Stable Diffusion原理
一、Diffusion扩散理论
1.1、 Diffusion Model(扩散模型)
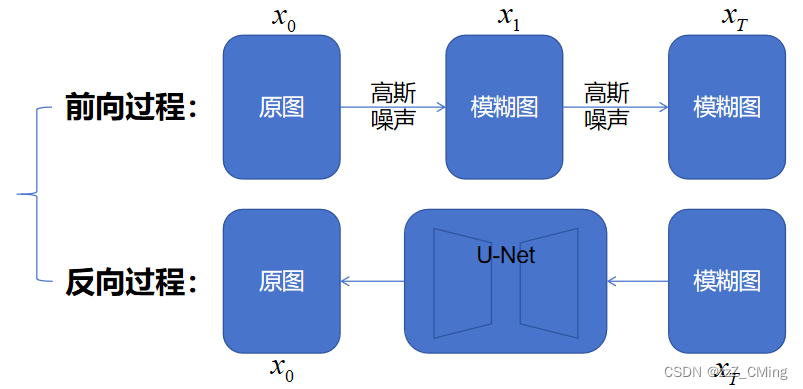
Diffusion扩散模型分为两个阶段:前向过程 + 反向过程
- 前向过程:不断往输入图片中添加高斯噪声来破坏图像
- 反向过程:使用一系列马尔可夫链逐步将噪声还原为原始图片
前向过程 ——>图片中添加噪声
反向过程——>去除图片中的噪声
1.2、 训练过程:U-Net网络
在每一轮的训练过程中,包含以下内容:
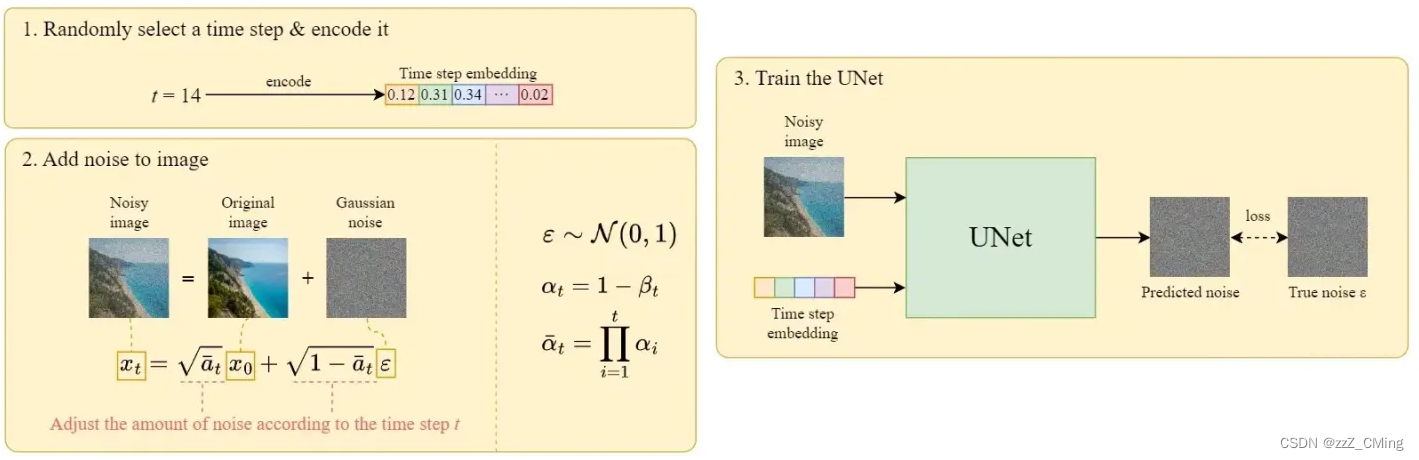
- 每一个训练样本对应一个随机时刻向量time step,编码时刻向量t转化为对应的time step Embedding向量;
- 将时刻向量t对应的高斯噪声ε应用到图片中,得到噪声图Noisy image;
- 将成组的time step Embedding向量、Noisy image注入到U-Net训练;
- U-Net输出预测噪声Predicted noise,与真实高斯噪声True noise ε,构建损失。
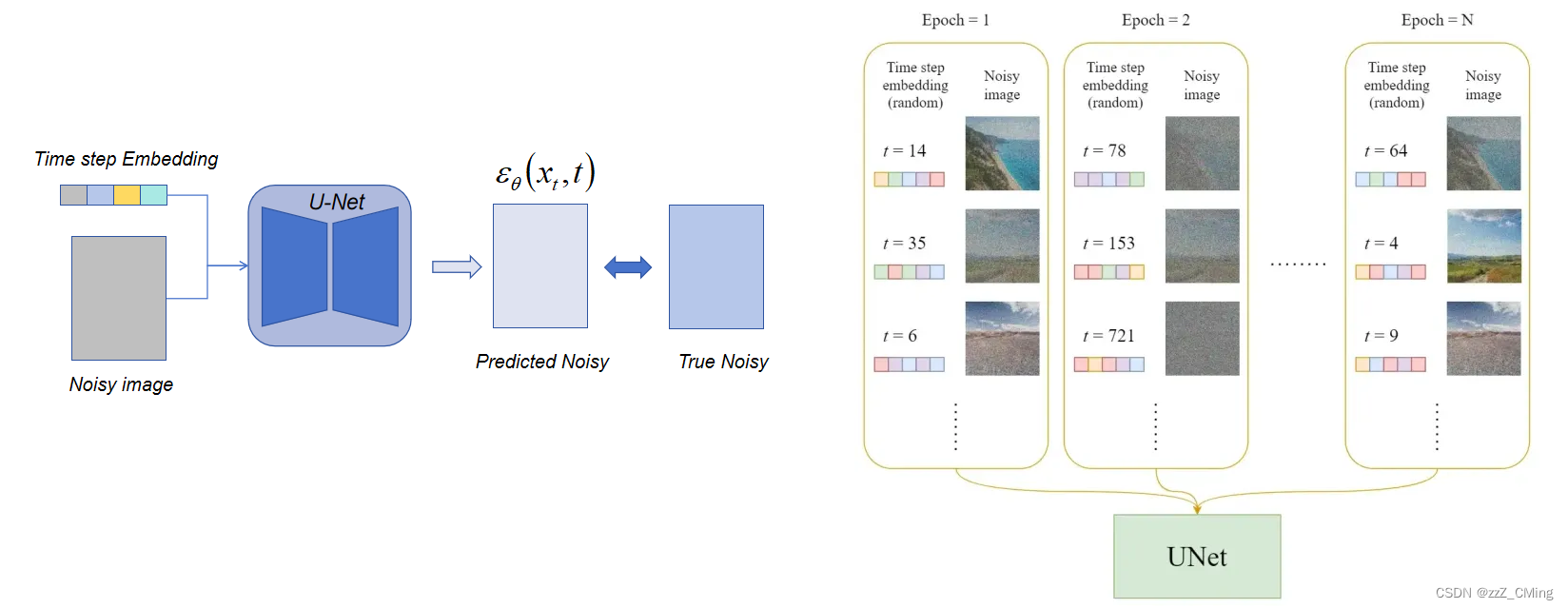
下图是每个Epoch详细的训练过程:

