redis缓存问题
缓存击穿
缓存击穿是指某个热点数据存储在redis中,该数据在高并发的场景下,当该key过期时就会有大量的请求去查询数据库,对数据库的压力非常大,可能会导致数据库压垮。
解决方案
1.不为热点的key设置过期时间。
2.使用分布式锁。
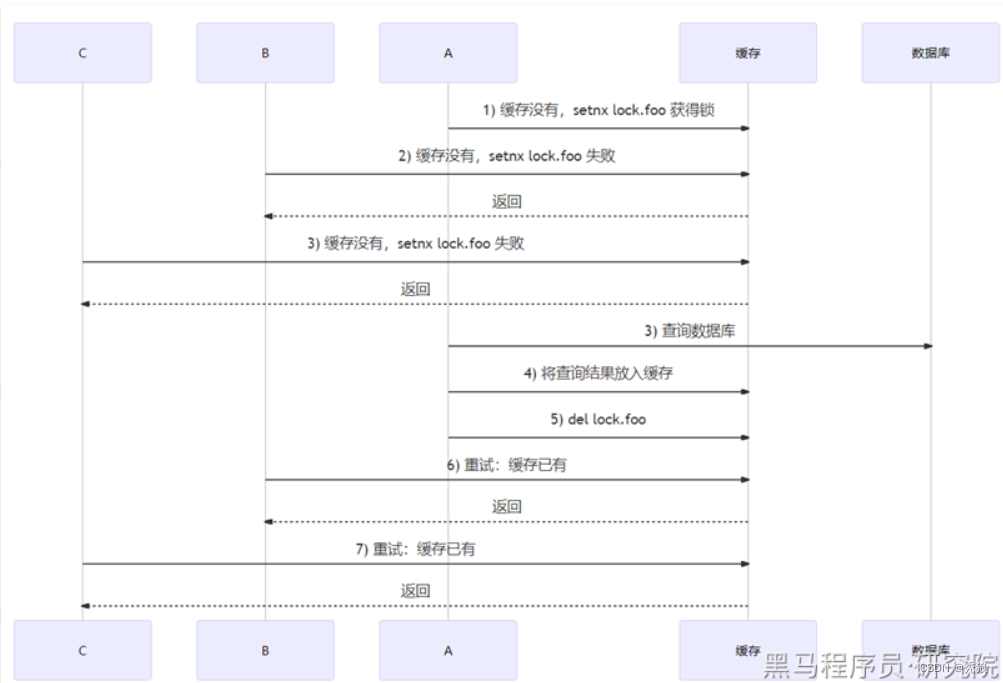
在查询数据库前需要获取锁,没有获取锁的请求会一直在重试,这样保证只有一条请求访问数据库,在该请求访问数据库后会将获得的信息重新存放到redis中,并将锁释放,在每次获取锁并访问数据库前还会再去redis中查询一次数据,这样就可以实现在第一个请求访问数据库后,后续的请求会直接从redis中查询出数据,解决了缓存击穿。
缓存雪崩
缓存雪崩存在两种情况
情况1:在redis中存的大量缓存的key设置了相同的过期时间,在这些key过期后就会大量请求访问数据库。
1情况2:redis服务宕机了,导致大量的请求访问数据库。
解决方案
情况1的解决方案
1.错开过期时间:在过期时间上添加(1~5分钟)的随机时间。
2.服务降级:停止非核心数据查询缓存,返回预定义信息。(就是实现FallbackFactory接口)
情况2的解决方案
1.搭建redis集群
2.构建二级缓存。(目前使用的就是 Caffeine作为一级缓存,redis做二级缓存)
3.熔断:通过监控一旦雪崩出现,暂停缓存访问待实例恢复,返回预定义信息。(有损方案)
4.限流:通过监控一旦数据库的访问量超出阈值,就限制访问数据库的请求数。(有损方案)
实现步骤
错开过期时间的实现为下:
自定义 MyRedisCacheManager类继承RedisCacheManager
import cn.hutool.core.util.ObjectUtil;
import cn.hutool.core.util.RandomUtil;
import org.springframework.data.redis.cache.RedisCache;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;import java.time.Duration;/*** 自定义CacheManager,用于设置不同的过期时间,防止雪崩问题的发生*/
public class MyRedisCacheManager extends RedisCacheManager {public MyRedisCacheManager(RedisCacheWriter cacheWriter, RedisCacheConfiguration defaultCacheConfiguration) {super(cacheWriter, defaultCacheConfiguration);}@Overrideprotected RedisCache createRedisCache(String name, RedisCacheConfiguration cacheConfig) {//获取到原有过期时间Duration duration = cacheConfig.getTtl();if (ObjectUtil.isNotEmpty(duration)) {//在原有时间上随机增加1~10分钟//后续使用时需要修改的就是这里的时间Duration newDuration = duration.plusMinutes(RandomUtil.randomInt(1, 11));cacheConfig = cacheConfig.entryTtl(newDuration);}return super.createRedisCache(name, cacheConfig);}
}
在RedisConfig中使用MyRedisCacheManager作自定义缓存管理器配置。
