rabbitMq (2)
RabbitMQ 消息应答与发布
文章目录
- 1. 消息应答
- 1.2 自动应答
- 1.2 手动应答
- 1.3 代码案例
- 2. RabbitMQ 持久化
- 2.1 队列持久化
- 2.2 消息持久化
- 3. 不公平分发
- 4. 预取值分发
- 5. 发布确认
- 5.1 发布确认逻辑
- 5.2 开启发布确认的方法
- 5.3 单个确认发布
- 5.4 批量确认发布
- 5.5 异步确认
- 5.5.1 处理异步未确认消息
前言
上文我们已经成功安装完成 rabbitmq 并且写一个helloworld 入门案例 ,下面我们来学习一下 rabbitMQ 的消息应答 与 发布
1. 消息应答
引用:
消费者完成一个任务可能需要一段时间,如果其中一个消费者处理一个长的任务并仅只完成了部分突然它挂掉了,会发生什么情况。RabbitMQ 一旦向消费者传递了一条消息,便立即将该消息标记为删除。在这种情况下,突然有个消费者挂掉了,我们将丢失正在处理的消息。以及后续发送给该消费者的消息,因为它无法接收到。
为了保证消息在发送过程中不丢失,引入消息应答机制 (又称 确认机制),消息应答就是:消费者在接收到消息并且处理该消息之后,告诉 rabbitmq 它已经处理了,rabbitmq 可以把该消息删除了。
这个就当前与在 网络中学习到的 应答机制. 主机A 发送一个数据包给 主机B , 主机A 就会等待 主机B 发送一个 ACK 回来 如果 主机A 收到了 主机B 的 ack 说明发送成功 ,如果没有收到就说明 发送失败 重新发送 .
关于 消息应答 rabbitmq 提供两种模式
- 自动应答
- 手动应答
这里先来看看 自动应答
1.2 自动应答
概念 : 在自动应答模式下,消费者从队列中获取消息后,RabbitMQ 会自动将消息标记为已传递(Delivered)状态,不需要消费者明确发送应答给 RabbitMQ。这种模式下,RabbitMQ 会立即将消息从队列中删除,并假设消息已经被成功处理。
需要注意: 自动应答需要良好的环境 , 不能存在极端的情况,简单来说 自动应答 不是很靠谱
这种模式需要在高吞吐量和数据传输安全性方面做权衡,因为这种模式如果消息在接收到之前,消费者那边出现连接或者 channel 关闭,那么消息就丢失了,当然另一方面这种模式消费者那边可以传递过载的消息,没有对传递的消息数量进行限制,当然这样有可能使得消费者这边由于接收太多还来不及处理的消息,导致这些消息的积压,最终使得内存耗尽,最终这些消费者线程被操作系统杀死,**所以这种模式仅适用在消费者可以高效并以 某种速率能够处理这些消息的情况下使用
自动应答简单看看,下面我们来学习一下手动应答
1.2 手动应答
手动应答概念 :
在默认情况下,消费者从队列中获取消息后,RabbitMQ 会立即将该消息标记为已传递(Delivered)状态。然而,在手动应答模式下,消费者需要明确告知 RabbitMQ 消息是否已被消费并处理完成。如果消费者成功处理了消息,则发送一个应答给 RabbitMQ,RabbitMQ 将该消息从队列中删除;如果消费者未发送应答或应答失败,则 RabbitMQ 认为消息未被成功处理,会将其重新发送给其他消费者。
手动消息应答使用的方法
Channel.basicAck : 手动应答消息的方法
basicAck(long deliveryTag, boolean multiple);1. deliveryTag: 表示消息的唯一标识符。每条消息都会被分配一个唯一的 deliveryTag。消费者在处理完一条消息后,需要将对应的 deliveryTag 传递给 basicAck 方法,以告知 RabbitMQ 哪条消息已经被成功处理。 --> 简单来说就是消息的标记2. multiple: 表示是否批量确认。如果设置为 true,则表示除了确认当前指定的 deliveryTag 对应的消息外,还要确认所有之前未确认的消息;如果设置为 false,则只确认当前指定的 deliveryTag 对应的消息。 --> 简单来说就是 rabbitmq 确定了当前的消息,可以将其丢弃了
Channel.basicReject : 拒绝 一条消息的方法
basicReject(long deliveryTag, boolean requeue);1. deliveryTag:表示消息的唯一标识符,与 basicAck 方法中的参数相同。每条消息都会被分配一个唯一的 deliveryTag。2. 表示是否重新将消息放回队列中进行重新投递。如果设置为 false,则消息会被直接丢弃;如果设置为 true,则消息会被重新放回队列,等待被消费者重新处理
Channel.basicNack: 用于一次性拒绝多个消息。
basicNack(long deliveryTag, boolean multiple, boolean requeue);这里 deliveryTag 和 requeue 和 Channel.basicReject 一样的, 这个方法只是多了一个 basicNack 方法用来 表示拒绝的多个参数multiple: 表示是否拒绝所有 deliveryTag 小于等于当前 deliveryTag 的消息。如果设置为 false,则只拒绝当前 deliveryTag 对应的消息;如果设置为 true,则会拒绝所有 deliveryTag 小于等于当前 deliveryTag 的消息。
Channel.basicRecover : 用于重新消费未被确认的方法
basicRecover(boolean requeue);requeue: 表示是否将未被确认的消息重新放回队列中等待投递。如果设置为 false,则未被确认的消息会被删除,否则它们将被重新排队并可供之后的消费者使用。
在上面这些方法中 又 multiple 参数 这里简单讲讲一下 multiple.
手动应答的好处是可以批量应答并且介绍网络阻塞,手动应答就是通过 multiple 参数来开启是否批量
multiple 取 true 表示 批量处理 channel (信道)中为应答的消息
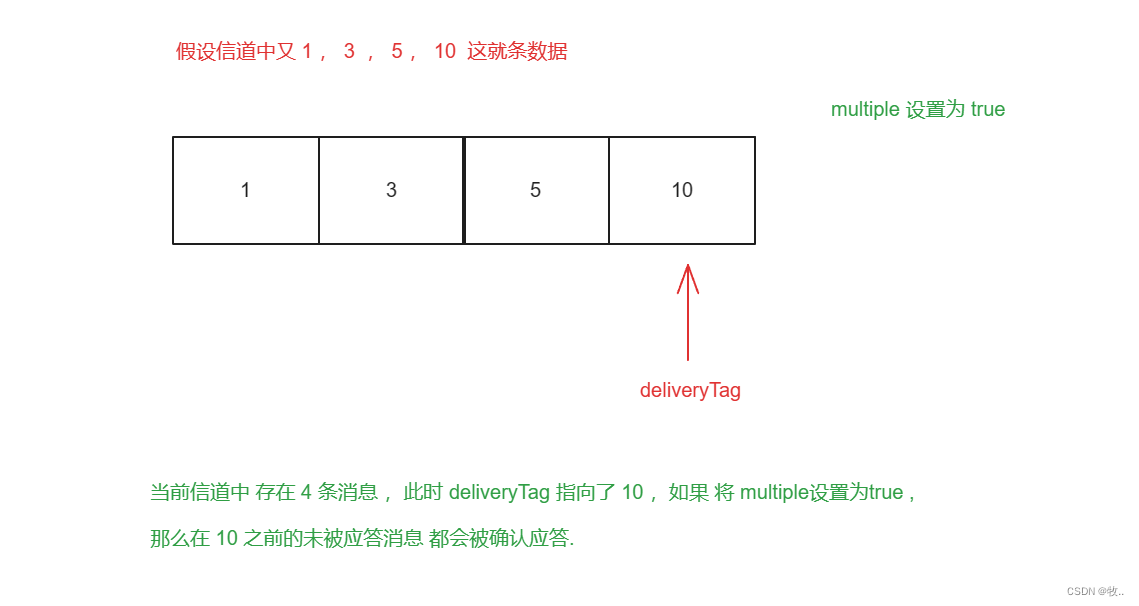
multiple 取 false 就不会开启批量处理的功能
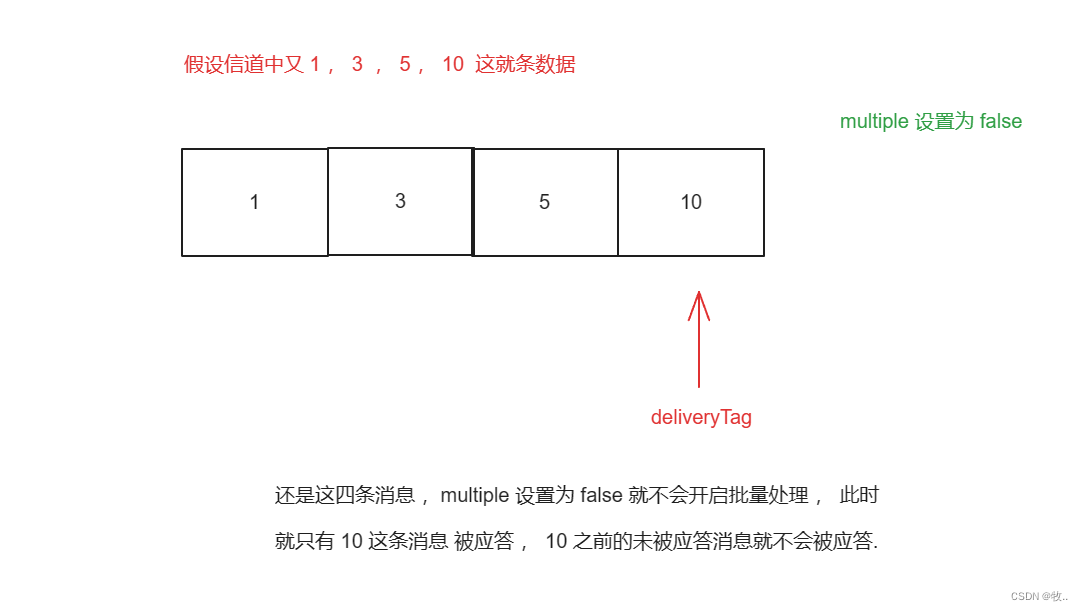
看完 multiple ,再来谈谈 重新消费,当有些消息被拒绝后会被重新放到队列中 ,等待被重新消费, 除了这种方法, 还有一种情况会导致消息重新入队 。
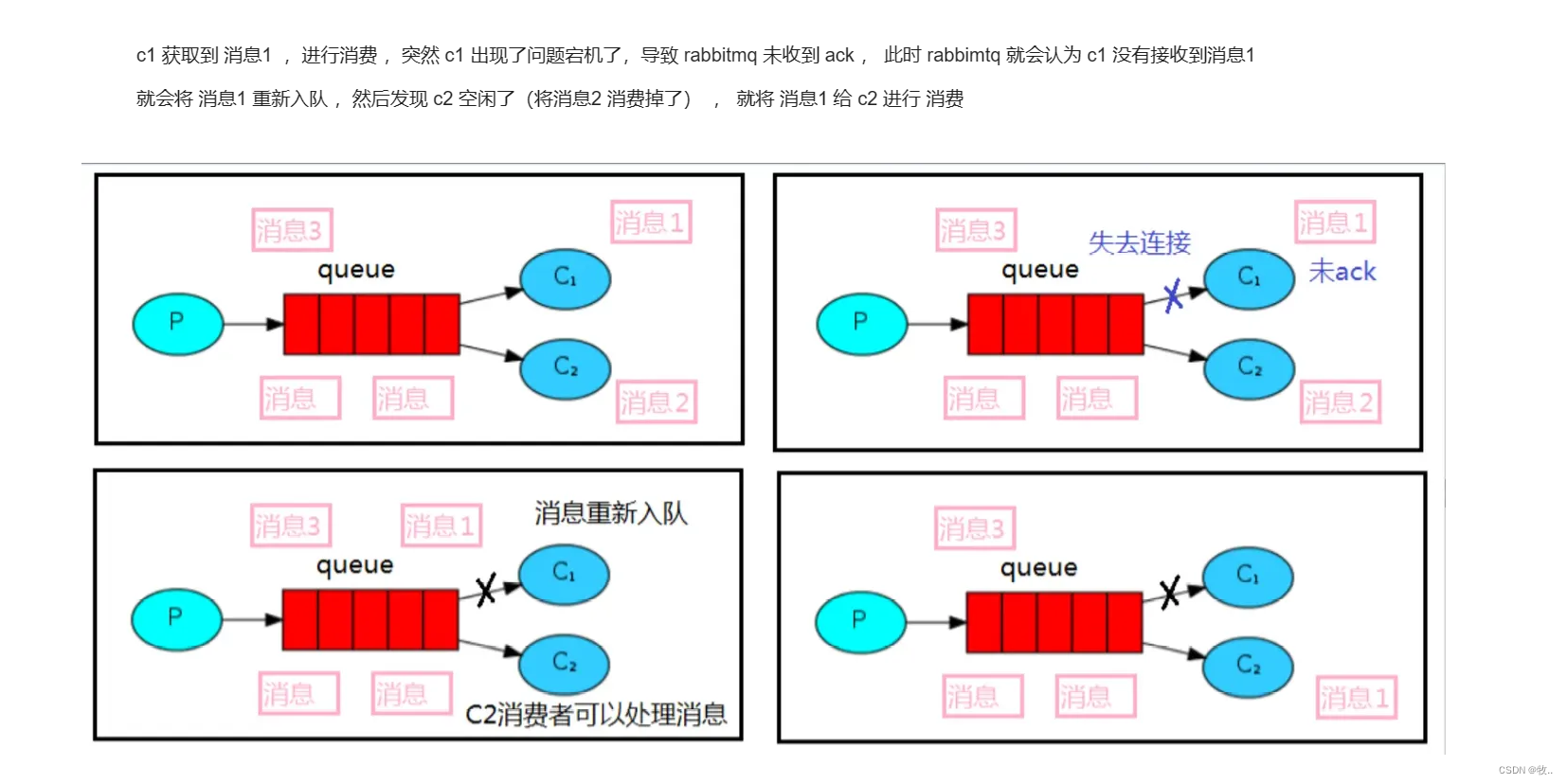
这种方式就是: 如果消费者由于某些原因失去连接(其通道已关闭,连接已关闭或 TCP 连接丢失),导致消息未发送 ACK 确认,RabbitMQ 将了解到消息未完全处理,并将对其重新排队。
如果此时其他消费者可以处理,它将很快将其重新分发给另一个消费者。这样,即使某个消费者偶尔死亡,也可以确保不会丢失任何消息。
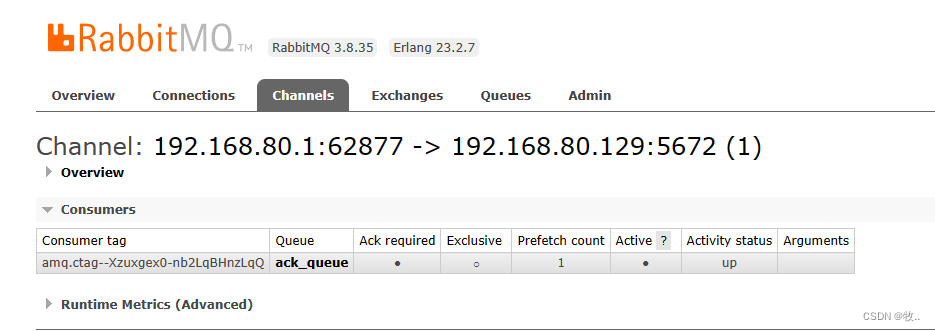
图: 消费者 c1 出现问题,未返回 ack ,消息重新回到队列 ,被其他消费者(c2)消费.
看完概念,就来写写代码 , 体验体验.
需要注意: rabbimt 默认采取的是 自定应答,要实现消息在消费过程中不被丢失,需要手动开启手动应答
1.3 代码案例
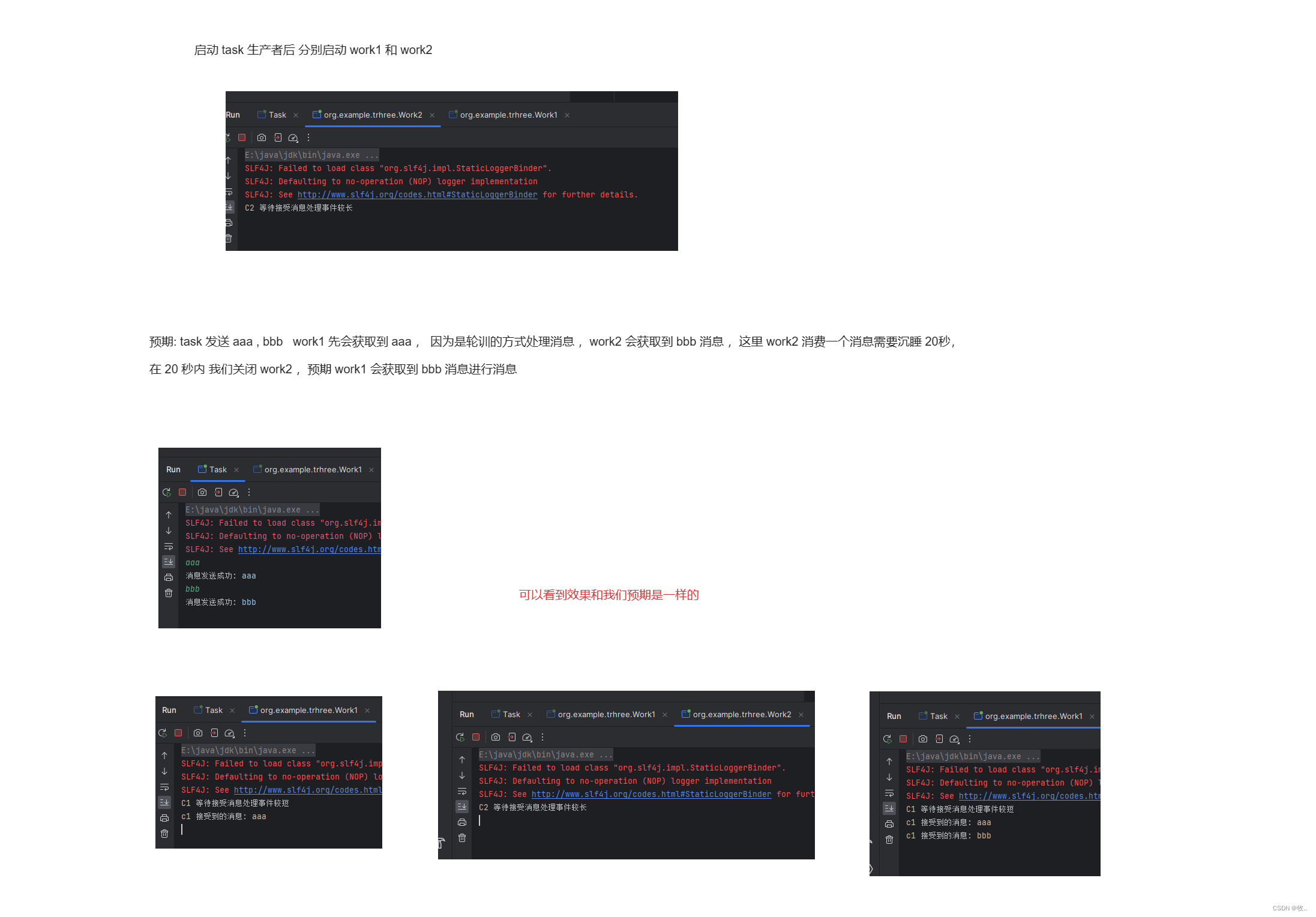
这里 创建一个消费者 ,消费者开启两个线程 , 消费者1 一秒消费 一个消息 , 消费者 20秒消费一个消息,然后在 消费者2 消费消息的时候,停止运行 (假设消费者2 宕机了) , 然后查看 消费者1 是否消费了 消费者2 没有消费的消息 (验证消息是否回到 队列,并重新安排消费者进行消费)
生产者:
package org.example.trhree;import com.rabbitmq.client.Channel;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.Scanner;
import java.util.concurrent.TimeoutException;/*** 消息再手动应答时不丢失,放回队列重新消费*/public class Task {// 队列名称public static final String TASK_QUEUE_NAME = "ack_queue";public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();// 声明一个队列channel.queueDeclare(TASK_QUEUE_NAME, false, false, false, null);// 从控制台中输入信息Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String message = sc.next();channel.basicPublish("", TASK_QUEUE_NAME, null, message.getBytes("UTF-8"));System.out.println("消息发送成功: " + message);}}
}
消费者1
package org.example.trhree;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.concurrent.TimeoutException;/*** 消费在手动应答时不丢失,放回到队列重新消费*/
public class Work1 {// 队列名称public static final String TASK_QUEUE_NAME = "ack_queue";//接收消息public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();System.out.println("C1 等待接受消息处理事件较短");DeliverCallback deliverCallback = (tag, message) -> {// 沉睡一秒try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("c1 接受到的消息: " + new String(message.getBody(), "UTF-8"));// 手动应答/*** basicAck 参数* 1. 消息的标记* 2. 是否批量应答 : true 批量 false 不批量*/channel.basicAck(message.getEnvelope().getDeliveryTag(), false);};// 采用手动应答boolean autoAck = false;channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, (tag -> {System.out.println("消费者取消消费: " + tag);}));}