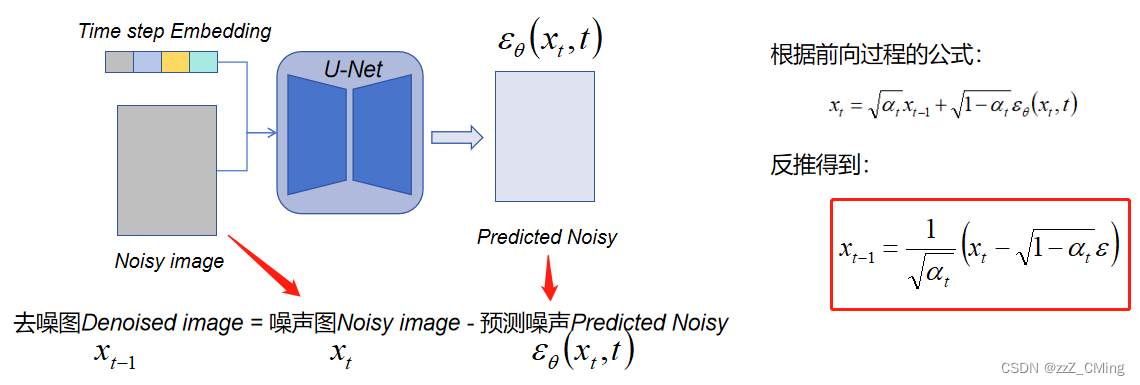
1.3、 推理过程:反向扩散
噪声图Noisy image经过训练后的U-Net网络,会得到预测噪声Predicted Noisy,而:去噪图Denoised image = 噪声图Noisy image - 预测噪声图Predicted Noisy。(计算公式省略了具体的参数,只表述逻辑关系)
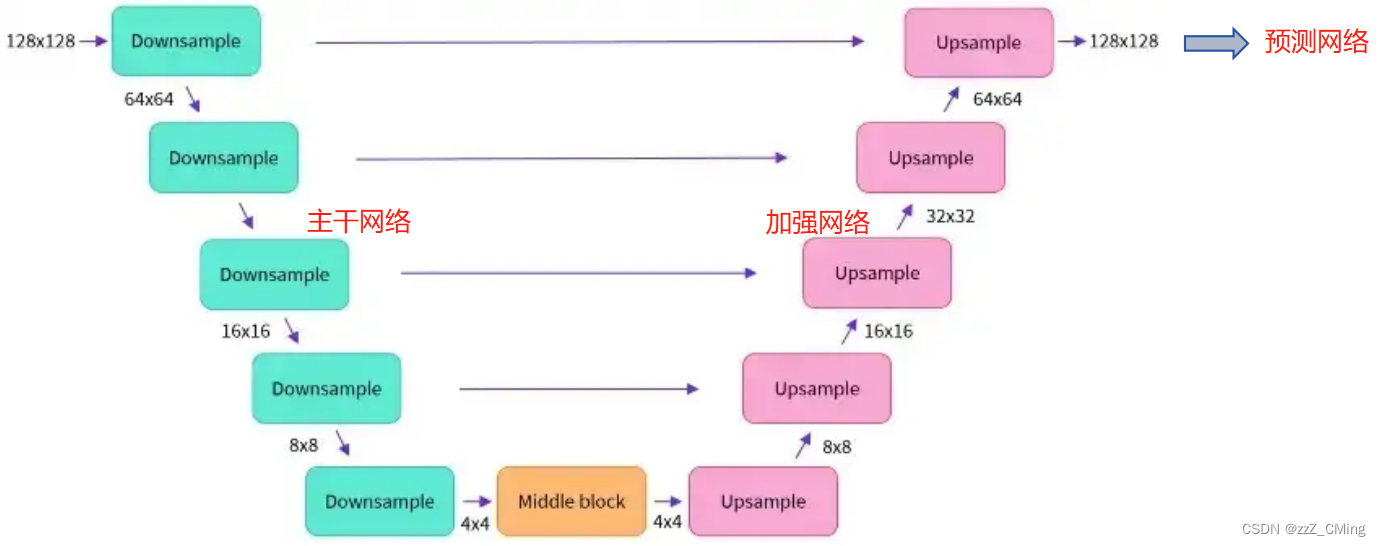
1.4、 补充:U-Net结构
U-Net的模型结构就是一个编-解码的过程,下采样Downsample、中间块Middle block、上采样Upsample中都包含了ResNet残差网络
1、主干网络做特征提取;2、加强网络做特征组合;3、预测网络做预测输出;
1.5、补充:DM扩散模型的缺点
- Diffusion Model是在原图上完成前向、反向扩散过程,计算量巨大;
- Diffusion Model只与时刻向量t产生作用,生成的结果不可控;
二、Stable Diffusion原理
为改善DM扩散模型的缺点,Stable Diffusion引入图像压缩技术,在低维空间完成扩散过程;并添加CLIP模型,使文本-图像产生关联。
2.1、Stable Diffusion的改进点
1. 图像压缩:DM扩散模型是直接在原图上进行操作,而Stale Diffusion是在较低维度的潜在空间上应用扩散过程,而不是使用实际像素空间,这样可以大幅减少内存和计算成本;
2. 文本-图像关联:在反向扩散过程中对U-Net的结构做了修改,使其可以添加文本向量Text Embedding,使得在每一轮的去噪过程中,让输出的图像与输入的文字产生关联;

