python如何创建自己的对冲交易算法
在这篇文章中,我解释了如何创建一个人工智能来每天为我进行自动交易。
随着机器学习的现代进步和在线数据的轻松访问,参与量化交易变得前所未有的容易。为了让事情变得更好,AWS 等云工具可以轻松地将交易想法转化为真正的、功能齐全的交易机器人。在过去的几年里,我一直在处理财务数据,最近决定冒险制定一个完全自动化的策略。
策略
由于这是我的第一个自动化策略,因此我决定使其变得相当简单。我会使用 ML 模型的明智决策来进行 SPY(标准普尔 500 指数)的波动交易。我决定使用 SPY 作为我的首选资产,因为如果我的策略出现问题,它的风险相对较低。
目标:使用由机器学习模型确定的知情买入/卖出点进行摇摆交易 SPY。
数据
为了就何时进行 SPY 交易做出明智的决定,我训练了一个 ML 模型,该模型可以根据来自各个金融部门和美国国库券的每日历史数据来预测交易。我使用开源 YFinance API 从这些资产中提取了大约 20 年的日常数据。
import yfinance as yf
import pandas as pdSPY_daily = yf.download('SPY')
energy_daily = yf.download('XLE')
materials_daily = yf.download('XLB')
industrial_daily = yf.download('XLI')
utilities_daily = yf.download('XLU')
health_daily = yf.download('XLV')
financial_daily = yf.download('XLF')
consumer_discretionary_daily = yf.download('XLY')
consumer_staples_daily = yf.download('XLP')
technology_daily = yf.download('XLK')
real_estate_daily = yf.download('VGSIX')
TYBonds_daily = yf.download('^TNX')
VIX_daily = yf.download('^VIX')以下是我在过去 20 年中为模型提取的所有数据。
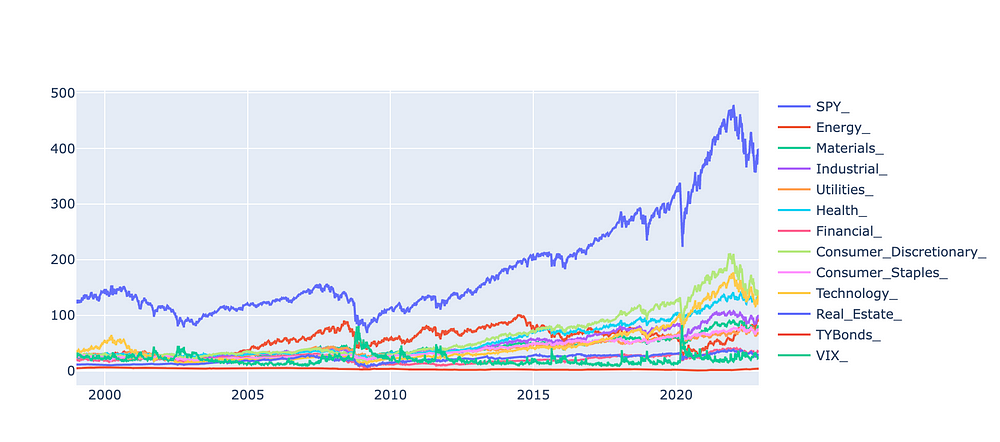
原始历史数据图
在 jupyter 笔记本中,数据如下所示,每一行都是一个单独的日期。
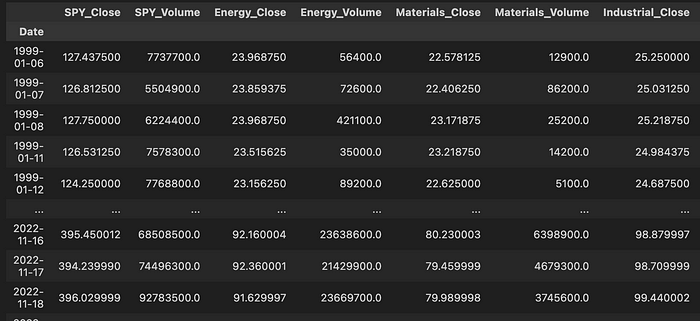
原始历史数据
特征工程
然后,使用我提取的原始历史数据,我为我的模型生成了附加功能。我导出了各种技术分析指标,包括简单移动平均线、波动率和相对强弱指数(RSI)等。为了使功能更加多样化,我用 7、20、50 和 200 天的窗口计算了这些技术指标。
def SMA(df, feature, window_size):new_col = 'MA' + feature + str(window_size)df[new_col] = df[feature].rolling(window=window_size).mean()return dfdef Volitility(df, feature, window_size):new_col = 'VOLITILITY' + feature + str(window_size)returns = np.log(df[feature]/df[feature].shift())returns.fillna(0, inplace=True)df[new_col] = returns.rolling(window=window_size).std()*np.sqrt(window_size)return dfdef RSI(df, feature, window_size):new_col = 'RSI' + feature + str(window_size)delta = df[feature].diff()delta = delta[1:]up, down = delta.clip(lower=0), delta.clip(upper=0)roll_up = up.rolling(window_size).mean()roll_down = down.abs().rolling(window_size).mean()RS = roll_up / roll_downRSI = 100.0 - (100.0 / (1.0 + RS))df[new_col] = RSIreturn df数据标签
一旦我的所有功能都派生出来,最困难的部分就来了,创建一种标记数据的方法,让机器学习模型可以在我的波动交易策略中使用。
在金融界众所周知,利用历史数据来预测未来价格几乎是不可能的。大多数证券不遵循任何明确的统计分布,尝试建立回归模型来预测未来价格几乎总是完全无用的。
相反,最好创建分类标签并使用分类模型来预测某些“事件”的概率。
三重屏障法
三重障碍法是一种为机器学习模型标记财务数据以预测贸易结果的直观方法。这个方法取自Marcos Lopez de Prado的书《金融机器学习的进展”(我强烈推荐)。
三重障碍法的工作原理如下:首先,确定您想要持有交易的时间范围。让我们将这100个交易日定为100个交易日。然后,让我们为任意交易确定一个理想的止盈阈值。我们将其设为1 x当前市场波动率。最后,让我们为任意交易设置一个理论止损。出于演示目的,我们还将其设为当前市场波动率的 1倍。这三个条件就是我们的“三关”。
