Django ORM查询
文章目录
- 1 增 -- 向表内插入一条数据
- 2 删 -- 删除表内数据(物理删除)
- 3 改 -- update操作更新某条数据
- 4 查 -- 基本的表查询(包括多表、跨表、子查询、联表查询)
- 4.1 基本查询
- 4.2 双下划线查询条件
- 4.3 逻辑查询:or、and、not
- 4.3.1 Q对象
- 4.3.2 or、and、not
- 4.3.3 集合查询
- 4.4 多表查询
- 4.4.1 一对多查询
- 4.4.2 多对多查询
- 总结
Django提供了一套非常方便的类似SqlAlchemy ORM的通过对象调用的方式操作数据库表的ORM框架。
Django ORM操作主要分为以下几类:
- 增:向表内插入一条数据
- 删:删除表内数据(物理删除)
- 改:update操作更新某条数据
- 查:基本的表查询(包括多表、跨表、子查询、联表查询)
其中比较复杂的是表查询。下面分类讲解这几种操作方式。
1 增 – 向表内插入一条数据
关于新增记录的操作这里分为两种方式:
- 第一种方式,通过模型对象的
save()方法:
userObj=User()
userObj.username= request.data.get('username')
# userObj.password= make_password(request.POST.get('password'),None,'pbkdf2_sha256') # 创建django密码,第三个参数为加密算法
userObj.set_password(request.data.get('password')) # 创建django密码,第三个参数为加密算法
userObj.name= request.data.get('name')
userObj.phone= request.data.get('phone')
userObj.email= request.data.get('email')
userObj.create_name= request.data.get('create_name')
userObj.update_name= request.data.get('update_name')
userObj.is_superuser= 0
print(userObj.username)
print('username %s' % (userObj.username))
print('password %s' % (userObj.password))
userObj.save()这种方式先创建一个模型对象,赋值,最后调用模型的 .save()方法的方式向数据库插入一条数据。
- 第二种方式,通过
objects.create的方式直接新增,类似一种缩略的方式,比较简单
res = models.User.objects.create(username='admin',make_password='123456',register_time=datetime.datetime.now())
print(res)
2 删 – 删除表内数据(物理删除)
django删除表数据是通过.delete()方法,举例:
如果我们只删除 user表 主键为1的记录:
ret = models.User.objects.get(pk=1).delete()
上述是只删一条记录,删除多条记录类似:ret = models.User.objects.filter(pk__gt=1).delete()
这样我们可以批量删除user表中主键值大于1的其他所有记录。
需要提醒的是,这种方式属于物理删除,删除后不可恢复,如需逻辑删除,参考下面 update的方式。
3 改 – update操作更新某条数据
django ORM 的改操作,这里分为三种方式。我们先按单记录的更新讲解,批量更新类似:
- 第一种,指定更新字段更新:
ret = models.User.objects.get(pk=1).update(username='admin',password='123456')
- 第二种,通过 Json 更新:
object = {'username':'admin','password':'123456'}
ret = models.User.objects.get(pk=1).update(**object)
- 第三种,类似增操作,直接通过
.save()方法更新整条记录
userObj=User()
userObj.id= request.data.get('id')
userObj.username= request.data.get('username')
# userObj.password= make_password(request.POST.get('password'),None,'pbkdf2_sha256') # 创建django密码,第三个参数为加密算法
userObj.set_password(request.data.get('password')) # 创建django密码,第三个参数为加密算法
userObj.name= request.data.get('name')
userObj.phone= request.data.get('phone')
userObj.email= request.data.get('email')
userObj.create_name= request.data.get('create_name')
userObj.update_name= request.data.get('update_name')
userObj.is_superuser= 0
print(userObj.username)
print('username %s' % (userObj.username))
print('password %s' % (userObj.password))
userObj.save()
这种方式不太建议用,需要注意数据的完整性。
4 查 – 基本的表查询(包括多表、跨表、子查询、联表查询)
4.1 基本查询
需要了解如下方法的使用:
all()查询所有数据filter()带有过滤条件的查询whereget()获取单条,查询不到会报错first()取queryset里第一条记录last()取queryset里最后一条记录values()指定要获取的字段
models.User.objects.filter(pk=1).values('username','phone')
# 返回 <QuerySet [{'username': 'admin', 'phone': '176****'}]>
values_list()列表套元祖
models.User.objects.filter(pk=1).values_list('username','phone')
# 返回 <QuerySet [('admin','176***')]>
distinct()去重
ret = models.User.objects.filter(pk=1).distinct()
需要注意,这里去重是针对整条数据的去重,主键不一样也不会去重
order_by()排序
ret = models.User.objects.order_by('username')# 默认升序
ret = models.User.objects.order_by('-username')# 降序
reverse()反转,前提已排序
ret = models.User.objects.order_by('username').reverse()# 默认升序
ret = models.User.objects.order_by('-username').reverse()# 降序
count()当前查询条件的记录数
ret = models.User.objects.filter(pk=1).count()
exclude()排除 ,相当于查询条件不等于
ret = models.User.objects.exclude(pk=1)
exists()记录是否存在,不太实用,不过多讲
4.2 双下划线查询条件
django不支持 类似:>=,<=等查询判断方式,但提供了一套很好用的方法:
-
__gt<=> 大于:
ret = models.User.objects.filter(id__gt=1)#查询id>1的记录 -