2.2、Stable Diffusion的生成过程
Stable Diffusion在实际应用中的过程:原图——经过编码器E变成低维编码图——DM的前向过程逐步添加噪声,变成噪声图——T轮U-Net网络完成DM的反向过程——经过解码器D变成新图。
- Stable Diffusion会事先训练好一个编码器E、解码器D,来学习原始图像与低维数据之间的压缩、还原过程;
- 首先通过训练好的编码器E ,将原始图像压缩成低维数据,再经过多轮高斯噪声转化为低维噪声Latent data;
- 然后用低维噪声Latent data、时刻向量t、文本向量Text Embedding、在U-Net网络进行T轮去噪,完成反向扩散过程;
- 最后将得到的低维去噪图通过训练好的解码器D,还原出原始图像,完成整个扩散生成过程。
2.3、补充:CLIP模型详解
CLIP(Contrastive Language-Image Pre-Training) 模型是 OpenAI 在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,是近年来在多模态研究领域的经典之作。OpenAI 收集了 4 亿对图像文本对(一张图像和它对应的文本描述),分别将文本和图像进行编码,使用 metric learning进行训练。希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
CLIP的论文地址
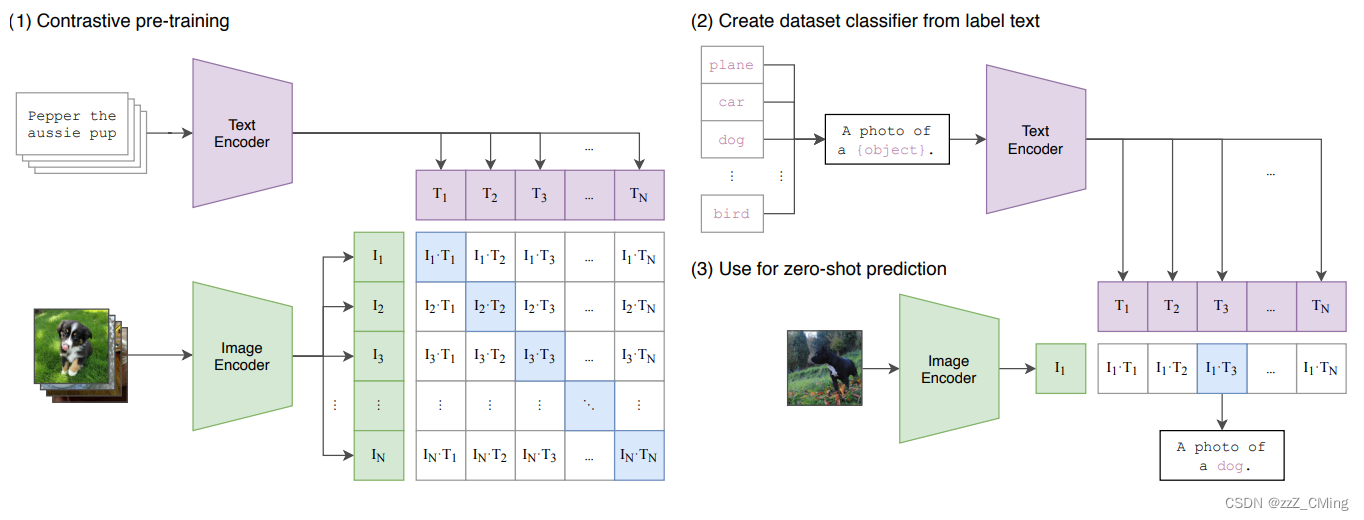
CLIP模型共有3个阶段:1阶段用作训练,2、3阶段用作推理。
- Contrastive pre-training:预训练阶段,使用图片 - 文本对进行对比学习训练;
- Create dataset classifier from label text:提取预测类别文本特征;
- Use for zero-shot predictiion:进行 Zero-Shot 推理预测;
2.3.1、训练阶段
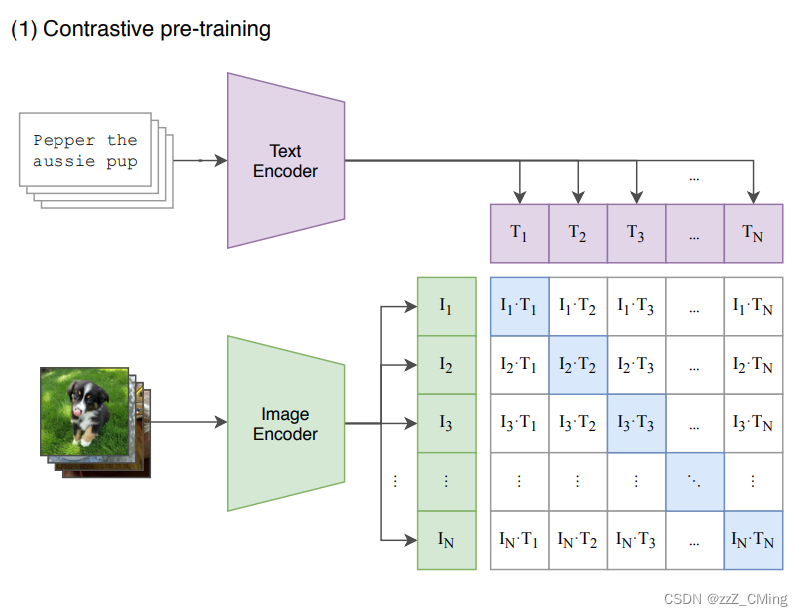
通过计算文本和目标图像的余弦相似度从而获取预测值。CLIP模型主要包含以下两个模型;
- Text Encoder:用来提取文本的特征,可以采用NLP中常用的text transformer模型;
- Image Encoder:用来提取图像的特征,可以采用常用CNN模型或者vision transformer模型;
这里举例一个包含N个文本-图像对的训练batch,对提取的文本特征和图像特征进行训练的过程:
- 输入图片 —> 图像编码器 —> 图片特征向量;输入文字 —> 文字编码器 —> 文字特征向量;并进行线性投射,得到相同维度;
- 将N个文本特征和N个图像特征两两组合,形成一个具有N2个元素的矩阵;
- CLIP模型会预测计算出这N2个文本-图像对的相似度(文本特征和图像特征的余弦相似性即为相似度);
- 对角线上的N个元素因为图像-标签对应正确被作为训练的正样本,剩下的N2-N个元素作为负样本;
- CLIP的训练目标就是最大化N个正样本的相似度,同时最小化N2-N个负样本的相似度;
2.3.2、推理过程
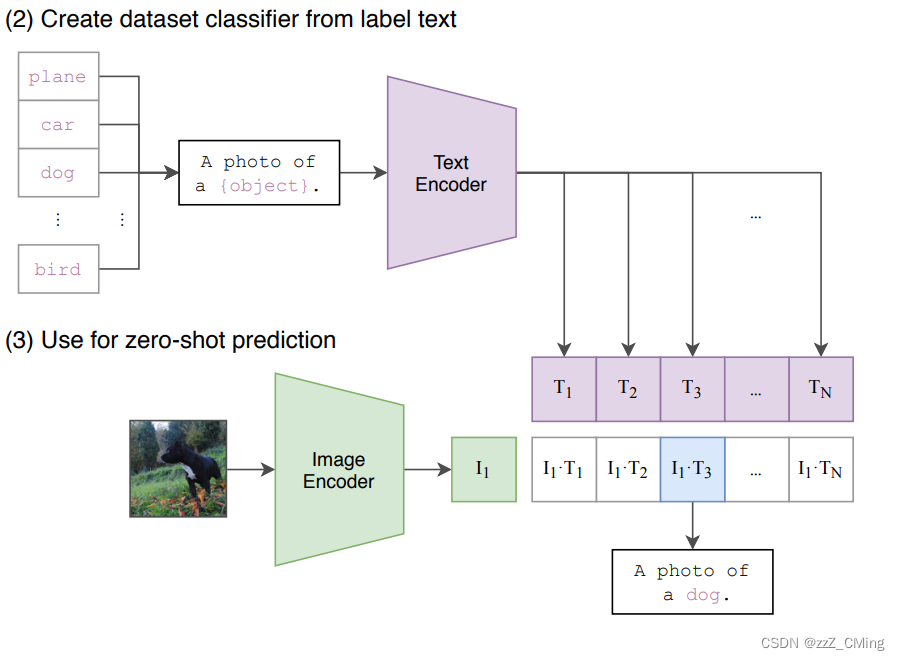
CLIP的预测推理过程主要有以下两步:
- 提取预测类别的文本特征:由于CLIP 预训练文本端的输出输入都是句子,因此需要将任务的分类标签按照提示模板 (prompt template)构造成描述文本(由单词构造成句子):
A photo of {object}.,然后再送入Text Encoder得到对应的文本特征。如果预测类别的数目为N,那么将得到N个文本特征。 - 进行 zero-shot 推理预测:将要预测的图像送入Image Encoder得到图像特征,然后与上述的N个文本特征计算余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果。进一步地,可以将这些相似度看成输入,送入softmax后可以得到每个类别的预测概率。
2.3.3、补充:zero-shot 零样本学习
zero-shot :零样本学习,域外泛化问题。利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集,期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
可以发现CLIP其实就是两个模型:视觉模型 + 文本模型。
在计算机视觉中,即便想迁移VGG、MobileNet这种预训练模型,也需要经过预训练、微调等手段,才能学习数据集的数据特征,而CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类,这也是CLIP亮点和强大之处。
我的猜测:CLIP的zero-shot能力是依赖于它预训练的4亿对图像-文本对,样本空间涵盖的太大,并不是真正的零样本学习,和解决域外泛化问题。和人脸比对的原理相似,依靠大量样本来学习分类对象的特征空间。人脸比对是image-to-image,CLIP是 image-to-text。
2.3.4、代码: CLIP实现zero-shot分类
OpenAI有关CLIP的代码链接地址
2.3.4.1、图像数据、文本数据
向模型提供8个示例图像及其文本描述,并比较相应特征之间的相似性
# images in skimage to use and their textual descriptions
descriptions = {"page": "a page of text about segmentation","chelsea": "a facial photo of a tabby cat","astronaut": "a portrait of an astronaut with the American flag","rocket": "a rocket standing on a launchpad","motorcycle_right": "a red motorcycle standing in a garage","camera": "a person looking at a camera on a tripod","horse": "a black-and-white silhouette of a horse", "coffee": "a cup of coffee on a saucer"
}

