Hadoop3教程(十六):MapReduce中的OutputFormat
文章目录
- (105)OutputFormat概述
- (106)自定义OutputFormat案例需求分析
- (107/108)自定义OutputFormat案例实现
- 自定义Mapper
- 自定义Reducer
- 自定义OutputFormat
- Driver
- 参考文献
(105)OutputFormat概述
我们之前讲过了Map阶段的InputFormat,对应的,Reduce阶段也有自己的OutputFormat。
Reducer在执行完reduce()之后,接下来就会通过OutputFormat来将处理结果输出至外界环境。
Hadoop里默认使用的是TextOutputFormat,即将reduce()的处理结果,按行输出到文件。
而OutputFormat是MapReduce输出的基类,所有实现了MR输出的程序,都必须实现OutputFormat接口。
OutputFormat有几种官方自带的实现类(具体功能就不展开了):
- NullOutputFormat
- FileOutputFormat
- MapFileOutputFormat
- SequenceFileOutputFormat
- TextOutputFormat(默认)
- FilterOutputFormat
- LazyOutputFormat
- DBOutputFormat
OutputFormat类的核心方法:public abstract RecordWriter<K,V> getRecordWriter(...)
最终结果怎么写,以什么形式写,写到哪儿,等等这些,都是在getRecordWriter()里控制的。
当然,这些自带的实现类在日常的生产中肯定是不足以满足各种情况的,所以多数情况下,我们会实现自定义的OutputFormat类。
自定义OutputFormat实现类需要:
- 继承FileOutputFormat;
- 改写RecordWriter,具体改写输出数据的方法write()
(106)自定义OutputFormat案例需求分析
需求:输入是一个日志文件,即log.txt,里面是罗列了一些访问过的网站,现在需要把其中包含atguigu的网站输出到a.log,不包含atguigu的网站输出到b.log。
输入数据形如:
http://www.baidu.com
http://www.atguibu.com
...
我们需要自定义一个OutputFormat类,即创建一个类LogRecordWriter继承RecordWriter,然后创建两个文件输出流,一个是atguiguOut,一个是otherOut。如果输入数据包含atguigu,就输出到atguiguOut,反之则输出到otherOut流。
最后还需要在驱动类里注册一下:
job.setOutputFormatClass(LogOutputFormat.class);
附注:
其实这个需求从直观上来讲,是可以通过分区来实现类似功能的,但是很遗憾,分区的话无法控制输出文件的名字,所以没法严格符合需求。
(107/108)自定义OutputFormat案例实现
这里直接复制了教程里的代码,来介绍一下,如何针对上一小节提出的需求,自定义OutputFormat。
自定义Mapper
首先需要创建一个自定义的Mapper类,如class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>
package com.atguigu.mapreduce.outputformat;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class LogMapper extends Mapper<LongWritable, Text,Text, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//不做任何处理,直接写出一行log数据context.write(value,NullWritable.get());}
}
自定义Reducer
然后新建一个自定义Reducer类:
package com.atguigu.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class LogReducer extends Reducer<Text, NullWritable,Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {// 防止有相同的数据,迭代写出for (NullWritable value : values) {context.write(key,NullWritable.get());}}
}
自定义OutputFormat
这里是最重要的一步,就是自定义一个OutputFormat类,继承RecordWriter:
- 创建两个文件的输出流:atguiguOut、otherOut;
- 如果输入数据中含有atguigu,则输出至atguiguOut,反之则输出到otherOut;
首先自定义OutputFormat类,重写RecordWriter方法,将我们自定义的LogRecordWriter放进去。
package com.atguigu.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> {@Overridepublic RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {//创建一个自定义的RecordWriter返回LogRecordWriter logRecordWriter = new LogRecordWriter(job);return logRecordWriter;}
}
然后编写LogRecordWriter类,:
package com.atguigu.mapreduce.outputformat;import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;import java.io.IOException;public class LogRecordWriter extends RecordWriter<Text, NullWritable> {private FSDataOutputStream atguiguOut;private FSDataOutputStream otherOut;public LogRecordWriter(TaskAttemptContext job) {try {//获取文件系统对象FileSystem fs = FileSystem.get(job.getConfiguration());//用文件系统对象创建两个输出流对应不同的目录atguiguOut = fs.create(new Path("d:/hadoop/atguigu.log"));otherOut = fs.create(new Path("d:/hadoop/other.log"));} catch (IOException e) {e.printStackTrace();}}@Overridepublic void write(Text key, NullWritable value) throws IOException, InterruptedException {String log = key.toString();//根据一行的log数据是否包含atguigu,判断两条输出流输出的内容if (log.contains("atguigu")) {atguiguOut.writeBytes(log + "\n");} else {otherOut.writeBytes(log + "\n");}}@Overridepublic void close(TaskAttemptContext context) throws IOException, InterruptedException {//关流IOUtils.closeStream(atguiguOut);IOUtils.closeStream(otherOut);}
}
Driver
最后编写LogDriver驱动类,把我们前面自定义的的类统统在驱动类里注册上:
package com.atguigu.mapreduce.outputformat;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(LogDriver.class);job.setMapperClass(LogMapper.class);job.setReducerClass(LogReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);//设置自定义的outputformatjob.setOutputFormatClass(LogOutputFormat.class);FileInputFormat.setInputPaths(job, new Path("D:\\input"));//虽然我们自定义了outputformat,但是因为我们的outputformat继承自fileoutputformat//而fileoutputformat要输出一个_SUCCESS文件,所以在这还得指定一个输出目录FileOutputFormat.setOutputPath(job, new Path("D:\\logoutput"));boolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
}
至此需求完成。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
:MapReduce中的OutputFormat)
Hadoop3教程(十六):MapReduce中的OutputFormat
文章目录 (105)OutputFormat概述(106)自定义OutputFormat案例需求分析(107/108)自定义OutputFormat案例实现自定义Mapper自定义Reducer自定义OutputFormatDriver 参考文献 (105)Outp…...