现在我们已经设置了障碍,我们使用以下步骤为间谍交易创建标签:
1. 在金融时间序列中选取一个我们想要标记的日期
2. 提前 100 个交易日。在这里创建一个垂直障碍。这个障碍代表交易是否持有太久而没有止损或触及我们的止盈。
3. 创建高于我们日期 1 倍市场波动率的水平障碍。该障碍代表交易是否已达到我们的止盈阈值。
4. 创建另一个水平障碍,其市场波动性低于我们的日期。该障碍代表交易是否已停止。
5. 根据 SPY 是否触及止盈障碍、触及止损障碍或持有时间过长,明确标记我们的日期
单个日期的最终结果将如下所示:
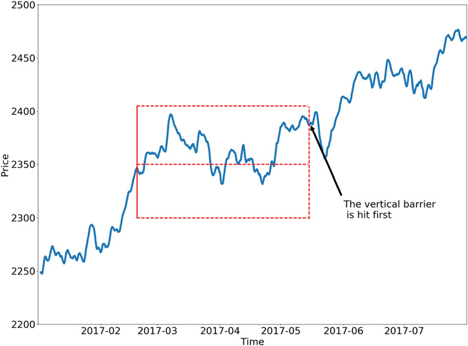
三重屏障法
上面的例子显示了 2017 年 2 月当天交易的三重障碍法。该交易没有达到我们的利润或止损阈值,而是首先触及垂直障碍。
对于我的策略,我调整了三重屏障方法,仅使用两个标签而不是三个标签。如果某个日期的理论交易达到了我的止盈阈值,我就给它贴上“盈利”标签,如果没有,我就给它贴上“无利润”标签。这将使我的数据适合训练二元分类模型,这将更容易进行微调。我还将止盈阈值调整为当前市场波动率的2 倍,并将最大持有期调整为仅10 天,这样我的策略就能更快地进行交易。
以这种方式标记我的数据将有助于训练我的模型,使其仅适用于更直接、大额支出的交易。
def get_Daily_Volatility(close,span0=20):# simple percentage returnsdf0=close.pct_change()# 20 days, a month EWM's std as boundarydf0=df0.ewm(span=span0).std()df0.dropna(inplace=True)return df0def get_3_barriers(daily_volatility, price):#create a containerbarriers = pd.DataFrame(columns=['days_passed', 'price', 'vert_barrier', \'top_barrier', 'bottom_barrier'], \index = daily_volatility.index)for day, vol in daily_volatility.iteritems():days_passed = len(daily_volatility.loc[daily_volatility.index[0] : day])#set the vertical barrier if (days_passed + t_final < len(daily_volatility.index) and t_final != 0):vert_barrier = daily_volatility.index[days_passed + t_final]else:vert_barrier = np.nan#set the top barrierif upper_lower_multipliers[0] > 0:top_barrier = prices.loc[day] + prices.loc[day] * upper_lower_multipliers[0] * volelse:#set it to NaNstop_barrier = pd.Series(index=prices.index)#set the bottom barrierif upper_lower_multipliers[1] > 0:bottom_barrier = prices.loc[day] - prices.loc[day] * upper_lower_multipliers[1] * volelse: #set it to NaNsbottom_barrier = pd.Series(index=prices.index)barriers.loc[day, ['days_passed', 'price', 'vert_barrier','top_barrier', 'bottom_barrier']] = \days_passed, prices.loc[day], vert_barrier, \top_barrier, bottom_barrierreturn barriersdef get_labels(barriers):labels = []size = [] # percent gained or lossed for i in range(len(barriers.index)):start = barriers.index[i]end = barriers.vert_barrier[i]if pd.notna(end):# assign the initial and final priceprice_initial = barriers.price[start]price_final = barriers.price[end]# assign the top and bottom barrierstop_barrier = barriers.top_barrier[i]bottom_barrier = barriers.bottom_barrier[i]#set the profit taking and stop loss conditonscondition_pt = (barriers.price[start: end] >= top_barrier).any()condition_sl = (barriers.price[start: end] <= bottom_barrier).any()#assign the labelsif condition_pt: labels.append(1)else: labels.append(0)size.append((price_final - price_initial) / price_initial)else:labels.append(np.nan)size.append(np.nan)return labels, size# how many days we hold the stock which set the vertical barrier
