Nvidia显卡L40S学习:产品规格,常用名词解释
L40S
1 产品形态
- 构建NVIDIA OVX服务器,面向数据中心,用于加速AI训练和推理、3D设计和可视化、视频处理和工业数字化等复杂的计算密集型应用
- 每个OVX服务器上8个L40S GPU,每个GPU配备48GB GDDR6超快内存
2 产品发展
- 具有许多与之前的 NVIDIA L40 相同的规格。NVIDIA L40 和 L40S 在很多方面都是 A40 的后继者。
- 设计用于装入 PCIe 服务器中
- 通过机箱气流冷却 GPU。
3 产品架构、规格
- 基于Ada架构,内置第四代Tensor Core和FP8 Transformer Engine
- 算力:提供超过1.45PFLOPS的张量处理能力,包含18176个CUDA内核,提供近5倍于A100 GPU的单精度浮点(FP32)性能,以加速复杂的计算和数据密集型分析,支持对于工程和科学模拟等计算要求苛刻的工作流程。
- 渲染:为了支持实时渲染、产品设计和3D内容创建等高保真的专业可视化工作流程,L40S GPU内置有142个第三代RT核心,可提供212TFLOPS的光追性能。
- 发展与性能优势:对于具有数十亿参数和多种数据模式(如文本和视频)的复杂AI工作负载,与A100 GPU相比,L40S可实现快1.2倍的AI推理性能、快1.7倍的训练性能、快3.5倍的渲染速度,启用DLSS3时Omniverse渲染速度更是能高到近4倍。
4 主要规格图
| 类别 | 详细规格 |
|---|---|
| Architecture(架构) | NVIDIA Ada Lovelace Architecture |
| Foundry(代工厂) | TSMC(台积电) |
| Process Size(制造工艺) | 4 nm NVIDIA Custom Process |
| Transistors(晶体管数量) | 76.3 billion |
| Die Size(Die面积) | 608.44 mm |
| CUDA Parallel Processing Cores(Cude 核数量) | 18176 |
| NVIDIA Tensor Cores (4th Gen) | 568 |
| NVIDIA RT Cores (3rd Gen) | 142 |
| Peak FP32 TFLOPS (non-Tensor) | 91.6 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate | 366.5 | 733* |
| Peak FP8 Tensor TFLOPs with FP16 Accumulate | 733 | 1466* |
| Peak TF32 Tensor TFLOPS | 183 | 366* |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate | 366.5 | 733* |
| Peak INT8 Tensor TOPS | 733 | 1466* |
| Peak INT4 Tensor TOPS | 733 | 1466* |
| RT Core Performance TFLOPS | 212 |
| GPU Memory(内存) | 48 GB GDDR6 with ECC |
| Memory Interface(内存位宽) | 384-bit |
| Memory Bandwidth(内存带宽) | 864 GB/s |
| Interconnect(通信接口) | x16 PCIe Gen4 (no NVLink) |
| Max Power Consumption(功耗) | 350 W |
| Graphics Bus(图形总线) | PCI Express 4.0 X16 |
| Display Connectors(显示接口) | DP 1.4a, Supports NVIDIA Mosaic and Quadro Sync |
| Display Max Resolution / Quantity(显示分辨率/质量) | four 5K Monitors @ 60Hz per card or dual 8K displays @ 60Hz per card Each display port can support 4K @ 120Hz with 30 -bit color |
| Form Factor(物理尺寸和形状标准) | 4.4" H × \times × 10.5" L Dual Slot |
5 一些名词解释
5.1 CUDA Parallel Processing Cores
在 NVIDIA GPU 架构中用于并行计算的核心单元。这些核心是专门设计用于执行并行计算任务的处理单元,可以同时处理多个计算任务,从而提高计算性能。