通过表查询 sm37 排程运行情况 JOB 数据保存在表TBTCP 和 TBTCO中
sm36 设置排程 sm37 查看排程 se11 查表 Values for TBTCO-STATUS: A - Cancelled F - Completed P - Scheduled R - Active S - Released JOB 数据保存在表TBTCP 和 TBTCO中 参考 https://blog.51cto.com/u_15680210/5757746?articleABtest0 https://answers.sap.co…...

append_ocr_trainf
read_image (Image, D:/图像文件/字符识别/1-1.bmp) access_channel (Image, Image1, 1) * draw_rectangle2 (3600, Row, Column, Phi, Length1, Length2) gen_rectangle2 (Rectangle, 96.0436, 715.9526, 0.0173917050943654, 110.186941, 18.041084) reduce_domain (Image1, …...
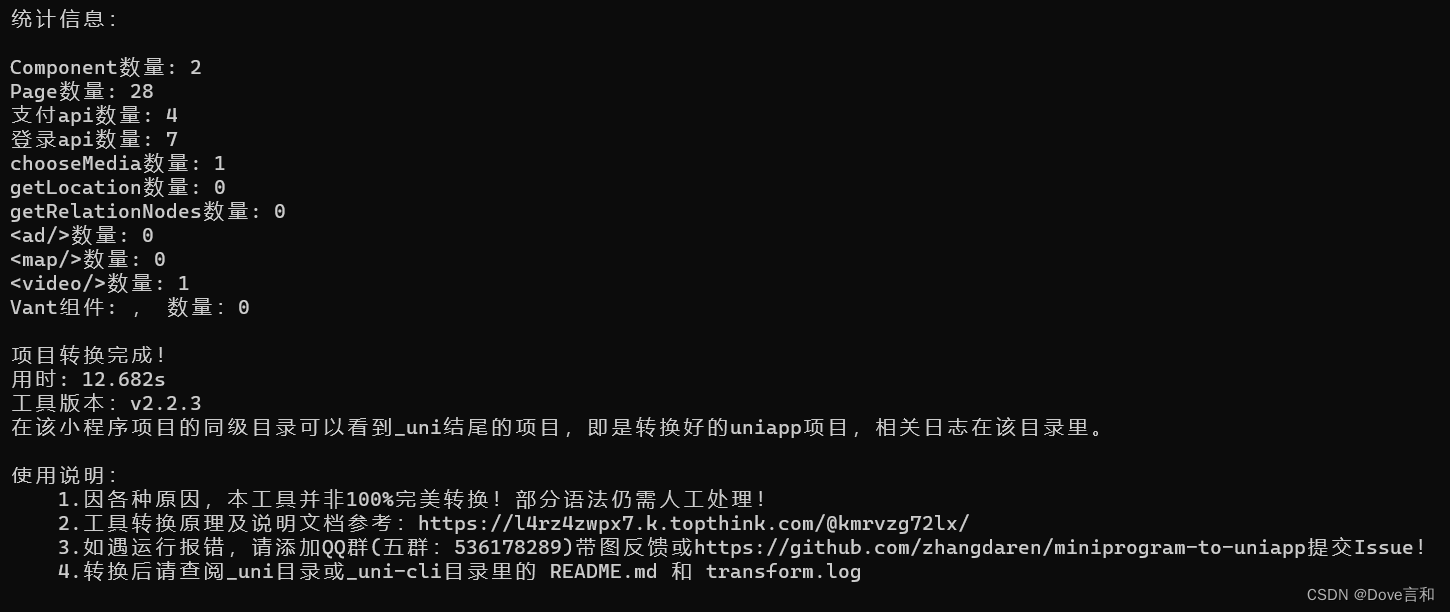
小程序原生代码转uniapp
写了一份小程序原生代码,想转为uniapp 再转为其他平台发布 1、在命令行里,运行【 npm install miniprogram-to-uniapp -g 】进行安装,因为这个包是工具,要求全局都能使用&#x…...

