2个问题,等研究完所有的算法以后再来考虑。
简单,使用归一化,将每个评分值缩放到0-1上,1代表最高,0代表最低。
对爬去到的数据进行排序, 有好几种排序算法:
第1个排名算法:根据单词位置进行评分的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的位置越靠前越好。比如我们往往习惯在文章的前面添加一些摘要性、概括性的描述。
# 根据单词位置进行评分的函数.# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)] def locationscore(self,rows):
locations=dict([(row[0],1000000) for row in rows])
for row in rows:
loc=sum(row[1:]) #计算每个链接的单词位置总和,越小说明越靠前
if loc<locations[row[0]]: #记录每个链接最小的一种位置组合
locations[row[0]]=loc
return self.normalizescores(locations,smallIsBetter=1)####
第2个排名算法:根据单词频度进行评价的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的次数越多越好。比如我们在指定主题的文章中会反复提到这个主题。
# 根据单词频度进行评价的函数# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]def frequencyscore(self,rows):counts=dict([(row[0],0) for row in rows])for row in rows: counts[row[0]]+=1 #统计每个链接出现的组合数目。 每个链接只要有一种位置组合就会保存一个元组。所以链接所拥有的组合数,能一定程度上表示单词出现的多少。return self.normalizescores(counts)
第3个排名算法:根据单词距离进行评价的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的越紧凑越好。这是因为我们更希望所有单词出现在一句话中,而不是不同的关键词出现在不同段落或语句中。
# 根据单词距离进行评价的函数。
# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]
def distancescore(self,rows):
# 如果仅查询了一个单词,则得分都一样
if len(rows[0])<=2: return dict([(row[0],1.0) for row in rows])
# 初始化字典,并填入一个很大的值mindistance=dict([(row[0],1000000) for row in rows])for row in rows:dist=sum([abs(row[i]-row[i-1]) for i in range(2,len(row))]) # 计算每种组合中每个单词之间的距离if dist<mindistance[row[0]]: # 计算每个链接所有组合的距离。并为每个链接记录最小的距离mindistance[row[0]]=distreturn self.normalizescores(mindistance,smallIsBetter=1)4 实现效果
热门主题推荐实现
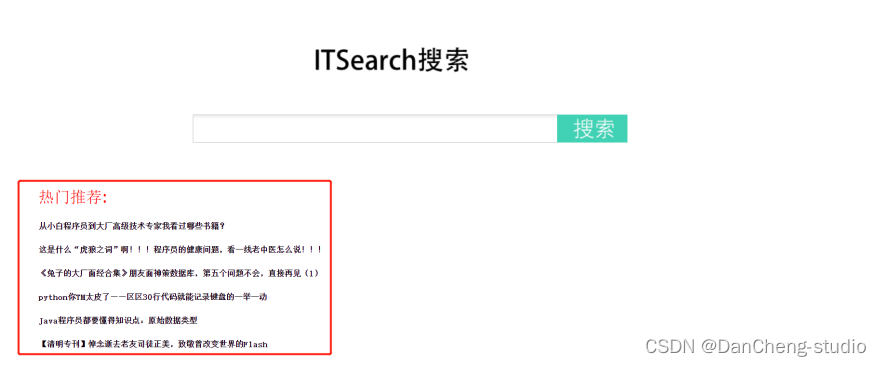
搜索界面的实现

