自然语言处理---Transformer机制详解之Transformer优势
1 Transformer的并行计算
对于Transformer比传统序列模型RNN/LSTM具备优势的第一大原因就是强大的并行计算能力.
- 对于RNN来说,任意时刻t的输入是时刻t的输入x(t)和上一时刻的隐藏层输出h(t-1),经过运算后得到当前时刻隐藏层的输出h(t),这个h(t)也即将作为下一时刻t+1的输入的一部分。
- 以上计算过程是RNN的本质特征,RNN的历史信息是需要通过这个时间步一步一步向后传递的。而这就意味着RNN序列后面的信息只能等到前面的计算结束后,将历史信息通过hidden state传递给后面才能开始计算,形成链式的序列依赖关系,无法实现并行。
- 对于Transformer结构来说, 在self-attention层, 无论序列的长度是多少, 都可以一次性计算所有单词之间的注意力关系,这个attention的计算是同步的,可以实现并行。
2 Transformer架构的并行化过程
2.1 Transformer架构中Encoder的并行化
首先Transformer的并行化主要体现在Encoder模块上
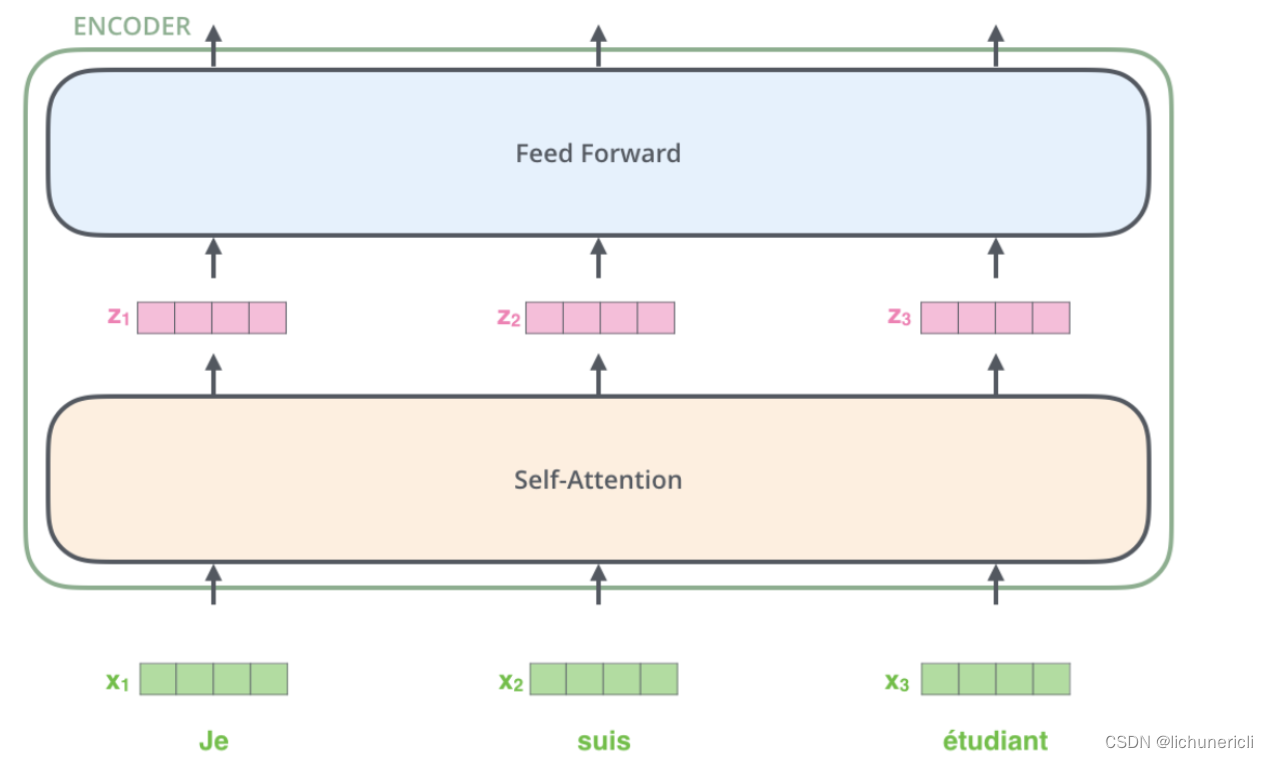
-
上图最底层绿色的部分, 整个序列所有的token可以并行的进行Embedding操作, 这一层的处理是没有依赖关系的.
-
上图第二层土黄色的部分, 也就是Transformer中最重要的self-attention部分, 这里对于任意一个单词比如x1, 要计算x1对于其他所有token的注意力分布, 得到z1. 这个过程是具有依赖性的, 必须等到序列中所有的单词完成Embedding才可以进行. 因此这一步是不能并行处理的. 但是从另一个角度看, 我们真实计算注意力分布的时候, 采用的都是矩阵运算, 也就是可以一次性的计算出所有token的注意力张量, 从这个角度看也算是实现了并行, 只是矩阵运算的"并行"和词嵌入的"并行"概念上不同而已.
-
上图第三层蓝色的部分, 也就是前馈全连接层, 对于不同的向量z之间也是没有依赖关系的, 所以这一层是可以实现并行化处理的. 也就是所有的向量z输入Feed Forward网络的计算可以同步进行, 互不干扰.
2.2 Transformer架构中Decoder的并行化
其次Transformer的并行化也部分的体现在Decoder模块上.
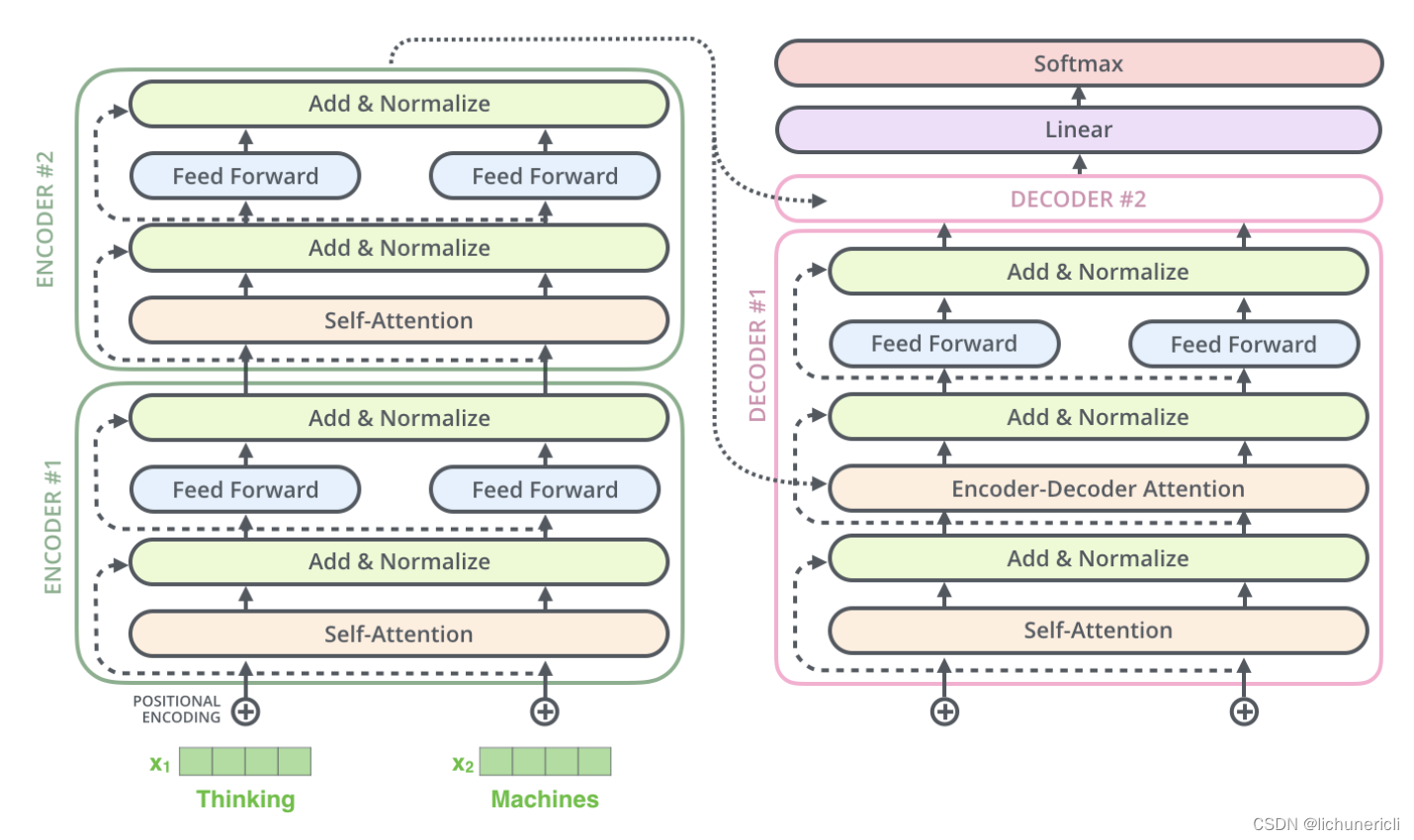
