正则表达式的神奇世界:表达、匹配和提取
正则表达式的神奇世界:表达、匹配和提取
- 前言
- 第一: 什么是正则表达式?
- 第二: 字符匹配和量词:
- 1. 字符匹配:
- 2. 量词:
- 3. 贪婪和非贪婪匹配:
- 第三:字符类和元字符
- 1. 字符类:
- 2. 特殊元字符:
- 第四:边界匹配
- 1. 开始和结束的边界:
- 2. 单词边界:
- 第五:分组和匹配
- 1. 使用括号进行分组:
- 2. 提取匹配的子字符串:
- 第六:正则表达式在编程中的应用:
- 第七:常见正则表达式示例
- 第八:正则表达式的高级用法
- 1. 向前向后查看(Lookahead and Lookbehind):
- 2. 自定义函数:
- 第九:常见错误和调试:
- 常见的正则表达式错误:
- 调试工具和技巧:
前言
正则表达式,这个看起来像密林中的迷宫的工具,既神秘又令人着迷。它是编程世界中的一门魔法,有着神奇的能力。你是否曾经在寻找或解析文本时感到束手无策?或许你想要从海量数据中提取特定信息?这正是正则表达式可以派上用场的时候。本文将带你探索这个神奇的工具,从入门到高级,帮助你驾驭它,解密你的数据。
第一: 什么是正则表达式?
正则表达式,也被称为正则表达式或正则模式,是一种用于匹配文本模式的工具。它是一个强大的文本处理工具,允许你根据特定模式来搜索、替换和提取文本数据。正则表达式可以用于多种编程语言和文本处理工具,如Python、JavaScript、Perl、以及文本编辑器中的查找与替换功能。
正则表达式的基本语法包括以下元字符和模式:
-
字面文本字符: 通常,正则表达式由字面文本字符组成,它们精确匹配输入文本中的相应字符。例如,正则表达式
abc将匹配输入文本中的字符 “abc”。 -
元字符: 正则表达式中的元字符具有特殊含义,用于定义匹配模式。一些常见的元字符包括:
.:匹配任何字符(除了换行符)。*:匹配前一个字符的零个或多个实例。+:匹配前一个字符的一个或多个实例。?:匹配前一个字符的零个或一个实例。^:匹配字符串的开头。$:匹配字符串的结尾。[]:用于定义字符类,匹配其中的任何一个字符。():用于分组,以便对表达式的一部分应用其他元字符。
-
转义字符: 如果要匹配元字符本身,需要使用反斜杠
\进行转义。例如,\.匹配实际的句点字符。 -
量词: 量词用于指定匹配的重复次数,如
{n}(精确匹配 n 次)、{n,}(至少匹配 n 次)、{n,m}(匹配 n 到 m 次)。 -
特殊字符: 正则表达式还包含一些特殊字符,如
\d(匹配数字)、\w(匹配字母、数字或下划线)、\s(匹配空白字符)。
正则表达式的语法和功能非常广泛,这里提到的是一些基本的概念。你可以根据需要进一步学习和使用正则表达式,以实现各种文本处理任务。在代码中,通常会使用字符串前缀 r 表示原始字符串,以避免反斜杠的转义。例如,r'\d+' 表示匹配一个或多个数字。
第二: 字符匹配和量词:
当使用正则表达式进行文本匹配时,你可以使用字符匹配和量词来指定匹配字符、数字、空格等,以及控制匹配多个字符的次数。此外,你还可以使用贪婪匹配和非贪婪匹配来控制匹配的行为。
1. 字符匹配:
\d:匹配任何数字(0-9)。\D:匹配任何非数字字符。\w:匹配字母、数字或下划线(单词字符)。\W:匹配任何非单词字符。\s:匹配空白字符,包括空格、制表符和换行符。\S:匹配非空白字符。
示例:
\d匹配任何数字字符。\w+匹配一个或多个连续的字母、数字或下划线字符。\s*匹配零个或多个连续的空白字符。
2. 量词:
*:匹配前一个字符的零个或多个实例。+:匹配前一个字符的一个或多个实例。?:匹配前一个字符的零个或一个实例。{n}:精确匹配前一个字符的 n 次。{n,}:匹配前一个字符至少 n 次。{n,m}:匹配前一个字符 n 到 m 次。
示例:
\d{3}匹配连续的三个数字。\w{2,5}匹配连续的字母、数字或下划线字符,其长度在2到5之间。\s?匹配零个或一个空白字符。
3. 贪婪和非贪婪匹配:
- 贪婪匹配是默认行为,它会尽可能多地匹配字符。
- 非贪婪匹配使用
*?、+?、??这样的量词后缀,使匹配尽可能少的字符。
示例:
- 对于字符串
"123456", 贪婪匹配(\d+)*会匹配整个字符串,而非贪婪匹配(\d+?)*会匹配每个数字。
这些是正则表达式中用于字符匹配和量词的基本概念。你可以根据具体的需求使用这些元字符和量词来构建正则表达式,以实现不同的文本匹配和提取操作。请记住,正则表达式的具体语法和行为可能会根据使用的编程语言或工具而有所不同,因此需要查看相关文档以获取更多详细信息。
第三:字符类和元字符
字符类和元字符是正则表达式中的重要概念,它们用于匹配字符范围和具有特殊含义的字符。下面是关于字符类和特殊元字符的介绍:
1. 字符类:
[...]:字符类用于匹配一个字符范围中的任何一个字符。在方括号内,你可以列出希望匹配的字符,例如[aeiou]可以匹配任何一个元音字母。也可以使用短划线表示范围,比如[0-9]匹配任何数字。[^...]:在字符类的开头使用脱字符^,它表示反向匹配,即匹配除了指定字符范围内的字符之外的所有字符。
示例:
[aeiou]匹配任何一个元音字母。[A-Za-z]匹配任何一个英文字母。[^0-9]匹配任何非数字字符。
2. 特殊元字符:
.:匹配除换行符之外的任何字符。例如,a.c可以匹配 “abc”、“a1c” 等。^:匹配字符串的开头,用于限定匹配从字符串开始的部分。$:匹配字符串的结尾,用于限定匹配到字符串结束的部分。|:用于表示或操作,例如A|B匹配 “A” 或 “B”。():用于分组,可以改变操作符的优先级,也可以捕获匹配的内容。*:匹配前一个字符的零个或多个实例。+:匹配前一个字符的一个或多个实例。?:匹配前一个字符的零个或一个实例。