__lt<=> 小于:ret = models.User.objects.filter(id__lt=1)#查询id<1的记录 -
__gte<=> 大于等于:ret = models.User.objects.filter(id__gte=1)#查询id>=1的记录 -
__lte<=> 小于等于:ret = models.User.objects.filter(id__lte=1)#查询id<=1的记录 -
__in<=> 条件是否归属所给的选择:ret = models.User.objects.filter(id__in=[1,2])#查询id=1或id=2的记录 -
__range<=> 范围:ret = models.User.objects.filter(id__range=[1,3])#查询1<=id<=3的记录 -
__contains<=> 模糊查询 ,区分大小写:ret = models.User.objects.filter(username__contains='a')#查询 username like '%a%'的记录 -
__icontains<=> 模糊查询 ,不区分大小写:ret = models.User.objects.filter(username__icontains='a')#查询 username like '%a%'的记录 -
__startswith<=> 模糊查询 ,指定内容开始:ret = models.User.objects.filter(username__icontains='a')#查询 username like 'a%'的记录 -
__endswith<=> 模糊查询 ,指定内容结束:ret = models.User.objects.filter(username__icontains='a')#查询 username like '%a'的记录
注意:__contains、__icontains、__startswith、__endswith这些模糊查询性能很低,生产环境不建议使用。
4.3 逻辑查询:or、and、not
涉及概念:Django的Q对象
4.3.1 Q对象
Q对象实例化后能够增加各个条件之间的关系,而且这种写法用在你不知道用户到底传入了多少个参数的时候很方便。
- 比如默认情况下
filter()里面每个字段的连接都是&,我们使用Q对象通常都是让它变成|,来进行查询 。
from django.db.models import Qquery = Q()
q1 = Q()
q1.connector = "AND" # 连接的条件是AND 代表就是&
q1.children.append(("email", "280773872@qq.com")) # email代表的是数据库的字段
q1.children.append(("password", "666"))# 等同于:email="280773872@qq.com" & password="666"
q2 = Q()
q2.connector = "AND" # 同样q2对象连接条件也是AND
q2.children.append(("username", "fe_cow")) # 同样数据库里username字段
q2.children.append(("password", "fe_cow666"))# 等同于:username="fe_cow" & password="fe_cow666"
query.add(q1, "OR")
query.add(q2, "OR")# query目前里面的符合条件结果就是: (email="280773872@qq.com" & password="666") | (username="fe_cow" & password="fe_cow666")
userinfo_obj = models.UserInfo.objects.filter(query).first()filter()过滤器的方法中关键字参数查询,会合并为And(),需要进行or查询,使用Q()对象,Q对象django.db.models.Q用于封装一组关键字参数,这些关键字参数与比较运算符中的相同。
- Q对象可以使用
&(and)、|(or)操作符组合起来,当操作符应用在两个Q对象时,会产生一个新的Q对象。
list.filter(pk__lt=6).filter(bcomment__gt=10)
list.filter(Q(pk__lt=6) | Q(bcomment__gt=10))
-
使用
~操作符在Q对象前表示取反:list.filter(~Q(pk__lt=6)) -
可以使用
&|~结合括号进行分组,构造出复杂的Q对象
4.3.2 or、and、not
import os
import djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'salary.settings')
django.setup(set_prefix=False)from employee.models import Employees # 这一行必须在`os.environ.setdefault`之后,先把配置、环境变量准备好后才能import
from django.db.models import Q
# emps = Employees.objects.all() # 懒查询,只有后面对查询结构有引用时,才会驱动真正的查询
# print(emps) # 查询集mgr = Employees.objects
# AND查询: 五种方式
x = mgr.filter(pk__gt=10005, pk__lt=10010)
print(x)
y = mgr.filter(pk__gt=10005).filter(pk__lt=10010)
print(y)
z = mgr.filter(pk__gt=10005) & mgr.filter(pk__lt=10010)
print(z)
# Django的Q对象
xx = mgr.filter(Q(pk__gt=10005) & Q(pk__lt=10010))
yy = mgr.filter(Q(pk__gt=10005), Q(pk__lt=10010))# OR查询: 三种方式
x = mgr.filter(pk__in=[10005, 10010])
print(x)
y = mgr.filter(pk=10005) | mgr.filter(pk=10010)
print(y)
z = mgr.filter(Q(pk=10005) | Q(pk=10010))# NOT查询:
x = mgr.exclude(pk=10005)
print(x)
y = mgr.filter(~(Q(pk__gt=10005) & Q(pk__lt=10010)))
print(y)
4.3.3 集合查询
# 聚合
from django.db.models import Max, Min, Count, Sum, Avg
x = mgr.filter(pk__gt=10008).count() # 将所有数据看做一行出结构
print(x) # 单值
# aggregate聚合函数:出统计函数的结果,返回字典,默认key命名为`字段名_聚合函数名`
y = mgr.filter(pk__gt=10008).aggregate(Count("pk"), Max("pk"), Min("pk"), sm_pk=Sum('pk'), avg_pk=Avg('pk')) # 可以给聚合查询结果起别名
print(y)
# 结果:{'sm_pk': 120174, 'avg_pk': 10014.5, 'pk__count': 12, 'pk__max': 10020, 'pk__min': 10009}
# annotate聚合函数:这个聚合函数会分组,没有指定分组使用pk分组,行行分组。返回结果集
z = mgr.filter(pk__gt=10013).annotate(Count("pk"), Max("pk"), Min("pk"), sm_pk=Sum('pk'), avg_pk=Avg('pk'))
print(z)
xx = mgr.filter(pk__gt=10013).values('gender').annotate(c=Count("pk")).values("c") # 第一个values控制分组,第二个values控制投影
print(xx)
4.4 多表查询
4.4.1 一对多查询
- Django不支持联合主键,只支持单一主键,这一点和sqlalchemy不一样
- Django不支持在Model中声明编码格式,这一点和sqlalchemy不一样,只能在setting.py的DATABASES注册中添加选项
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'test','USER': 'root','PASSWORD': 'cli*963.','HOST': '127.0.0.1','PORT': '3306',},'OPTIONS': {'charset': 'utf8mb4',}
}
一对多模型构造:
员工表 – 工资表是一对多的关系。由于django不支持联合主键,需改造工资表。增加自增的id列,并设为主键,删除其他主键和外键。