@Beanpublic RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {// 默认配置RedisCacheConfiguration defaultCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()// 设置key的序列化方式为字符串.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))// 设置value的序列化方式为json格式.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())).disableCachingNullValues() // 不缓存null.entryTtl(Duration.ofHours(redisTtl)); // 默认缓存数据保存1小时//使用自定义缓存管理器RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisTemplate.getConnectionFactory());MyRedisCacheManager myRedisCacheManager = new MyRedisCacheManager(redisCacheWriter, defaultCacheConfiguration);myRedisCacheManager.setTransactionAware(true); // 只在事务成功提交后才会进行缓存的put/evict操作return myRedisCacheManager;}缓存穿透
一个key在缓存和数据库中都不存在,这样每次查询该key都需要访问数据库。
- 很可能被恶意请求利用
- 缓存雪崩与缓存击穿都是数据库中有,但缓存暂时缺失
- 缓存雪崩与缓存击穿都能自然恢复,但缓存穿透则不能
解决方案
1. 如果数据库中没有,也将此key关联null存入缓存中,缺点就是这样的key没有作用,白白浪费空间。
2. 采用BloomFilter(布隆过滤器)解决,基本思路就是将存在数据的哈希值存储到一个足够大的Bitmap(Bit为单位存储数据,可以大大节省存储空间)中,在查询redis时,先查询布隆过滤器,如果数据不存在直接返回即可,如果存在的话,再执行缓存中命中、数据库查询等操作。(通过hash函数计算出key对应的位置,如果有值就将对应位置改为1,在后续查询redis前先从布隆过滤器中查询数据是否存在),适合用来做判断不存在的操作。
实现步骤
布隆过滤器
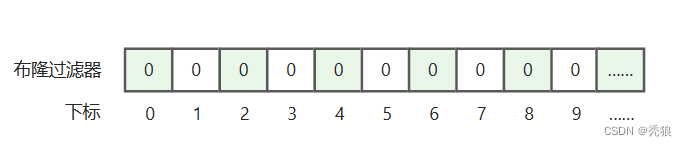
需要将数据存入布隆过滤器中,才能判断数据是否存在,存入时要通过hash算法函数计算出hash值,通过hash值确定存储的位置。
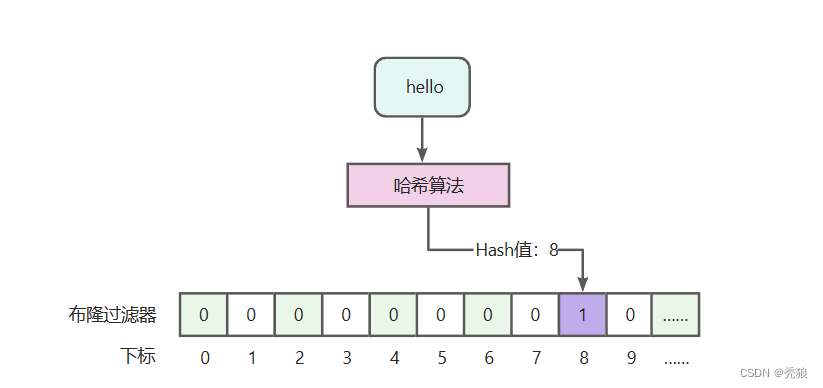 看到这里,你一定会有这样的疑问,不同的数据经过哈希算法计算,可能会得到相同的值,也就是,【张三】和【王五】可能会得到相同的hash值,会在同一个位置标记为1,这样的话,1个位置可能会代表多个数据,也就是会出现误判,没错,这个就是布隆过滤器最大的一个缺点,也是不可避免的特性。正因为这个特性,所以布隆过滤器基本是不能做删除动作的。
看到这里,你一定会有这样的疑问,不同的数据经过哈希算法计算,可能会得到相同的值,也就是,【张三】和【王五】可能会得到相同的hash值,会在同一个位置标记为1,这样的话,1个位置可能会代表多个数据,也就是会出现误判,没错,这个就是布隆过滤器最大的一个缺点,也是不可避免的特性。正因为这个特性,所以布隆过滤器基本是不能做删除动作的。
总结:使用布隆过滤器能够判断一定不存在,而不能用来判断一定存在。
为了降低误判率我们可以使用多哈希法。
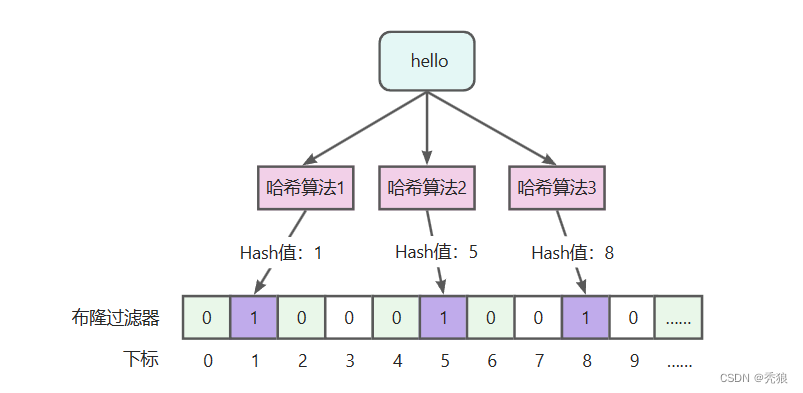 通过多个哈希算法计算参数多个位置,在这多个位置上进行标记,在后续查找时只有这多个位置同时为1时才说明存在数据,虽然降低了误判率,但误判数据存在还是存在的。
通过多个哈希算法计算参数多个位置,在这多个位置上进行标记,在后续查找时只有这多个位置同时为1时才说明存在数据,虽然降低了误判率,但误判数据存在还是存在的。
布隆过滤器的优缺点
- 优点
-
- 存储的二进制数据,1或0,不存储真实数据,空间占用比较小且安全。
- 插入和查询速度非常快,因为是基于数组下标的,类似HashMap,其时间复杂度是O(K),其中k是指哈希算法个数。
- 缺点
-
- 存在误判,可以通过增加哈希算法个数降低误判率,不能完全避免误判。
- 删除困难,因为一个位置可能会代表多个值,不能做删除。
牢记结论:布隆过滤器能够判断一定不存在,而不能用来判断一定存在 。
Redission基于Redis,使用string类型数据,生成二进制数组进行存储,最大可用长度为:4294967294。