示例:
^A匹配以 “A” 开头的字符串。abc|def匹配 “abc” 或 “def”。(abc)+匹配连续多个 “abc”。\d+匹配一个或多个数字。
这些特殊元字符和字符类提供了强大的匹配和搜索功能,允许你构建更复杂的正则表达式以匹配文本中的不同模式。记住,正则表达式的具体语法和特殊元字符可能因编程语言和工具的不同而有所变化,因此需要查看相关文档以获取详细信息。
第四:边界匹配
边界匹配是正则表达式中的一项重要功能,它允许你限定匹配发生在字符串的开始、结束或单词边界上。下面是关于边界匹配的两个常用概念:
1. 开始和结束的边界:
^:在正则表达式中使用^来匹配字符串的开始。例如,正则表达式^Hello将匹配以 “Hello” 开头的字符串。$:使用$来匹配字符串的结束。例如,正则表达式World$将匹配以 “World” 结尾的字符串。
示例:
^Start匹配以 “Start” 开头的字符串。End$匹配以 “End” 结尾的字符串。
2. 单词边界:
\b:单词边界是一个特殊的元字符,用于匹配单词的边界。它不匹配字符,而是匹配字符与非字符之间的位置。例如,\bword\b只匹配独立的 “word” 单词,而不匹配 “words” 中的 “word” 部分。\B:与\b相反,\B匹配非单词边界的位置。例如,\Bword\B可以用来匹配嵌入在其他单词中的 “word”。
示例:
\bhello\b匹配独立的 “hello”,不匹配 “helloworld” 中的 “hello”。\Bword\B匹配嵌入在其他字符中的 “word”,例如 “myword” 中的 “word”。
边界匹配非常有用,因为它允许你明确指定匹配发生的位置,以防止不必要的匹配。这对于在文本中查找完整的单词或确保匹配位于字符串的特定位置非常有用。
第五:分组和匹配
分组和捕获是正则表达式中强大的功能,允许你将模式分组并从匹配的文本中提取子字符串。这对于处理复杂的文本匹配任务非常有用。
1. 使用括号进行分组:
( ... ):括号用于将模式分组,可以包含一个或多个字符或子模式。这允许你对子模式应用量词、元字符等。|:竖线用于创建多个分组的选择,类似于逻辑或。例如,(apple|banana)匹配 “apple” 或 “banana”。
示例:
(abc)+匹配连续多个 “abc”。(red|green|blue)匹配 “red”、“green” 或 “blue”。(\d{2,4})-(\d{2})-(\d{2})匹配日期格式,例如 “2023-10-18”,并将年、月、日分别放入不同的捕获组。
2. 提取匹配的子字符串:
- 当使用括号进行分组时,你可以捕获匹配的子字符串以供后续处理。
- 使用捕获组编号来提取子字符串。通常,编号从 1 开始,按括号的左括号出现的顺序递增。
- 在许多编程语言中,你可以通过
\1、\2等来引用捕获组中的内容。
示例:
- 假设正则表达式为
(\d{2})-(\d{2})-(\d{4}),对于字符串 “18-10-2023”,可以通过\1获取日,\2获取月,\3获取年。 - 在Python中,你可以使用
re模块的match或search函数来提取捕获组中的内容。
import repattern = r'(\d{2})-(\d{2})-(\d{4})'
text = '18-10-2023'
match = re.search(pattern, text)
if match:day = match.group(1)month = match.group(2)year = match.group(3)
分组和捕获允许你更灵活地处理匹配的文本,将特定部分提取出来以便进一步操作,如数据处理、替换等。这在文本处理和数据提取任务中非常有用。
第六:正则表达式在编程中的应用:
正则表达式在编程中有广泛的应用,包括在文本编辑器中查找替换操作和在编程语言中的使用。以下是它们的具体应用:
在文本编辑器中查找和替换:
-
查找文本: 文本编辑器通常提供正则表达式搜索功能,允许用户使用正则表达式来查找文本文件中的特定模式。这对于大规模的文本处理和搜索非常有用。
-
替换文本: 正则表达式还可用于文本替换操作。你可以使用正则表达式来搜索匹配模式,并用指定的文本替换它们。这对于批量文本替换、格式规范化等任务非常实用。
在编程语言中的使用:
-
字符串操作: 编程语言通常内置对正则表达式的支持,允许你在字符串中进行匹配、搜索和提取操作。这对于处理用户输入、解析数据、验证格式等任务非常有用。
-
数据提取: 你可以使用正则表达式来从文本数据中提取有用的信息,如日期、电子邮件地址、URL、电话号码等。这在数据挖掘和文本分析中经常用到。
-
数据验证: 正则表达式可以用于验证输入的格式是否符合要求。例如,验证密码强度、身份证号码的格式等。
-
文本处理: 正则表达式可用于文本处理任务,如分词、词干提取、删除空白字符等。
-
日志分析: 在日志文件中,正则表达式可用于筛选出特定类型的日志条目,以进行分析和报告生成。
-
网页爬虫: 在网页爬虫开发中,正则表达式可用于从网页源代码中提取所需的信息,如链接、标题、价格等。
不同编程语言对正则表达式的支持略有不同,但通常都提供了相似的功能,例如在Python中,你可以使用re模块,而在JavaScript中,你可以使用内置的正则表达式功能。正则表达式是处理文本和数据的有力工具,但也需要谨慎使用,因为复杂的正则表达式可能会变得难以理解和维护。
第七:常见正则表达式示例
以下是一些常见的正则表达式示例,以及它们的用途:
-
匹配Email地址:
- 正则表达式:
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,} - 用途:用于验证和提取电子邮件地址。
- 正则表达式:
-
匹配URL:
- 正则表达式:
https?://\S+ - 用途:用于从文本中提取URL。
- 正则表达式:
-
匹配日期:
- 正则表达式:
\d{2}/\d{2}/\d{4} - 用途:用于识别和提取日期格式。
- 正则表达式:
-
匹配IP地址:
- 正则表达式:
\b(?:\d{1,3}\.){3}\d{1,3}\b - 用途:用于验证和提取IP地址。
- 正则表达式:
-
匹配HTML标签:
- 正则表达式:
<[^>]+> - 用途:用于从HTML文本中提取标签或删除标签。
- 正则表达式:
-
匹配电话号码:
- 正则表达式:
\d{3}-\d{3}-\d{4} - 用途:用于验证和提取电话号码。
- 正则表达式:
-
匹配空白行:
- 正则表达式:
^\s*$ - 用途:用于查找或删除空白行。
- 正则表达式:
-
匹配单词:
- 正则表达式:
\b\w+\b - 用途:用于提取文本中的单词。
- 正则表达式:
-
匹配十六进制颜色代码:
- 正则表达式:
#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3}) - 用途:用于验证和提取HTML颜色代码。
- 正则表达式:
-
匹配身份证号码:
- 正则表达式:
\d{17}[\dXx] - 用途:用于验证和提取身份证号码。
- 正则表达式:
这些示例只是冰山一角,正则表达式可以根据具体的需求变得更复杂。在使用正则表达式时,始终要谨慎测试和验证,以确保其按预期工作,特别是在处理用户输入或敏感数据时。
第八:正则表达式的高级用法
正则表达式的高级用法包括向前向后查看以及结合自定义函数的应用。这些功能提供了更复杂和灵活的文本处理和匹配能力。
1. 向前向后查看(Lookahead and Lookbehind):
- 向前查看:
(?=...),它用于匹配满足某个条件的位置,但不包括这个条件本身。例如,(?=\d)可以匹配后面跟着一个数字的位置。 - 向后查看:
(?<=...),它用于匹配位于某个条件之前的位置,但不包括这个条件本身。例如,(?<=\d)可以匹配前面有一个数字的位置。 - 负向前查看:
(?!...),用于匹配不满足某个条件的位置。例如,(?!\d)可以匹配后面不是数字的位置。 - 负向后查看:
(?<!...),用于匹配不位于某个条件之前的位置。例如,(?<!\d)可以匹配前面不是数字的位置。
这些向前和向后查看功能非常有用,因为它们允许你匹配特定位置而不捕获实际的字符。这对于复杂的匹配和排除情况非常有帮助。
2. 自定义函数:
- 有些编程语言允许你结合自定义函数与正则表达式一起使用。例如,Python的
re模块中的re.sub()函数可以接受一个自定义函数作为替换参数。 - 你可以在自定义函数中根据匹配的内容执行特定的操作,然后返回替代文本。
示例(Python):
import redef custom_replace(match):matched_text = match.group(0)# 在这里执行自定义操作,例如将匹配的文本转为大写return matched_text.upper()text = "hello world"
pattern = r'\b\w+\b'
result = re.sub(pattern, custom_replace, text)
print(result) # 输出: "HELLO WORLD"
自定义函数结合正则表达式提供了非常灵活的文本处理能力,你可以根据匹配情况执行各种自定义操作。
这些高级功能扩展了正则表达式的应用范围,允许你更精确地控制文本处理,但也需要更深入的理解和实践。在实际使用中,它们通常用于解决特定的复杂文本处理问题。
第九:常见错误和调试:
在编写正则表达式时,常常会出现一些错误。以下是一些常见的正则表达式错误以及调试工具和技巧,帮助你找到和修复这些问题:
常见的正则表达式错误:
-
语法错误: 正则表达式的语法非常严格,小错误可能导致匹配失败。例如,未转义特殊字符或未关闭括号。
-
贪婪匹配错误: 默认情况下,正则表达式是贪婪的,可能匹配更多字符,导致意外的结果。在量词后加上
?可以将其改为非贪婪匹配。 -
字符范围错误: 在字符类中,如果未正确定义字符范围,可能会导致不符预期的匹配。
-
没有考虑边界: 未正确处理边界情况,可能会导致匹配到不应该匹配的部分。
-
忘记转义: 特殊字符需要转义,例如句点
.应该用\.来匹配实际的句点字符。
调试工具和技巧:
-
在线正则表达式测试器: 有许多在线工具可用于测试正则表达式。你可以输入正则表达式和文本,然后查看匹配结果,如RegExr、Regex101等。
-
正则表达式编辑器: 许多文本编辑器和集成开发环境(IDE)具有内置的正则表达式支持,包括语法高亮和测试功能。
-
日志输出: 在调试时,可以将匹配的文本和捕获组的内容输出到日志文件,以查看正则表达式的实际效果。
-
逐步调试: 如果正则表达式非常复杂,可以逐步构建和测试它。将正则表达式分成多个小部分,逐步添加和测试,以确保每个部分按预期工作。
-
学习文档: 学习正则表达式的官方文档,了解不同编程语言和工具的正则表达式规则和支持。
-
练习: 练习编写正则表达式是掌握它的关键。有许多在线练习网站,如RegexOne,提供了练习的机会。
正则表达式在实践中可能需要一些时间来掌握,但一旦掌握了它,它将成为一个非常有用的工具,用于文本处理、搜索和提取。不断练习和调试将有助于改进你的正则表达式技能。
相关文章:

正则表达式的神奇世界:表达、匹配和提取
正则表达式的神奇世界:表达、匹配和提取 前言第一: 什么是正则表达式?第二: 字符匹配和量词:1. 字符匹配:2. 量词:3. 贪婪和非贪婪匹配: 第三:字符类和元字符1. 字符类&a…...

密码登录虽安全,但有时很麻烦!如何禁用或删除Windows 11中的密码登录
如果你想在Windows 11上自动登录,在本指南中,我们将向你展示如何删除你的帐户密码。 在Windows 11上,你可以至少通过三种方式从帐户中删除登录密码。在你的帐户上使用密码有助于保护你的计算机和文件免受来自internet或本地的未经授权的访问。然而,在某些情况下,密码可能…...

Python实现的快速排序代码
Python实现的快速排序代码 def bubble_sort(arr): n len(arr) for i in range(n): for j in range(0, n-i-1): if arr[j] > arr[j1]: arr[j], arr[j1] arr[j1], arr[j] return arr 冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,…...

【USRP】通信基带物理层历史
无线通信的基带物理层开发历史涵盖了从早期无线技术到当前复杂的移动通信标准的各种进步。以下是关于无线通信基带物理层开发的简要历史概述: 无线电初期:20世纪初,Guglielmo Marconi等人通过无线电进行了早期的无线通信尝试。这些早期的尝试…...
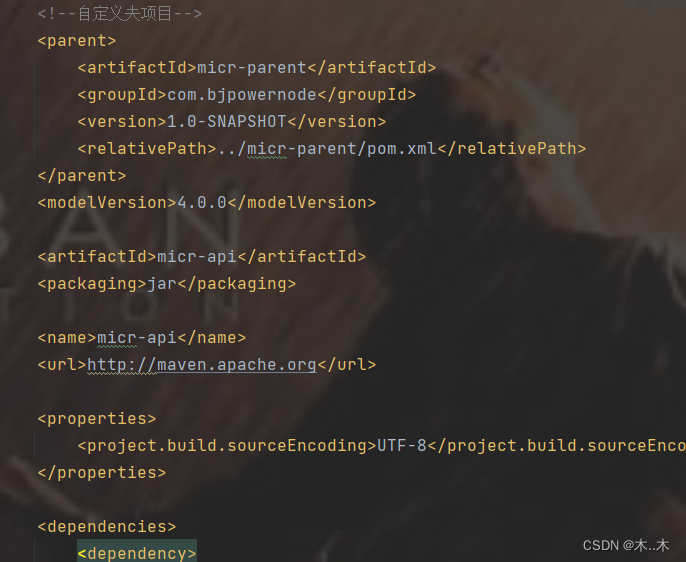
依靠继承与聚合,实现maven搭建分布式项目
简介聚合 对于复杂的Maven项目,一般建议采用多模块的方式来设计开发,便于后期维护管理。但是构建项目时,如果每次都需要按模块一个一个进行构建会十分麻烦,而Maven的聚合功能就可以很好的解决这个问题,当用户对聚合模…...
【java】A卷+B卷)
华为OD 叠积木(100分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为O…...

vue重修之自定义项目、ESLint和代码规范修复
文章目录 VueCli 自定义创建项目ESlint代码规范及手动修复代码规范错误 VueCli 自定义创建项目 安装脚手架 (已安装) npm i vue/cli -g创建项目 vue create xxx选项 Vue CLI v5.0.8 ? Please pick a preset:Default ([Vue 3] babel, eslint)Default ([Vue 2] babel, eslint) …...
【java】A卷+B卷)
华为OD 完全二叉树非叶子部分后序遍历(200分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应往年部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为OD…...

AI是未来?——神经网络篇
AI是未来?——神经网络篇 文章目录 AI是未来?——神经网络篇1. 神经网络小记问题记录: 1. 神经网络小记 疑问:假如让神经网络识别一张猫的图片,他经过了n个神经元节点最终识别为了狗。那么此时观察产生反应的这些神经…...

