python爬虫涨姿势板块
Python有许多用于网络爬虫和数据采集的库和框架。这些库和框架使爬取网页内容、抓取数据、进行数据清洗和分析等任务变得更加容易。以下是一些常见的Python爬虫库和框架:
-
Beautiful Soup: Beautiful Soup是一个HTML和XML解析库,用于从网页中提取数据。它提供了许多方法来导航和搜索文档树,从而轻松提取所需的信息。
-
Requests: Requests是一个HTTP库,用于向网站发送HTTP请求。它使得下载网页内容变得非常容易,可以与其他库(如Beautiful Soup)结合使用来处理和解析页面内容。
-
Scrapy: Scrapy是一个强大的Web爬虫框架,用于爬取网站和抓取数据。它提供了一整套工具和功能,包括页面爬取、数据存储、数据清洗和导出。
-
Selenium: Selenium是一个自动化测试工具,但也可用于Web爬虫。它模拟浏览器行为,允许爬取JavaScript生成的内容,执行交互操作,以及处理需要用户输入的网站。
-
Scrapy-Redis: 这是Scrapy框架的一个扩展,用于支持分布式爬取,将数据存储在Redis数据库中。
-
PyQuery: 类似于Beautiful Soup,PyQuery是一个库,用于解析HTML和XML文档,但它使用jQuery选择器语法。
-
Gevent: Gevent是一个用于异步网络编程的库,可用于构建高性能的网络爬虫。它可以轻松处理数千个并发请求。
-
Apache Nutch: Nutch是一个开源的网络搜索引擎,也可以用作爬虫框架。它支持大规模爬取和数据处理。
-
Splash: Splash是一个JavaScript渲染服务,可用于爬取需要JavaScript渲染的页面。它可以与Scrapy等框架一起使用。
-
Tornado: Tornado是一个网络框架,也可用于构建高性能的异步爬虫。
Beautiful Soup
下面是一个使用Beautiful Soup进行简单网页爬取的Python示例。在此示例中,我们将使用Beautiful Soup来提取并显示指定网页的标题和所有链接的文本和URL。
首先,确保您已经安装了Beautiful Soup,您可以使用pip install beautifulsoup4来安装它。
import requests
from bs4 import BeautifulSoup# 指定要爬取的网页URL
url = "https://www.sina.com.cn/" # 请将网址替换为您要爬取的网页# 发送HTTP GET请求并获取页面内容
response = requests.get(url)
response.encoding = 'utf-8' # 指定字符编码为 UTF-8
# 使用Beautiful Soup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')# 提取页面标题
title = soup.title.string
print("网页标题:", title)# 提取并显示所有链接的文本和URL
links = soup.find_all('a') # 查找所有<a>标签for link in links:link_text = link.textlink_url = link.get('href') # 获取链接的URLprint(f"链接文本: {link_text}\n链接URL: {link_url}\n")# 关闭HTTP连接
response.close()
首先使用requests.get(url)发送HTTP GET请求来获取指定网页的内容。然后,我们使用Beautiful Soup来解析HTML内容。我们提取了页面标题,并找到了所有的链接,然后逐个提取链接的文本和URL。最后,我们关闭了HTTP连接。
通常,您会使用Beautiful Soup来更深入地分析页面内容,找到特定元素,例如表格、列表或段落,以提取所需的数据。根据要爬取的网页的结构和需求,您可以使用Beautiful Soup来自定义更复杂的爬虫。
结合XPath
import requests
from bs4 import BeautifulSoup
from lxml import html# 发送HTTP请求,获取页面内容
url = "https://www.sina.com.cn/"
response = requests.get(url)
