测试PySpark
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
这篇文章旨在帮你写出健壮的pyspark 代码。
在这里,通过它写pyspark单元测试,看这个代码通过PySpark built,下载该目录代码,查看JIRA 看板票的pyspark测试
创建PySpark应用
这边一个例子是怎么创建pyspark应用,如果你的应用已经测试,你可以跳过这一段,测试你的pyspark程序。
现在,开始测试你的spark session
from pyspark.sql import SparkSession
from pyspark.sql.functions import col# Create a SparkSession
spark = SparkSession.builder.appName("Testing PySpark Example").getOrCreate()接下来,创建一个DataFrame
sample_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]df = spark.createDataFrame(sample_data)现在,我们对我们的DataFrame来定义转换算子
from pyspark.sql.functions import col, regexp_replace# Remove additional spaces in name
def remove_extra_spaces(df, column_name):# Remove extra spaces from the specified columndf_transformed = df.withColumn(column_name, regexp_replace(col(column_name), "\\s+", " "))return df_transformedtransformed_df = remove_extra_spaces(df, "name")transformed_df.show()+---+--------+ |age| name| +---+--------+ | 30| John D.| | 25|Alice G.| | 35| Bob T.| | 28| Eve A.| +---+--------+
测试你的pyspark应用
现在来测试你的pyspark转换算子。一个选择简化DataFrame测试结果,可以简化数据或者输入数据。更好的方式写测试例子,这里有一些例子怎么去测试我们的代码,这些代码是基于spark 3.5以下版本。对于这些例子做笔记是非常值得的,可以通过测试框架,不管你是使用unittest or pytest; built-in PySpark 测试是单机的,意味着他兼容测试框架和CI测试
选项1: 仅仅使用PySpark Built-in 测试方法
import pyspark.testing
from pyspark.testing.utils import assertDataFrameEqual# Example 1
df1 = spark.createDataFrame(data=[("1", 1000), ("2", 3000)], schema=["id", "amount"])
df2 = spark.createDataFrame(data=[("1", 1000), ("2", 3000)], schema=["id", "amount"])
assertDataFrameEqual(df1, df2) # pass, DataFrames are identical# Example 2
df1 = spark.createDataFrame(data=[("1", 0.1), ("2", 3.23)], schema=["id", "amount"])
df2 = spark.createDataFrame(data=[("1", 0.109), ("2", 3.23)], schema=["id", "amount"])
assertDataFrameEqual(df1, df2, rtol=1e-1) # pass, DataFrames are approx equal by rtol您还可以简单地比较两个 DataFrame 模式:
from pyspark.testing.utils import assertSchemaEqual
from pyspark.sql.types import StructType, StructField, ArrayType, DoubleTypes1 = StructType([StructField("names", ArrayType(DoubleType(), True), True)])
s2 = StructType([StructField("names", ArrayType(DoubleType(), True), True)])assertSchemaEqual(s1, s2) # pass, schemas are identical选项 2:使用单元测试
对于更复杂的测试场景,您可能需要使用测试框架。
最流行的测试框架选项之一是单元测试。让我们逐步了解如何使用内置 Pythonunittest库来编写 PySpark 测试。有关该unittest库的更多信息,请参阅此处: https: //docs.python.org/3/library/unittest.html。
首先,您需要一个 Spark 会话。您可以使用包@classmethod中的装饰器unittest来负责设置和拆除 Spark 会话。
import unittestclass PySparkTestCase(unittest.TestCase):@classmethoddef setUpClass(cls):cls.spark = SparkSession.builder.appName("Testing PySpark Example").getOrCreate()@classmethoddef tearDownClass(cls):cls.spark.stop() 现在我们来写一个unittest类。