2.3.4.2、计算余弦相似度
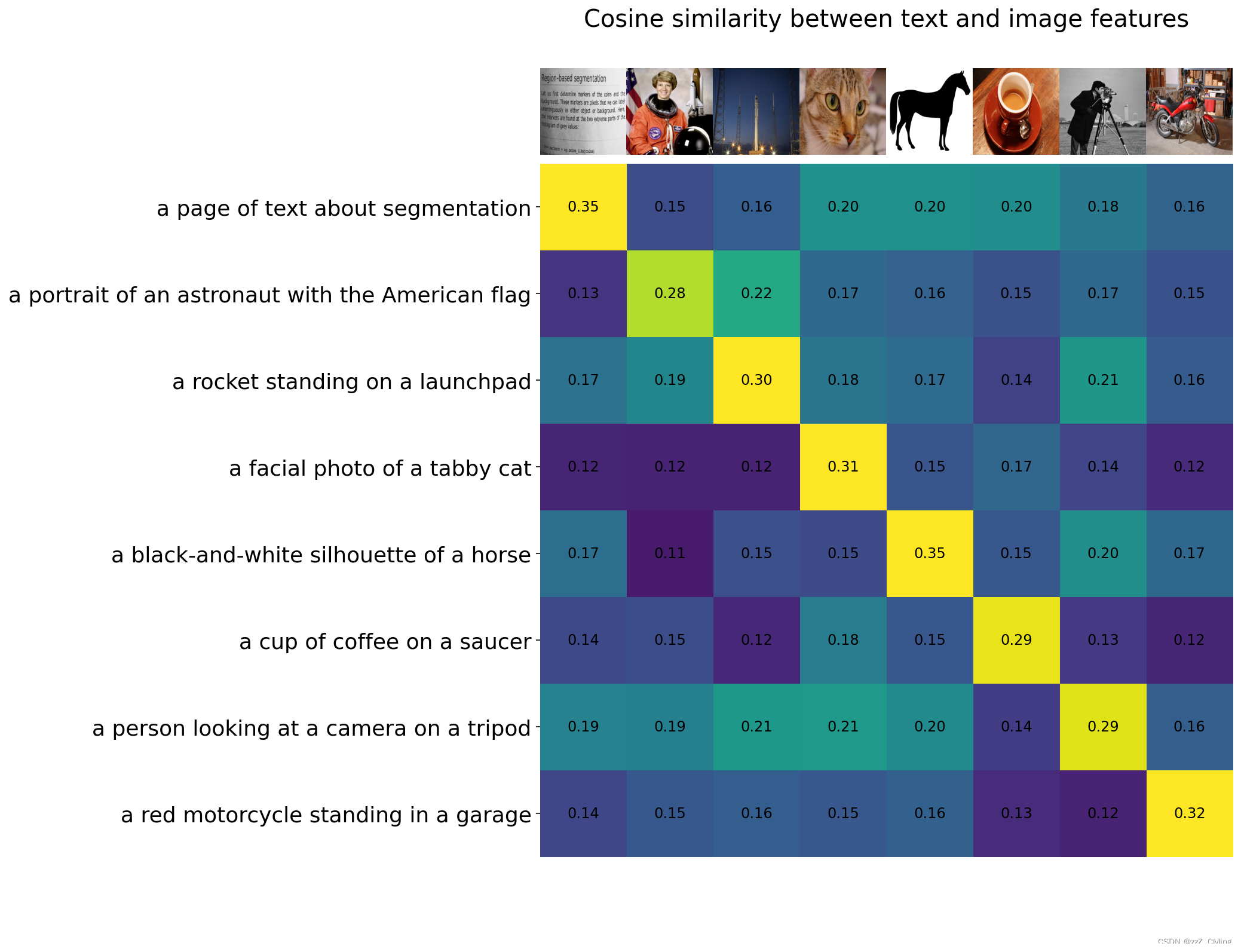
2.3.4.3、Zero-Shot图像分类
from torchvision.datasets import CIFAR100cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()with torch.no_grad():text_features = model.encode_text(text_tokens).float()text_features /= text_features.norm(dim=-1, keepdim=True)text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)plt.figure(figsize=(16, 16))for i, image in enumerate(original_images):plt.subplot(4, 4, 2 * i + 1)plt.imshow(image)plt.axis("off")plt.subplot(4, 4, 2 * i + 2)y = np.arange(top_probs.shape[-1])plt.grid()plt.barh(y, top_probs[i])plt.gca().invert_yaxis()plt.gca().set_axisbelow(True)plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])plt.xlabel("probability")plt.subplots_adjust(wspace=0.5)
plt.show()

