学会使用Pandas进行数据清洗
大家好,如果你对数据科学感兴趣,那么数据清洗可能对你来说是一个熟悉的术语,本文将向你介绍使用Pandas进行数据清洗的过程。我们的数据通常来自多个资源,而且并不干净,它可能包含缺失值、重复值、错误或不需要的格式等,在这种混乱的数据上运行实验会导致错误的结果。因此,在将数据输入模型之前,有必要对数据进行准备,这种通过识别和解决潜在的错误、不准确性和不一致性来准备数据的做法被称为数据清洗。
本文将使用著名的鸢尾花数据集进行操作。鸢尾花数据集包含三个品种的鸢尾花的四个特征测量值:萼片长度、萼片宽度、花瓣长度和花瓣宽度。本文将使用以下库:
-
Pandas:用于数据处理和分析的强大库
-
Scikit-learn:提供数据预处理和机器学习的工具
1. 加载数据集
使用Pandas的read_csv()函数加载鸢尾花数据集:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)
iris_data.head()
输出:
| id | sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
参数header=0表示CSV文件的第一行包含列名(标题)。
2. 探索数据集
为了深入了解数据集的基本信息,本文将使用pandas的内置函数打印一些基本信息:
print(iris_data.info())
print(iris_data.describe())
输出:
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):# 列名 非空计数 类型
--- ------ -------------- ----- 0 id 150 non-null int64 1 sepal_length 150 non-null float642 sepal_width 150 non-null float643 petal_length 150 non-null float644 petal_width 150 non-null float645 species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
None
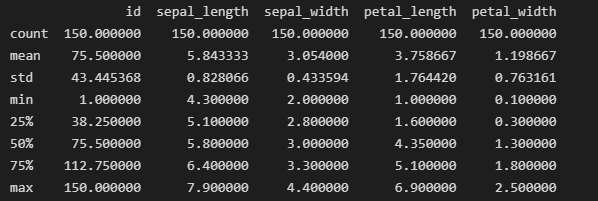
iris_data.describe()的输出结果
info()函数有助于了解数据帧的整体结构、每列中非空值的数量以及内存使用情况,而汇总统计信息则提供了数据集中数值特征的概览。
3. 检查类别分布
这是了解分类列中类别分布情况的重要步骤,对于分类任务来说非常重要,可以使用Pandas中的value_counts()函数来执行此步骤。
print(iris_data['species'].value_counts())
输出:
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: species, dtype: int64
输出的结果显示,数据集是平衡的,每个品种的代表数量相等,这为所有3个类别进行公平评估和比较奠定了基础。
4. 删除缺失值
由于从info()方法明显可见本文的数据中有5列没有缺失值,因此本文将跳过此步骤。但如果遇到任何缺失值,可以使用以下命令处理它们:
iris_data.dropna(inplace=True)
5. 删除重复值
重复值可能会扭曲我们的分析结果,因此本文会从数据集中删除它们。首先使用下面的命令检查是否存在重复值:
duplicate_rows = iris_data.duplicated()
print("Number of duplicate rows:", duplicate_rows.sum())
输出:
Number of duplicate rows: 0
本文的数据集中没有重复值。不过,如果有重复值,可以使用drop_duplicates()函数将其删除:
iris_data.drop_duplicates(inplace=True)
6. 独热编码
对于分类分析,本文将对品种列进行独热编码。由于机器学习算法更适合处理数值数据,所以本文进行独热编码这一步骤。独热编码过程将分类变量转换为二进制(0或1)格式。
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')
iris_data = pd.concat([iris_data, encoded_species], axis=1)
iris_data.drop(columns=['species'], inplace=True)

