计算机视觉中的数据预处理与模型训练技巧总结
计算机视觉主要问题有图像分类、目标检测和图像分割等。针对图像分类任务,提升准确率的方法路线有两条,一个是模型的修改,另一个是各种数据处理和训练的技巧(tricks)。图像分类中的各种技巧对于目标检测、图像分割等任务也有很好的作用,因此值得好好总结。本文在精读论文的基础上,总结了图像分类任务的各种tricks如下:
-
Warmup
-
Linear scaling learning rate
-
Label-smoothing
-
Random image cropping and patching
-
Knowledge Distillation
-
Cutout
-
Random erasing
-
Cosine learning rate decay
-
Mixup training
-
AdaBoud
-
AutoAugment
-
其他经典的tricks
1. Warmup
学习率是神经网络训练中最重要的超参数之一,针对学习率的技巧有很多。Warm up是在ResNet论文[1]中提到的一种学习率预热的方法。由于刚开始训练时模型的权重(weights)是随机初始化的(全部置为0是一个坑,原因见[2]),此时选择一个较大的学习率,可能会带来模型的不稳定。学习率预热就是在刚开始训练的时候先使用一个较小的学习率,训练一些epoches或iterations,等模型稳定时再修改为预先设置的学习率进行训练。论文[1]中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个iterations),然后使用0.1的学习率进行训练。
上述的方法是constant warmup,18年Facebook又针对上面的warmup进行了改进[3],因为从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。论文[3]提出了gradual warmup来解决这个问题,即从最开始的小学习率开始,每个iteration增大一点,直到最初设置的比较大的学习率。
from torch.optim.lr_scheduler import _LRScheduler
class GradualWarmupScheduler(_LRScheduler):"""Args:optimizer (Optimizer): Wrapped optimizer.multiplier: target learning rate = base lr * multipliertotal_epoch: target learning rate is reached at total_epoch, graduallyafter_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau)"""def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None):self.multiplier = multiplierif self.multiplier <= 1.:raise ValueError('multiplier should be greater than 1.')self.total_epoch = total_epochself.after_scheduler = after_schedulerself.finished = Falsesuper().__init__(optimizer)def get_lr(self):if self.last_epoch > self.total_epoch:if self.after_scheduler:if not self.finished:self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs]self.finished = Truereturn self.after_scheduler.get_lr()return [base_lr * self.multiplier for base_lr in self.base_lrs]return [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]def step(self, epoch=None):if self.finished and self.after_scheduler:return self.after_scheduler.step(epoch)else:return super(GradualWarmupScheduler, self).step(epoch)2. Linear scaling learning rate
Linear scaling learning rate是在论文[3]中针对比较大的batch size而提出的一种方法。
在凸优化问题中,随着批量的增加,收敛速度会降低,神经网络也有类似的实证结果。随着batch size的增大,处理相同数据量的速度会越来越快,但是达到相同精度所需要的epoch数量越来越多。也就是说,使用相同的epoch时,大batch size训练的模型与小batch size训练的模型相比,验证准确率会减小。
上面提到的gradual warmup是解决此问题的方法之一。另外,linear scaling learning rate也是一种有效的方法。在mini-batch SGD训练时,梯度下降的值是随机的,因为每一个batch的数据是随机选择的。增大batch size不会改变梯度的期望,但是会降低它的方差。也就是说,大batch size会降低梯度中的噪声,所以我们可以增大学习率来加快收敛。
具体做法很简单,比如ResNet原论文[1]中,batch size为256时选择的学习率是0.1,当我们把batch size变为一个较大的数b时,学习率应该变为 0.1 × b/256。
3. Label-smoothing
在分类问题中,我们的最后一层一般是全连接层,然后对应标签的one-hot编码,即把对应类别的值编码为1,其他为0。这种编码方式和通过降低交叉熵损失来调整参数的方式结合起来,会有一些问题。这种方式会鼓励模型对不同类别的输出分数差异非常大,或者说,模型过分相信它的判断。但是,对于一个由多人标注的数据集,不同人标注的准则可能不同,每个人的标注也可能会有一些错误。模型对标签的过分相信会导致过拟合。
标签平滑(Label-smoothing regularization,LSR)是应对该问题的有效方法之一,它的具体思想是降低我们对于标签的信任,例如我们可以将损失的目标值从1稍微降到0.9,或者将从0稍微升到0.1。标签平滑最早在inception-v2[4]中被提出,它将真实的概率改造为:
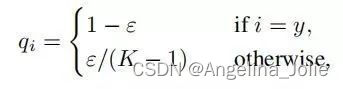
其中,ε是一个小的常数,K是类别的数目,y是图片的真正的标签,i代表第i个类别,是图片为第i类的概率。总的来说,LSR是一种通过在标签y中加入噪声,实现对模型约束,降低模型过拟合程度的一种正则化方法。
import torch
import torch.nn as nn
