Elasticsearch:painless script 语法基础和实战
摘要:Elasticsearch,Java
script的作用
script是Elasticsearch的拓展功能,通过定制的表达式实现已经预设好的API无法完成的个性化需求,比如完成以下操作
- 字段再加工/统计输出
- 字段之间逻辑运算
- 定义查询得分的计算公式
- 定义特殊过滤条件完成搜索
- 类似于pandas的个性化增删改操作
内容概述
- (1)script格式说明,inline和stored脚本的调用方法
- (2)在无新增文档的情况下,对现有文档的字段个性化字段更新(
update,_update_by_query,ctx._source,Math,数组add/remove) - (3)在不修改文档的情况下,在搜索返回中添加个性化统计字段(
_search,doc,script_fields,return) - (4)在无新增文档的情况下,对现有文档的字段进行新增和删除(
ctx._source,ctx._source.remove,条件判断) - (5)在无新增文档的情况下,基于现有的多个字段生成新字段(加权求和,大小比较)
- (6)搜索文档时使用script脚本
- (7)其他painless语法(循环,null判断)
script格式
语法都遵循相同的模式
"script": {"lang": "...", "source" | "id": "...", "params": { ... } }
其中三要素功能如下
lang:指定编程语言,默认是painless,还有其他编程语言选项如expression等source | id: source,id二者选其一,source后面接inline脚本(就是将脚本逻辑直接放在DSL里面),id对应一个stored脚本(就是预先设置类似UDF,使用的时候根据UDF的id进行调用和传参)params:在脚本中任何有名字的参数,用params传参
inline和stored脚本快速开始
使用script脚本修改某文档的某个字段,先插入一条文档
POST /hotel/_doc/100
{"name": "苏州木棉花酒店","city": "苏州","price": 399,"start_date": "2023-01-01"
}
(1)使用inline的方式将脚本写在DSL里面
POST /hotel/_doc/100/_update
{"script": {"source": "ctx._source.price=333"}
}
注意在kibiban客户端带上_update,否则相当于覆盖整个文档,新建了一个含有script字段的文档。本例中将price字段修改为333,如果是带有单引号的'333'则修改为字符串数据,字符串还可以使用\转义
POST /hotel/_doc/100/_update
{"script": {"source": "ctx._source.price=\"333\""}
}
获取字段的方式除了使用ctx._source.字段之外,还可以ctx._source['字段']
POST /hotel/_doc/100/_update
{"script": {"source": "ctx._source['price']=333"}
}
只要inline脚本中的内容出现些许不一样就需要重新编译,因此推荐的方法是把inline中固定的部分编译一次,变量命名放在params中传参使用,这样只需要编译一次,下次使用调用缓存
POST /hotel/_doc/100/_update
{"script": {"source": "ctx._source.price=params.price","params": {"price": 334}}
}
(2)使用stored预先设置脚本的方式
这种类似于先注册UDF函数,使用PUT对_scripts传入脚本
PUT /_scripts/my_script_1
{"script": {"lang": "painless", "source": "ctx._source.price=params.price"}
}
在插入之后使用GET可以查看到对应的脚本内容
GET /_scripts/my_script_1
{"_id" : "my_script_1","found" : true,"script" : {"lang" : "painless","source" : "ctx._source.price=params.price"}
}
脚本中并没有指定params,params在调用的是有进行设置,调用的时候使用id指定my_script_1这个id即可,不再使用source
POST /hotel/_doc/100/_update
{"script": {"id": "my_script_1","params": {"price": 335}}
}
script脚本更新字段
所有update/update_by_query 脚本使用 ctx._source
(1)普通字段更新
除了上面快速开始的直接使用=赋值修改的情况,还可以对字段做数值运算,比如加减乘除开方等等
POST /hotel/_doc/100/_update
{"script": {"source": "ctx._source.price += 100"}
}
使用Math.pow对数值进行开方
POST /hotel/_doc/100/_update
{"script": {"source": "ctx._source.price=Math.pow(ctx._source.price, 2)"}
}
Math下的方法还有sqrt,log等
(2)集合字段更新
主要说明下数组类型字段的更新,使用ctx._source.字段.add/remove,先新建一个带有数组字段的文档
POST /hotel/_doc/101
{"name": "苏州大酒店","city": "苏州","tag": ["贵"]
}
使用script将tag数组字段增加元素,使用add
POST /hotel/_doc/101/_update
{"script": {"source": "ctx._source.tag.add('偏')"}
}
插入新元素后看下数据,已经成功
{"_index" : "hotel","_type" : "_doc","_id" : "101","_score" : 1.0,"_source" : {"name" : "苏州大酒店","city" : "苏州","tag" : ["贵","偏"]}
删除数组元素使用remove指定对应的索引位置即可
POST /hotel/_doc/101/_update
{"script": {"source": "ctx._source.tag.remove(0)"}
}
如果位数不足会报错类似数组越界
script脚本对字段再加工返回
此功能使用search脚本,配合script中的doc实现,整体效果类似于map操作,对所选定的文档操作返回
