CUDA学习笔记(八)Branch Divergence and Unrolling Loop
Avoiding Branch Divergence
有时,控制流依赖于thread索引。同一个warp中,一个条件分支可能导致很差的性能。通过重新组织数据获取模式可以减少或避免warp divergence(该问题的解释请查看warp解析篇)。
The Parallel Reduction Problem
我们现在要计算一个数组N个元素的和。这个过程用CPU编程很容易实现:
int sum = 0;
for (int i = 0; i < N; i++)sum += array[i];那么如果Array的元素非常多呢?应用并行计算可以大大提升这个过程的效率。鉴于加法的交换律等性质,这个求和过程可以以元素的任意顺序来进行:
- 将输入数组切割成很多小的块。
- 用thread来计算每个块的和。
- 对这些块的结果再求和得最终结果。
数组的切割主旨是,用thread求数组中按一定规律配对的的两个元素和,然后将所有结果组合成一个新的数组,然后再次求配对两元素和,多次迭代,直到数组中只有一个结果。
比较直观的两种实现方式是:
- Neighbored pair:每次迭代都是相邻两个元素求和。
- Interleaved pair:按一定跨度配对两个元素。
下图展示了两种方式的求解过程,对于有N个元素的数组,这个过程需要N-1次求和,log(N)步。Interleaved pair的跨度是半个数组长度。

