论文阅读 | RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
ECCV2020光流任务best paper
论文地址:【here】
代码地址:【here】
介绍
光流是对两张相邻图像中的逐像素运动的一种估计。目前碰到的一些困难包括:物体的快速运动,遮挡、运动模糊和缺乏纹理信息的一些图案。
目前深度学习的方法在维持传统方法达到的性能的情况下,有着更快的推理速度。目前需要考虑的问题是:如何设计一个深度学习的光流估计网络,实现更好表现,更易训练和更好的泛化到不同场景。
Recurrent All-Pairs Field Transforms (RAFT)框架有如下优势:
- SOTA精度
- 更强泛化
- 更高效率
RAFT的主要结构:
- feature encoder(蓝色部分) +context encoder(灰色部分)
- 一个全像素区域的a correlation layer,同时带多尺度池化
- a recurrent GRU-based update operator

网络架构
- Feature encoder:
卷积网络,做了8倍下采样,两张图共享一个网络权重
- context encoder:
和feature encoder 一样的网络结构,只作用在左图,作为后续GRU的参数和左图特征
- correlation volume生成-相似度的计算
拿Feature encoder得到的两张8倍下采样图后的特征,通过逐像素间的特征相乘再求和可以得到一个逐像素间的相似度,利用的是余弦相似度的计算方式。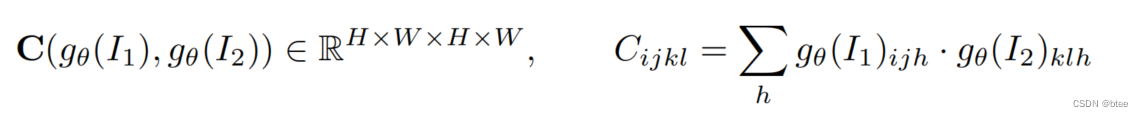
- Correlation Pyramid生成
由于correlation volume用于生成cost volume,即相邻像素区域之间的一个相似度(correlation volume是全局像素间的一个相似度),需要对correlation volume进行领域取值才能得到cost volume。
即correlation volume: H * W * H * W
cost volume: H * W * delta h * delta w
这样导致如果要搜寻更远空间(larger displacement)内的对应像素,delta h * delta w 会很大,导致占用很大的计算资源
于是本文根据这样的缺点,提出一种相关性金字塔Correlation Pyramid:
即构建了四个不同大小的correlation volume,通过对原始大小的correlation volume 池化得到尺寸为H * W * H/2 * W/2, H * W * H/4 * W/4,以此类推的Correlation Pyramid

途中阐释的图correlation volume的构建过程,即C3的correlation volume得到的是image2右图中一个方格内所有的像素点与左图image1某一个像素点的匹配相似度。

构建这样一个金字塔的correlation volume,目的是为了实现不同范围的搜寻空间。在最小的 H * W * H/8 * W/8 correlation volume的上,同样的半径范围r,对应原图的搜寻半径范围是8r.
构建Correlation Pyramid代码如下:
corr = CorrBlock.corr(fmap1, fmap2)batch, h1, w1, dim, h2, w2 = corr.shapecorr = corr.reshape(batch*h1*w1, dim, h2, w2)self.corr_pyramid.append(corr)for i in range(self.num_levels-1):corr = F.avg_pool2d(corr, 2, stride=2)self.corr_pyramid.append(corr)
- Correlation Lookup
这个步骤也就是上一个节,第3节中提到的correlation volume生成cost volume的过程。
具体操作为,在x维度上,生成一个索引图,H * W * (2r+1),存储每个对应的像素点的相邻坐标索引,用这个索引在Correlation Pyramid中取值,得到4个,尺寸为H * W * (2r+1)的cost volume,最后在特征层做特征连接合并不同范围位移的cost volume, 得到一个金字塔范围的cost volume。在y的维度上做同样的操作

代码如下
r = self.radiuscoords = coords.permute(0, 2, 3, 1)batch, h1, w1, _ = coords.shapeout_pyramid = []for i in range(self.num_levels):corr = self.corr_pyramid[i]dx = torch.linspace(-r, r, 2*r+1, device=coords.device)dy = torch.linspace(-r, r, 2*r+1, device=coords.device)delta = torch.stack(torch.meshgrid(dy, dx), axis=-1)centroid_lvl = coords.reshape(batch*h1*w1, 1, 1, 2) / 2**idelta_lvl = delta.view(1, 2*r+1, 2*r+1, 2)coords_lvl = centroid_lvl + delta_lvlcorr = bilinear_sampler(corr, coords_lvl)corr = corr.view(batch, h1, w1, -1)out_pyramid.append(corr)out = torch.cat(out_pyramid, dim=-1)
-
迭代更新过程
RAFT采用GRU不断迭代更新光流,先将光流初始化0,再不断通过计算的cost volume迭代更新光流,再用将新得到的光流与cost volume优化新的光流