from pyspark.testing.utils import assertDataFrameEqualclass TestTranformation(PySparkTestCase):def test_single_space(self):sample_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]# Create a Spark DataFrameoriginal_df = spark.createDataFrame(sample_data)# Apply the transformation function from beforetransformed_df = remove_extra_spaces(original_df, "name")expected_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]expected_df = spark.createDataFrame(expected_data)assertDataFrameEqual(transformed_df, expected_df)运行时,unittest将选取名称以“test”开头的所有函数。
选项 3:使用Pytest
pytest我们还可以使用最流行的 Python 测试框架之一来编写测试。有关 的更多信息pytest,请参阅此处的文档: https: //docs.pytest.org/en/7.1.x/contents.html。
使用pytest固定装置允许我们在测试之间共享 Spark 会话,并在测试完成时将其拆除。
import pytest@pytest.fixture
def spark_fixture():spark = SparkSession.builder.appName("Testing PySpark Example").getOrCreate()yield spark然后我们可以这样定义我们的测试:
import pytest
from pyspark.testing.utils import assertDataFrameEqualdef test_single_space(spark_fixture):sample_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]# Create a Spark DataFrameoriginal_df = spark.createDataFrame(sample_data)# Apply the transformation function from beforetransformed_df = remove_extra_spaces(original_df, "name")expected_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]expected_df = spark.createDataFrame(expected_data)assertDataFrameEqual(transformed_df, expected_df)
当您使用该pytest命令运行测试文件时,它将选取名称以“test”开头的所有函数。
把它们放在一起!
让我们在单元测试示例中一起查看所有步骤。
# pkg/etl.py
import unittestfrom pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.functions import regexp_replace
from pyspark.testing.utils import assertDataFrameEqual# Create a SparkSession
spark = SparkSession.builder.appName("Sample PySpark ETL").getOrCreate()sample_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]df = spark.createDataFrame(sample_data)# Define DataFrame transformation function
def remove_extra_spaces(df, column_name):# Remove extra spaces from the specified column using regexp_replacedf_transformed = df.withColumn(column_name, regexp_replace(col(column_name), "\\s+", " "))return df_transformed# pkg/test_etl.py
import unittestfrom pyspark.sql import SparkSession# Define unit test base class
class PySparkTestCase(unittest.TestCase):@classmethoddef setUpClass(cls):cls.spark = SparkSession.builder.appName("Sample PySpark ETL").getOrCreate()@classmethoddef tearDownClass(cls):cls.spark.stop()# Define unit test
class TestTranformation(PySparkTestCase):def test_single_space(self):sample_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]# Create a Spark DataFrameoriginal_df = spark.createDataFrame(sample_data)# Apply the transformation function from beforetransformed_df = remove_extra_spaces(original_df, "name")expected_data = [{"name": "John D.", "age": 30},{"name": "Alice G.", "age": 25},{"name": "Bob T.", "age": 35},{"name": "Eve A.", "age": 28}]expected_df = spark.createDataFrame(expected_data)assertDataFrameEqual(transformed_df, expected_df)unittest.main(argv=[''], verbosity=0, exit=False)
在 1.734 秒内完成 1 次测试
<unittest.main.TestProgram 位于 0x174539db0> 相关文章:

测试PySpark
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...

C语言- 原子操作
基本概念 在C语言(尤其是C11标准之后)中,原子操作提供了一种机制,使得程序员可以在并发环境中,不使用互斥或其他同步原语,而直接对数据进行操作,同时确保数据的完整性和一致性。 原子变量和原子操作的核心思想是:无论什么时候,只有一个线程能够看到变量的修改操作。…...
设置hadoop+安装java环境
上一篇 http://t.csdnimg.cn/K3MFS 基本操作 接着上一篇 先导入之前导出的虚拟机 选择导出到对应的文件夹中 这里修改一下保存虚拟机的位置(当然你默认也可以) 改一个名字 新建一个share文件夹用来存放共享软件的文件夹 在虚拟机的设置中找到这个设置…...

阿里云新加坡主机服务器选择
阿里云新加坡主机有哪些选择?可以选择云服务器ECS或轻量应用服务器,都有新加坡地域可以选择,东南亚地区可以选择新加坡、韩国首尔、日本东京等地域,阿里云新加坡主机测试IP地址:161.117.118.93 可以测试下本地到新加坡…...

21天打卡掌握java基础操作
Java安装环境变量配置-day1 参考: https://www.runoob.com/w3cnote/windows10-java-setup.html 生成class文件 java21天打卡-day2 输入和输出 题目:设计一个程序,输入上次考试成绩(int)和本次考试成绩࿰…...
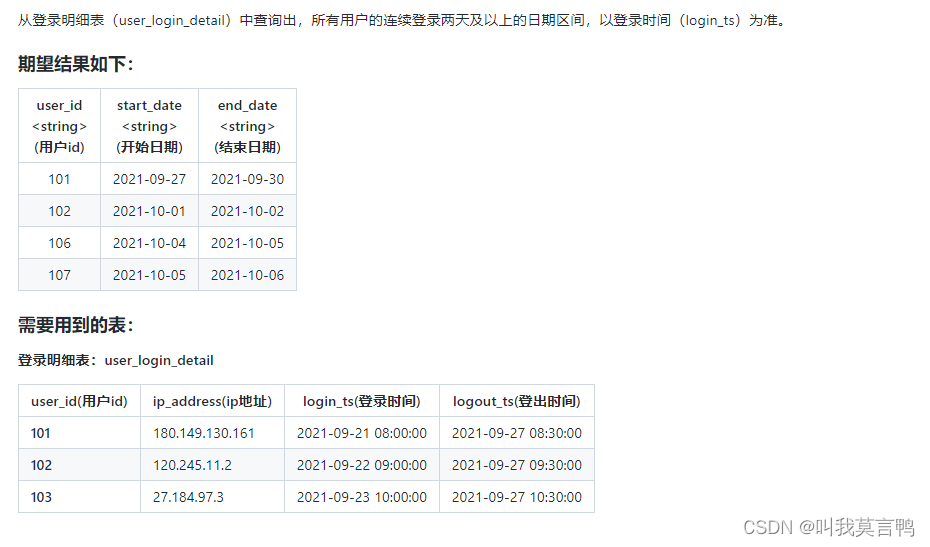
SQL题目记录
1.商品推荐题目 1.思路: 通过取差集 得出要推荐的商品差集的选取:except直接取差集 或者a left join b on where b null 2.知识点 1.except selectfriendship_info.user1_id as user_id,sku_id fromfriendship_infojoin favor_info on friendship_in…...
Linux程序调试器——gdb的使用
gdb的概述 GDB 全称“GNU symbolic debugger”,从名称上不难看出,它诞生于 GNU 计划(同时诞生的还有 GCC、Emacs 等),是 Linux 下常用的程序调试器。发展至今,GDB 已经迭代了诸多个版本,当下的…...