t_final = 10
#the up and low boundary multipliers
upper_lower_multipliers = [2, 2]
#allign the indexvol_df = get_Daily_Volatility(full_df.SPY_Close)
prices = full_df.SPY_Close[vol_df.index]
barriers = get_3_barriers(vol_df, prices)
barriers.index = pd.to_datetime(barriers.index)
labs, size = get_labels(barriers)
full_df = full_df[full_df.index.isin(barriers.index)]模型
我尝试使用许多不同的模型来做出明智的贸易预测。我首先尝试了 LSTM 深度神经网络,我发现它在过去对于理解复杂的时间序列非常有用。然而,在进行多次实验后,我无法得到一个没有过度拟合的结果,并且样本外结果非常差。
我最终决定使用更适合表格数据的模型:CatBoost。这个开源梯度增强模型有一个 Python 库,使用起来超级直观,并且性能非常好。
数据准备
为了在 CatBoost 模型中使用我的数据,需要对其进行扁平化,使其不仅包含单个日期的数据,还包含历史数据,以便模型可以了解哪些历史趋势会影响良好的交易。我编写了这个expand_features函数,它扩展了每个特征,获取每个特征相对于时间序列中前 100 个数据点的百分比变化。
def percentage_change(initial,final):return ((final - initial) / initial)def expand_features(full_df):window = 100new_df = pd.DataFrame()for col in full_df.columns:print(col)if not col.startswith('label'):column = full_df[col]for i in range(1, window):shifted = column.shift(i)new_df['Shifted' + str(i) + col] = percentage_change(shifted, column)else:new_df[col] = full_df[col]return new_dffull_df = expand_features(full_df)现在输入到我的 Catboost 模型中的数据如下所示,其中每列都展开以包含过去 x 天的百分比变化。现在有20,301 个独特特征被输入到模型中,代表了广泛的历史市场指标。
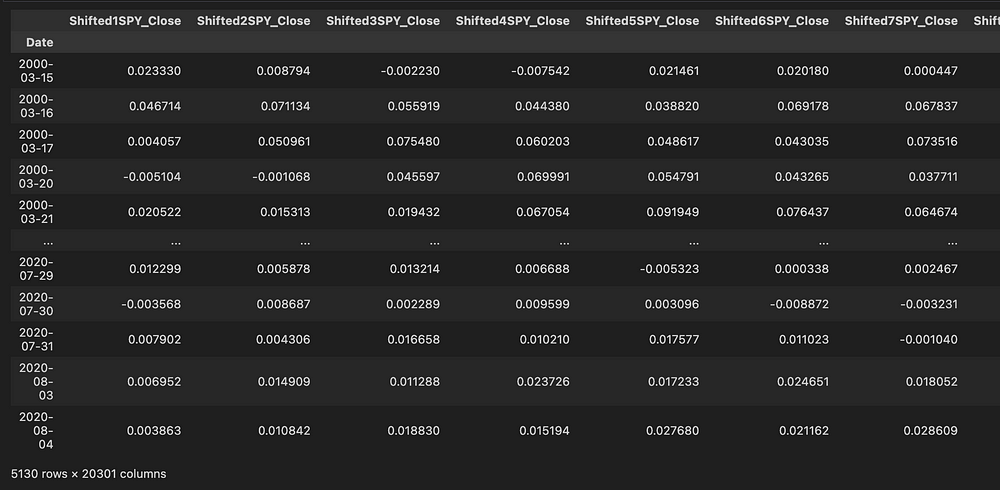
具有历史特征的扩展数据,由“ShiftedX”标注
Catboost模型
然后将数据拟合到以下模型中,以预测在每个日期购买 SPY 是否会产生有利可图的交易。
classification_params = {'loss_function':'Logloss','eval_metric':'AUC','early_stopping_rounds': 2,'verbose': 200,'random_seed': SEED}model = CatBoostClassifier(**classification_params)model.fit(X_train, Y_train, eval_set=(X_test, Y_test), use_best_model=True, )模型分析
交叉验证
为了验证我的模型,我将数据集分为训练集和“样本外”测试集。火车数据集由2000年3月 至2020年8月的数据组成,我的测试集由2020年8月至2022年11月的数据组成。
KFold 交叉验证用于使用我的训练数据确定模型性能。这涉及将训练数据分为 5 个不同的部分。然后,旋转 5 个分段中的 4 个来训练模型,同时使用 1 个分段来验证和微调模型性能。
模型性能
一旦我对模型架构充满信心,我就使用整个训练数据集训练了最终模型,并在测试数据上测试了样本性能。
结果显示该模型比我预期的要好得多,测试ROC AUC 为 0.69。虽然这并不是一个令人惊叹的 ROC 分数,但看到财务数据的这种结果给我留下了深刻的印象。财务数据具有令人难以置信的随机性,并且很难预测结果。任何比抛硬币更好的事情都被认为是我们交易策略中的优势。
该模型似乎过度拟合,训练ROC AUC 为 0.98,远优于测试数据性能0.69。老实说,我并不太担心这种过度拟合,因为这个模型明显产生了优势,而且看起来比猜测要好得多。然而,我认为肯定有更多的机会来推广这个模型以防止过度拟合。我相信这可以通过合并更多数据或使用随机森林等装袋集成来适应我的数据来完成。