采用了SIMD(Single Instruction Multiple Data)架构,即单指令多数据流架构。它允许对不同的数据进行操作同时执行相同的指令,但,从而实现高效的并行计算。每个CUDA 核心都包含多个处理单元,每个处理单元可以同时执行一个线程,这些线程可以同时访问共享的内存和寄存器。
CUDA Parallel Processing Cores 在各种计算密集型应用中发挥着重要作用,包括科学计算、深度学习、机器学习、图形渲染等。通过利用并行计算能力,CUDA 核心可以加速计算任务的执行,提高系统的性能和效率。
在 NVIDIA GPU 中,CUDA Parallel Processing Cores 的数量通常是评估其计算能力和性能的重要指标之一。更多的 CUDA 核心意味着更大的并行计算能力和更快的计算速度,对于需要大规模并行计算的应用来说,拥有更多的 CUDA 核心可以显著提升计算性能。
5.2 NVIDIA RT Cores (3rd Gen)
是指 NVIDIA(英伟达)显卡中的专门硬件单元,用于加速光线追踪(Ray Tracing)和其他与光线相关的计算任务。
光线追踪是一种计算密集型的渲染技术,用于模拟光线在场景中的传播和交互,以生成逼真的图像。传统的图形渲染技术通常使用光栅化(Rasterization)方法,但光线追踪可以更准确地模拟光的行为,从而产生更真实的光照效果。
为了加速光线追踪和相关计算,NVIDIA 在其显卡中引入了 RT Cores。第三代 RT Cores 是 NVIDIA 最新一代的光线追踪加速硬件,相比前代有更高的性能和效率。
RT Cores 使用专门的硬件电路和算法来加速光线追踪计算。它们能够高效地计算光线与场景中的物体的交点,并模拟光线的反射、折射和阴影等效果。通过使用 RT Cores,显卡可以更快地进行光线追踪计算,从而提供更高的渲染性能和更逼真的图像效果。
除了光线追踪,RT Cores 还可以用于其他与光线相关的计算任务,如全局光照(Global Illumination)和实时阴影生成。它们在计算机图形和游戏领域中发挥着重要的作用,提供更高质量的图像渲染和更真实的视觉效果。
5.3 NVIDIA Tensor Cores (4th Gen)
NVIDIA Tensor Cores 是 NVIDIA(英伟达)显卡中的专门硬件单元,用于加速深度学习计算。
深度学习是一种基于人工神经网络的机器学习方法,可以用于图像处理、自然语言处理、语音识别等多个领域。深度学习计算通常涉及大量的矩阵和张量运算,需要进行大量的浮点数计算。为了加速这些计算,NVIDIA 在其显卡中引入了 Tensor Cores。
Tensor Cores 使用专门的硬件电路和算法来加速深度学习计算。它们能够高效地执行矩阵乘法和卷积等深度学习计算中常见的操作,从而提高计算速度和效率。相比传统的计算方法,使用 Tensor Cores 可以显著减少深度学习计算的时间和能源消耗。
Tensor Cores 还支持混合精度计算,即同时使用半精度浮点数(FP16)和单精度浮点数(FP32)进行计算。这种方法可以在保持计算精度的同时,提高计算速度和效率。NVIDIA 的深度学习框架和库,如 TensorFlow 和 PyTorch,都支持 Tensor Cores 的使用。
Tensor Cores 在深度学习、人工智能和科学计算等领域中发挥着重要的作用,可以加速许多复杂的计算任务。它们在加速深度学习训练和推理方面具有独特的优势,是 NVIDIA 显卡的重要特性之一。
5.5 Peak X Tensor TFLOPS with X Accumulate
是指在使用不同的数据精度,例如 FP16(半精度浮点数)进行计算时,硬件设备可以达到的峰值浮点运算速度。
TFLOPS 是浮点运算每秒的计算能力单位,表示每秒可以执行的十亿次浮点运算。在这种情况下,“Peak FP16 Tensor TFLOPS” 指的是硬件设备在使用 FP16 数据类型进行张量运算时,每秒可以执行的浮点运算次数。
FP16 Accumulate 意味着在计算过程中使用 FP16 累加结果。累加是指将多个浮点数相加,以得到最终的结果。在这种情况下,“FP16 Accumulate” 表示在计算过程中使用 FP16 累加操作。
这个指标通常用于衡量硬件设备在进行机器学习和深度学习任务时的计算性能。由于深度学习模型通常具有大量的张量运算,硬件设备的峰值 FP16 Tensor TFLOPS 可以提供参考,以评估其在处理这些任务时的计算速度。然而,实际性能可能受到多种因素的影响,包括算法、数据集和内存带宽等。因此,这个指标应该视为硬件设备的潜力,而不是实际应用中的绝对性能。
关于后面数字的理解
在 “Peak FP16 Tensor TFLOPS with FP16 Accumulate” 中,后面的数字 “366.5|733” 可以这样理解:
366.5:这是指在 FP16(半精度浮点数)计算下,Tensor Cores 的峰值计算性能。TFLOPS 是一个衡量计算性能的单位,表示每秒可以执行的万亿次浮点数计算。因此,366.5 TFLOPS 表示在 FP16 计算下,Tensor Cores 每秒可以执行约 366.5 万亿次浮点数计算。
