Elasticsearch的聚集统计,可以进行各种统计分析
说明: Elasticsearch不仅是一个大数据搜索引擎,也是一个大数据分析引擎。它的聚集(aggregation)统计的REST端点可用于实现与统计分析有关的功能。Elasticsearch提供的聚集分为三大类。
- 度量聚集(Metric aggregation):度量聚集可以用于计算搜索结果在某个字段上的数量统计指标,比如平均值、最大值、最小值、总和等。
- 桶聚集(Bucket aggregation):桶聚集可以在某个字段上划定一些区间,每个区间是一个“桶”,然后按照搜索结果的文档内容把文档归类到它所属的桶中,统计的结果能明确每个桶中有多少文档。桶聚集还可以嵌套其他的桶聚集或者度量聚集来进行一些复杂的指标计算。
- 管道聚集(Pipeline aggregation):管道聚集就是把桶聚集统计的结果作为输入来继续做聚集统计,会在桶聚集的结果中追加一些额外的统计数据。
1.1、平均值聚集
平均值聚集用来计算索引中某个数值字段的平均值,对索引sougoulog的字段rank求平均值的聚集请求如下。
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"rank_avg": {"avg": {"field": "rank","missing": 0}}}
}
在这个请求中,aggs的参数使用了一个类型为avg的聚集,它会对rank字段求平均值,请求中的missing参数表示如果遇到rank字段为null的文档,则当作0计算。这一聚集被命名为rank_avg,当然得新建索引,添加数据。
1.2 最大值和最小值聚集
使用最大值和最小值聚集可以快速地得到搜索结果中某个数值字段的最大值、最小值,例如,获取rank字段的最大值的请求如下。
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"rank_max": {"max": {"field": "rank","missing": 0}}}
}
同理,如果要得到rank字段的最小值,把聚集类型设置为min即可。
1.3 求和聚集
与平均值聚集类似,求和聚集可以让搜索结果在某个数值字段上求和。
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"rank_sum": {"sum": {"field": "rank","missing": 0}}}
}
1.4 统计聚集统计
聚集可以一次性返回搜索结果在某个数值字段上的最大值、最小值、平均值、个数、总和。
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"rank_stats": {"stats": {"field": "rank","missing": 0}}}
}
2.1 百分比聚集
百分比聚集用于近似地查看搜索结果中某个字段的百分比分布数据,你可以根据搜索结果清晰地看出某个值以内的数据在整体数据集中的占比。例如,对sougoulog的rank字段做百分比聚集的请求如下。
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"rank_percent": {"percentiles": {"field": "rank"}}}
}
2.2 百分比等级聚集
百分比等级聚集跟百分比聚集的参数恰好相反,传入一组值,就可以看到这个值以内的数据占整体数据的百分比。例如:
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"percent_ranks": {"percentile_ranks": {"field": "rank","values": [ 10, 50 ]}}}
}
在这个聚集请求中,把聚集类型设置为percentile_ranks表示发起百分比等级聚集,values用来设置需要查看的rank值,可以得到以下结果。
"aggregations" : {"percent_ranks" : {"values" : {"10.0" : 82.98,"50.0" : 94.22}}}
这个结果表明,有82.98%的文档rank值小于等于10,有94.22%的文档rank值小于等于50。
2 桶聚集
桶聚集会按照某个字段划分出一些区间,把搜索结果的每个文档按照字段所在的区间划分到桶中,桶聚集会返回每个桶拥有的文档数目。桶的数目既可以用参数确定,也可以在执行过程中按照数据内容动态生成。桶的默认上限数目是65535,返回的桶数目超过这个数目会报错。另外,桶聚集可以嵌套其他的聚集来得到一些复杂的统计结果,度量聚集是不能嵌套其他子聚集的。
2.1 范围聚集范围
聚集需要你提供一组左闭右开的区间,在返回的结果中会得到搜索结果的某个字段落在每个区间的文档数目,参数from用于提供区间下界,to用于提供区间上界。统计的字段既可以是数值类型的字段也可以是日期类型的字段。例如:
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"range_rank": {"range": {"field": "rank","ranges": [{"to": 20},{"from": 20,"to": 50},{"from": 50}]}}}