引入依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId></dependency>设置redission配置
import cn.hutool.core.convert.Convert;
import cn.hutool.core.util.StrUtil;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.config.SingleServerConfig;
import org.springframework.boot.autoconfigure.data.redis.RedisProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.annotation.Resource;@Configuration
public class RedissonConfiguration {@Resourceprivate RedisProperties redisProperties;@Beanpublic RedissonClient redissonSingle() {Config config = new Config();SingleServerConfig serverConfig = config.useSingleServer().setAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort());if (null != (redisProperties.getTimeout())) {serverConfig.setTimeout(1000 * Convert.toInt(redisProperties.getTimeout().getSeconds()));}if (StrUtil.isNotEmpty(redisProperties.getPassword())) {serverConfig.setPassword(redisProperties.getPassword());}return Redisson.create(config);}}
自定义布隆过滤器配置
import lombok.Getter;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;/*** 布隆过滤器相关配置*/
@Getter
@Configuration
public class BloomFilterConfig {/*** 名称,默认:sl-bloom-filter*/@Value("${bloom.name:sl-bloom-filter}")private String name;/*** 布隆过滤器长度,最大支持Integer.MAX_VALUE*2,即:4294967294,默认:1千万*/@Value("${bloom.expectedInsertions:10000000}")private long expectedInsertions;/*** 误判率,默认:0.05*/@Value("${bloom.falseProbability:0.05d}")private double falseProbability;}
创建布隆过滤器的Service接口
/*** 布隆过滤器服务*/
public interface BloomFilterService {/*** 初始化布隆过滤器*/void init();/*** 向布隆过滤器中添加数据** @param obj 待添加的数据* @return 是否成功*/boolean add(Object obj);/*** 判断数据是否存在** @param obj 数据* @return 是否存在*/boolean contains(Object obj);}
编写Service的实现类
import com.sl.transport.info.config.BloomFilterConfig;
import com.sl.transport.info.service.BloomFilterService;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.stereotype.Service;import javax.annotation.PostConstruct;
