机器学习---CNN(创建和训练一个卷积神经网络并评估其性能)下
import numpy as np
import matplotlib.pyplot as plt
from cnn_operations import cnn_operations as cnn_oprconvolutional_neural_network模块:
1. 卷积神经网络类
def __init__(self):# 网络的层数self.n_layers = 0# list,网络中的各层self.layers = []# array,网络的输出self.output = None# 网络的代价self.loss = None# 权值的学习率self.learning_rate_weight = 0.1# 偏置的学习率self.learning_rate_bias = 0.1初始化网络结构相关属性,如层数、层列表;初始化输出、损失和学习率属性
层列表self.layers用于后续添加各层对象;输出self.output和损失self.loss记录训练过程中的值
def config(self, args):self.n_layers = len(args)prior_layer = Nonefor i in range(self.n_layers):# 配置网络的各层new_layer = cnn_layer(args[i][0])if i > 0:prior_layer = self.layers[-1]# 当前层设为上一层的next_layerself.layers[-1].next_layer = new_layernew_layer.config(args[i][1], self.learning_rate_weight, self.learning_rate_bias, prior_layer)self.layers.append(new_layer)return None配置网络:
args: 元组,其中`args[i][0]`代表第i层的类型,类型包括 "input"(输入层)、"convoluting"(卷积
层)、"pooling"(池化层)、"full_connecting"(全连接层)和 "output"(输出层)。args[i][1]是一
个元组,包含第i层的配置参数。
函数的主要流程:
①获取args元组的长度,即网络的层数。
②进入循环,对每一层进行配置。先创建一个新的层new_layer,然后判断如果不是第一层,就把
前一层prior_layer设为新创建的层的前一层,并把前一层的`next_layer`设为新创建的层。
③配置新创建的层,参数包括第i层的配置参数,学习率,以及前一层的信息。
④将新创建的层添加到网络的层级列表中。
def _feed_forward(self, x):# 输入层前向传播self.layers[0].feed_forward(x)# 其它各层前向传播for i in range(1, self.n_layers):self.layers[i].feed_forward(x)# self.layers[-1].n_nodes * size_batch array,网络的输出self.output = np.ndarray.flatten( \np.array(self.layers[-1].output)).reshape( \self.layers[-1].n_nodes, -1)return None前向传播:
x: 是一个3维数组,表示一个批次(batch)的输入图像。每个通道的尺寸为x.shape[0] *
x.shape[1],而x.shape[2]代表当前批次中图像的个数乘以每幅图像的通道数。
函数的主要流程:
①首先进行输入层的前向传播计算,输入参数为输入图像x。
②然后对从第二层开始的其他所有层进行前向传播计算,输入参数也为输入图像x。
③最后,将网络最后一层的输出进行降维处理,并保存到self.output中。这里,np.ndarray.flatten()
函数用于将一个多维数组转化为一维数组,np.reshape()函数用于改变数组的形状。
def _back_propagate(self, y):# 输出层反向传播self.layers[-1].back_propagate(y)# 其它各层反向传播for i in range(self.n_layers - 2, 0, -1):self.layers[i].back_propagate()return None反向传播:
y: 数组,表示输入样本对应的类别标签。
函数的主要流程:
①首先进行输出层的反向传播计算,输入参数为类别标签`y`。
②然后对从倒数第二层开始的其他所有层进行反向传播计算,无需传入参数。
反向传播是神经网络训练的核心部分,它的目标是通过计算损失函数关于网络参数的梯度,
然后根据这个梯度来更新网络的参数。具体来说,反向传播过程首先计算输出层的误差,然后依次
向前一层一层传递,直到输入层,每经过一层都会根据该层的误差来更新该层的参数。
def fit(self, X, Y, size_batch=1, n_epochs=1):self.size_batch = size_batch# 训练样本个数 * 每幅图片的通道数len_X = X.shape[-1]len_Y = Y.shape[0]# 每个epoch中batch的个数n_batches = int(np.ceil(len_X / self.layers[0].n_nodes / size_batch))loss = np.empty(n_epochs * n_batches)for i_epoch in range(n_epochs):print("Epoch: ", end="")print(i_epoch)for i_batch in range(n_batches):print("\tBatch: ", end="")print(i_batch, end="\t")y_offset = i_batch * size_batchx_offset = y_offset * self.layers[0].n_nodes# 将类别标签转换为向量y = np.zeros([self.layers[-1].n_nodes, size_batch])for i in range(size_batch):if i > len_Y - y_offset - 1:y = y[:, :, : i]breaky[Y[y_offset + i], i] = 1self._feed_forward(X[:, :, x_offset: x_offset + size_batch * \self.layers[0].n_nodes])loss[i_epoch * n_batches + i_batch] = \cnn_opr.calc_loss(y.T, self.output.T)print("loss = ", end="")print(loss[i_epoch * n_batches + i_batch])self._back_propagate(y)self.loss = lossplt.figure()plt.plot(loss, "r-")plt.xlabel("Batches")plt.ylabel("Loss")plt.grid()plt.show()return None训练卷积神经网络:
X: 3维数组,表示训练集。其中,X[:, :, i: i + self.layers[0].n_nodes]表示一个训练样本(图
片),self.layers[0].n_nodes即为每幅图片的通道数。
Y: 数组,表示训练集对应的类别标签。
size_batch: 一个批次(batch)中训练样本的个数。
n_epochs: 训练的迭代次数。
函数的主要流程:
①计算每个周期(epoch)中批次的个数,并创建一个空的损失数组用于存储每个批次的损失值。
②开始训练,对每个周期和每个批次进行循环。
③对于每个批次,首先获取该批次的输入图像和对应的类别标签,然后将类别标签转换为向量形式
(one-hot encoding)。
④然后执行前向传播,计算网络的输出,并计算损失值。损失值是真实标签和网络输出之间的差
异,通常用于评估网络的性能。
⑤接着执行反向传播,更新网络的参数。
⑥最后,将每个批次的损失值存储起来,并在训练结束后绘制损失值的变化图。
使用随机梯度下降方法训练卷积神经网络,通过循环迭代和反向传播,逐渐优化网络的参
数,使得网络的输出能够尽可能接近真实的标签,从而提高网络的性能。
def test(self, X, Y):n_correct = 0for i in range(0, X.shape[-1], self.layers[0].n_nodes):print("Test case: ", end="")print(i)y_predict = self.predict(X[:, :, i: i + self.layers[0].n_nodes])if y_predict == Y[i]:n_correct += 1correct_rate = n_correct / X.shape[-1]return correct_rate用于测试卷积神经网络的性能:
X: 3维数组,表示测试集。其中,X[:, :, i: i + self.layers[0].n_nodes]表示一个测试样本(图
片),self.layers[0].n_nodes即为每幅图片的通道数。
Y: 数组,表示测试集对应的类别标签。
函数的主要流程:
①初始化正确分类的样本数为0。
②对每个测试样本进行循环,对每个样本进行预测,并与真实标签进行比较。如果预测正确,则正
确分类的样本数加1。
③计算并返回测试集的分类正确率,即正确分类的样本数除以总样本数。
def predict(self, x):self._feed_forward(x.reshape(x.shape[0], x.shape[1], -1))# 根据网络输出层的类型,判定输入图像的类别if self.layers[-1].type_output is "softmax":y_predict = np.argmax(self.output[:, 0])elif self.layers[-1].type_output is "rbf":# TODO: passreturn y_predict用于预测输入样本的类别:
x: 2维或3维数组,表示输入样本(图像)。
函数的主要流程:
①对输入样本进行前向传播计算,得到网络的输出。
②根据网络输出层的类型,判断输入图像的类别。如果输出层的类型是"softmax",则选择输出向
量中值最大的元素对应的索引作为类别标签。如果输出层的类型是"rbf",目前该部分还未实现,需
要补充相应的代码。
③函数返回预测出的输入样本的类别。
2. 卷积神经网络中的一层(类)cnn_layer
def __init__(self, type_layer):# 当前层的类型self.type = type_layer# 当前层中神经元的个数self.n_nodes = 0# list,当前层中各神经元self.nodes = []# 当前层的上一层self.prior_layer = None# 当前层的下一层self.next_layer = None# list,当前层的输出self.output = []# 权值的学习率self.learning_rate_weight = 0.0# 偏置的学习率self.learning_rate_bias = 0.0if self.type is "input":# array,输入图像(每个通道)的尺寸self.size_input = Noneelif self.type is "convoluting":# 2-d array,当前层与上一层各神经元的连接矩阵self.connecting_matrix = None# array,卷积核尺寸self.size_conv_kernel = None# 卷积核步长self.stride_conv_kernel = 1# 边缘补零的宽度self.padding_conv = 0# 激活函数类型,{"relu", "sigmoid", "tanh", None}self.type_activation = Noneelif self.type is "pooling":# 池化核类型,{"max", "average"}self.type_pooling = "max"# array,池化核尺寸self.size_pool_kernel = np.array([2, 2])# 池化核步长self.stride_pool_kernel = 2# 边缘补零的宽度self.padding_pool = 0# 激活函数类型,{"relu", "sigmoid", "tanh", None}self.type_activation = Noneelif self.type is "full_connecting":# 激活函数类型,{"relu", "sigmoid", "tanh", None}self.type_activation = Noneelif self.type is "output":# 输出层类型,{"softmax", "rbf"}self.type_output = "softmax"type_layer: 当前层的类型,可以是"input"(输入层)、"convoluting"(卷积
层)、"pooling"(池化层)、"full_connecting"(全连接层)或"output"(输出层)。
首先,根据层的类型初始化共享的属性,如神经元个数、神经元列表、前一层、后一层、输
出、权值学习率和偏置学习率等。
然后,根据层的类型初始化特定的属性。例如,如果层的类型是"input",则初始化输入图像的
尺寸;如果层的类型是"convoluting",则初始化连接矩阵、卷积核尺寸、卷积核步长、边缘补零的
宽度和激活函数类型等。
def config(self, args, learning_rate_weight, learning_rate_bias, prior_layer=None):self.prior_layer = prior_layerself.learning_rate_weight = learning_rate_weightself.learning_rate_bias = learning_rate_biasif self.type is "input":size_input, = args# 输入图像为单通道if size_input.shape[0] == 2:self.n_nodes = 1self.size_input = size_input# 输入图像为多通道elif size_input.shape[0] == 3:# 每个神经元一个通道self.n_nodes = size_input[-1]# 输入图像每个通道的尺寸self.size_input = size_input[ : 2]self._config_input(self.size_input)elif self.type is "convoluting":connecting_matrix, size_conv_kernel, \stride_conv_kernel, padding_conv, type_activation = argsself.connecting_matrix = connecting_matrixself.n_nodes = connecting_matrix.shape[1]self.size_conv_kernel = size_conv_kernelself.stride_conv_kernel = stride_conv_kernelself.padding_conv = padding_convself.type_activation = type_activationself._config_convoluting(connecting_matrix, size_conv_kernel, stride_conv_kernel, padding_conv, type_activation)elif self.type is "pooling":type_pooling, size_pool_kernel, \stride_pool_kernel, padding_pool, type_activation = args# 池化层神经元个数与上一层卷积层(或激活层)神经元个数相同self.n_nodes = self.prior_layer.n_nodesself.type_pooling = type_poolingself.size_pool_kernel = size_pool_kernelself.stride_pool_kernel = stride_pool_kernelself.ppadding_pool = padding_poolself.type_activation = type_activationself._config_pooling(type_pooling, size_pool_kernel, stride_pool_kernel, padding_pool, type_activation)elif self.type is "full_connecting":n_nodes, type_activation = argsself.n_nodes = n_nodesself.type_activation = type_activationself._config_full_connecting(n_nodes, type_activation)elif self.type is "output":n_nodes, type_output = argsself.n_nodes = n_nodesself.type_output = type_outputself._config_output(n_nodes, type_output)# 初始化权值self._initialize()return None配置神经网络的各层:
args: 元组,包含当前层的配置参数。
learning_rate_weight: 权值的学习率。
learning_rate_bias: 偏置的学习率。
prior_layer: 当前层的上一层,默认值为None。
函数的主要流程:
①设置当前层的上一层以及权值和偏置的学习率。
②根据当前层的类型配置对应的参数。例如,如果当前层为"input"(输入层),则设置输入图像的
尺寸和通道数。如果当前层为"convoluting"(卷积层),则设置连接矩阵、卷积核尺寸和步长、边
缘补零的宽度以及激活函数类型等。
③调用_initialize()方法初始化权值。
def _config_input(self, size_input):for i in range(self.n_nodes):new_node = cnn_node(self.type)args = (size_input,)new_node.config(args)self.nodes.append(new_node)return None配置神经网络的输入层:
size_input: 数组,输入图像(每个通道)的尺寸。
函数的主要流程:
①通过遍历输入通道的数量,对每个通道创建一个新的神经元节点。
②使用输入尺寸参数调用每个节点的`config`方法进行配置。
③将配置好的节点添加到当前层的节点列表中。
def _config_convoluting(self, connecting_matrix, size_conv_kernel, stride_conv_kernel, padding_conv, type_activation):for i in range(self.n_nodes):new_node = cnn_node(self.type)# 上一层中与当前神经元连接的神经元nodes_prior_layer = []for j in range(connecting_matrix.shape[0]):if connecting_matrix[j, i] == 1:nodes_prior_layer.append(self.prior_layer.nodes[j])# 当前神经元添加至上一层中与之连接的神经元的nodes_next_layerself.prior_layer.nodes[j].nodes_next_layer.append(new_node)args = (nodes_prior_layer, size_conv_kernel, stride_conv_kernel, padding_conv, type_activation)new_node.config(args)self.nodes.append(new_node)return None用于配置神经网络的卷积层:
connecting_matrix: M * N数组,M为上一层神经元个数,N为当前层神经元个数,
connecting_matrix[m, n]为1表示上一层第m个神经元与当前层第n个神经元连接,为0表示不连接。
size_conv_kernel: 数组,卷积核尺寸。
stride_conv_kernel: 卷积核步长。
padding_conv: 边缘补零的宽度。
type_activation: 激活函数类型,可以是"relu"(修正线性单元)、"sigmoid"(S型曲
线)、"tanh"(双曲正切函数)或None。
函数的主要流程:
①遍历当前层的所有神经元。
②对于每个神经元,找出上一层与之连接的神经元,并将当前神经元添加到这些神经元的
nodes_next_layer列表中。
③调用每个神经元的`config`方法,使用给定的参数进行配置。
④将配置好的神经元添加到当前层的nodes列表中。
def _config_pooling(self, type_pooling, size_pool_kernel, stride_pool_kernel, padding_pool, type_activation):for i in range(self.n_nodes):new_node = cnn_node(self.type)# 上一层中与当前神经元连接的神经元nodes_prior_layer = self.prior_layer.nodes[i]# 当前神经元添加至上一层中与之连接的神经元的nodes_next_layerself.prior_layer.nodes[i].nodes_next_layer.append(new_node)args = (nodes_prior_layer, type_pooling, size_pool_kernel, stride_pool_kernel, padding_pool, type_activation)new_node.config(args)self.nodes.append(new_node)return None配置神经网络的池化层:
type_pooling: 池化核类型,可以是"max"(最大池化)或"average"(平均池化)。
size_pool_kernel: 数组,池化核尺寸。
stride_pool_kernel: 池化核步长。
padding_pool: 边缘补零的宽度。
type_activation: 激活函数类型,可以是"relu"(修正线性单元)、"sigmoid"(S型曲
线)、"tanh"(双曲正切函数)或None。
函数的主要流程:
①遍历当前层的所有神经元。
②对于每个神经元,找出上一层与之相对应的神经元,并将当前神经元添加到这个神经元的
nodes_next_layer列表中。
③调用每个神经元的config方法,使用给定的参数进行配置。
④将配置好的神经元添加到当前层的nodes列表中。
def _config_full_connecting(self, n_nodes, type_activation):# 上一层中所有神经元与当前层中每个经元连接nodes_prior_layer = self.prior_layer.nodesargs = (nodes_prior_layer, type_activation)# 上一层中神经元的个数n_nodes_prior_layer = len(nodes_prior_layer)for i in range(n_nodes):new_node = cnn_node(self.type)# 当前神经元添加至上一层中每个神经元的nodes_next_layerfor j in range(n_nodes_prior_layer):self.prior_layer.nodes[j].nodes_next_layer.append(new_node)new_node.config(args)self.nodes.append(new_node)return None配置神经网络的全连接层:
n_nodes: 全连接层中神经元的个数。
type_activation: 激活函数类型,可以是"relu"(修正线性单元)、"sigmoid"(S型曲
线)、"tanh"(双曲正切函数)或`None`。
函数的主要流程:
①获取上一层的所有神经元。
②对于全连接层中的每个神经元,将其添加到上一层每个神经元的`nodes_next_layer`列表中。
③调用每个神经元的`config`方法,使用给定的参数进行配置。
def _config_output(self, n_nodes, type_output):# 上一层中所有神经元与当前层中每个经元连接nodes_prior_layer = self.prior_layer.nodesargs = (nodes_prior_layer, type_output)# 上一层中神经元的个数n_nodes_prior_layer = len(nodes_prior_layer)for i in range(n_nodes):new_node = cnn_node(self.type)# 当前神经元添加至上一层中每个神经元的nodes_next_layerfor j in range(n_nodes_prior_layer):self.prior_layer.nodes[j].nodes_next_layer.append(new_node)new_node.config(args)self.nodes.append(new_node)return None配置神经网络的输出层:
n_nodes: 输出层中神经元的个数,也就是类别的数目。
type_output: 输出层的类型,可以是"softmax"或"rbf"(径向基函数)。
函数的主要流程:
①获取上一层的所有神经元。
②对于输出层中的每个神经元,将其添加到上一层每个神经元的nodes_next_layer列表中。
③调用每个神经元的config方法,使用给定的参数进行配置。
def _initialize(self):if self.type is "convoluting":self._initialize_convoluting()elif self.type is "full_connecting":self._initialize_full_connecting()elif self.type is "output":self._initialize_output()return NoneXavier初始化方法:
检查当前层的类型,然后对该层进行相应的初始化操作。如果类型是"convoluting",则调用
_initialize_convoluting方法进行卷积层的初始化。如果类型是"full_connecting",则调用
_initialize_full_connecting方法进行全连接层的初始化。如果类型是"output",则调用
_initialize_output方法进行输出层的初始化。
def _initialize_convoluting(self):fan_out = self.n_nodes * np.prod(self.size_conv_kernel)if self.prior_layer.type is "input":fan_in = self.prior_layer.n_nodes * np.prod(self.size_conv_kernel)u = np.sqrt(6 / (fan_in + fan_out))for i in range(self.n_nodes):for j in range(self.nodes[i].n_conv_kernels):self.nodes[i].conv_kernels[j] = u * 2 * \(np.random.rand(self.size_conv_kernel[0], self.size_conv_kernel[1]) - 0.5)elif self.prior_layer.type is "pooling":for i in range(self.n_nodes):fan_in = np.sum(self.connecting_matrix[:, i]) * \np.prod(self.size_conv_kernel)u = np.sqrt(6 / (fan_in + fan_out))for j in range(self.nodes[i].n_conv_kernels):self.nodes[i].conv_kernels[j] = u * 2 * \(np.random.rand(self.size_conv_kernel[0], self.size_conv_kernel[1]) - 0.5)return None初始化神经网络的卷积层:
计算出fan_out(输出值的个数)。
根据前一层的类型,分别计算出fan_in(输入值的个数)并初始化卷积核权重。如果前一层
是"input",则直接用前一层的神经元个数和卷积核大小计算出fan_in。如果前一层是"pooling",则
需要用连接矩阵和卷积核大小来计算fan_in。
根据Xavier初始化方法,用fan_in和fan_out来计算一个因子u,然后用这个因子u来初始化当
前层神经元的每个卷积核。
函数中用到的变量如下:
self.n_nodes:当前层神经元的个数。
self.size_conv_kernel:卷积核的大小。
self.prior_layer:前一层。
self.nodes:当前层的所有神经元。
self.connecting_matrix:当前层与前一层的连接矩阵。
def _initialize_full_connecting(self):fan_in = self.prior_layer.n_nodesfan_out = self.n_nodesu = np.sqrt(6 / (fan_in + fan_out))for i in range(self.n_nodes):self.nodes[i].weights = u * 2 * (np.random.rand(fan_in) - 0.5)return None初始化神经网络的全连接层:
计算fan_in(输入的数量),这个值等于前一层的神经元数量。计算fan_out(输出的数量),这个
值等于当前层的神经元数量。根据Xavier初始化方法,计算一个因子u,这个因子用来初始化当前
层神经元的权重。对于全连接层的每个神经元,都用这个因子u来初始化它的权重。
def _initialize_output(self):self._initialize_full_connecting()return None用于初始化神经网络的输出层。
def feed_forward(self, inputs=None):if self.type is "input":self._feed_forward_input(inputs)elif self.type is "output":self._feed_forward_output()else:self.output = []for i in range(self.n_nodes):# 当前层中每个神经元前向传播self.nodes[i].feed_forward()self.output.append(self.nodes[i].output)return None首先检查当前层的类型。如果当前层是输入层,调用_feed_forward_input方法进行前向传播。如
果当前层是输出层,调用_feed_forward_output方法进行前向传播。如果当前层既不是输入层也不
是输出层,那么对当前层的每个神经元进行前向传播,并将每个神经元的输出添加到self.output
列表中。
def _feed_forward_input(self, inputs):self.output = []# 输入图像为单通道,此时inputs[:, :, i]为每幅图像if self.n_nodes == 1:self.nodes[0].feed_forward(inputs)self.output.append(self.nodes[0].output)# 输入图像为多通道,此时inputs[:, :, i: i + 3]为每幅图像elif self.n_nodes > 1:for i in range(self.n_nodes):self.nodes[i].feed_forward(inputs[:, :, i: : self.n_nodes])self.output.append(self.nodes[i].output)return None初始化输出列表self.output,如果输入层神经元数量为1(即输入图像为单通道),那么直接对该
神经元进行前向传播,并将其输出添加到self.output列表中。如果输入层神经元数目大于1(即输
入图像为多通道),那么对每个神经元进行前向传播,并将每个神经元的输出添加到self.output
列表中。
def _feed_forward_output(self):if self.type_output is "softmax":# 输出层第一个神经元前向传播self.nodes[0].feed_forward()# size_batch * self.n_nodes arraycombinations = np.empty([self.nodes[0].combination.shape[-1], self.n_nodes])combinations[:, 0] = self.nodes[0].combination.reshape(-1)# 输出层其它神经元前向传播for i in range(1, self.n_nodes):self.nodes[i].feed_forward()combinations[:, i] = self.nodes[i].combination.reshape(-1)# $e^{w_j^T x}, \forall j$exp_combinations = np.exp(combinations)# $\sum_{j = 1}^n e^{w_j^T x}$sum_exp = np.sum(exp_combinations, axis=1)self.output = []for i in range(self.n_nodes):# 输出层神经元的output为size_batch array# $\frac{e^{w_i^T x}}{\sum_{j = 1}^n e^{w_j^T x}}$self.nodes[i].output = exp_combinations[:, i] / sum_expself.output.append(self.nodes[i].output)elif self.type_output is "rbf":# TODO: passreturn None检查输出层的类型,如果是"softmax"类型,执行以下步骤:
对输出层的第一个神经元进行前向传播。
初始化一个空数组combinations,用于存储输出层各神经元的组合值。
对输出层的其它神经元进行前向传播,并将每个神经元的组合值存储到combinations数组中。
计算exp_combinations,即对combinations中的每个元素求指数。
计算sum_exp,即exp_combinations中的元素按列求和。
最后,计算每个神经元的输出,公式为  ,并将每个神经元的输出添加到
,并将每个神经元的输出添加到
self.output列表中。
def back_propagate(self, y=None):if self.type is "convoluting":self._back_propagate_convoluting()elif self.type is "pooling":self._back_propagate_pooling()elif self.type is "full_connecting":self._back_propagate_full_connecting()elif self.type is "output":self._back_propagate_output(y)return None首先检查当前层的类型。如果当前层是卷积层,调用_back_propagate_convoluting方法进行反向
传播。如果当前层是池化层,调用_back_propagate_pooling方法进行反向传播。如果当前层是全
连接层,调用_back_propagate_full_connecting方法进行反向传播。如果当前层是输出层,调用
_back_propagate_output方法进行反向传播。
def _back_propagate_convoluting(self):if self.next_layer.type is "pooling":self._bp_pooling_to_convoluting()elif self.next_layer.type is "full_connecting":self._bp_full_connecting_to_convoluting()elif self.next_layer.type is "output":self._bp_output_to_convoluting()return None首先检查当前层的下一层的类型。如果下一层是池化层,调用_bp_pooling_to_convoluting方法进
行反向传播。如果下一层是全连接层,调用_bp_full_connecting_to_convoluting方法进行反向传
播。如果下一层是输出层,调用_bp_output_to_convoluting方法进行反向传播。
def _bp_pooling_to_convoluting(self):# TODO: if self.type_activation is None:passelif self.type_activation is "relu":passelif self.type_activation is "sigmoid":for i in range(self.n_nodes):# 下一层(池化层)中与当前(卷积层)神经元连接的神经元只有一个node_next_layer = self.nodes[i].nodes_next_layer[0]# 池化层中一个神经元只有一个权值# TODO: 下一层池化类型为"max"时delta_padded = node_next_layer.weights[0] * \cnn_opr.upsample_pool(node_next_layer.delta[:, :, 0], node_next_layer.type_pooling, node_next_layer.size_pool_kernel, node_next_layer.stride_pool_kernel)size_delta_padded = delta_padded.shapedelta = np.zeros(self.nodes[i].output.shape)delta[ : size_delta_padded[0], : size_delta_padded[1], 0] = \delta_paddedfor j in range(1, delta.shape[-1]):delta[ : size_delta_padded[0], : size_delta_padded[1], j] = \node_next_layer.weights[0] * \cnn_opr.upsample_pool(node_next_layer.delta[:, :, j], node_next_layer.type_pooling, node_next_layer.size_pool_kernel, node_next_layer.stride_pool_kernel)self.nodes[i].delta = delta * \(self.nodes[i].output - self.nodes[i].output**2)# 更新当前神经元的权值,即当前神经元的各卷积核for j in range(self.nodes[i].n_conv_kernels):# 卷积层的上一层可能为池化层或输入层delta_k = 0.0for iter_in_batch in range(delta.shape[-1]):delta_k += cnn_opr.inv_conv_2d( \self.nodes[i].nodes_prior_layer[j].output[ \:, :, iter_in_batch], self.size_conv_kernel, self.stride_conv_kernel, self.padding_conv, self.nodes[i].delta[:, :, iter_in_batch])delta_k /= delta.shape[-1]self.nodes[i].conv_kernels[j] -= \self.learning_rate_weight * delta_k# 更新当前神经元的偏置self.nodes[i].bias -= self.learning_rate_bias * \np.sum(self.nodes[i].delta) / delta.shape[-1]elif self.type_activation is "tanh":passreturn None首先检查当前层的激活函数类型。如果激活函数类型是"sigmoid",执行以下步骤:
对当前层的每个神经元进行处理。由于池化层中与当前卷积层神经元连接的神经元只有一个,所以
直接取出与之相连的池化层神经元node_next_layer。
对node_next_layer的误差进行上采样,将其扩大到与当前神经元输出相同的尺寸,得到
delta_padded。将delta_padded中的误差传播到当前神经元的误差delta中。
计算当前神经元的误差,公式为![]() 更新当前神经元
更新当前神经元
的权值,即卷积核的值。
对于每个卷积核,计算其对应的误差delta_k,然后根据学习率和delta_k更新卷积核的值。
更新当前神经元的偏置,公式为  ,其中n为
,其中n为
delta的最后一个维度的大小。
def _bp_full_connecting_to_convoluting(self):# TODO: if self.type_activation is None:passelif self.type_activation is "relu":passelif self.type_activation is "sigmoid":for i in range(self.n_nodes):delta = 0.0for j in range(len(self.nodes[i].nodes_next_layer)):# 全连接层神经元的delta为size_batch arraydelta += self.nodes[i].nodes_next_layer[j].weights[i] * \self.nodes[i].nodes_next_layer[j].deltadelta *= (self.nodes[i].output[0, 0, :] - self.nodes[i].output[0, 0, :]**2)delta = delta.reshape(1, 1, -1)self.nodes[i].delta = delta# 更新当前神经元的权值,即当前神经元的各卷积核for j in range(self.nodes[i].n_conv_kernels):# 卷积层的上一层可能为池化层或输入层delta_k = 0.0for iter_in_batch in range(delta.shape[-1]):delta_k += cnn_opr.inv_conv_2d( \self.nodes[i].nodes_prior_layer[j].output[ \:, :, iter_in_batch], self.size_conv_kernel, self.stride_conv_kernel, self.padding_conv, self.nodes[i].delta[:, :, iter_in_batch])delta_k /= delta.shape[-1]self.nodes[i].conv_kernels[j] -= \self.learning_rate_weight * delta_k# 更新当前神经元的偏置# self.nodes[i].delta实际上为1 * 1 * size_batch arrayself.nodes[i].bias -= self.learning_rate_bias * \np.sum(self.nodes[i].delta) / delta.shape[-1]elif self.type_activation is "tanh":passreturn None卷积层到全连接层的反向传播实现:
delta的计算:对每个卷积层神经元i,需要遍历全连接层所有的后继神经元j,将j的delta按权重回传,并结
合本层激活函数的导数计算delta。
卷积核的更新:对每个卷积核j,遍历每个样本,进行反卷积操作,并将所有样本的反卷积结果求平均作
为该卷积核的梯度,以此更新卷积核。
偏置的更新:将每个样本的delta求平均就可以得到偏置的梯度,以此更新偏置。
激活函数的处理:relu和sigmoid激活函数的导数计算不同,需要针对性实现。
reshape和维度对应:计算delta和更新参数时需要注意reshape,保证维度一致。
def _bp_output_to_convoluting(self):self._bp_full_connecting_to_convoluting()return Nonedef _back_propagate_pooling(self):if self.next_layer.type is "convoluting":self._bp_convoluting_to_pooling()elif self.next_layer.type is "full_connecting":self._bp_full_connecting_to_pooling()elif self.next_layer.type is "output":self._bp_output_to_pooling()return None卷积层和池化层的反向传播实现:
_bp_output_to_convoluting()函数表示当前层为卷积层,下一层为输出层时的反向传播情况。
_back_propagate_pooling()函数实现了池化层的反向传播。它会根据池化层的下一层类型来调用
不同的反向传播函数:
如果下一层是卷积层,调用 _bp_convoluting_to_pooling();如果下一层是全连接层,调用
_bp_full_connecting_to_pooling(),如果下一层是输出层,调用_bp_output_to_pooling(),实际上也
会调用到_bp_full_connecting_to_pooling()。
def _bp_convoluting_to_pooling(self):# TODO: if self.type_activation is None:passelif self.type_activation is "relu":passelif self.type_activation is "sigmoid":index_kernel = -1for j in range(self.next_layer.connecting_matrix.shape[0]):if self.next_layer.connecting_matrix[j, 0] == 1:index_kernel += 1if index_kernel == 0:delta_padded = cnn_opr.upsample_conv_2d( \self.next_layer.nodes[0].delta[:, :, 0], self.next_layer.nodes[0].conv_kernels[index_kernel], self.next_layer.nodes[0].size_conv_kernel, self.next_layer.nodes[0].stride_conv_kernel)for n in range(self.n_nodes):self.nodes[n].delta = np.zeros([ \delta_padded.shape[0], delta_padded.shape[1], self.next_layer.nodes[0].delta.shape[-1]])self.nodes[j].delta[:, :, 0] = delta_paddedfor iter_in_batch in range(1, self.next_layer.nodes[0].delta.shape[-1]):self.nodes[j].delta[:, :, iter_in_batch] += \cnn_opr.upsample_conv_2d( \self.next_layer.nodes[0].delta[ \:, :, iter_in_batch], self.next_layer.nodes[0].conv_kernels[ \index_kernel], self.next_layer.nodes[0].size_conv_kernel, self.next_layer.nodes[0].stride_conv_kernel)elif index_kernel > 0:for iter_in_batch in range( \self.next_layer.nodes[0].delta.shape[-1]):self.nodes[j].delta[:, :, iter_in_batch] += \cnn_opr.upsample_conv_2d( \self.next_layer.nodes[0].delta[ \:, :, iter_in_batch], self.next_layer.nodes[0].conv_kernels[ \index_kernel], self.next_layer.nodes[0].size_conv_kernel, self.next_layer.nodes[0].stride_conv_kernel)for i in range(1, self.next_layer.connecting_matrix.shape[1]):# 卷积层中每个神经元可能与上一层中多个神经元连接,# 即卷积层中的神经元可能有多个卷积核# 下一层(卷积层)中与当前神经元连接的神经元的卷积核的索引index_kernel = -1for j in range(self.next_layer.connecting_matrix.shape[0]):# 下一层的第i个神经元与当前层的第j个神经元连接,# 将下一层第i个神经元的delta传递至当前层第j个神经元if self.next_layer.connecting_matrix[j, i] == 1:index_kernel += 1for iter_in_batch in range( \self.next_layer.nodes[i].delta.shape[-1]):self.nodes[j].delta[:, :, iter_in_batch] += \cnn_opr.upsample_conv_2d( \self.next_layer.nodes[i].delta[ \:, :, iter_in_batch], self.next_layer.nodes[i].conv_kernels[ \index_kernel], self.next_layer.nodes[i].size_conv_kernel, self.next_layer.nodes[i].stride_conv_kernel)for i in range(self.n_nodes):# 令delta与output尺寸相同delta = np.zeros(self.nodes[i].output.shape)size_delta_padded = self.nodes[i].delta.shapedelta[ : size_delta_padded[0], : size_delta_padded[1], :] += \self.nodes[i].deltaself.nodes[i].delta = delta * \(self.nodes[i].output - self.nodes[i].output**2)# 更新当前神经元的权值# $\frac{\partial loss}{\partial w} = \sum{\delta \dot z}$# 池化层中每个神经元只有一个权值self.nodes[i].weights[0] -= self.learning_rate_weight * \np.sum(self.nodes[i].delta * self.nodes[i].combination) / \self.nodes[i].delta.shape[-1]# 更新当前神经元的偏置# $\frac{\partial loss}{\partial b} = \sum{\delta}$self.nodes[i].bias -= self.learning_rate_bias * \np.sum(self.nodes[i].delta) / self.nodes[i].delta.shape[-1]elif self.type_activation is "tanh":passreturn None当前层为池化层,下一层为卷积层时的反向传播逻辑:
①根据下一层(卷积层)的delta,通过上采样进行反卷积,得到本层的delta。
②将得到的delta调整形状匹配本层输出,然后乘以激活函数的导数。
③使用delta和combination更新当前层神经元的权重和偏置。
④对不同的激活函数类型(ReLU、sigmoid、tanh),计算delta时有略微不同。
具体来说:通过遍历下一层的连接矩阵,确定下一层每个神经元对应的卷积核,对下一层每个
神经元的delta进行上采样反卷积,得到与当前层形状匹配的delta,将delta乘以激活函数的导数作为
当前层的delta,使用delta更新当前层中每个神经元的权重和偏置。
def _bp_full_connecting_to_pooling(self):# TODO: if self.type_activation is None:passelif self.type_activation is "relu":passelif self.type_activation is "sigmoid":for i in range(self.n_nodes):delta = 0.0for j in range(len(self.nodes[i].nodes_next_layer)):delta += self.nodes[i].nodes_next_layer[j].weights[i] * \self.nodes[i].nodes_next_layer[j].deltadelta *= (self.nodes[i].output[0, 0, :] - \self.nodes[i].output[0, 0, :]**2)self.nodes[i].delta = delta.reshape(1, 1, -1)# 更新当前神经元的权值self.nodes[i].weights[0] -= self.learning_rate_weight * \np.sum(self.nodes[i].delta * self.nodes[i].combination) / \self.nodes[i].shape[-1]# 更新当前神经元的偏置self.nodes[i].bias -= self.learning_rate_bias * \np.sum(self.nodes[i].delta) / self.nodes[i].delta.shape[-1]elif self.type_activation is "tanh":passreturn None当前层为池化层,下一层为全连接层时的反向传播实现:
①初始化当前层每个节点的delta为0
②遍历当前层每个节点:对下一层每个连接到当前节点的全连接层节点,累加其权重与delta的乘积到
当前节点的delta;将delta乘以当前节点激活函数的导数作为当前节点的最终delta;将delta调整形
状为1×1×batch_size。
③使用计算得到的delta更新当前节点的权重和偏置
④对不同的激活函数,计算delta时略有不同
主要思路是:利用全连接层传入的delta,计算当前池化层节点的delta,更新当前池化层节点的参
数,依据不同的激活函数计算delta的细节不同。
def _bp_output_to_pooling(self):self._bp_full_connecting_to_pooling()return Nonedef _back_propagate_full_connecting(self):# TODO: if self.type_activation is None:passelif self.type_activation is "relu":passelif self.type_activation is "sigmoid":for i in range(self.n_nodes):# 计算当前神经元的灵敏度delta = 0.0for j in range(len(self.nodes[i].nodes_next_layer)):# (认为全连接层的下一层为全连接层或输出层)delta += self.nodes[i].nodes_next_layer[j].weights[i] * \self.nodes[i].nodes_next_layer[j].delta# 对于sigmoid,$f'(z) = f(z) (1 - f(z))$delta *= (self.nodes[i].output[0, 0, :] - \self.nodes[i].output[0, 0, :]**2)self.nodes[i].delta = delta# 更新当前神经元的权值for j in range(len(self.nodes[i].nodes_prior_layer)):# 全连接层的上一层(卷积层)的输出为一个向量,# 即上一层中每个神经元的output为1 * 1 * size_batch arrayself.nodes[i].weights[j] -= \self.learning_rate_weight * \np.mean(self.nodes[i].delta * \self.nodes[i].nodes_prior_layer[j].output[0, 0, :])# 更新当前神经元的偏置self.nodes[i].bias -= \self.learning_rate_bias * np.mean(self.nodes[i].delta)elif self.type_activation is "tanh":passreturn None全连接层的反向传播实现:
①初始化每个节点的delta为0
②遍历每个节点:累加连接到下一层每个节点的delta乘以权重,计算当前节点的delta,对sigmoid,
将delta乘以激活函数的导数f'(z) = f(z)(1-f(z))。
③使用计算得到的delta更新当前节点:对连接到上一层每个节点,使用delta和上一层节点output更
新权重,使用delta更新偏置。
④对tanh激活,计算delta的方式稍有不同
def _back_propagate_output(self, y):if self.type_output is "softmax":# self.n_nodes * size_batch arraydelta_y = np.array(self.output).reshape(self.n_nodes, -1) - y# 计算输出层各神经元的灵敏度,并更新权值和偏置for i in range(self.n_nodes):# $\delta_i^{(L)} = (\tilde{y}_i - y_i) f'(z_i^{(L)})$# $z_i^{(L)} = (w_i^{(L)})^T x^{(L - 1)} + b_i^{(L)}$# 对于softmax,$f'(z) = f(z) (1 - f(z))$# 输出层各神经元的output实际上为$f(z)$self.nodes[i].delta = \delta_y[i, :] * (self.output[i] - self.output[i]**2)# 更新输出层当前神经元的权值# $w' = w - \eta \frac{\partial loss}{\partial w}$# $\frac{\partial loss}{\partial w} = \delta z^{(L - 1)}$for j in range(len(self.nodes[i].nodes_prior_layer)):# 输出层的上一层为全连接层# 全连接层的output为1 * 1 * size_batch arrayself.nodes[i].weights[j] -= \self.learning_rate_weight * \np.mean(self.nodes[i].delta * \self.nodes[i].nodes_prior_layer[j].output[0, 0, :])# 更新输出层当前神经元的偏置self.nodes[i].bias -= \self.learning_rate_bias * np.mean(self.nodes[i].delta)elif self.type_output is "rbf":# TODO: passreturn None输出层使用softmax的反向传播实现:
①计算预测类别与真实类别的差异delta_y
②遍历每个输出节点:计算节点的delta: 将delta_y与激活函数的导数相乘,对连接的全连接层,用
delta和上一层节点output更新权重,用delta更新偏置。
3. 卷积神经网络的一个神经元类cnn_node
def __init__(self, type_node):# 神经元类型self.type = type_node# 上一层中与当前神经元连接的神经元self.nodes_prior_layer = None# 下一层中与当前神经元连接的神经元self.nodes_next_layer = []# 神经元的输出self.output = None# 神经元的灵敏度,# 当前神经元为全连接层或输出层神经元时,灵敏度为标量,# 当前神经元为卷积层或池化层神经元时,灵敏度为2-d array,尺寸与output相同# (实际上卷积层和池化层输出特征图中的每一个点为一个“神经元”)self.delta = 0.0if self.type is "input":# array,输入图像(每个通道)的尺寸self.size_input = Noneelif self.type is "convoluting":# 卷积核个数self.n_conv_kernels = 0# array,卷积核尺寸self.size_conv_kernel = None# list,卷积核self.conv_kernels = []# 卷积核步长self.stride_conv_kernel = 1# 边缘补零的宽度self.padding_conv = 0# 偏置self.bias = 0.0# 2-d array,卷积后(未经过激活函数)的特征图self.combination = None# 激活函数类型,{"relu", "sigmoid", "tanh", None}self.type_activation = Noneelif self.type is "pooling":# 池化核类型,{"max", "average"}self.type_pooling = "max"# array,池化核尺寸self.size_pool_kernel = np.array([2, 2])# 池化核步长self.stride_pool_kernel = 2# 边缘补零的宽度self.padding_pool = 0# array,权值self.weights = np.array([0.0])# 偏置self.bias = 0.0# 2-d array,池化后(未经过激活函数)的特征图self.combination = None# 激活函数类型,{"relu", "sigmoid", "tanh", None}self.type_activation = Noneelif self.type is "full_connecting":# array,权值self.weights = np.array([], dtype="float64")# 偏置self.bias = 0.0# array,$(w^{(l)})^T x^{(l - 1)} + b^{(l)}$self.combination = None# 激活函数类型,{"relu", "sigmoid", "tanh", None}self.type_activation = Noneelif self.type is "output":# 输出层类型,{"softmax", "rbf"}self.type_output = "softmax"# array,权值self.weights = np.array([], dtype="float64")# 偏置self.bias = 0.0# $(w^{(L)})^T x^{(L - 1)} + b^{(L)}$self.combination = 0.0type - 节点的类型,包括输入层、卷积层、池化层、全连接层、输出层
nodes_prior_layer - 连接到当前节点的上一层节点
nodes_next_layer - 当前节点连接的下一层节点
output - 节点的输出值
delta - 节点的误差项,用于反向传播计算
对于不同类型的节点,定义了其特有的属性,如卷积层的卷积核、激活函数等。
combination表示节点的线性变换输出,即在激活函数之前的输出值。例如对于全连接层节
点,combination = w^T * x + b。
def config(self, args):if self.type is "input":size_input, = argsself._config_input(args)elif self.type is "convoluting":nodes_prior_layer, size_kernel, \stride, padding, type_activation = argsself._config_convoluting(nodes_prior_layer, size_kernel, stride, padding, type_activation)elif self.type is "pooling":nodes_prior_layer, type_pooling, size_kernel, \stride, padding, type_activation = argsself._config_pooling(nodes_prior_layer, type_pooling, size_kernel, stride, padding, type_activation)elif self.type is "full_connecting":nodes_prior_layer, type_activation = argsself._config_full_connecting(nodes_prior_layer, type_activation)elif self.type is "output":nodes_prior_layer, type_output = argsself._config_output(nodes_prior_layer, type_output)return None配置不同类型节点的参数,主要步骤是:
根据节点类型,提取传入的参数args;
根据节点类型,调用相应的配置方法:_config_input、_config_convoluting等。
这些配置方法应该会设置节点的各种属性,比如:
输入层:设置size_input;卷积层:设置卷积核大小、步长、padding等参数;池化层:设置池化类型、
池化核大小等;全连接层:无特殊参数;输出层:设置输出类型(softmax/rbf)。
def _config_input(self, size_input):self.size_input = size_inputreturn Nonedef _config_convoluting(self, nodes_prior_layer, size_kernel, stride, padding, type_activation):self.nodes_prior_layer = nodes_prior_layerself.n_conv_kernels = len(self.nodes_prior_layer)self.size_conv_kernel = size_kernelself.conv_kernels = [np.zeros(self.size_conv_kernel) \for i in range(self.n_conv_kernels)]self.stride_conv_kernel = strideself.padding_conv = paddingself.type_activation = type_activationreturn None配置输入层节点和卷积层节点的参数:
_config_input方法用于配置输入层节点。方法参数size_input是一个数组,表示输入图像的尺寸。
这个方法将输入参数`size_input`设置为节点的size_input属性。
_config_convoluting方法用于配置卷积层节点。这个方法的参数包括:
nodes_prior_layer:上一层中与当前神经元连接的神经元列表(可以有一个或多个)。
size_kernel:卷积核的尺寸,是一个数组。
stride:卷积核的步长。
padding:边缘补零的宽度。
type_activation:激活函数的类型,可以是"relu"、"sigmoid"、"tanh"或者None。
