DRM中render-node编号的分配
DRM系统
DRM是direct rendering manager的简称。DRM是linux kernel中与负责video cards功能的GPU打交道的子系统。DRM给出了一组API,可以供用户程序来发送命令和数据给GPU设备从而来控制比如display、render等功能。
render-node由来
在以前,DRM子系统中给每个DRM device注册的device-node就是:/dev/dri/cardX ,通过该节点来作mode-setting和rendering的控制。后来发现这么做有问题:
-
mode-setting和rendering是通过同一个文件节点node来控制的
-
单卡的mode-setting资源不能在多个graphics-servers之间切分使用
-
在多cards之间共享display-controller实现过于复杂
然后就有了一些改进来解决这些问题。最终是mode-setting 和 render节点分家。
render node
render-node架构大概是2009年左右提出来的。站在用户程序角度来看,render node的作用是用来加速computing和rendering,render node可以通过 /dev/dri/renderDX 被访问,并且提供了基本的DRM rendering interface。与 /dev/dri/cardX 节点相比,/dev/dri/renderDX 少了一些特性:
-
没有mode-setting(KMS)ioctls功能
-
用dma-buf替换掉gem-flink(非安全的)
-
不再需要DRM-auth认证
-
不再支持pre-KMS DRM-API
这样一来,当应用程序需要hardware-acclerated rendering、访问GPGPU、offscreen rendering等时,就不需要通过DRI或者wl_drm来访问graphics-server,而是直接打开某个render node就开始使用即可。对于render node的访问权限控制则通过标注的file-system modes来控制了。
render-node并没有提供新的API,它们只是将原有的DRM-API分出了一部分到一个新的device-node,原来的node也保留了下来用于如mode-setting等控制。
render-node也没有和任何一个card进行绑定,它是由原有node的同一个driver创建的,所以尝试在原有node和render-node之间进行connect连接通信没有意义。当应用程序需要和graphics-server进行通信时,可以通过dma-buf。
mode-setting node
虽然从原有的node中分离出一个render-node,简化了应用程序的访问,但对于mode-setting程序的访问没有简化。当一个graphics-server想要编程一个display-controller时,它需要是给定card的DRM-Master,可以通过drmSetMaster()接口来获得身份,但同时只能有一个DRM-Master,而且必须是由CAP_SYS_ADMIN特权的程序才能成为DRM-Master,这会带来问题:
-
不能以非root权限运行XServer
-
不能在同一个card上使用两个不同的XServer来控制两个不同的独立的显示器
首先想到的解决办法就是分离出mode-setting node,类似render-node的方式,/dev/dri/modesetD1 和 /dev/dri/modesetD2 节点,来分割KMS CRTC和Connector资源。
另一种方法是将所有的mode-setting资源绑定到一个DRM-Master对象,然后谁要访问mode-setting资源就可以通过访问该DRM-Master对象来实现。
DRM infrastructure
不管是render-node还是mode-setting-node,在kernel角度是如何体现的?
如果hardware没有display-controller,则可以不设置DRIVER_MODESET flag只设置DRIVER_RENDER flag,这样内核DRM只会创建render-node。如果一个hardware只有display-controller而没有rendering hardware,可以设置DRIVER_MODESET而不设置DRIVER_RENDER。
大概回顾了下render node的由来。那么render node由kernel来负责创建,其编号为何从128开始,答案估计还要到kernel中寻找。
drm_dev_init
linux kernel中 drivers/gpu/drm/drm_drv.c中定义了drm_dev_init()函数,其中创建drm设备编号的代码如下
if (drm_core_check_feature(dev, DRIVER_COMPUTE_ACCEL)) {ret = drm_minor_alloc(dev, DRM_MINOR_ACCEL);if (ret)goto err;} else {if (drm_core_check_feature(dev, DRIVER_RENDER)) {ret = drm_minor_alloc(dev, DRM_MINOR_RENDER);if (ret)goto err;}ret = drm_minor_alloc(dev, DRM_MINOR_PRIMARY);if (ret)goto err;}
涉及到两个枚举类型结构体
enum drm_driver_feature {DRIVER_GEM = BIT(0),DRIVER_MODESET = BIT(1),DRIVER_RENDER = BIT(3),DRIVER_ATOMIC = BIT(4),DRIVER_SYNCOBJ = BIT(5),DRIVER_SYNCOBJ_TIMELINE = BIT(6),DRIVER_COMPUTE_ACCEL = BIT(7),DRIVER_USE_AGP = BIT(25),DRIVER_LEGACY = BIT(26),DRIVER_PCI_DMA = BIT(27),DRIVER_SG = BIT(28),DRIVER_HAVE_DMA = BIT(29),DRIVER_HAVE_IRQ = BIT(30),
};enum drm_minor_type {DRM_MINOR_PRIMARY,DRM_MINOR_CONTROL,DRM_MINOR_RENDER,DRM_MINOR_ACCEL = 32,
};
当drm core检查到device设置了DRIVER_RENDER标签时,就通过drm_minor_alloc(dev, DRM_MINOR_RENDER)来分配ID,而drm_minor_alloc()函数中最终分配ID是通过idr_alloc()函数来实现,这里的type传入的就是DRM_MINOR_RENDER,也就是2。
r = idr_alloc(&drm_minors_idr,NULL,64 * type,64 * (type + 1),GFP_NOWAIT);//idr_alloc又是调用idr_alloc_u32来实现
int idr_alloc(struct idr *idr, void *ptr, int start, int end, gfp_t gfp)
{u32 id = start;int ret;if (WARN_ON_ONCE(start < 0))return -EINVAL;ret = idr_alloc_u32(idr, ptr, &id, end > 0 ? end - 1 : INT_MAX, gfp);if (ret)return ret;return id;
}
EXPORT_SYMBOL_GPL(idr_alloc);
* idr_alloc() - Allocate an ID.* @idr: IDR handle.* @ptr: Pointer to be associated with the new ID.* @start: The minimum ID (inclusive).* @end: The maximum ID (exclusive).* @gfp: Memory allocation flags.
idr_alloc()的底3个参数就是ID的start,第4个参数是ID范围的end。所以,对于DRIVER_RENDER属性的device来说,其ID范围是
DRM_MINOR_RENDER * 64 = 128 至 (DRM_MINOR_RENDER + 1) * 64 = 192 之间。
所以才有renderD128、renderD129。
内核如何管理render-node的编号
问题:DRM中如何做到一个已经分配了的ID比如128,下一个device来分配时就不使用128而是129呢?换句话说kernel中如何记忆ID的分配结果的?
int idr_alloc_u32(struct idr *idr, void *ptr, u32 *nextid,unsigned long max, gfp_t gfp)
{struct radix_tree_iter iter;void __rcu **slot;unsigned int base = idr->idr_base;unsigned int id = *nextid;if (WARN_ON_ONCE(!(idr->idr_rt.xa_flags & ROOT_IS_IDR)))idr->idr_rt.xa_flags |= IDR_RT_MARKER;id = (id < base) ? 0 : id - base;radix_tree_iter_init(&iter, id);slot = idr_get_free(&idr->idr_rt, &iter, gfp, max - base);if (IS_ERR(slot))return PTR_ERR(slot);*nextid = iter.index + base;/* there is a memory barrier inside radix_tree_iter_replace() */radix_tree_iter_replace(&idr->idr_rt, &iter, slot, ptr);radix_tree_iter_tag_clear(&idr->idr_rt, &iter, IDR_FREE);return 0;
}
EXPORT_SYMBOL_GPL(idr_alloc_u32);
这里使用了基数树(radix-tree)。
两个显卡其分配render-node的顺序
比如我这个pc上有两个显卡intel UHD Graphics 630和Nvidia GTX 1050 Ti,然后/dev/dri/下也有两个render-node,renderD128和renderD129,内核分配它们的顺序是如何确定的?
应该是扫描PCI设备的时候就确定顺序了。
ubuntu上查看哪个card和哪个GPU绑定:
drm_info #该命令可以查看/dev/dri/card0对应的GPU驱动
比如我这里两个显卡,card0对应intel 630, card1对应nvidia GTX 1050Ti。
那么如何确定render node和GPU对应关系?
ls /sys/class/drm/card0/device/drm/
#可以看到card0中有card0, controlD64, renderD128
ls /sys/class/drm/card1/device/drm/
#可以看到card1中有card1, controlD65, renderD129
参考:
DRM render node number
相关文章:

DRM中render-node编号的分配
DRM系统 DRM是direct rendering manager的简称。DRM是linux kernel中与负责video cards功能的GPU打交道的子系统。DRM给出了一组API,可以供用户程序来发送命令和数据给GPU设备从而来控制比如display、render等功能。 render-node由来 在以前,DRM子系统…...
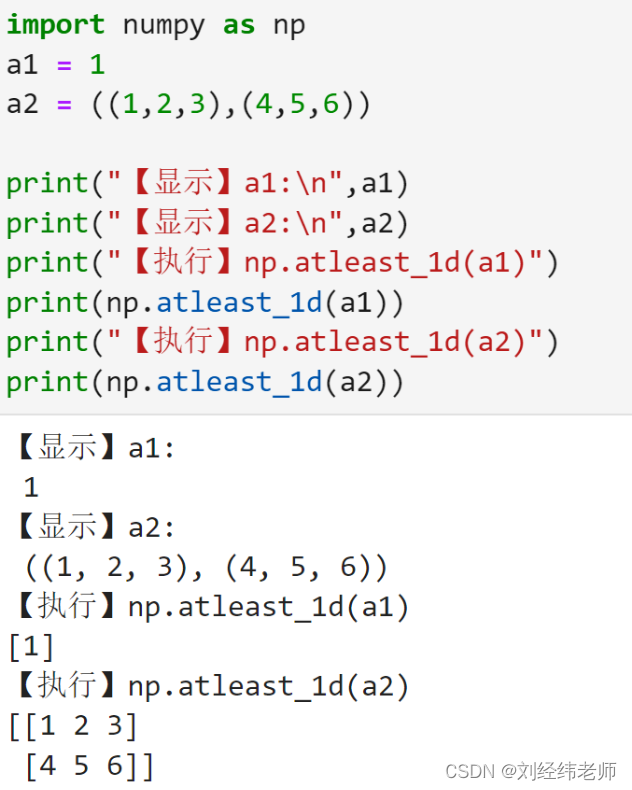
将输入对象转换为数组数组的维度大于等于1numpy.atleast_1d()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 将输入对象转换为数组 数组的维度大于等于1 numpy.atleast_1d() 选择题 使用numpy.atleast_1d()函数,下列正确的是? import numpy as np a1 1 a2 ((1,2,3),(4,5,6)) print("…...

