【TensorFlow1.X】系列学习笔记【入门二】
【TensorFlow1.X】系列学习笔记【入门二】
大量经典论文的算法均采用 TF 1.x 实现, 为了阅读方便, 同时加深对实现细节的理解, 需要 TF 1.x 的知识
文章目录
- 【TensorFlow1.X】系列学习笔记【入门二】
- 前言
- 神经网络的参数
- 神经网络的搭建
- 前向传播
- 反向传播
- 总结
前言
学习了张量、计算图、会话等基础知识,下一步就是实现神经网络的搭建了,本篇博文将讲解搭建神经网络的过程,并简练总结搭建八股。【参考】
神经网络的参数
神经网络的参数是指在神经网络模型中需要学习的可调整值。这些参数用于调整模型的行为,定了神经网络的行为和性能,使其能够更好地拟合训练数据和进行预测。
在典型的神经网络中,参数主要存在于两个部分,用变量表示:
- 权重(Weights):
权重是连接神经网络中不同层的神经元之间的参数。每个连接都有一个关联的权重,用于调整信息在网络中的传递。权重决定了每个输入对于特定神经元的重要性。在训练过程中,神经网络通过优化算法来调整权重,以最小化预测输出与实际输出之间的差距。 - 偏置(Biases):
偏置是神经元的可调整参数,用于调整神经元的激活阈值。每个神经元都有一个关联的偏置值,它在计算神经元的输出时被加到加权输入上。偏置允许神经元对不同的输入模式做出不同的响应。
这些权重和偏置参数是在训练过程中学习的,通过反向传播算法和优化方法(如梯度下降)来更新,训练过程旨在最小化损失函数,以使神经网络能够更准确地进行预测。
在 TensorFlow 1.x 中,可以使用以下方法来初始化神经网络的参数:
| 方法 | 功能 |
|---|---|
| tf.random_normal() | 生成正态分布随机数 |
| tf.truncated_normal() | 生成去掉过大偏离点的正态分布随机数 |
| tf.random_uniform() | 生成均匀分布随机数 |
| tf.random_uniform() | 生成均匀分布随机数 |
| tf.zeros | 表示生成全 0 数组 |
| tf.ones | 表示生成全 1 数组 |
| tf.fill | 表示生成全定值数组 |
| tf.constant | 表示生成直接给定值的数组 |
import tensorflow as tf
w = tf.Variable(tf.random_normal([2,3], stddev=2, mean=0, seed=1))