我的最终模型的 ROC 曲线
特征分析
我的模型的特征重要性看起来非常有趣。该模型主要优先考虑各个金融部门的波动性,以预测在任何给定日期购买 SPY 是否会产生获胜交易。无论出于何种原因,基于能源部门的特征始终对我的模型做出了巨大贡献。
我的模型优先考虑波动性这一事实是完全有道理的。获胜交易的特点是我们的资产大幅上涨,而市场波动是预测大幅波动的好方法。
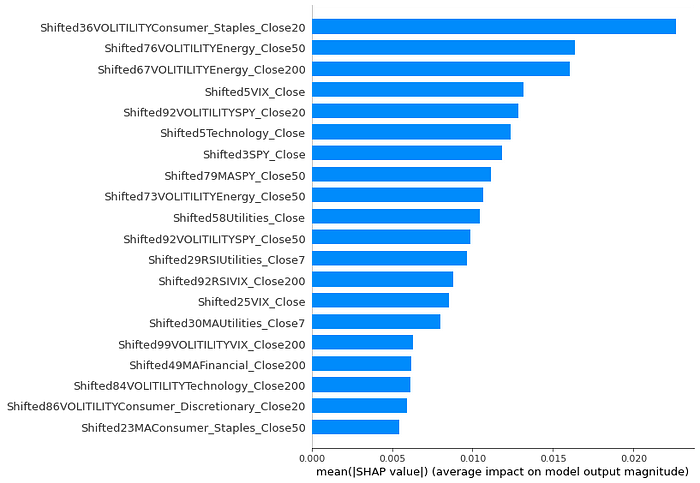
SHAP 特征对我的模型的重要性
概括
我现在创建了一个模型,该模型接收给定日期的历史财务数据,并预测购买 SPY 将在未来 10 天内产生可观利润交易的概率
输入:给定日期的历史财务信息
输出:购买 SPY 将在未来 10 天内产生可观利润交易的概率
回测
现在我有了一个功能模型来充当我们策略的预测引擎,我可以进入真正有趣的部分:弄清楚波段交易策略的执行效果如何。
设置最佳阈值
在实际测试模型之前,我首先需要确定模型产生的概率阈值应该触发交易。
我可以简单地说“如果模型产生的 概率大于 50%,则购买 SPY ”。然而,这通常不是二元分类模型的最佳情况,因为我们必须考虑误报和漏报的风险。相反,我通过查找在训练数据上产生最大F 分数的输出概率来确定最佳阈值。幸运的是,这在 Python 中非常简单!最佳交易阈值最终为0.46。
from sklearn.metrics import precision_recall_curve, f1_score
import numpy as np#Create a Precision/Recall curve for our training data
precision_train, recall_train, pr_thresholds_train = precision_recall_curve(Y_train, probabilities_train)
fscore_train = 2 * (precision_train * recall_train) / (precision_train + recall_train)#Find optimal thresh on PR curve train
ix = np.argmax(fscore_train)
optimal_threshold = pr_thresholds_train[ix]执行回测
然后,我用 Python 编写了一个函数,以确定我们的策略在样本外数据上的盈利能力。
该策略涉及波段交易 SPY,如下所示:
- 提取特定日期的财务数据,生成必要的特征,并将其输入到我们的模型中。
- 如果我们的模型产生的概率大于46%,则购买 SPY
- 将我们的交易设置为当前市场波动率 2 倍的止盈,并设置合理的止损以限制风险。
为了确定在给定交易中购买多少股票,我只需将我们当前的投资组合余额除以 SPY 当前市值的 5 倍。这将使我们能够在任何给定时间轻松地进行大约 5 笔交易,而不会耗尽现金。