class LSR(nn.Module):def __init__(self, e=0.1, reduction='mean'):super().__init__()self.log_softmax = nn.LogSoftmax(dim=1)self.e = eself.reduction = reductiondef _one_hot(self, labels, classes, value=1):"""Convert labels to one hot vectorsArgs:labels: torch tensor in format [label1, label2, label3, ...]classes: int, number of classesvalue: label value in one hot vector, default to 1Returns:return one hot format labels in shape [batchsize, classes]"""one_hot = torch.zeros(labels.size(0), classes)#labels and value_added size must matchlabels = labels.view(labels.size(0), -1)value_added = torch.Tensor(labels.size(0), 1).fill_(value)value_added = value_added.to(labels.device)one_hot = one_hot.to(labels.device)one_hot.scatter_add_(1, labels, value_added)return one_hotdef _smooth_label(self, target, length, smooth_factor):"""convert targets to one-hot format, and smooththem.Args:target: target in form with [label1, label2, label_batchsize]length: length of one-hot format(number of classes)smooth_factor: smooth factor for label smoothReturns:smoothed labels in one hot format"""one_hot = self._one_hot(target, length, value=1 - smooth_factor)one_hot += smooth_factor / lengthreturn one_hot.to(target.device)4. Random image cropping and patching
Random image cropping and patching (RICAP)[7]方法随机裁剪四个图片的中部分,然后把它们拼接为一个图片,同时混合这四个图片的标签。RICAP在caifar10上达到了2.19%的错误率。
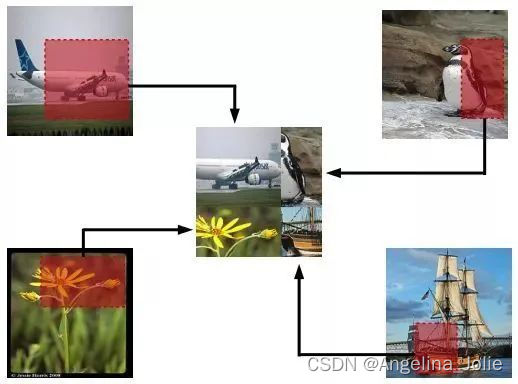
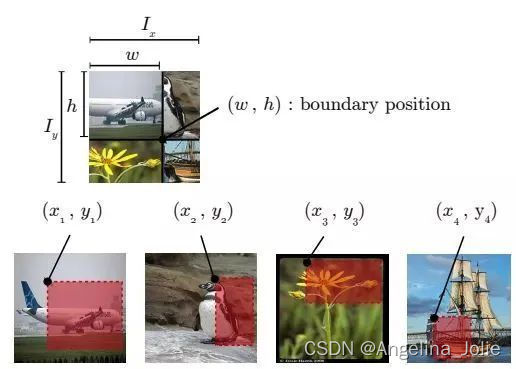
如下图所示,Ix, Iy是原始图片的宽和高。w和h称为boundary position,它决定了四个裁剪得到的小图片的尺寸。w和h从beta分布Beta(β, β)中随机生成,β也是RICAP的超参数。最终拼接的图片尺寸和原图片尺寸保持一致。
5. Knowledge Distillation
提高几乎所有机器学习算法性能的一种非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均。但是使用所有的模型集成进行预测是比较麻烦的,并且可能计算量太大而无法部署到大量用户。Knowledge Distillation(知识蒸馏)[8]方法就是应对这种问题的有效方法之一。
在知识蒸馏方法中,我们使用一个教师模型来帮助当前的模型(学生模型)训练。教师模型是一个较高准确率的预训练模型,因此学生模型可以在保持模型复杂度不变的情况下提升准确率。比如,可以使用ResNet-152作为教师模型来帮助学生模型ResNet-50训练。在训练过程中,我们会加一个蒸馏损失来惩罚学生模型和教师模型的输出之间的差异。
给定输入,假定p是真正的概率分布,z和r分别是学生模型和教师模型最后一个全连接层的输出。之前我们会用交叉熵损失l(p,softmax(z))来度量p和z之间的差异,这里的蒸馏损失同样用交叉熵。所以,使用知识蒸馏方法总的损失函数是
![]()
上式中,第一项还是原来的损失函数,第二项是添加的用来惩罚学生模型和教师模型输出差异的蒸馏损失。其中,T是一个温度超参数,用来使softmax的输出更加平滑的。实验证明,用ResNet-152作为教师模型来训练ResNet-50,可以提高后者的准确率。
6. Cutout
Cutout[9]是一种新的正则化方法。原理是在训练时随机把图片的一部分减掉,这样能提高模型的鲁棒性。它的来源是计算机视觉任务中经常遇到的物体遮挡问题。通过cutout生成一些类似被遮挡的物体,不仅可以让模型在遇到遮挡问题时表现更好,还能让模型在做决定时更多地考虑环境(context)。
import torch
import numpy as np
class Cutout(object):"""Randomly mask out one or more patches from an image.Args:n_holes (int): Number of patches to cut out of each image.length (int): The length (in pixels) of each square patch."""def __init__(self, n_holes, length):self.n_holes = n_holesself.length = lengthdef __call__(self, img):"""Args:img (Tensor): Tensor image of size (C, H, W).Returns:Tensor: Image with n_holes of dimension length x length cut out of it."""h = img.size(1)w = img.size(2)mask = np.ones((h, w), np.float32)for n in range(self.n_holes):y = np.random.randint(h)x = np.random.randint(w)y1 = np.clip(y - self.length // 2, 0, h)y2 = np.clip(y + self.length // 2, 0, h)x1 = np.clip(x - self.length // 2, 0, w)x2 = np.clip(x + self.length // 2, 0, w)mask[y1: y2, x1: x2] = 0.mask = torch.from_numpy(mask)mask = mask.expand_as(img)img = img * maskreturn img
7. Random erasing
Random erasing[6]其实和cutout非常类似,也是一种模拟物体遮挡情况的数据增强方法。区别在于,cutout是把图片中随机抽中的矩形区域的像素值置为0,相当于裁剪掉,random erasing是用随机数或者数据集中像素的平均值替换原来的像素值。而且,cutout每次裁剪掉的区域大小是固定的,Random erasing替换掉的区域大小是随机的。