733:这是指在 FP16 累积(accumulate)计算下,Tensor Cores 的峰值计算性能。累积计算是指在计算过程中将结果累加到一个累加器中,而不是每次计算都写回到内存中。这样可以减少内存访问的次数,提高计算效率。因此,733 表示在 FP16 累积计算下,Tensor Cores 每秒可以执行约 733 万亿次浮点数计算。
这两个数字表示了在不同计算模式下,Tensor Cores 的峰值计算性能。需要注意的是,这些数字是理论上的峰值性能,并不代表实际应用中的性能。实际性能受到多个因素的影响,包括算法、数据访问模式、显卡的功耗和散热等。因此,在实际应用中,实际性能可能会有所不同。
5.6 RT Core Performance
“RT Core Performance” 是指显卡中用于加速光线追踪计算的硬件单元的性能。RT Core 是 NVIDIA 显卡中的硬件单元,用于加速光线追踪计算,从而提高游戏和图形应用的视觉效果和真实感。
RT Core Performance 可以通过不同的指标来衡量,例如每秒光线追踪操作的数量、每秒光线追踪操作的速度等。这些指标通常以 TFLOPS (每秒浮点运算次数) 或 GRays/s (每秒光线追踪操作次数) 为单位进行衡量。
RT Core Performance 是显卡性能的一个方面,它对于实现更高的图形质量和更真实的光线追踪效果至关重要。然而,其他因素,如显存类型、显存容量、GPU 核心数等,也会对显卡的性能产生影响。因此,在选择显卡时,需要综合考虑多个因素来满足您的需求。
5.7 Memory Interface
“Memory Interface” 是指显卡与其显存之间的数据传输通道或接口。它决定了显存与图形处理器 (GPU) 之间的数据传输速度和带宽。
Memory Interface 通常以位数来表示,例如 256-bit 或 384-bit。位数表示显存与 GPU 之间每次传输的数据位数。较高的位数通常意味着更大的带宽和更高的数据传输速度。
Memory Interface 的大小对于显卡的性能和图形处理能力至关重要。较大的 Memory Interface 可以更快地传输数据,提供更高的带宽,从而支持更高的分辨率、更复杂的图形效果和更高的帧率。
然而,Memory Interface 仅仅是显卡性能的一个方面。其他因素,如显存类型、显存容量、GPU 核心数等,也会对显卡的性能产生影响。因此,在选择显卡时,需要综合考虑多个因素来满足您的需求。
5.8 Interconnect
“Interconnect” 是指用于连接不同组件或设备之间的通信接口或通道。在计算机系统中,Interconnect 用于传输数据和信号,以实现不同组件之间的通信和协作。
Interconnect 可以是硬件接口,如总线、电缆或线缆,也可以是软件协议或网络协议,如以太网、PCIe、USB 等。
在计算机系统中,Interconnect 扮演着重要的角色,它决定了组件之间的数据传输速度、带宽和延迟。较快的 Interconnect 可以提供更高的数据传输速度和更低的延迟,从而提高系统的整体性能。
Interconnect 在不同的领域和应用中有不同的含义。例如,在超级计算机中,Interconnect 是用于连接计算节点的高速网络;在数据中心中,Interconnect 是用于连接服务器和存储设备的网络;在芯片级别,Interconnect 是用于连接芯片内部的总线和互连网络。
总之,Interconnect 是指连接不同组件或设备之间的通信接口或通道,它对于计算机系统的性能和功能至关重要。
5.9 ECC
ECC 是 “Error Correction Code” 的缩写,指的是一种用于检测和纠正内存错误的技术。它是一种在计算机系统中使用的机制,旨在提高内存的可靠性和数据完整性。
在计算机内存中,由于各种原因,如硬件故障、电磁干扰或位翻转等,可能会发生数据错误。这些错误可能会导致程序崩溃、数据损坏或系统不稳定。
ECC 技术通过在内存中添加冗余的校验位来检测和纠正这些错误。当数据被写入内存时,ECC 会计算校验位,并将其存储在内存中。当数据被读取时,ECC 会重新计算校验位,并与存储的校验位进行比较。如果发现错误,ECC 将尝试纠正错误并修复数据。
ECC 技术通常用于对于数据完整性要求较高的应用,如服务器、工作站和科学计算等。然而,ECC 内存通常比非ECC内存更昂贵,因为它需要额外的硬件支持和计算资源。
总之,ECC 是一种用于检测和纠正内存错误的技术,它提高了计算机系统的可靠性和数据完整性。
5.10 NVLink
NVLINK 是 NVIDIA 推出的一种高速互连技术,用于连接多个 NVIDIA GPU 以实现更高的性能和更大的内存容量。
NVLINK 提供了一种直接的、点对点的连接方式,可以在多个 NVIDIA GPU 之间传输数据。相比传统的 PCIe 总线,NVLINK 具有更高的带宽、更低的延迟和更高的可扩展性。