云原生微服务 第五章 Spring Cloud Netflix Eureka集成负载均衡组件Ribbon
系列文章目录 第一章 Java线程池技术应用 第二章 CountDownLatch和Semaphone的应用 第三章 Spring Cloud 简介 第四章 Spring Cloud Netflix 之 Eureka 第五章 Spring Cloud Netflix 之 Ribbon 文章目录 系列文章目录[TOC](文章目录) 前言1、负载均衡1.1、服务端负载均衡1.2、…...
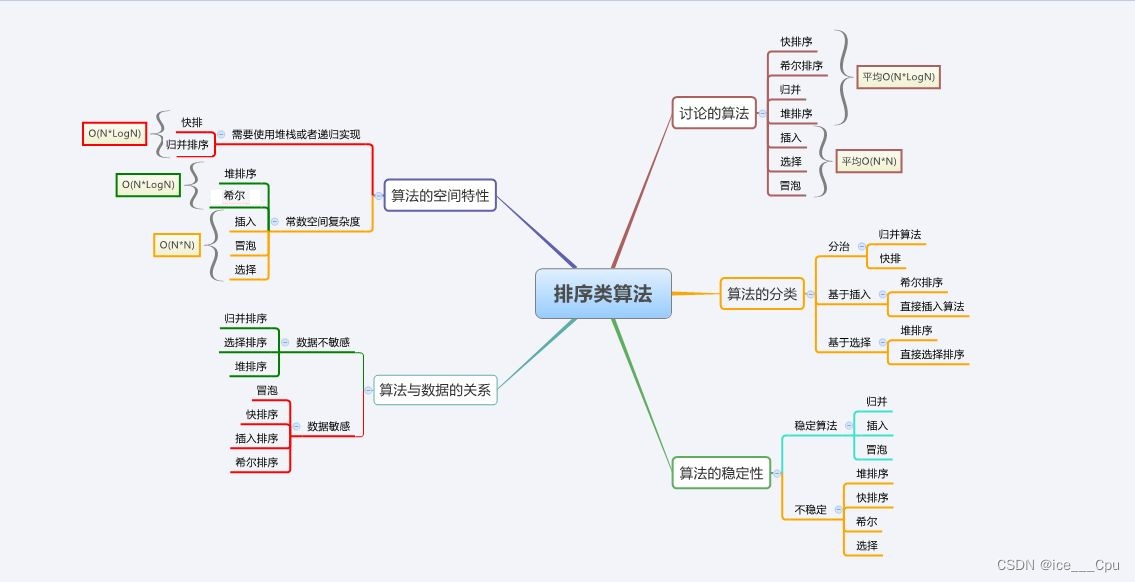
七大排序 (9000字详解直接插入排序,希尔排序,选择排序,堆排序,冒泡排序,快速排序,归并排序)
一:排序的概念及引入 1.1 排序的概念 1.1 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在…...

一、nginx配置
一、nginx配置 配置简介 1)nginx相关目录 工作目录:/etc/nginx 执行文件:/usr/sbin/nginx 日志目录:/var/log/nginx 启动文件:/etc/init.d/nginx web目录:/var/www/html/,首页文件是index.ng…...

win32汇编-LEA指令是将一个内存地址加载到一个寄存器中
LEA (Load Effective Address) 指令是用来将一个内存地址加载到一个寄存器中的指令。 其语法为: lea destination, source 其中,destination 是目标寄存器,source 是一个内存地址(即一个存储器操作数)。 举个例子…...

leetcode做题笔记189. 轮转数组
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: [5,6,7,1,2,3,4…...