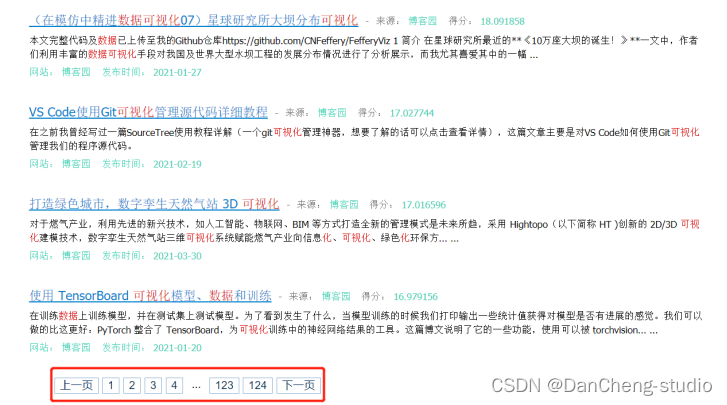
查询结果页面显示
查询结果分页显示
查询结果关键字高亮标记显示
4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
python的搜索引擎系统设计与实现 计算机竞赛
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 python的搜索引擎系统设计与实现 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:5分创新点:3分 该项目较为新颖ÿ…...

Unity随笔:在Unity中使用多线程需要注意什么
Unity3D 支持多线程编程,但是在 Unity 中使用多线程需要注意一些限制和注意事项。以下是在 Unity 中使用多线程时需要注意的事项: 1. Unity 主线程限制: Unity 中的大部分操作必须在主线程进行,包括场景的修改、资源的加载、渲染…...
 语法)
SQL Select(选择) 语法
SQL SELECT 语法 SELECT 语法用于从数据库中选择数据。 返回的数据存储在结果表中,称为结果集。 基本语法:SELECT和FROM 在任何SQL查询语句中都:SELECT和FROM他们必须按顺序排列。SELECT指示要查看哪些列,FROM标识它们所在的表。…...

Python武器库开发-基础篇(二)
基础篇(二) if 语句 编程时经常需要检查一系列条件,并据此决定采取什么措施。在Python中,if 语句让你能够检查程序的当前状态,并据此采取相应的措施 下面是一个简短的示例,演示了如何使用if 语句来正确地处理特殊情形。假设你有…...

在 CentOS 8.2 上安装 MySQL C/C++ 客户端库 libmysqlclient.so
添加 MySQL 官方 Yum 存储库: sudo dnf install https://dev.mysql.com/get/mysql80-community-release-el8-3.noarch.rpm 安装 MySQL C/C 客户端库: sudo dnf install mysql-devel 这将自动安装所需的依赖项,并将 libmysqlclient 库及其头…...

『C++ - STL』之优先级队列( priority_queue )
文章目录 前言优先级队列的结构优先级队列的模拟实现仿函数 最终代码 前言 什么是优先级队列,从该名中可以知道他一定有队列的一定属性,即先入先出(LILO),而这里的优先级则可以判断出它的另一个特点就是可以按照一定的条件将符合该条件的先进…...
?)
简述什么是服务端包含(Server Side Include)?
Server-side include(服务器端包括)是浏览器向服务器请求您的文档时并入您的文档的一个文件。 当访问者浏览器请求含有 include(包括)指令的文档时,服务器处理 include(包括)指令并创建新的文档,在新文档中 include(包括)指令被所包括的文件内容取代。然后服务器将此…...
领英如何注册?2023超全面详细教程
领英是一家面向商业用户的全球最大的职业社交网站,据统计,Linkedln用户每月与网页的交互次数超过10亿次。对于跨境人来说,他更是作为一个开发客户、广告营销的工具,被称为跨境的“风口”。 一、领英被封原因 1、IP、设备问题 1&…...