import javax.annotation.Resource;@Service
public class BloomFilterServiceImpl implements BloomFilterService {@Resourceprivate RedissonClient redissonClient;@Resourceprivate BloomFilterConfig bloomFilterConfig;private RBloomFilter<Object> getBloomFilter() {return this.redissonClient.getBloomFilter(this.bloomFilterConfig.getName());}@Override@PostConstruct // spring启动后进行初始化public void init() {RBloomFilter<Object> bloomFilter = this.getBloomFilter();bloomFilter.tryInit(this.bloomFilterConfig.getExpectedInsertions(), this.bloomFilterConfig.getFalseProbability());}@Overridepublic boolean add(Object obj) {return this.getBloomFilter().add(obj);}@Overridepublic boolean contains(Object obj) {return this.getBloomFilter().contains(obj);}
}
改造Controller的查询逻辑,如果布隆过滤器中不存在直接返回即可,无需进行缓存命中。
@ApiImplicitParams({@ApiImplicitParam(name = "transportOrderId", value = "运单id")})@ApiOperation(value = "查询", notes = "根据运单id查询物流信息")@GetMapping("{transportOrderId}")public TransportInfoDTO queryByTransportOrderId(@PathVariable("transportOrderId") String transportOrderId) {//如果布隆过滤器中不存在,无需缓存命中,直接返回即可boolean contains = this.bloomFilterService.contains(transportOrderId);if (!contains) {throw new SLException(ExceptionEnum.NOT_FOUND);}TransportInfoDTO transportInfoDTO = transportInfoCache.get(transportOrderId, id -> {//未命中,查询MongoDBTransportInfoEntity transportInfoEntity = this.transportInfoService.queryByTransportOrderId(id);//转化成DTOreturn BeanUtil.toBean(transportInfoEntity, TransportInfoDTO.class);});if (ObjectUtil.isNotEmpty(transportInfoDTO)) {return transportInfoDTO;}throw new SLException(ExceptionEnum.NOT_FOUND);}新增操作的Service中将数据写入布隆过滤器中,也就是调用bloomService层的add方法
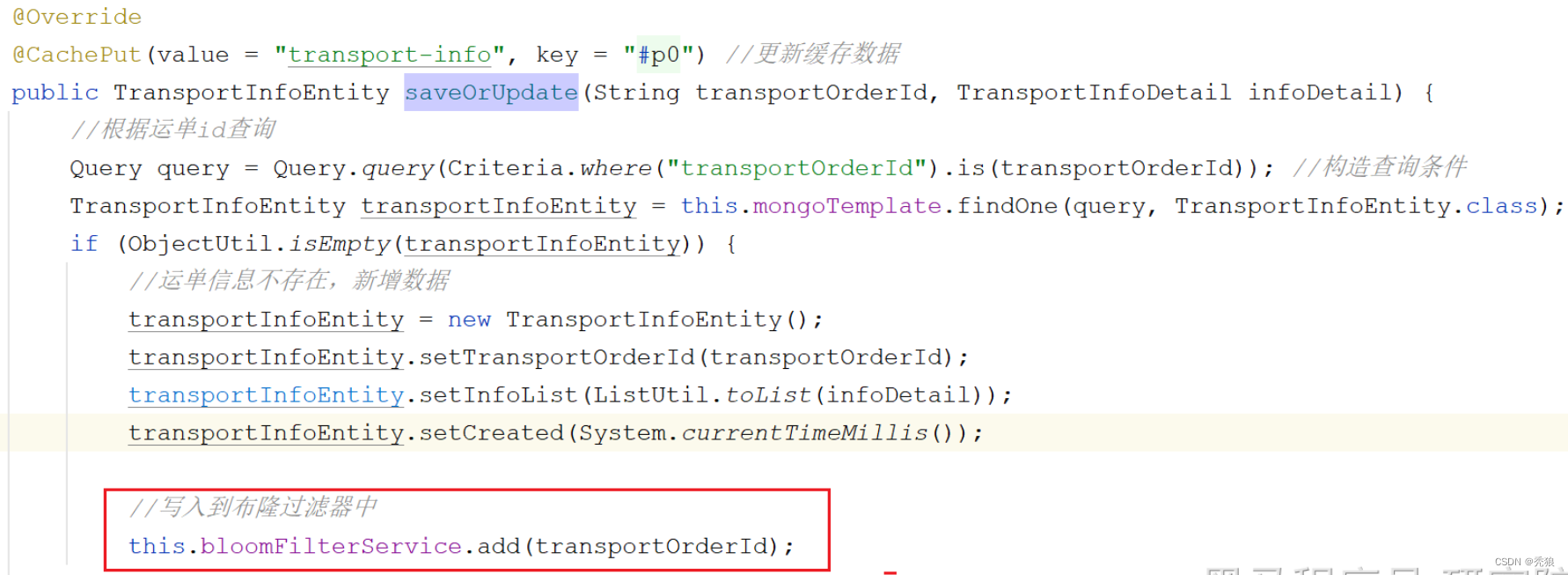
最终完成布隆过滤器的创建。
相关文章:
redis缓存问题
缓存击穿 缓存击穿是指某个热点数据存储在redis中,该数据在高并发的场景下,当该key过期时就会有大量的请求去查询数据库,对数据库的压力非常大,可能会导致数据库压垮。 解决方案 1.不为热点的key设置过期时间。 2.使用分布式锁…...