前端打包项目上线-nginx
第一步:下载nginx。 直接下载 nginx/Windows-1.25.2 pgp 第二步:解压zip包 第三步:打开文件夹,把http里的路径打开cmd 第四步:打开你的http-server服务,没有下载去下一次就ok了 打开后就可以访问了 第五步…...
创龙瑞芯微RK3568参数修改(调试口波特率和rootfs文件)
前言 前面写了基本的文件编译、系统编译和系统烧写,差不多前期工作就准备的差不多了。目前的东西能解决大部分入门级的需求。当然如果需要开发的话,还需要修改其他东西,下面一步一步的给小伙伴介绍关键参数怎么修改。 给定波特率 拿到开发板…...
VMware——VMware17安装WindowServer2012R2环境(图解版)
目录 一、WindowServer2012R2镜像百度云下载二、安装 一、WindowServer2012R2镜像百度云下载 下载链接:https://pan.baidu.com/s/1TWnSRJTk0ruGNn4YinzIgA 提取码:e7u0 二、安装 打开虚拟机,点击【创建新的虚拟机】,如下图&…...
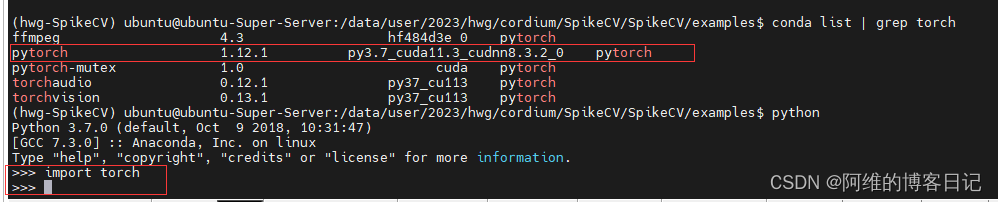
ModuleNotFoundError: No module named ‘torch‘
目录 情况1,真的没有安装pytorch情况2(安装了与CUDA不对应的pytorch版本导致无法识别出torch) 情况1,真的没有安装pytorch 虚拟环境里面真的是没有torch,这种情况就easy job了,点击此链接直接安装与CUDA对应的pytorch版本,CTRLF直接搜索对应CUDA版本即可查找到对应的命令.按图…...
采用Spring Boot框架开发的医院预约挂号系统3e3g0+vue+java
本医院预约挂号系统有管理员,医生和用户。管理员功能有个人中心,用户管理,医生管理,科室信息管理,预约挂号管理,用户投诉管理,投诉处理管理,通知公告管理,科室分类管理。…...
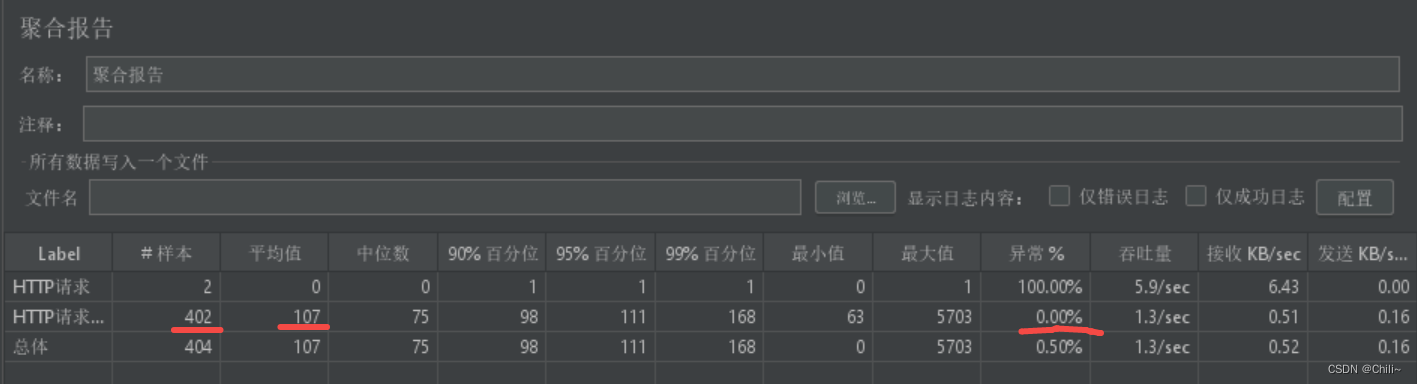
Jmeter性能测试(压力测试)
1.先保存 2.添加请求(即添加一个线程组) 3.添加取样器(在线程组下面添加一个http请求) 场景1:模拟半小时之内1000个用户访问服务器资源,要求平均响应时间在3000毫秒内,且错误率为0࿰…...
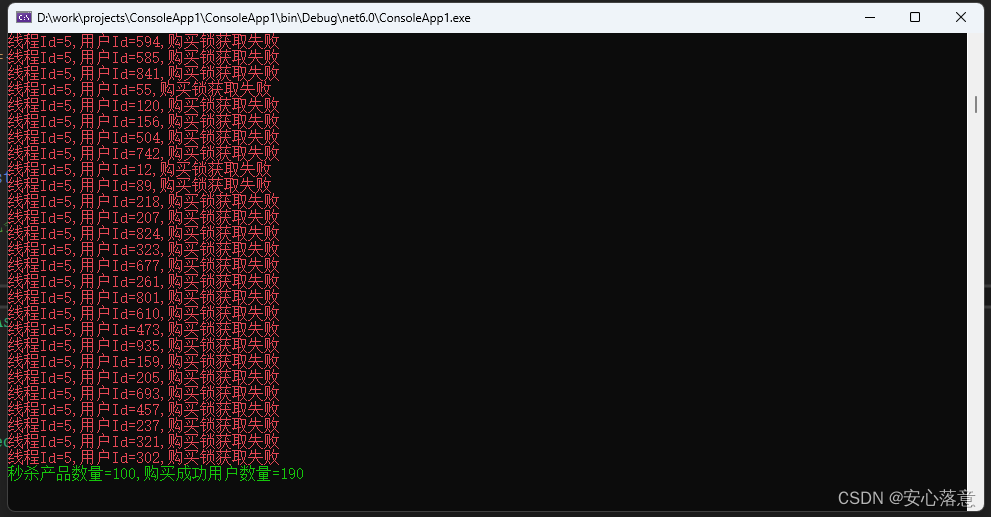
NetCore/Net8下使用Redis的分布式锁实现秒杀功能
目的 本文主要是使用NetCore/Net8加上Redis来实现一个简单的秒杀功能,学习Redis的分布式锁功能。 准备工作 1.Visual Studio 2022开发工具 2.Redis集群(6个Redis实例,3主3从)或者单个Redis实例也可以。 实现思路 1.秒杀开始…...