-
Decoder模块在训练阶段采用了并行化处理. 其中Self-Attention和Encoder-Decoder Attention两个子层的并行化也是在进行矩阵乘法, 和Encoder的理解是一致的. 在进行Embedding和Feed Forward的处理时, 因为各个token之间没有依赖关系, 所以也是可以完全并行化处理的, 这里和Encoder的理解也是一致的.
-
Decoder模块在预测阶段基本上不认为采用了并行化处理. 因为第一个time step的输入只是一个"SOS", 后续每一个time step的输入也只是依次添加之前所有的预测token.
-
注意: 最重要的区别是训练阶段目标文本如果有20个token, 在训练过程中是一次性的输入给Decoder端, 可以做到一些子层的并行化处理. 但是在预测阶段, 如果预测的结果语句总共有20个token, 则需要重复处理20次循环的过程, 每次的输入添加进去一个token, 每次的输入序列比上一次多一个token, 所以不认为是并行处理.
3 Transformer的特征抽取能力
对于Transformer比传统序列模型RNN/LSTM具备优势的第二大原因就是强大的特征抽取能力.
- Transformer因为采用了Multi-head Attention结构和计算机制, 拥有比RNN/LSTM更强大的特征抽取能力, 这里并不仅仅由理论分析得来, 而是大量的试验数据和对比结果, 清楚的展示了Transformer的特征抽取能力远远胜于RNN/LSTM.
- 注意: 不是越先进的模型就越无敌, 在很多具体的应用中RNN/LSTM依然大有用武之地, 要具体问题具体分析.
4 Transformer可以代替seq2seq
4.1 seq2seq的两大缺陷
-
seq2seq架构的第一大缺陷是将Encoder端的所有信息压缩成一个固定长度的语义向量中, 用这个固定的向量来代表编码器端的全部信息. 这样既会造成信息的损耗, 也无法让Decoder端在解码的时候去用注意力聚焦哪些是更重要的信息.
-
seq2seq架构的第二大缺陷是无法并行, 本质上和RNN/LSTM无法并行的原因一样.
4.2 Transformer的改进
- Transformer架构同时解决了seq2seq的两大缺陷, 既可以并行计算, 又应用Multi-head Attention机制来解决Encoder固定编码的问题, 让Decoder在解码的每一步可以通过注意力去关注编码器输出中最重要的那些部分.
5 小结