2.4、补充:Stable Diffusion训练的四个主流AI模型
- Dreambooth:会使用正则化。通常只用少量图片做输入微调,就可以做一些其他扩散模型不能或者不擅长的事情——具备个性化结果的能力,既包括文本到图像模型生成的结果,也包括用户输入的任何图片;
- text-inversion:通过控制文本到图像的管道,标记特定的单词,在文本提示中使用,以实现对生成图像的细粒度控制;
- LoRA:大型语言模型的低阶自适应,简化过程降低硬件需求;
- Hypernetwork:这是连接到Stable Diffusion模型上的一个小型神经网络,是噪声预测器U-Net的交叉互视(cross-attention)模块;
四个主流模型的区别:
- Dreambooth最直接但非常复杂占内存大,用的人很多评价好;
- text-inversion很聪明,不用重新创作一个新模型,所有人都可以下载并运用到自己的模型,模型小,存储空间占用小;
- LoRA可以在不做完整模型拷贝的情况下,让模型理解这个概念,速度快;
- Hypernetwork:没有官方论文;
三、补充:四大生成模型对比
GAN生成对抗模型、VAE变微分自动编码器、流模型、DM扩散模型
3.1、GAN生成对抗模型
- GAN模型要同时训练两个网络,难度较大,多模态分布学习困难;
- 不容易收敛,不好观察损失;
- 图像特征多样性较差,容易出现模型坍缩,只关注如何骗过判别器;
3.2、VAE变微分自动编码器
Deepfaker、DeepFaceLab的处理方式,生成中间状态
3.3、流模型
待完善
3.4、DM扩散模型
xx
参考:
神器CLIP:连接文本和图像,打造可迁移的视觉模型
相关文章:
Stable Diffusion原理
一、Diffusion扩散理论 1.1、 Diffusion Model(扩散模型) Diffusion扩散模型分为两个阶段:前向过程 反向过程 前向过程:不断往输入图片中添加高斯噪声来破坏图像反向过程:使用一系列马尔可夫链逐步将噪声还原为原始…...