(1)提取日期类型的元素并返回一个自定义字段
先设置一个字段schema
POST /hotel/_doc/_mapping
{"properties": {"dt": {"type": "date", "format": "yyyy-MM-dd HH:mm:ss"}}
}
插入一条日期数据
POST /hotel/_doc/301
{"dt": "2021-01-01 13:13:13"
}
插入效果如下
{"_index" : "hotel","_type" : "_doc","_id" : "301","_score" : 1.0,"_source" : {"dt" : "2021-01-01 13:13:13"}
下面检索所有文档,提取日期的年份,使用GET+_search请求,DSL中指定script_fields的自定义字段year,给year设置script脚本
GET /hotel/_doc/_search
{"script_fields": {"year": {"script": {"source": "if (doc.dt.length != 0) {doc.dt.value.year}"}}}
}
doc的取值方式
假设有一个字段:"a": 1,那么:
- doc['a']返回的是[1],是一个数组,如果文档没有该字段,返回空数组及doc['a'].length=0
- doc['a'].value返回的是1,也就是取第一个元素。
- doc['a'].values与doc['a']表现一致,返回整个数组[1]
script_fields脚本字段
每个_search 请求的匹配(hit)可以使用 script_fields定制一些属性,一个 _search 请求能定义多于一个以上的 script field这些定制的属性通常是:
- 针对原有值的修改(比如,价钱的转换,不同的排序方法等)
- 一个崭新的及算出来的属性(比如,总和,加权,指数运算,距离测量等)
script_fields在结果中的返回是{fileds: 字段名:[]}的json格式和_source同一级
doc.dt.value获取第一个数组元素,存储数据类型为amic getter [org.elasticsearch.script.JodaComp,该类型通过year属性获得年份。查看以下返回结果,由于没有筛选条件所有文档都被返回,存在dt字段的提取年份,不存在dt字段的也会有返回值为null,由此可见_search + doc操作实际上是完成了原始文档的一个映射转换操作,并产生了一个自定义的临时字段,不会对原始索引做任何更改操作
{"_index" : "hotel","_type" : "_doc","_id" : "301","_score" : 1.0,"fields" : {"year" : [2021]}},{"_index" : "hotel","_type" : "_doc","_id" : "002","_score" : 1.0,"fields" : {"year" : [null]}},
...
如果只返回存在dt字段的,需要在DSL中增加query逻辑
GET /hotel/_doc/_search
{"query": {"exists": {"field": "dt"}},"script_fields": {"year": {"script": {"source": "doc.dt.value.year"}}}
}
(2)统计一个数组字段数组的和并且返回
插入一个数值数组字段,搜索统计返回数组的和
POST /hotel/_doc/_mapping
{"properties": {"goals" : {"type": "keyword"}}
}
插入数据
POST /_bulk
{"index": {"_index": "hotel", "_type": "_doc", "_id": "123"}}
{"name": "a酒店","city": "扬州", "goals": [1, 5, 3] }
{"index": {"_index": "hotel", "_type": "_doc", "_id": "124"}}
{"name": "b酒店","city": "杭州", "goals": [9, 5, 1] }
{"index": {"_index": "hotel", "_type": "_doc", "_id": "125"}}
{"name": "c酒店","city": "云州", "goals": [2, 7, 9] }
下面计算有goals字段的求goals的和到一个临时字段
GET /hotel/_doc/_search
{"query": {"exists": {"field": "goals"}},"script_fields": {"goals_sum": {"script": {"source": """int total =0;for (int i=0; i < doc.goals.length; i++) {total += Integer.parseInt(doc.goals[i])}return total"""}}}
}
在script中每一行结束要加分号;,使用Java语法的循环求得数组的和,每个数组元素需要使用Java语法中的Integer.parseInt解析,否则报错String类型无法转Num,查看返回
"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "123","_score" : 1.0,"fields" : {"goals_sum" : [9]}},{"_index" : "hotel","_type" : "_doc","_id" : "124","_score" : 1.0,"fields" : {"goals_sum" : [15]}},{"_index" : "hotel","_type" : "_doc","_id" : "125","_score" : 1.0,"fields" : {"goals_sum" : [18]}}
script脚本新建/删除字段
新建字段和删除字段都是update操作,使用ctx._source
(1)新建字段
对于存在dt字段的文档,新增一个字段dt_year,值为dt的年份
POST /hotel/_doc/_update_by_query
{"query": {"exists": {"field": "dt"}}, "script": {"source": "ctx._source.dt_year = ctx._source.dt.year"}
}
以上直接在source中使用ctx._source.dt_year引入一个新列,可惜直接报错
"reason": "dynamic getter [java.lang.String, year] not found
此处并没有向doc一样数据为日期类型而是字符串,因此需要引入Java解析
POST /hotel/_doc/_update_by_query