- Transformer相比于RNN/LSTM的优势和原因.
- 第一大优势是并行计算的优势.
- 第二大优势是特征提取能力强.
- Transformer架构中Encoder模块的并行化机制.
- Encoder模块在训练阶段和测试阶段都可以实现完全相同的并行化.
- Encoder模块在Embedding层, Feed Forward层, Add & Norm层都是可以并行化的.
- Encoder模块在self-attention层, 因为各个token之间存在依赖关系, 无法独立计算, 不是真正意义上的并行化.
- Encoder模块在self-attention层, 因为采用了矩阵运算的实现方式, 可以一次性的完成所有注意力张量的计算, 也是另一种"并行化"的体现.
-
Transformer架构中Decoder模块的并行化机制.
- Decoder模块在训练阶段可以实现并行化.
- Decoder模块在训练阶段的Embedding层, Feed Forward层, Add & Norm层都是可以并行化的.
- Decoder模块在self-attention层, 以及Encoder-Decoder Attention层, 因为各个token之间存在依赖关系, 无法独立计算, 不是真正意义上的并行化.
- Decoder模块在self-attention层, 以及Encoder-Decoder Attention层, 因为采用了矩阵运算的实现方式, 可以一次性的完成所有注意力张量的计算, 也是另一种"并行化"的体现.
- Decoder模块在预测计算不能并行化处理.
-
seq2seq架构的两大缺陷.
- 第一个缺陷是Encoder端的所有信息被压缩成一个固定的输出张量, 当序列长度较长时会造成比较严重的信息损耗.
- 第二个缺陷是无法并行计算.
-
Transformer架构对seq2seq两大缺陷的改进.
- Transformer应用Multi-head Attention机制让编码器信息可以更好的展示给解码器.
- Transformer可以实现Encoder端的并行计算.
相关文章:
自然语言处理---Transformer机制详解之Transformer优势
1 Transformer的并行计算 对于Transformer比传统序列模型RNN/LSTM具备优势的第一大原因就是强大的并行计算能力. 对于RNN来说,任意时刻t的输入是时刻t的输入x(t)和上一时刻的隐藏层输出h(t-1),经过运算后得到当前时刻隐藏层的输出h(t),这个…...