js 删除树状图无用数据,如果子级没有数据则删除
有一个需求,当你从后端拿到一个树状图的时候,有些子级没数据,这时就需要我们处理一下数据,当然了,如果第一层底下的第二层没数据,第二层底下的所有都没数据,那这一层都不需要。 我的写法&#x…...
Docker 容器化(初学者的分享)
目录 一、什么是docker 二、docker的缺陷 三、简单的操作 一、首先配置一台虚拟机 二、安装Docker-CE 一、安装utils 二、 将 Docker 的软件源添加到 CentOS 的 yum 仓库中。这样可以通过 yum 命令来安装、更新和管理 Docker 相关的软件包。 三、将 download.docker.co…...

LCS 01.下载插件
题目来源: leetcode题目,网址:写文章-CSDN创作中心 解题思路: 假设需要 n 分钟下载插件,前 n-1 分钟将带宽加倍,最后一分钟下载时总时间最少。 解题代码: class Solution { public:int l…...
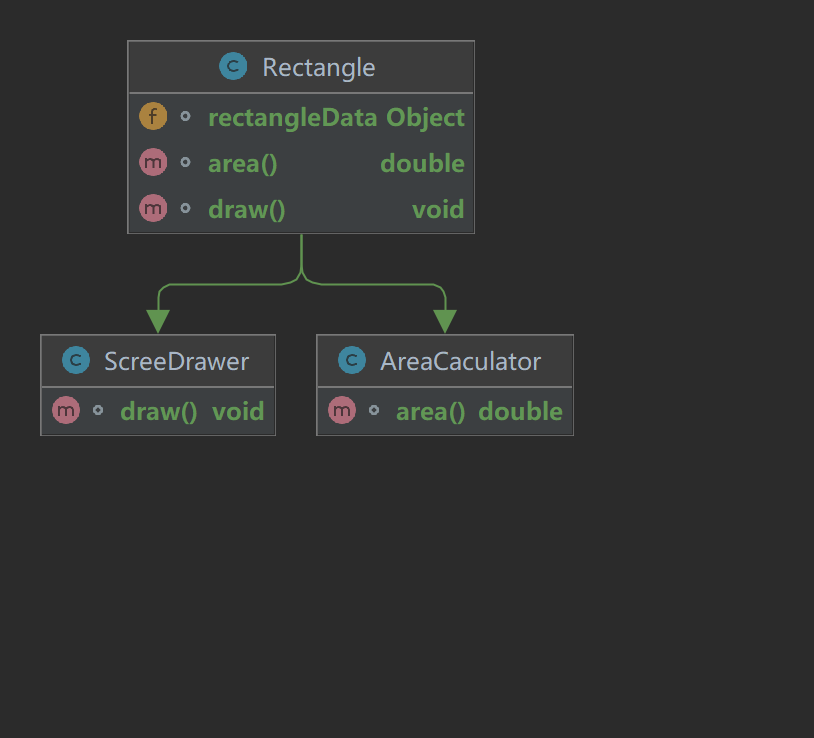
架构-设计原则
1、面向对象的SOLID 1.1 概述 SOLID是5个设计原则开头字母的缩写,其本身就有“稳定的”的意思,寓意是“遵从SOLID原则可以建立稳定、灵活、健壮的系统”。5个原则分别如下: Single Responsibility Principle(SRP)&am…...

