LeetCode-高频 SQL 50 题:连接 篇
目录
1378. 使用唯一标识码替换员工ID
题目描述:
SQL语句:
1068. 产品销售分析 I
题目描述:
SQL语句:
1581. 进店却未进行过交易的顾客
题目描述:
SQL语句:
197. 上升的温度
题目描述:
SQL语句:
1661. 每台机器的进程平均运行时间
题目描述:
SQL语句:
577. 员工奖金
题目描述:
SQL语句:
1280. 学生们参加各科测试的次数
题目描述:
SQL语句:
570. 至少有5名直接下属的经理
题目描述:
SQL语句:
1934. 确认率
SQL语句:
1378. 使用唯一标识码替换员工ID
题目描述:
Employees 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | name | varchar | +---------------+---------+ 在 SQL 中,id 是这张表的主键。 这张表的每一行分别代表了某公司其中一位员工的名字和 ID 。
EmployeeUNI 表:
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | unique_id | int | +---------------+---------+ 在 SQL 中,(id, unique_id) 是这张表的主键。 这张表的每一行包含了该公司某位员工的 ID 和他的唯一标识码(unique ID)。
展示每位用户的 唯一标识码(unique ID );如果某位员工没有唯一标识码,使用 null 填充即可。
你可以以 任意 顺序返回结果表。
返回结果的格式如下例所示。
示例 1:
输入: Employees表: +----+----------+ | id | name | +----+----------+ | 1 | Alice | | 7 | Bob | | 11 | Meir | | 90 | Winston | | 3 | Jonathan | +----+----------+EmployeeUNI表: +----+-----------+ | id | unique_id | +----+-----------+ | 3 | 1 | | 11 | 2 | | 90 | 3 | +----+-----------+ 输出: +-----------+----------+ | unique_id | name | +-----------+----------+ | null | Alice | | null | Bob | | 2 | Meir | | 3 | Winston | | 1 | Jonathan | +-----------+----------+ 解释: Alice and Bob 没有唯一标识码, 因此我们使用 null 替代。 Meir 的唯一标识码是 2 。 Winston 的唯一标识码是 3 。 Jonathan 唯一标识码是 1 。
SQL语句:
# Write your MySQL query statement below
SELECTEmployeeUNI.unique_id, Employees.name
FROMEmployees
LEFT JOIN EmployeeUNI
ONEmployees.id = EmployeeUNI.id
;1068. 产品销售分析 I
题目描述:
销售表 Sales:
+-------------+-------+ | Column Name | Type | +-------------+-------+ | sale_id | int | | product_id | int | | year | int | | quantity | int | | price | int | +-------------+-------+ (sale_id, year) 是销售表 Sales 的主键(具有唯一值的列的组合)。 product_id 是关联到产品表 Product 的外键(reference 列)。 该表的每一行显示 product_id 在某一年的销售情况。 注意: price 表示每单位价格。
产品表 Product:
+--------------+---------+ | Column Name | Type | +--------------+---------+ | product_id | int | | product_name | varchar | +--------------+---------+ product_id 是表的主键(具有唯一值的列)。 该表的每一行表示每种产品的产品名称。
编写解决方案,以获取 Sales 表中所有 sale_id 对应的 product_name 以及该产品的所有 year 和 price 。
返回结果表 无顺序要求 。
结果格式示例如下。
示例 1:
输入:
Sales 表:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product 表:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
输出:
+--------------+-------+-------+
| product_name | year | price |
+--------------+-------+-------+
| Nokia | 2008 | 5000 |
| Nokia | 2009 | 5000 |
| Apple | 2011 | 9000 |
+--------------+-------+-------+SQL语句:
# Write your MySQL query statement below
SELECTProduct.product_name,Sales.year, Sales.price
FROMSales,Product
WHERE Sales.product_id = Product. product_id
;1581. 进店却未进行过交易的顾客
题目描述:
表:Visits
+-------------+---------+ | Column Name | Type | +-------------+---------+ | visit_id | int | | customer_id | int | +-------------+---------+ visit_id 是该表中具有唯一值的列。 该表包含有关光临过购物中心的顾客的信息。
表:Transactions
+----------------+---------+ | Column Name | Type | +----------------+---------+ | transaction_id | int | | visit_id | int | | amount | int | +----------------+---------+ transaction_id 是该表中具有唯一值的列。 此表包含 visit_id 期间进行的交易的信息。
有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个解决方案,来查找这些顾客的 ID ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
返回结果格式如下例所示。
示例 1:
输入: Visits+----------+-------------+ | visit_id | customer_id | +----------+-------------+ | 1 | 23 | | 2 | 9 | | 4 | 30 | | 5 | 54 | | 6 | 96 | | 7 | 54 | | 8 | 54 | +----------+-------------+Transactions+----------------+----------+--------+ | transaction_id | visit_id | amount | +----------------+----------+--------+ | 2 | 5 | 310 | | 3 | 5 | 300 | | 9 | 5 | 200 | | 12 | 1 | 910 | | 13 | 2 | 970 | +----------------+----------+--------+ 输出: +-------------+----------------+ | customer_id | count_no_trans | +-------------+----------------+ | 54 | 2 | | 30 | 1 | | 96 | 1 | +-------------+----------------+ 解释: ID = 23 的顾客曾经逛过一次购物中心,并在 ID = 12 的访问期间进行了一笔交易。 ID = 9 的顾客曾经逛过一次购物中心,并在 ID = 13 的访问期间进行了一笔交易。 ID = 30 的顾客曾经去过购物中心,并且没有进行任何交易。 ID = 54 的顾客三度造访了购物中心。在 2 次访问中,他们没有进行任何交易,在 1 次访问中,他们进行了 3 次交易。 ID = 96 的顾客曾经去过购物中心,并且没有进行任何交易。 如我们所见,ID 为 30 和 96 的顾客一次没有进行任何交易就去了购物中心。顾客 54 也两次访问了购物中心并且没有进行任何交易。
SQL语句:
# Write your MySQL query statement below
SELECTcustomer_id,count(*) count_no_trans
FROMVisits
WHERE visit_id
NOT IN
(SELECT visit_idFROMTransactions
)
GROUP BYcustomer_id197. 上升的温度
题目描述:
表: Weather
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | recordDate | date | | temperature | int | +---------------+---------+ id 是该表具有唯一值的列。 该表包含特定日期的温度信息
编写解决方案,找出与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 无顺序要求 。