改进YOLO系列 | YOLOv5/v7 引入 Dynamic Snake Convolution | 动态蛇形卷积
准确分割拓扑管状结构,如血管和道路,在各个领域中至关重要,可以确保下游任务的准确性和效率。然而,许多因素使任务复杂化,包括细小的局部结构和可变的全局形态。在这项工作中,我们注意到管状结构的特殊性,并利用这一知识来引导我们的DSCNet,以在三个阶段同时增强感知:…...
postgresql14-表的管理(四)
表table 创建表 CREATE TABLE table_name --表名 (column_name data_type column_constraint, --字段名、字段类型、约束字段(可选)column_name data_type, --表级别约束字段...,table_constraint );CREATE TABLE emp1 --创建表 AS SELECT * FROM empl…...

Java--Object类
Java中Object类是所有类的父类,是Java中最高层的类。用户创建一个类时,除非指定继承了某个类,否则都是继承于Object类。 由于所有类都继承于Object类,所以所有类都可以重写Object类中的方法。但是Object类中被final修饰的getClass…...
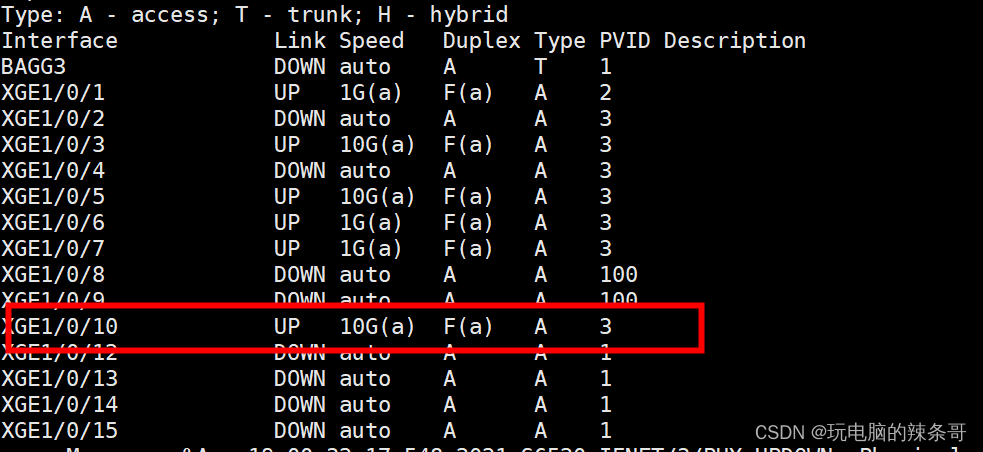
交换机端口灯常亮 端口up状态 服务器设置ip交换机获取不到服务器网卡mac地址 不能通信
环境: 深信服防火墙 8.0.75 AF-2000-FH2130B-SC S6520X-24ST-SI交换机 version 7.1.070, Release 6530P02 问题描述: 交换机一个vlan下有3台服务器,连接端口2、3、4,2和3连接的服务器正常,交换机3端口灯常亮 端口up状态 服务器自动获取不了地址,改为手动设置ip后,交…...
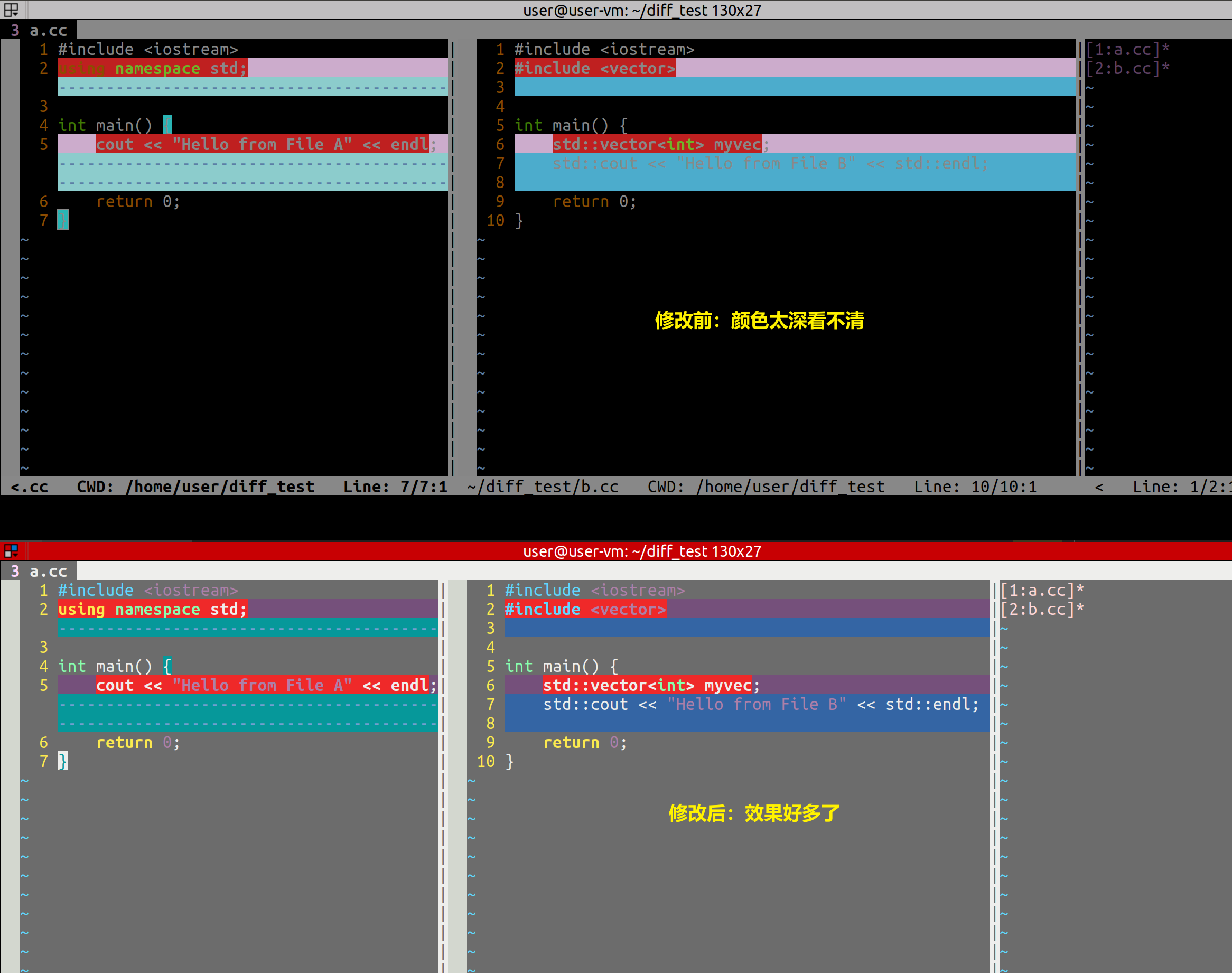
Linux笔记之diff和vimdiff
Linux笔记之diff和vimdiff code review! 文章目录 Linux笔记之diff和vimdiff一.diff1.1.使用diff比较文件夹1.2.使用diff比较文件1.4.colordiff——带颜色输出差异 二.vimdiff2.1.vimdiff颜色差异2.2.vimfiff调整栏宽2.3.修改颜色变谈,使代码可以看清楚2.4.vimdif…...