# => <tf.Variable 'Variable:0' shape=(2, 3) dtype=float32_ref>
w = tf.Variable(tf.truncated_normal([2,3], stddev=2, mean=0, seed=1))
# => <tf.Variable 'Variable_1:0' shape=(2, 3) dtype=float32_ref>
w = tf.random_uniform([2,3], minval=0, maxval=1, dtype=tf.int32, seed=1)
# => Tensor("random_uniform:0", shape=(2, 3), dtype=int32)
w = tf.zeros([3,2], tf.int32)
# => Tensor("zeros:0", shape=(3, 2), dtype=int32)
w = tf.ones([3,2], tf.int32)
# => Tensor("ones:0", shape=(3, 2), dtype=int32)
w = tf.fill([3,2], 6)
# => Tensor("Fill:0", shape=(3, 2), dtype=int32)
w = tf.constant([3,2])
# => Tensor("Const:0", shape=(2,), dtype=int32)
注意:①随机种子如果去掉每次生成的随机数将不一致,②如果没有特殊要求标准差、均值、随机种子是可以不写的。
神经网络的搭建
神经网络模型的实现过程:
- 准备数据集:作为神经网络模型的训练\测试数据
- 前向传播:搭建模型结构,先搭建计算图,再用会话执行,计算输出
- 反向传播:模型学习到大量特征数据,迭代优化模型参数
- 完成训练,验证模型精度
由此可见,基于深度学主要分为两个过程,即训练过程和使用过程。 训练过程是第一步、第二步、第三步的循环迭代,使用过程是第四步,一旦参数优化完成就可以固定这些参数,实现特定应用了。当前很多实际应用中,会优先使用现有的成熟可靠的模型结构,用个人的数据集训练模型,判断是否能对个人数据集作出正确响应,再适当更改网络结构,反复迭代,让机器自动训练参数找出最优结构和参数,以固定专用模型。
前向传播
前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对一组输入给出相应的输出。
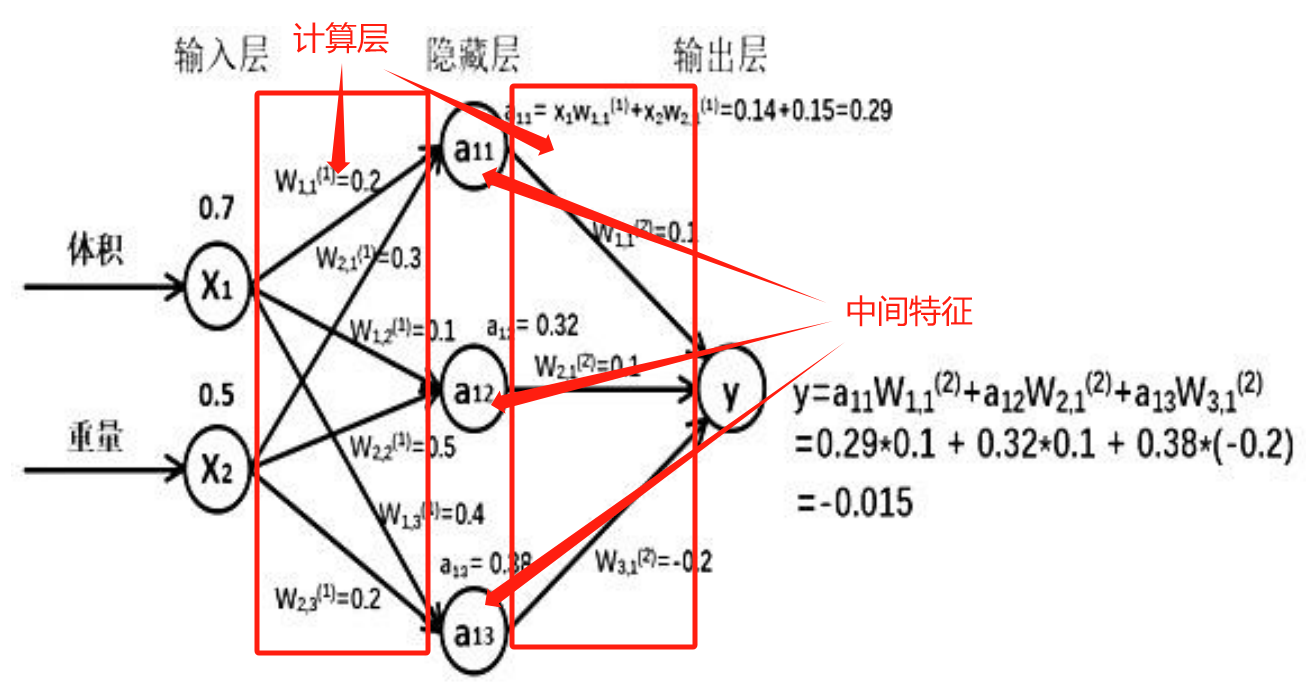
举个案例,假如快递运输费用,体积为 x1,重量为 x2,体积和重量就是我们选择的特征,把它们输入到神经网络,当体积和重量这组数据走过神经网络后会得到一个输出,即费用。
假如输入的特征值是:体积 0.7 重量 0.5:

由图可知,隐藏层节点 a11=x1w11+x2w21=0.14+0.15=0.29,同理算得节点 a12=0.32,a13=0.38,最终计算得到输出层 Y=-0.015,这便实现了前向传播过程。
前向传播过程的 tensorflow 描述:
- 输入层: X X X是 n × 2 {\rm{n}} \times 2 n×2的矩阵,表示一次输入 n n n组特征,这组特征包含了体积和重量两个元素。
x = tf.placeholder(tf.float32, shape=(None, 2)) - 隐藏层: W ( F r o n t N o d e N u m b e r , R e a r N o d e N u m b e r ) ( l a y e r s ) W_{(F{\rm{rontNodeNumber}},R{\rm{earNodeNumber)}}}^{({\rm{layers}})} W(FrontNodeNumber,RearNodeNumber)(layers)是待优化的参数,对于第一计算层的 w ( 1 ) {w^{({\rm{1}})}} w(1)前面有两个节点,后面有三个节点, w ( 1 ) {w^{({\rm{1}})}} w(1)是个两行三列矩阵:
W ( 1 ) = [ w ( 1 , 1 ) ( 1 ) w ( 1 , 2 ) ( 1 ) w ( 1 , 3 ) ( 1 ) w ( 2 , 1 ) ( 1 ) w ( 2 , 2 ) ( 1 ) w ( 2 , 3 ) ( 1 ) ] {W^{(1)}} = \left[ {\begin{array}{cc} {w_{(1,1{\rm{)}}}^{(1)}}&{w_{(1,2{\rm{)}}}^{(1)}}&{w_{(1,3{\rm{)}}}^{(1)}}\\ {w_{(2,1{\rm{)}}}^{(1)}}&{w_{(2,2{\rm{)}}}^{(1)}}&{w_{(2,3{\rm{)}}}^{(1)}} \end{array}} \right] W(1)=[w(1,1)(1)w(2,1)(1)w(1,2)(1)w(2,2)(1)w(1,3)(1)w(2,3)(1)],即 a ( 1 ) = [ a 11 , a 12 , a 13 ] = X W ( 1 ) {a^{\left( 1 \right)}} = \left[ {{a_{11}},{\rm{ }}{a_{12}},{\rm{ }}{a_{13}}} \right] = X{W^{(1)}} a(1)=[a11,a12,a13]=XW(1);
对于第二计算层的 w ( 2 ) {w^{({\rm{2}})}} w(2)前面有三个节点,后面有1个节点, w ( 2 ) {w^{({\rm{2}})}} w(2)是个三行一列矩阵:
W ( 2 ) = [ w ( 1 , 1 ) ( 2 ) w ( 2 , 1 ) ( 2 ) w ( 3 , 1 ) ( 2 ) ] {W^{(2)}} = \left[ {\begin{array}{cc} {w_{(1,1{\rm{)}}}^{(2)}}\\ {w_{(2,1{\rm{)}}}^{(2)}}\\ {w_{(3,1{\rm{)}}}^{(2)}} \end{array}} \right] W(2)= w(1,1)(2)w(2,1)(2)w(3,1)(2) ,即 y = a ( 1 ) W ( 1 ) {y} = {a^{\left( 1 \right)}}{W^{(1)}} y=a(1)W(1)。a = tf.matmul(x, w1) y = tf.matmul(a, w2)
神经网络共有几层(或当前是第几层网络)都是指的计算层,所有的计算层统称为隐藏层,而隐藏层的计算层计算出结果通常称做中间特征,不要错把这些当作隐藏层。
完整的前向传播代码。
import tensorflow as tf# 定义输入和参数
# 用tf.placeholder定义输入,在sess.run函数中要用feed_dict指定输入
x = tf.placeholder(tf.float32, shape=(None, 2))
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))# 定义前向传播过程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)# 汇总所有待优化变量
init_op = tf.global_variables_initializer()# 调用会话计算结果
# 变量初始化、计算图节点运算都要用会话(with结构)实现
with tf.Session() as sess:# 在sess.run函数中变量初始化sess.run(init_op)# 在sess.run函数中计算图节点运算print("the result of tf3_5.py is:\n",sess.run(y, feed_dict={x: [[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]}))print("w1:\n", sess.run(w1))print("w2:\n", sess.run(w2))反向传播
反向传播:训练模型参数,在所有参数上用梯度下降,使 NN 模型在训练数据上的损失函数最小。
反向传播过程的 tensorflow 描述:
- 损失函数(loss):计算得到的预测值 y 与已知真实值 y_的误差。均方误差 MSE