from __future__ import absolute_import
from torchvision.transforms import *
from PIL import Image
import random
import math
import numpy as np
import torch
class RandomErasing(object):'''probability: The probability that the operation will be performed.sl: min erasing areash: max erasing arear1: min aspect ratiomean: erasing value'''def __init__(self, probability = 0.5, sl = 0.02, sh = 0.4, r1 = 0.3, mean=[0.4914, 0.4822, 0.4465]):self.probability = probabilityself.mean = meanself.sl = slself.sh = shself.r1 = r1def __call__(self, img):if random.uniform(0, 1) > self.probability:return imgfor attempt in range(100):area = img.size()[1] * img.size()[2]target_area = random.uniform(self.sl, self.sh) * areaaspect_ratio = random.uniform(self.r1, 1/self.r1)h = int(round(math.sqrt(target_area * aspect_ratio)))w = int(round(math.sqrt(target_area / aspect_ratio)))if w < img.size()[2] and h < img.size()[1]:x1 = random.randint(0, img.size()[1] - h)y1 = random.randint(0, img.size()[2] - w)if img.size()[0] == 3:img[0, x1:x1+h, y1:y1+w] = self.mean[0]img[1, x1:x1+h, y1:y1+w] = self.mean[1]img[2, x1:x1+h, y1:y1+w] = self.mean[2]else:img[0, x1:x1+h, y1:y1+w] = self.mean[0]return imgreturn img8. Cosine learning rate decay
在warmup之后的训练过程中,学习率不断衰减是一个提高精度的好方法。其中有step decay和cosine decay等,前者是随着epoch增大学习率不断减去一个小的数,后者是让学习率随着训练过程曲线下降。
对于cosine decay,假设总共有T个batch(不考虑warmup阶段),在第t个batch时,学习率 为:

这里,η代表初始设置的学习率。这种学习率递减的方式称之为cosine decay。
下面是带有warmup的学习率衰减的可视化图[4]。其中,图(a)是学习率随epoch增大而下降的图,可以看出cosine decay比step decay更加平滑一点。图(b)是准确率随epoch的变化图,两者最终的准确率没有太大差别,不过cosine decay的学习过程更加平滑。
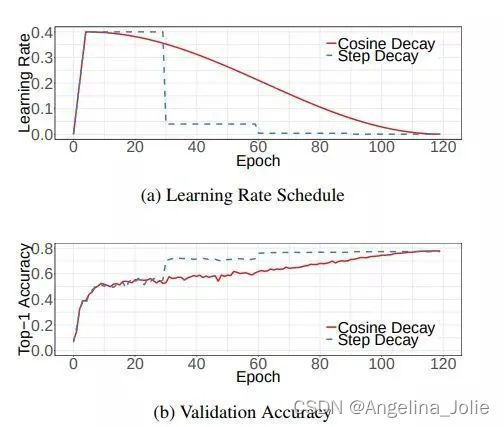
在pytorch的torch.optim.lr_scheduler中有更多的学习率衰减的方法,至于哪个效果好,可能对于不同问题答案是不一样的。对于step decay,使用方法如下:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
from torch.optim.lr_scheduler import StepLR
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):scheduler.step()train(...)validate(...)9. Mixup training
Mixup[10]是一种新的数据增强的方法。Mixup training,就是每次取出2张图片,然后将它们线性组合,得到新的图片,以此来作为新的训练样本,进行网络的训练,如下公式,其中x代表图像数据,y代表标签,则得到的新的,
。