数据库第七章作业
本篇用于日常记录和分享 第7章作业.xls 题量: 25 满分: 100 一. 单选题(共25题) 1. (单选题)二级封锁协议不能保证消除( )这一不一致现象。 A. 读取脏数据B. 死锁C. 不可重复读D. 丢失修改 我的答案: C :不可重复读; 2. (单…...

使用服务器训练模型的注意事项
一、图像展示 1.1、用VS Code远程连接服务器时,当我们想用matplotlib库来进行图像展示的时候,需要设置DISPLAY变量。 # 用终端工具(XShell)SSH远程服务器,在终端上输入下列语句 # 如果使用了anaconda的虚拟环境&…...

Linux性能优化--性能追踪3:系统级迟缓(prelink)
12.0 概述 本章包含的例子说明了如何用Linux性能工具寻找并修复影响整个系统而不是某个应用程序的性能问题。阅读本章后,你将能够: 追踪是哪一个进程导致了系统速度的降低。用strace调查一个不受CPU限制的进程的性能表现。用strace调查一个应用程序是如…...

SpringBoot2.x简单集成Flowable
环境和版本 window10 java1.8 mysql8 flowable6 springboot 2.7.6 配置 使用IDEA创建一个SpringBoot项目 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.…...
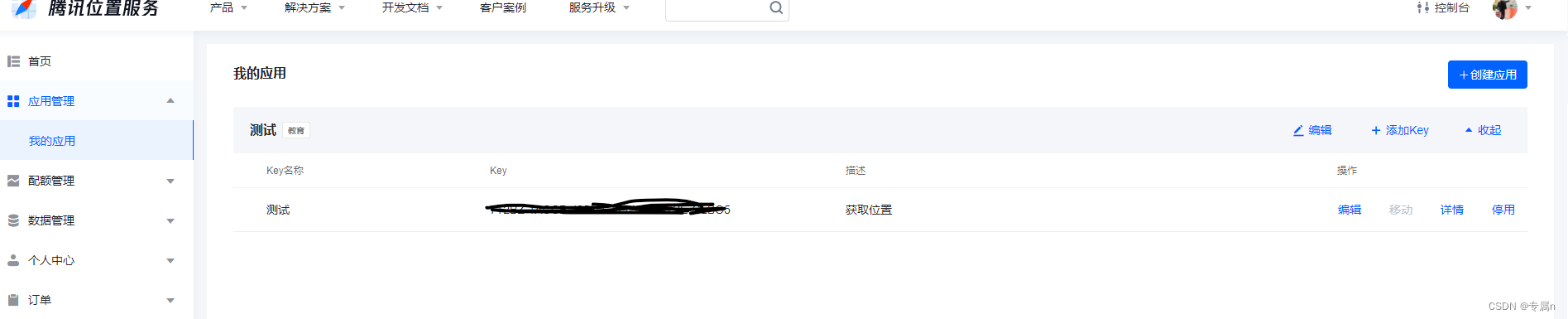