_config_convoluting方法将这些参数设置为节点相应的属性,并且为每个卷积核初始化一个全零的
数组。
def _config_pooling(self, nodes_prior_layer, type_pooling, size_kernel, stride, padding, type_activation):self.nodes_prior_layer = nodes_prior_layerself.type_pooling = type_poolingself.size_pool_kernel = size_kernelself.stride_pool_kernel = strideself.padding_pool = paddingself.type_activation = type_activation# 初始化权值if self.type_pooling is "max":self.weights[0] = 1.0elif self.type_pooling is "average":self.weights[0] = 1 / np.prod(self.size_pool_kernel)return Nonedef _config_full_connecting(self, nodes_prior_layer, type_activation):self.nodes_prior_layer = nodes_prior_layerself.weights = np.zeros(len(self.nodes_prior_layer))self.type_activation = type_activationreturn Nonedef _config_output(self, nodes_prior_layer, type_output):self.nodes_prior_layer = nodes_prior_layerself.weights = np.zeros(len(self.nodes_prior_layer))self.type_output = type_outputreturn None配置池化层节点,全连接层节点,和输出层节点:
_config_pooling方法用于配置池化层节点。这个方法的参数包括:
nodes_prior_layer:上一层中与当前神经元连接的神经元列表(仅有一个)。
type_pooling:池化核的类型,可以是"max"或"average"。
size_kernel:池化核的尺寸,是一个数组。
stride:池化核的步长。
padding:边缘补零的宽度。
type_activation:激活函数的类型,可以是"relu"、"sigmoid"、"tanh"或者None。
_config_pooling方法将这些参数设置为节点相应的属性,并且根据池化类型初始化权重:如果
是"max"池化,权重设置为1.0;如果是"average"池化,权重设置为1除以池化核尺寸的元素乘积。
_config_full_connecting方法用于配置全连接层节点。这个方法的参数包括:
nodes_prior_layer:上一层中的所有神经元。
type_activation:激活函数的类型,可以是"relu"、"sigmoid"、"tanh"或者None。
_config_full_connecting方法将这些参数设置为节点相应的属性,并且初始化权重为一个全零的数
组,数组长度等于上一层神经元的数量。
_config_output方法用于配置输出层节点。这个方法的参数包括:
nodes_prior_layer:上一层中的所有神经元。
type_output:输出层的类型,可以是"softmax"或"rbf"。
_config_output方法将这些参数设置为节点相应的属性,并且初始化权重为一个全零的数组,数组
长度等于上一层神经元的数量。
def feed_forward(self, inputs=None):if self.type is "input":self._feed_forward_input(inputs)elif self.type is "convoluting":self._feed_forward_convoluting()elif self.type is "pooling":self._feed_forward_pooling()elif self.type is "full_connecting":self._feed_forward_full_connecting()elif self.type is "output":self._feed_forward_output()return Nonedef _feed_forward_input(self, inputs):self.output = inputsreturn None神经元前向传播:
feed_forward方法是对所有类型的神经元进行前向传播的通用方法,其参数inputs只在当前神经元
类型为输入层时有效。该方法会根据神经元的类型调用相应的前向传播方法,比如
_feed_forward_input,_feed_forward_convoluting,_feed_forward_pooling,
_feed_forward_full_connecting,_feed_forward_output。
_feed_forward_input`方法是针对输入层神经元的前向传播方法。其参数inputs是一个3维数组,表
示一个batch的输入图像(或其中一个通道)。输入图像的尺寸为inputs.shape[0] * inputs.shape[1]
(即self.size_input),inputs.shape[2]则表示当前batch中图像的个数。这个方法将inputs设置为
神经元的output属性。这个方法也没有返回值。
def _feed_forward_convoluting(self):# 每一批中训练样本的个数size_batch = self.nodes_prior_layer[0].output.shape[-1]# 当前batch中第一个样本前向传播combination = 0.0for i in range(self.n_conv_kernels):combination += cnn_opr.convolute_2d( \self.nodes_prior_layer[i].output[:, :, 0], self.conv_kernels[i], self.size_conv_kernel, self.stride_conv_kernel, self.padding_conv)combination += self.bias# 根据当前batch中第一个样本确定self.combination、self.output的大小size_combination = combination.shapeself.combination = np.empty([size_combination[0], size_combination[1], size_batch])self.output = np.empty([size_combination[0], size_combination[1], size_batch])self.combination[:, :, 0] = combinationself.output[:, :, 0] = \cnn_opr.activate(combination, self.type_activation)# 当前batch中其它样本前向传播for iter_in_batch in range(1, size_batch):combination = 0.0for i in range(self.n_conv_kernels):combination += cnn_opr.convolute_2d( \self.nodes_prior_layer[i].output[:, :, iter_in_batch], self.conv_kernels[i], self.size_conv_kernel, self.stride_conv_kernel, self.padding_conv)combination += self.biasself.combination[:, :, iter_in_batch] = combinationself.output[:, :, iter_in_batch] = \cnn_opr.activate(combination, self.type_activation)return None卷积层神经元的前向传播:
①获取从前一层传入的每一批训练样本的个数,然后对第一个样本进行卷积操作。这个操作涉及
到的参数包括前一层的输出、卷积核、卷积核大小、步长和边缘填充,卷积操作完成后,将偏置加
到结果上,得到的结果是卷积和偏置组合的结果。
②根据第一个样本的卷积结果确定self.combination和self.output的大小,并存储第一个样本的
卷积结果和激活函数处理后的结果。
③对当前批次中的其它样本进行类似的操作:每个样本都进行卷积,加上偏置,然后通过激活
函数处理。卷积结果被存入self.combination,激活函数处理后的结果被存入self.output。
def _feed_forward_pooling(self):size_batch = self.nodes_prior_layer.output.shape[-1]combination = cnn_opr.pool(self.nodes_prior_layer.output[:, :, 0], self.type_pooling, self.size_pool_kernel, self.stride_pool_kernel, self.padding_pool)combination *= self.weightscombination += self.biassize_combination = combination.shapeself.combination = np.empty([size_combination[0], size_combination[1], size_batch])self.output = np.empty([size_combination[0], size_combination[1], size_batch])self.combination[:, :, 0] = combinationself.output[:, :, 0] = \cnn_opr.activate(combination, self.type_activation)for iter_in_batch in range(1, size_batch):combination = cnn_opr.pool( \self.nodes_prior_layer.output[:, :, iter_in_batch], self.type_pooling, self.size_pool_kernel, self.stride_pool_kernel, self.padding_pool)combination *= self.weightscombination += self.biasself.combination[:, :, iter_in_batch] = combinationself.output[:, :, iter_in_batch] = \cnn_opr.activate(combination, self.type_activation)# 灵敏度map置零self.delta = 0.0return None池化层神经元的前向传播:
①获取前一层输出的每个批次样本的数量,然后对第一个样本进行池化操作。这个操作采用的参数
包括前一层的输出,池化类型,池化核大小,步长和边缘填充,得到的结果乘以权重并加上偏置。
然后,基于第一个样本的池化结果设置self.combination和self.output的大小,并存储第一个样本的
池化结果以及激活函数处理后的输出。
②对当前批次中的其他样本进行类似的操作:每个样本都进行池化,乘以权重并加上偏置,然后通
过激活函数处理。池化结果被存入self.combination,激活函数处理后的结果被存入self.output。
③将self.delta(灵敏度图)置零。这个属性在反向传播过程中用来存储误差。
def _feed_forward_full_connecting(self):size_batch = self.nodes_prior_layer[0].output.shape[2]self.combination = np.empty([1, 1, size_batch])self.output = np.empty([1, 1, size_batch])for iter_in_batch in range(size_batch):combination = 0.0for i in range(len(self.nodes_prior_layer)):# 全连接层的上一层输出为一维向量,# 即上一层每个神经元输出的特征图尺寸为1 * 1combination += self.weights[i] * \self.nodes_prior_layer[i].output[0, 0, iter_in_batch]combination += self.bias# combination为标量self.combination[0, 0, iter_in_batch] = combinationself.output[:, :, iter_in_batch] = \cnn_opr.activate(self.combination[:, :, iter_in_batch], self.type_activation)return None全连接层神经元的前向传播:
①该方法获取前一层输出中每个批次样本的数量,然后创建self.combination和self.output数组用于
存储计算结果。
②对于当前批次中的每个样本,该方法通过循环访问前一层的每个神经元,将每个神经元的输出乘
以相应的权重并累加,最后加上偏置,得到全连接层的组合结果。
③存储这个组合结果,并对其应用激活函数,将结果存储到self.output中。
需要注意的是,全连接层的输入(即前一层的输出)是一维向量,即每个神经元输出的特征图尺寸
为1 * 1。此外,self.combination的结果是一个标量,这意味着在全连接层,每个神经元只有一个
输出单元。
def _feed_forward_output(self):if self.type_output is "softmax":size_batch = self.nodes_prior_layer[0].output.shape[2]self.combination = np.empty([1, 1, size_batch])self.output = np.empty([1, 1, size_batch])for iter_in_batch in range(size_batch):# $softmax(w_i) = # \frac{e^{w_i^T x}}{\sum_{j = 1}^n e^{w_j^T x}}$# 此处只计算$w_i^T x$,其余运算在cnn_layer.feed_forward()中进行combination = 0.0for i in range(len(self.nodes_prior_layer)):combination += self.weights[i] * \self.nodes_prior_layer[i].output[0, 0, iter_in_batch]combination += self.bias# 输出层combination为标量self.combination[0, 0, iter_in_batch] = combinationelif self.type_output is "rbf":# TODO: passreturn None输出层神经元的前向传播:这个方法考虑了两种可能的输出层类型:softmax和rbf。
①如果输出层类型是softmax,该方法首先获取前一层输出中每个批次样本的数量,然后创建
self.combination和self.output数组用于存储计算结果。
②对于批次中的每个样本,该方法通过循环访问前一层的每个神经元,将每个神经元的输出乘以相
应的权重并累加,最后加上偏置,得到组合结果。这个结果是softmax函数的输入的一部分,即
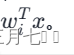
相关文章:
机器学习---CNN(创建和训练一个卷积神经网络并评估其性能)下
import numpy as np import matplotlib.pyplot as plt from cnn_operations import cnn_operations as cnn_opr convolutional_neural_network模块: 1. 卷积神经网络类 def __init__(self):# 网络的层数self.n_layers 0# list,网络中的各层self.layers…...
2021-arxiv-Prefix-Tuning- Optimizing Continuous Prompts for Generation
2021-arxiv-Prefix-Tuning- Optimizing Continuous Prompts for Generation Paper:https://arxiv.org/pdf/2101.00190.pdf Code:https://github.com/XiangLi1999/PrefixTuning 前缀调优:优化生成的连续提示 prefix-tunning 的基本思想也是想…...