结果格式如下例子所示
示例 1:
输入:
Weather 表:
+----+------------+-------------+
| id | recordDate | Temperature |
+----+------------+-------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+----+------------+-------------+
输出:
+----+
| id |
+----+
| 2 |
| 4 |
+----+
解释:
2015-01-02 的温度比前一天高(10 -> 25)
2015-01-04 的温度比前一天高(20 -> 30)SQL语句:
# Write your MySQL query statement below
SELECTw1.id
FROMWeather w1,Weather w2
WHERE w1.recordDate = ADDDATE(W2.recordDate, 1)
AND w1.temperature > w2.temperature
;1661. 每台机器的进程平均运行时间
题目描述:
表: Activity
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| machine_id | int |
| process_id | int |
| activity_type | enum |
| timestamp | float |
+----------------+---------+
该表展示了一家工厂网站的用户活动。
(machine_id, process_id, activity_type) 是当前表的主键(具有唯一值的列的组合)。
machine_id 是一台机器的ID号。
process_id 是运行在各机器上的进程ID号。
activity_type 是枚举类型 ('start', 'end')。
timestamp 是浮点类型,代表当前时间(以秒为单位)。
'start' 代表该进程在这台机器上的开始运行时间戳 , 'end' 代表该进程在这台机器上的终止运行时间戳。
同一台机器,同一个进程都有一对开始时间戳和结束时间戳,而且开始时间戳永远在结束时间戳前面。
现在有一个工厂网站由几台机器运行,每台机器上运行着 相同数量的进程 。编写解决方案,计算每台机器各自完成一个进程任务的平均耗时。
完成一个进程任务的时间指进程的'end' 时间戳 减去 'start' 时间戳。平均耗时通过计算每台机器上所有进程任务的总耗费时间除以机器上的总进程数量获得。
结果表必须包含machine_id(机器ID) 和对应的 average time(平均耗时) 别名 processing_time,且四舍五入保留3位小数。
以 任意顺序 返回表。
具体参考例子如下。
示例 1:
输入: Activity table: +------------+------------+---------------+-----------+ | machine_id | process_id | activity_type | timestamp | +------------+------------+---------------+-----------+ | 0 | 0 | start | 0.712 | | 0 | 0 | end | 1.520 | | 0 | 1 | start | 3.140 | | 0 | 1 | end | 4.120 | | 1 | 0 | start | 0.550 | | 1 | 0 | end | 1.550 | | 1 | 1 | start | 0.430 | | 1 | 1 | end | 1.420 | | 2 | 0 | start | 4.100 | | 2 | 0 | end | 4.512 | | 2 | 1 | start | 2.500 | | 2 | 1 | end | 5.000 | +------------+------------+---------------+-----------+ 输出: +------------+-----------------+ | machine_id | processing_time | +------------+-----------------+ | 0 | 0.894 | | 1 | 0.995 | | 2 | 1.456 | +------------+-----------------+ 解释: 一共有3台机器,每台机器运行着两个进程. 机器 0 的平均耗时: ((1.520 - 0.712) + (4.120 - 3.140)) / 2 = 0.894 机器 1 的平均耗时: ((1.550 - 0.550) + (1.420 - 0.430)) / 2 = 0.995 机器 2 的平均耗时: ((4.512 - 4.100) + (5.000 - 2.500)) / 2 = 1.456
SQL语句:
# Write your MySQL query statement below
SELECT a3.machine_id, ROUND(AVG(a3.process_time), 3) AS processing_time
FROM (SELECTa1.machine_id,(a2.timestamp - a1.timestamp) AS process_timeFROMActivity AS A1,Activity AS a2WHEREa1.machine_id = a2.machine_idAND a1.process_id = a2.process_idAND a1.activity_type = 'start' AND a2.activity_type = 'end'
) AS a3
GROUP BY a3.machine_id577. 员工奖金
题目描述:
表:Employee
+-------------+---------+ | Column Name | Type | +-------------+---------+ | empId | int | | name | varchar | | supervisor | int | | salary | int | +-------------+---------+ empId 是该表中具有唯一值的列。 该表的每一行都表示员工的姓名和 id,以及他们的工资和经理的 id。
表:Bonus
+-------------+------+ | Column Name | Type | +-------------+------+ | empId | int | | bonus | int | +-------------+------+ empId 是该表具有唯一值的列。 empId 是 Employee 表中 empId 的外键(reference 列)。 该表的每一行都包含一个员工的 id 和他们各自的奖金。
编写解决方案,报告每个奖金 少于 1000 的员工的姓名和奖金数额。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入: Employee table: +-------+--------+------------+--------+ | empId | name | supervisor | salary | +-------+--------+------------+--------+ | 3 | Brad | null | 4000 | | 1 | John | 3 | 1000 | | 2 | Dan | 3 | 2000 | | 4 | Thomas | 3 | 4000 | +-------+--------+------------+--------+ Bonus table: +-------+-------+ | empId | bonus | +-------+-------+ | 2 | 500 | | 4 | 2000 | +-------+-------+ 输出: +------+-------+ | name | bonus | +------+-------+ | Brad | null | | John | null | | Dan | 500 | +------+-------+
SQL语句:
# Write your MySQL query statement below
SELECT et.name,bt.bonus
FROMEmployee AS et
LEFT JOIN Bonus AS bt
ONet.empId = bt.empId
WHEREbt.bonus < 1000 ORbt.bonus is null
;1280. 学生们参加各科测试的次数
题目描述:
学生表: Students
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ 在 SQL 中,主键为 student_id(学生ID)。 该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects
+--------------+---------+ | Column Name | Type | +--------------+---------+ | subject_name | varchar | +--------------+---------+ 在 SQL 中,主键为 subject_name(科目名称)。 每一行记录学校的一门科目名称。
考试表: Examinations
+--------------+---------+ | Column Name | Type | +--------------+---------+ | student_id | int | | subject_name | varchar | +--------------+---------+ 这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。 学生表里的一个学生修读科目表里的每一门科目。 这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示。
示例 1:
输入: Students table: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | | 13 | John | | 6 | Alex | +------------+--------------+ Subjects table: +--------------+ | subject_name | +--------------+ | Math | | Physics | | Programming | +--------------+ Examinations table: +------------+--------------+ | student_id | subject_name | +------------+--------------+ | 1 | Math | | 1 | Physics | | 1 | Programming | | 2 | Programming | | 1 | Physics | | 1 | Math | | 13 | Math | | 13 | Programming | | 13 | Physics | | 2 | Math | | 1 | Math | +------------+--------------+ 输出: +------------+--------------+--------------+----------------+ | student_id | student_name | subject_name | attended_exams | +------------+--------------+--------------+----------------+ | 1 | Alice | Math | 3 | | 1 | Alice | Physics | 2 | | 1 | Alice | Programming | 1 | | 2 | Bob | Math | 1 | | 2 | Bob | Physics | 0 | | 2 | Bob | Programming | 1 | | 6 | Alex | Math | 0 | | 6 | Alex | Physics | 0 | | 6 | Alex | Programming | 0 | | 13 | John | Math | 1 | | 13 | John | Physics | 1 | | 13 | John | Programming | 1 | +------------+--------------+--------------+----------------+ 解释: 结果表需包含所有学生和所有科目(即便测试次数为0): Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试; Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试; Alex 啥测试都没参加; John 参加了数学、物理、编程测试各 1 次。
SQL语句:
# Write your MySQL query statement below
SELECT st.student_id,st.student_name,sb.subject_name,ifnull(attended_exams,0) attended_exams
FROM Students st
CROSS JOIN Subjects sb
LEFT JOIN (SELECT student_id,subject_name,count(*) attended_examsFROM ExaminationsGROUP BY student_id, subject_name) tON st.student_id = t.student_idAND sb.subject_name = t.subject_name
ORDER BY st.student_id, sb.subject_name;570. 至少有5名直接下属的经理
题目描述:
表: Employee
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | | department | varchar | | managerId | int | +-------------+---------+ 在 SQL 中,id 是该表的主键列。 该表的每一行都表示雇员的名字、他们的部门和他们的经理的id。 如果managerId为空,则该员工没有经理。 没有员工会成为自己的管理者。
查询至少有5名直接下属的经理 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入: Employee 表: +-----+-------+------------+-----------+ | id | name | department | managerId | +-----+-------+------------+-----------+ | 101 | John | A | None | | 102 | Dan | A | 101 | | 103 | James | A | 101 | | 104 | Amy | A | 101 | | 105 | Anne | A | 101 | | 106 | Ron | B | 101 | +-----+-------+------------+-----------+ 输出: +------+ | name | +------+ | John | +------+
SQL语句:
# Write your MySQL query statement below
select name from Employee e, (select count(*) cnt, managerId from Employee group by managerId) t where e.id = t.managerId and t.cnt >= 51934. 确认率
题目描述:
表: Signups
+----------------+----------+ | Column Name | Type | +----------------+----------+ | user_id | int | | time_stamp | datetime | +----------------+----------+ User_id是该表的主键。 每一行都包含ID为user_id的用户的注册时间信息。
表: Confirmations
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
| action | ENUM |
+----------------+----------+
(user_id, time_stamp)是该表的主键。
user_id是一个引用到注册表的外键。
action是类型为('confirmed', 'timeout')的ENUM
该表的每一行都表示ID为user_id的用户在time_stamp请求了一条确认消息,该确认消息要么被确认('confirmed'),要么被过期('timeout')。
用户的 确认率 是 'confirmed' 消息的数量除以请求的确认消息的总数。没有请求任何确认消息的用户的确认率为 0 。确认率四舍五入到 小数点后两位 。
编写一个SQL查询来查找每个用户的 确认率 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例1:
输入: Signups 表: +---------+---------------------+ | user_id | time_stamp | +---------+---------------------+ | 3 | 2020-03-21 10:16:13 | | 7 | 2020-01-04 13:57:59 | | 2 | 2020-07-29 23:09:44 | | 6 | 2020-12-09 10:39:37 | +---------+---------------------+ Confirmations 表: +---------+---------------------+-----------+ | user_id | time_stamp | action | +---------+---------------------+-----------+ | 3 | 2021-01-06 03:30:46 | timeout | | 3 | 2021-07-14 14:00:00 | timeout | | 7 | 2021-06-12 11:57:29 | confirmed | | 7 | 2021-06-13 12:58:28 | confirmed | | 7 | 2021-06-14 13:59:27 | confirmed | | 2 | 2021-01-22 00:00:00 | confirmed | | 2 | 2021-02-28 23:59:59 | timeout | +---------+---------------------+-----------+ 输出: +---------+-------------------+ | user_id | confirmation_rate | +---------+-------------------+ | 6 | 0.00 | | 3 | 0.00 | | 7 | 1.00 | | 2 | 0.50 | +---------+-------------------+ 解释: 用户 6 没有请求任何确认消息。确认率为 0。 用户 3 进行了 2 次请求,都超时了。确认率为 0。 用户 7 提出了 3 个请求,所有请求都得到了确认。确认率为 1。 用户 2 做了 2 个请求,其中一个被确认,另一个超时。确认率为 1 / 2 = 0.5。
SQL语句:
# Write your MySQL query statement below
SELECTuser_id,round(avg(if(action = 'confirmed', 1, 0)), 2) confirmation_rate
FROM(SELECTs.user_id,c.actionFROMSignups sLEFT JOIN Confirmations c ON s.user_id = c.user_id) t
GROUP BYuser_id相关文章:

LeetCode-高频 SQL 50 题:连接 篇
目录 1378. 使用唯一标识码替换员工ID 题目描述: SQL语句: 1068. 产品销售分析 I 题目描述: SQL语句: 1581. 进店却未进行过交易的顾客 题目描述: SQL语句: 197. 上升的温度 题目描述࿱…...
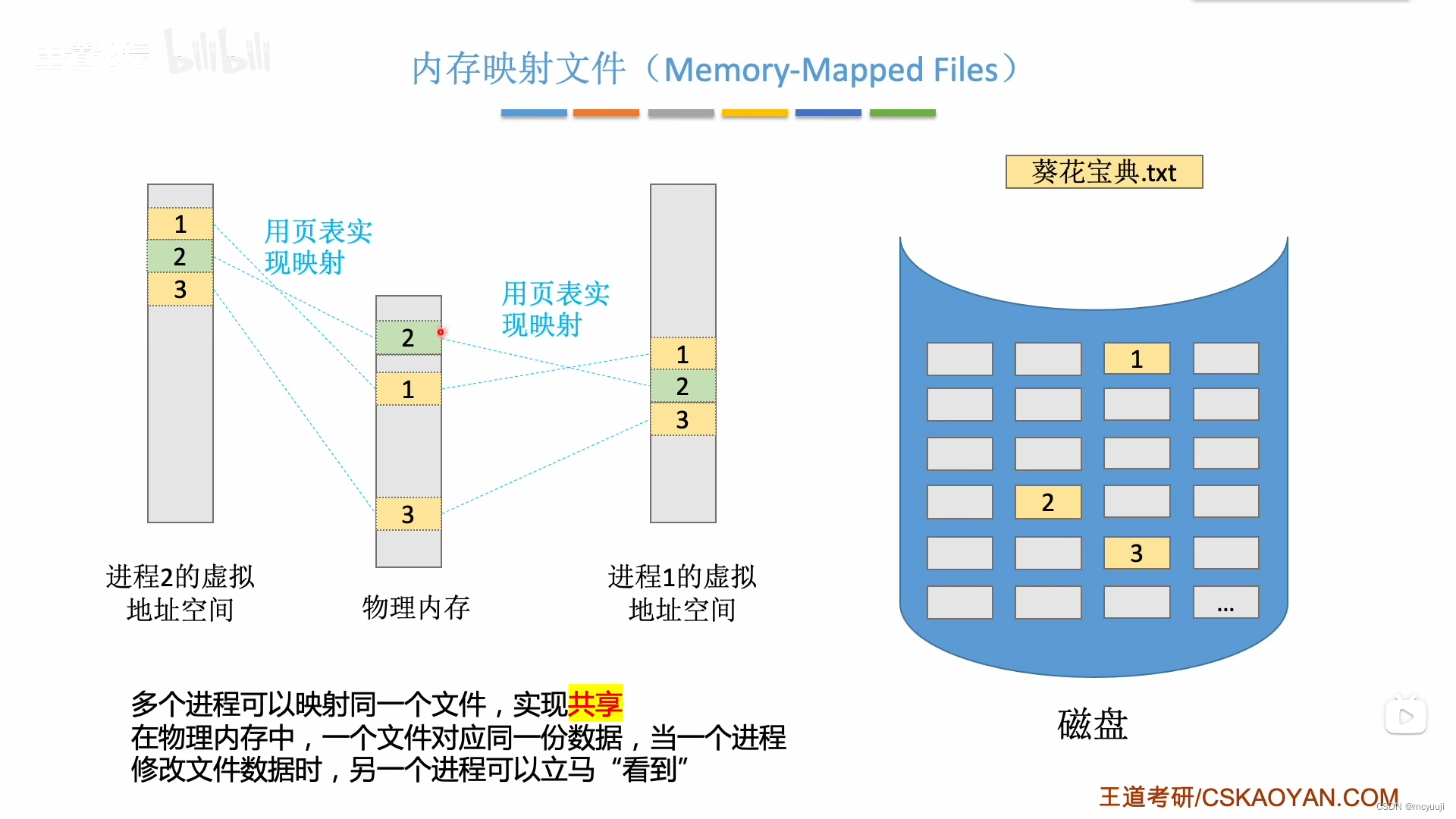
操作系统备考学习 day10
操作系统备考学习 day10 第三章 内存管理3.2 虚拟内存管理3.2.1 虚拟内存的基本概念传统存储管理方式的特征、缺点局部性原理虚拟内存的定义和特征如何实现虚拟内存技术 3.2.2 请求分页管理方式页表机制缺页中断机构地址变换机构 3.2.3 页面置换算法最佳置换算法(OP…...