}
此时的聚集类型为range,field设置了统计的字段为rank,ranges提供区间内容,得到的结果如下。
"aggregations" : {"range_rank" : {"buckets" : [{"key" : "*-20.0","to" : 20.0,"doc_count" : 8895},{"key" : "20.0-50.0","from" : 20.0,"to" : 50.0,"doc_count" : 521},{"key" : "50.0-*","from" : 50.0,"doc_count" : 584}]}}
这个结果表示,有8895个文档的rank值小于20,有521个文档的rank值大于等于20小于50,rank值大于等于50的文档有584个。
2.2 日期范围聚集
日期范围聚集是一种特殊的范围聚集,它要求统计的字段类型必须是日期类型,在索引test-3-2-1中保存的日期字段born用的是UTC时间,下面的代码会实现在这个born字段上做日期范围聚集。
POST test-3-2-1/_search
{"query": {"match_all": {}},"size": 10,"aggs": {"range_rank": {"date_range": {"field": "born","ranges": [{"from": "2020-09-11 00:00:00","to": "2020-10-11 00:00:00"},{"from": "2020-10-11 00:00:00","to": "2020-11-11 00:00:00"}]}}}
}
2.3 直方图聚集
直方图聚集经常用于做一些柱状图和折线图的展示,它可以选择一个数值或日期字段,然后根据字段的最小值和区间步长生成一组区间,统计出每个区间的文档数目。例如:
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"histogram_rank": {"histogram": {"field": "rank","interval": 400,"extended_bounds": {"min": 0,"max": 1500}}}}
}
上面的请求使用extended_bounds中的max设置区间的上限,使用min设置区间的下限
"aggregations" : {"histogram_rank" : {"buckets" : [{"key" : 0.0,"doc_count" : 9760},{"key" : 400.0,"doc_count" : 9},{"key" : 800.0,"doc_count" : 231},{"key" : 1200.0,"doc_count" : 0}]}}
0表示0-400的数据,400表示4000-800的数据,其他依次类推。
2.4 日期直方图聚集
日期直方图聚集的功能和直方图聚集的基本一样,但它只能在日期字段上做聚集,常用于做时间维度的统计分析。使用它可以非常方便地设置时间间隔,既可以是固定长度的时间间隔,也可以是日历时间间隔,例如你想了解每个月文档的数量分布,由于大小月的关系,应该把时间间隔设置为month,而不是固定为30天。参数calendar_interval用于设置日历时间间隔,可选配置如下。
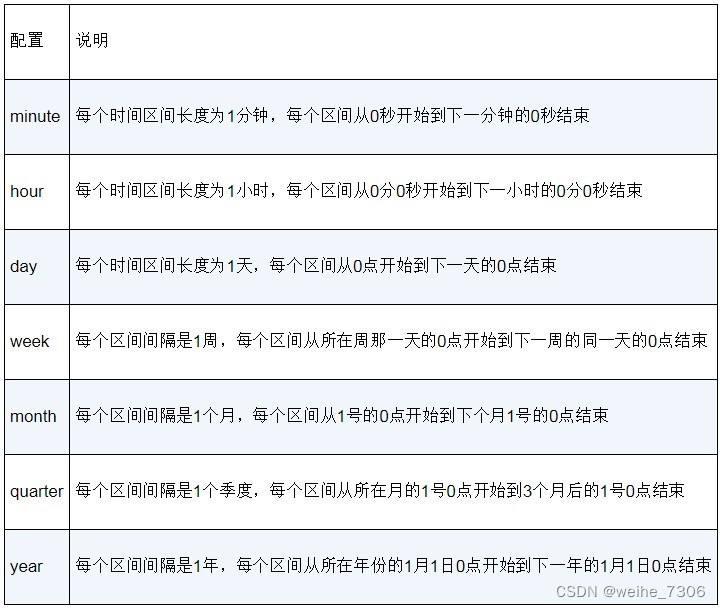
下面来尝试实现日期直方图聚集,只需要传入时间间隔就可以切分区间,不用像范围聚集那样需传入每个区间的边界。
POST test-3-2-1/_search
{"query": {"match_all": {}},"size": 10,"aggs": {"range_rank": {"date_histogram": {"field": "born","calendar_interval": "month","time_zone": "+08:00"}}}
}
2.5 缺失聚集
使用缺失聚集可以很方便地统计出索引中某个字段缺失或者为空的文档数量。例如:
POST test-3-2-1/_search
{"query": {"match_all": {}},"size": 10,"aggs": {"miss": {"missing": {"field": "age"}}}
}
该聚集请求直接返回age字段为空的文档数量。
2.6 过滤器聚集
过滤器聚集往往作为其他聚集的父聚集使用,它可以在其他的聚集开始之前去掉一些文档使其不纳入统计,但是过滤器聚集的过滤条件对搜索结果不起作用。也就是说,它只过滤聚集结果,不过滤搜索结果。例如:
POST test-3-2-1/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"filteraggs": {"filter": {"term": {"name.keyword": "张三"}},"aggs": {"names": {"terms": {"field": "name.keyword","size": 10}}}}}
}