回测在样本外数据上的表现非常好,在我们的时间范围内产生了50%的回报。相比之下,整体市场回报率仅为12%。我们的策略还产生了稳定的回报,且回撤很少。
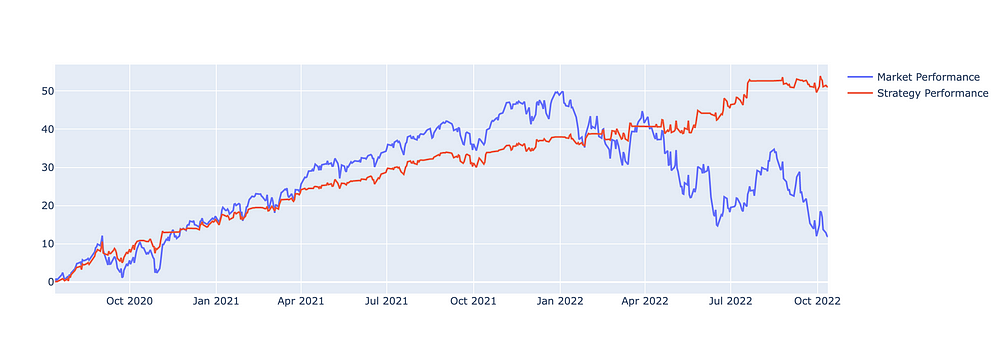
样本外数据的回报百分比
我还计算了一些常见的统计数据,以使用10,000 美元的理论起始余额来评估我们在测试时间范围内的策略表现。
总回报率:50.97%
总交易:284
净利润总额:5107.70 美元
利润系数:2.67
盈利交易百分比:46.47%
平均贸易净利润:17.98 美元
最大回撤:$-554.87
令人惊讶的是,我们的策略只有46.47% 的交易 盈利。然而,由于该模型试图预测股票的大幅上涨,因此获胜的交易大大弥补了我们亏损的交易。即使有大量亏损交易,每笔交易平均净利润为17.98 美元。
基础设施
为了将我的策略投入使用,我使用 AWS 云开发套件 (CDK) 创建基础设施来托管我的策略。然后,该策略被设置为与 Alpaca ( https://alpaca.markets/ ) 进行交互,Alpaca 是一个用于股票和加密货币交易的 API。
首先,我将模型存储在 AWS S3 中,这是一个简单的云存储解决方案。然后,我创建了 2 个独立的 Lambda 函数:一个购买函数和一个销售函数。购买功能将在每个交易日结束时运行,生成是否进行交易的模型预测,并使用 Alpaca API 设置交易。然后,卖出功能会不断扫描未平仓交易,看看它们是否达到了关闭的阈值,要么是因为它们已经达到了止损、利润阈值,要么是持有时间超过 10 天。最后,我创建了两个 DynamoDB 表,一个用于跟踪当前未平仓交易的交易表,以及一个用于跟踪历史交易的历史交易表。
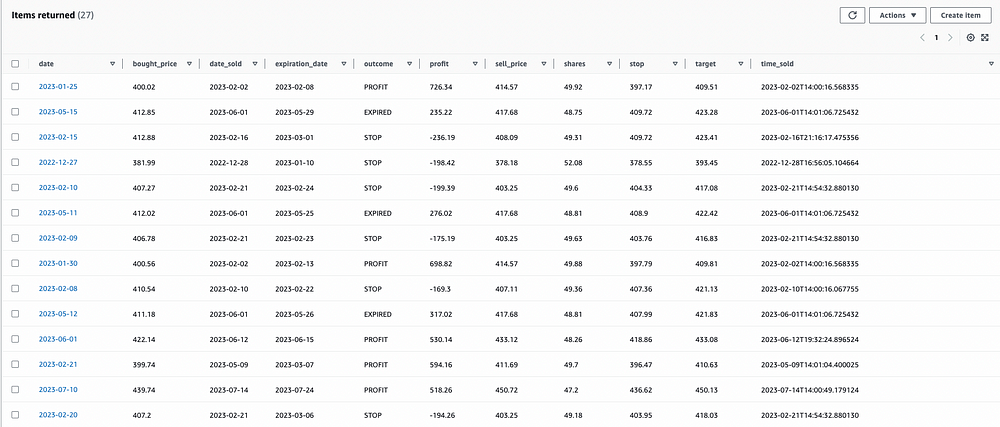
历史交易 DynamoDB 表
将一切结合在一起
快进到今天:我已经在 Alpaca 经纪公司进行纸面交易策略大约 6 个月了。它的表现与回测结果非常相似,产生了稳定的利润,而且回撤很少。自成立以来迄今已上涨6%。看看它如何随着时间的推移继续表现将会很有趣。
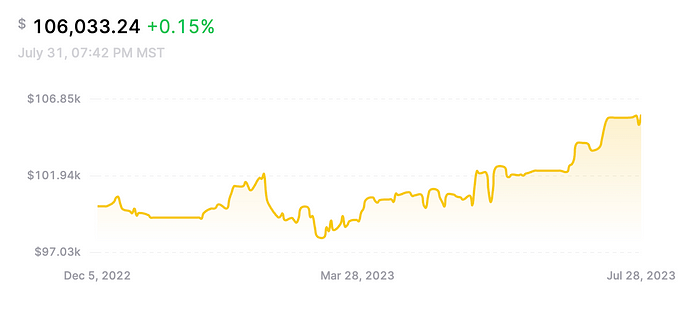
实时交易结果
相关文章:
python如何创建自己的对冲交易算法
在这篇文章中,我解释了如何创建一个人工智能来每天为我进行自动交易。 随着机器学习的现代进步和在线数据的轻松访问,参与量化交易变得前所未有的容易。为了让事情变得更好,AWS 等云工具可以轻松地将交易想法转化为真正的、功能齐全的交易机器…...
Ubuntu22.04安装,SSH无法连接
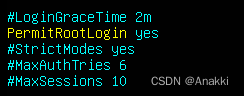
Ubuntu初始化安装后,系统默认不允许root通过ssh连接,因此需要完成三个设置 1.修改ssh配置文件 vim /etc/ssh/sshd_config 将PermitRootLogin注释打开,并将值改为yes 保存修改并退出 :wq 2.重启ssh服务 sudo service ssh restart 3.重新打…...

