es : java 查询
1. POM 配置
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.6.2</version></dependency>2. 建立ES集群连接
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost(IP, PORT, "http")));同样,如果我们要连接集群中多个ES节点时,只需要在RestClient 的 builder 方法中多添加几个HttpPost对象即可
String ipPort = "10.xx:9200,10.xx:9200,10.xx:9200";
String[] ipPortArry = ipPort.split(",");
List<HttpHost> httpHostsList = new ArrayList();for(String ips : ipPortArry){String[] ipArray = ips.split(":");httpHostsList.add(new HttpHost(ipArray[0], Integer.parseInt(ipArray[1]), "http"));}RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(httpHostsList.toArray(new HttpHost[httpHostsList.size()])));补充:
Java配置多个ES节点时,请求的时候会随机选一个节点作为协调节点负责分发请求和处理结果,所以Java链接ES节点数量的多少,不会影响到Java请求ES查询结果的速度,只是其中某个节点宕机时,其他节点可以保证正常的查询和操作。ES 端口9200与9300的区别:
9200作为Http协议,主要用于外部通讯
9300作为Tcp协议,jar之间就是通过tcp协议通讯
ES集群之间是通过9300进行通讯
3. 简单的查询并获取查询结果
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));SearchRequest searchRequest = new SearchRequest("my_index");
//或者
/*SearchRequest searchRequest = new SearchRequest();searchRequest.indices("my_index");
*/SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//配置source源字段过虑,1显示的,2排除的
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","description"},new String[]{});searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
//获取所有搜索结果、总匹配数量SearchHits hits = searchResponse.getHits();long totalHits = hits.getTotalHits(); //如果总是超过1万, index没有设置,则返回1万SearchHit[] searchHits = hits.getHits();//遍历结果for(SearchHit searchHit:searchHits){String index = searchHit.getIndex();String type = searchHit.getType();String id = searchHit.getId();float score = searchHit.getScore();String sourceAsString = searchHit.getSourceAsString();Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();String name = (String) sourceAsMap.get("name");String studymodel = (String) sourceAsMap.get("studymodel");String description = (String) sourceAsMap.get("description");System.out.println(name);System.out.println(studymodel);System.out.println(description);}//关闭链接
client.close()es的dsl: {"query": {"match_all": {}},"_source" : ["name","studymodel","description"]
}4. 使用es的json 拼接查询语句
StringBuffer dsl = new StringBuffer();dsl.append("{\"bool\": {");dsl.append(" \"must\": [");dsl.append(" {");dsl.append(" \"term\": {");dsl.append(" \"mdid.keyword\": {");dsl.append(" \"value\": \"2fa9d41e1af460e0d47ce36ca8a98737\"");dsl.append(" }");dsl.append(" }");dsl.append(" }");dsl.append(" ]");dsl.append(" }");dsl.append("}");SearchRequest searchRequest = new SearchRequest();searchRequest.indices("my_index");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(ueryBuilders.wrapperQuery(dsl.toString()));
//配置source源字段过虑,1显示的,2排除的
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","description"},new String[]{});searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
5. query
5.0 QueryBuilders转换为JSON字符串,方便调试
QueryBuilder query = QueryBuilders.termQuery("name", "John");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(query);String json = sourceBuilder.toString();
System.out.println(json);
并将其转换为JSON字符串
toString()方法返回的字符串是格式化的,可以在控制台中方便地查看和调试。5.1 Term Query
{"query": {"term" : {"name": "spring"}},"_source" : ["name","studymodel"]}SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("name","spring"));
searchSourceBuilder.fetchSource(new String[]{"name","studymodel","description"}, new String[]{});5.2 terms query ES提供根据多个id值匹配的方法
{"query": {"terms": {"systemAssignedTo.keyword": ["1","2"]}}
}select * from mr_zcy where systemAssignedTo in ('1','2')SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String[] ids = {"1", "2"};
searchSourceBuilder.query(QueryBuilders.termsQuery("systemAssignedTo.keyword",ids));5.3 match query (匹配单个字段)
{"query": {"match": {"name": {"query": "spring开发","operator": "or"}}},"_source" : ["name"]}
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name","spring开发").operator(Operator.OR));
searchSourceBuilder.fetchSource(new String[]{"name"}, new String[]{});
5.4 minimum_should_match
{"query": {"match": {"description": {"query": "spring开发框架","minimum_should_match": "80%"}}}}
spring开发框架 会被分为三个词:spring、开发、框架设置 minimum_should_match:80% 表示,三个词在文档的匹配占比为 80%,即 3 * 0.8=2.4,向上取整得2,表示至少有 两个词 在文档中要匹配成功。searchSourceBuilder.query(QueryBuilders.matchQuery("description","spring开发框架").minimumShouldMatch("80%"));
5.5 multi query (匹配多个字段)
{"query": {"multi_match": {"query": "spring框架","minimum_should_match": "50%","fields": ["name^10","description"]}}}
拿关键字 spring css去匹配 name 和 description 字段。
name^10 表示权重提升 10 倍,执行上边的查询,发现 name 中包括 spring 关键字的文档排在前边
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架", "name", "description").minimumShouldMatch("50%");
multiMatchQueryBuilder.field("name",10);
searchSourceBuilder.query(multiMatchQueryBuilder);
5.6 布尔查询
{"_source": ["name","studymodel","description"],"from": 0,"size": 1,"query": {"bool": {"must": [{"multi_match": {"query": "spring框架","minimum_should_match": "50%","fields": ["name^10","description"]}},{"term": {"studymodel": "201001"}}]}}}//创建multiMatch查询
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架", "name", "description").minimumShouldMatch("50%");multiMatchQueryBuilder.field("name",10);//创建term查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("studymodel", 201001);//创建布尔查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(multiMatchQueryBuilder);
boolQueryBuilder.must(termQueryBuilder);
5.7 过滤器
{"_source": ["name","studymodel","description","price"],"query": {"bool": {"must": [{"multi_match": {"query": "spring框架","minimum_should_match": "50%","fields": ["name^10","description"]}}],"filter": [{"term": {"studymodel": "201001"}},{"range": {"price": {"gte": 60,"lte": 100}}}]}}}SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//创建multiMatch查询
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("spring框架", "name", "description").minimumShouldMatch("50%");multiMatchQueryBuilder.field("name",10);//布尔查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(multiMatchQueryBuilder);//过虑条件
boolQueryBuilder.filter(QueryBuilders.termQuery("studymodel", "201001"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(60).lte(100));
searchSourceBuilder.query(boolQueryBuilder);
5.8 排序
可以在字段上添加一个或多个排序,支持在 keyword、date、float 等类型上添加,text 类型的字段上不允许添加排序。
{"_source": ["name","studymodel","description","price"],"query": {"bool": {"filter": [{"range": {"price": {"gte": 0,"lte": 100}}}]}},"sort": [{"studymodel": "desc"},{"price": "asc"}]}SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//boolQuery搜索方式//定义一个boolQuery