在这个嵌套聚集请求中,先使用过滤器聚集只保留姓名为“张三”的文档,然后嵌套了词条聚集,聚集的结果只出现一个桶,但是搜索结果还是会返回所有的文档。这里设置了size为0没有展示搜索详情,但是如下所示total已经返回了全部文档总数。
2.7 多过滤器聚集
跟过滤器聚集相比,多过滤器聚集允许添加多个过滤条件,每个条件生成一个桶,聚集结果会返回每个桶匹配的文档数。你还可以把不属于任何过滤器的文档全部放入一个名为“other”的桶。例如:
POST test-3-2-1/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"filtersaggs": {"filters": {"other_bucket": true,"filters": {"zhang": {"match": {"name": "张"}},"wang": {"match": {"name": "王"}}}}}}
}
这个请求定义了两个过滤条件,分别用match搜索姓名包含“张”和“王”的文档,搜索的结果数会各自返回到桶中,other_bucket参数设置为true表示显示不属于任何过滤器的文档数到名为“other”的桶中
3、管道聚集
前面谈到的聚集都是对索引的文档数据进行统计,但是管道聚集统计的对象不是索引中的文档数据,它是对桶聚集产生的结果做进一步聚集从而得到一些新的统计结果。管道聚集需要你提供一个桶聚集的相对路径来确定统计的桶对象。根据管道聚集出现的位置,管道聚集可以分为父管道聚集和兄弟管道聚集。
3.1 平均桶聚集
假如你通过日期直方图聚集或直方图聚集产生了3个桶,现在你想对这3个桶的统计值取平均值并做展示,这时候就可以使用平均桶聚集,例如:
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"date": {"date_histogram": {"field": "visittime","fixed_interval": "4m"},"aggs": {"rank_avg": {"avg": {"field": "rank"}}}},"rank_sum":{"avg_bucket": {"buckets_path": "date>rank_avg"}}}
}
“buckets_path”: "date>rank_avg"表示执行顺序,先用date进行时间分割,后面都数据求平均值。
.3.2 求和桶聚集
除了可以对桶聚集的值求平均值,还可以使用sum_bucket对多个桶的值求和。例如:
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"date": {"date_histogram": {"field": "visittime","fixed_interval": "4m"},"aggs": {"rank_sum": {"sum": {"field": "rank"}}}},"rank_sum":{"sum_bucket": {"buckets_path": "date>rank_sum"}}}
}
3.3 最大桶和最小桶聚集
最大桶和最小桶聚集分别用于求多个桶的最大值和最小值,使用方法与求和桶聚集类似。例如:
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"date": {"date_histogram": {"field": "visittime","fixed_interval": "4m"},"aggs": {"rank_data": {"stats": {"field": "rank"}}}},"max_rank":{"max_bucket": {"buckets_path": "date>rank_data.max"}}}
}
3.4 差值聚集差值
聚集用于计算直方图聚集的相邻桶数据的增量值,它也是父管道聚集。例如:
POST sougoulog/_search
{"query": {"match_all": {}},"size": 0,"aggs": {"date": {"date_histogram": {"field": "visittime","fixed_interval": "4m"},"aggs": {"avg_rank": {"avg": {"field": "rank"}},"hb":{"derivative": {"buckets_path": "avg_rank"}}}}}
}
差值聚集可以用于计算相邻桶数据的环比增长值,因此从第二个桶开始才有统计结果,结果如下。
"aggregations" : {"date" : {"buckets" : [{"key_as_string" : "00:00:00","key" : 0,"doc_count" : 4231,"avg_rank" : {"value" : 13.434885369888915}},{"key_as_string" : "00:04:00","key" : 240000,"doc_count" : 4115,"avg_rank" : {"value" : 46.68262454434994},"hb" : {"value" : 33.247739174461024}},{"key_as_string" : "00:08:00","key" : 480000,"doc_count" : 1654,"avg_rank" : {"value" : 47.66142684401451},"hb" : {"value" : 0.9788022996645651}}]}}