这里的光流用于直接查找 cost volume,因此是绝对值,最后的值要与最初的光流相减 -
upsample过程
由于整个过程都是再8倍下采样分辨率下,因此最后做了一个upsample.
upsample用mask学习周围邻域的分布权重情况,做加权mask的upsample.

def upsample_flow(self, flow, mask):""" Upsample flow field [H/8, W/8, 2] -> [H, W, 2] using convex combination """N, _, H, W = flow.shapemask = mask.view(N, 1, 9, 8, 8, H, W)mask = torch.softmax(mask, dim=2)up_flow = F.unfold(8 * flow, [3,3], padding=1)up_flow = up_flow.view(N, 2, 9, 1, 1, H, W)up_flow = torch.sum(mask * up_flow, dim=2)up_flow = up_flow.permute(0, 1, 4, 2, 5, 3)return up_flow.reshape(N, 2, 8*H, 8*W)
- 损失函数直接用L1损失
实验
精度
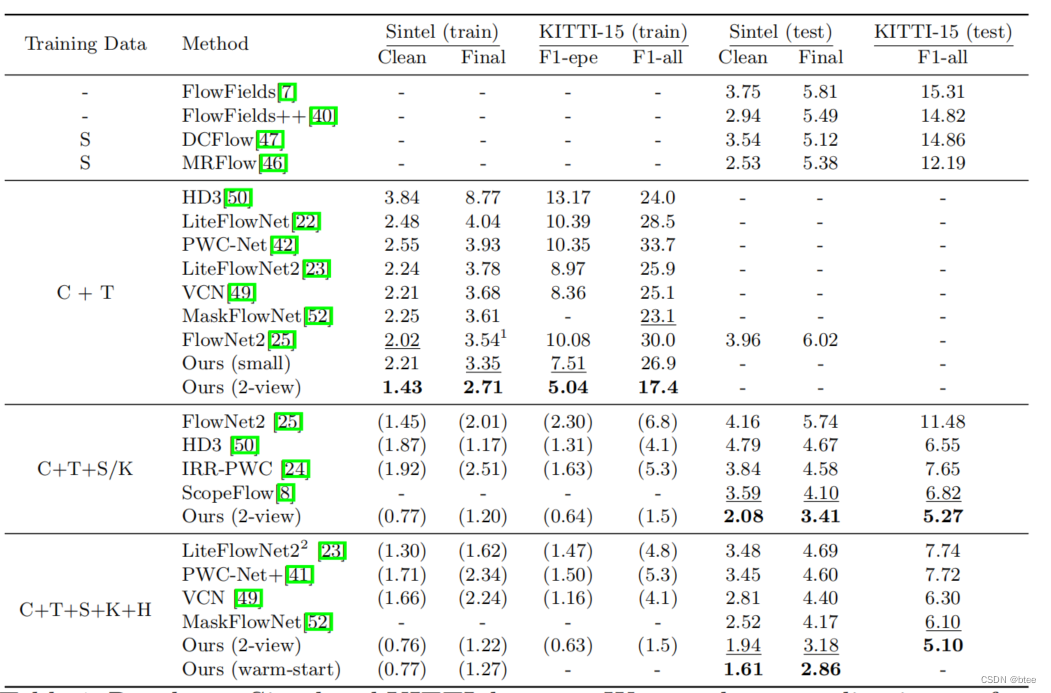
效率
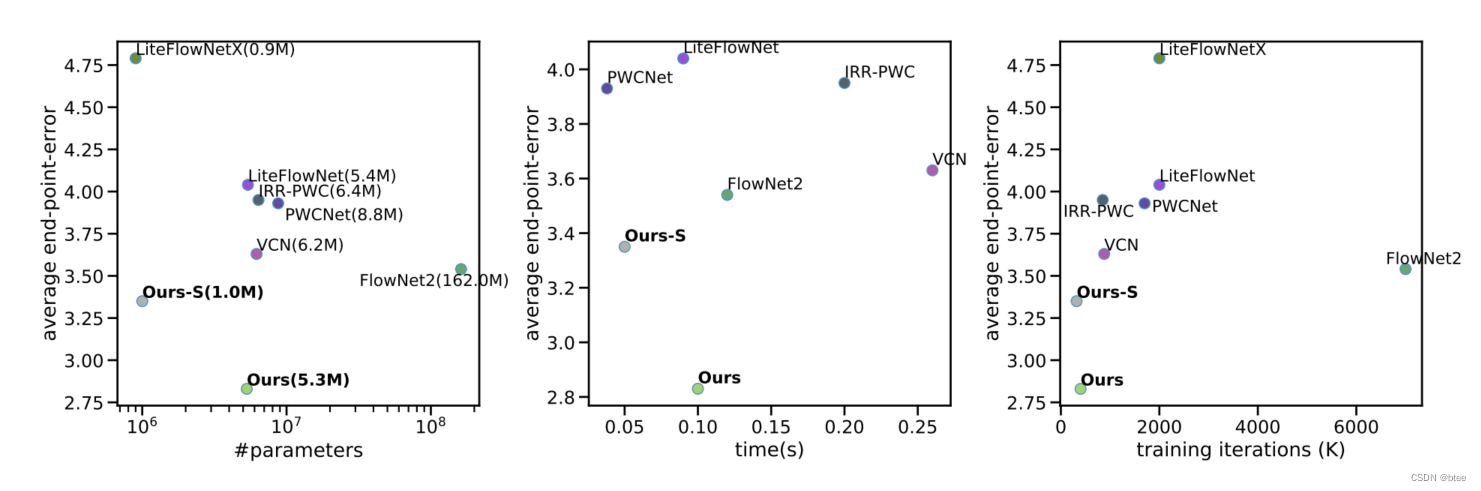
总结
本文的优势:精度好、效率高,在不同数据集上表现都好
相关文章:
论文阅读 | RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow ECCV2020光流任务best paper 论文地址:【here】 代码地址:【here】 介绍 光流是对两张相邻图像中的逐像素运动的一种估计。目前碰到的一些困难包括:物体的快速运动ÿ…...