mysql创建自定义函数报错
mysql创建自定义函数报错:This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declarat… 这是我们开启了bin-log,我们就必须指定我们的函数是否是 1.DETERMINISTIC 不确定的 2.NO SQL没有sql语句,当然也不会修改数…...

Docker 的数据管理与网络通信以及Docker镜像的创建
目录 Docker的数据管理 1、数据卷 2、数据卷容器 3、端口映射 4、容器互联 二、Docker网络 1、Docker网络实现原理 2、Docker的网桥模式 1)Host 2)Container 3)none 4)bridge 5)自定义网络 3、创建自定义…...

linux系统查看bash的history
要输出最近的20条命令,可以使用history命令。在Bash终端中,输入以下命令即可获取最近的20条命令历史记录: history 20这将显示你最近执行的20条命令及其相应的行号。 要将最近的20条命令写入到一个名为 “command.txt” 的文本文件中&#…...
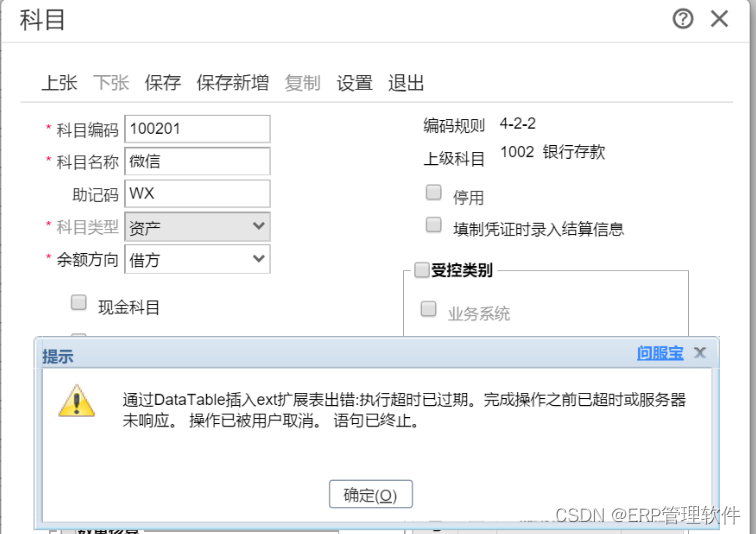
【T+】畅捷通T+增加会计科目提示执行超时已过期。
【问题描述】 在畅捷通T软件中, 增加会计科目的时候提示: 通过DataTable插入ext扩展表出错:执行超时已过期。 完成操作之前已超时或服务器未响应。 操作已被用户取消。 语句已终止。 【解决方法】 【方法一】 注销用户登录,回到软件登录界面…...
0基础学习VR全景平台篇第111篇:全景图拼接和编辑 - PTGui Pro教程
上课!全体起立~ 大家好,欢迎观看蛙色官方系列全景摄影课程! 前情回顾:上节,我们将源图像导入了PTGui,也设置好了各项参数。 下面我们就开始拼接全景图,并且在编辑器里进行一系列检查错位和设…...
Dynamics 365 使用ILMerge 合并CRM开发后的DLL
很久以前写过一篇博文,关于用ILMerge 命令合并DLL,当时时纯敲命令行的,现在有了更简单的方式,只需要在NuGet下载如下两个包 另外插件引用第三方dll的新方案Preview来了,不久的将来就不需要使用ILMerge了...