c语言练习94:分割链表
分割链表 给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你不需要 保留 每个分区中各节点的初始相对位置。 示例 1: 输入:head [1,4,3,2,5,2], x…...
【java】A卷+B卷)
华为OD 数组二叉树(200分)【java】A卷+B卷
华为OD统一考试A卷+B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应往年部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击以下链接进入: 我用夸克网盘分享了「华为OD…...
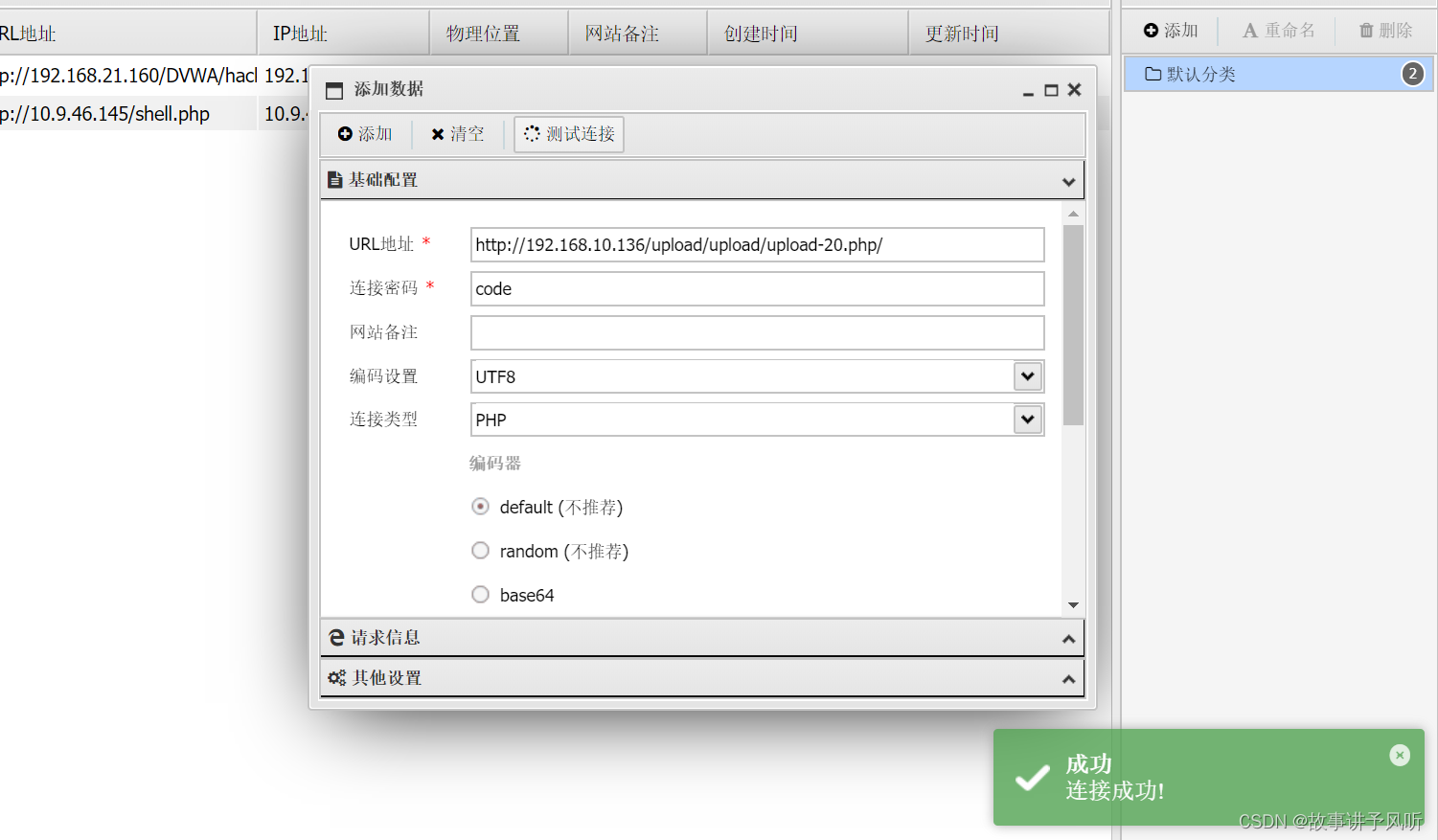
Upload-labs(1-20关保姆级教程)
靶场下载链接 https://github.com/c0ny1/upload-labs 话不多说,直接喂饭 lab-1 上传php木马,发现弹出提示框,查看源码可知是前端过滤 bp抓包,先上传一张正常的jpg图片 修改文件内容和后缀,大概就是想怎么改就怎么…...
C语言实现调整数组中奇数偶数顺序
目录 1.思路2. 代码 1.思路 给定两个下标left和right,left放在数组的起始位置,right放在数组中最后一个元素的位置循环进行一下操作 a. 如果left和right表示的区间[left, right]有效,进行b,否则结束循环 b. left从前往后找&#…...