{"query": {"exists": {"field": "dt"}}, "script": {"source": """LocalDateTime time2Parse = LocalDateTime.parse(ctx._source.dt, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));ctx._source.dt_year = time2Parse.getYear()"""}
}
查看结果
{"_index" : "hotel","_type" : "_doc","_id" : "301","_score" : 1.0,"_source" : {"dt" : "2021-01-01 13:13:13","dt_year" : 2021}
}
也可以做其他操作比如获得LocalDateTime类型之后再做格式化输出
POST /hotel/_doc/_update_by_query
{"query": {"exists": {"field": "dt"}}, "script": {"source": """LocalDateTime time2Parse = LocalDateTime.parse(ctx._source.dt, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));ctx._source.dt_year = time2Parse.format(DateTimeFormatter.ofPattern("yyyy-MM-dd"))"""}
}
(2)删除字段
删除字段直接使用ctx._source.remove(\"字段名\"),可以删除单个文档,也可以update_by_query批量删除
POST /hotel/_doc/123
{"script": {"source": "ctx._source.remove(\"goals\")"}
}
POST /hotel/_doc/_update_by_query
{"query": {"exists": {"field": "goals"}},"script": {"source": "ctx._source.remove(\"goals\")"}
}
script脚本条件判断
支持if,else if,else,比如根据某值进行二值判断生成新字段
POST /hotel/_doc/_update_by_query
{"query": {"exists": {"field": "price"}},"script": {"source": """double price = ctx._source.price;if (price >= 10) {ctx._source.expensive = 1} else {ctx._source.expensive = 0}"""}
}
POST /hotel/_doc/_update_by_query
{"query": {"exists": {"field": "price"}},"script": {"source": """double price = ctx._source.price;if (price >= 10) {ctx._source.expensive = 1} else if (price == 0) {ctx._source.expensive = -1} else {ctx._source.expensive = 0}"""}
}
注意:经过多轮测试如果source中有多轮if判断语法会报错,貌似只能支持一个if,解决方案是使用Java的三元表达式
?;,三元表达式写多少个判断都行
script使用return
return用在_search操作中,配合script_fields使用,例如在搜索结果中新增一个字段area为china,此字段不更新到索引只是在搜索时返回
GET /hotel/_doc/_search
{"_source": true,"script_fields": {"area": {"script": {"source": "return \"china\""}}}
}
以上指定"_source": true防止被script_fields覆盖,一条输出结果如下
{"_index" : "hotel","_type" : "_doc","_id" : "123","_score" : 1.0,"_source" : {"city" : "扬州","name" : "a酒店"},"fields" : {"area" : ["china"]}
script多个字段组合/逻辑判断
(1)多个字段加权求和
先插入3个子模型分,在生成一个总分,权重是0.6,0.2,0.2
POST /_bulk
{"index": {"_index": "hotel", "_type": "_doc", "_id": "333"}}
{"name": "K酒店","city": "扬州", "model_1": 0.79, "model_2": 0.39, "model_3": 0.72}
{"index": {"_index": "hotel", "_type": "_doc", "_id": "334"}}
{"name": "L酒店","city": "江州", "model_1": 0.62, "model_2": 0.55, "model_3": 0.89}
{"index": {"_index": "hotel", "_type": "_doc", "_id": "335"}}
{"name": "S酒店","city": "兖州", "model_1": 0.83, "model_2": 0.45, "model_3": 0.58}
现在计算总分给到score字段
POST /hotel/_doc/_update_by_query
{"query": {"bool": {"must": [{"exists": {"field": "model_1"}},{"exists": {"field": "model_2"}},{"exists": {"field": "model_3"}}]}},"script": {"source": "ctx._source.score = 0.6 * ctx._source.model_1 + 0.2 * ctx._source.model_2 + 0.2 * ctx._source.model_3" }
}
看一下运行结果
GET /hotel/_doc/_search
{"query": {"exists": {"field": "score"}}
}