7. 浮点数列的归一化
归一化是将数值特征缩放为均值为0、标准差为1的过程,这一过程旨在确保各特征对分析的贡献相等。本文将对浮点数列进行归一化,以便进行一致的缩放。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
scaled_data = scaler.fit(iris_data[cols_to_normalize])
iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize])
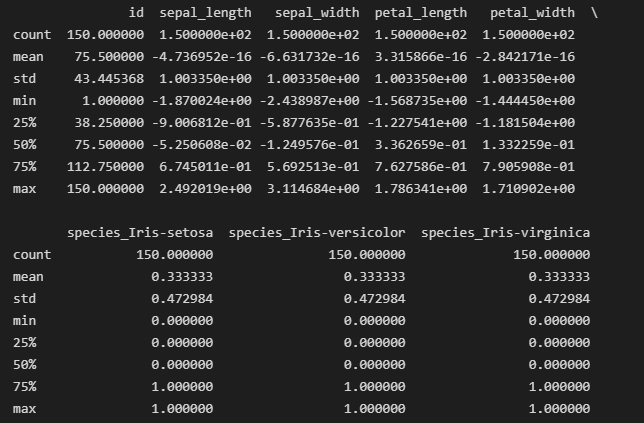
归一化后的iris_data.describe()输出结果
8. 保存清洗后的数据集
将清洗后的数据集保存到新的CSV文件中。
iris_data.to_csv('cleaned_iris.csv', index=False)
如果完成上述步骤,你已成功使用Pandas清洗了第一个数据集。在处理复杂数据集时,可能会遇到其他挑战,然而本文介绍的基本技术将帮助你入门,并为开始数据分析做好准备。
相关文章:
学会使用Pandas进行数据清洗
大家好,如果你对数据科学感兴趣,那么数据清洗可能对你来说是一个熟悉的术语,本文将向你介绍使用Pandas进行数据清洗的过程。我们的数据通常来自多个资源,而且并不干净,它可能包含缺失值、重复值、错误或不需要的格式等…...
Stable Diffusion WebUI扩展a1111-sd-webui-tagcomplete之Booru风格Tag自动补全功能详细介绍
安装地址 直接附上地址先: Ranting8323 / A1111 Sd Webui Tagcomplete GitCodeGitCode——开源代码托管平台,独立第三方开源社区,Git/Github/Gitlabhttps://gitcode.net/ranting8323/a1111-sd-webui-tagcomplete.git上面是GitCode的地址,下面是GitHub的地址,根据自身情…...

Linux中iostat命令
iostat命令是IO性能分析的常用工具,其是input/output statistics的缩写。 一、安装 yum install sysstat -y二、参数说明 -c: 显示CPU使用情况-d: 显示磁盘使用情况--dec{ 0 | 1 | 2 }: 指定要使用的小数位数,默认为 2-g GROUP_NAME { DEVICE [...] | A…...
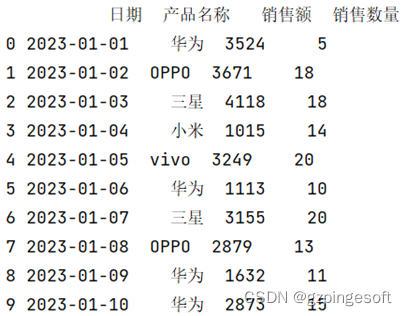
Pandas数据处理分析系列3-数据如何预览
Pandas-数据预览 Pandas 导入数据后,我们通常需要对数据进行预览,以便更好的进行数据分析。常见数据预览的方法如下: ①head() 方法 功能:读取数据的前几行,默认显示前5行 语法结构:df.head(行数) df1=pd.read_excel("销售表.xlsx",sheet_name="手机销…...

【汇编语言-王爽】第二章:寄存器
知识点 (一)寄存器 一个典型的CPU由运算器、控制器、寄存器等器件构成,这些器件靠内部总线相连。8086CPU有14个寄存器:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。其中AX、BX、CX、DX为通用寄存器,可…...
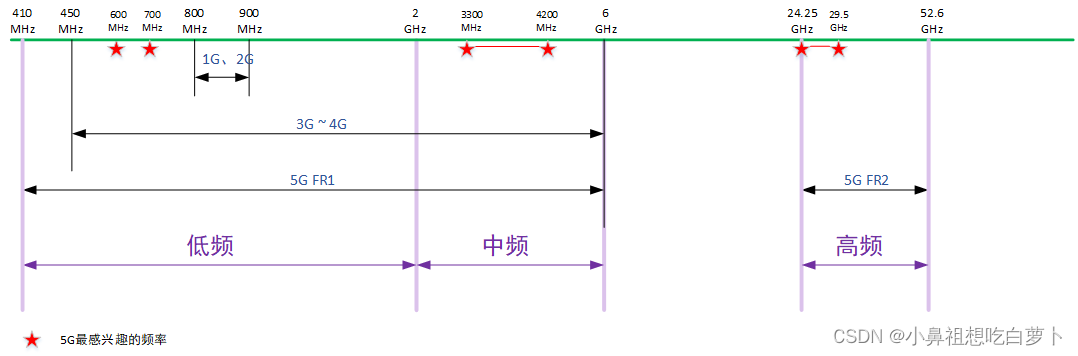
5G学习笔记之5G频谱
参考:《5G NR通信标准》1. 5G频谱 1G和2G移动业务的频段主要在800MHz~900MHz,存在少数在更高或者更低频段;3G和4G的频段主要在450MHz ~ 6GHz;5G主要是410MHz ~ 6GHz,以及24GHz ~ 52GHz。 5G频谱跨度较大,可…...