2022年亚太杯APMCM数学建模大赛A题结晶器熔剂熔融结晶过程序列图像特征提取及建模分析求解全过程文档及程序
2022年亚太杯APMCM数学建模大赛 A题 结晶器熔剂熔融结晶过程序列图像特征提取及建模分析 原题再现: 连铸过程中的保护渣使钢水弯液面隔热,防止钢水在连铸过程中再次氧化,控制传热,为铸坯提供润滑,并吸收非金属夹杂物…...

金融网站如何做好安全防护措施?
联网的发展为当代很多行业的发展提供了一个更为广阔的平台,而对于中国的金融业来说,互联网金融这一新兴理念已经为 人们所接受,且发展迅速。我们也都知道金融行业对互联网技术是非常严格的,这对互联网的稳定性和可靠性提出了较高的…...

2023年中国恋爱社区未来发展趋势分析:多元化盈利模式实现可持续发展[图]
恋爱社区指满足情侣之间互动、记录及娱乐需求,以维护情侣恋爱关系的虚拟社区。恋爱社区行业主要以线上APP的虚拟形式为用户提供相关服务,其业务包括情侣记录、情侣互动、情侣娱乐、公共社区、线上购物、增值服务。 恋爱社区主要业务 资料来源࿱…...

Elasticsearch:生成式人工智能带来的社会转变
作者:JEFF VESTAL 了解 Elastic 如何走在大型语言模型革命的最前沿 – 通过提供实时信息并将 LLM 集成到数据分析的搜索、可观察性和安全系统中,帮助用户将 LLM 提升到新的高度。 iPhone 社会转变:新时代的黎明 曾几何时,不久前…...

服务器数据恢复-RAID5中磁盘被踢导致阵列崩溃的服务器数据恢复案例
服务器数据恢复环境: 一台3U的某品牌机架式服务器,Windows server操作系统,100块SAS硬盘组建RAID5阵列。 服务器故障: 服务器有一块硬盘盘的指示灯亮黄灯,这块盘被raid卡踢出后,raid阵列崩溃。 服务器数据…...

负荷不均衡问题分析处理流程
一、负荷不均衡分析 负荷不均衡判断标准:4G同覆盖扇区内存在无线利用率大于50%的小区,且两两小区间无线利用率差值大于30%,判定为4G负荷不均衡扇区;5G同覆盖扇区内存在无线利用率大于50%的小区,且两两小区间无线利用率…...

Spring篇---第四篇
系列文章目录 文章目录 系列文章目录一、说说你对Spring的IOC是怎么理解的?二、解释一下spring bean的生命周期三、解释Spring支持的几种bean的作用域?一、说说你对Spring的IOC是怎么理解的? (1)IOC就是控制反转,是指创建对象的控制权的转移。以前创建对象的主动权和时机…...

算法通过村第十五关-超大规模|白银笔记|经典问题
文章目录 前言从40个亿中产生一个不存在的整数位图存储数据的原理使用10MB来存储如何确定分块的区间 用2GB内存在20亿的整数中找到出现次数最多的数从100亿个URL中查找的问题40亿个非负整数中找出两次的数。总结 前言 提示:人生之中总有空白,但有时&…...
Mini小主机All-in-one搭建教程6-安装苹果MacOS系统
笔者使用的ESXI7.0 Update 3 抱着试试的态度想安装一下苹果的MacOS系统 主要步骤有2个 1.解锁unlocker虚拟机系统 2.安装苹果MacOS系统 需要下载的文件 unlocker 这一步是最耗时间的,要找到匹配自己系统的unlocker文件。 https://github.com/THDCOM/ESXiUnloc…...