from django.db import models# Create your models here.class Employees(models.Model):"""CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_date` date NOT NULL,`first_name` varchar(14) NOT NULL,`last_name` varchar(16) NOT NULL,`gender` enum('M','F') NOT NULL,`hire_date` date NOT NULL,PRIMARY KEY (`emp_no`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COLLATE=utf8mb3_general_ci;"""class Meta: # 数据库表名,固定的,Django就是这样定义,一个Meta类db_table = "employees" # 表名emp_no = models.IntegerField(primary_key=True, null=False)birth_date = models.DateField(null=False)first_name = models.CharField(max_length=14, null=False)last_name = models.CharField(null=False, max_length=16)gender = models.SmallIntegerField(null=False)hire_date = models.DateField(null=False)# 在多端添加了外键属性后,主端的(Employees)类属性字典__dict__中会自动增加一个默认名称为Salaries_set的属性。# 如果外键声明的参数中使用了related_name=***,则这个属性的名称变为related_name指定的值# 序列化filed = '__all__'depth = 1def __repr__(self):return "<Employee: {} {} {}>".format(self.emp_no, self.first_name, self.last_name)@propertydef full_name(self):return "full name:{}-{}".format(self.first_name, self.last_name)__str__ = __repr__class Salaries(models.Model):"""CREATE TABLE `salaries` (`emp_no` int(11) NOT NULL,`salary` int(11) NOT NULL,`from_date` date NOT NULL,`to_date` date NOT NULL,`id` int(11) NOT NULL AUTO_INCREMENT,PRIMARY KEY (`id`) USING BTREE,KEY `emp_no` (`emp_no`),CONSTRAINT `salaries_ibfk_1` FOREIGN KEY (`emp_no`) REFERENCES `employees` (`emp_no`) ON DELETE CASCADE) ENGINE=InnoDB AUTO_INCREMENT=41 DEFAULT CHARSET=utf8mb3 COLLATE=utf8mb3_general_ci;"""class Meta:db_table = "salaries"# 一对多的多端,被引用的主表中的字段名emp_no,在多端(从表)的类属性字典__dict__中保存的key值为emp_no_id,实际上对应了主表emp_no在数据库中的值。# 多端查询这个被引用的外键值时,也是拿着emp_no_id去主表中查的,此时会报key emp_no_id不存在异常。这种情况只需在外键声明的参数中使用db_column='emp_no'指定key值。emp_no = models.ForeignKey('Employees', models.CASCADE, db_column='emp_no')# emp_no = models.ForeignKey('Employees', models.CASCADE, db_column='emp_no', related_name="salaries") # 使用related_namesalary = models.IntegerField(null=False)from_date = models.DateField(null=False)to_date = models.DateField(null=False)id = models.AutoField(primary_key=True) # 自增def __repr__(self):return "<Salaries: {} {}>".format(self.emp_no_id, self.salary)__str__ = __repr__如上示例,在Salaries Model模型类中,创建ForeignKey外键。创建外键后:
- 一对多的多端:多端这里就是
Salaries定义的表。在这里,多端(从表)引用的主表的主键对应的字段名为emp_no。
多端Salaries的类属性字典__dict__中会自动增加一个属性,命名规则为被引用的字段名_id,这里就是emp_no_id,
对应主表在数据库中emp_no字段的值。在多端查询时,由于拿着emp_no_id去主表中查,而主表中的key为emp_no,
导致报key emp_no_id不存在错误时,这种情况需在外键声明中加上db_column="emp_no"就可以了,
表示不要用Django自动命名的emp_no_id去查,而是用指定的key值去主表中查。 - 一对多的一端:多端加了外键属性后,主表类属性字典
__dict__中会自动增加salaries_set属性,命名规则默认为多端表名_set。
如果在外键声明中增加related_name="Salaries"参数,则这个自动增加的属性名则使用related_name指定的值
所以:
- 从一端向多端查,则使用
instance.salaries_set - 从多端向一端查,则使用
instance.emp_no_id - 在多端的
__repr__中,为了提高效率不触发主表查询,也应该用self.emp_no_id,而不是self.emp_no
print(*Employee.__dict__.items(), sep='\n')
# 一端,Employees类中多了一个类属性
#('salaries_set', <django.db,models.fields.related_descriptors.ReverseManyTooneDescriptor object at 0x000001303FB09838>)print(*salary._dict_,itemsO), sep='\n')
# 多端,Salaries类中也多了一个类属性
#('emp_no_id',<django.db.models.query_utils.DeferredAttribute object at 0x000001303F809828>)
#('emp_no' <django.db.mode1s.fields.related_ descriptors. ForwardManyTo0neDescriptor object at 0x000001303FB09860>)指向Employees类的一个实例
查询示例:
import os
import djangoos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'salary.settings')
django.setup(set_prefix=False)from employee.models import Employees, Salaries # 这一行必须在`os.environ.setdefault`之后,先把配置、环境变量准备好后才能importprint(Employees.__dict__.items())
print('_______________')
print(Salaries.__dict__.items())
print('______________')
emps = Employees.objects
sals = Salaries.objects
# 查询10004号员工的工资
# 从员工表查询,这个好,没有冗余查询
emp = emps.get(pk=10004) # 一个Employees对象
print(emp.salaries_set.all()) # 返回一个查询结果集# 从工资表查询,这个不好,多对一,产生了冗余查询
sal = sals.filter(emp_no=10004).all()
print(sal)
distinct去重:
# 查询工资大于5500的员工
_emps = sals.filter(salary__gt=5500).values('emp_no').distinct()
print(_emps)
print(emps.filter(emp_no__in=_emps)) # in子查询
# print(emps.filter(emp_no__in=[x.get("emp_no") for x in _emps])) # in列表
raw的使用:
对于非常复杂的sql语句,使用django ORM不好写了,可以使用raw,直接执行sql语句。 例如:
# 查询工资大于50000的所有员工的姓名
sql = """
SELECT DISTINCT e.* from employees as e
JOIN salaries as s
ON e.emp_no = s.emp_no
WHERE salary > 50000
"""
emgr = Employees.objects # 管理器