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//定义过虑器boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100));searchSourceBuilder.query(boolQueryBuilder);//添加排序searchSourceBuilder.sort("studymodel", SortOrder.DESC);searchSourceBuilder.sort("price", SortOrder.ASC);searchSourceBuilder.fetchSource(new String[]{"name","studymodel","description"}, new String[]{});//向搜索请求对象中设置搜索源searchRequest.source(searchSourceBuilder);
5.9 高亮
public void testHighlight() throws IOException, ParseException {//搜索请求对象SearchRequest searchRequest = new SearchRequest("xc_course");//指定类型searchRequest.types("doc");//搜索源构建对象SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//boolQuery搜索方式//先定义一个MultiMatchQueryMultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("开发框架", "name", "description").minimumShouldMatch("50%").field("name", 10);//定义一个boolQueryBoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(multiMatchQueryBuilder);//定义过虑器boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(0).lte(100));searchSourceBuilder.query(boolQueryBuilder);//设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段searchSourceBuilder.fetchSource(new String[]{"name","studymodel","price","timestamp"},new String[]{});//设置高亮HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.preTags("<tag>");highlightBuilder.postTags("</tag>");highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
// highlightBuilder.fields().add(new HighlightBuilder.Field("description"));searchSourceBuilder.highlighter(highlightBuilder);//向搜索请求对象中设置搜索源searchRequest.source(searchSourceBuilder);//执行搜索,向ES发起http请求SearchResponse searchResponse = client.search(searchRequest);//搜索结果SearchHits hits = searchResponse.getHits();//匹配到的总记录数long totalHits = hits.getTotalHits();//得到匹配度高的文档SearchHit[] searchHits = hits.getHits();//日期格式化对象SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");for(SearchHit hit:searchHits){//文档的主键String id = hit.getId();//源文档内容Map<String, Object> sourceAsMap = hit.getSourceAsMap();//源文档的name字段内容String name = (String) sourceAsMap.get("name");//取出高亮字段Map<String, HighlightField> highlightFields = hit.getHighlightFields();if(highlightFields!=null){//取出name高亮字段HighlightField nameHighlightField = highlightFields.get("name");if(nameHighlightField!=null){Text[] fragments = nameHighlightField.getFragments();StringBuffer stringBuffer = new StringBuffer();for(Text text:fragments){stringBuffer.append(text);}name = stringBuffer.toString();}}//由于前边设置了源文档字段过虑,这时description是取不到的String description = (String) sourceAsMap.get("description");//学习模式String studymodel = (String) sourceAsMap.get("studymodel");//价格Double price = (Double) sourceAsMap.get("price");//日期Date timestamp = dateFormat.parse((String) sourceAsMap.get("timestamp"));System.out.println(name);System.out.println(studymodel);System.out.println(description);}}
5.10 聚合
#聚合搜索 address 中包含 mill 的所有人的年龄分布以及平均薪资
GET bank/_search
{"query":{"match": {"address": "mill"}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 10}},"balanceAvg":{"avg":{"field": "balance"}}},"size": 0
}SearchRequest searchRequest = new SearchRequest();
//指定索引
searchRequest.indices("bank");//指定DSL 检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
//按照年龄只分布进行聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);searchSourceBuilder.aggregation(ageAgg);
//计算平均薪资
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("blance");
searchSourceBuilder.aggregation(balanceAvg);//打印检索条件
System.out.println("检索条件:"+searchSourceBuilder);
searchRequest.source(searchSourceBuilder);
//执行检索
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit: searchHits){String sourceAsString = hit.getSourceAsString();Accout accout = JSON.parseObject(sourceAsString, Accout.class);System.out.println(accout.toString());
}
//获取检索的分析信息
Aggregations aggregations = search.getAggregations();
// for (Aggregation aggregation : aggregations.asList()) {
// System.out.println("当前聚合名字:"+aggregation.getName());
// }
//分类聚合
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {String keyAsString = bucket.getKeyAsString();System.out.println("年龄:" + keyAsString + "人数:"+bucket.getDocCount());
}
//平局值
Avg balanceAvg1 = aggregations.get("balanceAvg");
System.out.println("平均薪资"+ balanceAvg1.getValue());6.分页查询
6.1 from,size
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//分页查询,设置起始下标,从0开始
searchSourceBuilder.from(0);
//每页显示个数
searchSourceBuilder.size(10);
//source源字段过虑
searchSourceBuilder.fetchSource(new String[]{"name","studymodel"}, new String[]{});
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest);
6.2 searchAfter
searchSourceBuilder.query(QueryBuilders.wrapperQuery(dsl.toString()));
searchSourceBuilder.size(10);
searchSourceBuilder.sort("id", SortOrder.ASC);
searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] searchHits = searchResponse.getHits().getHits();while (searchHits.length > 0) {SearchHit last = searchHits[searchHits.length - 1];sourceBuilder.searchAfter(last.getSortValues());searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);searchHits = searchResponse.getHits().getHits();}
6.3 Scroll分页
Elasticsearch-Scroll分页-Java示例-CSDN博客
searchSourceBuilder.query(QueryBuilders.wrapperQuery(dsl.toString()));
searchSourceBuilder.size(10);
searchSourceBuilder.sort("id", SortOrder.ASC);searchRequest.source(searchSourceBuilder);
// 指定超时时间
searchRequest.scroll(new TimeValue(5000));SearchResponse searchResponse = highLevelClient.search(searchRequest, RequestOptions.DEFAULT);long length = searchResponse.getHits().getHits().length;
String scrollId = null;
while (length > 0) {consumer.accept(searchResponse);scrollId = searchResponse.getScrollId();SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId).scroll(keepAlive);searchResponse = highLevelClient.scroll(scrollRequest, RequestOptions.DEFAULT);length = searchResponse.getHits().getHits().length;
}// 清空快照记录,避免内存占用if (isClearScroll && scrollId != null) {ClearScrollRequest clearScrollRequest = new ClearScrollRequest();clearScrollRequest.addScrollId(scrollId);highLevelClient.clearScrollAsync(clearScrollRequest, RequestOptions.DEFAULT, new ActionListener<ClearScrollResponse>() {@Overridepublic void onResponse(ClearScrollResponse clearScrollResponse) {}@Overridepublic void onFailure(Exception e) {throw new ElasticsearchException(e);}});}相关文章:

es : java 查询
1. POM 配置 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.6.2</version></dependency> 2. 建立ES集群连接 RestHighLevelClient cli…...
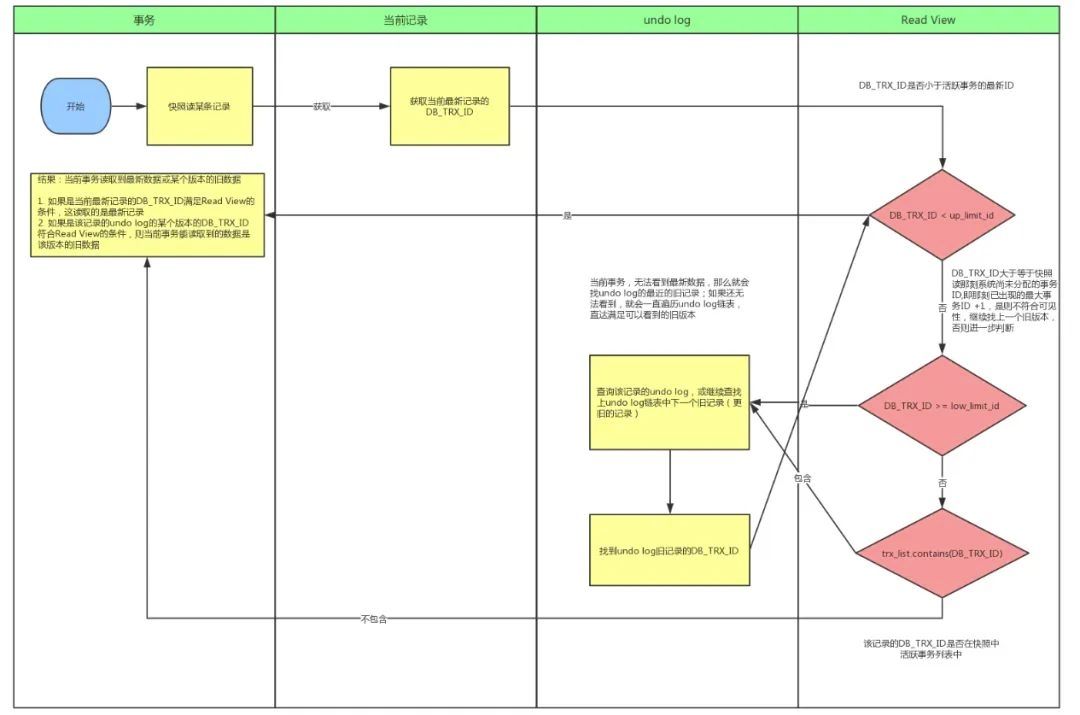
MySQL MVCC机制探秘:数据一致性与并发处理的完美结合,助你成为数据库高手
一、前言 在分析 MVCC 的原理之前,我们先回顾一下 MySQL 的一些内容以及关于 MVCC 的一些简单介绍。(注:下面没有特别说明默认 MySQL 的引擎为 InnoDB ) 1.1 数据库的并发场景 数据库并发场景有三种,分别是: 读-读…...
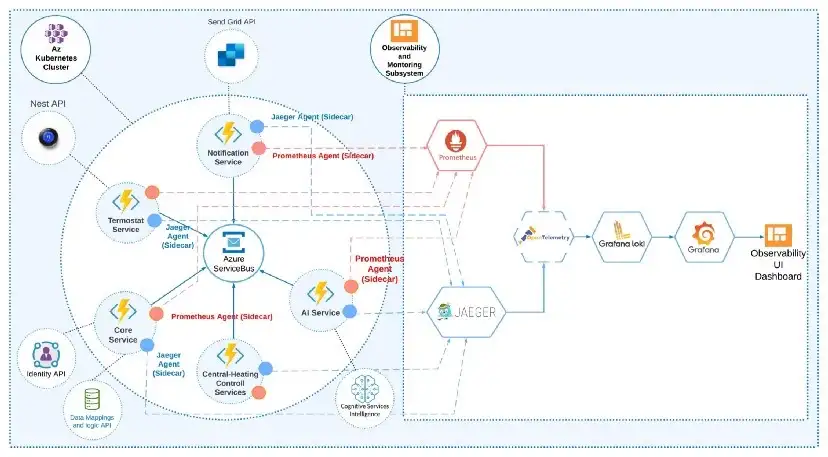
5分钟搞懂分布式可观测性
可观测性是大规模分布式(微服务)系统的必要组件,没有可观测系统的支持,监控和调试分布式系统将是一场灾难。本文讨论了可观测系统的主要功能,并基于流行的开源工具搭建了一套可观测系统架构。原文: A Primer on Distributed Systems Observab…...