6.3 使用fielddata聚集
text字段通过前面的讲解,你应该已经学会了Elasticsearch支持的各种常用的聚集方式,然而这些聚集请求的聚集字段均未使用text字段,原因是实现聚集统计时需要使用字段的doc value值,而text字段不支持doc value。为了让text字段也能做聚集统计,Elasticsearch给text字段提供了fielddata字段数据功能,使用该功能可以在内存中临时生成字段的doc value值,从而实现对text字段做聚集统计。字段数据是一种缓存机制,它会取出字段的值放入内存,可用于排序和聚集统计。
先建立一个映射fielddata-test,它只有一个text字段,在映射中开启字段数据功能。
PUT fielddata-test
{"mappings": {"properties": {"content": {"type": "text","fielddata": true}}}
}
然后向其中添加一条数据。
PUT fielddata-test/_doc/1
{"content":"hello php java"
}
尝试在这个text字段上做词条聚集。
POST fielddata-test/_search
{"query": {"match_all": {}},"aggs": {"termdata": {"terms": {"field": "content","size": 10}}}
}
要显示内存中的content字段数据所占用的大小,可以使用以下代码。
id host ip node field size
EijMhNrDSoy-Bbmo3W8JGA 127.0.0.1 127.0.0.1 node-1 content 512b
字段数据可能会消耗大量内存,为了防止内存被字段数据过度消耗,可以在elasticsearch.yml中使用indices.fielddata.cache.size配置字段数据消耗内存的上限,可以给定一个百分比值,也可以给定具体大小值,该参数配置完后需要重启集群才能生效。
除了内存上限的配置,还可以使用字段数据的断路器,它会评估一个请求使用字段数据消耗的内存量,如果消耗的内存量超过indices.breaker.request.limit中配置的数值,它就会终止该请求继续消耗内存,这种配置可以使用REST端点动态修改,代码如下。
PUT /_cluster/settings
{"persistent" : {"indices.breaker.request.limit" : "30%"}
}
6.4 给聚集请求添加后过滤器
给聚集请求添加后过滤器前面已经介绍过两种过滤器,一种是在布尔查询的过滤上下文中添加搜索条件,另一种是过滤器聚集。本节介绍的后过滤器与它们都有区别。
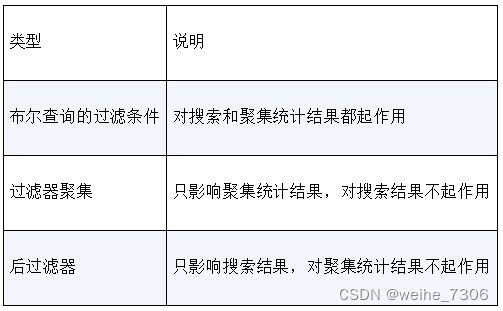
由于后过滤器是在生成聚集统计结果之后对搜索结果进行过滤,所以它对聚集统计的结果没有任何影响,你可以在聚集请求的后面添加一个后过滤器,例如:
POST test-3-2-1/_search
{"query": {"match_all": {}},"size": 10,"aggs": {"names": {"terms": {"field": "name.keyword","size": 10}}},"post_filter": {"term": {"name.keyword": "张三"}}
}
这个请求把后过滤器的过滤条件放到了聚集请求的后面,表示搜索结果只显示名字为“张三”的数据,聚集统计的结果是索引的全部文档,代码如下。
"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "test-3-2-1","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : "1","sex" : false,"name" : "张三","born" : "2020-09-11 00:02:20","location" : {"lat" : 41.12,"lon" : -71.34}}}]},"aggregations" : {"names" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "王五","doc_count" : 1},{"key" : "张三","doc_count" : 1},{"key" : "赵二","doc_count" : 1},{"key" : "李四","doc_count" : 1}]}}
相关文章:
Elasticsearch的聚集统计,可以进行各种统计分析
说明: Elasticsearch不仅是一个大数据搜索引擎,也是一个大数据分析引擎。它的聚集(aggregation)统计的REST端点可用于实现与统计分析有关的功能。Elasticsearch提供的聚集分为三大类。 度量聚集(Metric aggregation):度量聚集可以用于计算搜…...