目标检测YOLO实战应用案例100讲-基于改进的YOLOV5算法的垃圾分类模型
目录 前言 国内外研究现状 目标检测算法发展现状 YOLO算法的发展现状...

我做不到受每个人喜欢
我做不到受每个人喜欢 我想描述一下昨天发生争吵后我个人的观点,希望能够重新呈现出一种积极的态度。 首先,让我简要梳理一下事件的经过,当天我像往常一样去另一个宿舍找人聊天,可能因为说话声音有点大,坐在我后面的那…...
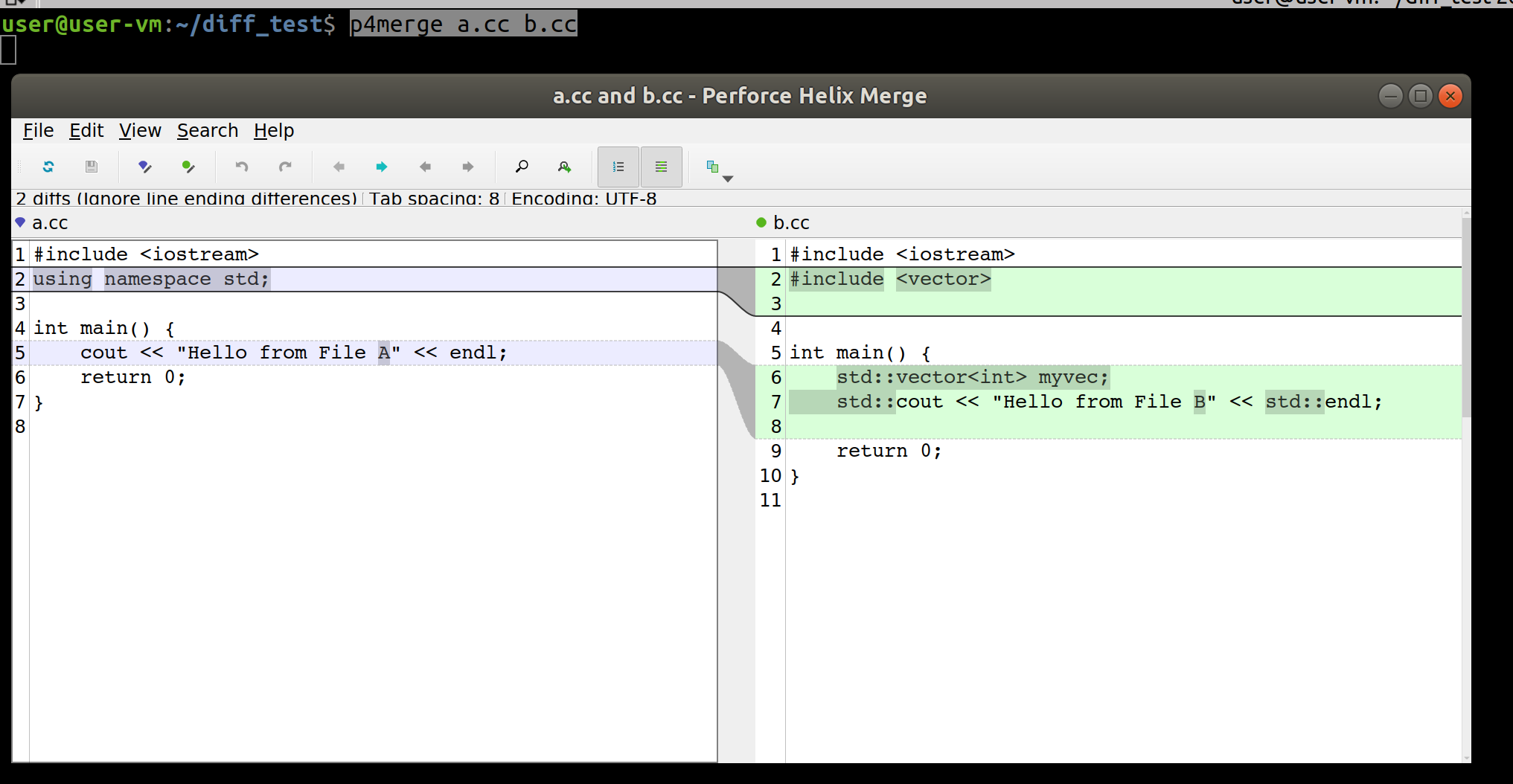
Linux笔记之diff工具软件P4merge的使用
Linux笔记之diff工具软件P4merge的使用 code review! 文章目录 Linux笔记之diff工具软件P4merge的使用1.安装和配置2.使用:p4merge a.cc b.cc3.配置git 参考博文: Ubuntu Git可视化比较工具 P4Merge 的安装/配置及使用 1.安装和配置 $ wget https://cdist2.per…...