桥梁结构健康监测系统落地方案
桥梁结构健康监测的意义是多方面的。首先,它可以实时采集桥梁的结构数据,并对其进行处理和分析,以确定结构损伤的位置、评估桥梁的健康状况,并预测承载力的发展趋势。这有助于及时发现桥梁的结构问题和潜在风险,为采取…...

hive和presto的求数组长度函数区别及注意事项
1、任务 获取邮箱字符串’后字符串 ,求长度 2、hive & spark-sql 求数组长度的函数 size hive & spark-sql 求数组长度的函数 sizeselect size(split(email, )),split(email, ),split(email, )[0],split(email, )[1] FROM (select "jack126.com"…...

Kotlin Lambda表达式与标准库中的高阶函数
在Kotlin中,Lambda表达式和标准库中的高阶函数为我们提供了一种简洁而强大的方式来处理集合和执行各种操作。本篇博客将介绍Lambda表达式的基本概念,并结合标准库中的高阶函数示例,展示它们的用法和功能。 Lambda表达式的基本概念 Lambda表…...
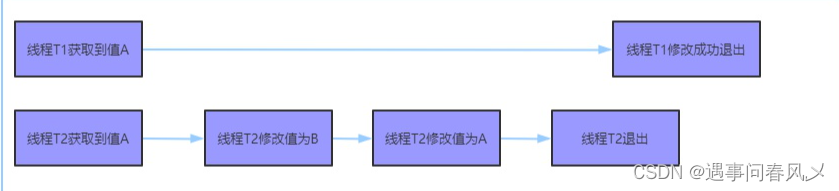
【JavaEE初阶】 CAS详解
文章目录 🌲什么是 CAS🚩CAS伪代码 🎋CAS 是怎么实现的🌳CAS的应用🚩实现原子类🚩实现自旋锁 🎄CAS 的 ABA 问题🚩什么是 ABA 问题🚩ABA 问题引来的 BUG🚩解决…...

Docker镜像制作
目录 Dockfile是什么 构建镜像的三个步骤 dockerfile内容基础知识 docker执行一个Dockerfile脚本的大致流程 Dockerfile指令 FROM MAINTAINER RUN EXPOSE WORKDIR ENV ADD COPY VOLUME USER ONBUILD CMD ENTRYPOINT CMD和ENTRYPOINT区别 构建dockerfile Do…...

v-on 可以监听多个方法吗?
目录 编辑 前言:Vue 3 中的 v-on 指令 详解:v-on 指令的基本概念 用法:v-on 指令监听多个方法 解析:v-on 指令的优势和局限性 优势 局限性 **v-on 指令的最佳实践** - **适度监听**: - **方法抽离**&#x…...
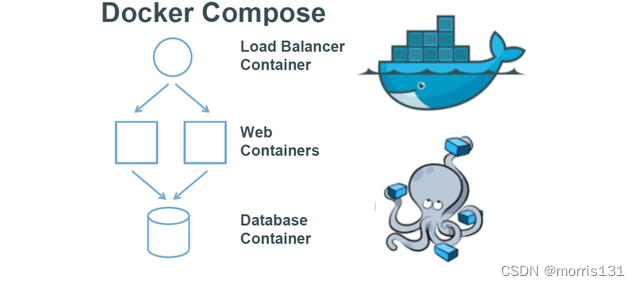
【Docker】Docker Compose的使用
我们知道使用一个Dockerfile模板文件,可以让用户很方便的定义⼀个单独的应用容器。然而,在日常工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。 例如要实现一个Web项目,除了Web服务容器本身,往往还需要…...
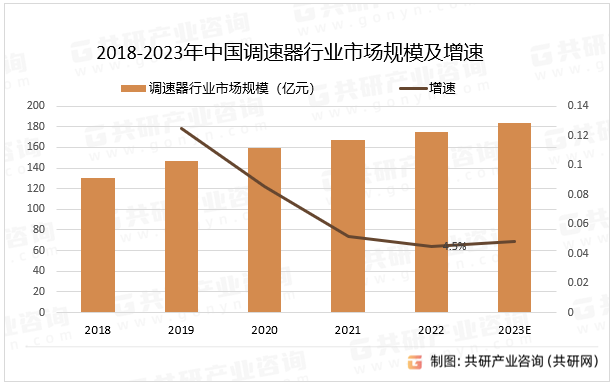
2023年中国调速器产量、销量及市场规模分析[图]
调速器行业是指生产、销售和维修各种调速器设备的行业。调速器是一种能够改变机械传动系统输出转速的装置,通过调整输入和输出的转速比来实现转速调节的功能。 调速器行业分类 资料来源:共研产业咨询(共研网) 随着工业自动化程度…...