Webpack 理解 input output 概念
一、介绍 如果还没用过 Webpack 请先阅读 Webpack & 基础入门 再回头看本文。 Webpack 的核心只做两件事,输入管理(Input Management)和输出管理(Output Management),什么花里胡哨的插件和配置都离不…...

【字符函数】
✨博客主页:小钱编程成长记 🎈博客专栏:进阶C语言 🎈相关博文:字符串函数(一)、字符串函数(二) 字符函数 字符函数1.字符分类函数1.1 iscntrl - 判断是否是控制字符1.2 i…...
git创建与合并分支
文章目录 创建与合并分支分支管理的概念实际操作 解决冲突分支管理策略Bug分支Feature分支多人协作 创建与合并分支 分支管理的概念 分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码…...

【电子通识】USB TYPE-A 2.0/3.0连接器接口
基础知识 USB TYPE-A连接器又可称为USB-A,现在不少PC、PC周边、手机充电器等等都依然采用了这种扁平的矩形接口,是目前普及度最高的USB接口了。 USB-A亦有分为插头与插座。常见的USB-A数据线的A端就是插头,而充电器上的则是插座。插头和插座…...

org.apache.sshd的SshClient客户端 连接服务器执行命令 示例
引入依赖 <dependency><groupId>org.apache.sshd</groupId><artifactId>sshd-core</artifactId><version>2.9.1</version></dependency>示例代码,可以直接执行,也可以做替换命令、维护session等修改 p…...

STM32 裸机编程 03
MCU 启动和向量表 当 STM32F429 MCU 启动时,它会从 flash 存储区最前面的位置读取一个叫作“向量表”的东西。“向量表”的概念所有 ARM MCU 都通用,它是一个包含 32 位中断处理程序地址的数组。对于所有 ARM MCU,向量表前 16 个地址由 ARM …...

Python ‘list‘ object is not callable错误
我尝试着解决“TypeError: ‘list’ object is not callable”这个错误。在Python编程中,我有时会遇到这个错误。这个错误通常是由于我错误地尝试像函数一样调用一个列表对象。为了解决这个问题,我需要找出错误发生的具体位置,然后进行修正。…...

原生php 实现redis登录五次被禁,隔天再登陆
<?php /*** Created by PhpStorm.* User: finejade* Date: 2023-10-18* Time: 11:08*/ session_start();include_once(header.php); include_once(connect.php); include_once(common.php); include_once(redis.php); try {// 常量 用户错误次数记录define("USER_LOGI…...

24. Kernel 4.19环境下,Cilium网络仍然需要使用iptables
在设计这套容器集群服务时,我从原来的k3s架构中分离出一个问题,那就是容器网络插件应该选择哪个。因为我设计的目标是给服务器领域使用的容器引擎,所以我就不需要考虑太多边缘IOT设备的情况,直接拉满技能找了cilium。cilium借助内核ebpf技术的出现,让我看到了网络性能更好…...
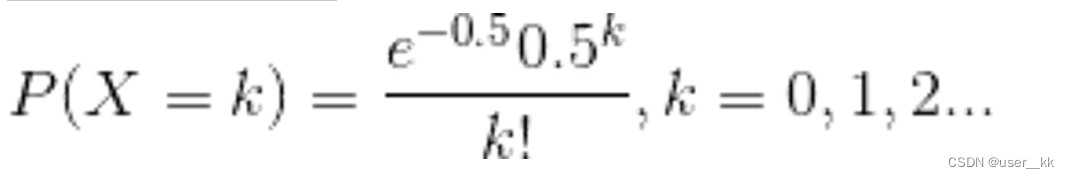
java中的容器(集合),HashMap底层原理,ArrayList、LinkedList、Vector区别,hashMap加载因子0.75原因
一、java中的容器 集合主要分为Collection和Map两大接口;Collection集合的子接口有List、Set;List集合的实现类有ArrayList底层是数组、LinkedList底层是双向非循环列表、Vector;Set集合的实现类有HashSet、TreeSet;Map集合的实现…...