NVLINK 技术可以用于多种应用场景,包括高性能计算、人工智能、深度学习等。通过连接多个 GPU,可以实现并行计算和加速大规模数据处理,从而提高计算性能和数据处理能力。
NVLINK 还支持高速 GPU 间的内存共享,使多个 GPU 可以共享大容量的显存,从而扩展了显存的可用空间。这对于需要处理大型数据集或者进行大规模模型训练的任务非常有用。
总之,NVLINK 是一种高速互连技术,用于连接多个 NVIDIA GPU,提供更高的性能、更大的内存容量和更低的延迟,适用于高性能计算、人工智能和深度学习等领域。
5.11 Graphics Bus
Graphics Bus(图形总线)是指用于连接图形卡(显卡)和计算机主板之间的物理接口。它是数据传输和通信的通道,允许图形卡与主板之间进行数据交换和通信。
在过去,常见的图形总线包括 PCI(Peripheral Component Interconnect)和 AGP(Accelerated Graphics Port)。然而,随着技术的发展,现代计算机主板通常采用 PCIe(Peripheral Component Interconnect Express)作为主要的图形总线接口。
PCIe 是一种高速串行总线接口,它提供了更高的带宽和更低的延迟,适用于连接图形卡、扩展卡和其他高性能设备。PCIe 接口分为不同的版本,如 PCIe 3.0、PCIe 4.0 和 PCIe 5.0,每个版本都提供了不同的带宽和性能。
通过图形总线,图形卡可以与计算机主板进行数据传输,从主板获取数据并将渲染后的图像传送回显示器。图形总线的带宽和性能对于图形处理能力和显示效果至关重要,因此选择适合的图形总线对于构建高性能图形系统至关重要。
总之,图形总线是用于连接图形卡和计算机主板之间的物理接口,允许数据传输和通信。PCIe 是现代计算机主板中常见的图形总线接口。通过图形总线,图形卡可以与主板进行数据交换,并将渲染后的图像传送到显示器上显示。
5.12 Display Connectors
显示连接器是用于将计算机或其他设备连接到显示器或显示屏的物理接口。它们提供了视频信号和音频信号传输的通道,使用户可以将计算机或其他设备的图像和声音显示在显示器上。
以下是一些常见的显示连接器:
HDMI(High-Definition Multimedia Interface):HDMI 是一种数字化的高清多媒体接口,广泛用于连接计算机、电视、投影仪和其他设备。它支持高清视频和多声道音频传输,并提供了高质量的图像和声音输出。
DisplayPort:DisplayPort 是一种数字化的视频和音频接口,用于连接计算机、显示器和其他设备。它支持高分辨率、高刷新率和多显示器配置,并提供了高质量的图像和音频传输。
VGA(Video Graphics Array):VGA 是一种模拟视频接口,曾经是最常见的显示连接器之一。它可以连接计算机、显示器和投影仪,但不支持高分辨率和高质量的图像传输。
DVI(Digital Visual Interface):DVI 是一种数字化的视频接口,用于连接计算机、显示器和其他设备。它支持高分辨率和高质量的图像传输,但不支持音频传输。
Thunderbolt:Thunderbolt 是一种高速数据传输和视频接口,可以连接计算机、显示器和其他外部设备。它支持高速数据传输、高分辨率视频和音频传输,并提供了高质量的图像和声音输出。
除了上述常见的显示连接器,还有一些其他类型的连接器,如USB-C(支持DisplayPort和Thunderbolt)、DVI-D(仅支持数字信号)等。
总之,显示连接器是用于将计算机或其他设备连接到显示器或显示屏的物理接口。常见的显示连接器包括HDMI、DisplayPort、VGA、DVI和Thunderbolt等,它们提供了视频和音频信号传输的通道,使用户可以将图像和声音显示在显示器上。
5.13 Dual Slot
Dual Slot 是指硬件设备占用主板上两个相邻插槽的宽度。在计算机领域,插槽是用于安装各种扩展卡的接口,如显卡、声卡、网卡等。每个插槽通常有固定的宽度,以容纳特定类型的扩展卡。
当一个硬件设备被描述为 Dual Slot 时,它意味着该设备需要占用两个相邻的插槽空间。这通常是由于设备尺寸较大或需要更多的散热空间。这种设计可以提供更好的散热效果,以确保设备在高负载下的稳定运行,并防止过热。
由于 Dual Slot 设备占用了两个插槽的空间,用户在安装这样的设备时需要确保主板上有足够的空间来容纳它,并且需要相应的插槽来连接它。此外,由于设备占用了相邻的插槽,用户还需要确保其他设备不会与之冲突。
总的来说,Dual Slot 设备通常具有更大的尺寸和散热需求,以满足更高的性能和功耗要求。这种设计可以提供更好的散热和稳定性,但也需要用户在选择和安装设备时注意相应的硬件兼容性和插槽空间。
6 参考文献
[浅谈NVIDIA L40S,用于数据中心可视化的GPU - 知乎](
相关文章:

Nvidia显卡L40S学习:产品规格,常用名词解释
L40S 1 产品形态 构建NVIDIA OVX服务器,面向数据中心,用于加速AI训练和推理、3D设计和可视化、视频处理和工业数字化等复杂的计算密集型应用每个OVX服务器上8个L40S GPU,每个GPU配备48GB GDDR6超快内存 2 产品发展 具有许多与之前的 NVID…...

【safetensor】介绍和基础代码
Hugging Face, EleutherAI, StabilityAI 用的多 介绍 文件形式 header,体现其特性。如果强行将pickle或者空软连接 打开,会出现报错。解决详见:debug 连接到其他教程结构和参数 安装 with pip:Copied pip install safetensors with con…...

【STM32】--PZ6860L,STM32F4,ARM3.0开发板
一、ARM3.0开发板详细介绍 1.开发板整体介绍 (1)各种外设和主板原理图 (2)主板供电部分5V和3.3V兼容设计 注意跳线帽 2.STM32核心板介绍 3.核心板原理图 STM32和51的IO对应关系 下载电路 二、ARM3.0开发板ISP下载原理分析 1.I…...

百分点科技再度亮相GITEX全球大会
10月16-20日,全球最大科技信息展会之一 GITEX Global 2023在迪拜世贸中心开展,本届展会是历年来最大的一届,吸引了来自180个国家的6,000家参展商和180,000名技术高管参会。 百分点科技作为华为生态合作伙伴,继去年之后再度参展&a…...
机器学习笔记 - 深度学习中跳跃连接的直观解释
一、概述 如今人们利用深度学习做无数的应用。然而,为了理解在许多作品中看到的大量设计选择(例如跳过连接),了解一点反向传播机制至关重要。 如果你在 2014 年尝试训练神经网络,你肯定会观察到所谓的梯度消失问题。简单来说:你在屏幕后面检查网络的训练过程,你看到的只…...

利用python中if函数判断三角形的形状
1 问题 如何利用python中if函数判断三角形形状。 2 方法 给以一个三角形的三边长a,b和c(边长是浮点数),根据三角形三边关系定理以及勾股定理为基础,使用if函数判断三角形的形状。若是锐角三角形,输出R, 若是直角三角形,输出Z, 若是…...
分布式共识算法及落地
摘要 本文介绍常见的分布式共识算法,使用场景,以及相关已经落地了的程序或框架 1. 为什么要分布式共识算法 在分布式系统中,不同节点之间可能存在网络延迟、故障等原因导致彼此之间存在数据不一致的情况,为了保证分布式系统中的…...

HTML图像标签
html文件: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>图像标签学习</title> </head> <body> <img src"../resources/image/01.jpg" alt"小狗图…...
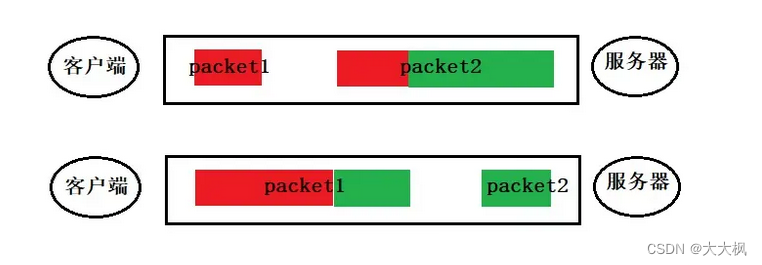
Openssl数据安全传输平台006:粘包的处理-代码框架及实现-TcpSocket.cpp
文章目录 0. 代码仓库1. TCP通信粘包问题2. 粘包、拆包表现形式2.1 正常情况2.2 两个包合并成一个包2.3 出现了拆包 3. 粘包的处理-参考仓库中的文件TcpSocket.cpp3.1 发送数据时候的处理3.2 接收数据时候的处理 0. 代码仓库 https://github.com/Chufeng-Jiang/OpenSSL_Secure_…...

Java中在控制台读取字符
Scanner 是 Java 中的一个类,用于从各种输入源获取输入,如键盘、字符串、文件等。以下是如何使用 Scanner 的基本示例: javaimport java.util.Scanner; // 导入 Scanner 类public class Main { public static void main(String[] args) { Sca…...