SpringBoot Web请求响应
目录 前言请求PostmanPostman使用 简单参数原始方式接收普通参数SpringBoot方式接收普通参数参数名不一致问题 实体参数简单实体参数复杂实体对象 数组集合参数数组参数集合参数 日期参数JSON参数路径参数 响应ResponseBody统一响应结果请求响应案例案例需求与准备工作案例实现…...
Jenkins CLI二次开发工具类
使用Jenkins CLI进行二次开发 使用背景 公司自研CI/DI平台,借助JenkinsSonarQube进行代码质量管理。对接版本 Jenkins版本为:Version 2.428 SonarQube版本为:Community EditionVersion 10.2.1 (build 78527)技术选型 Java对接Jenkins有第…...

2. 计算WPL
题目 Huffman编码是通信系统中常用的一种不等长编码,它的特点是:能够使编码之后的电文长度最短。 更多关于Huffman编码的内容参考教材第十章。 输入: 第一行为要编码的符号数量n 第二行~第n1行为每个符号出现的频率 输…...
筹备三年,自动驾驶L3标准将至,智驾产业链的关键一跃
作者|张祥威 编辑|德新 多位知情人士告诉HiEV,智能网联汽车准入试点通知,乐观预计将在一个月内发布。试点的推动,意味着国家层面的自动驾驶L3标准随之到来。 「L3标准内容大部分与主机厂相关,由工信部牵头,找了几家…...

【Python】Python使用Switch语句
这里写目录标题 1.使用字典(Dictionary)2.使用if-elif-else 1.使用字典(Dictionary) 在 Python 中,没有内置的 switch 语句,但可以使用其他方式来实现类似的功能。以下是两种常见的方法: 使用…...

一年一度的1024程序员节
前言 1024 程序员节是中国程序员的节日,于每年的 10 月 24 日庆祝。这个节日旨在纪念和表彰程序员对科技和社会发展所做的贡献。 1024 程序员节最早由中国互联网公司 CSDN(中国软件开发者网)发起,自然而然地成为了中国程序员社区…...

第十七章 数据库操作
数据库基础 和JDBC概论和常用类和接口就不过多的说了 直接来到 数据库的操作 一开始是在数据库中插入了四个类型 两个int 两个varchar类型 再分别插入 名字 序号 号码 性别 然后再在java中操作增删改查 这几个操作 全部代码如下 package 第十七章; import j…...
RTI-DDS代码分析使用介绍
DDS(Data Distribution Service数据分发服务)是对象管理组织OMG的有关分布式实时系统中数据发布的规范。 DDS规范采用了发布/订阅体系结构,但对实时性要求提供更好的支持。DDS是以数据为中心的发布/订阅通信模型。 以下工程基于rti_connext_dds-7.2.0 hello_world.…...

ant-design-vue 3 a-table保留选中状态
业务需求需要保留选中状态 <a-table class"satistic-table" :row-selection"{ selectedRowKeys: selectedRowKeys, onSelect:onSelect,onSelectAll:onSelectAll }" :row-key"(row)>{ return row.customerId}" :columns"columns"…...

golang 工程组件:grpc-gateway option自定义http规则
option自定义http规则和http body响应 简介 本篇接上文 golang 工程组件:grpc-gateway 环境安装默认网关测试 默认网关配置终究是难用,本篇介绍一下proto里采用option自定义http规则以及让网关返回http响应而不是我们定义的grpc响应 option定义http…...