}
消费者2 : 代码和消费者1 一毛一样 , 改改 log 里面打印即可
package org.example.trhree;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.concurrent.TimeoutException;/*** 消费在手动应答时不丢失,放回到队列重新消费*/
public class Work2 {// 队列名称public static final String TASK_QUEUE_NAME = "ack_queue";//接收消息public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();System.out.println("C2 等待接受消息处理事件较长");DeliverCallback deliverCallback = (tag, message) -> {// 沉睡20秒 &&& 注意消费者是要消费 20 秒的try {Thread.sleep(20000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("c1 接受到的消息: " + new String(message.getBody(), "UTF-8"));// 手动应答/*** basicAck 参数* 1. 消息的标记* 2. 是否批量应答 : true 批量 false 不批量*/channel.basicAck(message.getEnvelope().getDeliveryTag(), false);};// 采用手动应答boolean autoAck = false; channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, (tag -> {System.out.println("消费者取消消费: " + tag);}));}
}
效果:
2. RabbitMQ 持久化
默认情况下,RabbitMQ 创建的队列是非持久化的,这意味着在 RabbitMQ 服务器停止或重启时,队列将被删除。
我们想要在 RabbitMQ 服务暂停或重启以后 ,消息的生产者发送过来的消息不丢失,就需要来学习一下 如何开启 rabbitmq 持久化 .
2.1 队列持久化
在之前的例子中,我们所创建的队列都是非持久化的, RabbitMQ 重启或者故障 导致 宕机 ,队列都会被删除 这肯定是不行的, 这里我们想要队列持久化 就要 在声明队列的时候 将 durable 属性值设置为 true .
package org.example.trhree;import com.rabbitmq.client.Channel;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.Scanner;
import java.util.concurrent.TimeoutException;public class Task2 {// 队列名称public static final String TASK_QUEUE_NAME = "ack_queue";public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();// 开启持久化boolean durable = true;// 声明一个队列 --> 将第二个参数设置为 ture 就表示这个队列 是持久化的.channel.queueDeclare(TASK_QUEUE_NAME, durable, false, false, null);// 从控制台中输入信息Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String message = sc.next();channel.basicPublish("", TASK_QUEUE_NAME, null, message.getBytes("UTF-8"));System.out.println("消息发送成功: " + message);}}
}
声明完后 ack_queue 队列就是持久化的, 但是需要注意一点 ,如果 ack_queue 之前 声明的时候不是持久化的 (再次声明会报错),就需要先把 ack_queue 队列删除掉 或者重新建立一个 持久化的队列.
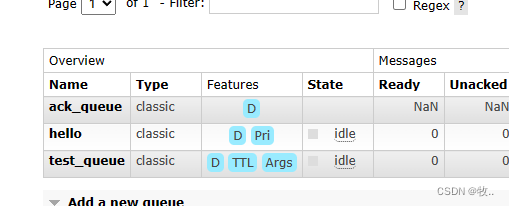
这里 通过上面的代码声明出来的 ack_queue 队列 在 Features 就会多出 一个 D ,表示 这是一个持久化的队列。
2.2 消息持久化
我们将队列设置为持久化 ,默认情况下 消息是仍然是非持久化的 (rabbitmq 服务器段宕机后 队列还在 ,但是队列里的消息没了) .
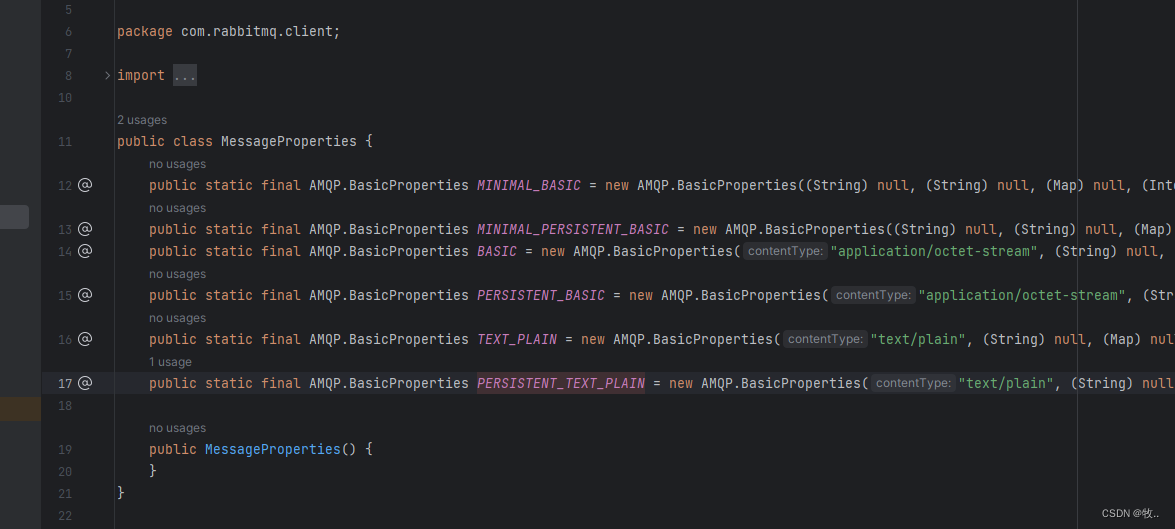
这里我们想要消息持久化 需要在 basicPublish 方法的第二个参数添加这个 属性: MessageProperties.PERSISTENT_TEXT_PLAIN
MessageProperties 类型
引用:
BASIC: 默认的消息属性,无特殊配置。MINIMAL_BASIC: 最小化的基本属性,不包含任何附加属性。PERSISTENT_BASIC: 基本持久化属性,将消息设置为持久化。PERSISTENT_TEXT_PLAIN: 文本类型的持久化属性,将消息设置为持久化,并指定内容类型为文本。PERSISTENT_BINARY: 二进制类型的持久化属性,将消息设置为持久化,并指定内容类型为二进制。NON_PERSISTENT_BASIC: 基本非持久化属性,将消息设置为非持久化。
package org.example.trhree;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.Scanner;
import java.util.concurrent.TimeoutException;public class Task2 {// 队列名称public static final String TASK_QUEUE_NAME = "ack_queue";public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();// 开启持久化boolean durable = true;// 声明一个队列channel.queueDeclare(TASK_QUEUE_NAME, durable, false, false, null);// 从控制台中输入信息Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String message = sc.next();// 通过 MessageProperties.PERSISTENT_TEXT_PLAIN 开启消息持久化channel.basicPublish("", TASK_QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));System.out.println("消息发送成功: " + message);}}
}
这里虽然 设置了 消息 持久化 ,但是消息并不能完全保证不丢失, 尽管它告诉 RabbitMQ 将消息保存到磁盘,但是这里依然存在当消息刚准备存储在磁盘的时候 但是还没有存储完,消息还在缓存的一个间隔点。此时并没 有真正写入磁盘。持久性保证并不强,但是对于我们的简单任务队列而言,这已经绰绰有余了。
3. 不公平分发
看完 rabbitmq 的 消息应答 和 持久化 ,下面我们来说说 不公平分发 ,在之前的文章说过 rabbitmq 采用 轮询的方式来分发消息 , 但是在某种场景下 轮询分发 并不是很好的选择, 比如 上面消息持久化举得例子 ,存在两个消费者 , 消费者1 消费消息 需要 1 秒钟 , 消费者2 消费消息 需要 10 分钟 ,采用轮询的方法 就会导致 消费者1 一直处于 空闲状态 ,而 消费者 2 一直处于工作状态 ,明显是不好的 (消费者1 处理完消息 一直等待 消费者2 处理完消息 ) , 按照 常理来说 ,我们应该给 有能力者 安排多一点的工作 ,能力比较差的 ,少安排一点工作 .
rabbitmq 就考虑到了这种情况 ,当 有一方 处理 能力比较 低 ,一方处理能力比较高 ,就会 给 较高的一方 安排多一点 任务 , 低的一方 安排少一点 .
我们想要 使用 不公平分发 这种 模式 需要 在 消费者消费消息之前 ,设置 参数 channel.basicQos(1) (轮询是 basicQos 设置为 0)
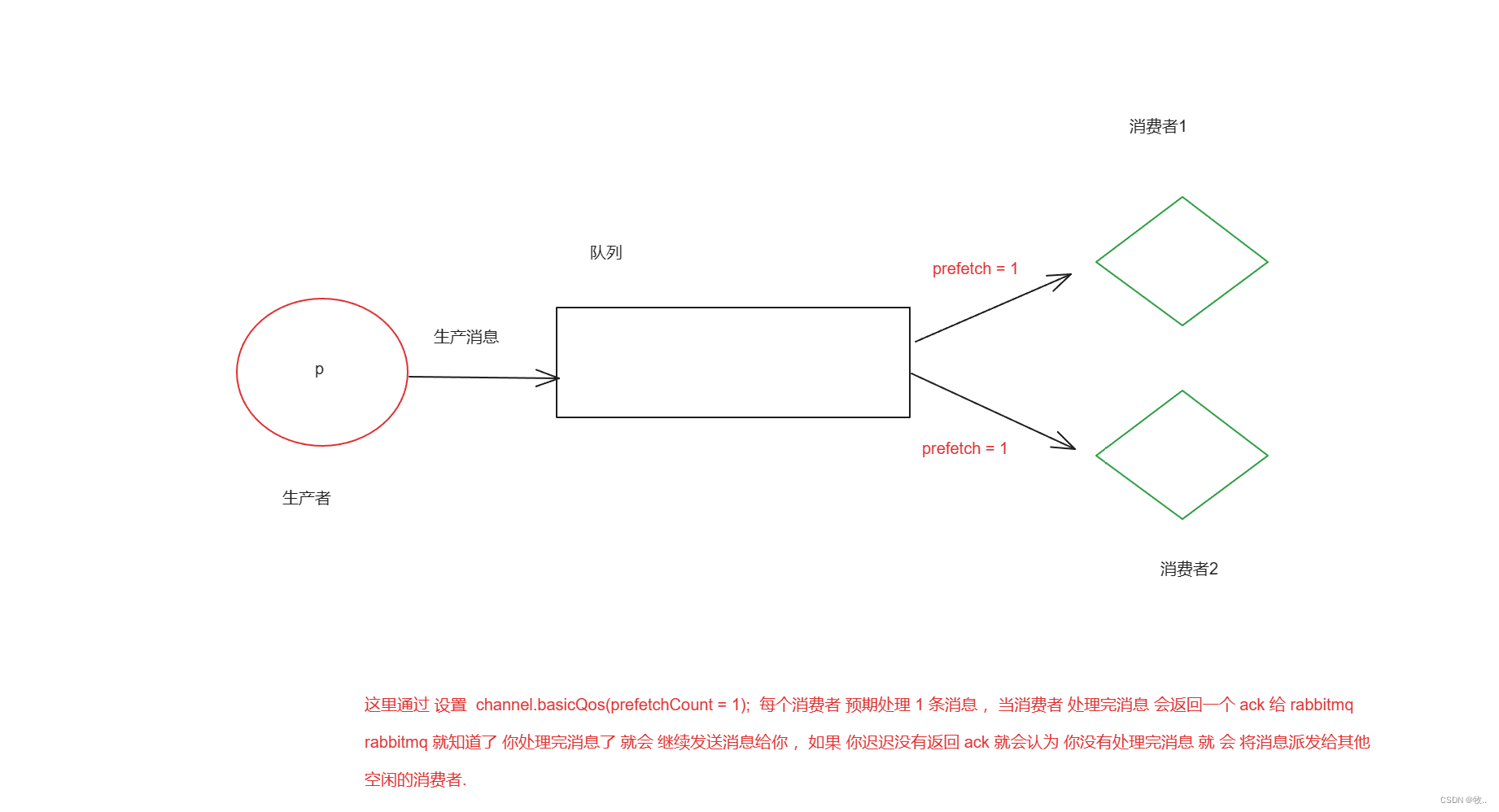
代码演示:
package org.example.trhree;import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.concurrent.TimeoutException;public class Work3 {// 队列名称public static final String TASK_QUEUE_NAME = "ack_queue";// 接受消息public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();DeliverCallback deliverCallback = (tag, message) -> {System.out.println("手动应答处理消息");// 手动应答channel.basicAck(message.getEnvelope().getDeliveryTag(), false);};CancelCallback cancelCallback = (tag -> {System.out.println(tag + "消费者取消消费接口回调逻辑");});// 设置不公平分发int prefetchCount = 1;channel.basicQos(prefetchCount);// 采用手动应答boolean autoAck = false;channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, cancelCallback);}