解决dirsearch扫描工具pkg_resources模块警告问题
一、pkg_resources模块问题 ┌──(kali㉿kali)-[~/桌面/XXX/dirsearch-master] └─$ python dirsearch.py -h /home/kali/XX/XXXX/dirsearch-master/dirsearch.py:23: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io…...
JAVA-编程基础-11-04-java IO 字符流
Lison <dreamlison163.com>, v1.0.0, 2023.05.07 JAVA-编程基础-11-04-java IO 字符流 文章目录 JAVA-编程基础-11-04-java IO 字符流字符流Reader 和 Writer字符输入流(Reader)**FileReader构造方法****FileReader读取字符数据** 字符输出流&am…...
亚马逊云代码AI助手CodeWhisperer使用教程
一、CodeWhisperer 简介 1、CodeWhisperer是一款基于机器学习的通用代码生成器,由Amazon出品,可以给我们提供代码建议。 2、CodeWhisperer 基于各种上下文线索提供建议,包括光标在源代码中的位置、位于光标前面的代码、注释,以及…...
2023全新小程序广告流量主奖励发放系统源码 流量变现系统
2023全新小程序广告流量主奖励发放系统源码 流量变现系统 分享软件,吃瓜视频,或其他资源内容,通过用户付费买会员来变现,用户需要付费,有些人喜欢白嫖,所以会流失一部分用户,所以就写了这个系统…...