下面是用递归实现的interleaved pair代码(host):
int recursiveReduce(int *data, int const size) {// terminate checkif (size == 1) return data[0];// renew the strideint const stride = size / 2;// in-place reductionfor (int i = 0; i < stride; i++) {data[i] += data[i + stride];}// call recursivelyreturn recursiveReduce(data, stride);
}上述讲的这类问题术语叫reduction problem。Parallel reduction(并行规约)是指迭代减少操作,是并行算法中非常关键的一种操作。
在这个kernel里面,有两个global memory array,一个用来存放数组所有数据,另一个用来存放部分和。所有block独立的执行求和操作。__syncthreads(关于同步,请看前文)用来保证每次迭代,所有的求和操作都做完,然后进入下一步迭代。
__global__ void reduceNeighbored(int *g_idata, int *g_odata, unsigned int n) {// set thread IDunsigned int tid = threadIdx.x;// convert global data pointer to the local pointer of this blockint *idata = g_idata + blockIdx.x * blockDim.x;// boundary checkif (idx >= n) return;// in-place reduction in global memoryfor (int stride = 1; stride < blockDim.x; stride *= 2) {if ((tid % (2 * stride)) == 0) {idata[tid] += idata[tid + stride];}// synchronize within block__syncthreads();}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = idata[0];
}因为没有办法让所有的block同步,所以最后将所有block的结果送回host来进行串行计算,如下图所示:
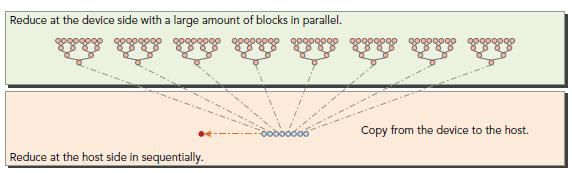
int main(int argc, char **argv) {
// set up device
int dev = 0;
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("%s starting reduction at ", argv[0]);
printf("device %d: %s ", dev, deviceProp.name);
cudaSetDevice(dev);
bool bResult = false;
// initialization
int size = 1<<24; // total number of elements to reduce
printf(" with array size %d ", size);
// execution configuration
int blocksize = 512; // initial block size
if(argc > 1) {
blocksize = atoi(argv[1]); // block size from command line argument
}
dim3 block (blocksize,1);
dim3 grid ((size+block.x-1)/block.x,1);
printf("grid %d block %d\n",grid.x, block.x);
// allocate host memory
size_t bytes = size * sizeof(int);
int *h_idata = (int *) malloc(bytes);
int *h_odata = (int *) malloc(grid.x*sizeof(int));
int *tmp = (int *) malloc(bytes);
// initialize the array
for (int i = 0; i < size; i++) {
// mask off high 2 bytes to force max number to 255
h_idata[i] = (int)(rand() & 0xFF);
}
memcpy (tmp, h_idata, bytes);
size_t iStart,iElaps;
int gpu_sum = 0;
// allocate device memory
int *d_idata = NULL;
int *d_odata = NULL;
cudaMalloc((void **) &d_idata, bytes);
cudaMalloc((void **) &d_odata, grid.x*sizeof(int));
// cpu reduction
iStart = seconds ();
int cpu_sum = recursiveReduce(tmp, size);
iElaps = seconds () - iStart;
printf("cpu reduce elapsed %d ms cpu_sum: %d\n",iElaps,cpu_sum);
// kernel 1: reduceNeighbored
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
iStart = seconds ();
warmup<<<grid, block>>>(d_idata, d_odata, size);
cudaDeviceSynchronize();
iElaps = seconds () - iStart;
cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i=0; i<grid.x; i++) gpu_sum += h_odata[i];
printf("gpu Warmup elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n",
iElaps,gpu_sum,grid.x,block.x);
// kernel 1: reduceNeighbored
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
iStart = seconds ();
reduceNeighbored<<<grid, block>>>(d_idata, d_odata, size);
cudaDeviceSynchronize();
iElaps = seconds () - iStart;
cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i=0; i<grid.x; i++) gpu_sum += h_odata[i];
printf("gpu Neighbored elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n",
iElaps,gpu_sum,grid.x,block.x);
cudaDeviceSynchronize();
iElaps = seconds() - iStart;
cudaMemcpy(h_odata, d_odata, grid.x/8*sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x / 8; i++) gpu_sum += h_odata[i];
printf("gpu Cmptnroll elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n",
iElaps,gpu_sum,grid.x/8,block.x);
/// free host memory
free(h_idata);
free(h_odata);
// free device memory
cudaFree(d_idata);
cudaFree(d_odata);
// reset device
cudaDeviceReset();
// check the results
bResult = (gpu_sum == cpu_sum);
if(!bResult) printf("Test failed!\n");
return EXIT_SUCCESS;
}初始化数组,使其包含16M元素:
int size = 1<<24;
kernel配置为1D grid和1D block:
dim3 block (blocksize, 1); dim3 block ((siize + block.x – 1) / block.x, 1);
编译:
$ nvcc -O3 -arch=sm_20 reduceInteger.cu -o reduceInteger
运行:
$ ./reduceInteger starting reduction at device 0: Tesla M2070 with array size 16777216 grid 32768 block 512 cpu reduce elapsed 29 ms cpu_sum: 2139353471 gpu Neighbored elapsed 11 ms gpu_sum: 2139353471 <<<grid 32768 block 512>>> Improving Divergence in Parallel Reduction
考虑上节if判断条件:
if ((tid % (2 * stride)) == 0)
因为这表达式只对偶数ID的线程为true,所以其导致很高的divergent warps。第一次迭代只有偶数ID的线程执行了指令,但是所有线程都要被调度;第二次迭代,只有四分之的thread是active的,但是所有thread仍然要被调度。我们可以重新组织每个线程对应的数组索引来强制ID相邻的thread来处理求和操作。如下图所示(注意途中的Thread ID与上一个图的差别):
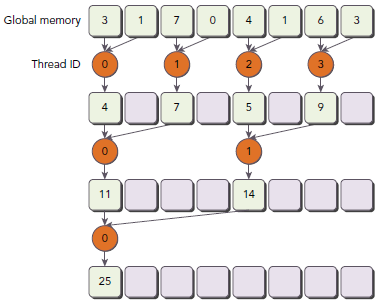
新的代码:
__global__ void reduceNeighboredLess (int *g_idata, int *g_odata, unsigned int n) {// set thread IDunsigned int tid = threadIdx.x;unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;// convert global data pointer to the local pointer of this blockint *idata = g_idata + blockIdx.x*blockDim.x;// boundary checkif(idx >= n) return;// in-place reduction in global memoryfor (int stride = 1; stride < blockDim.x; stride *= 2) {// convert tid into local array indexint index = 2 * stride * tid;if (index < blockDim.x) {idata[index] += idata[index + stride];} // synchronize within threadblock__syncthreads();}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = idata[0];
}注意这行代码:
int index = 2 * stride * tid;
因为步调乘以了2,下面的语句使用block的前半部分thread来执行求和:
if (index < blockDim.x)
对于一个有512个thread的block来说,前八个warp执行第一轮reduction,剩下八个warp什么也不干;第二轮,前四个warp执行,剩下十二个什么也不干。因此,就彻底不存在divergence了(重申,divergence只发生于同一个warp)。最后的五轮还是会导致divergence,因为这个时候需要执行threads已经凑不够一个warp了。
// kernel 2: reduceNeighbored with less divergence
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
iStart = seconds();
reduceNeighboredLess<<<grid, block>>>(d_idata, d_odata, size);
cudaDeviceSynchronize();