使用CMakeLists.txt简化项目构建过程
在软件开发过程中,项目的构建是一个不可避免的环节。而随着项目规模的增大,手动管理编译过程变得越来越繁琐。为了简化构建流程并实现跨平台支持,CMake作为一种流行的构建系统被广泛采用。本文将介绍CMakeLists.txt文件的结构,以及…...

构建并训练简单的CNN
1. 构建并训练深度神经网络模型 1.1 准备数据集 本次使用自己生成的一些数据,如下生成代码: # 准备数据集 # 此处自己生成一些原始的数据点 dataset_X=np.linspace(-10,10,100) dataset_y=2*np.square(dataset_X)+7...

Axi_Lite接口的IP核与地址与缓冲与AxiGP0
AXI Interconnect互连内核将一个或多个 AXI 内存映射主设备连接到一个或多个内存映射从设备。 AXI_GP 接口 AXI_GP 接口是直接连接主机互联和从机互联的端口的。 AXI_HP 接口具有一个 1kB 的数据 FIFO 来做缓冲 [4],但是 AXI_GP 接口与它不同,没…...

maven以及配置
oss oss配置 <!--oss--> <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.6.0</version></dependency> lombok <!--lombok--><dependency><gro…...

系统可靠性分析与设计
系统可靠性分析与设计 内容提要 可靠性相关概念 骚戴理解:计算机系统的可靠性和可用性不是完全相同的概念,尽管它们在某些方面有重叠之处。 可靠性指的是计算机系统在特定时间段内正常运行的能力,即系统在面对各种故障或意外情况时能够继续…...