res = emgr.raw(sql)
print(list(res))
更多学习案例:
https://juejin.cn/post/6974298891353063431
4.4.2 多对多查询
多对多查询有两种建模方式:
- 借助第三张表。
例如一个员工可以在多个部门,一个部门有多个员工。这种多对多的关系,可以增加第三张表"部门-员工表"。这样多对多模型转换为"多-1-多"的模型:部门表 - 部门&员工表 - 员工表"。最后查询转为为一对多的查询。
- 使用
models.ManyToManyField,构建多对多模型。
models.ManyToManyField会自动创建第三张表。models.ManyToManyField可以建在两个模型类中的任意一个。
下面以第二种方式举例。
多对多模型: 一篇文章可以被多个用户关注,一个用户也可以关注多篇文章,二者是多对多的关系
模型构建:
定义两张表:User表(用户表),Artile表(文章表)。
import datetime
from django.db import models
from django.contrib.auth.models import AbstractUser
from django.contrib.auth.hashers import make_password #密码加密class Artile(models.Model):"""title: 标题sub_title: 子标题content: 内容"""def __str__(self):return self.titletitle = models.CharField(max_length=250,default='',verbose_name='标题')sub_title = models.CharField(max_length=250,default='',verbose_name='子标题')content = models.CharField(max_length=2000,default='',blank=True,verbose_name='内容')# 通过models.DateTimeField与User表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表users = models.ManyToManyField(to='User', )create_time = models.DateTimeField(default=datetime.datetime.now(),verbose_name='创建时间')create_name = models.CharField(max_length=20,verbose_name='创建人')update_time = models.DateTimeField(default=datetime.datetime.now(),blank=True,verbose_name='更新时间')update_name = models.CharField(max_length=20,verbose_name='更新人',blank=True,)is_delete = models.IntegerField(default=0,verbose_name='删除状态',blank=True,) # 逻辑删除 0 正常 1:删除class Meta:verbose_name = "文章"verbose_name_plural = verbose_nameapp_label = 'webApi'class User(AbstractUser):"""name: 昵称account: 用户名pwd: 密码phone:手机号email:邮箱avator:头像group_id:归属组"""def __str__(self):return self.accountname = models.CharField(max_length=20,default='',verbose_name='昵称')phone = models.CharField(max_length=20,default='',blank=True,verbose_name='手机号')email = models.CharField(max_length=20,default='',blank=True,verbose_name='邮箱')avator = models.CharField(max_length=200,default='',blank=True,verbose_name='头像')group_id = models.CharField(max_length=50,default='',blank=True,verbose_name='组')create_time = models.DateTimeField(default=datetime.datetime.now(),verbose_name='创建时间')create_name = models.CharField(max_length=20,verbose_name='创建人')update_time = models.DateTimeField(default=datetime.datetime.now(),blank=True,verbose_name='更新时间')update_name = models.CharField(max_length=20,verbose_name='更新人',blank=True,)is_delete = models.IntegerField(default=0,verbose_name='删除状态',blank=True,) # 逻辑删除 0 正常 1:删除# blank=True, 可选字段class Meta:verbose_name = "用户"verbose_name_plural = verbose_namedef __str__(self):return self.username# 明文密码转加密def set_password(self, password):print('set_password %s' % (password))self.password = make_password(password,'jxy','pbkdf2_sha256')# 验证密码是否匹配def check_password(self, password):print('password: %s' % (password))print('check_password: %s' % (make_password(password,'jxy','pbkdf2_sha256')))print('self.password: %s' % (self.password))return self.password == make_password(password,'jxy','pbkdf2_sha256')
添加记录:
向这张关系表中添加几条关系。比如,我们将 Artile表主键为1的一条记录,添加User表 主键为1,2两条关系。
user1 = models.User.object.filter(pk=1).first()
user2 = models.User.object.filter(pk=2).first()artile1 = models.Artile.object.filter(pk=1).first()
artile1.users.add(user1,user2)# 方法二
userSet = models.User.object.filter(pk__in=[1,2]).all()
artile1.users.add(*userSet)
这样便在关系表中创建了 Artile表主键为1的记录与User表主键为1,2的两条关系。
另外清除关系绑定用法类似,使用remove替代add:
artile1 = models.Artile.object.filter(pk=1).first()
userSet = models.User.object.filter(pk__in=[1,2]).all()
artile1.users.remove(*userSet) #解绑指定关系
artile1.users.clear() #清空所有关系
多对多查询:
- 正向查询,例如查询Artile表第一条记录有哪些用户关注:
artile1 = models.Artile.object.filter(pk=1).first()
print(artile1.users.all().values('username')) # 打印关注Artile表第一条记录的用户名称
- 逆向查询,例如查询User表第一条记录关注过哪些Artile:
user1 = models.User.object.filter(pk=1).first()
print(user1.artile__set.all().values('title')) # 打印User表第一条记录关注的文章名称
总结
在开发中,一般都会采用ORM框架,这样就可以使用对象操作表了。
- Django中,定义表映射的类,继承自Model类。Model类使用了元编程,改变了元类。
- 使用Field实例作为类属性来描述字段。
- 使用ForeignKey来定义外键约束。
相关文章:

Django ORM查询
文章目录 1 增 -- 向表内插入一条数据2 删 -- 删除表内数据(物理删除)3 改 -- update操作更新某条数据4 查 -- 基本的表查询(包括多表、跨表、子查询、联表查询)4.1 基本查询4.2 双下划线查询条件4.3 逻辑查询:or、and…...

如何在CentOS 7中卸载Python 2.7,并安装3.X
Python是一种常用的编程语言,但是如果您不需要在服务器上使用Python 2.7,那么本文将详细介绍如何在CentOS 7上卸载Python 2.7。 一、检查Python版本 在卸载Python 2.7之前,必须检查系统上的Python版本。 在终端中执行以下命令:…...

10.17七段数码管单个多个(部分)
单个数码管的实现 第一种方式 一端并接称为位码;一端分别接收电平信号以控制灯的亮灭,称为段码 8421BCD码转七段数码管段码是将BCD码表示的十进制数转换成七段LED数码管的7个驱动段码, 段码就是LED灯的信号 a为1表示没用到a,a为…...
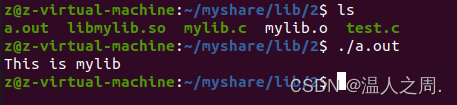
linux静态库与动态库
库是一种可执行的二进制文件,是编译好的代码。使用库可以提高开发效率。在Linux 下有静态库和动态库。 静态库在程序编译的时候会被链接到目标代码里面。所以程序在运行的时候不再需要静态库了。因此编译出来的体积就比较大。以 lib 开头,以.a 结尾。…...