基于侏儒猫鼬优化的BP神经网络(分类应用) - 附代码
基于侏儒猫鼬优化的BP神经网络(分类应用) - 附代码 文章目录 基于侏儒猫鼬优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.侏儒猫鼬优化BP神经网络3.1 BP神经网络参数设置3.2 侏儒猫鼬算法应用 4.测试结果…...

ios safari 正则兼容问题
背景: 系统是自己开发的采购管理系统; 最近升级系统之后客户反馈部分苹果手机现在在进入单据界面的时候报错, 内容显示不全; 安卓手机正常; 苹果首页是之前有使用过系统的才不行, 如果是之前没有使用过系统, 现在也是可以(后面查证这一点可能不是很准确, 跟是否等过过系统…...
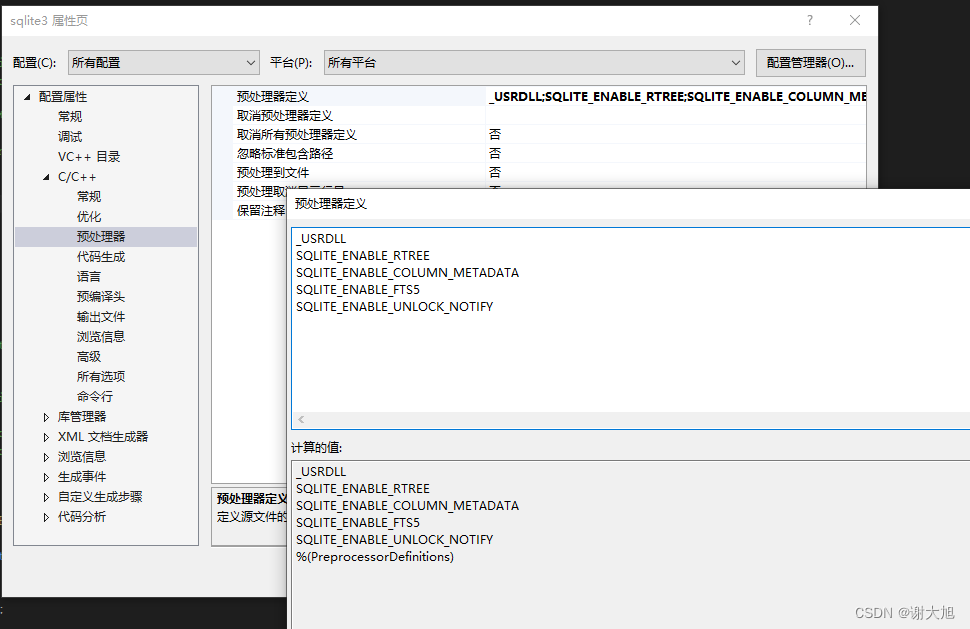
Win10下基于VS2015编译SQLite3源码
一、下载SQLite SQLite SQLite Download Page 下载红框部分的3个文件 提示:这里有个 sglite-autoconf-3420000.tar.gz 是免编译版,想省事就下载这个,但我自己用这个老是编译不过 所以我这里不推荐这个了 二、配置SQLite 打开vs 2015或者其他…...