是比较常用的方法之一,它计算前向传播求出的预测值与已知真实值之差的平方再求平均: M S E ( y _ , y ) = ∑ i = 1 n ( y − y _ ) 2 n MSE(y\_,y) = \frac{{\sum\nolimits_{i = 1}^n {{{(y - y\_)}^2}} }}{n} MSE(y_,y)=n∑i=1n(y−y_)2loss_mse = tf.reduce_mean(tf.square(y-y_)) - 反向传播优化方法:以减小 loss 值为优化目标,常见的三种有随机梯度下降、momentum 优化器、adam优化器等优化方法。
# 学习率(learning_rate):决定每次参数更新的幅度。 train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) train_step = tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss) train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)方法 功能 tf.train.GradientDescentOptimizer() 梯度下降用于最小化损失函数。它通过计算损失函数关于每个可训练参数的梯度,并将参数沿着梯度的反方向进行更新,以减少损失函数的值。 tf.train.MomentumOptimizer() 动量优化器在梯度下降的基础上引入了动量的概念,以加速训练过程,它通过累积之前梯度的方向来更新参数,以减少损失函数的值。 tf.train.AdamOptimizer() 结合了动量优化器和自适应学习率的思想。它根据梯度的平均值和方差来自适应地调整学习率,以在训练过程中更好地适应不同参数的变化,以减少损失函数的值。
完整的反向传播代码。
# coding:utf-8
# 0导入模块,生成模拟数据集。
import tensorflow as tf
import numpy as np# 每次训练的数量
BATCH_SIZE = 8
SEED = 23455# 基于seed产生随机数
rdm = np.random.RandomState(SEED)
# 随机数返回32行2列的矩阵 表示32组 体积和重量 作为输入数据集
X = rdm.rand(32, 2)
# 从X这个32行2列的矩阵中 取出一行 判断如果和小于1 给Y赋值1 如果和不小于1 给Y赋值0
# 作为输入数据集的标签(正确答案)
Y_ = [[int(x0*0.5+x1*0.8)] for (x0, x1) in X]# 定义神经网络的输入、参数和输出,定义前向传播过程。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))a = tf.matmul(x, w1)
y = tf.matmul(a, w2)# 定义损失函数及反向传播方法。
loss_mse = tf.reduce_mean(tf.square(y - y_))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
# train_step = tf.train.MomentumOptimizer(0.001,0.9).minimize(loss_mse)
# train_step = tf.train.AdamOptimizer(0.001).minimize(loss_mse)# 生成会话,训练STEPS轮
with tf.Session() as sess:init_op = tf.global_variables_initializer()sess.run(init_op)# 输出目前(未经训练)的参数取值。print("w1:\n", sess.run(w1))print("w2:\n", sess.run(w2))# 训练模型# 悬链次数STEPS = 3000for i in range(STEPS):# 随机选取一组batchsize为8的数据段start = (i * BATCH_SIZE) % 32end = start + BATCH_SIZEsess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]})if i % 500 == 0:total_loss = sess.run(loss_mse, feed_dict={x: X, y_: Y_})print("After %d training step(s), loss_mse on all data is %g" % (i, total_loss))# 输出训练后的参数取值。print("w1:\n", sess.run(w1))print("w2:\n", sess.run(w2))
总结
梳理出神经网络搭建的八股,搭建过程分四步完成:准备工作、前向传播、反向传播和循环迭代:
- 导入模块,生成模拟数据集;
- 前向传播:定义输入、参数和输出;
- 反向传播:定义损失函数、反向传播方法;
- 生成会话,训练n轮。
相关文章:
【TensorFlow1.X】系列学习笔记【入门二】
【TensorFlow1.X】系列学习笔记【入门二】 大量经典论文的算法均采用 TF 1.x 实现, 为了阅读方便, 同时加深对实现细节的理解, 需要 TF 1.x 的知识 文章目录 【TensorFlow1.X】系列学习笔记【入门二】前言神经网络的参数神经网络的搭建前向传播反向传播 总结 前言 学习了张量、…...