最详细STM32,cubeMX外部中断
这篇文章将详细介绍 cubeMX外部中断的配置,实现过程。 文章目录 前言一、外部中断的基础知识。二、cubeMX 配置外部中断三、自动生成的代码解析四、代码实现。总结 前言 实验开发板:STM32F103C8T6。所需软件:keil5 , cubeMX 。实…...

云栖大会?全部免费!!抢先一步看!
2023云栖大会定档10月31日! 点击链接免费预约云栖门票: 2023云栖大会-领票页面 2023 云栖大会将于 10.31-11.2 在杭州云栖小镇举办,深度拥抱大数据AI 核心技术,见证阿里云大数据AI产品年度重磅发布及创新。开放融合的科技展示平…...

Linux常用的调试工具
在开发和调试Linux的过程中,经常会遇到各种各样的问题,如程序崩溃、性能低下、内存泄漏等。这时候,调试就显得尤为重要。调试技巧和工具能够帮助开发人员快速定位问题并快速解决。在本文中,我们将介绍一些常用的Linux调试技巧和工…...

PX4-Autopilot下载与编译
文章目录 1 Git clone 代码2 下载子模块3 编译4 可能遇到的问题参考 1 Git clone 代码 Github Repository 链接:PX4-Autopilot 查看现有版本: 在终端用命令下载,-b表示branch git clone -b v1.14.0 https://github.com/PX4/PX4-Autopilot.…...

关于数据可视化那些事
干巴巴的数据没人看,数据可视化才能直观展现数据要点,提升数据分析、数字化运营决策效率。那关于可视化的实现方式、技巧、工具等,你了解几分?接下来,我们就来聊聊数据可视化那些事。 1、什么是数据可视化?…...

【Java小知识点】类加载器的区别
🎄欢迎来到边境矢梦的csdn博文🎄 🎄本文主要梳理Java类加载器的区别🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以关注一下🫰ᾯ…...
分布式微服务技术栈-SpringCloud<Eureka,Ribbon,nacos>
微服务技术栈 一、微服务 介绍了解1 架构结构案例与 springboot 兼容关系拆分案例拆分服务拆分-服务远程调用 2 eureka注册中心Eureka-提供者与消费者Eureka-eureka原理分析Eureka-搭建eureka服务Eureka-服务注册Eureka-服务发现 3 Ribbon组件 负载均衡Ribbon-负载均衡原理Ribb…...

Unity解决:导出AndroidStudio工程 出现如下报错的解决方法
unity2019.4+ androidStudio2023.x+ 问题1: cvc-complex-type.2.4.a: 发现了以元素 base-extension 开头的无效内容。应以 {layoutlib} 之一开头。 解决:第一个Build.gradle更改如下 // GENERATED BY UNITY. REMOVE THIS COMMENT TO PREVENT OVERWRITING WHEN EXPORTING …...
Mac电脑怎么在Dock窗口预览,Dock窗口预览工具DockView功能介绍
DockView是一款Mac电脑上的软件,它可以增强Dock的功能,让用户更方便地管理和切换应用程序。 DockView的主要功能是在 DockQ,栏上显示每个窗口的缩略图,并提供了一些相关的操作选项。当用户将鼠标悬停在Dock栏上的应用程序图标上时…...
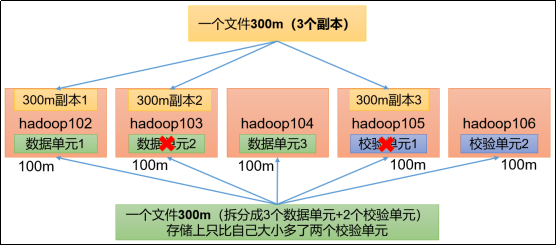
Hadoop3教程(三十):(生产调优篇)纠删码
文章目录 (155)纠删码原理纠删码原理纠删码相关命令纠删码策略解释 (156)纠删码案例实操参考文献 (155)纠删码原理 纠删码原理 默认情况下,一个文件在HDFS里会保留3个副本,以此提高…...

用nodejs爬虫台湾痞客邦相册
情景:是这样的,我想保存一些喜欢的小伙伴的照片,一张张保存太慢了, 所以我写了个js,放在国外服务器爬,国内的自己解决~ 使用方法 1.点相册随便一张, 复制url, 这张开始接下来的图片都会保存 /*** 2023年10月23日 22:58:44* 支持解析痞客邦相册* 只需要复制相册第一张图片的ur…...

物联网_01_物理设备的网络接入
设备的网络接入及物理层使用到的传输协议 现在物理设备有两种接入方式,一种是直接接入另一种是网关接入 直接接入 给物理设备添加NB-IOT通信模组等设备使之具有直接接入网络的能力 网关接入 物理设备在本地组网后通过统一的网关接入到网络(ZigBee无线组网网关).网关是处在本地…...