"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "335","_score" : 1.0,"_source" : {"score" : 0.704,"city" : "兖州","name" : "S酒店","model_1" : 0.83,"model_3" : 0.58,"model_2" : 0.45}},{"_index" : "hotel","_type" : "_doc","_id" : "333","_score" : 1.0,"_source" : {"score" : 0.6960000000000001,"city" : "扬州","name" : "K酒店","model_1" : 0.79,"model_3" : 0.72,"model_2" : 0.39}},...
(2)两个字段大小比较
直接取ctx._source对应字段进行比较,使用Java三元表达式?:赋值给新字段
POST /hotel/_doc/_update_by_query
{"query": {"bool": {"must": [{"exists": {"field": "model_1"}},{"exists": {"field": "model_2"}}]}},"script": {"source": "ctx._source.max_score = ctx._source.model_1 > ctx._source.model_2 ? ctx._source.model_1 : ctx._source.model_2" }
}
script脚本null判断
有两种情况字段为null和params为null
(1)字段为null
如果某字段为空,文档不存在该字段,则填充为0
POST /hotel/_doc/_update_by_query
{"script": {"source": "if (ctx._source.score == null) ctx._source.score = 0.0"}
}
(2)params传参为null
如果传入params不存在某个key,则删除该字段
POST /hotel/_doc/_update_by_query
{"script": {"source": """String[] cols = new String[3];cols[0] = "name";cols[1] = "city";cols[2] = "price";for (String c : cols) {if (params[c] == null) {ctx._source.remove(c)} else {ctx._source[c] = params[c]}}""","params": {"name": "test","city": "test_loc"}}
}
注意:在循环中拿到局部变量c传递给params,
params[c]不能用点.或者带有双引号params["c"],否则是判断params中是否有c这个名字的字段
在本例中使用String[] cols = new String[3];创建了一个静态变量,对于这种集合类的变量painless的语法和Java略有不同,写几个例子如下
ArrayList l = new ArrayList(); // Declare an ArrayList variable l and set it to a newly allocated ArrayList
Map m = new HashMap(); // Declare a Map variable m and set it to a newly allocated HashMapList l = new ArrayList(); // Declare List variable l and set it a newly allocated ArrayList
List m; // Declare List variable m and set it the default value null
int[] ia1; //Declare int[] ia1; store default null to ia1
int[] ia2 = new int[2]; //Allocate 1-d int array instance with length [2] → 1-d int array reference; store 1-d int array reference to ia1
ia2[0] = 1; //Load from ia1 → 1-d int array reference; store int 1 to index [0] of 1-d int array reference
int[][] ic2 = new int[2][5]; //Declare int[][] ic2; allocate 2-d int array instance with length [2, 5] → 2-d int array reference; store 2-d int array reference to ic2
ic2[1][3] = 2; //Load from ic2 → 2-d int array reference; store int 2 to index [1, 3] of 2-d int array reference
ic2[0] = ia1; //Load from ia1 → 1-d int array reference; load from ic2 → 2-d int array reference; store 1-d int array reference to index [0] of 2-d int array reference; (note ia1, ib1, and index [0] of ia2 refer to the same instance)
List,Map这些集合都没有泛型,并且集合的值貌似不能直接初始化,需要add,put进来
script作为查询过滤条件
查看某列的值大于某列,在query下可以使用script,注意格式script下还套着一个script,search请求使用doc获取值
GET /hotel/_doc/_search
{"query": {"script" : {"script" : {"source": "doc.score.value < doc.model_3.value"}}}}
以上语句会报warn,doc选取字段如果字段为空会填充默认值,因此再限制一下字段不为空
GET /hotel/_doc/_search
{"query": {"bool" : {"must" : [{"script" : {"script" : {"source": "doc.score.value < doc.model_3.value"}}},{"exists": {"field": "score"}}, {"exists": {"field": "model_3"}}]}}
}
作者:xiaogp
链接:https://www.jianshu.com/p/66a72d7ba3da
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
相关文章:

Elasticsearch:painless script 语法基础和实战
摘要:Elasticsearch,Java script的作用 script是Elasticsearch的拓展功能,通过定制的表达式实现已经预设好的API无法完成的个性化需求,比如完成以下操作 字段再加工/统计输出字段之间逻辑运算定义查询得分的计算公式定义特殊过…...

《数据结构、算法与应用C++语言描述》使用C++语言实现数组双端队列
《数据结构、算法与应用C语言描述》使用C语言实现数组双端队列 定义 队列的定义 队列(queue)是一个线性表,其插入和删除操作分别在表的不同端进行。插入元素的那一端称为队尾(back或rear),删除元素的那一…...

TikTok Shop新结算政策:卖家选择权加强,电商市场蓄势待发
据悉,从2023年11月1日开始,TikTok Shop将根据卖家的店铺表现来应用3种不同类型的结算期,其中,标准结算期:资金交收期为8个日历日;快速结算期:资金交收期为3个日历日;延长结算期&…...
asp.net特色商品购物网站系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net特色商品购物网站系统 是一套完善的web设计管理系统,系统采用mvc模式(BLLDALENTITY)系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 vs2010,数据库为sqlserver2008&a…...
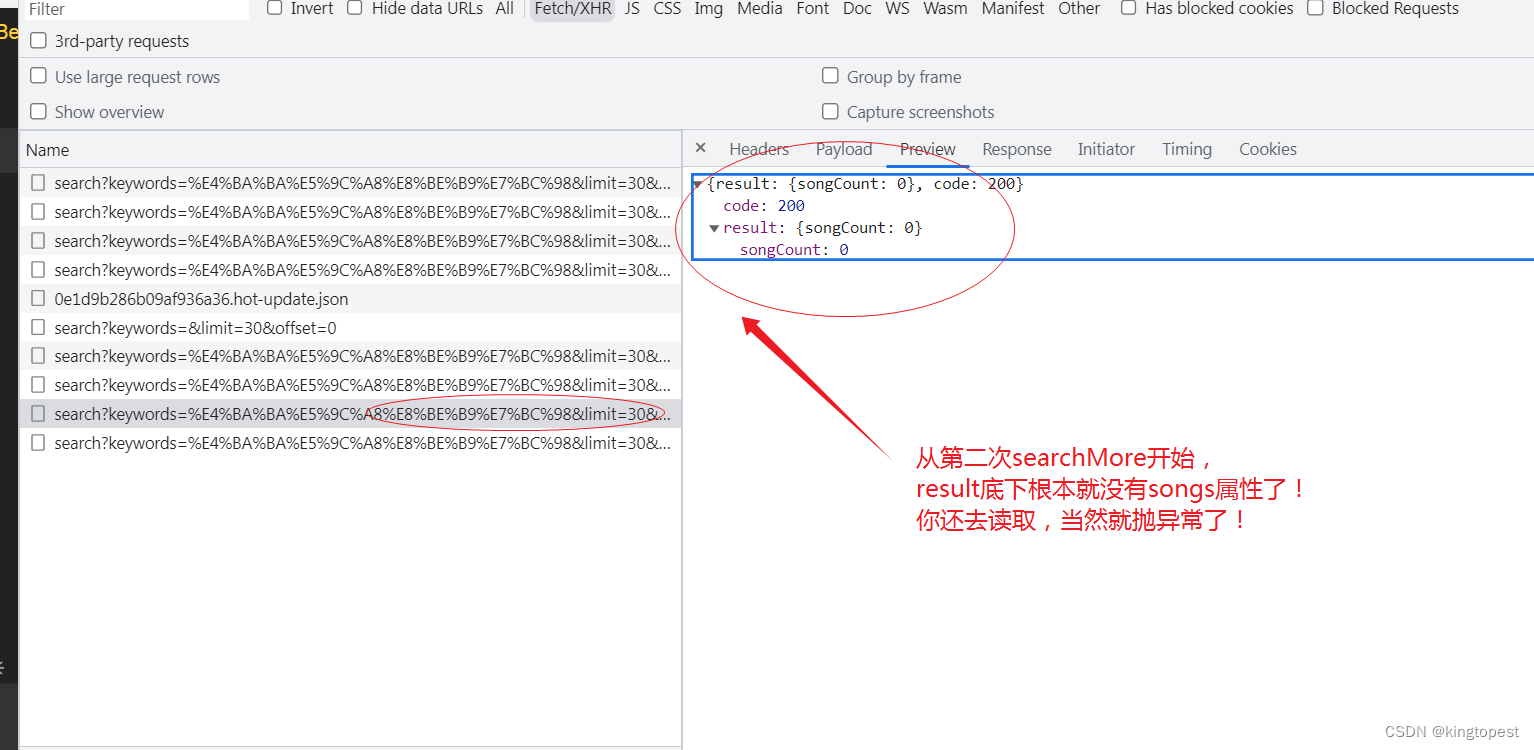
解决一则诡异的javascript函数不执行的问题
有个vue 音乐播放器项目,由于之前腾讯的搜索接口没法用了,于是改成了别家的搜索接口。 但是由于返回数据结构不一样,代码重构的工作量还是挺大的:包括数据请求,数据处理,dom渲染,处理逻辑都进行…...