其中,λ是从Beta(α, α)随机采样的数,在[0,1]之间。在训练过程中,仅使用( , )。
Mixup方法主要增强了训练样本之间的线性表达,增强网络的泛化能力,不过mixup方法需要较长的时间才能收敛得比较好。
for (images, labels) in train_loader:l = np.random.beta(mixup_alpha, mixup_alpha)index = torch.randperm(images.size(0))images_a, images_b = images, images[index]labels_a, labels_b = labels, labels[index]mixed_images = l * images_a + (1 - l) * images_boutputs = model(mixed_images)loss = l * criterion(outputs, labels_a) + (1 - l) * criterion(outputs, labels_b)acc = l * accuracy(outputs, labels_a)[0] + (1 - l) * accuracy(outputs, labels_b)[0]10. AdaBound
AdaBound是最近一篇论文[5]中提到的,按照作者的说法,AdaBound会让你的训练过程像adam一样快,并且像SGD一样好。如下图所示,使用AdaBound会收敛速度更快,过程更平滑,结果更好。
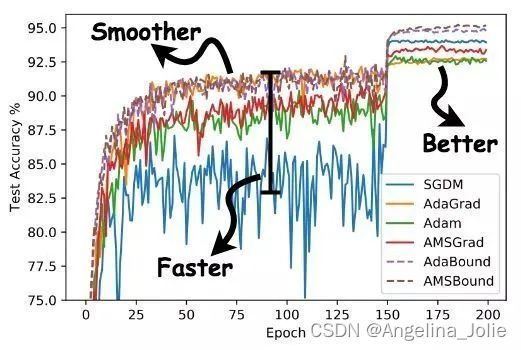
另外,这种方法相对于SGD对超参数的变化不是那么敏感,也就是说鲁棒性更好。但是,针对不同的问题还是需要调节超参数的,只是所用的时间可能变少了。
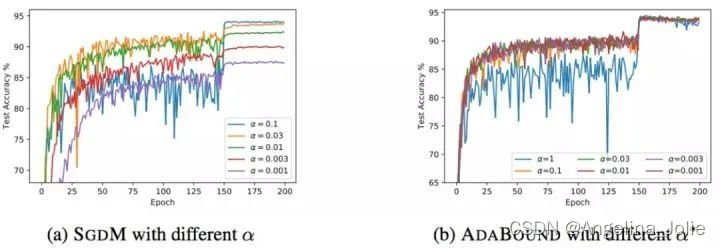
当然,AdaBound还没有经过普遍的检验,也有可能只是对于某些问题效果好。
使用方法如下:安装AdaBound
pip install adabound使用AdaBound(和其他PyTorch optimizers用法一致)
optimizer = adabound.AdaBound(model.parameters(), lr=1e-3, final_lr=0.1)11. AutoAugment
数据增强在图像分类问题上有很重要的作用,但是增强的方法有很多,并非一股脑地用上所有的方法就是最好的。那么,如何选择最佳的数据增强方法呢?AutoAugment[11]就是一种搜索适合当前问题的数据增强方法的方法。该方法创建一个数据增强策略的搜索空间,利用搜索算法选取适合特定数据集的数据增强策略。此外,从一个数据集中学到的策略能够很好地迁移到其它相似的数据集上。
12. 其他经典的tricks
常用的正则化方法为
-
Dropout
-
L1/L2正则
-
Batch Normalization
-
Early stopping
-
Random cropping
-
Mirroring
-
Rotation
-
Color shifting
-
PCA color augmentation
其他
-
Xavier init[12]
参考文献
-
[1] Deep Residual Learning for Image Recognition(https://arxiv.org/pdf/1512.03385.pdf)
-
[2] http://cs231n.github.io/neural-networks-2/
-
[3] Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour(https://arxiv.org/pdf/1706.02677v2.pdf)
-
[4] Rethinking the Inception Architecture for Computer Vision(https://arxiv.org/pdf/1512.00567v3.pdf)
-
[4]Bag of Tricks for Image Classification with Convolutional Neural Networks(https://arxiv.org/pdf/1812.01187.pdf)
-
[5] Adaptive Gradient Methods with Dynamic Bound of Learning Rate(https://www.luolc.com/publications/adabound/)
-
[6] Random erasing(https://arxiv.org/pdf/1708.04896v2.pdf)
-
[7] RICAP(https://arxiv.org/pdf/1811.09030.pdf)
-
[8] Distilling the Knowledge in a Neural Network(https://arxiv.org/pdf/1503.02531.pdf)
-
[9] Improved Regularization of Convolutional Neural Networks with Cutout(https://arxiv.org/pdf/1708.04552.pdf)
-
[10] Mixup: BEYOND EMPIRICAL RISK MINIMIZATION(https://arxiv.org/pdf/1710.09412.pdf)
-
[11] AutoAugment: Learning Augmentation Policies from Data(https://arxiv.org/pdf/1805.09501.pdf)
-
[12] Understanding the difficulty of training deep feedforward neural networks(http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf)
相关文章:
计算机视觉中的数据预处理与模型训练技巧总结
计算机视觉主要问题有图像分类、目标检测和图像分割等。针对图像分类任务,提升准确率的方法路线有两条,一个是模型的修改,另一个是各种数据处理和训练的技巧(tricks)。图像分类中的各种技巧对于目标检测、图像分割等任务也有很好的作用&#…...
GeoHash分享
写在前边 复制的一个内部分享,所以可能更偏向PPT性质,本文提出的问题,在末尾参考材料中都会有所提及,包括更深层次的实现原理和各大API对于GeoHash的优化。感兴趣的读者可以拓展看一下。 START GeoHash是一种地址编码ÿ…...