}
work4 : 拷贝 work3 , 在 处理消息的回调 deliver中 睡眠 10 ,
package org.example.trhree;import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.concurrent.TimeoutException;public class Work4 {// 队列名称public static final String TASK_QUEUE_NAME = "ack_queue";// 接受消息public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();DeliverCallback deliverCallback = (tag, message) -> {System.out.println("手动应答处理消息");try {Thread.sleep(10000);} catch (InterruptedException e) {throw new RuntimeException(e);}// 手动应答channel.basicAck(message.getEnvelope().getDeliveryTag(), false);};CancelCallback cancelCallback = (tag -> {System.out.println(tag + "消费者取消消费接口回调逻辑");});// 设置不公平分发int prefetchCount = 1;channel.basicQos(prefetchCount);// 采用手动应答boolean autoAck = false;channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, cancelCallback);}
}
启动一下看看效果:
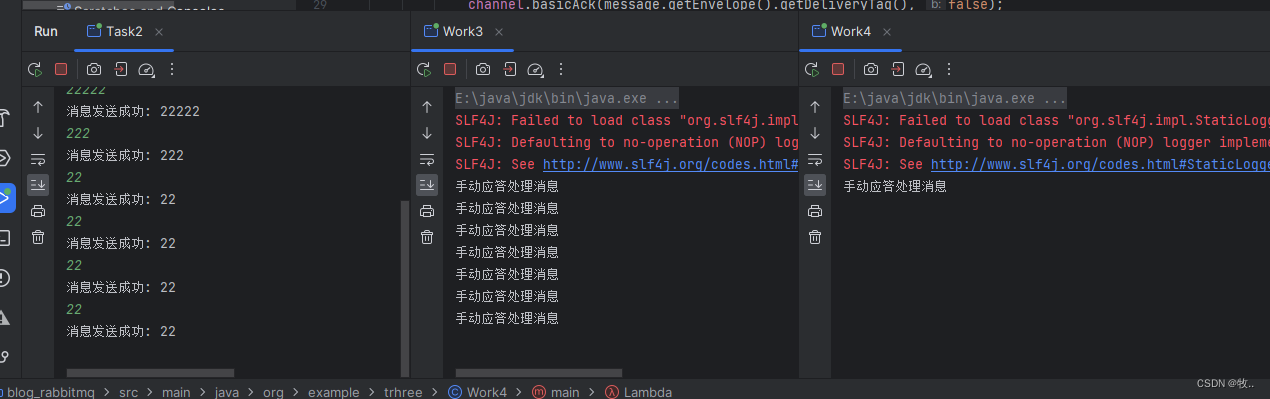
可以看到 , 此时 work3 就处理了多条消息 .
最后在说说 不公平分发思想:
不公平分发思想:如果一个工作队列还没有处理完或者没有应答签收一个消息,则不拒绝 RabbitMQ 分配新的消息到该工作队列。此时 RabbitMQ 会优先分配给其他已经处理完消息或者空闲的工作队列。如果所有的消费者都没有完成手上任务,队列还在不停的添加新任务,队列有可能就会遇到队列被撑满的情况,这个时候就只能添加新的 worker (工作队列)或者改变其他存储任务的策略。
看完不公平分发,我们来看看预取值分发 。
4. 预取值分发
引用:
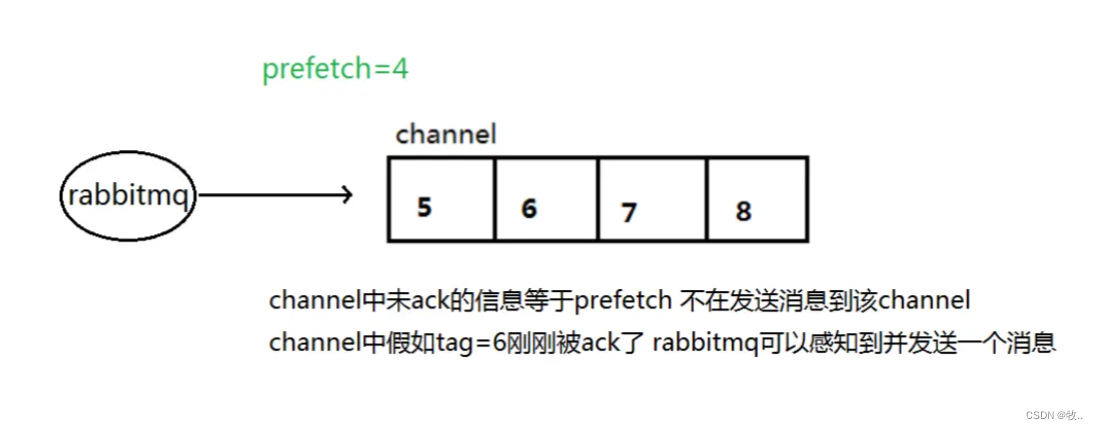
预取值分发是带权的消息分发 , 默认消息的发送是异步发送的,所以在任何时候,channel 上不止只有一个消息来自消费者的手动确认,所以本质上是异步的。因此这里就存在一个未确认的消息缓冲区,希望开发人员能限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题。这个时候就可以通过使用
basic.basicQos方法设置「预取计数」值来完成的。
该值定义通道上允许的未确认消息的最大数量。一旦数量达到配置的数量, RabbitMQ 将停止在通道上传递更多消息,除非至少有一个未处理的消息被确认,例如,假设在通道上有未确认的消息 5、6、7,8,并且通道的预取计数设置为 4,此时 RabbitMQ 将不会在该通道上再传递任何消息,除非至少有一个未应答的消息被 ack。比方说 tag=6 这个消息刚刚被确认 ACK,RabbitMQ 将会感知这个情况到并再发送一条消息。消息应答和 QoS 预取值对用户吞吐量有重大影响。
通常,增加预取将提高向消费者传递消息的速度。虽然自动应答传输消息速率是最佳的,但是,在这种情况下已传递但尚未处理的消息的数量也会增加,从而增加了消费者的 RAM 消耗(随机存取存储器)应该小心使用具有无限预处理的自动确认模式或手动确认模式,消费者消费了大量的消息如果没有确认的话,会导致消费者连接节点的内存消耗变大,所以找到合适的预取值是一个反复试验的过程,不同的负载该值取值也不同 100 到 300 范围内的值通常可提供最佳的吞吐量,并且不会给消费者带来太大的风险。
预取值为 1 是最保守的。当然这将使吞吐量变得很低,特别是消费者连接延迟很严重的情况下,特别是在消费者连接等待时间较长的环境 中。对于大多数应用来说,稍微高一点的值将是最佳的。
图解:
代码演示:
生产者:
package org.example.four;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.Scanner;
import java.util.concurrent.TimeoutException;public class Task {// 队列名称public static final String TASK_QUEUE_NAME = "test_queue_expect";public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();// 开启持久化boolean durable = true;// 声明一个队列channel.queueDeclare(TASK_QUEUE_NAME, durable, false, false, null);// 从控制台中输入信息Scanner sc = new Scanner(System.in);while (sc.hasNext()) {String message = sc.next();// 通过 MessageProperties.PERSISTENT_TEXT_PLAIN 开启消息持久化channel.basicPublish("", TASK_QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));System.out.println("消息发送成功: " + message);}}
}
消费者 c1
package org.example.four;import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.concurrent.TimeoutException;// 消费者 c1
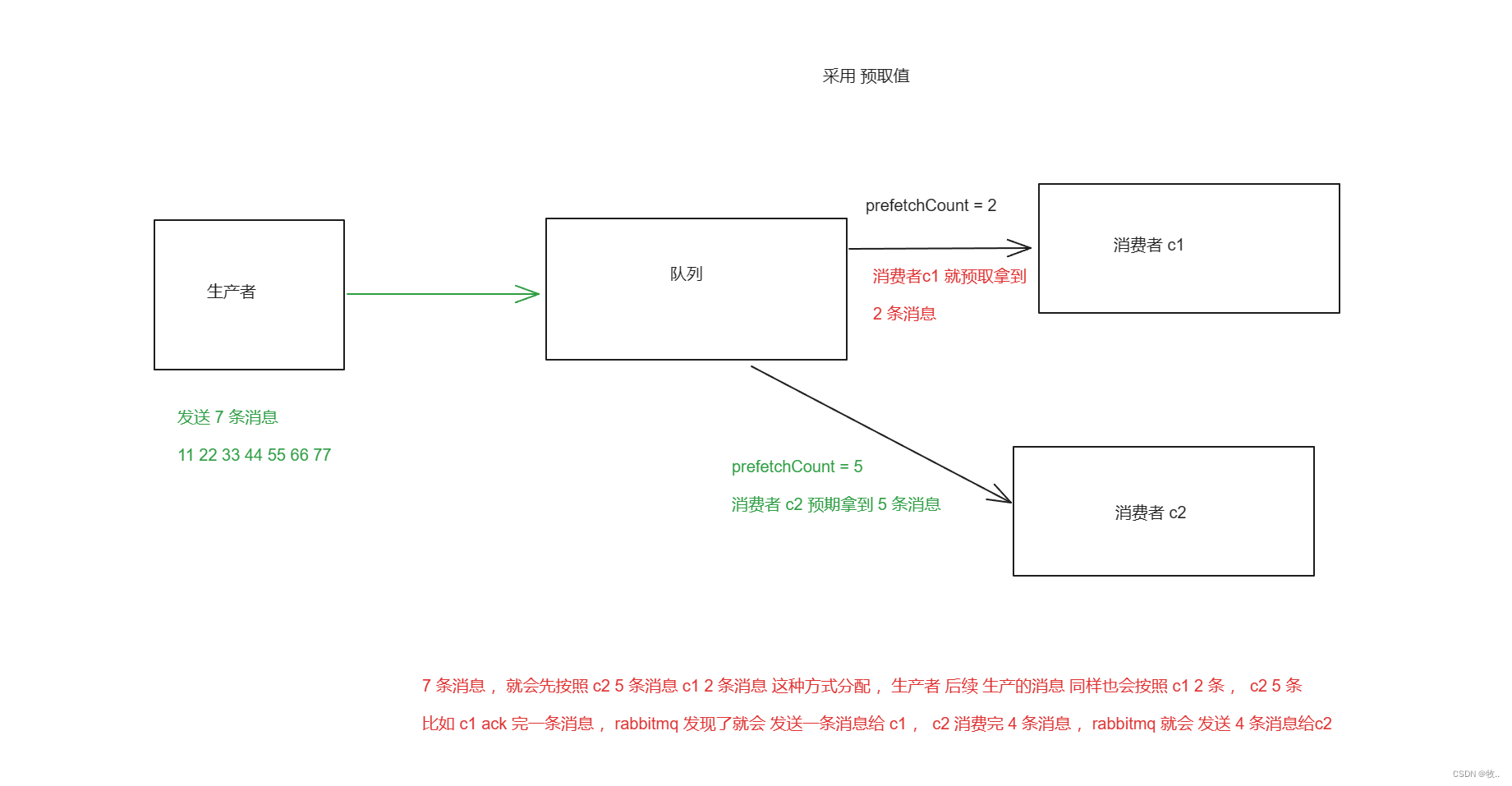
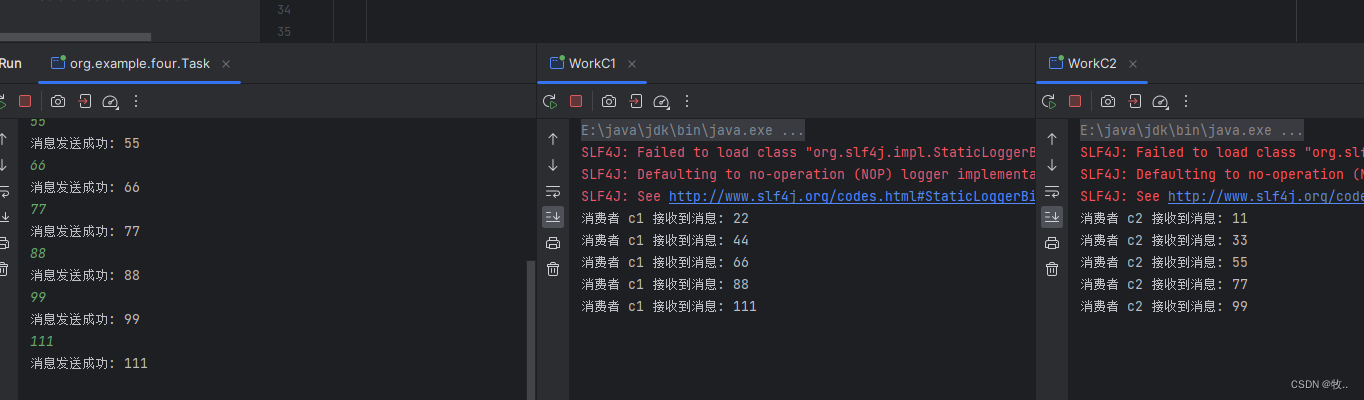
public class WorkC1 {// 队列名称public static final String TASK_QUEUE_NAME = "test_queue_expect";public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();DeliverCallback deliverCallback = (tag, message) -> {System.out.println("消费者 c1 接收到消息: " + new String(message.getBody()));try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}channel.basicAck(message.getEnvelope().getDeliveryTag(), false);};CancelCallback cancelCallback = (tag -> {System.out.println(tag + "消费者取消消费接口回调逻辑");});// 设置 c1 的预期取值为 2int prefetchCount = 2;channel.basicQos(prefetchCount);// 采用 手动应答boolean autoAck = false;channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, cancelCallback);}
}
消费者 c2 :
package org.example.four;import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.concurrent.TimeoutException;// 消费者 c1
public class WorkC2 {// 队列名称public static final String TASK_QUEUE_NAME = "test_queue_expect";public static void main(String[] args) throws IOException, TimeoutException {Channel channel = RabbitMQUtils.getChannel();DeliverCallback deliverCallback = (tag, message) -> {System.out.println("消费者 c2 接收到消息: " + new String(message.getBody()));try {Thread.sleep(10000);} catch (InterruptedException e) {throw new RuntimeException(e);}channel.basicAck(message.getEnvelope().getDeliveryTag(), false);};CancelCallback cancelCallback = (tag -> {System.out.println(tag + "消费者取消消费接口回调逻辑");});// 设置 c2 的预期取值为 5int prefetchCount = 5;channel.basicQos(prefetchCount);// 采用 手动应答boolean autoAck = false;channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, cancelCallback);}
}
效果:
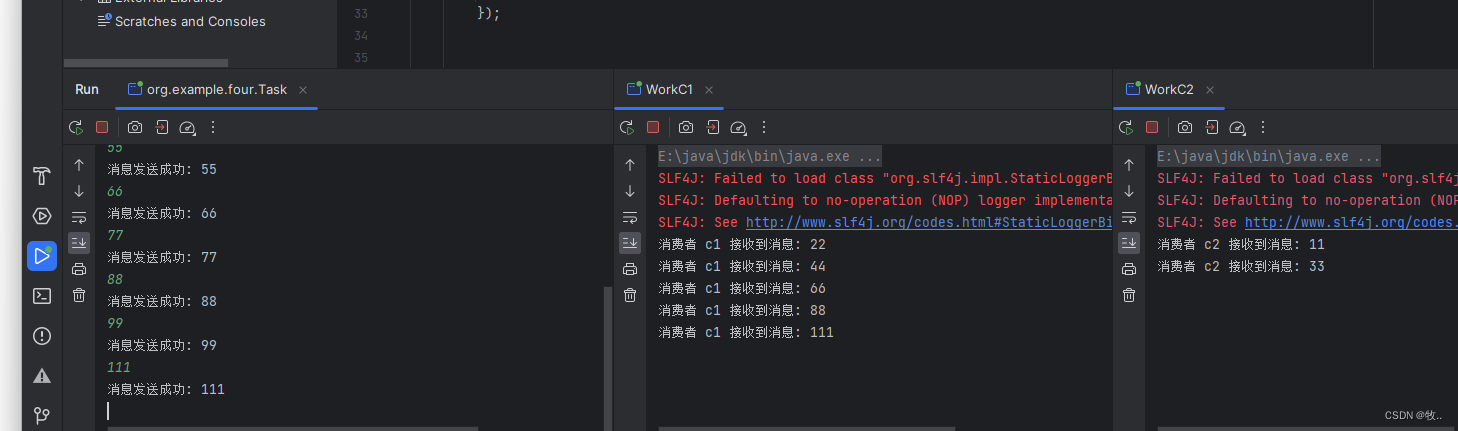
总共发送了 10 条消息 , c2 处理一条消息需要10秒钟 ,c1处理一条消息 需要 1 秒钟, 可以看到上面的图中 ,c1 消费了 5 条消息 , 应为 c2 预期接受到的消息是 5 条 ,所以 ,c2 消费完 预取值的 2 条消息 ,rabbitmq 就会 再发 2 条消息,又因为 c2 处能力 比较弱 ,还没有处理完 预取值的消息 , rabbitmq 就将 最后一条消息 交给了 c1 处理.