汽车安全的未来:毫米波雷达在碰撞避免系统中的角色
随着科技的飞速发展,汽车安全系统变得愈加智能化,而毫米波雷达技术正是这一领域的亮点之一。本文将深入探讨毫米波雷达在汽车碰撞避免系统中的关键角色,以及其对未来汽车安全的影响。 随着城市交通的拥堵和驾驶环境的变化,汽车安全…...

体感互动游戏研发虚拟场景3D漫游
体感互动游戏是一种结合虚拟现实(VR)或增强现实(AR)技术的游戏,允许玩家以身体动作和姿势来与游戏互动。这种类型的游戏通常需要特殊的硬件设备,例如体感控制器、摄像头或传感器,以捕捉玩家的动…...
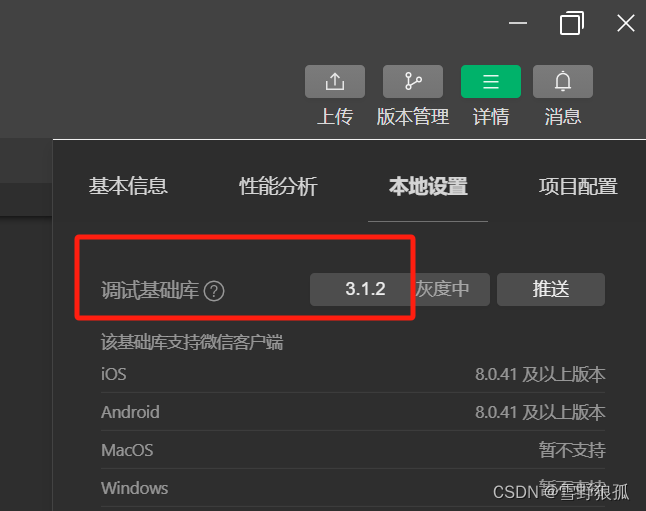
微信小程序获取手机号(2023年10月 python版)[无需订阅]
技术栈: 1. 微信开发者工具中的调试基础库版本:3.1.2。 2. 后台:django。 步骤: 1. 首先在后台django项目的定时任务中增加一个下载access_token函数,并把得到的access_token保存在数据库中(其实随便哪里…...