神经网络的发展历史
神经网络的发展历史可以追溯到上世纪的数学理论和生物学研究。以下是神经网络发展史的详细概述: 早期的神经元模型: 1943年,Warren McCulloch和Walter Pitts提出了一种神经元模型,被称为MCP神经元模型,它模拟了生物神经…...

【单元测试】--单元测试最佳实践
一、单元测试代码风格 编写单元测试代码时,遵循一致的风格和最佳实践是非常重要的,因为它有助于提高代码的可读性、可维护性和可靠性。以下是一些常见的单元测试代码风格和最佳实践: 命名约定: 测试方法的名称应当清晰、描述性&…...
llava1.5-部署
llava1.5 ——demo部署 下载代码和权重 新建weights文件夹,并下载到LLaVA/weights/中。->需要修改文件名为llava-版本,例如llava-v1.5-7b. 运行 启动控制台 python -m llava.serve.controller --host 0.0.0.0 --port 4006启动gradio python -m…...

倒计时 1 天|KCD 2023 杭州站
距离「KCD 2023 杭州站」开始只有 1 天啦 大家快点预约到现场哦~ KCD 2023 活动介绍 HANGZHOU 关于 KCD Kubernetes Community Days(KCD)由云原生计算基金会(CNCF)发起,由全球各国当地的 CNCF 大使、CNCF 员…...
什么是模拟芯片,模拟芯片都有哪些测试指标?
模拟芯片又称处理模拟信号的集成电路 模拟集成电路主要是指由电容、电阻、晶体管等组成的模拟电路集成在一起用来处理模拟信号的集成电路。有许多的模拟集成电路,如运算放大器、模拟乘法器、锁相环、电源管理芯片等。 模拟集成电路的主要构成电路有:放…...