Linux Server 终止后立即重启报错 bind error: Address already in use
先启动Server,再启动Client,然后使用CtrlC关闭Server,马上再运行Server,会得到以下结果: bind error: Address already in use这是因为,虽然Server的应用程序终止了,但TCP协议层的连接并没有完全…...

【Python 千题 —— 基础篇】分解数据
题目描述 题目描述 编写一个程序,输入一个类似 “233,234,235” 格式的字符串,然后提取字符串中的数字,将这些数字存储在列表中,并输出该列表。在这里,我们使用 eval 函数来解析字符串中的数字。 输入描述 输入一个…...

【C++】C++11新特性之右值引用与移动语义
文章目录 一、左值与左值引用二、右值与右值引用三、 左值引用与右值引用比较四、右值引用使用场景和意义1.左值引用的短板2.移动构造和移动赋值3.STL中右值引用的使用 五、万能引用与完美转发1.万能引用2.完美转发 一、左值与左值引用 在C11之前,我们把数据分为常…...

家庭燃气表微信抄表识别系统
1.背景需求 目前家里燃气度数的读数上报,每个月在社区微信群里面将手机拍摄的燃气表读数截图(加住址信息水印),发到群里给抄表员。 2.总体设计 设计目标 功能一:手机上随时可以远程采集读数图片(自动加住…...

EF执行迁移时提示provider: SSL Provider, error: 0 - 证书链是由不受信任的颁发机构颁发的
ef在执行时提示provider: SSL Provider, error: 0 - 证书链是由不受信任的颁发机构颁发的。 只需要在数据库链接字符串后增加EncryptTrue;TrustServerCertificateTrue;即可 再次执行...

视频标注的两个主要方法
视频标注技术 单一图像法 在自动化工具面世之前,视频标注效率不高。各公司使用单一图像法提取视频中的所有帧,然后使用标准图像标注技术将它们作为图像来标注。在30fps的视频中,每分钟有1800帧。这个过程没有利用视频标注的优势,…...