使用 OpenSSL 扩展来实现公钥和私钥加密
首先,你需要生成一对公钥和私钥。可以使用 OpenSSL 工具来生成: 1、生成私钥 openssl genpkey -algorithm RSA -out private_key.pem 2、从私钥生成公钥: openssl rsa -pubout -in private_key.pem -out public_key.pem现在你有了一个私钥…...

二、安全与风险管理—安全与风险管理基础
目录 目录 1.什么是信息与信息的生命周期 2.信息安全的基本目标 3.风险管理与控制类型...

rust学习——栈、堆、所有权
文章目录 栈、堆、所有权栈(Stack)与堆(Heap)栈堆性能区别所有权与堆栈 所有权原则变量作用域所有权与函数返回值与作用域 栈、堆、所有权 栈(Stack)与堆(Heap) 栈和堆是编程语言最核心的数据结构,但是在很多语言中,你并不需要深入了解栈与堆。 但对于…...

如何从小白成长为AI工程师笔记
📚入门机器学习基础 对于本科生来说,需要打好数学基础,包括高数、概率论和线性代数。 对于已经上研究生或工作想转行的人来说,可以直接开始学习机器学习算法,重要的是理解算法的原理和推导过程。如果有时间和需要&am…...

fail-fast 和 fail-safe 迭代器
fail-fast 和 fail-safe 迭代器是两种不同的迭代器设计策略,用于在遍历集合(如 ArrayList、HashMap)时处理并发修改的情况。它们的行为和应对策略有所不同: Fail-Fast 迭代器: Fail-Fast 迭代器在遍历集合期间&#x…...

Nvidia显卡基础概念介绍
一、PCIe与SXM 1.1 Nvidia GPU PCIe PCIe(peripheral component interconnect express)是一种高速串行计算机扩展总线标准,是英特尔公司在2001年提出来的,它的出现主要是为了取代AGP接口,优点就是兼容性比较好,数据传输速率高、…...

使用screen实现服务器代码一直运行
1.安装screen sudo apt install screen 2.创建一个screen(创建一个名为chatglm的新的链接,用来一直运行 screen -S chatglm 3.查看进程列表 screen -ls 创建之后,就可以在当前窗口利用cd命令进入要执行的项目中,开始执行…...

Linux系统自有服务
一、Linux中防火墙firewalld 1、什么是防火墙 防火墙:防范一些网络攻击。有软件防火墙、硬件防火墙之分。 防火墙选择让正常请求通过,从而保证网络安全性。 Windows防火墙: Windows防火墙的划分与开启、关闭操作: 2、防火墙的作…...