Linux 指令学习
Linux 指令学习 以此为记录,也方便自己日后查看回顾! Linux命令基础格式 无论是什么命令,用于什么用途,在Linux中,命令有其通用的格式: command: 命令本身 options:[可选…...

前端渲染后端返回的HTML格式的数据
在日常开发中,经常有需要前端渲染后端返回页面的需求,对于不同数据结构,前端的渲染方式也不尽相同,本文旨在对各种情况进行总结。 后端返回纯html文件格式 数据包含html标签等元素,数据类型如下图: 前端通…...
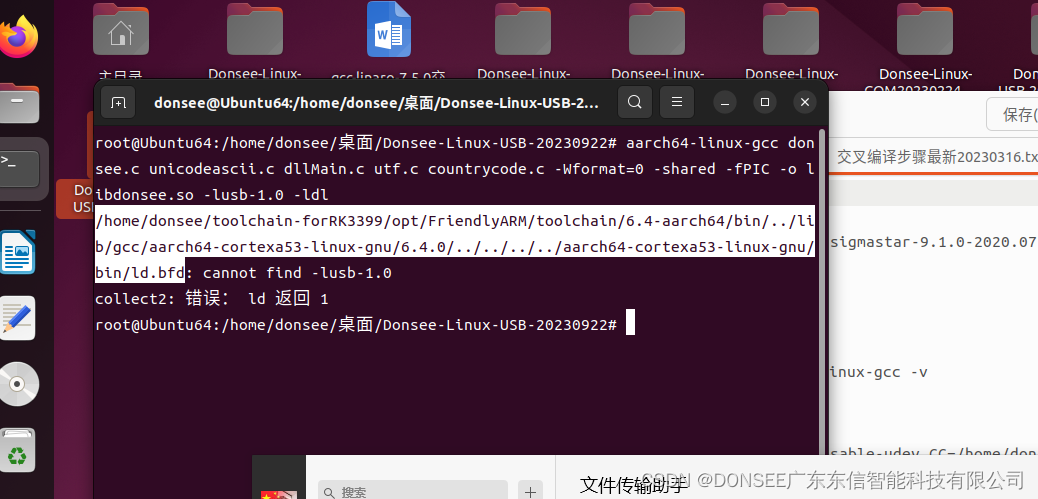
身份证读卡器ubuntu虚拟机实现RK3399 Arm Linux开发板交叉编译libdonsee.so找不到libusb解决办法
昨天一个客户要在RK3399 Linux开发板上面使用身份证读卡器,由于没有客户的开发板,故只能用本机ubuntu虚拟机来交叉编译,用客户发过来的交叉编译工具,已经编译好libusb然后编译libdonsee.so的时候提示找不到libusb,报错…...

触想五代强固型工业一体机在近海船舶上的应用
1、行业发展背景 近海船舶的发展紧密关联着海上运输、渔业贸易、旅游开发、能源探测等多领域,带动区域经济、文化繁荣发展。 随着现代科学与信息技术在各行各业的作用增强,工业4.0带动的产业升级逐步渗透进船舶领域,在此背景下,船…...

Node-创建Web应用
题记 node创建web应用,以下是所有流程和代码 与php比较:使用 PHP 来编写后端的代码,需要 Apache 或者 Nginx 的 HTTP 服务器,并配上 mod_php5 模块和 php-cgi。 Node应用的组成 node应用由三部分组成: require 指令&a…...

Redis查找并删除key
redis安装在IP为x.x.x.x的服务器上 redis安装 第一步,安装编译工具及库文件。 命令:yum -y install make zlib zlib-devel gcc-c libtool openssl openssl-devel 第二步,下载redis安装包。 命令:cd /usr/local/src wget ht…...
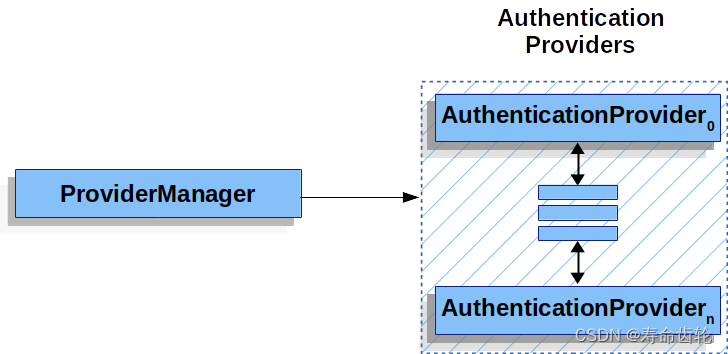
Spring Security认证架构介绍
在之前的Spring Security:总体架构中,我们讲到Spring Security整个架构是通过Bean容器和Servlet容器对过滤器的支持来实现的。我们将从过滤器出发介绍Spring Security的Servlet类型的认证架构。 1.AbstractAuthenticationProcessingFilter AbstractAut…...