iElaps = seconds() - iStart;
cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i=0; i<grid.x; i++) gpu_sum += h_odata[i];
printf("gpu Neighbored2 elapsed %d ms gpu_sum: %d <<<grid %d block %d>>>\n",iElaps,gpu_sum,grid.x,block.x);运行结果:
$ ./reduceInteger Starting reduction at device 0: Tesla M2070
vector size 16777216 grid 32768 block 512
cpu reduce elapsed 0.029138 sec cpu_sum: 2139353471
gpu Neighbored elapsed 0.011722 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>
gpu NeighboredL elapsed 0.009321 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>新的实现比原来的快了1.26。我们也可以使用nvprof的inst_per_warp参数来查看每个warp上执行的指令数目的平均值。
$ nvprof --metrics inst_per_warp ./reduceInteger
输出,原来的是新的kernel的两倍还多,因为原来的有许多不必要的操作也执行了:
Neighbored Instructions per warp 295.562500 NeighboredLess Instructions per warp 115.312500
再查看throughput:
$ nvprof --metrics gld_throughput ./reduceInteger
输出,新的kernel拥有更大的throughput,因为虽然I/O操作数目相同,但是其耗时短:
Neighbored Global Load Throughput 67.663GB/s NeighboredL Global Load Throughput 80.144GB/s Reducing with Interleaved Pairs
Interleaved Pair模式的初始步调是block大小的一半,每个thread处理像个半个block的两个数据求和。和之前的图示相比,工作的thread数目没有变化,但是,每个thread的load/store global memory的位置是不同的。
Interleaved Pair的kernel实现:
/// Interleaved Pair Implementation with less divergence
__global__ void reduceInterleaved (int *g_idata, int *g_odata, unsigned int n) {
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x;
// boundary check
if(idx >= n) return;
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
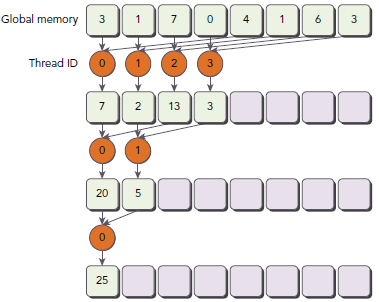
注意下面的语句,步调被初始化为block大小的一半:
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
下面的语句使得第一次迭代时,block的前半部分thread执行相加操作,第二次是前四分之一,以此类推:
if (tid < stride)
下面是加入main的代码:
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
iStart = seconds();
reduceInterleaved <<< grid, block >>> (d_idata, d_odata, size);
cudaDeviceSynchronize();
iElaps = seconds() - iStart;
cudaMemcpy(h_odata, d_odata, grid.x*sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++) gpu_sum += h_odata[i];
printf("gpu Interleaved elapsed %f sec gpu_sum: %d <<<grid %d block %d>>>\n",iElaps,gpu_sum,grid.x,block.x);运行输出
$ ./reduce starting reduction at device 0: Tesla M2070
with array size 16777216 grid 32768 block 512
cpu reduce elapsed 0.029138 sec cpu_sum: 2139353471
gpu Warmup elapsed 0.011745 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>
gpu Neighbored elapsed 0.011722 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>
gpu NeighboredL elapsed 0.009321 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>
gpu Interleaved elapsed 0.006967 sec gpu_sum: 2139353471 <<<grid 32768 block 512>>>这次相对第一个kernel又快了1.69,比第二个也快了1.34。这个效果主要由global memory的load/store模式导致的(这部分知识将在后续博文介绍)。
UNrolling Loops
loop unrolling 是用来优化循环减少分支的方法,该方法简单说就是把本应在多次loop中完成的操作,尽量压缩到一次loop。循环体展开程度称为loop unrolling factor(循环展开因子),loop unrolling对顺序数组的循环操作性能有很大影响,考虑如下代码:
for (int i = 0; i < 100; i++) {a[i] = b[i] + c[i];
}
如下重复一次循环体操作,迭代数目将减少一半:
for (int i = 0; i < 100; i += 2) {a[i] = b[i] + c[i];a[i+1] = b[i+1] + c[i+1];
}
从高级语言层面是无法看出性能提升的原因的,需要从low-level instruction层面去分析,第二段代码循环次数减少了一半,而循环体两句语句的读写操作的执行在CPU上是可以同时执行互相独立的,所以相对第一段,第二段性能要好。
Unrolling 在CUDA编程中意义更重。我们的目标依然是通过减少指令执行消耗,增加更多的独立指令来提高性能。这样就会增加更多的并行操作从而产生更高的指令和内存带宽(bandwidth)。也就提供了更多的eligible warps来帮助hide instruction/memory latency 。
Reducing with Unrolling
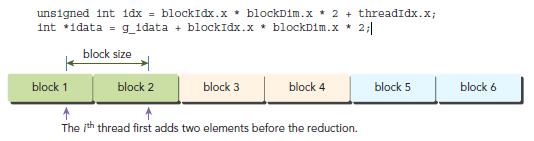
在前文的reduceInterleaved中,每个block处理一部分数据,我们给这数据起名data block。下面的代码是reduceInterleaved的修正版本,每个block,都是以两个data block作为源数据进行操作,(前文中,每个block处理一个data block)。这是一种cyclic partitioning:每个thread作用于多个data block,并且从每个data block中取出一个元素处理。
__global__ void reduceUnrolling2 (int *g_idata, int *g_odata, unsigned int n) {// set thread IDunsigned int tid = threadIdx.x;unsigned int idx = blockIdx.x * blockDim.x * 2 + threadIdx.x;// convert global data pointer to the local pointer of this blockint *idata = g_idata + blockIdx.x * blockDim.x * 2;// unrolling 2 data blocksif (idx + blockDim.x < n) g_idata[idx] += g_idata[idx + blockDim.x];__syncthreads();// in-place reduction in global memoryfor (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {if (tid < stride) {idata[tid] += idata[tid + stride];}// synchronize within threadblock__syncthreads();}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = idata[0];
}注意下面的语句,每个thread从相邻的data block中取数据,这一步实际上就是将两个data block规约成一个。
if (idx + blockDim.x < n) g_idata[idx] += g_idata[idx+blockDim.x];
global array index也要相应的调整,因为,相对之前的版本,同样的数据,我们只需要原来一半的thread就能解决问题。要注意的是,这样做也会降低warp或block的并行性(因为thread少啦):
main增加下面代码:
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
iStart = seconds();
reduceUnrolling2 <<< grid.x/2, block >>> (d_idata, d_odata, size);
cudaDeviceSynchronize();
iElaps = seconds() - iStart;
cudaMemcpy(h_odata, d_odata, grid.x/2*sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x / 2; i++) gpu_sum += h_odata[i];
printf("gpu Unrolling2 elapsed %f sec gpu_sum: %d <<<grid %d block %d>>>\n",iElaps,gpu_sum,grid.x/2,block.x);由于每个block处理两个data block,所以需要调整grid的配置:
reduceUnrolling2<<<grid.x / 2, block>>>(d_idata, d_odata, size);
运行输出:
gpu Unrolling2 elapsed 0.003430 sec gpu_sum: 2139353471 <<<grid 16384 block 512>>>
这样一次简单的操作就比原来的减少了3.42。我们在试试每个block处理4个和8个data block的情况:
reduceUnrolling4 : each threadblock handles 4 data blocks
reduceUnrolling8 : each threadblock handles 8 data blocks
加上这两个的输出是:
gpu Unrolling2 elapsed 0.003430 sec gpu_sum: 2139353471 <<<grid 16384 block 512>>> gpu Unrolling4 elapsed 0.001829 sec gpu_sum: 2139353471 <<<grid 8192 block 512>>> gpu Unrolling8 elapsed 0.001422 sec gpu_sum: 2139353471 <<<grid 4096 block 512>>>
可以看出,同一个thread中如果能有更多的独立的load/store操作,会产生更好的性能,因为这样做memory latency能够更好的被隐藏。我们可以使用nvprof的dram_read_throughput来验证:
$ nvprof --metrics dram_read_throughput ./reduceInteger
下面是输出结果,我们可以得出这样的结论,device read throughtput和unrolling程度是正比的:
Unrolling2 Device Memory Read Throughput 26.295GB/s Unrolling4 Device Memory Read Throughput 49.546GB/s Unrolling8 Device Memory Read Throughput 62.764GB/s Reducinng with Unrolled Warps
__syncthreads是用来同步block内部thread的(请看warp解析篇)。在reduction kernel中,他被用来在每次循环中年那个保证所有thread的写global memory的操作都已完成,这样才能进行下一阶段的计算。
那么,当kernel进行到只需要少于或等32个thread(也就是一个warp)呢?由于我们是使用的SIMT模式,warp内的thread 是有一个隐式的同步过程的。最后六次迭代可以用下面的语句展开:
if (tid < 32) {volatile int *vmem = idata;vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];
}warp unrolling避免了__syncthreads同步操作,因为这一步本身就没必要。
这里注意下volatile修饰符,他告诉编译器每次执行赋值时必须将vmem[tid]的值store回global memory。如果不这样做的话,编译器或cache可能会优化我们读写global/shared memory。有了这个修饰符,编译器就会认为这个值会被其他thread修改,从而使得每次读写都直接去memory而不是去cache或者register。
__global__ void reduceUnrollWarps8 (int *g_idata, int *g_odata, unsigned int n) {// set thread IDunsigned int tid = threadIdx.x;unsigned int idx = blockIdx.x*blockDim.x*8 + threadIdx.x;// convert global data pointer to the local pointer of this blockint *idata = g_idata + blockIdx.x*blockDim.x*8;// unrolling 8if (idx + 7*blockDim.x < n) {int a1 = g_idata[idx];int a2 = g_idata[idx+blockDim.x];int a3 = g_idata[idx+2*blockDim.x];int a4 = g_idata[idx+3*blockDim.x];int b1 = g_idata[idx+4*blockDim.x];int b2 = g_idata[idx+5*blockDim.x];int b3 = g_idata[idx+6*blockDim.x];int b4 = g_idata[idx+7*blockDim.x];g_idata[idx] = a1+a2+a3+a4+b1+b2+b3+b4;}__syncthreads();// in-place reduction in global memoryfor (int stride = blockDim.x / 2; stride > 32; stride >>= 1) {if (tid < stride) {idata[tid] += idata[tid + stride];}// synchronize within threadblock__syncthreads();}// unrolling warpif (tid < 32) {volatile int *vmem = idata;vmem[tid] += vmem[tid + 32];vmem[tid] += vmem[tid + 16];vmem[tid] += vmem[tid + 8];vmem[tid] += vmem[tid + 4];vmem[tid] += vmem[tid + 2];vmem[tid] += vmem[tid + 1];}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = idata[0];
}因为处理的data block变为八个,kernel调用变为;
reduceUnrollWarps8<<<grid.x / 8, block>>> (d_idata, d_odata, size);
这次执行结果比reduceUnnrolling8快1.05,比reduceNeighboured快8,65:
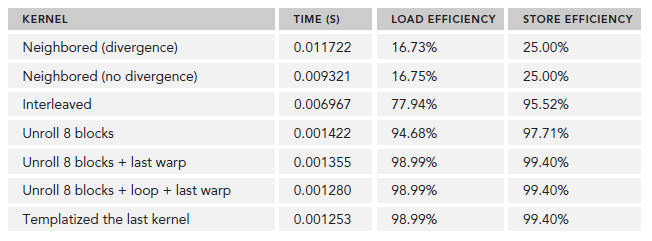
gpu UnrollWarp8 elapsed 0.001355 sec gpu_sum: 2139353471 <<<grid 4096 block 512>>>
nvprof的stall_sync可以用来验证由于__syncthreads导致更少的warp阻塞了:
$ nvprof --metrics stall_sync ./reduce Unrolling8 Issue Stall Reasons 58.37% UnrollWarps8 Issue Stall Reasons 30.60% Reducing with Complete Unrolling
如果在编译时已知了迭代次数,就可以完全把循环展开。Fermi和Kepler每个block的最大thread数目都是1024,博文中的kernel的迭代次数都是基于blockDim的,所以完全展开循环是可行的。
__global__ void reduceCompleteUnrollWarps8 (int *g_idata, int *g_odata,
unsigned int n) {// set thread IDunsigned int tid = threadIdx.x;unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;// convert global data pointer to the local pointer of this blockint *idata = g_idata + blockIdx.x * blockDim.x * 8;// unrolling 8if (idx + 7*blockDim.x < n) {int a1 = g_idata[idx];int a2 = g_idata[idx + blockDim.x];int a3 = g_idata[idx + 2 * blockDim.x];int a4 = g_idata[idx + 3 * blockDim.x];int b1 = g_idata[idx + 4 * blockDim.x];int b2 = g_idata[idx + 5 * blockDim.x];int b3 = g_idata[idx + 6 * blockDim.x];int b4 = g_idata[idx + 7 * blockDim.x];g_idata[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;}__syncthreads();// in-place reduction and complete unrollif (blockDim.x>=1024 && tid < 512) idata[tid] += idata[tid + 512];__syncthreads();if (blockDim.x>=512 && tid < 256) idata[tid] += idata[tid + 256];__syncthreads();if (blockDim.x>=256 && tid < 128) idata[tid] += idata[tid + 128];__syncthreads();if (blockDim.x>=128 && tid < 64) idata[tid] += idata[tid + 64];__syncthreads();// unrolling warpif (tid < 32) {volatile int *vsmem = idata;vsmem[tid] += vsmem[tid + 32];vsmem[tid] += vsmem[tid + 16];vsmem[tid] += vsmem[tid + 8];vsmem[tid] += vsmem[tid + 4];vsmem[tid] += vsmem[tid + 2];vsmem[tid] += vsmem[tid + 1];}// write result for this block to global memif (tid == 0) g_odata[blockIdx.x] = idata[0];
}main中调用:
reduceCompleteUnrollWarps8<<<grid.x / 8, block>>>(d_idata, d_odata, size);
速度再次提升:
gpu CmptUnroll8 elapsed 0.001280 sec gpu_sum: 2139353471 <<<grid 4096 block 512>>>
Reducing with Templete Functions
CUDA代码支持模板,我们可以如下设置block大小:
template <unsigned int iBlockSize>
__global__ void reduceCompleteUnroll(int *g_idata, int *g_odata, unsigned int n) {
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 8;// unrolling 8
if (idx + 7*blockDim.x < n) {
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int b1 = g_idata[idx + 4 * blockDim.x];
int b2 = g_idata[idx + 5 * blockDim.x];
int b3 = g_idata[idx + 6 * blockDim.x];
int b4 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1+a2+a3+a4+b1+b2+b3+b4;
}
__syncthreads();// in-place reduction and complete unroll
if (iBlockSize>=1024 && tid < 512) idata[tid] += idata[tid + 512];
__syncthreads();if (iBlockSize>=512 && tid < 256) idata[tid] += idata[tid + 256];
__syncthreads();if (iBlockSize>=256 && tid < 128) idata[tid] += idata[tid + 128];
__syncthreads();if (iBlockSize>=128 && tid < 64) idata[tid] += idata[tid + 64];
__syncthreads();// unrolling warp
if (tid < 32) {
volatile int *vsmem = idata;
vsmem[tid] += vsmem[tid + 32];
vsmem[tid] += vsmem[tid + 16];
vsmem[tid] += vsmem[tid + 8];
vsmem[tid] += vsmem[tid + 4];
vsmem[tid] += vsmem[tid + 2];
vsmem[tid] += vsmem[tid + 1];
}// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}
对于if的条件,如果值为false,那么在编译时就会去掉该语句,这样效率更好。例如,如果调用kernel时的blocksize是256,那么,下面的语句将永远为false,编译器会将他移除不予执行:
IBlockSize>=1024 && tid < 512
这个kernel必须以一个switch-case来调用:
switch (blocksize) {case 1024:reduceCompleteUnroll<1024><<<grid.x/8, block>>>(d_idata, d_odata, size);break;case 512:reduceCompleteUnroll<512><<<grid.x/8, block>>>(d_idata, d_odata, size);break;case 256:reduceCompleteUnroll<256><<<grid.x/8, block>>>(d_idata, d_odata, size);break;case 128:reduceCompleteUnroll<128><<<grid.x/8, block>>>(d_idata, d_odata, size);break;case 64:reduceCompleteUnroll<64><<<grid.x/8, block>>>(d_idata, d_odata, size);break;
}各种情况下,执行后的结果为:

$nvprof --metrics gld_efficiency,gst_efficiency ./reduceInteger
相关文章:
CUDA学习笔记(八)Branch Divergence and Unrolling Loop
Avoiding Branch Divergence 有时,控制流依赖于thread索引。同一个warp中,一个条件分支可能导致很差的性能。通过重新组织数据获取模式可以减少或避免warp divergence(该问题的解释请查看warp解析篇)。 The Parallel Reduction …...
Android MQTT连接阿里云使用Json解析数据
Android Studio 连接阿里云订阅主题然后使用JSON解析数据非常好用 导入MQTT的JAR包1、在项目中添加依赖然后使用Studio 去下载库2、直接下载JAR包,然后作为库进行导入 环境验证:给程序进行联网权限XML布局文件效果如下: MainActitive.java 主…...
生成二维码
Qt本地生成二维码-第三方库Libqrencode Chapter1 Qt本地生成二维码-第三方库Libqrencode一、功能简介二、本地生成二维码三、在线生成二维码 Chapter2 Qt生成二维码图片方法QRCode二维码简介如何选定QR码版本?主要方法(1) 下载qrencode源码(2) 将qrencode源码移植到…...

【C++入门 一 】学习C++背景、开启C++奇妙之旅
目录 1.什么是C2. C的发展史3. C的重要性3.1 语言的使用广泛度3.2 在工作领域1. 操作系统以及大型系统软件开发2. 服务器端开发3. 游戏开发4. 嵌入式和物联网领域5. 数字图像处理6. 人工智能7. 分布式应用 3.3 在校招领域3.3.1 岗位需求3.3.2 笔试题 4. 如何学习C4.1 别人怎么学…...
oracle 表空间详解以及配置操作
Oracle 数据库是由若干个表空间构成的。任何数据库对象在存储时都必须存储在某个 表空间中。表空间对应于若干个数据文件,即表空间是由一个或多个数据文件构成的。 1、常用表空间: 系统表空间 (system tablespace) 是每个 Oracle 数据库都必须具备的。…...