Linux下设置网关以及网络相关命令
一、临时设置网关 查看当前路由表:route -n设置网关:route add default gw <路由器的网关IP> 注意:系统重启时,这些更改将不生效 二、永久设置网关 列出可用网络连接:nmcli connection show设置网关&#x…...

linux三剑客~sed命令的使用
1.工作原理: sed是一种流编辑器,它是文本处理中非常有用的工具 能够完美的配合正则表达式使用,处理时,把当前处理的行存储在临时缓冲区中,称为模式空间,接着用sed命令处理缓冲区中的内容 处理完成后&…...
virtualBox虚拟机安装多个+主机访问虚拟机+虚拟机访问外网配置
目的:本机安装3个虚拟机 一、虚拟机安装:Oracle VM VirtualBox (https://www.virtualbox.org/)源代码可下载,且免费使用 1、https://www.virtualbox.org/ 进入网站中Download 模块选择与自己电脑系统相应的下载包下载即可 如果安装过程报错如…...

正点原子嵌入式linux驱动开发——Linux按键输入
在前几篇笔记之中都是使用的GPIO输出功能,还没有用过GPIO输入功能,本章就来学习一下如果在Linux下编写GPIO输入驱动程序。正点原子STM32MP1开发板上有三个按键,就使用这些按键来完成GPIO输入驱动程序,同时利用原子操作来对按键值进…...

java--强制类型转换
类型范围大的数据或者变量,直接赋值给小范围的变量,会报错 1.强制类型转换 强行将类型范围大的变量、数据赋值给类型范围小的变量 2.强制类型转换在计算机中的执行原理 解释说明1:a是int类型有8个字节32位,然后在执行下一行代码…...

java后端调用接口Basic auth认证
该方法接收一个JSON字符串参数phoneNum 内容: {"phone":"13712312312"} 然后解析参数中的手机号,作为data去调用URL接口,接收接口返回的复合JSON并解析,拿到想要的数据public String queryUserResumeURLIn…...

App爬虫之强大的Airtest的操作总结
App爬虫之强大的Airtest的操作总结 App爬虫之强大的Airtest的操作总结 # Python使用该框架需要安装的依赖库 pip install airtest pip install poco pip install pocouifrom airtest.core.api import * from airtest.cli.parser import cli_setup from poco.drivers.android.…...
MODBUS-TCP转MODBUS-RTU通信应用(S7-1200和串口服务器通信)
在学习本博客之前,大家需要熟悉MODBUS-TCP和MODBUS-RTU通信,这2个通信的编程应用,大家可以查看下面文章链接: MODBUS-RTU通信 MODBUS-RTU通信协议功能码+数据帧解读(博途PLC梯形图代码)-CSDN博客MODBUS通信详细代码编写,请查看下面相关链接,这篇博客主要和大家介绍MODB…...

开源贡献难吗?
本文整理自字节跳动 Flink SQL 技术负责人李本超在 CommunityOverCode Asia 2023 上的 Keynote 演讲,李本超根据自己在开源社区的贡献经历,基于他在贡献开源社区过程中的一些小故事和思考,如何克服困难,在开源社区取得突破&#x…...

seata的TCC模式分析
TCC是 Try- Confirm-Cancel 这3个名词的首字母简称,是一个2阶段提交的变体思路。 Try:对资源的检查和预留; Confirm: 确认对预留资源的消耗,执行业务操作; Cancel:预留资源的释放; TCC的事务…...

常用linux命令【主要用于日志查询,目录切换】
Xshell设置登录 :主机,端口号 用户身份验证:账号/密码登录脚本:等待-[hcuserserver02 ]$ 发送-cd /data/logs/pl-capital-processer-server/$(date “%Y-%m-%d”) 下方-添加按钮/编辑 发送文本,追加 grep --color de…...