最终:
到此 预取值分发 看完, 我们应该能发现 , 使用 不公平分发或预取值分发, 都是 使用 basicQos 方法 .
当 basicQos 方法 取值为 1 的时候是 不公平分发 , basicQos 取其他整数值时为 预取值分发 (取 0 为 轮询分发).
两种分发方式看完,下面我们来学习 发布确认 (发布确认是保证消息不丢失的重要环节) .
5. 发布确认
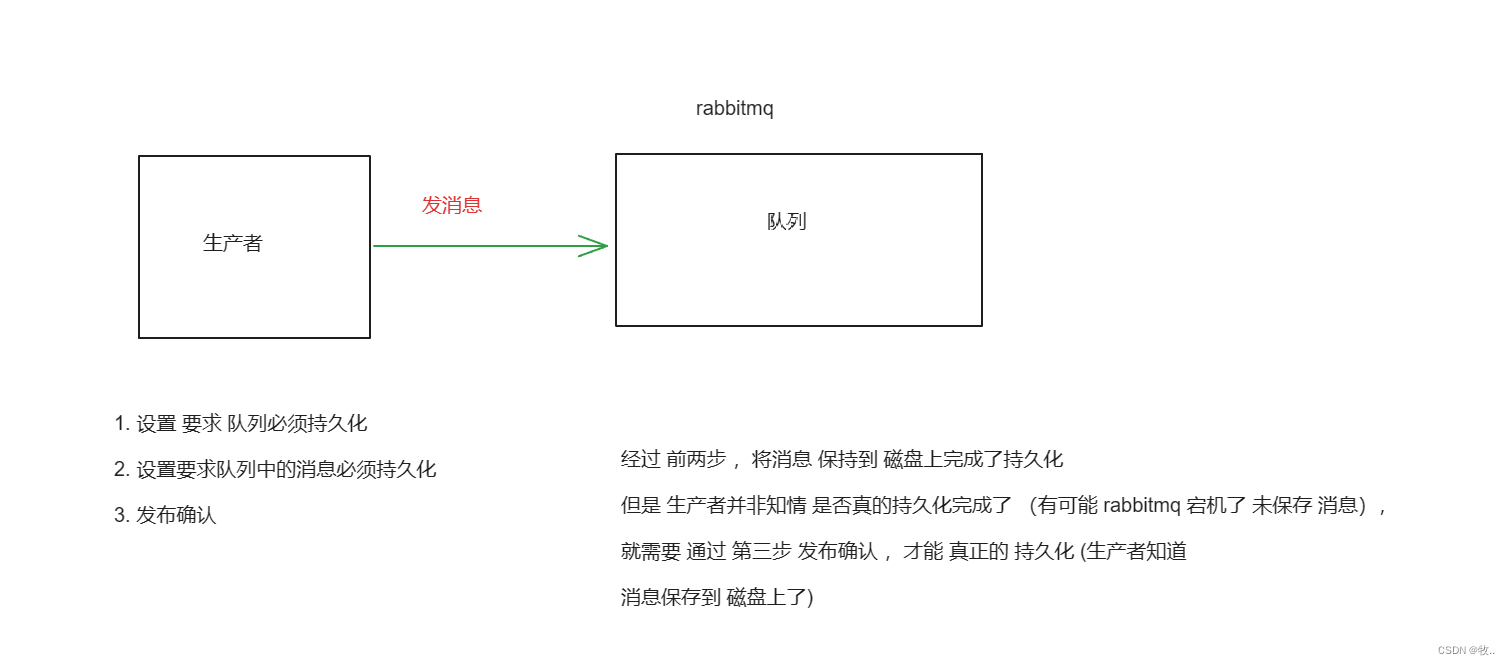
生产者发布消息到 RabbitMQ 后,需要 RabbitMQ 返回「ACK(已收到)」给生产者,这样生产者才知道自己生产的消息成功发布出去。
5.1 发布确认逻辑
引用:
生产者将信道设置成 confirm 模式,一旦信道进入 confirm 模式,所有在该信道上面发布的消息都将会被指派一个唯一的 ID(从 1 开始),一旦消息被投递到所有匹配的队列之后,broker 就会发送一个确认给生产者(包含消息的唯一 ID),这就使得生产者知道消息已经正确到达目的队列了,如果消息和队列是可持久化的,那么确认消息会在将消息写入磁盘之后发出,broker 回传给生产者的确认消息中 delivery-tag 域包含了确认消息的序列号,此外 broker 也可以设置 basic.ack 的 multiple 域,表示到这个序列号之前的所有消息都已经得到了处理。
confirm 模式最大的好处在于是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,如果RabbitMQ 因为自身内部错误导致消息丢失,就会发送一条 nack 消息, 生产者应用程序同样可以在回调方法中处理该 nack 消息。
5.2 开启发布确认的方法
发布确认默认是没有开启的,如果要开启需要调用方法 confirmSelect,每当你要想使用发布确认,都需要在 channel 上调用该方法
//开启发布确认
channel.confirmSelect();// 确认消息 (持久化完成)
channel.waitForConfirms();
在确认发布中 有三种 方法 :
- 单独确认
- 批量确认
- 异步确认
接下来我们一个一个学习 . 另外我会在 代码案例中 通过计算确认时间 来展示三种确认的发布速度.
5.3 单个确认发布
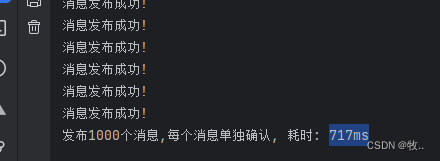
这是一种简单的确认方式,它是一种同步确认发布的方式,也就是发布一个消息之后只有它被确认发布,后续的消息才能继续发布,waitForConfirmsOrDie(long) 这个方法只有在消息被确认的时候才返回,如果在指定时间范围内这个消息没有被确认那么它将抛出异常。
这种确认方式有一个最大的缺点就是:发布速度特别的慢,因为如果没有确认发布的消息就会阻塞所有后续消息的发布,这种方式最多提供每秒不超过数百条发布消息的吞吐量。当然对于某些应用程序来说这可能已经足够了。
代码案例:
package org.example.four.tow;import com.rabbitmq.client.Channel;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.UUID;
import java.util.concurrent.TimeoutException;public class ConfirmMessage {// 单个发消息的个数public static final int MESSAGE_COUNT = 1000;public static void main(String[] args) throws IOException, TimeoutException, InterruptedException {publishMessageIndividually();// 发布 1000 个消息 并确认 耗时:}// 单个确认public static void publishMessageIndividually() throws IOException, TimeoutException, InterruptedException {Channel channel = RabbitMQUtils.getChannel();// 队列的声明String queueName = UUID.randomUUID().toString();channel.queueDeclare(queueName, false, true, false, null);// 开去发布确认channel.confirmSelect();// 开始时间long begin = System.currentTimeMillis();for (int i = 0; i < MESSAGE_COUNT; i++) {String message = i + "";channel.basicPublish("", queueName, null, message.getBytes());// 单个消息 --> 通过 waitForConfirms 确认这个消息boolean flag = channel.waitForConfirms();if (flag) {System.out.println("消息发布成功!");}}// 结束时间long end = System.currentTimeMillis();System.out.println("发布" + MESSAGE_COUNT + "个消息,每个消息单独确认, 耗时: " + (end - begin) + "ms");}
}
效果:
单个 看完 下面我们来看 批量确认发布
5.4 批量确认发布
引用:
单个确认发布方式非常慢,与单个等待确认消息相比,先发布一批消息然后一起确认可以极大地提高吞吐量,当然这种方式的缺点就是:当发生故障导致发布出现问题时,不知道是哪个消息出问题了,我们必须将整个批处理保存在内存中,以记录重要的信息而后重新发布消息。当然这种方案仍然是同步的,也一样阻塞消息的发布。
代码案例:
package org.example.four.tow;import com.rabbitmq.client.Channel;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.UUID;
import java.util.concurrent.TimeoutException;public class ConfirmMessage2 {// 发送消息的个数public static final int MESSAGE_COUNT = 1000;public static void main(String[] args) throws IOException, TimeoutException, InterruptedException {publishMessageIndividually();// 发布 1000 个消息 并确认 耗时:}// 批量发布确认public static void publishMessageIndividually() throws IOException, TimeoutException, InterruptedException {Channel channel = RabbitMQUtils.getChannel();// 队列的声明String queueName = UUID.randomUUID().toString();channel.queueDeclare(queueName, false, true, false, null);// 开去发布确认channel.confirmSelect();// 开始时间long begin = System.currentTimeMillis();// 批量确认消息大小int batchSize = 100;for (int i = 0; i < MESSAGE_COUNT; i++) {String message = i + "";channel.basicPublish("", queueName, null, message.getBytes());// 单个消息 --> 通过 waitForConfirms 确认这个消息if ((i + 1) % batchSize == 0) {// 此时 发送消息 到了 100 , 使用 waitForConfirms 确认消息channel.waitForConfirms();}}// 结束时间long end = System.currentTimeMillis();System.out.println("发布" + MESSAGE_COUNT + "个消息,每次批量确认100个消息, 耗时: " + (end - begin) + "ms");}
}
效果:
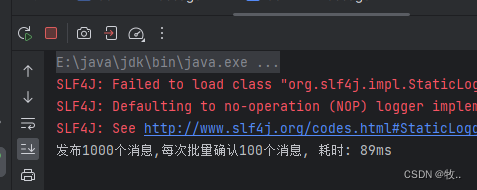
对比一下 单个确认发布 耗费的时间 ,批量确认 , 明显快很多 (上面 单个确认 ,有一个 打印 所以时间会比 批量确认耗费时间很多)
最后我们来看一下 异步确认
5.5 异步确认
异步确认 会比 批量确认 和 单个确认 在编程逻辑上 复杂很多 ,但也带来了性能上的优势 , 异步确认 效率和可靠性都非常好,是 通过 回调函数来达到消息可靠传递的.
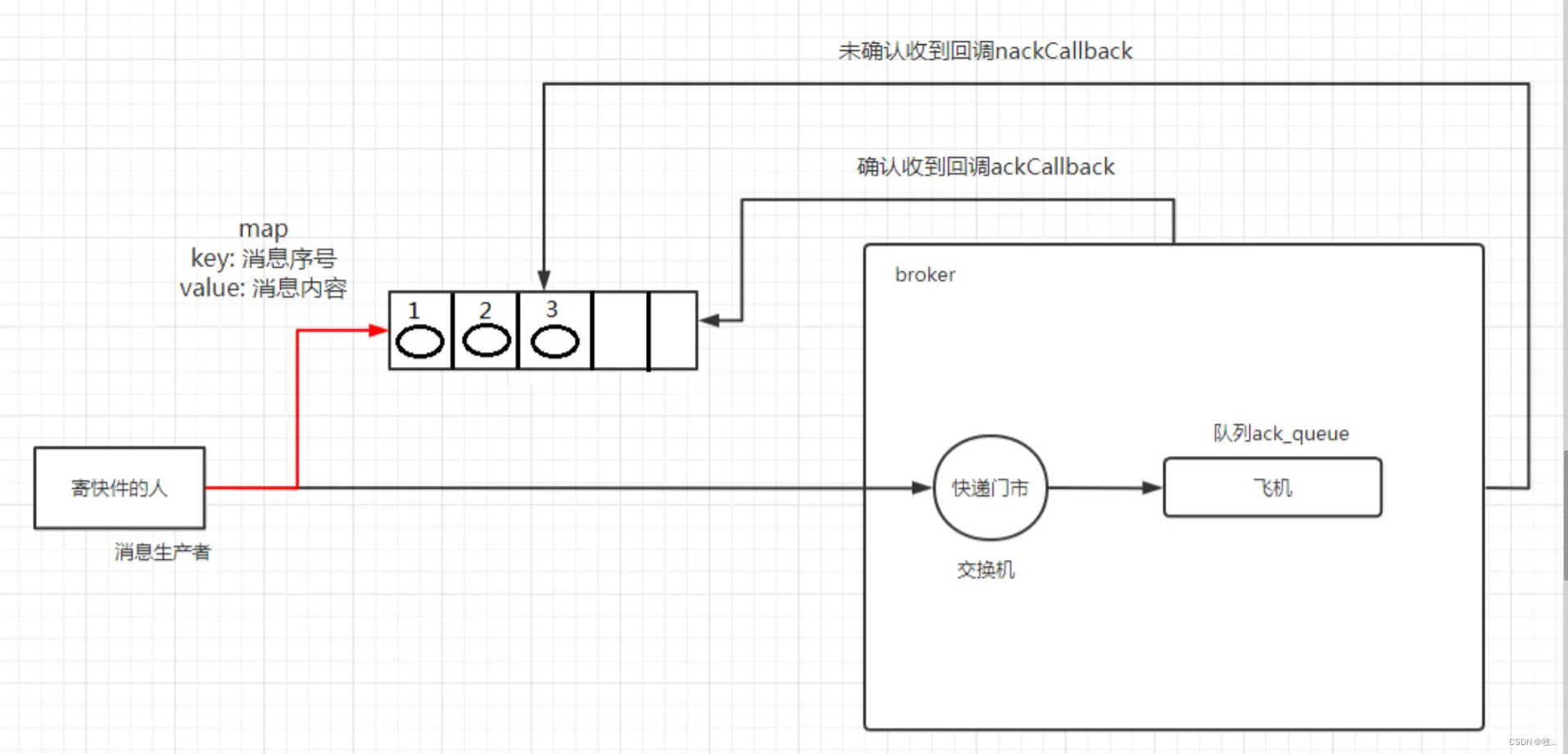
上面这张图 大致 流程是 , 消息生产者 发送消息 发送给 broker ,broker 会通过 ackCallback 回调函数 告诉 生产者 那些 消息是成功应答了的 ,失败的消息 会通过 nackCallback 告诉生产者 ,
代码案例:
package org.example.four.tow;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.ConfirmCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.UUID;