提升代码重用性:模板设计模式在实际项目中的应用
在软件开发中,我们经常面临着相似的问题,需要使用相同的解决方法。当我们希望将这种通用的解决方法抽象出来,并在不同的情境中重复使用时,就可以使用设计模式中的模板模式(Template Pattern)。模板模式是一…...

11-k8s-service网络
文章目录 一、网络相关资源介绍二、开启ipvs三、nginx网络示例四、pod之间的访问示例五、service反向代理示例 一、网络相关资源介绍 Servcie介绍 Service是对一组提供相同功能的Pods的抽象,并为它们提供一个统一的入口。借助Service,应用可以方便的实现…...
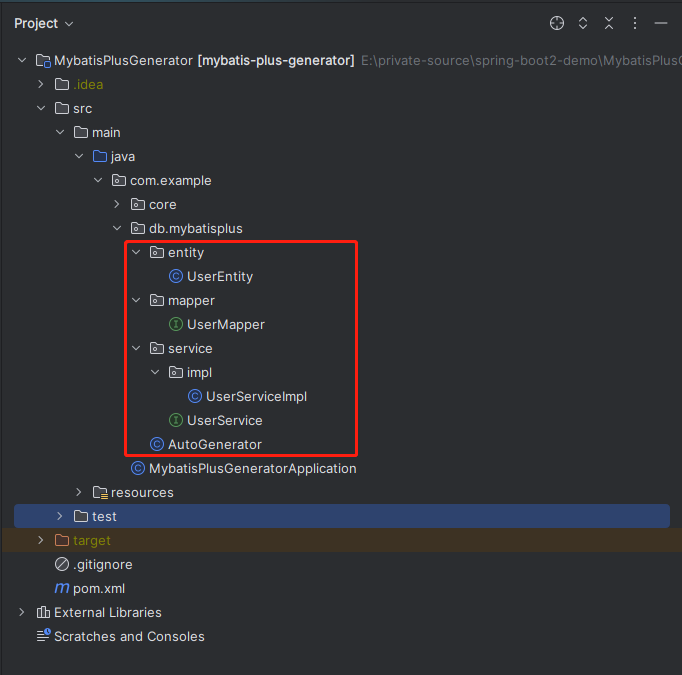
MyBatisPlus(二十二)代码生成器
使用场景 使用代码生成器,根据数据库表,自动生成对应的 Entity,Mapper,Service,Controller 。 代码 依赖 两个依赖: 生成器依赖模板依赖 <dependency><groupId>com.baomidou</groupId&…...

git报错The project you were looking for could not be found 解决方式
问题描述: 使用git从远程仓库克隆项目到本地的时候。 git clone http://gitlab.com/project/xxxx.git出现这个问题:The project you were looking for could not be found. 原因分析: 你的账号没有项目的权限,你可以在浏览器输…...
“编辑微信小程序与后台数据交互与微信小程序wxs的使用“
引言 在现代移动应用开发中,微信小程序已经成为了一个非常流行和广泛使用的平台。为了使小程序能够展示丰富的内容和实现复杂的功能,与后台数据的交互是至关重要的。同时,微信小程序还提供了一种特殊的脚本语言——wxs,用于增强小…...

从Linux的tty_struct指针获取驱动上下文
背景 问题 前段时间开发一个tty驱动,用途是实现仪器对GPIB消息的接收、处理和上报。对于上报场景,下位机应用将上报内容写入一个驱动创建的tty设备,tty子系统将应用的输入转发给tty驱动,tty驱动将其转换成对SPI从设备࿰…...
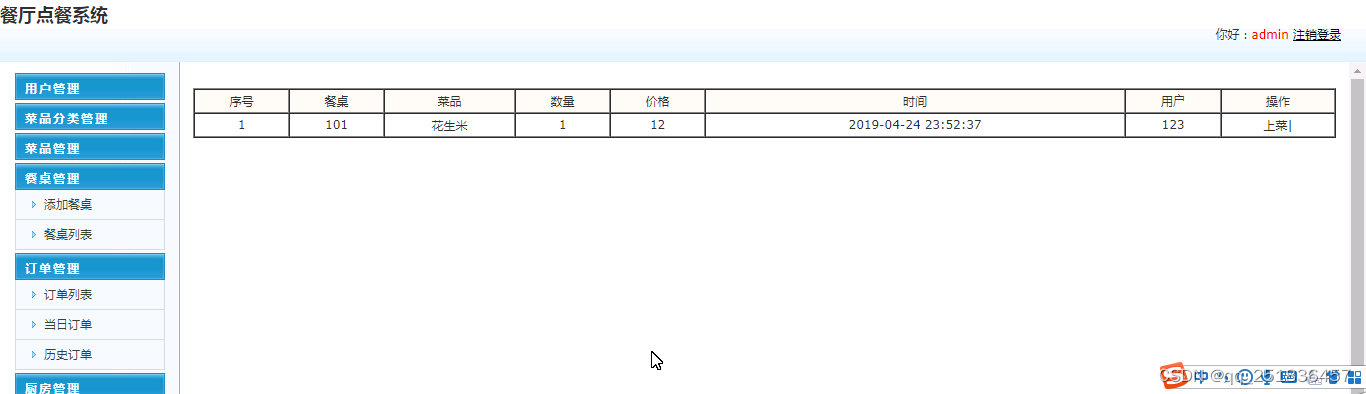
PHP WAP餐厅点餐系统mysql数据库web结构apache计算机软件工程网页wamp
一、源码特点 PHP餐厅点餐系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 PHP WAP餐厅点餐系统 代码 https://download.csdn.net/download/qq_41221322/88440001 二、…...