深入了解JVM调优:解锁Java应用程序性能的秘诀
文章目录 🍊 JVM调优🎉 增大Eden 空间大小🎉 如果MinorGC 频繁,且容易引发 Full GC📝 S1 区大小 < MGC 存活的对象大小,对象的年龄才1岁📝 相同年龄的对象所占总空间大小>s1区空间大小的一…...

[java进阶]——线程池的使用,自定义线程池
🌈键盘敲烂,年薪30万🌈 目录 一、线程池的存在意义 二、线程池的使用 2.1线程池的核心原理 2.2线程池的代码实现 三、自定义线程池 3.1线程池的参数详解 3.2线程池的执行原理 3.3灵魂两问 3.4线程池多大合适 3.5拒绝策略 一、线程池…...
Linux 进程切换与命令行参数
假设进程1现在要切走了,切入进程2.那进程1就要先保存数据,方便以后恢复, 然后进程2再切走,进程1再把数据还原: 操作系统又分为实时操作系统和分时操作系统。 实时操作系统是是给操作系统一个进程,操作系统…...

Python基础入门例程6-NP6 牛牛的小数输出
目录 描述 输入描述: 输出描述: 示例1 解答: 说明: 描述 牛牛正在学习Python的输出,他想要使用print函数控制小数的位数,你能帮助它把所有读入的数据都保留两位小数输出吗? 输入描述&a…...

传奇游戏常见问题解决办法
GEE合区出现错误常规解决方案 GEE合区出现错误大部分因数据库损坏导致的合区报错,如果合区提示内存不足,更新64位合区,使用64位合区工具在服务器上进行合并,合区需要将2个区数据大部分提取到内存中,32位合区工具支持内…...

2310D的dll问题
原文 我正在开发一个游戏引擎,偶然发现了一些空针问题. 考虑此简单程序: class Test {void doIt(){} } void main() {Test t;t.doIt(); }它编译,然后在Linux上使用DMD时,用11信号干掉了. 如果使用Java,甚至不会构建该程序,因为它会失败,说明从未初化它. 但我不关心分析器,我宁…...