微信小程序一键获取位置
需求 有个表单需要一键获取对应位置 并显示出来效果如下: 点击一键获取获取对应位置 显示在 picker 默认选中 前端 代码如下: <view class"box_7 {{ showChange1? change-style: }}"><view class"box_11"><view class"…...
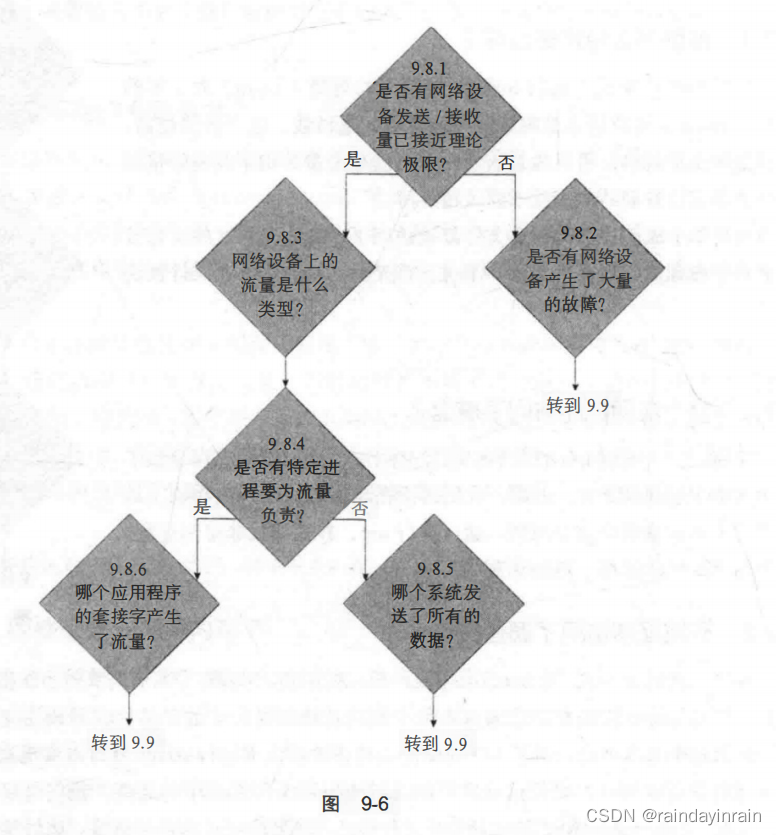
Linux性能优化--使用性能工具发现问题
9.0 概述 本章主要介绍综合运用之前提出的性能工具来缩小性能问题产生原因的范围。阅读本章后,你将能够: 启动行为异常的系统,使用Linux性能工具追踪行为异常的内核函数或应用程序。启动行为异常的应用程序,使用Linux性能工具追…...
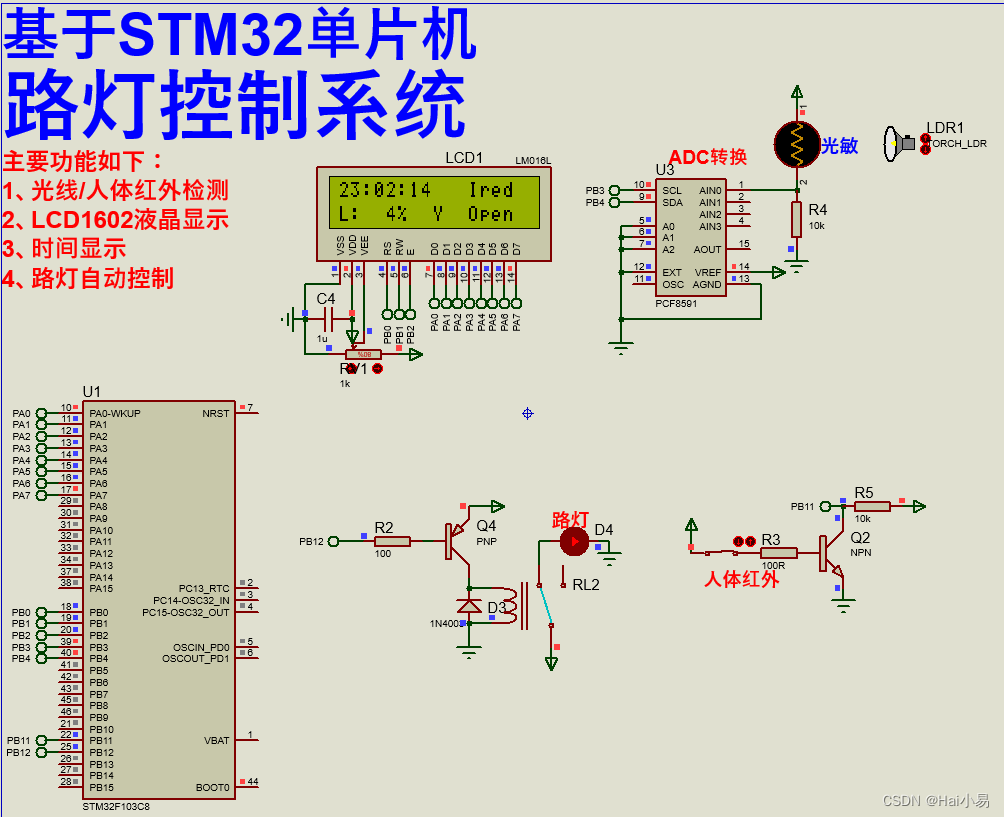
【Proteus仿真】【STM32单片机】路灯控制系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用LCD1602显示模块、人体红外传感器、光线检测模块、路灯继电器控制等。 主要功能: 系统运行后,LCD1602显示时间、工作模…...

Flutter笔记:发布一个Flutter头像模块 easy_avatar
Flutter笔记 发布一个头像Flutter模块 easy_avatar 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/1339…...