import java.util.concurrent.TimeoutException;public class ConfirmMessage3 {// 发送消息的个数public static final int MESSAGE_COUNT = 1000;public static void main(String[] args) throws IOException, TimeoutException, InterruptedException {publishMessageIndividually();// 发布 1000 个消息 并确认 耗时:}// 批量发布确认public static void publishMessageIndividually() throws IOException, TimeoutException, InterruptedException {Channel channel = RabbitMQUtils.getChannel();// 队列的声明String queueName = UUID.randomUUID().toString();channel.queueDeclare(queueName, false, true, false, null);// 开去发布确认channel.confirmSelect();// 开始时间long begin = System.currentTimeMillis();/*** 1. 消息的标记* 2. 是否批量确认*/// 消息确认 回调的函数ConfirmCallback ackCallback = (deliveryTag, multiple) -> {System.out.println("确认的消息: " + deliveryTag);};ConfirmCallback nackCallback = (deliveryTag, multiple) -> {System.out.println("未确认的消息: " + deliveryTag);};// 消息的监听器 ,监听那些消息成功了 ,那些消息失败了channel.addConfirmListener(ackCallback, nackCallback); // 异步通知/*** 参数解释* 1. 监听那些消息成功了* 2. 监听那些消息失败了*/// 发送消息for (int i = 0; i < MESSAGE_COUNT; i++) {String message = i + "";channel.basicPublish("", queueName, null, message.getBytes());}// 结束时间long end = System.currentTimeMillis();System.out.println("发布" + MESSAGE_COUNT + "个消息,通过异步确认,进行确认耗时: " + (end - begin) + "ms");}
}
效果: 这里 最后 发布 xxxx 消息 在 确认消息 之前 是因为 监听 消息成功 和 失败的 回调函数 是 异步的.
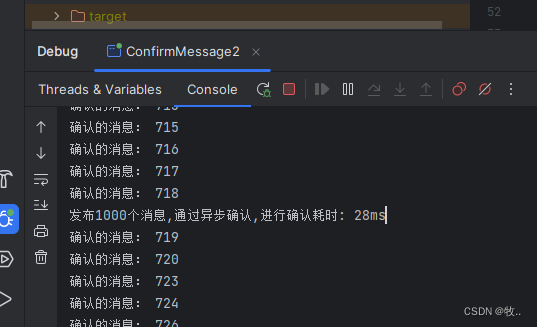
可以看到 时间是 28ms , 注意这里是带 打印语句了 是会 耗费一点时间的 , 很明显这是 比 批量确认 和 单个确认消息 效率高的.
看完了代码案例, 再来讲一个很重要的 ,就是 如何处理异步未确认消息 , 上面的 案例 打印出来的 全是 已确认的 ,在以后面对的场景中肯定会出现 ,消息未确认的情况 ,那么 我们要如何 消费者知道 未确认的消息并 重新发送呢?
要解决这个问题 下面我们就来学习一下 处理异步未确认消息
5.5.1 处理异步未确认消息
关于异步处理未确认的消息: 最好的解决的解决方案就是把未确认的消息放到一个基于内存的能被发布线程访问的队列,比如说用 ConcurrentLinkedQueue 这个队列在 confirm , callbacks 与发布线程之间进行消息的传递。
代码案例:
package org.example.four.tow;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.ConfirmCallback;
import org.example.utils.RabbitMQUtils;import java.io.IOException;
import java.util.UUID;
import java.util.concurrent.ConcurrentNavigableMap;
import java.util.concurrent.ConcurrentSkipListMap;
import java.util.concurrent.TimeoutException;public class ConfirmMessage4 {// 发送消息的个数public static final int MESSAGE_COUNT = 1000;public static void main(String[] args) throws IOException, TimeoutException, InterruptedException {publishMessageIndividually();// 发布 1000 个消息 并确认 耗时:}// 批量发布确认public static void publishMessageIndividually() throws IOException, TimeoutException, InterruptedException {// 准备一个 线程安全有序的一个哈希表 适用于高并发的情况下// 1. 轻松的将序号与消息进行关联// 2. 轻松批量删除条目 只要给到序号// 3. 支持高并发 (多线程)ConcurrentSkipListMap<Long, String> outStandingConfirms = new ConcurrentSkipListMap<>();Channel channel = RabbitMQUtils.getChannel();// 队列的声明String queueName = UUID.randomUUID().toString();channel.queueDeclare(queueName, false, true, false, null);// 开去发布确认channel.confirmSelect();// 开始时间long begin = System.currentTimeMillis();/*** 1. 消息的标记* 2. 是否批量确认*/// 消息确认 回调的函数ConfirmCallback ackCallback = (deliveryTag, multiple) -> {if (multiple) {// 删除所有已经确认的消息 ,剩下的就是未确认的消ConcurrentNavigableMap<Long, String> confirmed = outStandingConfirms.headMap(deliveryTag);/*** headMap 方法用于将已确认的消息存入新的 Map 缓存区里 (标记小于 deliveryTag的信息),* 然后手动清除该新缓存区的内容。因为 headMap 方法是浅拷贝,所以清除了缓存区,相当于清除了内容的地址,* 也就清除了队列的确认的消息。*/} else {// 不是 批量确认 , 通过 remove 删除确认的消息outStandingConfirms.remove(deliveryTag);}System.out.println("确认的消息: " + deliveryTag);};ConfirmCallback nackCallback = (deliveryTag, multiple) -> {// 处理未确认的消息String message = outStandingConfirms.get(deliveryTag);System.out.println("未确认的消息: " +message+" 编号为: "+ deliveryTag);};// 消息的监听器 ,监听那些消息成功了 ,那些消息失败了channel.addConfirmListener(ackCallback, nackCallback); // 异步通知/*** 参数解释* 1. 监听那些消息成功了* 2. 监听那些消息失败了*/// 发送消息for (int i = 0; i < MESSAGE_COUNT; i++) {String message = i + "";channel.basicPublish("", queueName, null, message.getBytes());// 记录所有要发送的消息outStandingConfirms.put(channel.getNextPublishSeqNo(), message);}// 结束时间long end = System.currentTimeMillis();System.out.println("发布" + MESSAGE_COUNT + "个消息,通过异步确认,进行确认耗时: " + (end - begin) + "ms");}
}
效果:
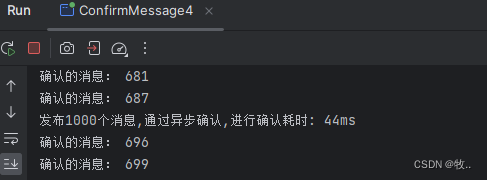
最后对 三种发布确认消息速度对比:
-
单独发布消息
同步等待确认,简单,但吞吐量非常有限。
-
批量发布消息
批量同步等待确认,简单,合理的吞吐量,一旦出现问题但很难推断出是那条消息出现了问题。
-
异步处理
最佳性能和资源使用,在出现错误的情况下可以很好地控制,但是实现起来稍微难些
最最后面,在来说一下应答和发布的区别 , 应答功能属于消费者,当消费者消费完消息后告诉 rabbitmq 消费成功 ,发布属于生产者,生产者生产的消息到达 rabbitmq 后 ,rabbitmq 告诉生产者接收到消息.
相关文章:
rabbitMq (2)
RabbitMQ 消息应答与发布 文章目录 1. 消息应答1.2 自动应答1.2 手动应答1.3 代码案例 2. RabbitMQ 持久化2.1 队列持久化2.2 消息持久化 3. 不公平分发4. 预取值分发5. 发布确认5.1 发布确认逻辑5.2 开启发布确认的方法5.3 单个确认发布5.4 批量确认发布5.5 异步确认5.5.1 处理…...
通讯协议学习之路:RS422协议理论
通讯协议之路主要分为两部分,第一部分从理论上面讲解各类协议的通讯原理以及通讯格式,第二部分从具体运用上讲解各类通讯协议的具体应用方法。 后续文章会同时发表在个人博客(jason1016.club)、CSDN;视频会发布在bilibili(UID:399951374) 一、…...
为false解决)
剪映failed to initialize,cuda.is_available()为false解决
debug记录帖 错误1:打开剪映发现弹窗提示failed to initialize graphics backed for D3D11 错误2:torch版本、cuda版本(之前的正常环境)都对但是torch.cuda.is_available()为false 怀疑是显卡驱动的问题 打开Nvidia Geforce Exp…...