包管理工具
代码共享方案 放到npm仓库,下载到本地放到node_modules npm配置文件 必须填写的属性:name、version name是项目的名称; version是当前项目的版本号; description是描述信息,很多时候是作为项目的基本描述;…...
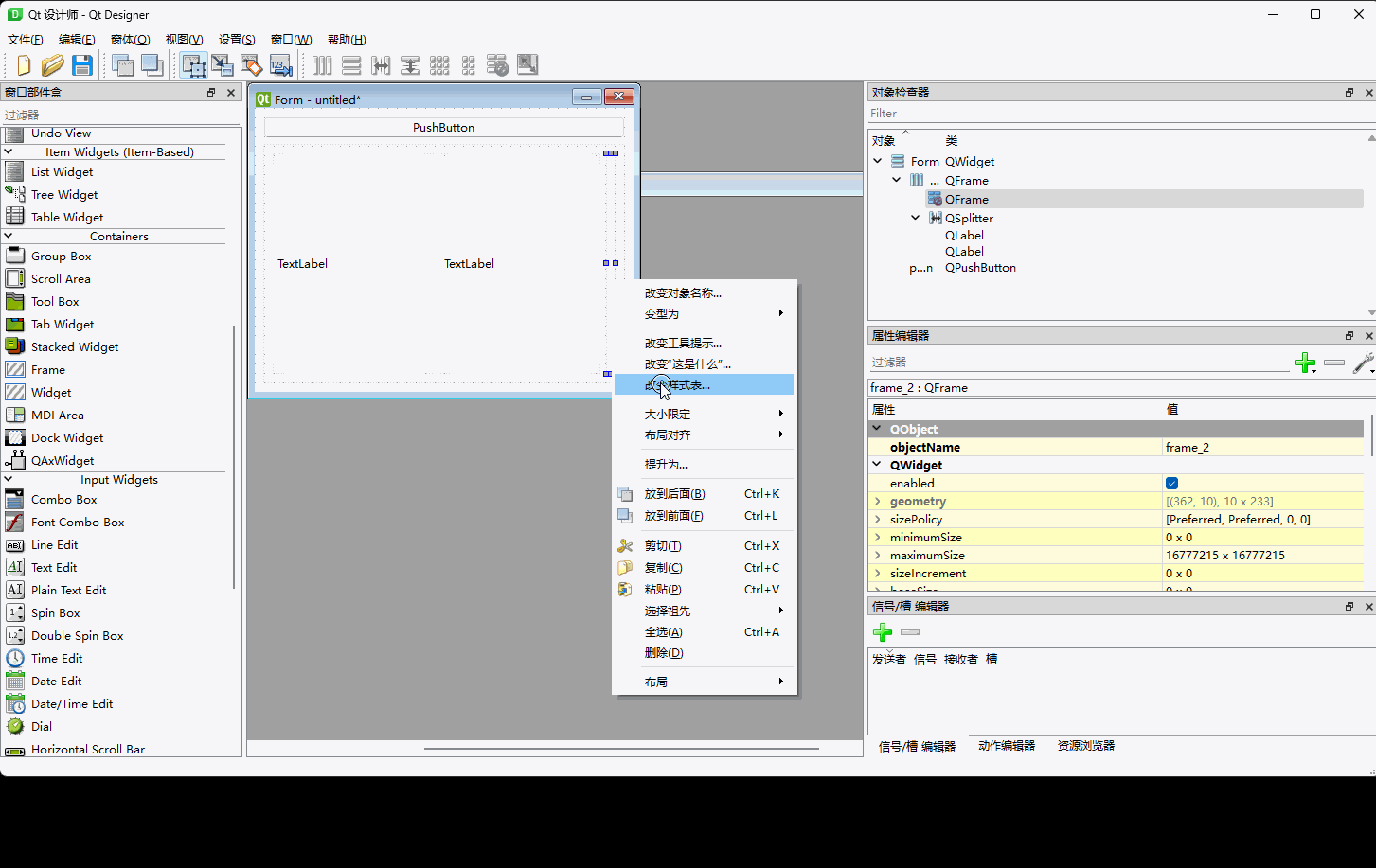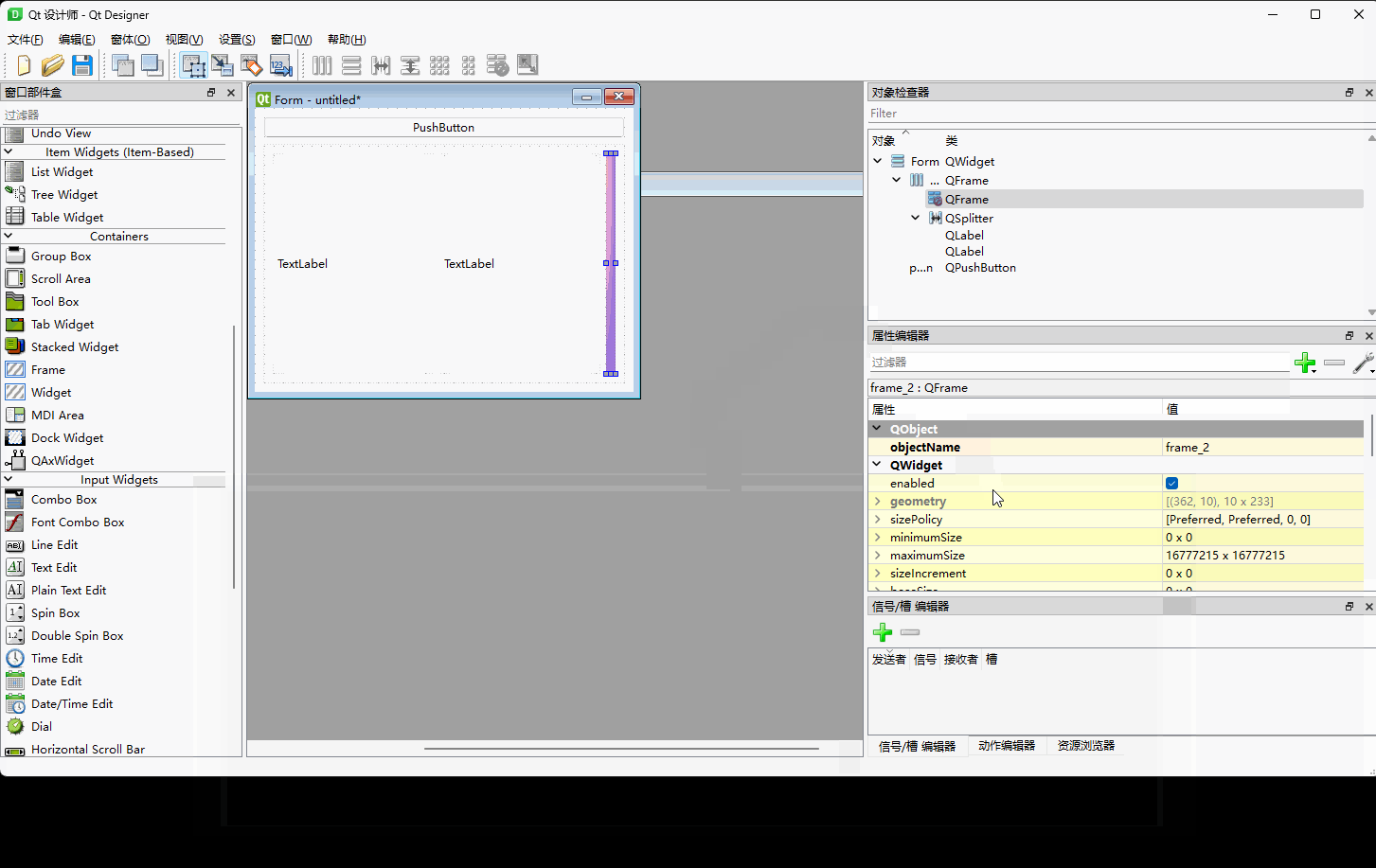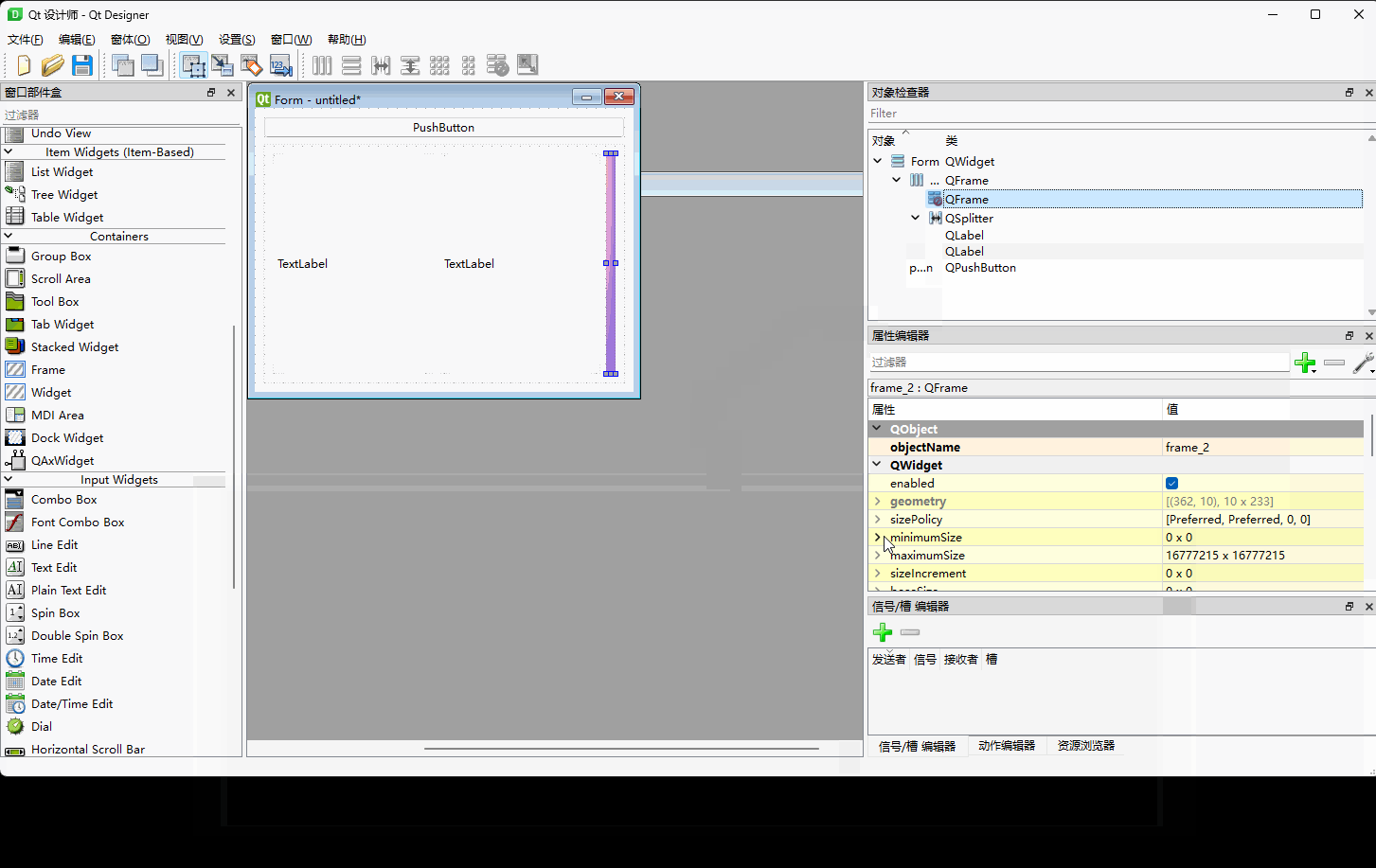