【超详细】CentOS 7安装MySQL 5.7【安装及密码配置、字符集配置、远程连接配置】
准备工作:CentOS 7系统,并确保可以联通网络 1、获取MySQL 5.7 Community Repository软件包 注意:这里使用的是root用户身份。 wget https://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm2、安装软件包 rpm -ivh mysql5…...

Elasticsearch 8.X 分词插件版本更新不及时解决方案
1、关于 Elasticsearch 8.X IK 分词插件相关问题 球友在 ElasticSearch 版本选型问题中提及:如果要使用ik插件,是不是就使用目前最新的IK对应elasticsearch的版本“8.8.2”? https://github.com/medcl/elasticsearch-analysis-ik/releases/ta…...
Delete `␍`eslintprettier/prettier
将CRLF改为LF 然后就消失了 除此之外,也可以修改git全局配置 git config --global core.autocrlf false...
4种实用的制作URL 文件的方法
很多小伙伴有自己的博客、淘宝或者共享文件网站,想要分享、推广自己的网址做成url文件,让别人点击这个url文件直接访问自己的网站。URL文件其实就一个超级链接,制作的方法很多,这里列举4种。 收藏网站直接拖拽 1.第一种…...

css总结
记录做项目经常会写到的css 1、左边导航栏固定,右边div占满剩余宽度 <template><div class"entrance"><div class"left"></div><div class"right"><div class"content"></div>…...

[C语言]排序的大乱炖——喵喵的成长记
宝子,你不点个赞吗?不评个论吗?不收个藏吗? 最后的最后,关注我,关注我,关注我,你会看到更多有趣的博客哦!!! 喵喵喵,你对我真的很重要…...

Docker 网络与Cgroup资源限制
目录 一、Docker 网络实现原理: 二、Docker 的网络模式: 三、网络模式详解: 1. host模式: 2. container模式: 3. none模式: 4.bridge模式: 5.自定义网络: 四、Cgroup资源控制: …...

D - United We Stand
思路: (1)题目要求将集合A划分为B,C两组,使得C中任意数都不是B中的除数 (2)直观感受,只要让C中数比B中大,则满足条件,不妨只取最大的放入C中; …...
【1.总纲】
目录 知识框架No.0 总纲安排No.1课程安排一、目标二、内容三、 学到 No.2 深度学习介绍一、AI地图二、图片分类三、物体检测和分割四、样式迁移五、人脸合成六、文字生成图片七、文字生成-GPT八、无人驾驶九、广告点击 No.3 安装No.3 安装 知识框架 No.0 总纲安排 B站网址&…...