AD9371 官方例程之 tx_jesd 与 xcvr接口映射
AD9371 系列快速入口 AD9371ZCU102 移植到 ZCU106 : AD9371 官方例程构建及单音信号收发 AD9371 官方例程 时钟间的关系与生成 : AD9371 官方例程HDL详解之JESD204B TX侧时钟生成(一) AD9371 官方例程 时钟间的关系与生成 &…...
UserWarning: CUDA initialization: CUDA unknown error
CUDA在suspend之后不可用问题 问题描述 一觉醒来,电脑cuda不可用 /home/你的电脑/pytorch/lib/python3.8/site-packages/torch/cuda/__init__.py:107: UserWarning: CUDA initialization: CUDA unknown error - this may be due to an incorrectly set up enviro…...

OpenClaw 微信通道配置与部署速查
一、前置核查(必做)版本适配微信:iOS≥8.0.70、安卓≥8.0.69,未达标则更新至最新版。OpenClaw:需为最新稳定版,执行openclaw --version验证,异常则重新获取部署包。环境与权限网络:开…...

SGLang-v0.5.6应用:快速搭建智能客服对话系统
SGLang-v0.5.6应用:快速搭建智能客服对话系统 1. 引言 在当今企业数字化转型浪潮中,智能客服系统已成为提升服务效率和用户体验的关键工具。传统客服系统面临人力成本高、响应速度慢、服务时间受限等痛点,而基于大语言模型的智能客服解决方…...
)
收藏必备!小白入门:详解开源网络入侵检测系统(Suricata、Snort、Zeek_Bro、Security Onion)
收藏必备!小白程序员入门:详解开源网络入侵检测系统(Suricata、Snort、Zeek/Bro、Security Onion) 本文介绍了网络入侵检测系统(NIDS)和主机入侵检测系统(HIDS)的概念,重…...

版本降级实战:在VirtualBox 6.0.24中成功启用嵌套虚拟化
1. 为什么要在旧版本中启用嵌套虚拟化? 最近在调试一个遗留项目时,遇到了一个棘手的问题:客户的生产环境使用的是VirtualBox 6.0.24版本,而我们需要在这个虚拟机里再运行一个虚拟机(也就是嵌套虚拟化)。这个…...

探索LiquidPrompt插件生态系统:释放命令行提示的无限可能
探索LiquidPrompt插件生态系统:释放命令行提示的无限可能 【免费下载链接】liquidprompt A full-featured & carefully designed adaptive prompt for Bash & Zsh 项目地址: https://gitcode.com/gh_mirrors/li/liquidprompt LiquidPrompt是一款为Ba…...

AI超清画质增强实战:低分辨率图片修复,让模糊变清晰
AI超清画质增强实战:低分辨率图片修复,让模糊变清晰 1. 技术背景与核心价值 1.1 为什么需要超分辨率技术 在数字图像处理领域,我们经常遇到这样的困扰:珍贵的家庭老照片因年代久远变得模糊不清;从网络下载的图片分辨…...

OpenClaw技能组合策略:千问3.5-35B-A3B-FP8驱动复杂工作流5个案例
OpenClaw技能组合策略:千问3.5-35B-A3B-FP8驱动复杂工作流5个案例 1. 为什么需要技能组合? 去年我尝试用单一技能处理竞品分析时,发现模型生成的报告总是缺少关键数据支撑。当我手动补充爬虫结果后,又面临图表生成与多语言翻译的…...

基于YOLOV5的手势识别检测系统
基于YOLOV5的手势识别检测系统项目介绍: 软件:PycharmAnaconda 环境:python3.8 opencv_python PyQt5文件: 1.完整程序文件(.py等) 2.UI界面源文件、图标(.ui、.qrc、.py等) 3.测试图…...

2026年OpenClaw怎么部署OpenClaw接入飞书保姆级教程
2026年,OpenClaw(原Clawdbot、Moltbot,社区昵称“小龙虾”)凭借本地优先、多通道接入、插件化扩展的特性,成为企业与个人搭建AI自动化助理的首选工具。对于零基础用户而言,阿里云轻量应用服务器是部署OpenC…...

基于ip-iq变换的谐波检测算法,并联型APF/有源电力滤波器/谐波电流检测 matlab/
基于ip-iq变换的谐波检测算法,并联型APF/有源电力滤波器/谐波电流检测 matlab/ simulink仿真学习模型,其他检测方法也做了,有参考文献,适合自学。车间里变频器嗡嗡作响,流水线上的机械臂突然抽搐了两下。老师傅老张叼着…...