在 Python 3 中释放 LightGBM 的力量:您的机器学习大师之路
机器学习是 Python 占据主导地位的领域,它一直在给全球各行各业带来革命性的变化。要在这个不断变化的环境中脱颖而出,掌握正确的工具是关键。LightGBM 就是这样一个工具,它是一个强大且快速的梯度提升框架。在这份综合指南中,我们将通过实际示例和示例数据集从基础知识到高…...
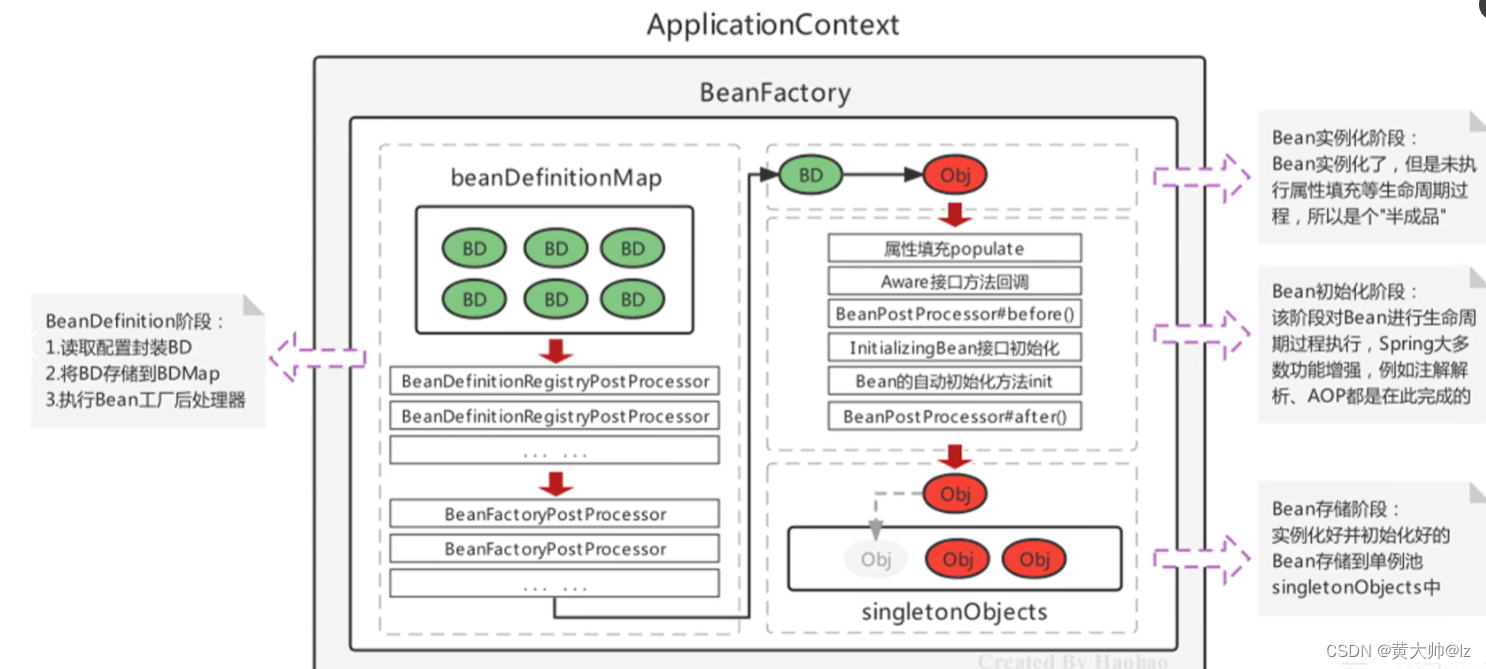
Spring学习笔记(2)
Spring学习笔记(2) 一、Spring配置非定义Bean1.1 DruidDataSource1.2、Connection1.3、Date1.4、SqlSessionFactory 二、Bean实例化的基本流程2.1 BeanDefinition2.2 单例池和流程总结 三、Spring的bean工厂后处理器3.1 bean工厂后处理器入门3.2、注册Be…...