Python学习基础笔记七十六——Python装饰器2
装饰器,英文名字decorator。 我们开发Python代码的时候,经常碰到装饰器。 通常被装饰后的函数,会在原来的函数的基础上,增加一些功能。 通常装饰器本事也是一个函数,那么装饰器是怎么装饰另外一个函数的呢?…...
)
PHP+MySQL图书管理系统实战:从环境搭建到功能实现的保姆级教程(附完整源码)
PHPMySQL图书管理系统实战:从零构建企业级应用 1. 环境配置与项目初始化 在开始构建图书管理系统之前,我们需要搭建一个稳定的开发环境。不同于传统的独立安装方式,我将推荐使用Docker容器化方案,这能确保开发环境的一致性并避免&…...
)
伯克利Octo机器人框架实战:5步搞定跨平台任务迁移(附代码)
伯克利Octo机器人框架实战:5步搞定跨平台任务迁移(附代码) 在机器人开发领域,硬件平台的多样性一直是阻碍算法快速部署的主要瓶颈。想象一下,你花费数月为WidowX机械臂开发的抓取算法,当实验室新购入UR5工业…...

Phi-4-mini-reasoning效果展示:同参数量级中推理准确率超Llama3-8B实测对比
Phi-4-mini-reasoning效果展示:同参数量级中推理准确率超Llama3-8B实测对比 1. 开篇亮点:小模型的大智慧 Phi-4-mini-reasoning这款仅有3.8B参数的轻量级开源模型,正在重新定义我们对小模型能力的认知。作为专为数学推理、逻辑推导和多步解…...

终极指南:如何在NixOS上完美打包与使用SilentSDDM主题
终极指南:如何在NixOS上完美打包与使用SilentSDDM主题 【免费下载链接】SilentSDDM A very customizable SDDM theme that actually looks good. 项目地址: https://gitcode.com/gh_mirrors/si/SilentSDDM SilentSDDM是一款高度可定制且视觉精美的SDDM登录主…...

能做表格的 AI 软件:Excel-Agent,AI 原生重构表格数据分析全流程
当传统 Excel 被卡顿、复杂公式、海量数据难处理、手动重复操作困住时,能做表格的 AI 软件正成为效率破局关键 —— 而 Excel-Agent,正是专为 Excel 场景打造的 AI 数据智能体,以自然语言交互、本地高效计算、全链路数据处理能力,…...

嵌入式轻量级任务调度框架cola_os解析与实践
1. 嵌入式轻量级任务调度框架cola_os深度解析在嵌入式开发中,我们经常面临一个经典困境:对于功能简单、实时性要求不高的多任务场景,使用完整的RTOS显得过于臃肿,而裸机轮询又难以维护。今天要介绍的cola_os正是为解决这个问题而生…...

GCN在推荐系统中的应用:如何用图神经网络提升电商个性化推荐效果
GCN在电商推荐系统中的实战指南:从二部图构建到A/B测试全流程 当你在电商平台浏览商品时,那些"猜你喜欢"的推荐背后,可能正运行着一套基于图神经网络(GCN)的复杂算法系统。与传统的协同过滤不同,GCN能够捕捉用户-商品交…...

轻量级PDF阅读器SumatraPDF核心功能与效率提升指南
轻量级PDF阅读器SumatraPDF核心功能与效率提升指南 【免费下载链接】sumatrapdf SumatraPDF reader 项目地址: https://gitcode.com/gh_mirrors/su/sumatrapdf 在数字文档处理领域,速度与资源占用往往难以平衡。SumatraPDF以其独特的轻量级设计,重…...

FastMind:比 LangGraph 更轻量的 Python Agent 框架
在 AI Agent 开发领域,LangGraph 是一个知名的框架,但如果你正在寻找一个更轻量、更简洁、更适合快速开发的替代方案,那么 FastMind 值得你关注。 项目定位 LangGraph 定位: 企业级 Agent 开发框架特点: 功能全面,支持复杂工作流复…...

汇川小型机 H5U编写程序 设备采用回转hu小型机编写程序不含的硬件配置有ECT的总线
汇川小型机 H5U编写程序 设备采用回转hu小型机编写程序不含的硬件配置有ECT的总线,包括汇川660系列伺服驱动器以及Io模块。 设备程序分段明确采用梯形图编写更加方便,直观,易懂各个伺服轴密切配合,实现收放卷pid调节,以…...