I/O模型之非阻塞IO
简介 五种IO模型 阻塞IO 非阻塞IO 信号驱动IO IO多路转接 异步IO 代码书写 非阻塞IO 再次理解IO 什么是IO?什么是高效的IO? 为了理解后面的一个问题,我们首先要再重新理解一下什么是IO 在之前的网络介绍中ÿ…...
2023版 STM32实战11 SPI总线读写W25Q
SPI全称 英文全称:Serial peripheral Interface 串行外设接口 SPI特点 -1- 串行(逐bit传输) -2- 同步(共用时钟线) -3- 全双工(收发可同时进行) -4- 通信只能由主机发起(一主,多从机) 开发使用习惯和理解 -1- CS片选一般配置为软件控制 -2- 片选低电平有效,从…...
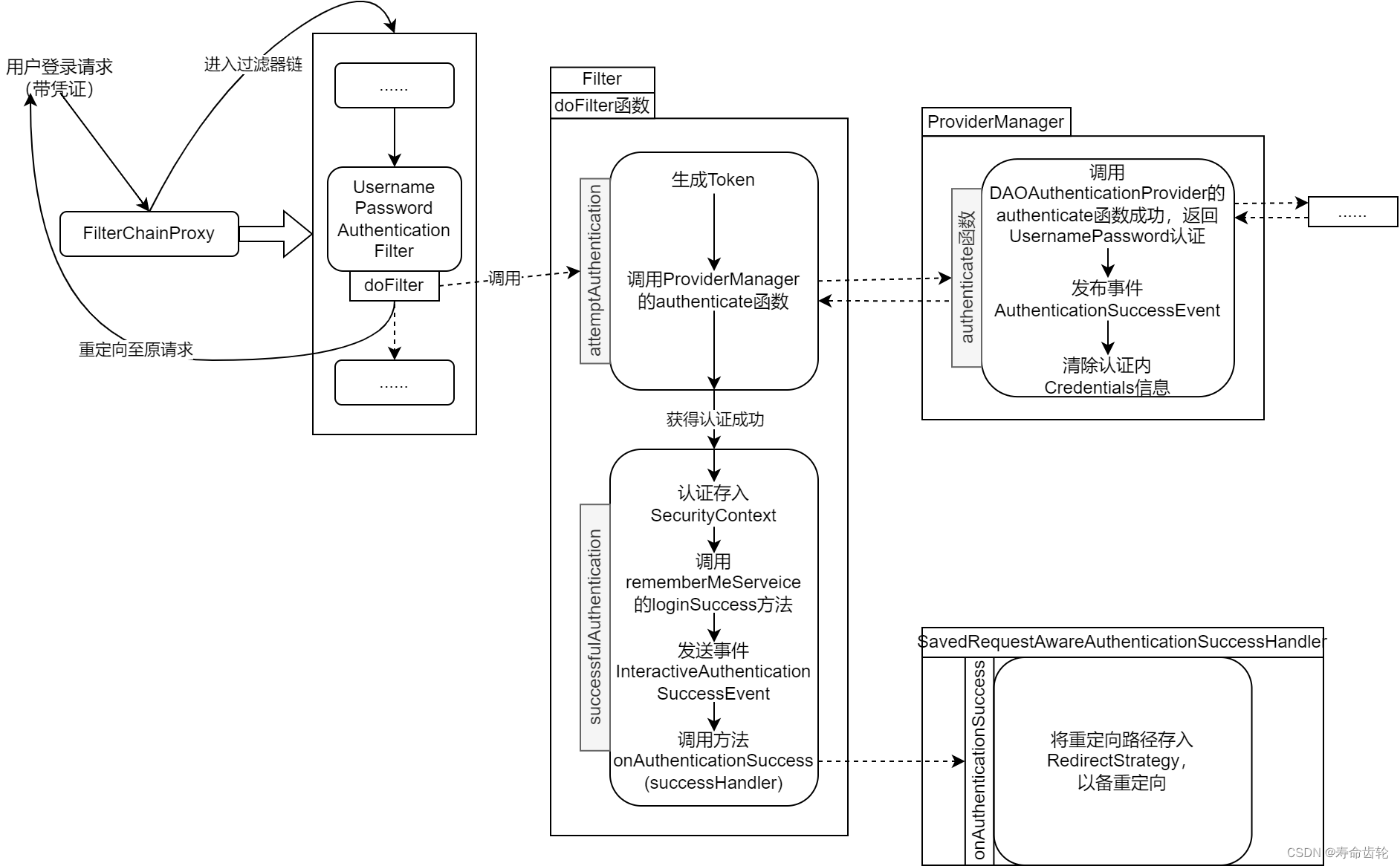
Spring Security认证源码解析(示意图)
建议先看完Spring Security总体架构介绍和Spring Security认证架构介绍,然后从FilterChainProxy的doFilterInternal函数开始,配合文章进行debug以理解Spring Security认证源码的执行流程。 在之前的Spring Security认证架构介绍中,我们已经知…...
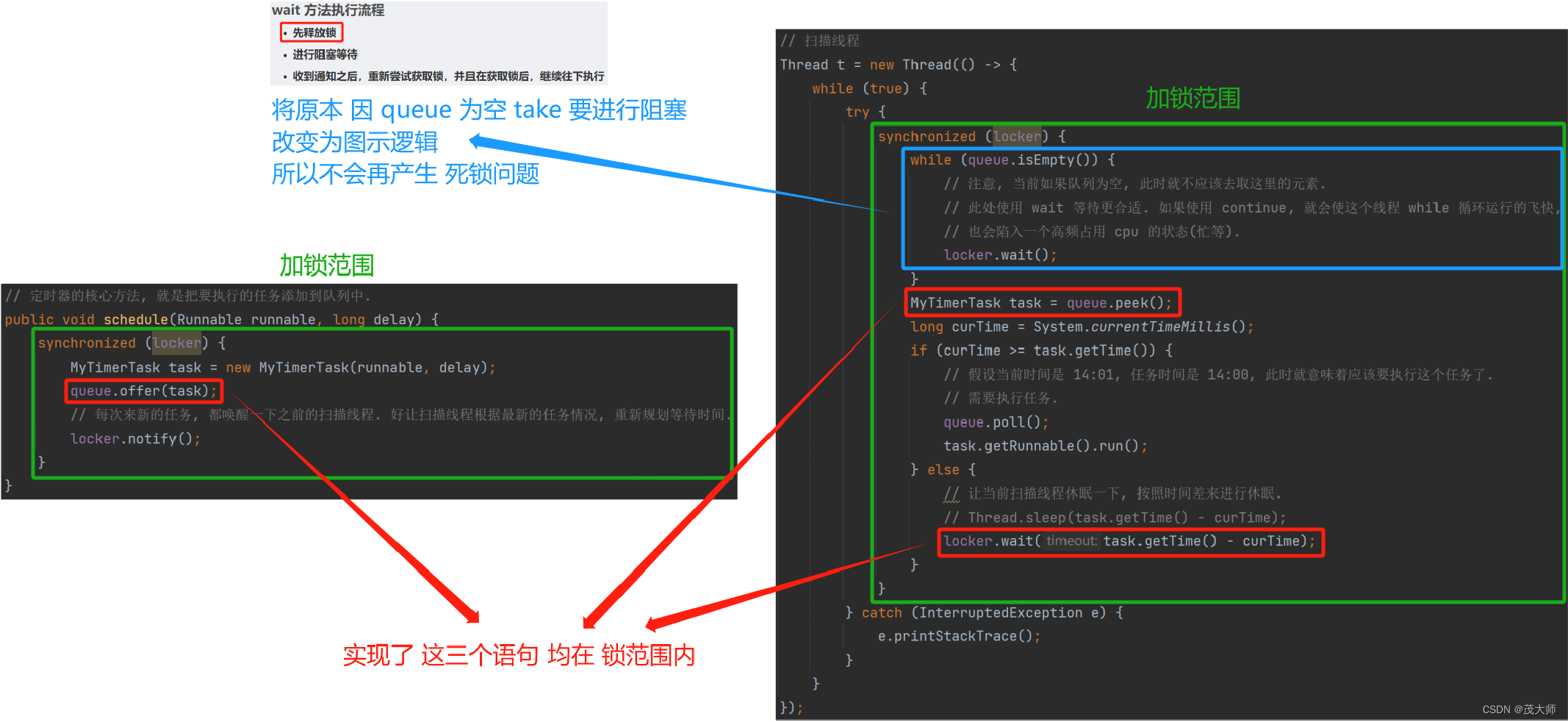
2023.10.22 关于 定时器(Timer) 详解
目录 引言 标准库定时器使用 自己实现定时器的代码 模拟实现的两大方面 核心思路 重点理解 自己实现的定时器代码最终代码版本 引言 定时器用于在 预定的时间间隔之后 执行特定的任务或操作 实例理解: 在服务器开发中,客户端向服务器发送请求&#…...
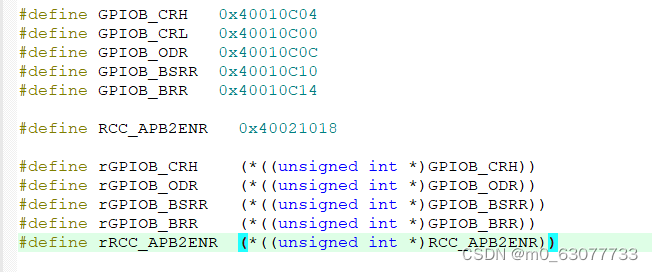
【STM32】GPIO控制LED(寄存器版)
在开始之前记得先准备好环境: STM32F103核心板下载教程.pdf 林何/STM32F103C8 - 码云 - 开源中国 (gitee.com) 一、STM32的GPIO模块数据手册详解 每个GPIO端口对应16个引脚,例GPIOA(PA0~PA15)内核cpu就可以通过APB2总线对寄存器…...