CSS 浮动布局
本文参考 https://blog.csdn.net/ZhangJiWei_2019/article/details/114669722 文档流简介 正常文档流 正常文档流,又称为“普通文档流”或“普通流”,也就是W3C标准所说的“normal flow”。 我们先来看一下正常文档流的简单定义:正常文档…...

CentOS 系统安装和使用Docker服务
系统环境 使用下面的命令,可以查看CentOS系统的版本。 lsb_release -a结果: 说明我的系统是7.9.2009版本的 安装Docker服务 依次执行下面的指令: yum install -y yum-utilsyum install -y docker即可安装docker服务 如果这样安装不成功…...
Docker-镜像的备份迁移及私有仓库的搭建
一、Docker-备份与迁移 A服务器系统配置 B服务器系统配置 1.用命令将容器保存为镜像。 案例,将A服务器的Docker容器迁移到另外一台服务器B,A服务器的容器配置过对应的文件,不想在B服务器重新搭建,可以使用该案例。 docker c…...
SQL数据库管理工具RazorSQL mac中文版特点与功能
RazorSQL mac是一款功能强大的SQL数据库管理工具,它支持多种数据库,包括MySQL、Oracle、Microsoft SQL Server、SQLite、PostgreSQL等。 RazorSQL mac 软件特点和功能 多种数据库支持:RazorSQL支持多种数据库,用户可以通过一个工…...

Unigui可以使用WebSocket进行客户端之间的实时互相发消息
Unigui可以使用WebSocket进行客户端之间的实时互相发消息。WebSocket是一种支持双向通信的网络协议,可以使客户端和服务器之间实时地进行数据交换。 实现步骤: 1. 在Unigui项目中添加WebSocket组件。 2. 在WebModule的OnCreate事件中开启WebSocket服务。 proced…...
Win32 简单日志实现
简单实现日志保存, 支持设置日志文件数量, 单个日志文件大小上限, 自动超时保存日志, 日志缓存超限保存 CLogUtils.h #pragma once#include <string> #include <windows.h> #include <vector> #include <map> #include <mutex> #include <tc…...

保姆级阿里云ESC服务器安装nodejs或Linux安装nodejs
1. 创建node文件夹 默认 /opt 下边 /opt/node 也可建到其他地方,如/usr/local/node 等 创建后切换到文件夹下 cd /opt/node cd /opt/node2. 下载node并解压 使用命令下载node wget https://nodejs.org/dist/v18.12.0/node-v18.12.0-linux-x64.tar.xz wget https…...

《动手学深度学习 Pytorch版》 9.3 深度循环神经网络
将多层循环神经网络堆叠在一起,通过对几个简单层的组合,产生一个灵活的机制。其中的数据可能与不同层的堆叠有关。 9.3.1 函数依赖关系 将深度架构中的函数依赖关系形式化,第 l l l 个隐藏层的隐状态表达式为: H t ( l ) ϕ l …...