C++-json(2)-unsigned char-unsigned char*-memcpy-strcpy-sizeof-strlen
1.类型转换: //1.赋值一个不知道长度的字符串unsigned char s[] "kobe8llJfFwFSPiy"; //1.用一个字符串初始化变量 unsigned int s_length strlen((char*)s); //2.获取字符串长度//2.字符串里有双引号"" 需要…...
python安装第三方包
1 命令行下载 pip install 包名称 进入命令行输入该命令 由于pip是连接的国外的网站进行包的下载,所以有的时候会速度很慢。 我们可以通过如下命令,让其连接国内的网站进行包的安装: pip install -i https://pypi.tuna.tsinghua.edu.cn/s…...
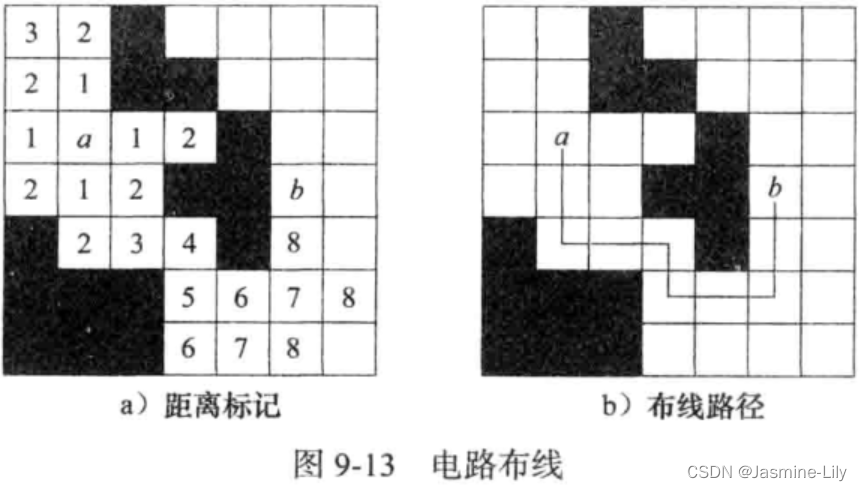
《数据结构、算法与应用C++语言描述》-队列的应用-电路布线问题
《数据结构、算法与应用C语言描述》-队列的应用-电路布线问题 问题描述 在 迷宫老鼠问题中,可以寻找从迷宫入口到迷宫出口的一条最短路径。这种在网格中寻找最短路径的算法有许多应用。例如,在电路布线问题的求解中,一个常用的方法就是在布…...

GC overhead limit exceeded问题
1.问题现象 程序包运行时候发生了java.lang.OutOfMemoryError: GC overhead limit exceeded异常, 详细信息如下 org.apache.ibatis.exceptions.PersistenceException: ### Error querying database. Cause: org.jboss.util.NestedSQLException: Error; - nested t…...

What‘s new in Arana v0.2.0
Arana 定位于云原生数据库代理,它可以以 sidecar 模式部署为数据库服务网格,项目地址是 https://github.com/arana-db/arana 。Arana 提供透明的数据访问能力,当用户在使用时,可以不用关心数据库的 “分片” 细节,像使…...

STM32 串口接收中断被莫名关闭
使用cubeidestm32f4进行调试,发现UART4串口会被莫名的关掉,导致不能接收数据,经过排查如下: HAL_StatusTypeDef HAL_UART_Transmit(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size, uint32_t Timeout) {uint8_t *pd…...
接口测试vs功能测试
接口测试和功能测试的区别: 本文主要分为两个部分: 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者之前的区别与联系。但该部分只交代了怎么做和如何做?并没有解释为什…...
)
前端面试题整理(1.0)
1.nextTick原理 Vue是异步执行Dom更新的,一旦观察到数据变化,Vue就会开启一个队列,然后把在同一个事件循环(event loop)当中观察到数据变化的Watcher推送到这个队列。如果这个Watcher被触发多次,智慧被推送…...

使用Spire.PDF for Python插件从PDF文件提取文字和图片信息
目录 一、Spire.PDF插件的安装 二、从PDF文件提取文字信息 三、从PDF文件提取图片信息 四、提取图片和文字信息的进阶应用 总结 在Python中,提取PDF文件的文字和图片信息是一种常见的需求。为了满足这个需求,许多开发者会选择使用Spire.PDF插件&…...
springBoot整合讯飞星火认知大模型
1.概述 讯飞星火大模型是科大讯飞最近开放的拥有跨领域的知识和语言理解能力的大模型,能够完成问答对话和文学创作等。由于讯飞星火大模型最近可以免费试用,开发者都可以免费申请一个QPS不超过2的账号,用来实现对平台能力的验证。本文将利用…...

JMM对数据竞争的定义
JMM对数据竞争的定义 Java内存模型规范对数据竞争的定义如下在一个线程中写一个变量,在另一个线程读同一个变量,而且写和读没有通过同步来排序。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。当程序未正确同步时&…...
食品安全满意度调查如何开展)
民安智库(湖北知名满意度测评公司)食品安全满意度调查如何开展
食品安全问题一直以来都是社会各界广泛关注的焦点之一。近年来,食品安全事件频发,引起了公众的高度关注和担忧。因此,开展食品安全满意度调查,了解公众对食品安全状况的认知和满意程度,对于促进食品安全共建共治共享具…...

Rust 语法笔记
变量绑定(声明变量) let 变量名: 类型 变量值; let 变量名 变量值[类型]; // 整型 默认 i32;浮点 默认 f64所有的 let 绑定都必须尾接;,代码块也不例外。 mut 可以通过重新声明的方式来改变变量类型 可以下划线改善数字的可读…...