从车窗升降一探 Android 车机的重要 API:车辆属性 CarProperty
前言 前面我们介绍过 Android 车机 Automotive OS 的几块重要内容: 一文了解 Android 车机如何处理中控的旋钮输入从实体按键看 Android 车机的自定义事件机制深度入门 Android 车机核心 CarService 的构成和链路 本篇文章我们聚焦 Android 车机上最重要、最常用…...
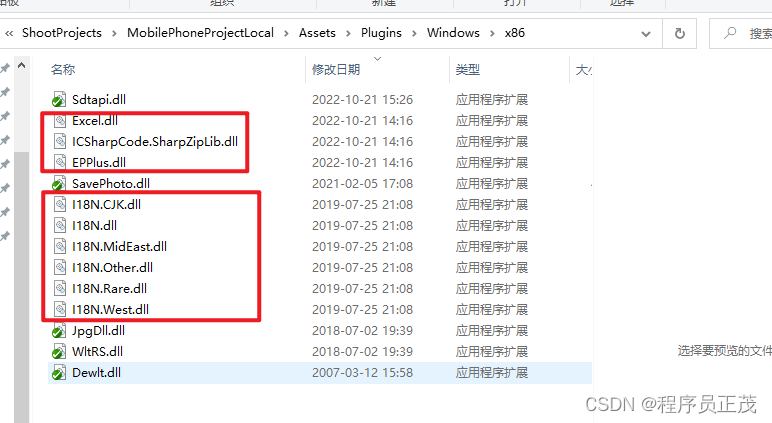
Unity读取写入Excel
1.在Plugins中放入dll,118开头的dll在Unity安装目录下(C:\Program Files\Unity\Editor\Data\Mono\lib\mono\unity) 2.写Excel public void WriteExcel(){//文件地址FileInfo newFile new FileInfo(Application.dataPath "/test.xlsx…...
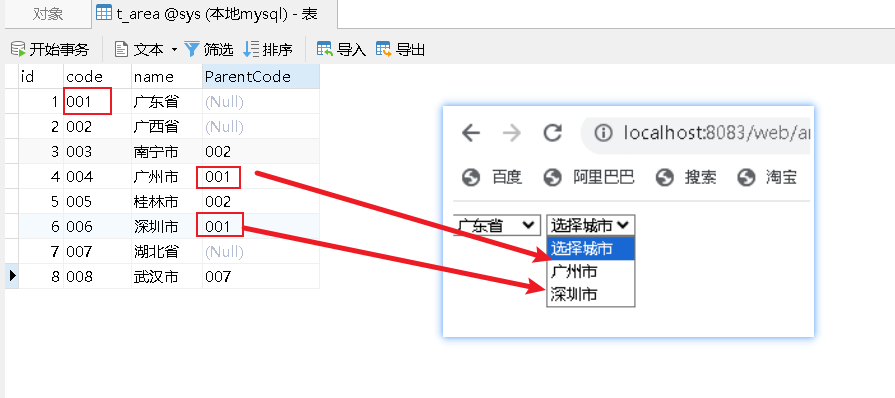
手搭手Ajax经典基础案例省市联动
环境介绍 技术栈 springbootmybatis-plusmysql 软件 版本 mysql 8 IDEA IntelliJ IDEA 2022.2.1 JDK 1.8 Spring Boot 2.7.13 mybatis-plus 3.5.3.2 pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http:/…...