基于Spring Boot的LDAP开发全教程
写在前面 协议概述 LDAP(轻量级目录访问协议,Lightweight Directory Access Protocol)是一种用于访问和维护分布式目录服务的开放标准协议,是一种基于TCP/IP协议的客户端-服务器协议,用于访问和管理分布式目录服务,如企业内部的…...

在 Linux 上保护 SSH 服务器连接的 8 种方法
SSH 是一种广泛使用的协议,用于安全地访问 Linux 服务器。大多数用户使用默认设置的 SSH 连接来连接到远程服务器。但是,不安全的默认配置也会带来各种安全风险。 具有开放 SSH 访问权限的服务器的 root 帐户可能存在风险。尤其是如果使用的是公共 IP 地…...
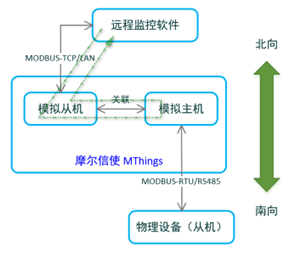
摩尔信使MThings的协议转换(数据网关)功能
摩尔信使MThings可以作为现场总线(RS485)和以太网的数据中枢,并拥有强大的Modbus协议转换功能。 数据网关功能提供协议转换和数据汇聚功能,可实现多维度映射,包括:不同的通道(总线)类型、协议类型ÿ…...
Mac安装Kali保姆级教程
Mac安装Kali保姆级教程 其他安装教程:使用VMware安装系统Window、Linux(kali)、Mac操作系统 1 虚拟机安装VM Fusion 去官网下载VM Fusion 地址:https://customerconnect.vmware.com/en/evalcenter?pfusion-player-personal-13 …...