标准化助推开源发展丨九州未来参编开源领域4项团体标准正式发布
在数字中国及数字经济时代的大背景下,开源逐步成为各行业数字化发展的关键模式。在开源产业迅速发展的同时,如何评估、规范开源治理成为行业极度关注的问题。 近日,中电标2023年第27号团体标准公告正式发布,九州未来作为起草单位…...

ChatGPT对于留学生论文写作有哪些帮助?
2022年11月,OpenAI公司的智能聊天产品ChatGPT横空出世,并两个月之内吸引了超过1亿用户,打破了TikTok(抖音国际版)9个月用户破亿的纪录。 划时代的浪潮 ChatGPT的火爆立即引起了全球关注并成为热门话题,它…...

【yolov8目标检测】使用yolov8训练自己的数据集
目录 准备数据集 python安装yolov8 配置yaml 从0开始训练 从预训练模型开始训练 准备数据集 首先得准备好数据集,你的数据集至少包含images和labels,严格来说你的images应该包含训练集train、验证集val和测试集test,不过为了简单说…...

有些路看起来很难走,其实是在带你慢慢变强
生活里,很多人都希望自己走的是一条轻松一点、顺利一点的路。最好努力了就能有结果,付出了就能被看见,遇到的问题也都能很快解决。可真正经历过一些事情后才会发现,人生并不会总按照理想的节奏前进。很多时候,那些让人…...
Pixel Aurora Engine部署案例:边缘计算设备(Jetson Orin)轻量化部署
Pixel Aurora Engine部署案例:边缘计算设备(Jetson Orin)轻量化部署 1. 项目背景与价值 Pixel Aurora Engine是一款基于AI扩散模型的创意工具,专为生成复古像素艺术设计。其独特的8-bit游戏风格界面和高效生成能力,使…...

教育培训品牌视觉体系全攻略:5步打造统一、专业、让人过目不忘的品牌形象
教育培训机构的品牌视觉是否混乱,直接影响家长和学员的第一印象。宣传海报用一种蓝,公众号封面又是另一种蓝,课程介绍册的字体也和官网不一样。这种视觉不统一的问题,会让品牌显得不够专业,降低信任感。今天分享一套用…...

Legacy iOS Kit终极指南:让你的旧iPhone/iPad重获新生!
Legacy iOS Kit终极指南:让你的旧iPhone/iPad重获新生! 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-i…...

QMCFLAC2MP3终极指南:一键解锁QQ音乐格式限制的完整解决方案
QMCFLAC2MP3终极指南:一键解锁QQ音乐格式限制的完整解决方案 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经从QQ音乐下载了心爱的歌曲…...

用STM32F103C8T6和NRF24L01自制遥控器,从硬件选型到代码调试的完整避坑指南
STM32F103C8T6与NRF24L01遥控器开发实战:从硬件设计到软件调试的全流程解析 在创客和嵌入式开发领域,无线遥控系统一直是热门话题。无论是机器人控制、无人机飞行还是智能家居应用,稳定可靠的遥控器都是不可或缺的核心组件。本文将详细介绍如…...

1.6.2 掌握Scala数据结构 - 列表
本次实战深入讲解了Scala中不可变列表与可变列表的核心操作。首先,详细演示了不可变列表的创建与元素添加,重点强调了其不可变特性——任何添加或合并操作(如::、)都会生成新列表而不改变原列表。接着,介绍了可变列表L…...

漫画脸描述生成保姆级教程:如何调试生成结果提升SD绘图匹配度
漫画脸描述生成保姆级教程:如何调试生成结果提升SD绘图匹配度 你是不是也遇到过这样的情况:脑子里有个超棒的二次元角色形象,但用AI绘图工具画出来总是差那么点意思?要么发型不对,要么表情奇怪,要么服装细…...
信号传输差异对比与选型建议)
CameraLink三种模式(Base/Medium/Full)信号传输差异对比与选型建议
CameraLink三种工作模式深度解析与工业选型实战指南 在工业视觉检测线上,一台高速运行的贴片机正以每分钟800次的速度捕捉元件位置。当工程师将相机从200万像素升级到800万像素时,原本稳定的图像突然出现随机噪点——这往往是CameraLink模式选择不当导致…...

高标准农田+农业四情监测——智慧农业小型气象站
智慧农业气象站解决方案,结合农业种植实际需求,整合核心硬件与软件技术,具备四大核心优势,彻底解决传统气象监测的痛点,助力智慧农业落地:12要素全面监测,数据精准可靠:覆盖农业生产…...