cmd使用ssh连接Linux脚本
前言 在开发过程中,由于MobaXterm,我不知道怎么分页(不是屏内分页),用crtlTab,用起来不习惯,主要是MobaXterm连接了多个服务器,切换起来很麻烦。我是比较习惯使用altTab,…...

Python万圣节蝙蝠
目录 系列文章 前言 蝙蝠 程序设计 程序分析 运行结果 尾声 系列文章 序号文章目录直达链接1浪漫520表白代码https://want595.blog.csdn.net/article/details/1306668812满屏表白代码https://want595.blog.csdn.net/article/details/1297945183跳动的爱心https://want5…...
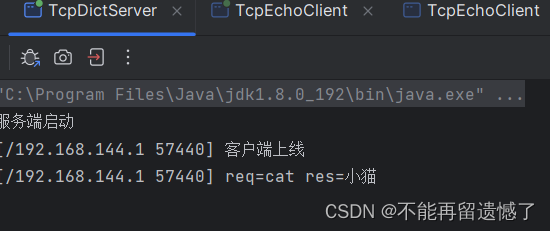
TCP流套接字编程
文章目录 前言TCP 和 UDP 的特点对比TcpEchoServer 服务端实现1. 创建 ServerSocket 类实现通信双方建立连接2. 取出建立的连接实现双方通信3. 服务端业务逻辑实现关闭资源服务端整体代码 TcpEchoClient 客户端实现1. 创建出 Socket 对象来与服务端实现通信2. 实现客户端的主要…...

Python迭代器创建与使用:从入门到精通
一、可迭代对象 1、 什么是可迭代对象? 表示可以逐一迭代或者遍历的对象,序列:列表、元组、集合、字符串。非序列:字典、文件。自定义对象:实现了__iter__()方法的对象;实现了使用整数索引的 getitem()方…...
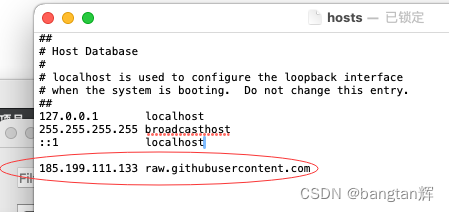
mac虚拟机安装homebrew时的问题
安装了mac虚拟机,结果在需要通过“brew install svn”安装svn时,才注意到没有下载安装homebrew。 于是便想着先安装homebrew,网上查的教程大多是通过类似以下命令 “ruby <(curl -fsSkL raw.github.com/mxcl/homebrew/go)” 但是都会出现…...
学信息系统项目管理师第4版系列32_信息技术发展
1. 大型信息系统 1.1. 大型信息系统是指以信息技术和通信技术为支撑,规模庞大,分布广阔,采用多级 网络结构,跨越多个安全域;处理海量的,复杂且形式多样的数据,提供多种类型应用 的大系统 1.1.…...
Vue3 + Nodejs 实战 ,文件上传项目--大文件分片上传+断点续传
目录 1.大文件上传的场景 2.前端实现 2.1 对文件进行分片 2.2 生成hash值(唯一标识) 2.3 发送上传文件请求 3.后端实现 3.1 接收分片数据临时存储 3.2 合并分片 4.完成段点续传 4.1修改后端 4.2 修改前端 5.测试 博客主页:専心_前端…...

宏(预编译)详解
目录 一、程序的编译环境 二、运行环境 三、预编译详解 3.1预定义符号 3.2.1 #define 定义标识符 3.2.2 #define 定义宏 3.2.3#define替换规则 3.2.4 #和## 2)##的作用: 3.2.5宏和函数的对比 3.2.6宏的命名约定和#undef指令 一、命名约定: …...
hue实现对hiveserver2 的负载均衡
如果你使用的是CDH集群那就很是方便的 在Cloudera Manager中,进入HDFS Service 进入Instances标签页面,点击Add Role Instances按钮,如下图所示 点击Continue按钮,如下图所示 返回Instances页面,选择HttpFS角色…...