php判断是否是email格式
要判断一个字符串是否是有效的电子邮件地址,你可以使用正则表达式和PHP内置函数来完成。以下是一个示例代码: $email "exampleexample.com"; // 你要检查的电子邮件地址// 使用正则表达式检查电子邮件格式 if (filter_var($email, FILTER_VA…...

AJAX与JSON
1.AJAX 1.AJAX概述 AJAX(Asynchronous JavaScript And XML):异步的 JavaScript 和 XML 本身不是一种新技术,而是多个技术综合。用于快速创建动态网页的技术 一般的网页如果需要更新内容,必需重新加载个页面。 而 Ajax通过浏览器与服务器…...
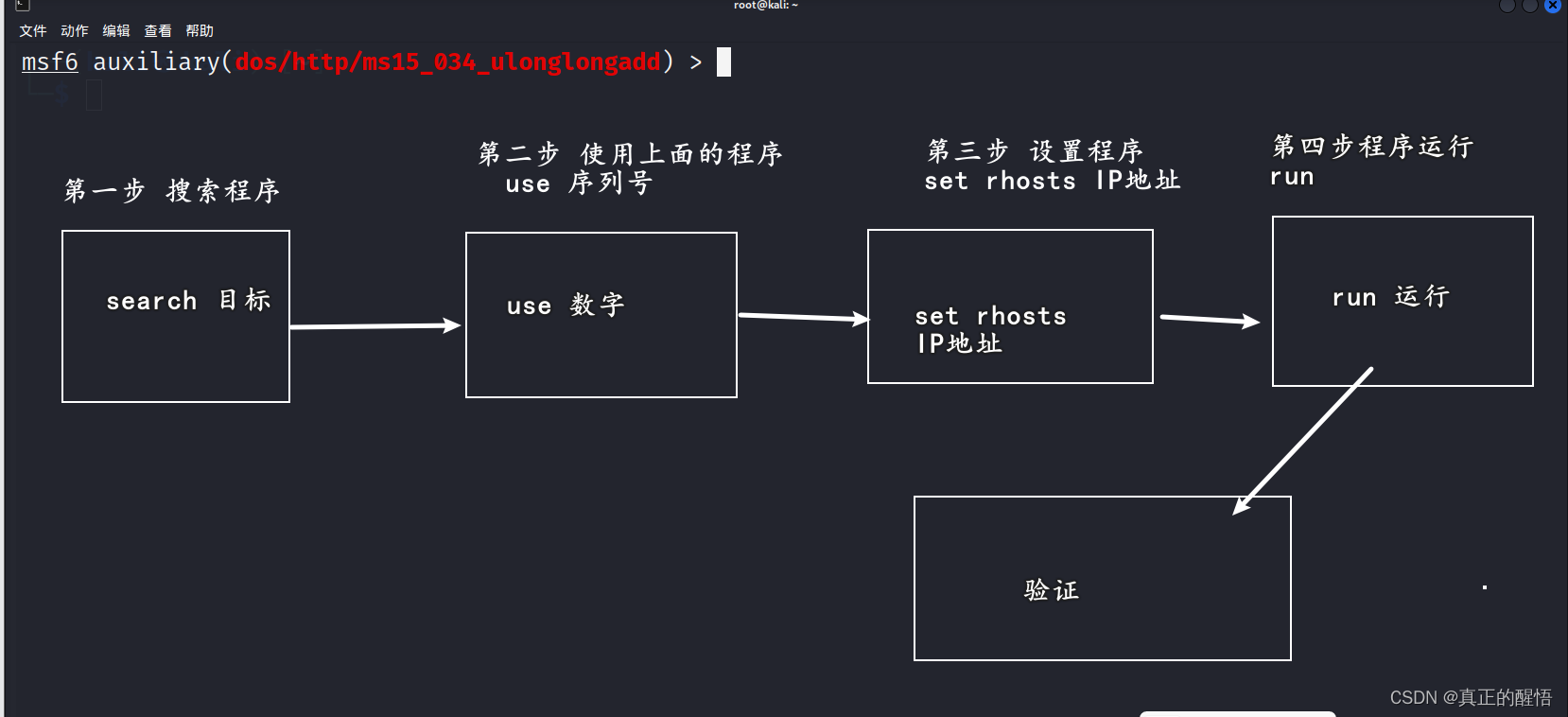
1024常玩到的漏洞(第十六课)
1024常玩到的两个漏洞(第十六课) 漏洞扫描工具 1024渗透OpenVas扫描工具使用(第十四课)-CSDN博客 流程 一 ms12-020漏洞分析 MS12-020漏洞是一种远程桌面协议(RDP)漏洞。在攻击者利用该漏洞之前,它需要将攻击者的计算机连接到受害者的计算机上。攻击者可以通过向受害者计算…...
)
【Edabit 算法 ★★★★★★】【两个大整数相加】Recursion: Sum of Two Numbers (With A Twist!)
Recursion: Sum of Two Numbers (With A Twist!) Instructions This is an “expert” challenge!!! Why is a sum of two numbers an “expert” challenge!!! Well, the numbers can have 1000 digits or even beyond such count… So, what’s the twist? You have to do …...