PositiveSSL的泛域名SSL证书
PositiveSSL是Sectigo旗下的一个子品牌,致力于为全球用户提供优质、高效的SSL证书服务。PositiveSSL以Sectigo强大的品牌影响力和全球网络为基础,秉承“安全、可靠、高效”的服务理念,为各类网站提供全面的SSL证书解决方案。今天就随SSL盾小编…...
模拟 Junit 框架
需求 定义若干个方法,只要加了MyTest注解,就可以在启动时被触发执行 分析 定义一个自定义注解MyTest,只能注解方法,存活范围是一直都在定义若干个方法,只要有MyTest注解的方法就能在启动时被触发执行,没有这…...
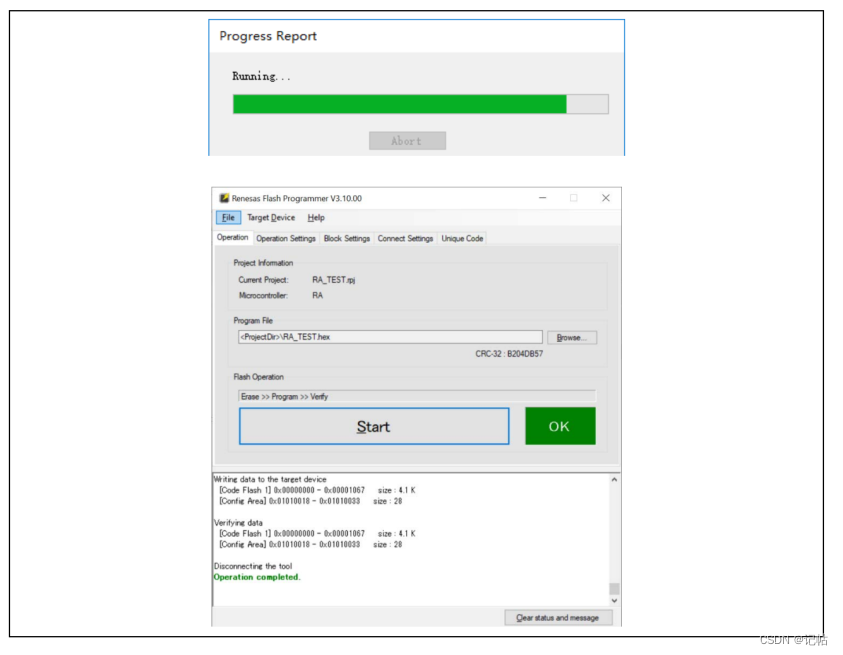
瑞萨e2studio(27)----使用EZ-CUBE3烧录
瑞萨e2studio.27--使用EZ-CUBE3烧录 概述视频教学样品申请引脚配置EZ-CUBE3 仿真器开关设置对RA族MCU进行Flash编程蓝色 LED 指示灯的状态信息 概述 EZ-CUBE3(CYRCNEZCUBE03)是具有Flash存储器编程功能的片上调试仿真器,可以用于调试MCU程序…...
springBoot--web--函数式web
函数式web 前言场景给容器中放一个Bean:类型是 RouterFunction<ServerResponse>每个业务准备一个自己的handler使用集合的时候加注解请求的效果 前言 springmvc5.2 以后允许我们使用函数式的方式,定义web的请求处理流程 函数式接口 web请求处理的…...