SkyWalking 告警规则配置说明
Skywalking告警功能是在6.x版本新增的,其核心由一组规则驱动,这些规则定义在config/alarm-settings.yml 文件中。告警规则定义分为两部分: 1、告警规则:它们定义了应该如何触发度量警报,应该考虑什么条件 2、webhook(网络钩子):定义当告警触发时,哪些服务终端需要被…...
HTML 表单笔记/练习
表单 概述 表单用于收集用户信息,用户填写表单提交到服务器 一般传参方式: GETPOSTCookie 传参要素 传参方式 GETPOST 参数的名字目标页面内容的数据类型(只有在上传文件的时候) 提示信息 一个表单中通常还包含一些说明性的文…...

关于Java Integer和Long使用equals直接比较
Integer和Long不能直接equals比较会返回False Long.class源码 public boolean equals(Object obj) {if (obj instanceof Long) {return this.value (Long)obj;} else {return false;} }Integer.class源码 public boolean equals(Object obj) {if (obj instanceof Integer) {…...
)
从芯片设计到产线测试:深入浅出聊聊DFT中的SCAN链设计与JTAG标准(含IEEE 1149.1)
从芯片设计到产线测试:深入浅出聊聊DFT中的SCAN链设计与JTAG标准(含IEEE 1149.1) 在芯片设计领域,可测试性设计(DFT)早已从"锦上添花"变成了"不可或缺"的核心环节。想象一下࿰…...

SSM+Vue大学生兼职网站源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

3大核心功能解放明日方舟玩家双手:MAA自动化助手全攻略
3大核心功能解放明日方舟玩家双手:MAA自动化助手全攻略 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gi…...

便利店老板的备货神器——基于粒子群优化支持向量机的单日关东煮销量预测
基于粒子群优化支持向量机(PSO-SVM)的时间序列预测 PSO-SVM时间序列 matlab代码暂无Matlab版本要求 -- 推荐 2018B 版本及以上 采用 Libsvm 工具箱(无需安装,可直接运行),仅支持 Windows 64位系统昨天便利店刚进了一箱新口味的魔芋…...

新手入门福音:用快马AI生成你的第一个Python版游戏账号管理工具
作为一个刚接触Python编程的新手,最近想尝试开发一个简单的游戏账号管理工具。这个需求其实挺常见的,比如我平时玩多个游戏,账号密码经常记混,如果能有个小工具统一管理就方便多了。在朋友的推荐下,我尝试用InsCode(快…...

StructBERT-WebUI部署案例:AI客服中台语义路由模块集成实践
StructBERT-WebUI部署案例:AI客服中台语义路由模块集成实践 1. 项目背景与价值 在现代AI客服系统中,语义理解是核心能力之一。当用户提出"我的订单怎么还没到"时,系统需要准确理解这其实是在询问"物流状态",…...
)
别再只会用中断了!用状态机查表法搞定AB相编码器,STM32代码实测(附防抖技巧)
状态机查表法在AB相编码器中的工程实践与优化 记得第一次在电机控制项目中使用旋转编码器时,我整整花了三天时间调试中断服务程序。每当电机转速提高,计数器就会莫名其妙地漏脉冲或跳变。直到发现状态机查表法这个"神器",才真正解决…...

sinx/x在0到无穷积分的条件收敛性分析与证明
1. 从物理现象到数学问题:为什么研究sinx/x的积分? 我第一次接触sinx/x的积分是在信号处理课程中,这个看似简单的函数在傅里叶变换和频谱分析中扮演着关键角色。工程师们用它来描述理想低通滤波器的频率响应,物理学家则在衍射现象…...

PakePlus云打包入门指南:从零到一的GitHub Token配置与安全实践
PakePlus云打包入门指南:从零到一的GitHub Token配置与安全实践 【免费下载链接】PakePlus Turn any webpage/HTML/Vue/React and so on into desktop and mobile app under 5M with easy in few minutes. 轻松将任意网站/HTML/Vue/React等项目构建为轻量级(小于5M)…...

矩阵理论进阶:内积空间与正交变换的深度解析
1. 内积空间:从几何直觉到严格定义 第一次接触内积空间时,很多人会被各种抽象定义搞得晕头转向。其实我们可以从最熟悉的二维平面开始理解——当你计算两个向量的点积时,本质上是在测量它们的"相似程度"。这种几何直觉正是内积空间…...