LeetCode 面试题 10.03. 搜索旋转数组
文章目录 一、题目二、C# 题解 一、题目 搜索旋转数组。给定一个排序后的数组,包含n个整数,但这个数组已被旋转过很多次了,次数不详。请编写代码找出数组中的某个元素,假设数组元素原先是按升序排列的。若有多个相同元素ÿ…...

SpringCloudSleuth异步线程支持和传递
场景 在使用Sleuth做链路跟踪时,默认情况下异步线程会断链,需要进行代码调整支持。 调整内容 方式一 使用Async实现异步线程 开启异步线程池 EnableAsync SpringBootApplication public class LizzApplication {public static void main(String[] a…...
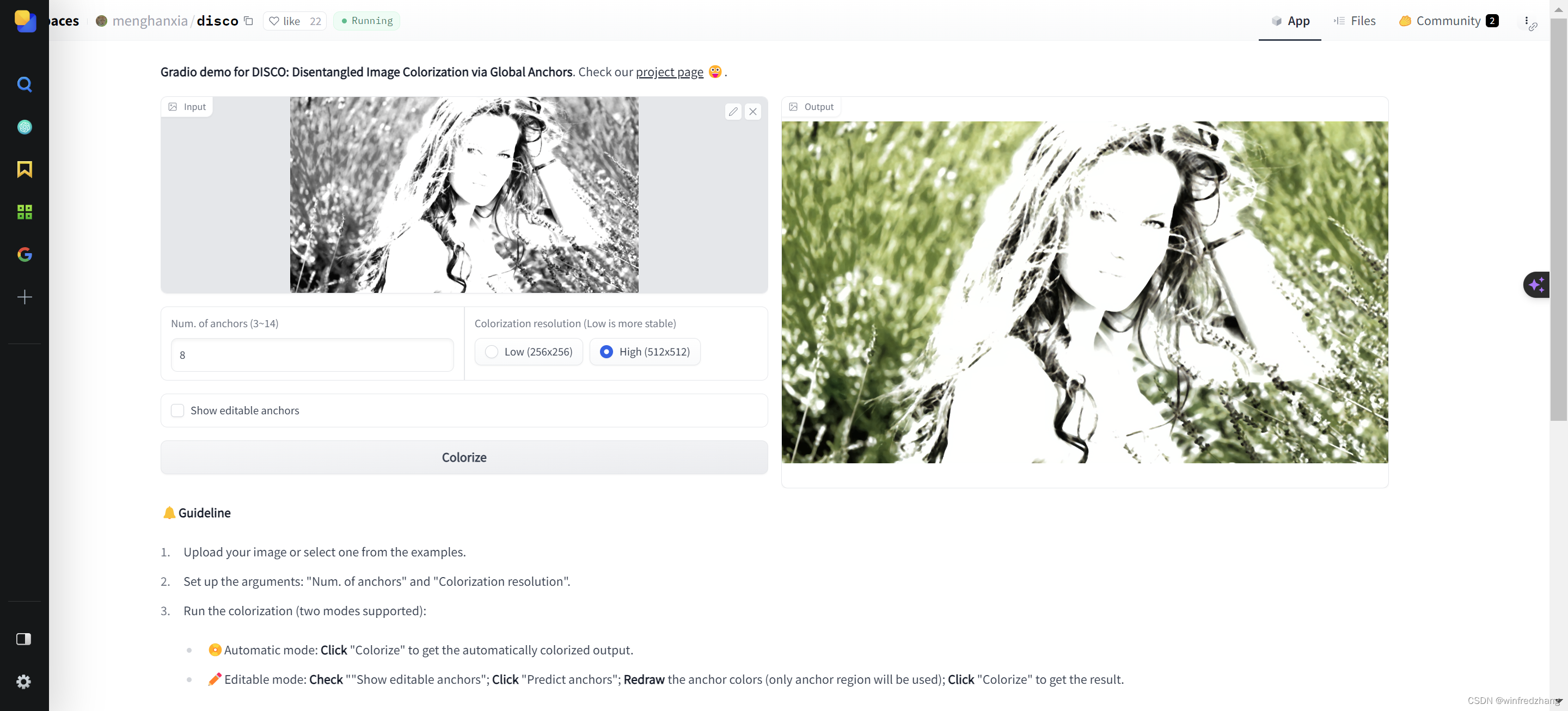
如何使用 Disco 将黑白照片彩色化
Disco 是一个基于视觉语言模型(LLM)的图像彩色化工具。它使用 LLM 来生成彩色图像,这些图像与原始黑白图像相似。 本文将介绍如何使用 Disco 将黑白照片彩色化。 使用 Disco 提供了一个简单的在线演示,可以用于测试模型。 访问…...