Andriod学习笔记(二)
页面设计的零碎知识 通用属性设置文本大小设置视图宽高设置视图的对齐方式 页面布局LinearLayoutRelativeLayoutGridLayoutScollView 按钮触控ButtonImageViewImageButton 通用属性 设置文本大小 纯数字的setTextSize方法,内部默认字体单位为sp,sp是An…...
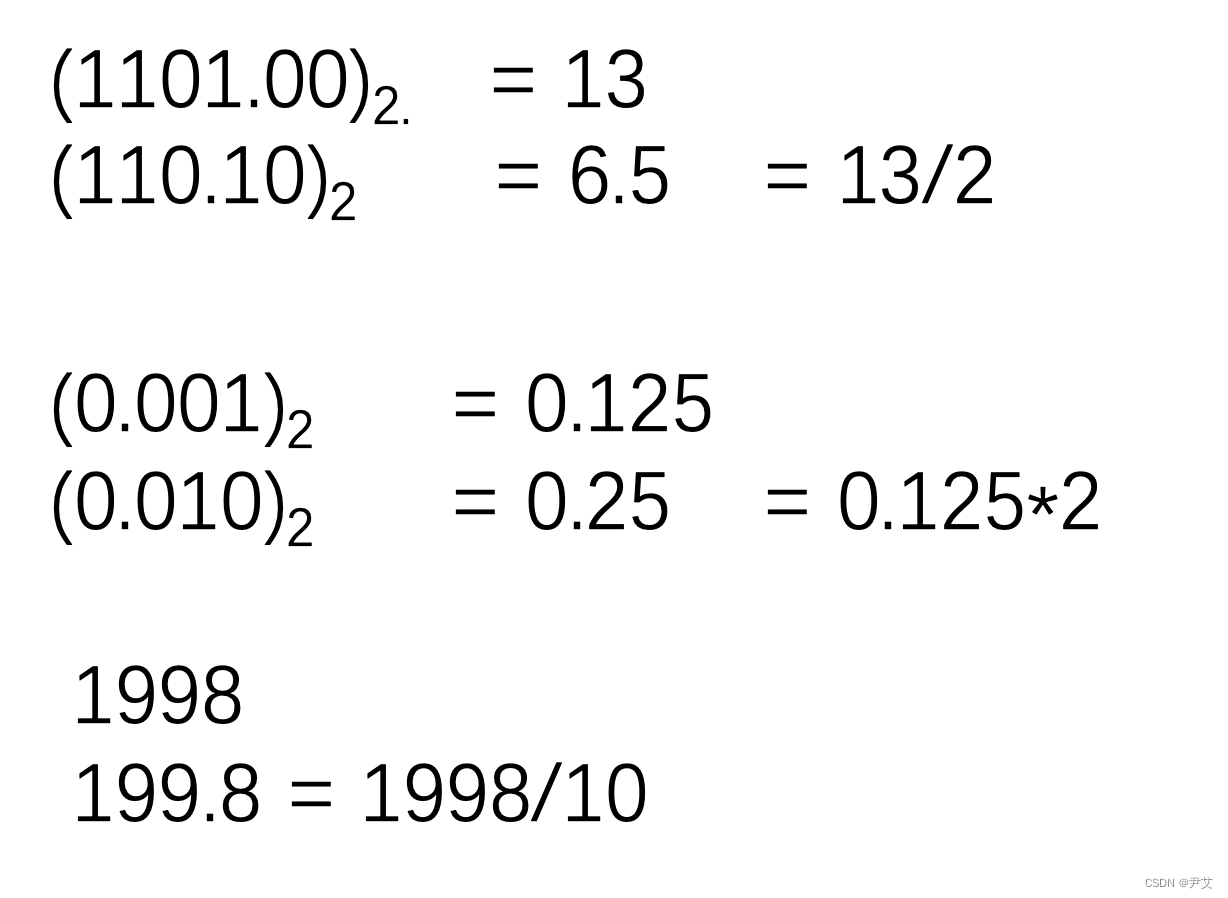
【超级基础版】十进制与二进制的转换
目录 一、为什么是二进制? 二、二进制的加法和乘法 三、二进制向十进制转换 四、十进制整数向二进制转换 五、十进制小数向二进制小数的转换 六、八进制和十六进制的引入 一、为什么是二进制? 我们知道电脑的数据本质上是0和1,就是我们…...
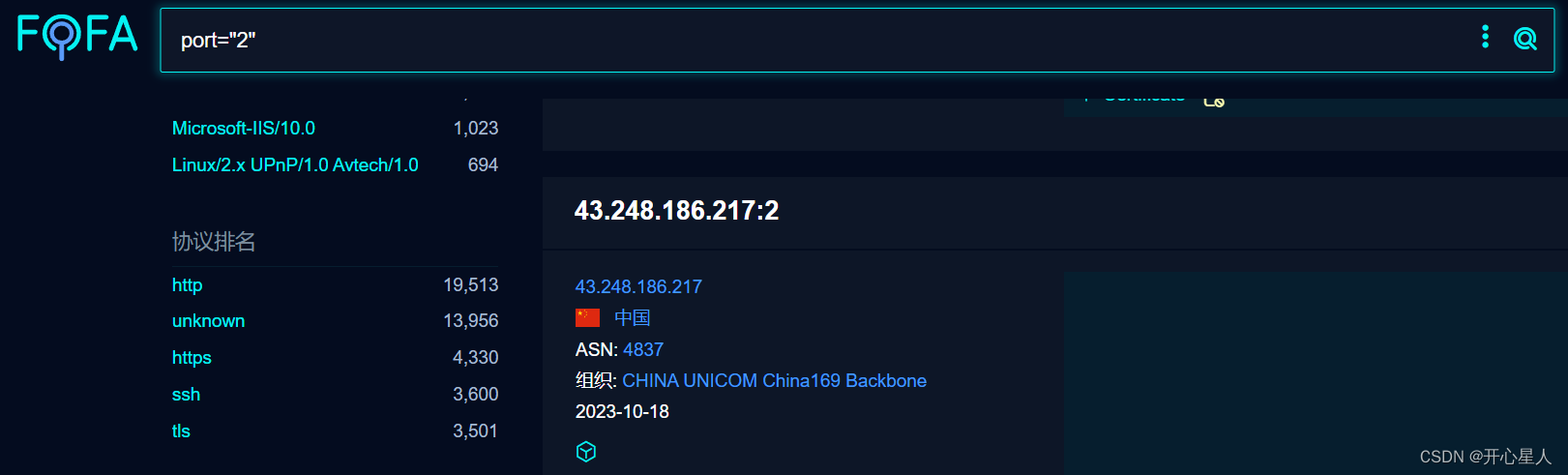
爬虫学习日记第八篇(爬取fofa某端口的协议排行及其机器数目,统计top200协议)
需求 找到最常用的200个协议 通过fofa搜索端口,得到协议排名前五名和对应机器的数目。 遍历端口,统计各个协议对应的机器数目(不准,但能看出个大概) 读写API API需要会员,一天只能访问1000次。 import…...