2023-10-19 LeetCode每日一题(同积元组)
2023-10-19每日一题 一、题目编号 1726. 同积元组二、题目链接 点击跳转到题目位置 三、题目描述 给你一个由 不同 正整数组成的数组 nums ,请你返回满足 a * b c * d 的元组 (a, b, c, d) 的数量。其中 a、b、c 和 d 都是 nums 中的元素,且 a ! b…...
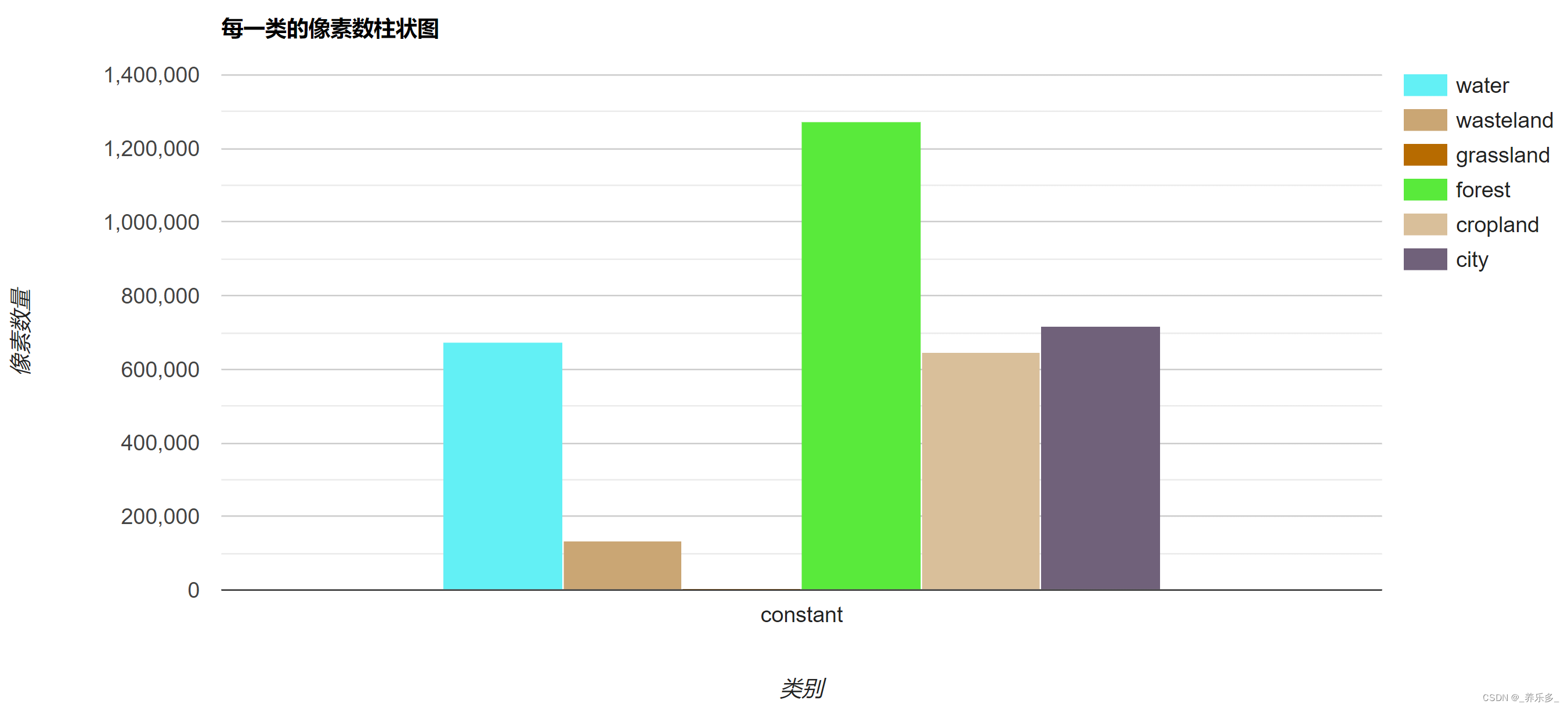
GEE:绘制土地利用类型面积分布柱状图
作者:CSDN @ _养乐多_ 本文记录了,在 Google Earth Engine (GEE)中进行随机森林分类后绘制不同类型面积分布柱状图的代码片段。 完整代码请看博客《GEE:随机森林分类教程(样本制作、特征添加、训练、精度、参数优化、贡献度、统计面积)》 柱状图效果如下所示, 文章目…...
2021年03月 Python(三级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python编程(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 下列代码的输出结果是?( ) x 0x10print(x)A:2 B:8 Cÿ…...

全网最丑焊锡教程(仅排针焊接心得)
一直以来玩各种开发板,焊接水平太差始终是阻碍我买性价比高的板子的最大原因。淘宝上好多芯片搭载上肥猪流板子是不包排针焊接的。终于下定决心要克服这个困难。不过,只是会焊接排针在高手面前最好不要说自己会焊锡,这应该是两码事。 首先上…...
重测序基因组:Pi核酸多样性计算
如何计算核酸多样性 Pi 本期笔记分享关于核酸多样性pi计算的方法和相关技巧,主要包括原始数据整理、分组文件设置、计算原理、操作流程、可视化绘图等步骤。 基因组Pi核酸多样性(Pi nucleic acid diversity)是一种遗传学研究中用来描述种群内…...