ChatGPT AIGC 制作大屏可视化分析案例
第一部分提示词prompt: 商品 价格 p1 13 p2 41 p3 42 p4 53 p5 19 p6 28 p7 92 p8 62 城市 销量 北京 69 上海 13 南京 18 武汉 66 成都 70 你现在是一名非常专业的数据分析师,请结合上述数据完成下列几件事情 1:第一部分数…...

2023年9款好用的在线流程图软件推荐!
随着互联网技术和基础设施的发展,人们能用上比过去更加稳定的网络,因此在使用各类工具软件时,越来越倾向于选择在线工具,或是推出了网页版的应用。 就流程图软件而言,过去想要绘制流程图,我们得在电脑上安…...

剑指Offer || 044.在每个树行中找最大值
题目 给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。 示例1: 输入: root [1,3,2,5,3,null,9] 输出: [1,3,9] 解释:1/ \3 2/ \ \ 5 3 9 示例2: 输入: root [1,2,3] 输出: [1,3] 解释:1/ \2 3示例3ÿ…...

ESP32网络开发实例-UDP数据发送与接收
UDP数据发送与接收 文章目录 UDP数据发送与接收1、UDP简单介绍2、软件准备3、硬件准备4、代码实现本文将详细介绍在Arduino开发环境中,如何实现ESP32通过UDP协议进行数据发送与接收。 1、UDP简单介绍 用户数据报协议 (UDP) 是一种跨互联网使用的通信协议,用于对时间敏感的传…...

液压自动化成套设备比例阀放大器
液压电气成套设备的比例阀放大器是一种电子控制设备,用于控制液压动力系统中的液压比例阀1。 比例阀放大器通常采用电子信号进行控制,以控制比例阀的开度和流量,以实现液压系统的可靠控制。比例阀放大器主要由以下组成部分: 驱动…...

专业144,总分440+,上岸西北工业大学827西工大信号与系统考研经验分享
我的初试备考从4月末,持续到初试前,这中间没有中断。 总的时间分配上,是数学>专业课>英语>政治,虽然大家可支配时间和基础千差万别,但是这么分配是没错的。 数学 时间安排:3月-7月:…...

JQuery - template.js 完美解决动态展示轮播图,轮播图不显示问题
介绍 在JQuery中,使用template.js把轮播图的图片渲染到页面后,发现无法显示。 解决方案 首先,打开控制台发现,图片dom是生成了的,排除dom的缺失其次,换了一个插件Swiper,发现效果一样,排除插件的沦丧把动态数据换成假数据,...

CC2540和CC2541的区别简单解析
CC2541理论上是CC2540的精简版,去除了USB接口,增加了1个HW1C接口。 CC2540集成了2.4GHz射频收发器,是一款完全兼容8051内核的无线射频单片机,它与蓝牙低功耗协议栈共同构成高性价比、低功耗的片上系统(SOC)…...
-- Stream的collect()与Collectors的联合运用)
Java8 新特性之Stream(八)-- Stream的collect()与Collectors的联合运用
目录 1. collect()的 收集 作用 2. collect()的 统计 作用 3. collect()的 分组 作用 4. collect()的 拼接 作用...
SpringBoot基础详解
目录 SpringBoot自动配置 基于条件的自动配置 调整自动配置的顺序 纷杂的SpringBoot Starter 手写简单spring-boot-starter示例 SpringBoot自动配置 用一句话说自动配置:EnableAutoConfiguration借助SpringFactoriesLoader将标准了Configuration的JavaConfig类…...
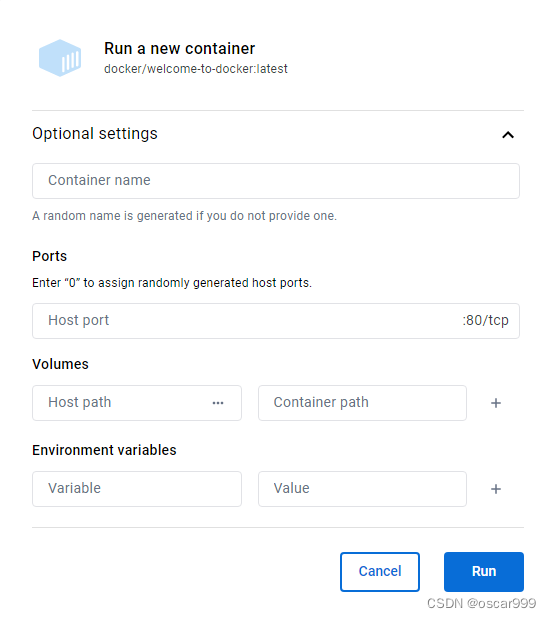
学会Docker之---应用场景和基本操作
实体机、VM和容器 实体机(Physical Machine)是指实际的物理设备,例如我们常见的计算机主机、服务器等。它们是由硬件组成,可以直接运行操作系统和应用程序。 虚拟机(Virtual Machine)是在一台物理机上通过…...