利用Spring Boot框架做事件发布和监听
一、编写事件 1.编写事件类并集成spring boot 事件接口,提供访问事件参数属性 public class PeriodicityRuleChangeEvent extends ApplicationEvent {private final JwpDeployWorkOrderRuleDTO jwpDeployWorkOrderRuleDTO;public PeriodicityRuleChangeEvent(Obje…...
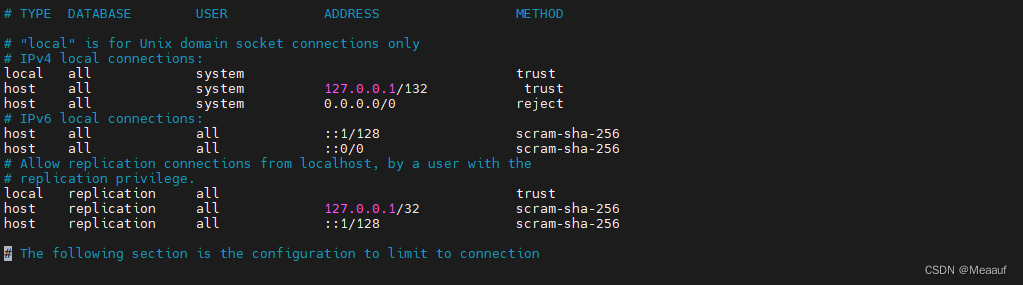
KingBase库模式表空间和客户端认证(kylin)
库、模式、表空间 数据库 数据库基集簇与数据库实例 KES集簇是由单个KES实例管理的数据库的集合KES集簇中的库使用相同的全局配置文件和监听端口、共享相关的进程和内存结构同一数据库集簇中的进程、相关的内存结构统称为实例 数据库 数据库是一个长期存储在计算机内的、有…...
h5的扫一扫功能 (非微信浏览器环境下)
必须在 https 域名下才生效 <template><div><van-field label"服务商编码" right-icon"scan" placeholder"扫描二维码获取" click-right-icon"getCameras" /> <div class"scan" :style"{disp…...
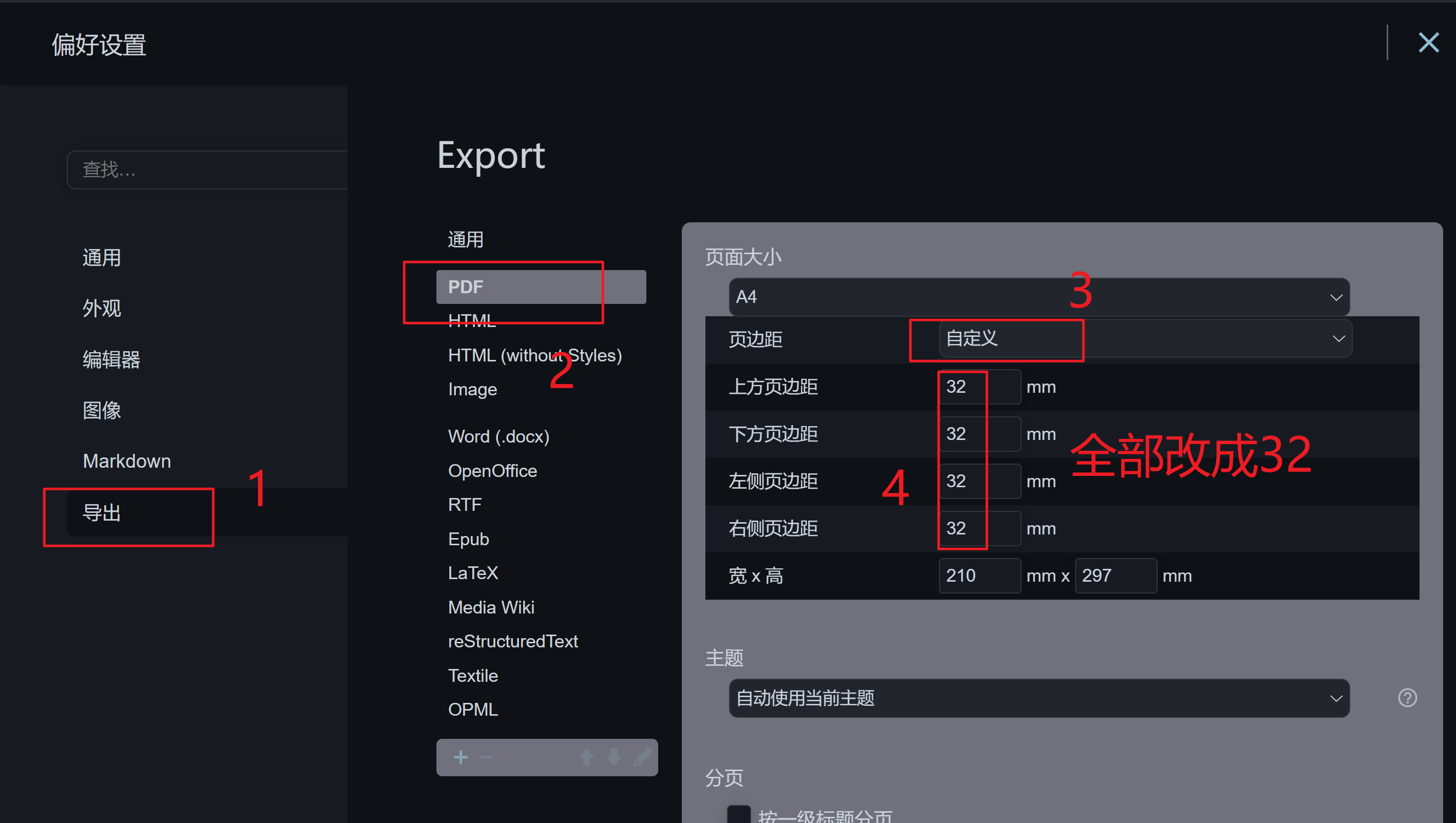
Typora 导出PDF 报错 failed to export as pdf. undefined 解决方案
情况 我想把一个很大的markdown 导出为 248页的pdf 然后就报错 failed to export as pdf. undefined 原因 : 个人感觉应该是图片太大了 格式问题之类导致的 解决 文件 -> 偏好设置 - > 导出 -> pdf -> 自定义 -> 把大小全部改为24mm (虽然图中是32 …...
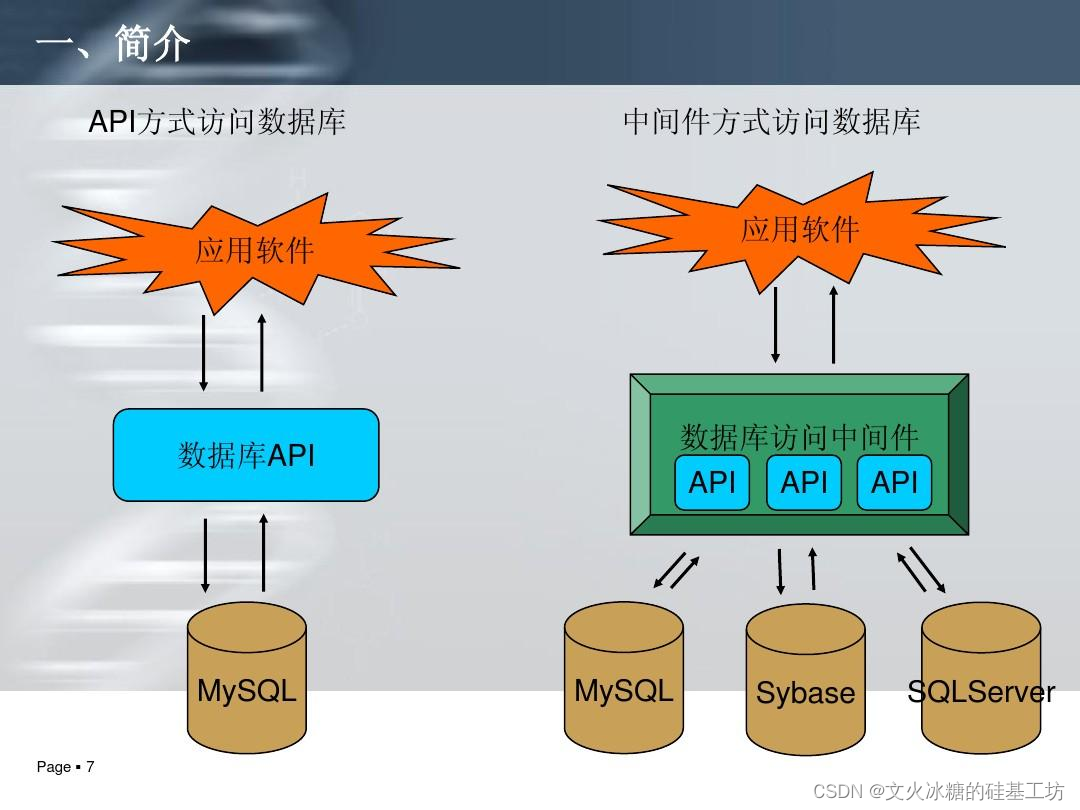
[架构之路-239]:目标系统 - 纵向分层 - 中间件middleware
目录 前言: 一、中间件概述 1.1 中间件在软件层次中的位置 1.2 什么是中间件 1.3 为什么需要中间件 1.4 中间件应用场合(应用程序不用的底层需求:计算、存储、通信) 1.5 中间件分类 - 按内容分 二、嵌入式系统的中间件 2…...