react中hooks闭包
import React, { useState } from react;function Counter() {const [count, setCount] useState(0);return (<div><p>Count: {count}</p><button onClick{() > setCount(count 1)}>Increment</button></div>); }在上面的 React 组件…...
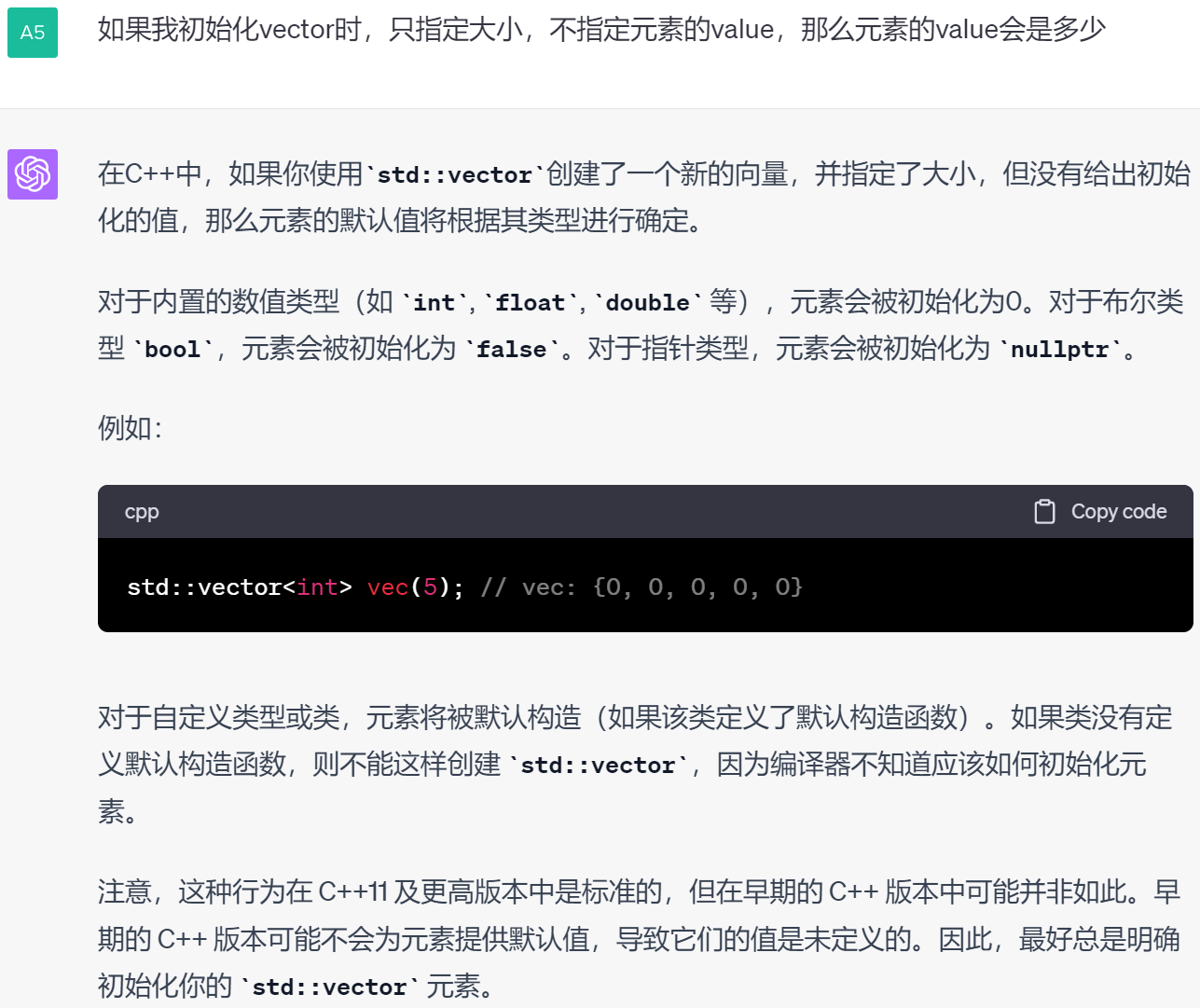
C++笔记之vector的初始化以及assign()方法
C笔记之vector的初始化以及assign()方法 —— 2023年4月15日 上海 code review 文章目录 C笔记之vector的初始化以及assign()方法代码——实践出真知0. 空的vector1. 花括号(initializer_list)——最推荐的初始化方法2. 花括号3. 圆括号花括号4. 圆括号5. 圆括号6. 指针花括号7…...

OSPF基础实验
一、实验拓扑 二、实验要求 1、按照图示配置 IP 地址 2、R1,R2,R3 运行 OSPF 使内网互通,所有接口(公网接口除外)全部宣告进 Area 0; 要求使用环回口作为 Router-id 3、业务网段不允许出现协议报文 4、R5 模拟互联网,内网通过…...

笔记本Charge与Vcore方案
一、笔记本Vcore方案 IMVP8/9:Intel Mobile Voltage Positionin VR12.5:就是指FIVR集成式调压模块(Haswell架构) PMIC:电源管理芯片(Power Management Integrated Circuits) 常见问题分析 1. 不开机,VCORE 短路 : 通常是因为Low side MOS短路造成.量测时可以先将MOS拿…...

error C2632: ‘char‘ followed by ‘char‘ is illegal
error C2632: char followed by char is illegal remove -stdc99...
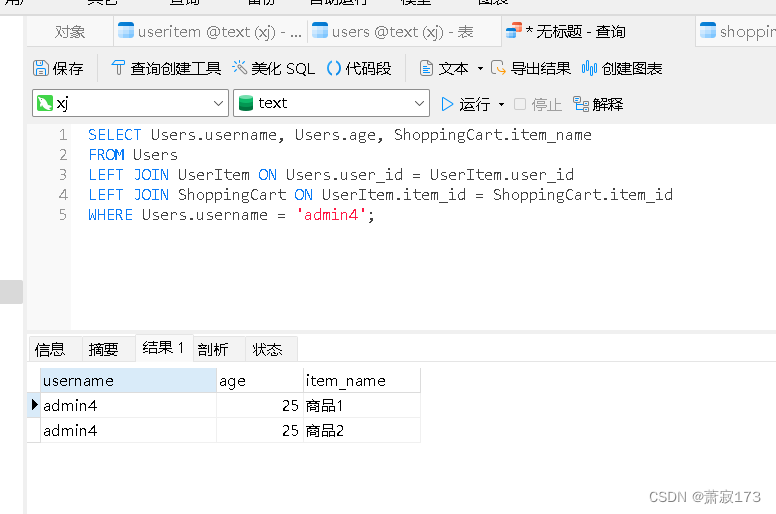
MySql数据库实现注册登录及个人信息查询的数据库设计
前言: 数据库使用的是mysql 以下创建的表,实现以下功能: 用户1,账号admin,年龄20,关联3件商品 用户2,账号admin2,年龄30,关联2件商品(没有商品和用户1重复) 用户3,账号admin3,年龄50,关联2件商品(这两件商品均是用户1的其中两种) 登录查询对应数据的实现 1.创建用户表Users,并…...