详解一下HTML的语义化标签
目录 什么是语义化标签: HTML5的语义化元素的优点: HTML5的语义化元素的缺点: 来个例子: 语义化标签有那些: 什么是语义化标签: 语义化标签是HTML的一种特性,其核心目标是让标签具有特定的意义。它们的存在不仅帮助开发者更好地理解文档的结构,也让…...
C++11的for循环
在C03/98中,不同的容器和数组,遍历的方法不尽相同,写法不统一,也不够简洁,而C11基于范围的for循环以统一,简洁的方式来遍历容器和数组,用起来更方便了。 for循环的新用法 #include <iostre…...

代码随想录算法训练营第六十天| 739. 每日温度、 496.下一个更大元素 I
代码随想录算法训练营第六十天| 739. 每日温度、 496.下一个更大元素 I 739. 每日温度496.下一个更大元素 I 今天的题都能看懂,做了一个小时 739. 每日温度 题目链接:739. 每日温度 文章链接 状态:看视频能看懂,还是要多练。 代码…...

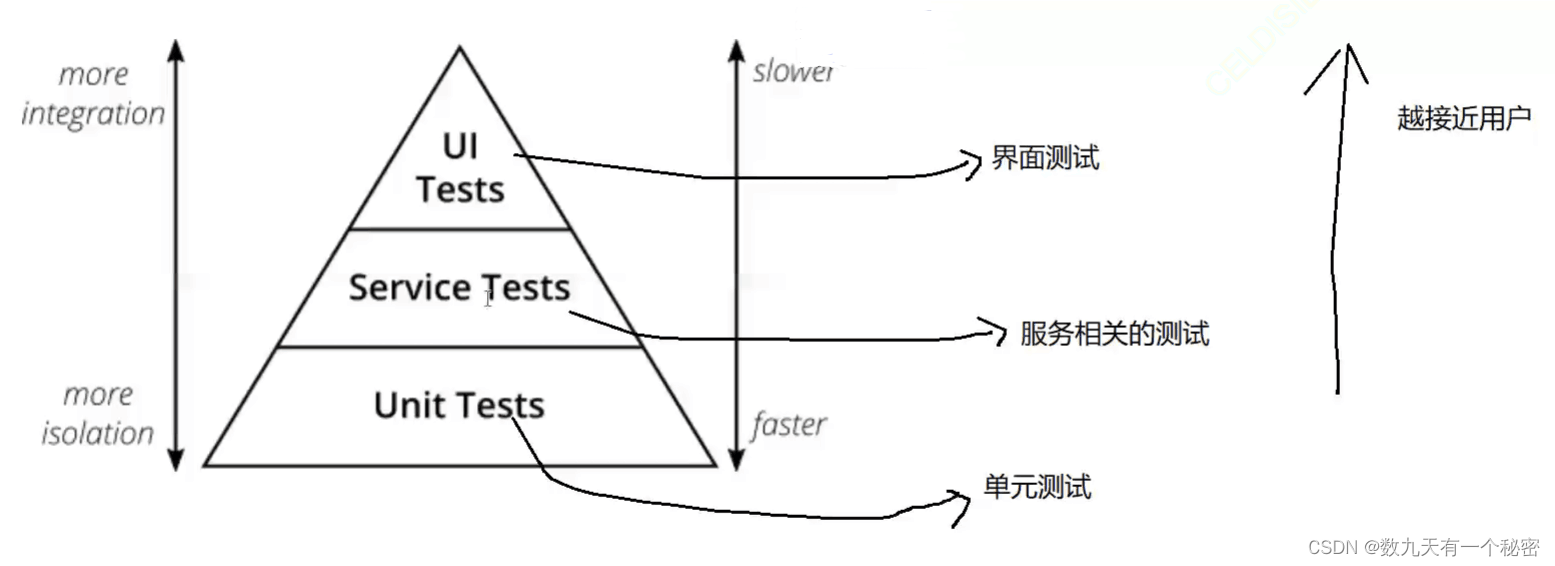
13.3测试用例进阶
一.测试对象划分 1.界面测试(参考软件规格说明书和UI视觉稿) a.什么是界面 1)WEB站(浏览器) 2)app 3)小程序 4)公众号 b.测试内容 1)界面内容显示的一致性,完整性,准确性,友好性.比如界面内容对屏幕大小的自适应,换行,内容是否全部清晰展示. 2)验证整个界面布局和排版…...

[云原生1] Docker网络模式的详细介绍
1. Docker 网络 1.1 Docker 网络实现原理 Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0), Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP, 同时Docker网桥是每个容器的默认…...

uni——底部弹框显示,底部导航隐藏
案例 在uni-app中,如果你在tabbar页面显示一个底部弹框,底部导航默认是会依旧显示的。如果你想在弹框显示时隐藏底部导航,你可以使用uni.hideTabBar和uni.showTabBar方法来控制底部导航的显示和隐藏。 export default {methods: {openPopup(…...