智慧公厕改变城市生活,厕所革命标杆应用解决方案
随着城市化进程的加快,公厕作为城市基础设施的重要组成部分,扮演着不可忽视的角色。然而,传统的公厕粗放型管理模式,已经无法满足市民日益增长的需求。为了提升公厕的管理和服务水平,智慧公厕应运而生。 什么是智慧公…...

Docker 27车载部署必踩的9个坑,第7个导致某头部智驾平台批量召回ECU固件更新
第一章:Docker 27车载部署容器稳定性综述Docker 27(即 Docker v27.x 系列)作为面向边缘与车载场景深度优化的发行版,显著增强了容器在资源受限、网络波动、电源中断频发等车规级环境下的运行韧性。其内核调度器适配了 Linux CFS 的…...

告别javax.servlet:SpringBoot3项目整合knife4j 4.1.0接口文档的完整配置流程
SpringBoot3技术栈迁移实战:从javax.servlet到knife4j 4.1.0的完整升级指南 当SpringBoot3正式发布时,许多开发者发现原先运行良好的Swagger文档突然报出java.lang.ClassNotFoundException: javax.servlet.http.HttpServletRequest错误。这背后是Java EE…...

Python实战:用PyCryptodome构建你的数据安全防线
1. PyCryptodome:Python开发者的加密利器 当你需要为Python应用添加加密功能时,PyCryptodome绝对是个绕不开的名字。这个库的前身是著名的PyCrypto,现在已经成为Python生态中最强大的密码学工具之一。我在多个实际项目中使用过它,…...
阶段最容易被忽略的5个细节检查)
避开这些坑!IEEE校样(Proof)阶段最容易被忽略的5个细节检查
IEEE论文校样阶段:5个关键细节检查清单 收到论文被接收的邮件总是令人兴奋,但随之而来的校样阶段却常常让研究者们措手不及。48小时的黄金校对窗口转瞬即逝,而一旦错过关键细节,可能面临无法挽回的遗憾。这不是简单的拼写检查——…...

DNA复制中的酶学:从大肠杆菌到人类,这些酶如何精准合成遗传密码?
DNA复制的分子交响曲:从大肠杆菌到人类的酶协作密码 在显微镜下,DNA复制过程如同一场精密编排的交响乐——数十种酶分子在纳米尺度上协同工作,以每秒上千个碱基的速度合成遗传信息。这场分子芭蕾的每个动作都关乎生命延续的准确性:…...

用Excel抓取历史天气数据避坑指南:UTF-8编码与Web.Contents函数详解
Excel抓取历史天气数据避坑指南:UTF-8编码与Web.Contents函数实战解析 天气预报数据对商业决策、活动策划和学术研究都至关重要。但当你需要批量获取多个城市的历史气象记录时,手动复制粘贴显然不现实。Excel的Power Query功能可以自动化这一过程&#x…...

从视频拼接屏到雷达信号处理:拆解AXI4-Stream Switch在真实项目里的两种高阶用法
从视频拼接屏到雷达信号处理:AXI4-Stream Switch的两种高阶实战解析 在FPGA系统设计中,数据流的高效调度往往成为性能瓶颈的关键突破点。想象一下,当16路4K视频流需要实时分配到8个显示终端,或者32通道雷达回波数据要动态分配给4个…...
)
把Snort当“网络监控摄像头”:5分钟教你用嗅探模式分析本地网络流量(Windows实操)
用Snort打造你的网络流量监控台:Windows实战指南 每次看到网络监控设备上闪烁的指示灯,总让我想起城市路口的交通摄像头——它们无声地记录着每一辆车的通行状态。而在数字世界里,Snort就是这样一个"网络监控摄像头",它…...
)
为什么92%的C项目不敢升级?2026规范成本陷阱识别图谱(含GCC 14.2/Clang 18.1兼容性速查表)
第一章:现代 C 语言内存安全编码规范 2026 概览C 语言因其零开销抽象与硬件贴近性,仍在操作系统、嵌入式系统及高性能基础设施中占据核心地位。然而,传统 C 编程中普遍存在的缓冲区溢出、悬空指针、未初始化内存访问等缺陷,已成为…...
支持验证)
RWKV-7多语言对话实战:东南亚小语种(泰/越/印尼)支持验证
RWKV-7多语言对话实战:东南亚小语种(泰/越/印尼)支持验证 1. 项目背景与价值 在全球化交流日益频繁的今天,多语言AI对话工具的需求持续增长。传统大语言模型往往存在显存占用高、推理速度慢等问题,特别是在处理东南亚…...