if response.status_code == 200:# 解析页面内容soup = BeautifulSoup(response.text, 'html.parser')# 转换Beautiful Soup对象为lxml对象root = html.fromstring(str(soup))# 使用XPath查询来获取所有链接links = root.xpath('//a')# 打印所有链接for link in links:href = link.get('href')if href:print(href)
else:print("Failed to retrieve the page. Status code:", response.status_code)lxml 是一个强大且高性能的Python库,用于处理XML和HTML文档。它提供了方便的API来解析、操作和构建XML文档。lxml 基于 C 语言的 libxml2 和 libxslt 库,因此它具有出色的性能和稳定性。
以下是 lxml 的一些主要特点和用法:1. 解析XML和HTML文档:lxml 可以用于解析标准的XML和HTML文档,包括处理各种复杂的文档结构和标签嵌套。2. XPath 支持:lxml 支持XPath,允许你使用XPath表达式来定位和选择文档中的元素。这使得数据提取和文档导航变得非常方便。3. ElementTree API:lxml 提供了 ElementTree API 的实现,这使得文档的处理更加易于理解和操作。4. HTML 清理和解析:lxml 提供了功能强大的 HTML 清理工具,允许你将不规范的 HTML 转换为规范的 XML,以便进一步处理。5. HTML 生成:lxml 也可以用于创建和生成 XML 和 HTML 文档,包括添加元素、属性和文本。6. 高性能:lxml 的 C 语言底层库使其具有出色的性能,适用于处理大型文档和高吞吐量的应用。7. 验证和模式检查:lxml 允许你验证 XML 文档是否符合给定的模式或 DTD(文档类型定义)。
Scrapy
Scrapy 是一个功能强大的Python网络爬虫框架,用于抓取和提取网站上的数据。下面是一个简单的 Scrapy 实例,用于爬取特定网站上的文章标题和链接。首先,确保你已安装 Scrapy。
- 首先,确保你已经安装了 Scrapy。如果没有安装,你可以使用以下命令安装 Scrapy:
pip install scrapy
然后,创建一个 Scrapy 项目。在命令行中执行以下命令:
scrapy startproject myproject
这将创建一个名为 “myproject” 的 Scrapy 项目目录。
- 进入项目目录:
cd myproject
- 创建一个爬虫。在命令行中执行以下命令,其中 “example_spider” 是爬虫的名称:
scrapy genspider example_spider example.com
这将创建一个名为 “example_spider” 的爬虫,并指定要爬取的网站域名为 “example.com”。
- 打开 “myproject/spiders/example_spider.py” 文件,编辑爬虫的规则和抓取逻辑。下面是一个简单的示例,用于爬取 “example.com” 网站上的标题和链接:
import scrapyclass ExampleSpider(scrapy.Spider):name = 'example_spider'start_urls = ['http://www.example.com']def parse(self, response):for entry in response.xpath('//h2/a'):yield {'title': entry.xpath('text()').get(),'link': entry.xpath('@href').get()}
- 运行爬虫。在项目目录中执行以下命令:
scrapy crawl example_spider
这将启动爬虫并开始抓取 “example.com” 网站上的信息。抓取的结果将显示在终端上。
Scrapy 具有丰富的功能和配置选项,可根据你的需求进行进一步定制。你还可以配置数据的存储、数据处理、请求头、中间件等。请查阅 Scrapy 文档以获取更多信息和示例:https://docs.scrapy.org/en/latest/index.html
相关文章:

python爬虫涨姿势板块
Python有许多用于网络爬虫和数据采集的库和框架。这些库和框架使爬取网页内容、抓取数据、进行数据清洗和分析等任务变得更加容易。以下是一些常见的Python爬虫库和框架: Beautiful Soup: Beautiful Soup是一个HTML和XML解析库,用于从网页中提取数据。它…...

软件设计原则-里氏替换原则讲解以及代码示例
里氏替换原则 一,介绍 1.前言 里氏替换原则(Liskov Substitution Principle,LSP)是面向对象设计中的一条重要原则,它由Barbara Liskov在1987年提出。 里氏替换原则的核心思想是:父类的对象可以被子类的…...

Sui提供dApp Kit 助力快速构建React Apps和dApps
近日,Mysten Labs推出了dApp Kit,这是一个全新的解决方案,可用于在Sui上开发React应用程序和去中心化应用程序(dApps)。mysten/dapp-kit是专门为React定制的全新SDK,旨在简化诸如连接钱包、签署交易和从RPC…...

2023年系统设计面试如何破解?进入 FAANG 面试的实战指南
如果您正在准备编码面试,但想知道如何准备关键的系统设计主题,并寻找正确方法、技巧和问题的分步指导,那么您来对地方了。在本文中,我将分享 2023 年系统设计面试的完整指南。 在软件开发领域,如果您正在申请高级工程…...
vite项目中的路径别名的配置)
(react+ts)vite项目中的路径别名的配置
简单两个步骤 找到vite.config.ts,这里会现实报错,需要安装一下 npm i -D types/node 这个库的ts声明配置 import path from path // https://vitejs.dev/config/ export default defineConfig({plugins: [react()],resolve:{alias:{"":path.resolve(__…...
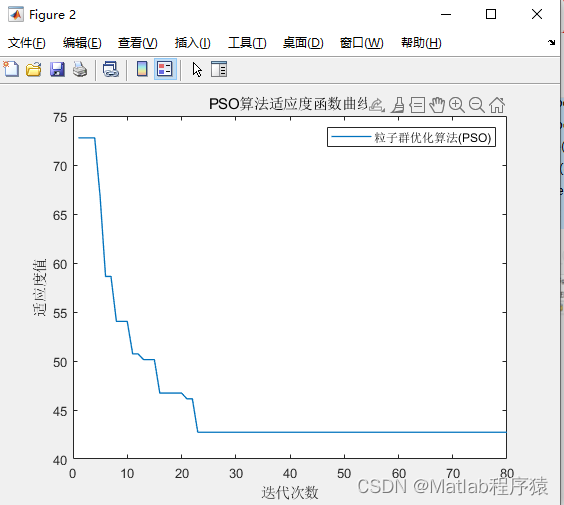
【MATLAB源码-第51期】基于matlab的粒子群算法(PSO)的栅格地图路径规划。
操作环境: MATLAB 2022a 1、算法描述 粒子群算法(Particle Swarm Optimization,简称PSO)是一种模拟鸟群觅食行为的启发式优化方法。以下是其详细描述: 基本思想: 鸟群在寻找食物时,每只鸟都会…...
React之render
一、原理 首先,render函数在react中有两种形式: 在类组件中,指的是render方法: class Foo extends React.Component {render() {return <h1> Foo </h1>;} }在函数组件中,指的是函数组件本身:…...
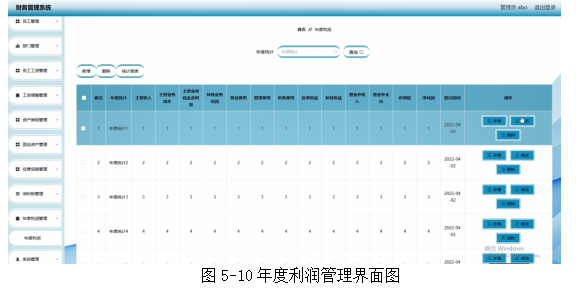
基于springboot实现财务管理系统项目【项目源码+论文说明】计算机毕业设计
基于springboot实现财务管理系统演示 摘要 随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生&#x…...
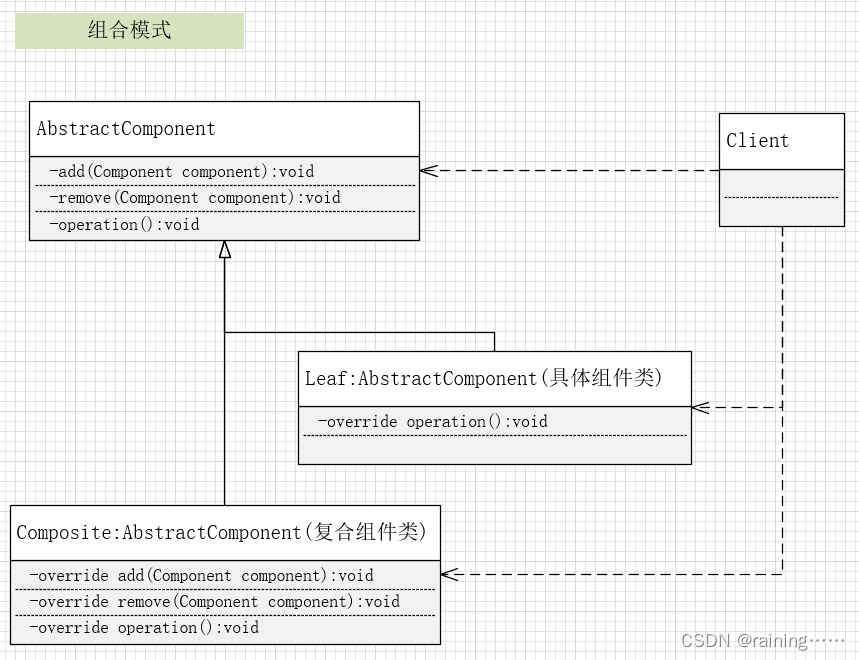
设计模式:组合模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
上一篇《模板模式》 下一篇《代理模式》 简介: 组合模式,它是一种用于处理树形结构、表示“部分-整体”层次结构的设计模式。它允许你将对象组合成树形结构,以表示部分…...
超强满血不收费的AI绘图教程来了(在线Stable Diffusion一键即用)
超强满血不收费的AI绘图教程来了(在线Stable Diffusion一键即用) 一、简介1.1 AI绘图1.2 Stable Diffusion1.2.1 原理简述1.2.2 应用流程 二、AI绘图工具2.1 吐司TusiArt2.2 哩布哩布LibLibAI2.3 原生部署 三、一键即用3.1 开箱尝鲜3.2 模型关联3.3 Cont…...
【蓝桥每日一题]-动态规划 (保姆级教程 篇12)#照相排列
这次是动态规划最后一期了,感谢大家一直以来的观看,以后就进入新的篇章了 目录 题目:照相排列 思路: 题目:照相排列 思路: 首先记录状态f[a][b][c][d][e]表示每排如此人数下对应的方案数,然…...