分类预测 | MATLAB实现SSA-CNN-BiLSTM-Attention数据分类预测(SE注意力机制)
分类预测 | MATLAB实现SSA-CNN-BiLSTM-Attention数据分类预测(SE注意力机制) 目录 分类预测 | MATLAB实现SSA-CNN-BiLSTM-Attention数据分类预测(SE注意力机制)分类效果基本描述模型描述程序设计参考资料 分类效果 基本描述 1.MAT…...

Springboot后端开发_日志
SpringBoot_日志 简介1、日志框架2、SLF4j使用1、如何在系统中使用SLF4j https://www.slf4j.org2、遗留问题 3、SpringBoot日志关系4、日志使用1、默认配置2、指定配置 5、切换日志框架拓展:日志分组 简介 6 种日志级别 TRACE: designates finer-grained informat…...

Unable to connect to the server: x509: certificate is valid for问题解决
文章目录 环境描述问题描述问题原因解决方案额外问题问题描述问题解决方案新问题 环境描述 Kubernetes版本1.15测试客户端centos7 问题描述 将构建于内网网络环境上的kubernetes集群的/etc/kubernetes/admin.conf文件拷贝到外网的一台装有kubernetes客户端的设备上ÿ…...
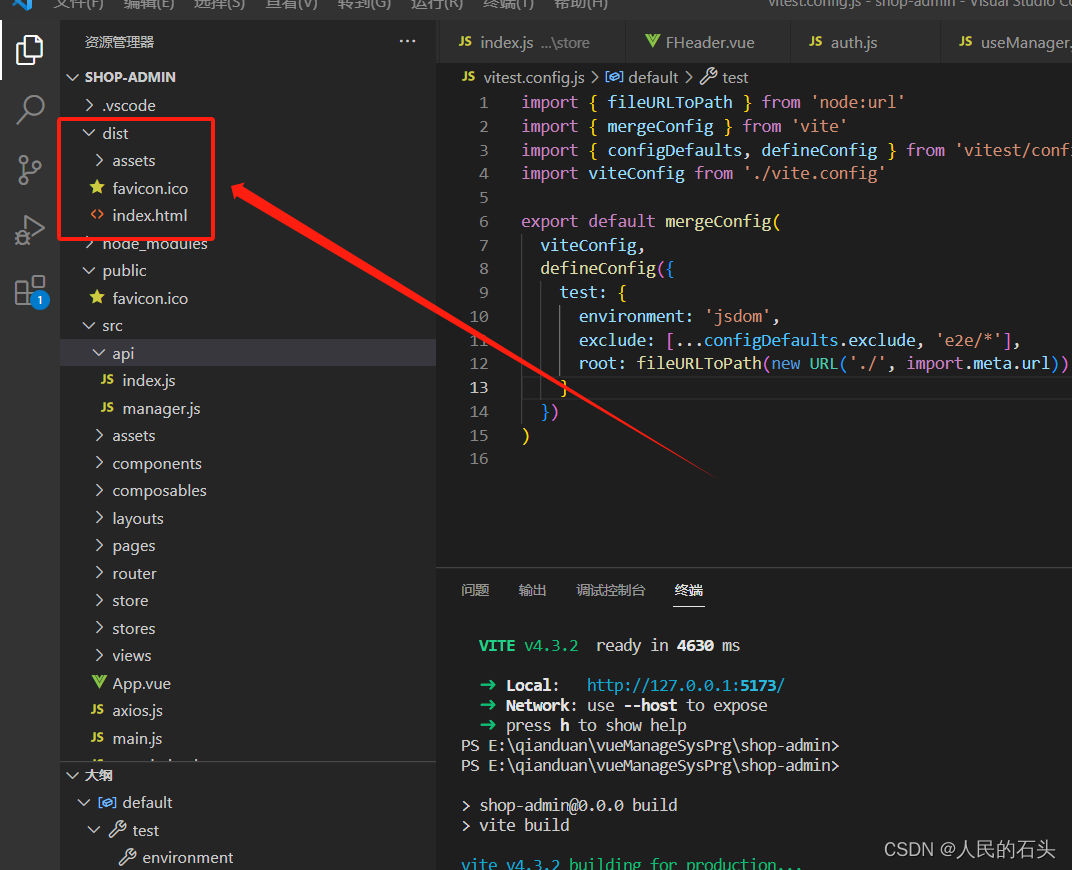
使用vite搭建前端项目
1、在vscode 终端那里执行创建前端工程项目,其中shop-admin为项目名称: npm init vite-app shop-admin 提示如需安装其他依赖执行npm install ....,否则忽略(第三步再讲)。 2、执行npm run dev 命令直接运行创建好的项目,在浏览器打开链接…...