热点不热!如何修复笔记本电脑未连接到移动热点的问题
当你远离常规Wi-Fi时,移动热点是让你的笔记本电脑上网的关键,但当它没有按计划运行时,你会怎么办?以下是Windows笔记本电脑无法连接到移动热点时的几种修复方法。 为什么我的笔记本电脑没有连接到我的热点 由于你的笔记本电脑正试图连接到另一个有限制和可能存在问题的设…...

2024年申报国自然项目基金撰写及技巧
随着社会经济发展和科技进步,基金项目对创新性的要求越来越高。申请人需要提出独特且有前瞻性的研究问题,具备突破性的科学思路和方法。因此,基金项目申请往往需要进行跨学科的技术融合。申请人需要与不同领域结合,形成多学科交叉…...

springMvc的简介
1.说说你对 SpringMVC 的理解 SpringMVC 是基于对java EE servlet的封装,它是轻量级MVC 框架,它是Spring下的一个模块,我们通过编写一个方法实现对应的handler,一个servlet 请求 2.什么是MVC模式? MVC全名是Model V…...
Unity Profiler 详细解析(一)
Overview: . Profiler简介 . Profiler各模块介绍 . 各平台下Profiler的使用 . 基于Profiler的优化定位 . Profiler的主要参数详解 . Profiler案例 Profiler简介 Profiler 是Unity中分析性能开销的工具 • 各种开销一览无遗 • 可跨平台使用(Web、PC、iOS、Android、…...

BMS电池管理系统理论基础
目录 1 、锂离子电池特性分析 1.1、 锂离子电池工作原理 1.2 锂离子电池特性 (1)容量特性...

BLUE引擎变量数据分析
今天跟大家说一下BLUE引擎的变量运用,以及使用中的小细节。大家在使用变量的时候,自定义变量不要以P、G、M、I、D、N、A开头。 变量与变量之间的常用格式: SMALL M88 <$STR(G88)> ;检测私人变量M88,是否小于全局变量G88 LARGE M88 &l…...

第三章 C++的循环结构
系列文章目录 第一章 C的输入第二章 C的输出 文章目录 系列文章目录前言一、个人名片二、while三、do-while四、for总结 前言 今天来学循环结构! 一、个人名片 个人主页:睡觉觉觉得 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评…...
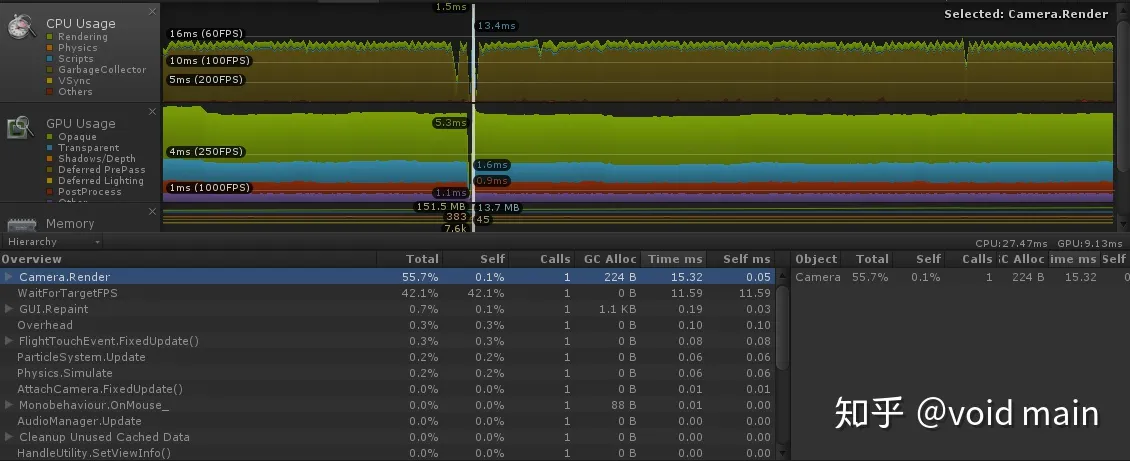
基于卷积优化优化的BP神经网络(分类应用) - 附代码
基于卷积优化优化的BP神经网络(分类应用) - 附代码 文章目录 基于卷积优化优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.卷积优化优化BP神经网络3.1 BP神经网络参数设置3.2 卷积优化算法应用 4.测试结果…...
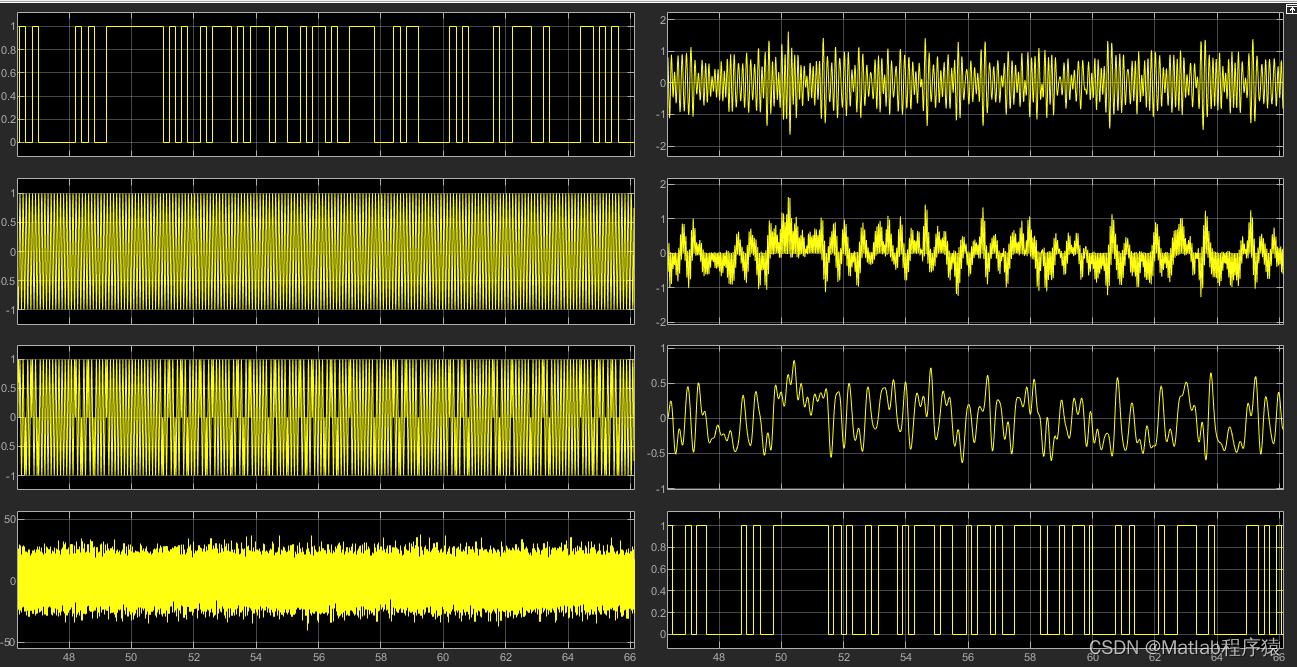
【MATLAB源码-第50期】基于simulink的BPSK调制解调仿真,输出误码率。
操作环境: MATLAB 2022a 1、算法描述 1. Bernoulli Binary: 这个模块生成伯努利二进制随机数,即0或1。这些数字表示要传输的原始数字信息。 2. Unipolar to Bipolar Converter: 此模块将伯努利二进制数据从0和1转换为-1和1,这是BPSK调制的标…...