电容屏物体识别手工制作
电容屏识别物体效果2 电容屏识别物体效果1 电容屏识别物体效果3 电容屏识别物体效果4 电容识别物理效果5 我们感兴趣的是找到让我们的平面屏幕与物理三维物体和表面交互的方法。 触摸屏无处不在,成千上万的应用程序中有多种设备和屏幕格式,但我们只找到…...

13JVM进阶
JVM内存模型 1、线程私有的数据区 1)、程序计数器 我们知道,线程是CPU调度的基本单位。在多线程情况下,当线程数超过CPU数量或CPU内核数量时,线程之间就要根据 时间片轮询抢夺CPU时间资源。也就是说,在任何一个确定的时刻&#…...

java与c++中的交换方法
最近在写算法的时候,遇到一个问题。 java中编写swap(交换)方法还需要传入一个数组,但是在c中则不需要。 可以看到,在没有传入数组进行交换数组元素的时候,交换前与交换后的值是一样的。 而在c中ÿ…...
OpenCV中world模块介绍
OpenCV中有很多模块,模块间保持最小的依赖关系,用户可以根据自己的实际需要链接相关的库,而不需链接所有的库,这样在最终交付应用程序时可以减少总库的大小。但如果需要依赖OpenCV的库太多,有时会带来不方便,此时可以使…...

IMX6ULL板开发——第一个应用程序
实现第一个应用程序:在IMX6ULL开发板上运行程序hello.c #include <stdio.h>/* 执行命令: ./hello weidongshan* argc 2* argv[0] ./hello* argv[1] weidongshan*/int main(int argc, char **argv) {if (argc > 2)printf("Hello, %s!\n", arg…...

MyBatis Generator - 快速生成 实体类 和 映射文件
目录 一、MyBatis Generator 的使用 1.1、生成类和映射文件 1.1.1、在 pom.xml 中引入依赖 1.1.2、根据 configurationFile 标签中配置的路径 创建 generatorConfig.xml 文件 1.1.3、自动生成类 和 映射文件 1.1.4、在 Insert 标签中添加获取主键值的选项 1.1.5、扫描配置…...
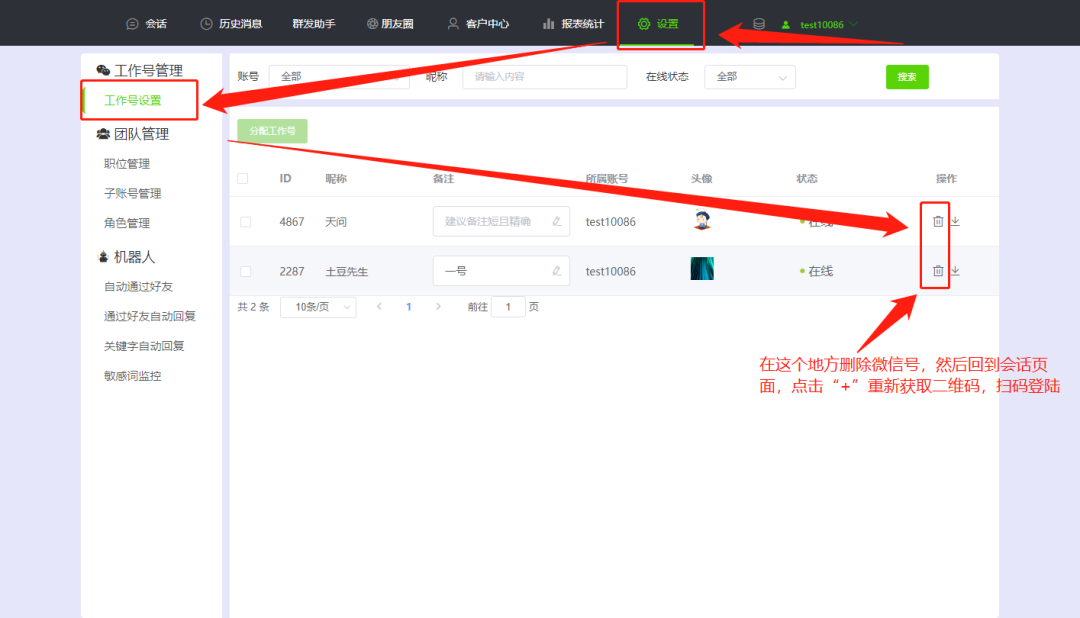
点击查看详情 | 网页版微信客户管理系统如何操作试用?
微信作为我们日常生活中最常用的社交应用之一,早已成为我们与朋友、家人和同事保持联系的重要工具,也是营销引流的重要平台。 通过微信营销,可以比较精准定向亲近用户。而微信的功能并没有很能满足做微信营销的人群,所以我们需要借…...