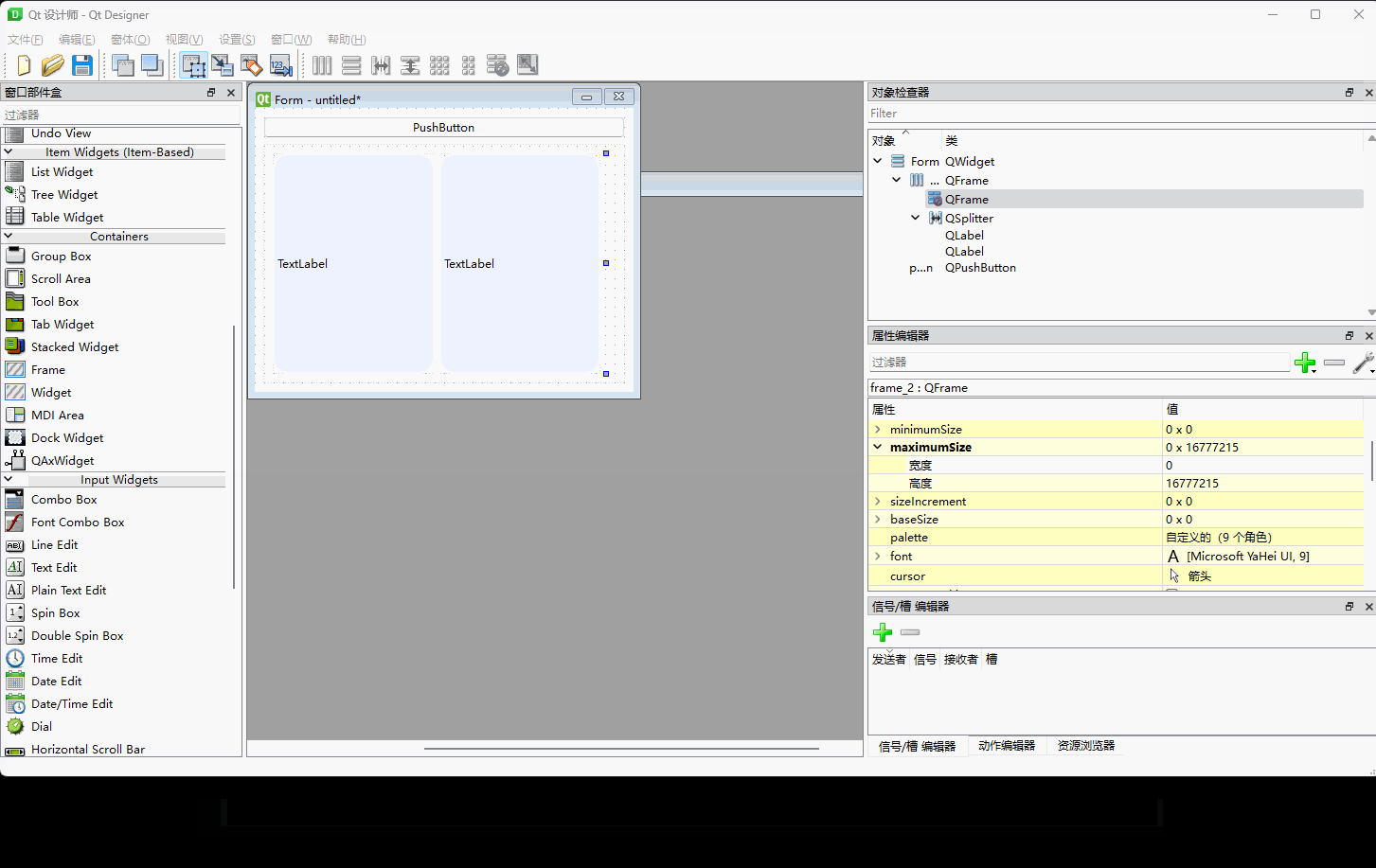
Qt第六十五章:自定义菜单栏的隐藏、弹出
目录 一、效果图 二、qtDesigner 三、ui文件如下: 四、代码 一、效果图 二、qtDesigner 原理是利用属性动画来控制QFrame的minimumWidth属性。 ①先拖出相应的控件 ②布局一下 ③填上一些样式 相关QSS background-color: rgb(238, 242, 255); border:2px sol…...