SEATA分布式事务——AT模式烂
简介 AI Agent 不仅仅是一个能聊天的机器人(如普通的 ChatGPT),而是一个能够感知环境、进行推理、自主决策并调用工具来完成特定任务的智能系统,更够完成更为复杂的AI场景需求。 AI Agent 功能 根据查阅的资料,agent的…...

解决Navicat从备份中提取单表数据失败报错怎么办_错误日志排查
Navicat 导入 SQL 备份报错主因是上下文缺失:跨库语句(USE/CREATE DATABASE)、权限语句、全限定表名、编码不匹配或锁超时。应删无关语句、确认库存在及权限、用纯 UTF-8 编码、避免图形界面导大数据,优先用 mysqldump 配合「运行…...

WinBtrfs:让Windows用户也能享受Btrfs文件系统的强大功能
WinBtrfs:让Windows用户也能享受Btrfs文件系统的强大功能 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs WinBtrfs是一款专为Windows系统设计的开源Btrfs文件系统驱动程序&…...

为什么 Rust 开发的 glTF 查看器是 3D 开发者的新宠?
为什么 Rust 开发的 glTF 查看器是 3D 开发者的新宠? 【免费下载链接】gltf-viewer glTF 2.0 Viewer written in Rust 项目地址: https://gitcode.com/gh_mirrors/gl/gltf-viewer 在 3D 图形开发领域,glTF 已经成为事实上的标准格式,而…...

AudioLDM-S实战:快速生成机械键盘声、猫咪呼噜,小白轻松上手
AudioLDM-S实战:快速生成机械键盘声、猫咪呼噜,小白轻松上手 想不想自己动手,创造出那些只在电影、游戏里听到的逼真音效?比如,清脆的机械键盘敲击声、猫咪满足的呼噜声,或是雨林深处的自然白噪音。以前这…...

解决Bootstrap项目中日期时间选择难题:bootstrap-datetimepicker深度集成指南
解决Bootstrap项目中日期时间选择难题:bootstrap-datetimepicker深度集成指南 【免费下载链接】bootstrap-datetimepicker 项目地址: https://gitcode.com/gh_mirrors/boo/bootstrap-datetimepicker 在Bootstrap项目开发中,日期时间选择器是表单…...

突破限制!OBS虚拟摄像头插件实现4路视频同时分发终极方案
突破限制!OBS虚拟摄像头插件实现4路视频同时分发终极方案 【免费下载链接】obs-virtual-cam 项目地址: https://gitcode.com/gh_mirrors/obsv/obs-virtual-cam 你是否曾经遇到过这样的困扰?当你使用OBS进行直播或录制时,想要将画面同…...

如何快速解决Windows热键冲突问题:Hotkey Detective完整使用指南
如何快速解决Windows热键冲突问题:Hotkey Detective完整使用指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

iOS开发中.p12证书密码丢失的应急处理与安全导出指南
1. 当.p12证书密码丢失时,开发者该怎么办? 遇到.p12证书密码丢失的情况,很多iOS开发者会感到手足无措。这种情况在实际开发中并不少见,特别是当项目交接或长时间未使用证书时。我曾经接手过一个老项目,就遇到过前任开发…...

FireRedASR-AED-L实现Python语音识别:从音频到文本的完整教程
FireRedASR-AED-L实现Python语音识别:从音频到文本的完整教程 1. 引言 语音识别技术正在改变我们与设备交互的方式,从智能助手到实时字幕,这项技术已经深入到日常生活的方方面面。今天我要介绍的FireRedASR-AED-L,是一个专门为中…...