Android中使用Glide加载圆形图像或给图片设置指定圆角
一、Glide加载圆形头像 效果 R.mipmap.head_icon是默认圆形头像 ImageView mImage findViewById(R.id.image);RequestOptions options new RequestOptions().placeholder(R.mipmap.head_icon).circleCropTransform(); Glide.with(this).load("图像Uri").apply(o…...
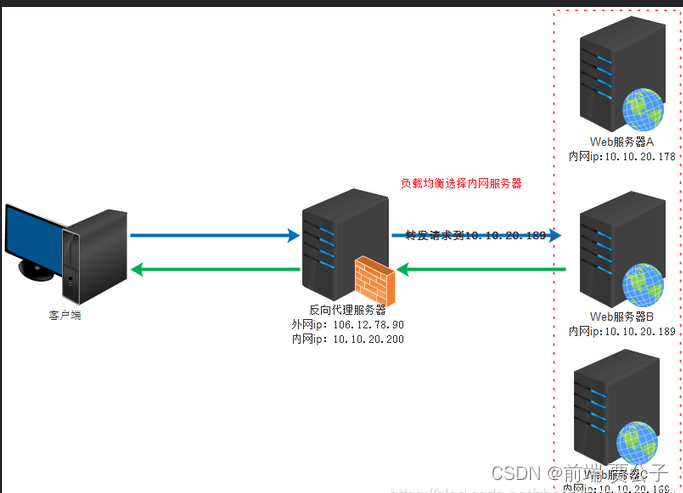
Nginx 代理
目录 正向代理 反向代理 负载均衡 负载均衡的工作原理 优势和好处 算法和策略 应用领域 Nginx 的反向代理 应用场景 在网络通信中,代理服务器扮演着重要的角色,其中正向代理和反向代理是两种常见的代理服务器模式。它们在网络安全、性能优化和…...
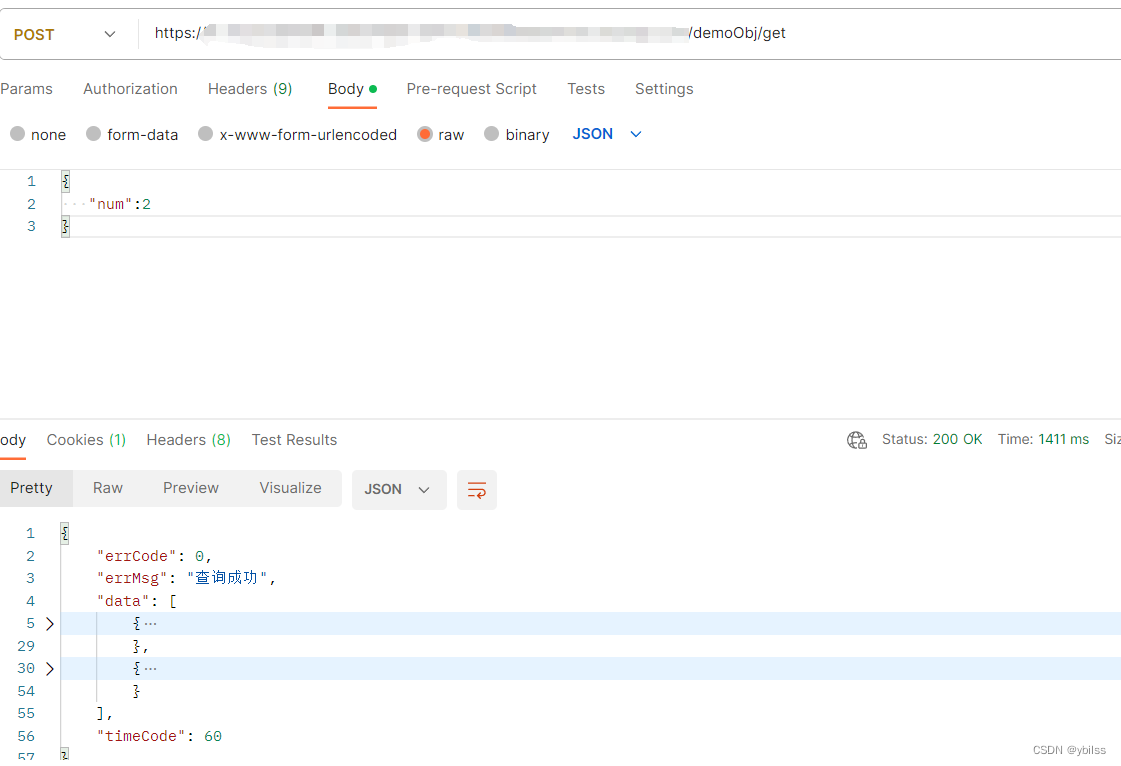
uniapp(uncloud) 使用生态开发接口详情4(wangeditor 富文本, 云对象, postman 网络请求)
wangeditor 官网: https://www.wangeditor.com/v4/pages/01-%E5%BC%80%E5%A7%8B%E4%BD%BF%E7%94%A8/01-%E5%9F%BA%E6%9C%AC%E4%BD%BF%E7%94%A8.html 这里用vue2版本,用wangeditor 4 终端命令: npm i wangeditor --save 开始使用 在项目pages > sy_news > add.vue 页面中…...
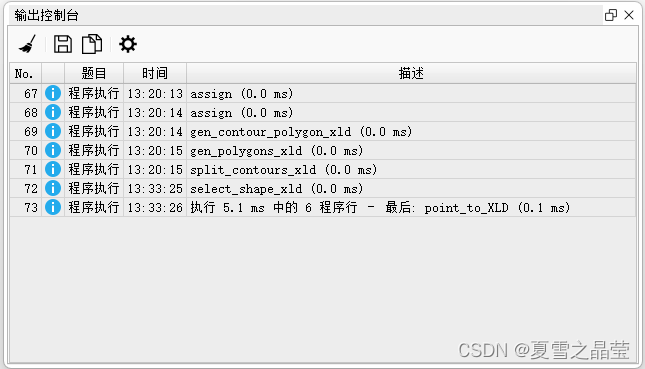
Halcon 中查看算子和函数的执行时间
1、在Halcol主窗口的底栏中的第一个图标显示算子或函数的执行时间,如下图: 2、在Halcon的菜单栏中选择【窗口】,在下拉框中选择【打开输出控制台】,进行查看算子或函数的执行时间,如下图:...
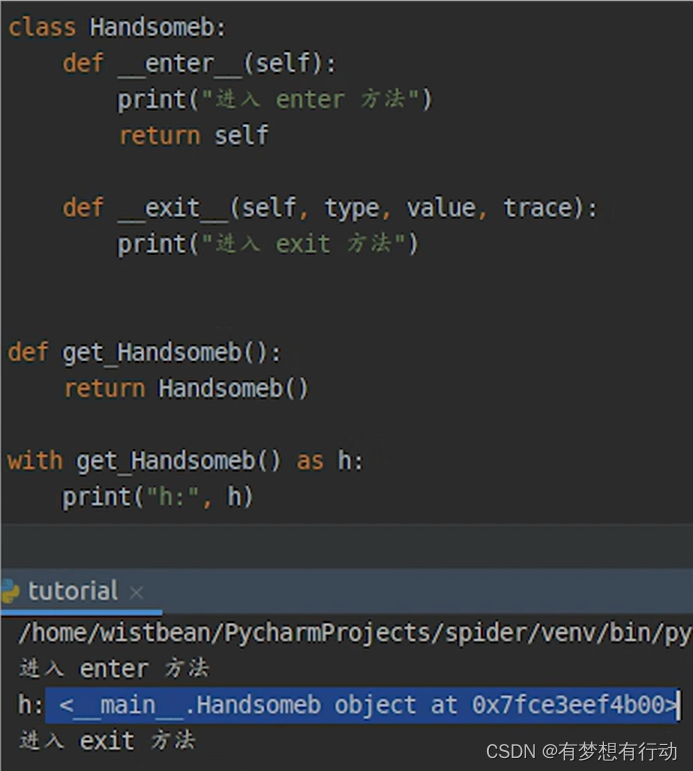
Python中的With ...as... 作用
Python中的with … as …作用: 1、通过with语句可以得到一个上下文管理器 2、执行对象 3、加载__enter__方法 4、加载__exit__方法 5、执行__enter__方法 6、as 可以得到enter的返回值 7、拿到对象执行相关操作 8、执行完了之后调用__exit__方法 9、如果遇到异常&a…...