element table中嵌套el-select 无法选择问题
<el-table-column align"left" label"姓名" show-overflow-tooltip :key"tableKey"><template slot-scope"scope"><el-select placeholder"请选择" :disabled"!saveButton" v-model"scope.ro…...

【算法日记】Day 9 动态规划专题——最长递增子序列问题及扩展
Abstract:#动态规划 #最长递增子序列 #二分查找 #排序 1. 题目 题目:LeetCode 354. 俄罗斯套娃信封核心思路:先将信封按宽度升序排序,若宽度相同则按高度降序排序。然后对排序后的高度序列求最长递增子序列(LIS&…...

FastAPI负载测试终极指南:从配置到性能优化的完整方案
FastAPI负载测试终极指南:从配置到性能优化的完整方案 【免费下载链接】fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 项目地址: https://gitcode.com/GitHub_Trending/fa/fastapi FastAPI作为一款高性…...
)
手把手教你将YOLOv10模型部署到RK3588开发板(含Docker环境搭建与模型转换避坑指南)
从零部署YOLOv10到RK3588开发板:完整流程与实战避坑指南 边缘计算设备上的AI模型部署正成为工业检测、智能安防等场景的核心需求。RK3588作为一款高性能AIoT芯片,其6TOPS算力与丰富接口使其成为边缘AI的理想载体。本文将详解YOLOv10模型在RK3588平台的完…...

LangGraph 容错机制设计:节点降级+流程跳转+异常捕获
LangGraph 容错机制设计:节点降级+流程跳转+异常捕获 关键词 LangGraph, 容错机制, 节点降级, 流程跳转, 异常捕获, 大语言模型应用可靠性, Agent编排 摘要 随着大语言模型(LLM)在生产环境中的应用日益广泛,Agent编排系统(如LangChain中的LangGraph)的可靠性与容错能力…...

Aurix Tricore开发避坑指南:从零理解Trap机制,手把手教你写异常处理程序
Aurix Tricore开发实战:Trap机制深度解析与异常处理程序编写指南 引言 在嵌入式系统开发中,异常处理往往是区分新手与资深工程师的关键能力。Aurix Tricore系列微控制器凭借其强大的实时性能和安全性,广泛应用于汽车电子、工业控制等领域。然…...

我不是在用 AI 助手,我在把自己的能力沉淀成组织资产婆
1. 什么是 Apache SeaTunnel? Apache SeaTunnel 是一个非常易于使用、高性能、支持实时流式和离线批处理的海量数据集成平台。它的目标是解决常见的数据集成问题,如数据源多样性、同步场景复杂性以及资源消耗高的问题。 核心特性 丰富的数据源支持&#…...

3种方法如何解决Balena Etcher在Arch Linux上的安装难题
3种方法如何解决Balena Etcher在Arch Linux上的安装难题 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 问题诊断:为什么Arch Linux安装Etcher总是失…...

解锁毕业论文新姿势:好写作AI,你的学术“超级外挂”!
在学术的江湖里,毕业论文就像是那终极BOSS,每个学子都得独自面对,挑战重重。选题迷茫、文献浩如烟海、写作卡壳……这些问题是不是让你头疼不已?别怕,今天咱们就来揭秘一个学术界的“超级外挂”——好写作AI࿰…...

Facenet-Pytorch人脸识别实战指南:5步快速构建精准人脸识别系统
Facenet-Pytorch人脸识别实战指南:5步快速构建精准人脸识别系统 【免费下载链接】facenet-pytorch Pretrained Pytorch face detection (MTCNN) and facial recognition (InceptionResnet) models 项目地址: https://gitcode.com/gh_mirrors/fa/facenet-pytorch …...

CANFD双ID过滤的妙用:用STM32实现车载ECU的故障诊断与正常通信分离
CANFD双ID过滤在车载ECU中的实战应用:诊断与通信的智能分离 在汽车电子系统中,ECU(电子控制单元)需要同时处理诊断请求和常规通信报文。传统做法往往需要复杂的软件过滤逻辑,不仅增加了CPU负担,还可能导致实…...