亚马逊添加购物车和收藏有什么区别
亚马逊的添加购物车和收藏是两个不同的功能,它们在用户行为和用途上有明显的区别: 1、添加购物车(Add to Cart): 当用户点击"添加到购物车"按钮时,所选商品将被放入他们的购物车,而…...
JAVA-编程基础-11-03-java IO 字节流
Lison <dreamlison163.com>, v1.0.0, 2023.05.07 JAVA-编程基础-11-03-java IO 字节流 文章目录 JAVA-编程基础-11-03-java IO 字节流字节输出流(OutputStream)FileOutputStream类**FileOutputStrea 的构造方法**使用文件名创建FileOutputStream…...

python之Cp、Cpk、Pp、Ppk
目录 1、Cp、Cpk、Pp、Ppk 2、python计算 1、Cp、Cpk、Pp、Ppk Cp Process Capability Ratio 可被译为“过程能力指数” Cpk Process Capability K Ratio 可被译为“过程能力K指数” Pp Process Performance Ratio 可被译为“过程绩效指数” Ppk Process Performance K Ra…...

通义千问1.5-1.8B-Chat-GPTQ-Int4一键部署效果展示:低显存占用下的流畅对话体验
通义千问1.5-1.8B-Chat-GPTQ-Int4一键部署效果展示:低显存占用下的流畅对话体验 最近在尝试各种轻量级大模型本地部署,一个绕不开的痛点就是显存。动不动就十几GB的显存需求,让很多只有一张普通消费级显卡的朋友望而却步。正好,我…...

FLUX.1-dev驱动像素终端实战:API服务封装与Python脚本批量调用示例
FLUX.1-dev驱动像素终端实战:API服务封装与Python脚本批量调用示例 1. 像素幻梦工坊概述 Pixel Dream Workshop是一款基于FLUX.1-dev扩散模型的像素艺术生成终端,专为创作者设计。它采用16-bit像素风格的现代明亮界面,彻底改变了传统AI绘图…...

高效电源芯片ASP3605性能优化全解析,使用Django从零开始构建一个个人博客系统。
ASP3605电源芯片的基本特性 ASP3605是一款高效同步降压DC-DC转换器芯片,输入电压范围通常在4.5V至18V之间,输出电流能力可达5A。其开关频率可调节(300kHz至2MHz),支持轻载高效模式(如PFM)&#…...

OpenClaw+百川2-13B-4bits:智能客服模拟器搭建教程
OpenClaw百川2-13B-4bits:智能客服模拟器搭建教程 1. 为什么需要本地化客服模拟器 去年参与一个电商项目时,我遇到了一个典型痛点:每次修改客服话术都需要重新训练线上模型,既消耗API费用又影响真实客户体验。当时就萌生了搭建本…...
:仅限前500名开发者获取的11项成本基线指标)
Mojo与Python混合架构的成本可控性验证报告(内部绝密版):仅限前500名开发者获取的11项成本基线指标
第一章:Mojo与Python混合架构的成本可控性验证总览Mojo作为新兴的系统编程语言,专为AI原生开发设计,兼具Python语法亲和力与接近C的执行效率。在实际工程落地中,全量迁移至Mojo尚不现实,而采用Mojo与Python混合架构——…...

5个核心策略解决Windows更新故障
5个核心策略解决Windows更新故障 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool Windows更新是系统健康的重要保障,…...

vue3 父组件向子组件传参
vue3中父组件向子组件传递参数,核心方案是:父组件用 v-bind 绑定数据,子组件用 defineProps 接收数据(组合式 API 语法)。即:v-bind 传 (父) defineProps 收(子ÿ…...

CANoe CAPL文件读写保姆级教程:从记录测试数据到读取配置文件
CANoe CAPL文件读写实战指南:从数据记录到动态配置 在汽车电子测试领域,数据记录和参数配置的自动化程度直接影响着测试效率和可靠性。想象这样一个场景:凌晨三点的耐久性测试实验室,测试工程师需要每隔15分钟手动记录一次总线报文…...

Phimp.me性能优化实践:如何提升图片处理速度的10个技巧
Phimp.me性能优化实践:如何提升图片处理速度的10个技巧 【免费下载链接】phimpme-android Phimp.me Photo Imaging and Picture Editor https://play.google.com/store/apps/details?idorg.fossasia.phimpme 项目地址: https://gitcode.com/gh_mirrors/ph/phimpm…...
)
为什么92%的Python工程师还没掌握无锁并发?——CPython 3.13 subinterpreter实战避坑清单(含内存泄漏检测脚本)
第一章:无锁并发的底层逻辑与CPython 3.13 subinterpreter革命性意义无锁并发(Lock-Free Concurrency)并非简单地“不用锁”,而是通过原子操作(如 compare-and-swap、load-acquire/store-release)构建线程安…...