避开这些坑!百度智能云AppBuilder API调用中的5个常见错误及解决方案
百度智能云AppBuilder API实战避坑指南:从鉴权到调用的深度解析 第一次接触百度智能云AppBuilder API时,我像大多数开发者一样,以为这不过是又一个标准的RESTful接口。直到凌晨三点被报警短信惊醒——某个未做限流的API密钥在短短两小时内耗尽…...

MySQL 索引失效排查思路
MySQL索引失效排查思路:提升查询性能的关键 在数据库优化中,索引是提升查询性能的核心手段。即使创建了索引,查询速度仍可能不理想,这往往是由于索引失效导致的。如何快速定位并解决索引失效问题?本文将从常见场景出发…...

专为AWD/CTF攻防而生!一站式管理、权限维持、基线加固、Flag读取,助力参赛选手在比赛中高效管理多个目标
0x01 工具介绍 LingOps(灵控)是专为AWD/AWDP/CTF攻防竞赛打造的自动化平台,精准贴合赛事实战需求,集IP探测、WebShell与SSH终端管控、木马生成、权限维持、WAF防御、基线加固、Flag定时读取等全流程功能于一体,一站式…...

原神祈愿记录导出工具:3分钟掌握你的抽卡命运
原神祈愿记录导出工具:3分钟掌握你的抽卡命运 【免费下载链接】genshin-wish-export Easily export the Genshin Impact wish record. 项目地址: https://gitcode.com/GitHub_Trending/ge/genshin-wish-export 核心关键词:原神抽卡记录导出、祈愿…...

[特殊字符]5分钟快速体验Lychee-Rerank:本地启动→输入→出分全流程详解
5分钟快速体验Lychee-Rerank:本地启动→输入→出分全流程详解 想不想在本地快速搭建一个智能的文档相关性评分工具?不用联网,不用担心数据隐私,还能直观地看到每篇文档的匹配度高低。今天,我就带你用5分钟时间&#x…...

第三章:LangChain Classic vs. 新版 LangChain —— 架构演进与迁移指南
系列:深入 LangChain —— 从核心原理到生产实践 前置阅读:第一章:LangChain 生态全景、第二章:LangChain Core 深度剖析 学习目标 理解 langchain-classic(libs/langchain/)与新版 langchain(libs/langchain_v1/)的本质区别 掌握 Classic 中 Chain、Agent、Memory 三大…...
数据处理实战:从人脑图谱构建到动物模型分析)
静息态功能磁共振成像(rs-fMRI)数据处理实战:从人脑图谱构建到动物模型分析
1. rs-fMRI数据处理全流程解析 静息态功能磁共振成像(rs-fMRI)是研究大脑自发神经活动的重要工具。与任务态fMRI不同,rs-fMRI不需要受试者执行特定任务,只需保持安静状态即可。这种技术特别适合研究抑郁症等精神疾病,因…...

IO 管理是涵盖驱动、调度、缓存、接口的完整子系统。
1. 接口层 (Interface):统一的“下单窗口” 角色:虚拟文件系统 (VFS) 或 字符/块设备接口。职责: 抽象化:向应用程序提供统一的 API(如 read(), write(), open())。屏蔽差异:应用层不需要知道底…...
)
收藏!大模型求职避坑指南:别再死背八股,这样准备才稳过面试(小白/程序员必看)
最近和不少研一、研二的同学,还有刚入门大模型的程序员聊天,发现大家都在踩同一个坑:刷了上百道八股题,Transformer的结构、注意力机制倒背如流,RAG的每个模块(检索、召回、重排)都能侃侃而谈&a…...

Tox故障排除指南:常见问题及解决方案大全
Tox故障排除指南:常见问题及解决方案大全 Tox是一款强大的命令行驱动CI前端和开发任务自动化工具,能够帮助开发者在不同环境中自动化测试、打包和部署流程。本文将汇总Tox使用过程中的常见问题及解决方案,助你快速定位并解决问题,…...