Spring Cloud Gateway 使用 Redis 限流使用教程
从本文开始,笔者将总结 spring cloud 相关内容的教程 版本选择 为了适应 java8,笔者选择了下面的版本,后续会出 java17的以SpringBoot3.0.X为主的教程 SpringBoot 版本 2.6.5 SpringCloud 版本 2021.0.1 SpringCloudAlibaba 版本 2021.0.1.…...
Qt事件系统 day7
Qt事件系统 day7 事件系统 在Qt中,事件是派生自抽象QEvent类的对象,它表示应用程序内发生的事情或应用程序需要知道的外部活动的结果。事件可以由QObject子类的任何实例接收和处理,但它们与小部件尤其相关。Qt程序需要在main()函数创建一个…...
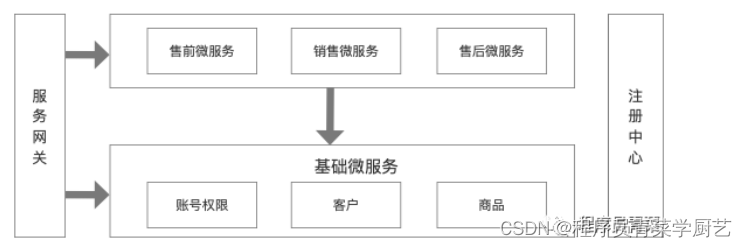
微服务拆分的思考
一、前言 前面几篇文章介绍了微服务核心的两个组件:注册中心和网关,今天我们来思考一下微服务如何拆分,微服务拆分难度在于粒度和层次,粒度太大拆分的意义不大,粒度太小开发、调试、运维会有很多坑。 二、微服务划分…...

DateUtil工具类记录
为支持日常工作需要,记录所用到的一些关于时间的工具类方法。随时进行补充。 /*** Description:获取两个日期之间的天数差* Author:hanyq* Date:2023/9/19 11:23*/public static int getDateDifference(Date startDate,Date endDate){int days 0;try {Calendar st…...

可信执行环境简介:ARM 的 TrustZone
目录 可信执行环境安全世界与普通世界 - 上下文切换机制ARMv7 中的异常处理ARMv8 中的异常处理 信任区商业实施TrustZone 本身的漏洞高通Trustonic 信任区强化的弱点结论声明 可信执行环境 具有信任区的 ARM 处理器实现了架构安全性每个物理处理器内核提供两个虚拟的扩展 核心…...
【音视频流媒体】 3、ffmpeg、ffplay、ffprobe 超详细介绍
文章目录 一、ffmpeg1.1 安装1.2 基本参数 二、ffprobe2.1 查编码格式2.2 查视频时长 五、视频转流5.1 MP4转H2645.2 H264转MP45.3 AVI转MP45.4 MP4转H265 六、视频文件6.1 播放6.2 filter 过滤器6.2.1 crop 6.3 视频截取6.4 视频拼接6.5 获取分辨率 七、视频和图7.1 视频抽帧7…...

解决kong部署自定义插件报 helloworld plugin is enabled but not installed
背景 我使用的是docker环境部署,使用的是自定义挂载plugins路径 -e "KONG_LUA_PACKAGE_PATH/plugins/?.lua" \ -v "/plugins:/plugins" \ -e "KONG_PLUGINSbundled,helloworld" \但是当我只需docker run的时候就报错 [error] 1#0:…...

动态数据源自定义SqlSessionFactoryBean时mybatis plus配置失效
环境: 动态数据源spring-boot 2.7.15mybatis-plus 3.5.2 yaml配置: spring:datasource:db100:username: xxxpassword: xxxjdbc-url: jdbc:kingbase8://xxx.xxx.xxx.xxx:54321/100driver-class-name: com.kingbase8.Driver# url: jdbc:postgresql://xxx…...

【Qt控件之QDialogButtonBox】概述及使用
概述 QDialogButtonBox类是一个小部件,它以适合当前小部件样式的布局呈现按钮。 对话框和消息框通常以符合该台界面指南的布局呈现按钮。不同的平台会有不同的对话框布局。QDialogButtonBox允许发人员向其添加按钮,并将自使用用户的桌面环境所适合的布局…...