腾讯云国际站服务器如何打开音频设备?
在使用腾讯云服务器进行音频处理或直播等活动时,或许需求翻开服务器的音频设备。本文将详细介绍如安在腾讯云服务器上翻开音频设备。 在腾讯云服务器上翻开音频设备的过程如下: 登录腾讯云服务器办理控制台 1.首先,需求登录腾讯云服务器的办理…...

k8s day05
上周内容回顾: - 基于kubeadm部署k8s集群 ***** - Pod的基础管理 ***** 是K8S集群中最小的部署单元。 ---> 网络基础容器(pause:v3.1),提供网络 ---> 初始化容器(initContainer),做初始化的准备工作…...
微信小程序里报名链接怎么做
微信小程序是一种便捷、实用的应用程序,它依托于微信平台,无需下载安装即可使用。在小程序中,我们可以制作报名链接,以便用户直接在微信中进行报名操作,提高服务效率。下面我们将探讨如何制作微信小程序里的报名链接为…...

Kotlin中的逻辑运算符
在Kotlin中,逻辑运算符用于对布尔值进行逻辑运算。Kotlin提供了三个逻辑运算符:与运算(&&)、或运算(||)和非运算(!)。下面对这些逻辑运算符进行详细介绍,并提供示…...

启智平台新建一个调试任务后,如何配环境,并提交镜像
1. 选一个基础版的镜像,我选的是第一个 2. 点击“调试”,进入调试页面 3. 输入bash,再输入pip list 就可以看到镜像自带的conda中已经安装的包 !注意,这里一进入到调试页面,不要输入su,一定要…...

当生物黑客入侵脑机接口:安全测试救了我们公司
在脑机接口(Brain-Computer Interface, BCI)技术飞速发展的今天,软件测试从业者正面临前所未有的安全挑战。作为一名资深测试工程师,我亲历了一场惊心动魄的生物黑客入侵事件——一场针对我们公司脑机接口产品的攻击险些导致灾难性…...

C语言实战:构建嵌入式eMMC RPMB安全读写组件
1. eMMC RPMB分区基础解析 我第一次接触RPMB分区是在开发智能门锁项目时,需要存储指纹特征码等敏感数据。传统存储方式容易被篡改,而RPMB完美解决了这个问题。RPMB(Replay Protected Memory Block)是eMMC芯片中的特殊安全存储区域…...

InSpec插件生态系统:扩展框架功能的完整教程
InSpec插件生态系统:扩展框架功能的完整教程 【免费下载链接】inspec InSpec: Auditing and Testing Framework 项目地址: https://gitcode.com/gh_mirrors/in/inspec InSpec作为一款强大的合规性测试框架,其真正的威力在于其可扩展的插件生态系统…...

百度网盘秒传链接终极指南:网页版工具全平台免费使用教程
百度网盘秒传链接终极指南:网页版工具全平台免费使用教程 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 还在为百度网盘文件分享的繁琐…...

掌握LSLib:解锁《神界原罪》与《博德之门3》MOD制作的神器
掌握LSLib:解锁《神界原罪》与《博德之门3》MOD制作的神器 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib LSLib是一个功能强大的开源工具集࿰…...

ALM代码编辑器实战教程:从HTML到TSX的转换技巧
ALM代码编辑器实战教程:从HTML到TSX的转换技巧 【免费下载链接】alm :rose: A :cloud: ready IDE just for TypeScript :heart: 项目地址: https://gitcode.com/gh_mirrors/al/alm ALM代码编辑器是一款专为TypeScript开发打造的云端IDE,提供了丰富…...

3大创新突破:CoreCycler单核心稳定性测试全攻略
3大创新突破:CoreCycler单核心稳定性测试全攻略 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.com/gh_mir…...

AI辅助前端设计:让快马平台生成酷炫的滚动视差与3D交互效果代码
AI辅助前端设计:让快马平台生成酷炫的滚动视差与3D交互效果代码 最近在做一个科技公司的产品介绍页,想实现一些炫酷的交互效果来提升用户体验。传统方式需要手动编写大量CSS和JavaScript代码,调试起来也很耗时。不过现在有了AI辅助开发工具&…...

ModelScope环境安装避坑指南:从NLP到语音,不同领域模型依赖到底怎么装?
ModelScope环境安装避坑指南:从NLP到语音,不同领域模型依赖到底怎么装? 当你第一次尝试在ModelScope上运行一个语音识别模型时,系统突然报错提示缺少libsndfile库;当你满怀期待地安装CV模型时,却因为mmcv版…...

显卡驱动彻底清理指南:用DDU解决90%的显示问题
显卡驱动彻底清理指南:用DDU解决90%的显示问题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstaller 当…...