openGauss学习笔记-102 openGauss 数据库管理-管理数据库安全-客户端接入之查看数据库连接数
文章目录 openGauss学习笔记-102 openGauss 数据库管理-管理数据库安全-客户端接入之查看数据库连接数102.1 背景信息102.2 操作步骤 openGauss学习笔记-102 openGauss 数据库管理-管理数据库安全-客户端接入之查看数据库连接数 102.1 背景信息 当用户连接数达到上限后&#…...

lspci源码
lspci 显示Linux系统的pci设备最简单的方法就是使用lspci命令,前提是要安装pciutils包(centos在最小化安装时不会自带该包,需要自己下载安装) pciutils包的源码github地址为: https://github.com/pciutils/pciutils …...

CMake教程-第 8 步:添加自定义命令和生成文件
CMake教程-第 8 步:添加自定义命令和生成文件 1 CMake教程介绍2 学习步骤Step 1: A Basic Starting PointStep 2: Adding a LibraryStep 3: Adding Usage Requirements for a LibraryStep 4: Adding Generator ExpressionsStep 5: Installing and TestingStep 6: Ad…...

快速入门:Spring Cache
目录 一:Spring Cache简介 二:Spring Cache常用注解 2.1:EnableCaching 2.2: Cacheable 2.3:CachePut 2.4:CacheEvict 三:Spring Cache案例 3.1:先在pom.xml中引入两个依赖 3.2:案例 3.2.1:构建数据库表 3.2.2:构建User类 3.2.3:构建Controller mapper层代码 3.…...

探索音频传输系统:数字声音的无限可能 | 百能云芯
音频传输系统是一项关键的技术,已经在数字时代的各个领域中广泛应用,从音乐流媒体到电话通信,再到多媒体制作。本文将深入探讨音频传输系统的定义、工作原理以及在现代生活中的各种应用,以帮助您更好地了解这一重要技术。 音频传输…...
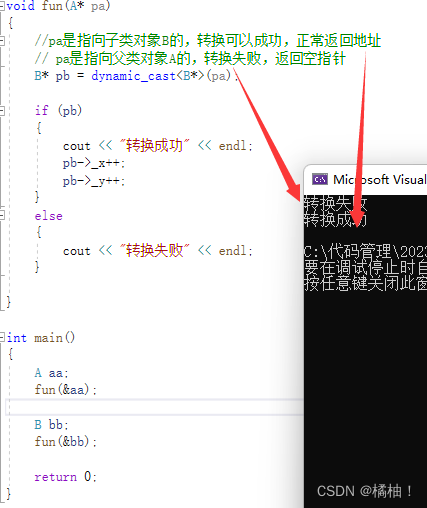
【C++】-c++的类型转换
💖作者:小树苗渴望变成参天大树🎈 🎉作者宣言:认真写好每一篇博客💤 🎊作者gitee:gitee✨ 💞作者专栏:C语言,数据结构初阶,Linux,C 动态规划算法🎄 如 果 你 …...