IPv6知识概述 - ND协议
IPv6知识概述 - ND协议 参考文章:https://blog.csdn.net/Gina_wj/article/details/106708770 IPv6基础篇(四):邻居发现协议NDP ND协议功能概述 ND(Neighbor Discovery,邻居发现)协议是IPv6的…...

react-redux的connect函数实现
react-redux对store订阅的实现原理: storeContext.js import { createContext } from "react";export const StoreContext createContext() connect.js import React, { PureComponent } from react // import store from ../../store; import {Stor…...
Vue3使用Vite创建项目
node版本:node -v v18.16.0 npm版本: npm -v 9.5.1 Vite Vite:是一种新型前端构建工具,能够显著提升前端开发体验 脚手架,创建Vue项目,替代 Vue-cli 基于Vite创建vue项目: 1.npm create vitelatest 2.完…...

手把手教你复现CVE-2022-25578:利用.htaccess文件上传绕过,在Taocms 3.0.2靶场拿Flag
从零实战复现CVE-2022-25578:Taocms 3.0.2靶场渗透全解析 在网络安全领域,文件上传漏洞一直是渗透测试中的经典突破口。今天我们将深入剖析CVE-2022-25578漏洞,这是一个基于.htaccess文件配置不当导致的安全问题。不同于简单的漏洞复现教程&a…...

OmenSuperHub终极指南:3步解锁暗影精灵完整性能潜力
OmenSuperHub终极指南:3步解锁暗影精灵完整性能潜力 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 想要彻底掌控惠普暗影精灵笔记本的性能吗&…...

独立开发者如何借助Taotoken管理多个AI侧项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken管理多个AI侧项目 作为一名独立开发者,同时维护多个使用大模型的小型项目是常态。你可能有…...

避坑指南:PyCharm 2023.3 + Anaconda 虚拟环境配置,绕开‘解释器路径选择界面消失’的陷阱
PyCharm 2023.3与Anaconda虚拟环境深度配置指南:从原理到实战避坑 在数据科学和机器学习项目的开发过程中,PyCharm与Anaconda的组合堪称黄金搭档。然而,当PyCharm 2023.3遇到Anaconda虚拟环境配置时,不少开发者会陷入"解释器…...

智慧工业控制面板工控部件元器件LCD部件检测数据集VOC+YOLO格式365张8类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):365标注数量(xml文件个数):365标注数量(txt文件个数):365标注类别数&…...

手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线
手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线 在电磁仿真领域,材料参数的精确建模往往是决定仿真结果可靠性的关键因素。当我们需要模拟特殊频段的吸波材料、频率色散介质或各向异性材料时,仅依赖CST内置材料库…...

双向脑机接口:从神经信号解码到感觉编码的核心原理与挑战
1. 从科幻到现实:双向脑机接口的演进与核心挑战十几年前,当我第一次在学术会议上看到猴子用意念控制机械臂抓取食物的视频时,那种震撼至今记忆犹新。那时,脑机接口(BCI)还只是顶级实验室里昂贵的“魔术”。…...

预上屏是什么鬼?KikaInputMethod 输入预测功能深度解析
文章目录预上屏的本质预上屏执行流程核心预上屏代码Enter 键确认上屏光标操作全集私有命令通信(sendPrivateCommand)物理键盘处理(onKeyDown)InputClient 关键接口速查踩坑记录写在最后用搜狗或者系统键盘打字时,打到一…...
)
给Hadoop初学者的环境搭建备忘录:为什么你的JDK配置总在重启后‘消失’?(Linux基础解惑)
Hadoop环境搭建中的Linux系统原理:为什么你的配置总在重启后"消失"? 很多Hadoop初学者在搭建开发环境时,都会遇到一个令人困惑的问题:明明按照教程一步步配置好了JDK和Hadoop,为什么重启后环境变量就"消…...

终极指南:Original Prusa i3 MK3S 3D打印机的完整构建与定制方案
终极指南:Original Prusa i3 MK3S 3D打印机的完整构建与定制方案 【免费下载链接】Original-Prusa-i3 Original Prusa i3 MK2 3D printer printed parts 项目地址: https://gitcode.com/gh_mirrors/or/Original-Prusa-i3 Original Prusa i3 MK3S是一款由PRUS…...