C++学习之多态详解
目录 多态的实现 例题 重载 重写 重定义的区别 抽象类 多态实现原理 多态的实现 C中的多态是指,当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。多态意味着调用成员函数时,会根据调用函数的对象的类型来执…...

139. 由于卸载Rancher主目录,恢复失败
访问Rancher-K8S解决方案博主,企业合作伙伴 : When attempting to restore an RKE2 cluster, it fails due to Rancher directories being unmounted by the rke2-killall.sh script. 当尝试恢复 RKE2 集群时,由于 rke2-killall.sh 脚本卸载…...

Revit插件开发进阶:如何设计一个专业且易用的Ribbon UI?聊聊按钮交互逻辑与用户体验
Revit插件开发进阶:专业Ribbon UI设计的交互逻辑与用户体验优化 在Revit二次开发领域,功能实现只是基础门槛,真正区分业余与专业插件的关键往往在于界面设计的专业度和用户体验的流畅性。许多开发者能够熟练调用API实现功能,却忽略…...

别再乱用OneHot编码了!用Pandas的get_dummies处理分类变量,这3个参数能帮你避开90%的坑
别再乱用OneHot编码了!用Pandas的get_dummies处理分类变量,这3个参数能帮你避开90%的坑 在数据科学项目中,分类变量的编码是特征工程中最容易被低估的环节之一。许多从业者习惯性地使用OneHotEncoder或简单调用pd.get_dummies(),却…...
)
Cadence IC617实战:手把手教你用Virtuoso仿真共源级放大器(含电阻负载分析)
Cadence IC617实战:手把手教你用Virtuoso仿真共源级放大器(含电阻负载分析) 在集成电路设计领域,掌握主流EDA工具的操作技巧是工程师的必备技能。作为业界标杆的Cadence Virtuoso平台,其IC617版本凭借稳定的性能和丰富…...

python argon2
## 关于 Python 中的 Argon2:一个密码哈希的现代选择 如果你写过需要处理用户密码的代码,肯定知道不能把密码原文存进数据库。早年很多系统用 MD5 或 SHA-1 这类快速哈希算法,后来大家发现这不够安全——显卡能每秒算几十亿次哈希,…...

别再只用平均值了!用Python的sklearn QuantileRegressor做分位数回归,预测区间更靠谱
分位数回归实战:用QuantileRegressor构建更可靠的预测区间 当我们在电商平台上预测下个季度的销售额时,传统线性回归给出的"平均预测值"往往让人心里没底——那些突然爆款的商品和滞销的长尾商品会让预测误差大得惊人。这时候,分位…...
KART-RERANK模型解析:深入理解Transformer在重排序任务中的应用
KART-RERANK模型解析:深入理解Transformer在重排序任务中的应用 如果你对搜索技术感兴趣,可能听说过BM25、TF-IDF这些传统排序算法。它们就像图书馆的老式卡片目录,能帮你找到相关书籍,但很难理解“深度学习在自然语言处理中的应…...

新手避坑指南:用PCF85063 RTC芯片搞定项目时间,从BCD码转换到寄存器配置详解
PCF85063 RTC芯片实战指南:从寄存器配置到时间管理全解析 在嵌入式系统开发中,精确的时间管理往往是项目成功的关键要素之一。无论是构建智能家居设备、工业传感器节点还是可穿戴设备,实时时钟(RTC)模块都扮演着不可或缺的角色。NXP的PCF8506…...

汽车嵌入式系统中安全状态机的设计与实现
1. 汽车嵌入式系统中的状态机安全实现概述在汽车电子控制单元(ECU)开发中,状态机是实现复杂控制逻辑的核心架构。以电子节气门控制系统为例,当驾驶员踩下油门踏板时,系统需要处理来自多个传感器的信号,经过状态判断后输出相应的控…...

DeepSeek-OCR-2轻松上手:解决文字识别痛点,提升工作效率实测
DeepSeek-OCR-2轻松上手:解决文字识别痛点,提升工作效率实测 1. 为什么你需要一个更好的OCR工具 如果你经常需要处理纸质文档、扫描件或者图片里的文字,肯定遇到过这样的烦恼:识别出来的文字错漏百出,格式乱七八糟&a…...