新加坡攻略
文章目录 基础信息入境行李App电信交通餐饮购物法规旅游牛车水(Chinatown)克拉码头(Clarke Quay)东海岸(East Coast)丹戎巴葛(Tanjong Pagar)滨海湾(Marina Bayÿ…...
AM@导数的应用@二阶导数的应用@函数的性态研究@函数图形的绘制
文章目录 概念称呼说明驻点极值和极值点最值极值点和最值比较曲线的凹凸性凹凸性判定定理👺例证明 凹凸性和单调性无必然关系拐点寻找拐点👺 函数图形的绘制例 概念 本文讨论导数的应用:利用导数研究函数的性态相关定理主要通过Lagrange中值定理进行推导…...

【2024秋招】2023-9-14 最右后端开发线下一面
1 自我介绍 2 计算机网络 2.1 说说你对tcp滑动窗口的理解 TCP 滑动窗口是 TCP 协议流量控制的一个重要机制。它的主要目的是确保发送方不会因为发送太多数据而使接收方不堪重负。下面我会详细地描述滑动窗口的概念: 窗口的大小: 滑动窗口的大小&#…...
uniapp无感刷新token实现过程
路漫漫其修远兮,前端道路逐渐迷茫,时隔好久好久终于想起了我还有一个小博客,最近在一直在弄uniapp,属实有被恶心到,但也至少会用了,最近实现了一个比较通用的功能,就是无感刷新token,…...

NaViL-9B图文问答指南:如何构造高质量prompt提升识别准确率
NaViL-9B图文问答指南:如何构造高质量prompt提升识别准确率 1. 认识NaViL-9B多模态模型 NaViL-9B是上海人工智能实验室研发的原生多模态大语言模型,它不仅能处理纯文本问答,还具备强大的图片理解能力。这意味着你可以上传一张图片ÿ…...

Qwen3.5-9B-AWQ-4bit效果展示:复杂场景图识别准确率实测与典型失败案例复盘
Qwen3.5-9B-AWQ-4bit效果展示:复杂场景图识别准确率实测与典型失败案例复盘 1. 模型能力概览 Qwen3.5-9B-AWQ-4bit是一款支持图像理解的多模态模型,能够结合上传图片与文字提示词输出中文分析结果。这个量化版本在保持较高识别准确率的同时,…...
Pixel Couplet Gen 惊艳作品集:算法驱动下的传统年俗像素艺术
Pixel Couplet Gen 惊艳作品集:算法驱动下的传统年俗像素艺术 1. 当传统年俗遇上像素艺术 春节贴春联是中国人延续千年的文化传统,而如今,这项传统正在与数字艺术碰撞出新的火花。Pixel Couplet Gen模型通过算法创新,将传统春联…...

Keil5开发STM32的AI伙伴:Phi-4-mini-reasoning辅助嵌入式代码编写
Keil5开发STM32的AI伙伴:Phi-4-mini-reasoning辅助嵌入式代码编写 1. 为什么需要AI辅助嵌入式开发 嵌入式开发向来以门槛高著称,特别是STM32这类ARM架构的MCU开发。寄存器配置复杂、外设驱动繁琐、调试过程耗时,这些问题让不少开发者头疼。…...

影墨·今颜小红书算法洞察:‘神韵强度’参数如何动态调节LoRA注入权重
影墨今颜小红书算法洞察:‘神韵强度’参数如何动态调节LoRA注入权重 1. 引言:从“塑料感”到“呼吸感”的跃迁 如果你玩过AI生成人像,大概率遇到过这样的困扰:生成的人像乍一看很美,但细看总觉得哪里不对劲——皮肤过…...

AirPodsDesktop终极指南:让苹果耳机在Windows上重获新生
AirPodsDesktop终极指南:让苹果耳机在Windows上重获新生 【免费下载链接】AirPodsDesktop ☄️ AirPods desktop user experience enhancement program, for Windows and Linux (WIP) 项目地址: https://gitcode.com/gh_mirrors/ai/AirPodsDesktop 还在为Win…...

信息学奥赛一本通 1248:Dungeon Master | 三维迷宫搜索算法精讲
1. 三维迷宫搜索算法入门:从Dungeon Master开始 第一次看到《Dungeon Master》这个题目时,我完全被三维迷宫的概念震撼到了。相比常见的二维迷宫,这个题目要求我们在一个立体的空间中寻找最短路径,就像被困在一个真实的地牢里一样…...

WebPlotDigitizer:科研图表数据提取的终极指南,效率提升700%
WebPlotDigitizer:科研图表数据提取的终极指南,效率提升700% 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 你…...

技术速递|GitHub Copilot CLI 结合多模型能力提供“第二视角”
作者:Nick McKenna & Bartek Perz 排版:Alan Wang 了解 Rubber Duck 如何为 GitHub Copilot CLI 带来不同的思路与视角。 当你让一个编码智能体构建数据管道时,它未必会采用最优结构。但如果在执行方案之前,让它先获得“第二视…...

通信标准11之HARQ-ACK码本:从Type-1到Type-3的演进与实战解析
1. HARQ-ACK码本:5G通信的"确认回执"系统 想象一下你在网购时,每收到一个包裹都要给卖家发一条确认短信。HARQ-ACK码本就是5G通信系统中的这种"确认回执"机制,只不过它的复杂度和智能化程度远超普通快递通知。作为通信标…...