javascript利用xhr对象实现http流的comet轮循,主要是利用readyState等于3的特点
//此文件 为前端获取http流 <!DOCTYPE html> <html xmlns"http://www.w3.org/1999/xhtml" lang"UTF-8"></html> <html><head><meta http-equiv"Content-Type" content"text/html; charsetUTF-8"/&g…...

【Mybatis源码】XPathParser解析器
XPathParser是Mybatis中定义的进行解析XML文件的类,此类用于读取XML文件中的节点文本与属性;本篇我们主要介绍XPathParser解析XML的原理。 一、XPathParser构造方法 这里我们介绍主要的构造方法 public XPathParser(InputStream inputStream, boolean validation, Propert…...

辉视智慧酒店解决方案助力传统酒店通过智能升级焕发新生
辉视智慧酒店解决方案基于强大的物联网平台,将酒店客控、网络覆盖、客房智能化控制、酒店服务交互等完美融合,打造出全方位的酒店智慧化产品。利用最新的信息化技术,我们推动酒店智慧化转型,综合运用前沿的信息科学和技术、消费方…...

文件和命令的查找与处理
1.命令查找 which which 接命令 2.文件查找 find 按文件名字查找 准确查找 find / -name "hosts" 粗略查找 find / -name "ho*ts" 扩展名查找 find / -name "*.txt" 按文件类型查找 find / -type f 文件查找 find / -ty…...
)
第七章:最新版零基础学习 PYTHON 教程—Python 列表(第三节 -Python程序访问列表中的索引和值)
有多种方法可以访问列表的元素,但有时我们可能需要访问元素及其所在的索引。让我们看看访问列表中的索引和值的所有不同方法。 目录 使用Naive 方法访问列表中的索引和值 使用列表理解访问列表中的索引和值...

接口测试面试题整理
HTTP, HTTPS协议 什么是DNSHTTP协议怎么抓取HTTPS协议说出请求接口中常见的返回状态码http协议请求方式HTTP和HTTPS协议区别HTTP和HTTPS实现机有什么不同POST和GET的区别HTTP请求报文与响应报文格式什么是Http协议无状态协议?怎么解决HTTP协议无状态协议常见的POST提交数据方…...

【保姆级教程】ChatGPT/GPT4科研技术应用与AI绘图
查看原文>>>https://mp.weixin.qq.com/s?__bizMzAxNzcxMzc5MQ&mid2247663763&idx1&snbaeb113ffe0e9ebf2b81602b7ccfa0c6&chksm9bed5f83ac9ad6955d78e4a696949ca02e1e531186464847ea9c25a95ba322f817c1fc7d4e86&token1656039588&langzh_CN#rd…...
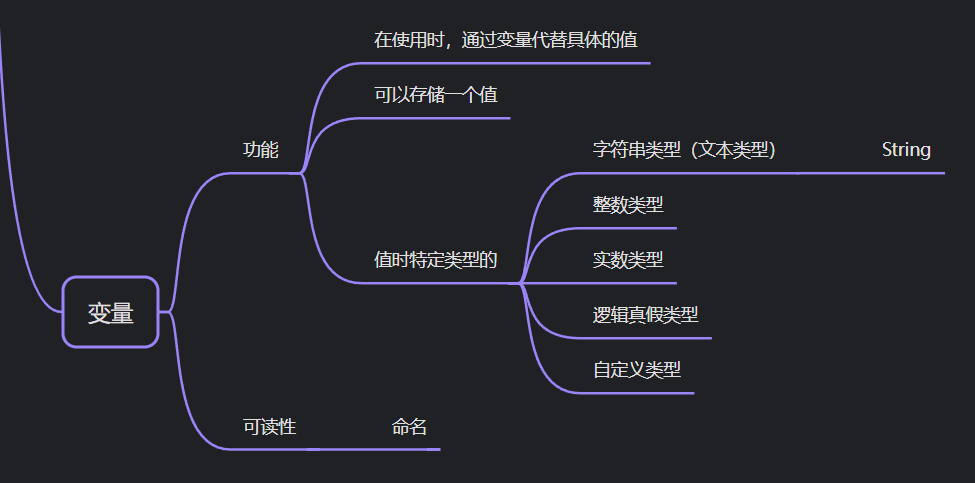
凉鞋的 Godot 笔记 202. 变量概述与简介
202. 变量概述与简介 想要用好变量不是一件简单的事情,因为变量需要命名。 我们可以从两个角度去看待一个变量,第一个角度是变量的功能,第二个是变量的可读性。 变量的功能其实非常简单,变量可以存储一个值,这个值是…...
)
python复习--进程相关--is_alive()
一、Process.is_alive() is_alive() 是 multiprocessing.Process 提供的方法,用于 判断进程当前是否仍在运行。 process.is_alive()返回值: True → 进程正在运行False → 进程未启动 或 已经结束 二、进程生命周期与 is_alive() 一个 Process 对象…...

8种Prompt优化技巧:解决大模型输出不稳定痛点
8种Prompt优化技巧:解决大模型输出不稳定痛点 在大模型应用落地过程中,开发者常遇到输出结果不可控的问题:同样的需求多次调用返回内容差异巨大、回答偏离核心要求、格式混乱无法直接解析,这些问题严重影响业务流程的稳定性和用户…...

Janus-Pro-7B入门指南:零基础Python调用与第一个AI应用创建
Janus-Pro-7B入门指南:零基础Python调用与第一个AI应用创建 你是不是对AI大模型充满好奇,想亲手试试调用一个强大的模型,但又觉得门槛太高,被各种复杂的部署和配置劝退?别担心,今天我们就来彻底解决这个问…...

STM32CubeIDE用DAP下载器?这份OpenOCD配置文件修改与复位难题解决指南请收好
STM32CubeIDE深度调优:DAP下载器OpenOCD配置与自动复位难题实战解析 当你在STM32CubeIDE中切换ST-LINK与DAP调试器时,是否注意到两者在用户体验上的显著差异?特别是当使用DAP调试器时,每次下载后都需要手动复位开发板才能运行程序…...

深入解析RevokeMsgPatcher:Windows平台防撤回补丁的技术实现与架构设计
深入解析RevokeMsgPatcher:Windows平台防撤回补丁的技术实现与架构设计 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: ht…...

Qt网络编程实战:基于QTcpSocket构建带进度反馈的可靠文件传输系统
1. 为什么需要带进度反馈的文件传输系统 在开发桌面应用时,文件传输是个绕不开的刚需功能。特别是传输大文件时,用户最怕的就是看着界面发呆——不知道传输进行到哪一步了,也不知道还要等多久。我做过一个医疗影像传输系统,医生们…...

UV固化三防漆好用吗?光固化速度与设备要求
UV固化三防漆好用吗?光固化速度与设备要求高效快速的固化优势 UV固化三防漆(也称紫外光固化保形涂层)是一种专为印刷电路板(PCB)设计的保护材料,通过紫外光照射触发光引发剂瞬间聚合,实现快速固…...

快手数据采集引擎:无水印解析与多源内容整合工具
快手数据采集引擎:无水印解析与多源内容整合工具 【免费下载链接】kuaishou-crawler As you can see, a kuaishou crawler 项目地址: https://gitcode.com/gh_mirrors/ku/kuaishou-crawler 价值定位:重新定义短视频数据采集标准 在数字内容分析与…...

SEO_避开这些SEO误区,优化效果事半功倍
SEO误区:避开这些误区,优化效果事半功倍 在当今竞争激烈的互联网环境中,搜索引擎优化(SEO)成为了每一个网站主的必修课。不少人在SEO实践中却犯下了一些常见的误区,这些误区不仅没有提升网站的排名&#x…...
`反而变慢了?Python 3.14 JIT缓存键生成算法变更深度解析(附3.13→3.14 ABI不兼容警告))
为什么你的`@jit(cache=True)`反而变慢了?Python 3.14 JIT缓存键生成算法变更深度解析(附3.13→3.14 ABI不兼容警告)
第一章:Python 3.14 JIT 编译器性能调优 面试题汇总Python 3.14 引入了实验性内置 JIT(Just-In-Time)编译器,基于 PGO(Profile-Guided Optimization)与轻量级字节码重写机制,在 CPU-bound 场景下…...