学成在线第一天-项目介绍、项目的搭建、开发流程以及相关面试题
目录 一、项目介绍 二、项目搭建 三、开发流程 四、相关面试题 五、总结 一、项目介绍 背景 业务 技术 背景:首先是整个这个行业的背景 然后基于这个行业的背景引出当前项目的背景 业务:功能模块 功能业务流程 技术:整体架构&am…...
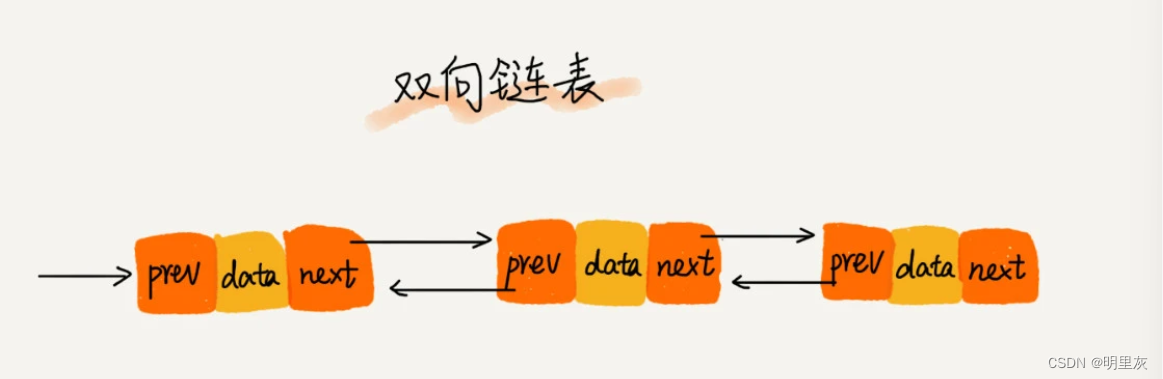
《数据结构与算法之美》读书笔记1
Java的学习 方法参数多态(向上和向下转型) 向上转型: class Text{public static void main(String[] args) {Animals people1 new NiuMa();people1.eat1();//调用继承后公共部分的方法,没重写调用没重写的,重写了调…...
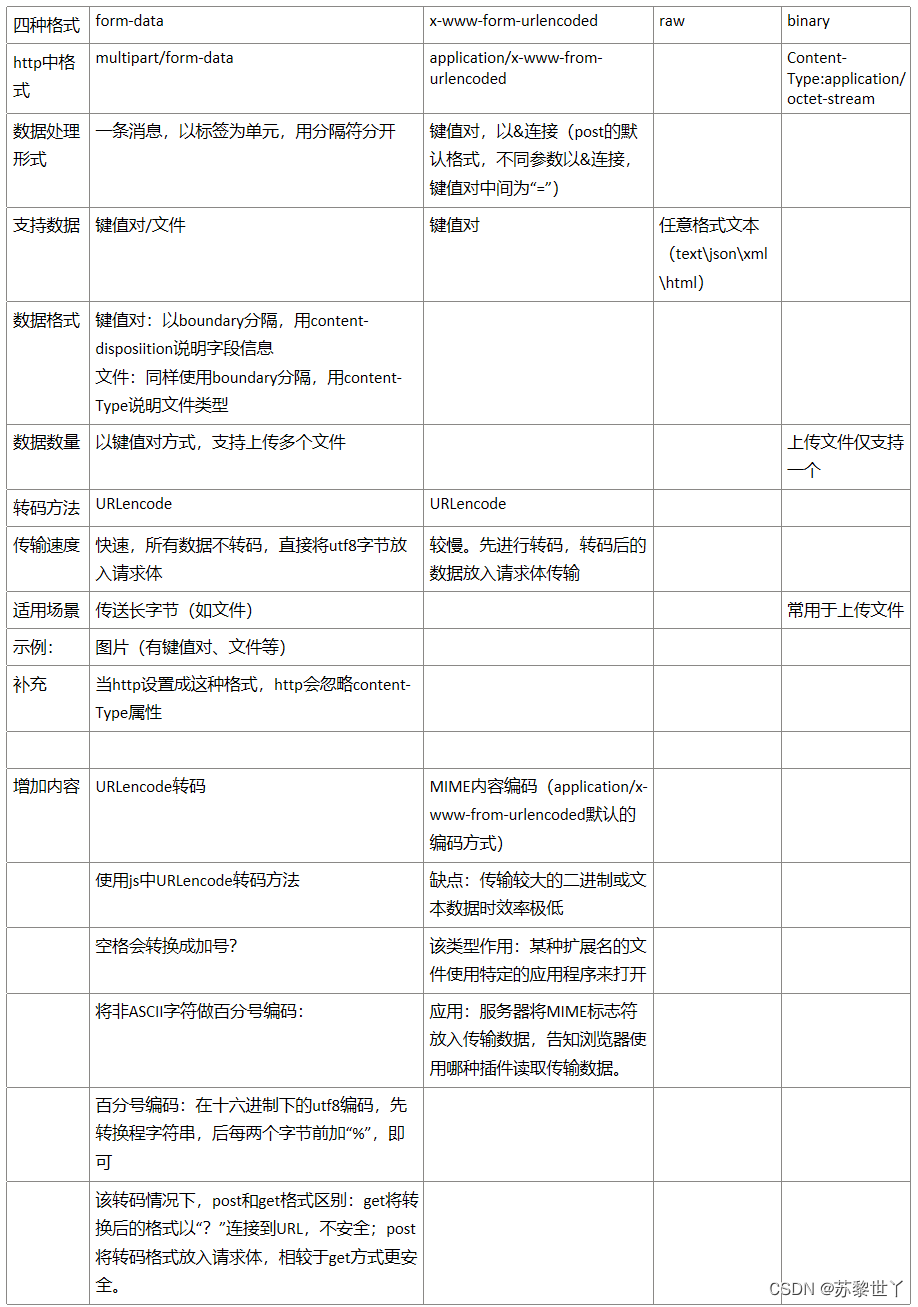
接口测试经验合集
一 、接口测试常见问题 前景提要:由于本人测试小白,可能所遇问题都较为基础,测试小白可以参考 1.1 postman会报 connect ECONNREFUSED jemeter会报 org.apache.http.conn.HttpHostConnectException: Connect tofailed: Connection refus…...