HammerDB的安装和使用(超详细)
目录 编辑 一、HammerDB的介绍 二、HammerDB的安装 1、下载hammerdb安装包 2、权限配置以及安装 3、查看安装目录 三、安装前的配置 1、启动监听 2、启动数据库 3、创建表空间 1.修改临时表空间 2…...

java经典面试题总结
1.请简述Java的继承,重写和多态的概念和运用 继承是一种Java中重要的面向对象编程方式,它允许一个类从另一个类继承某些属性和方法,在这种关系下,子类可以重写父类的方法,从而实现不同的行为。 多态是继承实现的一种关…...

django中template中post请求接口csrf问题
$(function () {$.ajaxSetup({headers: { "X-CSRFToken": getCookie("csrftoken") }}); });// 为防止CSRF(Cross-site request forgery)跨站请求伪造,发post请求时需要在cookie中创建随机码 function getCookie(name) {v…...

聊聊RocketMQMessageListener的实现机制
序 本文主要研究一下RocketMQMessageListener的实现机制 示例 Service RocketMQMessageListener(nameServer "${demo.rocketmq.myNameServer}", topic "${demo.rocketmq.topic.user}", consumerGroup "user_consumer") public class UserC…...

ConfigurationProperties注解详解
ConfigurationProperties和Value注解用于获取配置文件中的属性定义并绑定到Java Bean或属性中 一个简单的例子 ConfigurationProperties需要和Configuration配合使用,我们通常在一个POJO里面进行配置: Data Configuration ConfigurationProperties(pre…...

三、组件与数据交互
一、组件基础 1、单文件组件 第一步:引入组件 import ComponentTest from ./components/ComponentTest.vue 第二步:挂载组件 components: {ComponentTest } 第三步:显示组件 <ComponentTest></ComponentTest><!-- 父组件 --…...

#define 宏定义看这一篇文章就够了
前言:在c/c学习的过程中,宏定义(#define)是作为初学者学习到的为数不多的预处理指令,在学习的时候我们被告知他可以帮助我们更高效的写程序,可以增加程序的可读性,但宏定义(#define&…...

LeetCode算法栈—验证图书取出顺序
验证图书取出顺序 目录 验证图书取出顺序 题解: 代码: 运行结果: 验证图书取出顺序 现在图书馆有一堆图书需要放入书架,并且图书馆的书架是一种特殊的数据结构,只能按照 一定 的顺序 放入 和 拿取 书籍。 给定一个…...
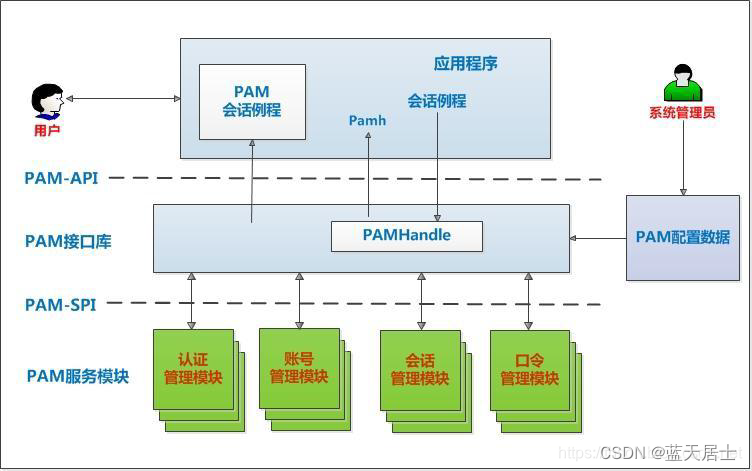
PAM从入门到精通(十八)
接前一篇文章:PAM从入门到精通(十七) 本文参考: 《The Linux-PAM Application Developers Guide》 PAM 的应用开发和内部实现源码分析 先再来重温一下PAM系统架构: 更加形象的形式: 六、整体流程示例 2.…...

【区间 DP】热门区间 DP 运用题
题目描述 这是 LeetCode 上的 「312. 戳气球」 ,难度为 「困难」。 Tag : 「区间 DP」、「动态规划」 有 n 个气球,编号为 0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。 现在要求你戳破所有的气球。戳破第 i …...
正则表达式,日期选择器时间限制,报错原因
目录 一、正则表达式 1、表达式含义 2、书写表达式 二、时间限制 1、原始日期选择器改造 2、禁止选择未来时间 3、从...到...两个日期选择器的时间限制 三、Uncaught (in promise) Error报错 一、正则表达式 1、表达式含义 (1)/^([a-zA-Z0-9_.…...