Llama-3.2V-11B-cot效果展示:识别艺术海报中风格与主题逻辑断层
Llama-3.2V-11B-cot效果展示:识别艺术海报中风格与主题逻辑断层 1. 工具介绍 Llama-3.2V-11B-cot是基于Meta Llama-3.2V-11B-cot多模态大模型开发的高性能视觉推理工具。该工具针对双卡4090环境进行了深度优化,特别适合需要分析复杂视觉内容的场景&…...
人工智能创意工作流:Pixel Script Temple 与 AI Agent 协同创作
人工智能创意工作流:Pixel Script Temple 与 AI Agent 协同创作 1. 多智能体协作的艺术革命 当三个专业AI Agent组成创意团队,会产生怎样的化学反应?这套由Pixel Script Temple驱动的协同工作流,正在重新定义数字艺术创作的可能…...

Spring_couplet_generation 模型推理性能优化:操作系统级调优指南
Spring_couplet_generation 模型推理性能优化:操作系统级调优指南 想让你的春联生成模型跑得更快、更稳吗?很多朋友在部署AI模型时,往往只关注模型本身和代码,却忽略了承载这一切的“地基”——操作系统。今天,我们就…...

SAP-ABAP:SAP ABAP 经典弹窗函数 POPUP_TO_CONFIRM 完全指南
SAP ABAP 经典弹窗函数 POPUP_TO_CONFIRM 完全指南在SAP开发中,如何优雅地让用户确认“你确定要删除这条数据吗?”——答案就是 POPUP_TO_CONFIRM。在 ABAP 开发的世界里,与用户的交互不仅仅是输入输出。很多时候,我们需要在程序执…...

OpenClaw极简安装:Qwen3.5-9B云端体验与快速验证方案
OpenClaw极简安装:Qwen3.5-9B云端体验与快速验证方案 1. 为什么选择云端体验OpenClaw? 上周我在本地尝试部署OpenClaw时,被各种环境依赖折腾得够呛——Node版本冲突、Python包缺失、端口占用问题接踵而至。正当准备放弃时,偶然发…...

掰开揉碎魔改claudecode后,我盯着 Claude Code 跑了一圈,终于看懂顶级 AI Agent是如何炼成的
开头先来一句狠的很多人以为,Claude Code 之所以强,是因为模型更聪明。但我把它运行时真正生效的 Payload 抓出来之后,结论反而更明确了:顶级 AI Agent 的差距,很多时候不在模型本身,而在它背后那套“怎么约…...

EasyAnimation性能优化指南:确保动画流畅运行的7个关键点
EasyAnimation性能优化指南:确保动画流畅运行的7个关键点 【免费下载链接】EasyAnimation A Swift library to take the power of UIView.animateWithDuration(_:, animations:...) to a whole new level - layers, springs, chain-able animations and mixing view…...

GLM-4v-9b多图对比分析:上传两张产品图→自动识别差异点→生成结构化对比报告
GLM-4v-9b多图对比分析:上传两张产品图→自动识别差异点→生成结构化对比报告 1. 产品对比分析的新选择 在日常工作中,我们经常需要对比两个相似的产品图片——可能是不同版本的设计稿、竞品分析、或者产品质量检查。传统方法需要人工逐像素比对&#…...

工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式
工业冷水机控制程序西门子1200plc含压缩机,电子膨胀阀控制策略,饱和温度计算公式凌晨三点钟的冷水机组房,设备轰鸣声中闪烁着PLC运行指示灯。手指划过TP1200触摸屏的瞬间,压缩机启动电流曲线在屏幕上划出漂亮的爬坡轨迹——这就是…...

【C++27范围库前瞻实战指南】:20年标准库专家亲授5大扩展接口的工业级应用模式
第一章:C27范围库扩展全景概览C27 将对标准范围库(Ranges)进行实质性增强,聚焦于提升表达力、运行时效率与编译期元编程能力。核心演进方向包括惰性求值语义强化、范围适配器的定制化组合机制、对异步与并行范围操作的原生支持&am…...