AI智慧安防智能监控平台如何做到健身房智能视频监控?
随着大家对健身的重视,健身房也开始遍地开花,健身房的兴起是必然的,但是健身房的管理不容疏忽,通过EasyCVR智能视频监控系统,则可以解决监管不足的问题。 1、安全摄像头布局 根据健身房的大小和布局,合理规…...

不止于调试:用Modbus Poll深度解析Modbus TCP/IP协议帧,看懂每一行通信报文
不止于调试:用Modbus Poll深度解析Modbus TCP/IP协议帧,看懂每一行通信报文 当你熟练使用Modbus Poll完成设备读写时,是否好奇过点击"Read/Write Once"按钮后,工具与PLC之间究竟传递了哪些信息?那些十六进制…...
)
SV约束控制进阶:像开关一样动态管理你的随机约束块(constraint_mode详解)
SV约束控制进阶:动态管理随机约束块的实战技巧 在芯片验证领域,随机约束测试已成为覆盖复杂设计场景的核心手段。但当验证环境需要模拟数十种工作模式时,静态约束往往会变成沉重的负担——要么产生大量冗余用例,要么无法精准触发目…...

STM32F103x + ULN2003驱动28BYJ-48步进电机:从开环控制到细分驱动的进阶实践
1. 认识28BYJ-48步进电机与ULN2003驱动模块 第一次拿到28BYJ-48这个小家伙时,我完全没想到它能在我的项目中发挥这么大作用。这款直径28mm的永磁减速步进电机,名字里的每个字母数字都有含义:B代表步进电机,Y表示永磁体,…...

从Kindle转投BOOX:一个重度阅读者的真实体验与避坑指南
从Kindle转投BOOX:一个重度阅读者的真实体验与避坑指南 作为一名每天阅读时间超过3小时的深度用户,我曾在Kindle生态中沉浸了整整7年。直到去年,当我发现自己的阅读需求已经远远超出封闭系统的承载能力时,终于决定尝试开放系统的B…...

RISC-V IDE混战,我为什么最终选择了Segger Embedded Studio?
RISC-V IDE选型实战:为何Segger Embedded Studio成为我的最终选择? 当兆易创新GD32V103开发板静静躺在桌面上时,我意识到这个预算有限的物联网网关项目正面临关键抉择——在碎片化的RISC-V生态中,如何选择一款既符合团队技术栈又能…...

【2026内存安全编码白皮书】:C语言开发者必须立即落地的7项零成本接入策略
第一章:现代 C 语言内存安全编码规范 2026 如何实现快速接入现代 C 语言内存安全编码规范 2026(简称 MSC-2026)是一套面向工业级嵌入式与系统软件的轻量级、可增量集成的内存安全实践集合,聚焦于编译时约束、运行时防护与静态分析…...
)
【仅限首批信创集成商内部流通】Docker 27 国产化适配白皮书(含17个真实POC环境日志+4类CPU架构差异对照表)
第一章:Docker 27 国产化适配总体技术路线与政策背景近年来,国家密集出台《“十四五”数字经济发展规划》《关键信息基础设施安全保护条例》及《信创产业三年行动计划(2023–2025)》等政策文件,明确将容器技术纳入基础…...

3个月速成模型大师!2026年大模型进阶秘籍,薪资直接翻倍!
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。 接下来告诉你一条最快的邪修路线, 3个月即可成为模型大师,薪资直接起飞。阶段1:大模型基础阶段2:RAG应用开发工程阶段3:大模型Agent应用架构阶段4:大模型微调与私有化部署学习资源&am…...

2026年Hermes Agent/OpenClaw如何部署?阿里云及Coding Plan配置保姆级指南
2026年Hermes Agent/OpenClaw如何部署?阿里云及Coding Plan配置保姆级指南。OpenClaw(前身为Clawdbot/Moltbot)作为开源、本地优先的AI助理框架,凭借724小时在线响应、多任务自动化执行、跨平台协同等核心能力,成为个人…...

亦庄人形机器人半程马拉松:大厂入局改写竞争规则,赛事成具身智能行业新秩序催化剂
马拉松给具身智能产业泼冷水马拉松给具身智能产业泼了盆冷水。过去,资本和观众愿意给原生玩家时间,但这场比赛让大家看到,产业竞争不会因“还需要时间”而放慢。当荣耀这样的科技大厂夺冠,native厂商面临更大竞争压力。资本也许会…...