YOLOv7 改进原创 HFAMPAN 结构,信息高阶特征对齐融合和注入,全局融合多级特征,将全局信息注入更高级别
💡本篇内容:YOLOv7 改进原创 HFAMPAN 结构,信息高阶特征对齐融合和注入,全局融合多级特征,将全局信息注入更高级别 💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可 💡本文提出改进 原创 方式:二次创新,YOLOv7 专属 论文理…...
该怎么选)
别再死记硬背了!一文搞懂机器人伺服电机的三种控制模式(脉冲/模拟/通信)该怎么选
机器人伺服电机控制模式实战指南:脉冲、模拟与通信的黄金选择法则 在工业自动化领域,伺服电机如同机器人的"肌肉系统",其控制精度直接决定了整个设备的性能表现。我曾亲眼见证过一个价值数百万的自动化产线项目,仅仅因为…...

避开定时器分频的坑:STM32 CubeMX ADC欠采样配置中的精度损失与应对策略
STM32 CubeMX ADC欠采样实战:破解非整数分频下的定时器精度困局 当我们需要用100kHz采样率捕获1MHz信号时,传统方案往往束手无策。欠采样技术通过巧妙的时间间隔设计,让低速ADC也能采集高频信号。但当你将采样间隔设置为1.1μs时,…...

面试官总问的‘线程安全List’怎么选?深入源码对比synchronizedList和CopyOnWriteArrayList的性能与内存开销
面试官最爱问的线程安全List选择指南:synchronizedList与CopyOnWriteArrayList深度解析 在Java并发编程的面试中,线程安全集合的选择几乎是必考题。当面试官抛出"如何保证List线程安全"这个问题时,你能从底层原理到实战场景给出令人…...
)
PaddleOCR实战:手把手教你训练一个识别金属零件字符的定制化模型(从PPOCRLabel标注到模型部署)
PaddleOCR工业实战:金属零件字符识别模型定制全流程解析 金属零件表面的字符识别一直是工业质检中的关键环节。与通用OCR不同,工业场景下的字符往往面临反光、油污、低对比度等复杂干扰。本文将完整演示如何基于PaddleOCR框架,从零构建专用于…...
)
别再只画图了!用Matlab Simulink+Simscape Multibody给你的SolidWorks装配体做个‘体检’(附完整联动教程)
机械设计动态验证:用Simscape Multibody为SolidWorks装配体做专业"体检" 在机械设计领域,完成三维建模只是第一步。真正考验设计合理性的,是装配体在实际运动中的表现——关节受力是否均匀?运动轨迹是否符合预期&#…...

5G网络调度器如何“精打细算”?手把手拆解gNB如何根据UE的BSR MAC-CE分配PUSCH资源
5G网络调度器如何“精打细算”?手把手拆解gNB如何根据UE的BSR MAC-CE分配PUSCH资源 在5G网络中,上行资源调度是保障用户体验和网络效率的关键环节。作为网络侧的"大脑",gNB调度器需要根据终端设备(UE)上报的…...
)
外企面试求生指南:除了刷LeetCode,Booking、eBay们还看重什么?(附系统设计/AB测试避坑点)
外企技术面试突围战:超越算法题的6个关键能力图谱 去年帮一位朋友复盘Booking.com的面试失败经历时,发现一个有趣现象:他在LeetCode周赛排名前5%,却倒在一道看似简单的流量控制算法题上。面试官给的反馈是"边界条件处理不成熟…...

如何一键检测谁删除了你的微信好友:WechatRealFriends实战指南
如何一键检测谁删除了你的微信好友:WechatRealFriends实战指南 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFri…...

从CentOS7到Go 1.19.4:一条yum命令背后的源配置原理与版本选择实战
从CentOS7到Go 1.19.4:深入解析yum源配置与版本选择策略 当技术团队需要在CentOS7系统上部署Go语言环境时,直接执行yum install golang往往会遭遇"没有可用包"的报错。这背后隐藏着Linux包管理系统的复杂机制和版本选择的艺术。本文将带您穿透…...

跨越数字边界的文化守护者:AO3-Mirror-Site开源镜像网络革命
跨越数字边界的文化守护者:AO3-Mirror-Site开源镜像网络革命 【免费下载链接】AO3-Mirror-Site 项目地址: https://gitcode.com/gh_mirrors/ao/AO3-Mirror-Site 当一位中国同人创作者在深夜试图访问AO3却遭遇连接失败,当一位研究者需要引用特定同…...