具身智能会取代人类工作吗?安全性如何?
替代与创造并存 安全性挑战:技术风险与伦理风险交织 结论:在替代与共生之间寻找平衡...

iwrqk:Flutter打造的Iwara社区移动端终极指南
iwrqk:Flutter打造的Iwara社区移动端终极指南 【免费下载链接】iwrqk Unofficial Iwara Flutter Client 项目地址: https://gitcode.com/gh_mirrors/iw/iwrqk Iwara作为全球知名的二次元创作分享平台,汇聚了海量高质量的MMD动画、Vtuber内容和同人…...

丹青识画入门必学:中文多模态提示词设计与意境引导技巧
丹青识画入门必学:中文多模态提示词设计与意境引导技巧 1. 理解多模态提示词的核心价值 多模态提示词是连接视觉内容与语言描述的关键桥梁。在丹青识画这样的智能影像雅鉴系统中,提示词的质量直接决定了生成描述的准确性和艺术性。 传统的图像识别系统…...

youlai-mall常见问题解决方案:部署、配置与开发中的坑与填法
youlai-mall常见问题解决方案:部署、配置与开发中的坑与填法 【免费下载链接】youlai-mall 🚀基于 Spring Boot 3、Spring Cloud & Alibaba 2022、SAS OAuth2 、Vue3、Element-Plus、uni-app 构建的开源全栈商城。 项目地址: https://gitcode.com/…...

终极指南:如何用ViGEmBus虚拟手柄驱动彻底解决Windows游戏兼容性问题
终极指南:如何用ViGEmBus虚拟手柄驱动彻底解决Windows游戏兼容性问题 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的尴尬…...

告别Foremost和DD:用Python脚本一键自动化提取CTF中的‘图种’和隐藏文件
用Python打造CTF隐写分析利器:自动化提取图种与隐藏文件 在CTF竞赛中,压缩包隐写和文件拼接是常见的挑战类型。许多选手习惯使用foremost或dd这类工具进行文件分离,但这些工具往往需要手动操作,在处理批量文件或复杂嵌套结构时效率…...

深入Canvas渲染管线:从Rebuild、Rebatch到动静分离,一次讲清Unity UI合批原理
深入Canvas渲染管线:从Rebuild、Rebatch到动静分离,一次讲清Unity UI合批原理 在Unity UI开发中,性能优化是一个永恒的话题。当我们面对复杂的UI界面时,经常会遇到卡顿、掉帧等问题,而这些问题往往与Canvas的渲染机制密…...

Ryujinx模拟器终极实战指南:从零配置到性能优化的完整教程
Ryujinx模拟器终极实战指南:从零配置到性能优化的完整教程 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想要在PC上畅玩Switch游戏?Ryujinx模拟器是你的最佳选…...
)
告别POI内存溢出!用EasyExcel 2.2.3处理百万级Excel数据实战(附性能对比)
百万级Excel处理实战:EasyExcel 2.2.3内存优化全解析 当Java开发者面对百万行Excel数据时,传统Apache POI的内存溢出问题就像悬在头顶的达摩克利斯之剑。我曾亲历一个生产事故——凌晨三点被报警叫醒,发现POI在解析80MB的订单文件时吃光了16G…...

10分钟精通WinUtil:Windows系统管理与优化的终极解决方案
10分钟精通WinUtil:Windows系统管理与优化的终极解决方案 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil WinUtil是一款专为Windo…...