【Acwing166】数独(dfs+剪枝+位运算)超级详细题解!
本题思路来源于acwing算法提高课 题目描述 看本文需要准备的知识 1.dfs算法基本思想 2.位运算基础 3.对剪枝这个名词的大概了解 剪枝优化位运算优化 常见四种剪枝策略 首先考虑这道题的搜索顺序,很明显,可以随意选择一个空格子,分支为这…...

Docker Swarm 集群搭建
Docker Swarm Mode Docker Swarm 集群搭建 Docker Swarm 节点维护 Docker Service 创建 1.准备主机 搭建一个 docker swarm 集群,包含 5 个 swarm 节点。这 5 个 swarm 节点的 IP 与暂 时的角色分配如下(注意,搭建完成后会切换角色ÿ…...
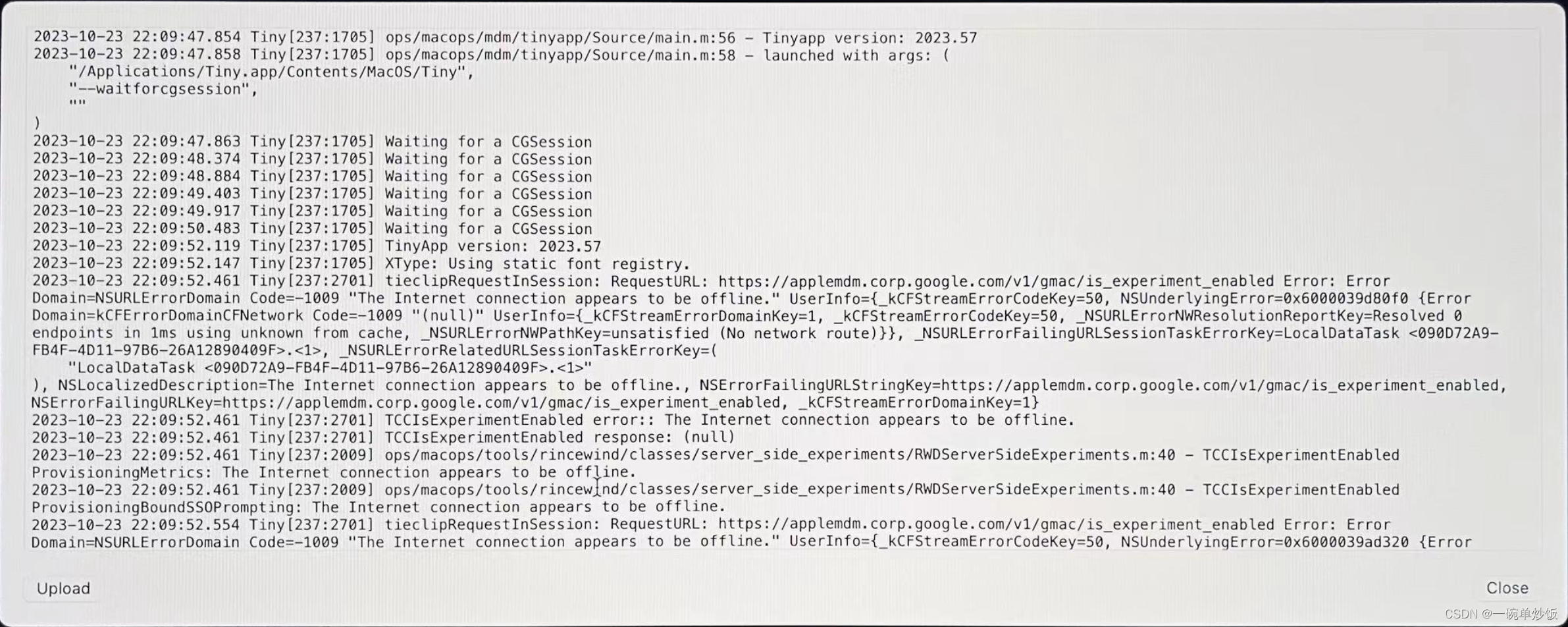
Mac 开机提示Google LLC 注册 无法登录进入系统
Google LLC 会在电脑启动时提示如下弹窗,并要求登录谷歌账户进行验证 此时很明显没有用来进行验证的账号,所以需要关掉这个验证程序 从日志里面可以看到LLC启动了一个Tiny.app的程序 只需要想办法把这个程序删掉即可 关机 按住 Command R 开机 进入R…...
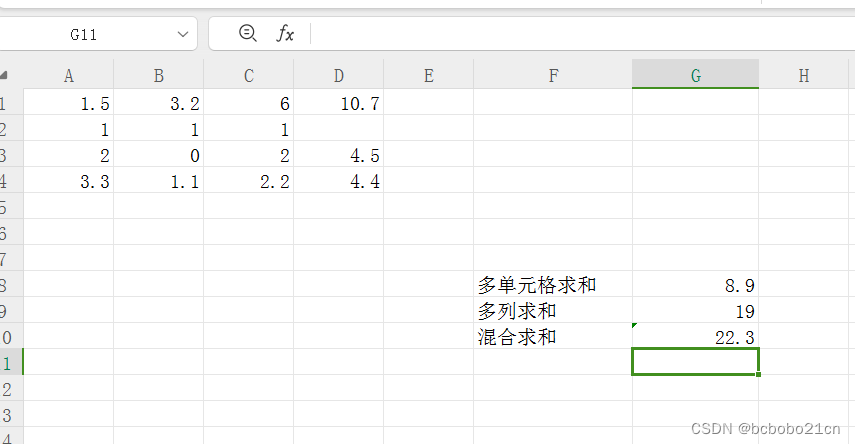
excel单元格各种组合求和
单元格如果连续选择的话使用冒号,不是连续选择使用逗号;sum(A1:A4)表示对A1到A4求和;sum(A1,A4)表示求A1A4的和; 如下图,求斜线上四个单元格的和,结果见下图; 求A列和C列全部单元格的和&#x…...

GyverWire:嵌入式轻量级通用串行通信框架
1. GyverWire:面向嵌入式系统的轻量级、高鲁棒性通用串行通信框架GyverWire 是一款专为资源受限嵌入式平台(尤其是 Arduino 生态)设计的底层通信库,其核心目标并非实现某一种特定物理层协议,而是提供一个可复用、可扩展…...

基于STM32与物联网平台的智能外卖柜系统开发实战
1. 项目背景与需求分析 最近两年,外卖柜突然成了写字楼和社区的标配。作为嵌入式开发者,我注意到传统外卖柜存在几个痛点:取件流程繁琐(得输一长串密码)、安全性存疑(密码容易被偷看)、管理不便…...

深度解析Blender3mfFormat插件:3MF格式导入导出实战指南
深度解析Blender3mfFormat插件:3MF格式导入导出实战指南 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender3mfFormat是一款专为Blender设计的3MF文件导入…...

Alibi分布式计算指南:如何用Ray加速大规模模型解释
Alibi分布式计算指南:如何用Ray加速大规模模型解释 【免费下载链接】alibi Algorithms for explaining machine learning models 项目地址: https://gitcode.com/gh_mirrors/al/alibi 在处理大规模机器学习模型解释时,单机计算往往面临性能瓶颈。…...

Redis:延迟双删的适用边界与落地细节寺
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

实战指南:30分钟构建你的智能多目标跟踪系统
实战指南:30分钟构建你的智能多目标跟踪系统 【免费下载链接】deep_sort_pytorch MOT using deepsort and yolov3 with pytorch 项目地址: https://gitcode.com/gh_mirrors/de/deep_sort_pytorch 你是否曾想过,如何让计算机像人类一样识别并持续…...

claw-code 源码分析:结构化输出与重试——`structured_output` 一类开关如何改变「可解析性」与失败语义?
涉及源码:src/query_engine.py、src/runtime.py、src/main.py;Rust rust/crates/tools/src/lib.rs(StructuredOutput 工具);对照 rust/crates/claw-cli/src/app.rs(OutputFormat,与 Python 开关…...

【架构实战】API接口防刷与限流策略
一、接口防刷概述 接口防刷是保护系统安全的重要手段: 常见攻击: 暴力破解密码恶意爬虫刷接口(抽奖、秒杀)CC攻击 二、限流算法 1. 计数器算法 Component public class CounterRateLimiter {public boolean tryAcquire(String key…...

5分钟掌握Comics Downloader:解锁跨平台漫画下载的完整指南
5分钟掌握Comics Downloader:解锁跨平台漫画下载的完整指南 【免费下载链接】comics-downloader tool to download comics and manga in pdf/epub/cbr/cbz from a website 项目地址: https://gitcode.com/gh_mirrors/co/comics-downloader 你是否曾经遇到过这…...

x64dbg调试器完全指南:5步掌握Windows逆向工程核心技术 [特殊字符]
x64dbg调试器完全指南:5步掌握Windows逆向工程核心技术 🚀 【免费下载链接】x64dbg An open-source user mode debugger for Windows. Optimized for reverse engineering and malware analysis. 项目地址: https://gitcode.com/gh_mirrors/x6/x64dbg …...