终极指南:PointNet激活函数性能大比拼 ReLU、LeakyReLU与Swish深度测试
终极指南:PointNet激活函数性能大比拼 ReLU、LeakyReLU与Swish深度测试 【免费下载链接】pointnet PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation 项目地址: https://gitcode.com/gh_mirrors/po/pointnet PointNet作为3D点…...
)
总泵缸体加工(论文+DWG图纸+proe三维图+工艺卡片)
总泵缸体作为液压系统的核心部件,其加工质量直接影响整车制动性能与安全性。该零件需同时满足高强度、高密封性及复杂型面精度要求,加工过程中需兼顾材料特性与工艺可行性。从毛坯预处理到最终检验,每个环节均需严格遵循行业标准,…...

学AI学成了高级废物
过去一年,我亲眼看着无数人高喊着“要拥抱AI”,结果半年后依然原地踏步、越来越焦虑、越来越废。他们不是不努力,而是努力得极其愚蠢。我把这些血淋淋的真实案例总结了一下,发现99%的人都会踩中下面这三个致命大坑,一旦…...

报价单外发失控:商业机密是怎么从邮件里流出去的
报价单发出去三天后,老板让我查一下那家客户——说采购在问能不能再降三个点。 我心里咯噔一下。 那份报价单我亲手发的,PDF格式,对方说"收到啦谢谢",然后就没有然后了。结果现在采购开口就是三个点,明显是知…...

基于ChatGLM3-6B的智能文档处理系统:从PDF解析到知识提取
基于ChatGLM3-6B的智能文档处理系统:从PDF解析到知识提取 1. 引言 每天都有海量的文档需要处理,从合同协议到技术手册,从财务报告到学术论文。传统的人工处理方式不仅效率低下,还容易出错。想象一下,一个法务团队需要…...
效果对照表)
Neeshck-Z-lmage_LYX_v2实战教程:提示词引导强度(1.0-7.0)效果对照表
Neeshck-Z-lmage_LYX_v2实战教程:提示词引导强度(1.0-7.0)效果对照表 1. 引言:为什么你需要关注这个参数? 如果你用过文生图工具,肯定遇到过这种情况:明明输入了“一只猫”,结果生…...

【AIAgent架构混沌工程实战白皮书】:20年SRE专家亲授5大高危故障注入模式与3类生产级熔断验证框架
第一章:AIAgent架构混沌工程实战白皮书导论 2026奇点智能技术大会(https://ml-summit.org) AIAgent系统正从单体推理服务演进为多智能体协同、动态编排、跨模态感知的复杂运行时生态。其架构天然具备高耦合性、强状态依赖与非确定性决策特征,传统测试手…...

GO-FLY国际化与多语言支持:面向全球用户的客服系统
GO-FLY国际化与多语言支持:面向全球用户的客服系统 【免费下载链接】goflylivechat 开源在线客服系统GO语言开发GO-FLY,免费在线客服系统/GOFLY LIVE CHAT: open source self-hosted private cloud customer support live chat software by golang 项目地址: http…...

如何快速掌握WandEnhancer使用:面向新手的完整免费增强指南
如何快速掌握WandEnhancer使用:面向新手的完整免费增强指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer WandEnhancer是一款专为游戏辅助…...
)
AIAgent架构自动化测试方案(工业级CI/CD集成手册)
第一章:AIAgent架构自动化测试方案(工业级CI/CD集成手册) 2026奇点智能技术大会(https://ml-summit.org) AI Agent系统具备多模块协同、动态决策链路与外部工具调用等复杂特性,传统单元测试难以覆盖其端到端行为一致性。本方案面…...