C++_linux下_非阻塞键盘控制_程序暂停和继续
1. 功能 在程序执行过程中,点击键盘p按键(pause), 程序暂停, 点击键盘上的n按键(next),程序继续执行 2. 代码 #include <iostream> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <sys/ioctl.h> char get_keyboar…...
)
SQL AND, OR and NOT(与,或不是运算符)
SQL AND & OR 运算符 AND&OR运算符用于根据一个以上的条件过滤记录,即用于组合多个条件以缩小SQL语句中的数据。 WHERE子句可以与AND,OR和NOT运算符结合使用。 AND和OR运算符用于根据多个条件筛选记录: 如果由AND分隔的所有条件为TR…...

STM32 的IIC通信接收和发送详解
STM32 的 IIC 通信:IIC 接收和发送详解 1. 前言 IIC,也常写作 I2C,是单片机开发中非常常用的一种同步串行通信协议。 在 STM32 项目中,很多外设模块都会使用 IIC 通信,例如: OLED 显示屏;EEPROM…...

靠谱的openai claudecode AI中转站
各位大神开发都用那些模型?最近用Trae的模型一下就降智,切换到apikeyfun.com 用了ops4.7和gpt5.5简直是降维打击,速度快,还不错!...

告别Web Client:当ESXi主机SSH连不上时,我用这10条esxcli命令完成了紧急修复
告别Web Client:当ESXi主机SSH连不上时,我用这10条esxcli命令完成了紧急修复 凌晨三点,数据中心告警铃声刺破夜空。一台承载着核心业务的ESXi主机突然失联,vSphere Client和Web界面均无法访问,SSH连接也毫无响应。面对…...

Context-Mode:基于React Context的模式化状态管理新范式
1. 项目概述:一个为现代前端开发量身定制的状态管理新范式 最近在重构一个中后台项目时,我又一次陷入了状态管理的泥潭。组件间层层传递的 props 像一团乱麻,全局 store 里塞满了各种不相关的数据,每次修改一个状态都得小心翼…...

抖音批量下载神器:三步搞定无水印视频下载,告别手动烦恼
抖音批量下载神器:三步搞定无水印视频下载,告别手动烦恼 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser f…...

STM32篇-12.指针函数和函数指针
指针函数是什么指针函数是指返回值类型为指针的函数 比如:int* open(void) { return (an addr); }该函数返回的地址或者变量;函数指针是什么函数指针其实类似变量的指针; 比如下面:#include <stdio.h>void open(void) {prin…...

如何在Windows平台上快速构建专业级词法语法分析器:WinFlexBison终极指南
如何在Windows平台上快速构建专业级词法语法分析器:WinFlexBison终极指南 【免费下载链接】winflexbison Main winflexbision repository 项目地址: https://gitcode.com/gh_mirrors/wi/winflexbison WinFlexBison是Windows平台上最专业的词法分析和语法解析…...

使用Nodejs和Taotoken快速构建一个支持多模型切换的聊天服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js和Taotoken快速构建一个支持多模型切换的聊天服务 基础教程类,面向全栈或后端开发者,教程将引导…...

终极ASI加载器:Windows游戏修改的完整解决方案
终极ASI加载器:Windows游戏修改的完整解决方案 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ultimate-ASI-Loader …...
)
用Logisim从零搭建MIPS CPU:我的计组课设通关实录(附完整电路文件)
从零构建MIPS CPU:一位计算机系学生的Logisim实战指南 1. 为什么选择Logisim搭建MIPS CPU 作为一名计算机专业的学生,第一次接触计算机组成原理课程设计时,面对"用Logisim搭建MIPS CPU"这个任务,我既兴奋又忐忑。兴奋的…...