Spring Boot OAuth 2.0整合—高级配置
一、概述 HttpSecurity.oauth2Login() 为定制OAuth 2.0登录提供了大量的配置选项。主要的配置选项被分组到它们的协议端点对应处。 例如,oauth2Login().authorizationEndpoint() 允许配置授权端点,而 oauth2Login().tokenEndpoint() 允许配置令牌端点。…...

软考-虚拟专用网原理与应用
本文为作者学习文章,按作者习惯写成,如有错误或需要追加内容请留言(不喜勿喷) 本文为追加文章,后期慢慢追加 by 2023年10月 虚拟专用网概念 虚拟专用网(Virtual Private Network)是一种通过…...

clock_property 时钟的常用属性
get_property [get_clocks] property_option 1. period get_property [get_clocks] period 查询所有clock 的周期,如果存在loops会生成CTE_loops.rpt 2.clock_network_pins 查询clock所有的pins 3.generated_clocks_extended 查询clock分频产生的generate…...

平板有必要买触控笔吗?推荐的ipad手写笔
iPad之所以能吸引这么多人,主要是因为它的功能出色。用来画画、做笔记,也是一种不错的体验。但如果只是用来看电视和打游戏的话,那就真的有点大材小用了。如果你不需要昂贵的苹果电容笔,也不需要用来专业的绘图,那你可…...
)
绕过Boss直聘反爬:用Selenium+本地Chrome Profile实现稳定数据采集(附防封号心得)
企业招聘数据采集实战:基于用户行为模拟的合规解决方案 在数字化招聘时代,市场情报分析已成为企业人力资源战略的重要组成部分。许多技术团队希望通过自动化手段获取公开的招聘平台数据,用于行业人才分布分析、薪资水平调研和技能需求趋势预测…...

从混乱到智能:一家精品酒店如何通过客控系统升级实现降本增效
面对激烈的市场竞争与持续攀升的能耗成本,酒店管理者选择客控系统时,品牌与技术路线的决策直接关系到运营成败。本文将通过一个真实案例,拆解一家面临典型困境的精品酒店如何通过精准的客控系统选型与实施,实现运营效率与宾客体验…...
)
Figma+Cursor联动实战:5分钟搞定AI设计稿生成(含最新manifest导入避坑指南)
FigmaCursor联动实战:5分钟搞定AI设计稿生成(含最新manifest导入避坑指南) 在快节奏的前端开发领域,设计稿与代码的同步效率往往成为项目瓶颈。传统工作流中,设计师产出视觉稿后,开发者需要手动还原每个像素…...

工业模拟量传感器抗干扰设计与实践
1. 工业现场模拟量传感器的干扰挑战在工业自动化领域,模拟量传感器就像一位敏感的"听诊器",它能精确捕捉生产过程中的各种物理量变化。但现实中的工业环境往往充斥着各种"噪音"——大功率电机启停产生的电磁干扰、变频器工作时的谐波…...

Python主流框架全解析
以下是 Python 常用框架的分类解析:一、Web 开发框架1. Django定位:全能型框架,内置 ORM、模板引擎、路由系统等特点:开箱即用(如自带后台管理、用户认证)遵循 MVC 设计模式(MTV 变体࿰…...

【无限视距】:R3nzSkin的MOBA视野增强技术原理与实战指南
【无限视距】:R3nzSkin的MOBA视野增强技术原理与实战指南 【免费下载链接】R3nzSkin Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3n/R3nzSkin 在MOBA游戏的对抗中,视野控制往往决定战局走向。R3nzSkin…...
)
为什么你的API吞吐量卡在8k QPS?Span<T> + MemoryPool<T>组合拳让Kestrel直冲23k QPS(附压测报告)
第一章:为什么你的API吞吐量卡在8k QPS?Span<T> MemoryPool<T>组合拳让Kestrel直冲23k QPS(附压测报告)当默认 ASP.NET Core Web API 在 Kestrel 上稳定输出 8,000 QPS 时,瓶颈往往不在网络层或 CPU&…...

超越系统默认:ImageGlass如何重新定义图像浏览体验
超越系统默认:ImageGlass如何重新定义图像浏览体验 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 当你下载了一张HEIC格式的照片却无法打开,或是处…...

IAR堆栈优化实战:如何精准配置与监控嵌入式内存布局
1. 嵌入式开发中的内存管理痛点 刚入行嵌入式开发那会儿,我最怕遇到系统莫名其妙崩溃的情况。有一次做智能家居控制器项目,设备运行几天后就会死机,排查了一周才发现是线程栈溢出导致的。这种内存问题就像定时炸弹,可能在任何时候…...

NPJ Precis Oncol 重庆大学附属肿瘤医院张久权教授团队:基于纵向MRI的分形分析预测乳腺癌新辅助化疗反应
01文献学习今天分享的文献是由重庆大学附属肿瘤医院张久权教授等团队于12月12日在肿瘤学顶刊《npj Precision Oncology》(中科院1区top,IF8)上发表的研究“Fractal analysis of longitudinal MRI for predicting response to neoadjuvant che…...