纺织工厂数字孪生3D可视化管理平台,推动纺织产业数字化转型
近年来,我国加快数字化发展战略部署,全面推进制造业数字化转型,促进数字经济与实体经济深度融合。以数字孪生、物联网、云计算、人工智能为代表的数字技术发挥重要作用。聚焦数字孪生智能工厂可视化平台,推动纺织制造业数字化转型…...
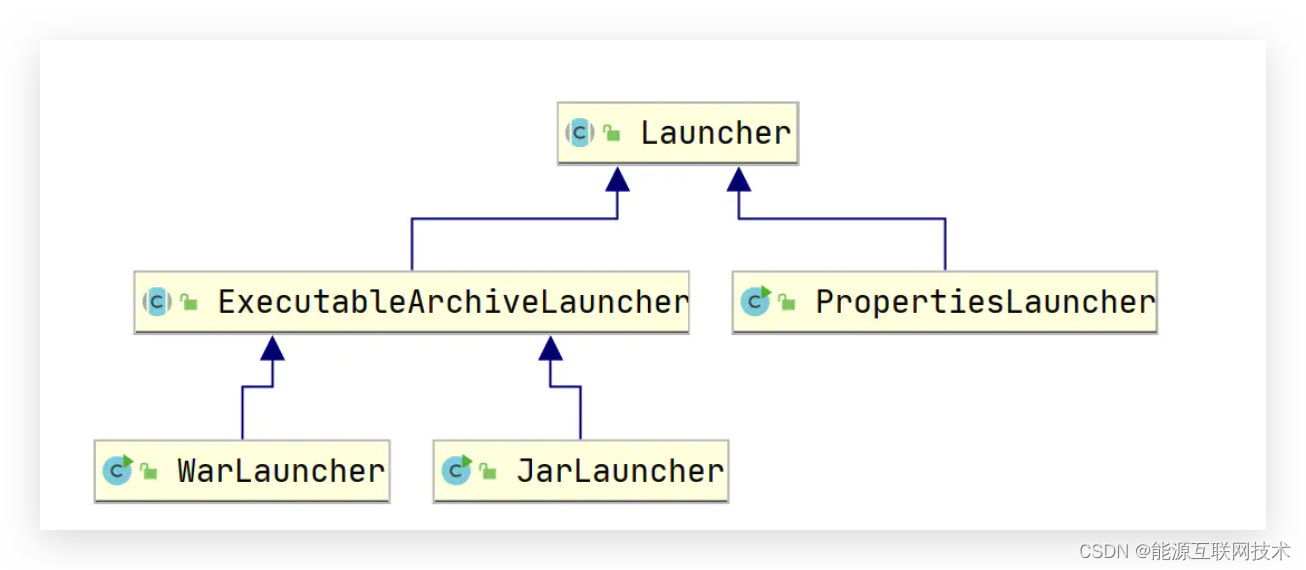
【七】SpringBoot为什么可以打成 jar包启动
SpringBoot为什么可以打成 jar包启动 简介:庆幸的是夜跑的习惯一直都在坚持,正如现在坚持写博客一样。最开始刚接触springboot的时候就觉得很神奇,当时也去研究了一番,今晚夜跑又想起来了这茬事,于是想着应该可以记录一…...

031-第三代软件开发-屏幕保护
第三代软件开发-屏幕保护 文章目录 第三代软件开发-屏幕保护项目介绍屏幕保护 关键字: Qt、 Qml、 MediaPlayer、 VideoOutput、 function 项目介绍 欢迎来到我们的 QML & C 项目!这个项目结合了 QML(Qt Meta-Object Language&#…...

Ubuntu 22.04 更新完内核重启卡在 grub 命令行解决办法
倒霉伊始 升级内核过程中出现如下警告,然后重启引导失败: Warning: os-prober will not be executed to detect other bootable partitions 屏幕内容如下: GNU GRUB version 2.06Minimal BASH-like line editing is supported. For the fir…...
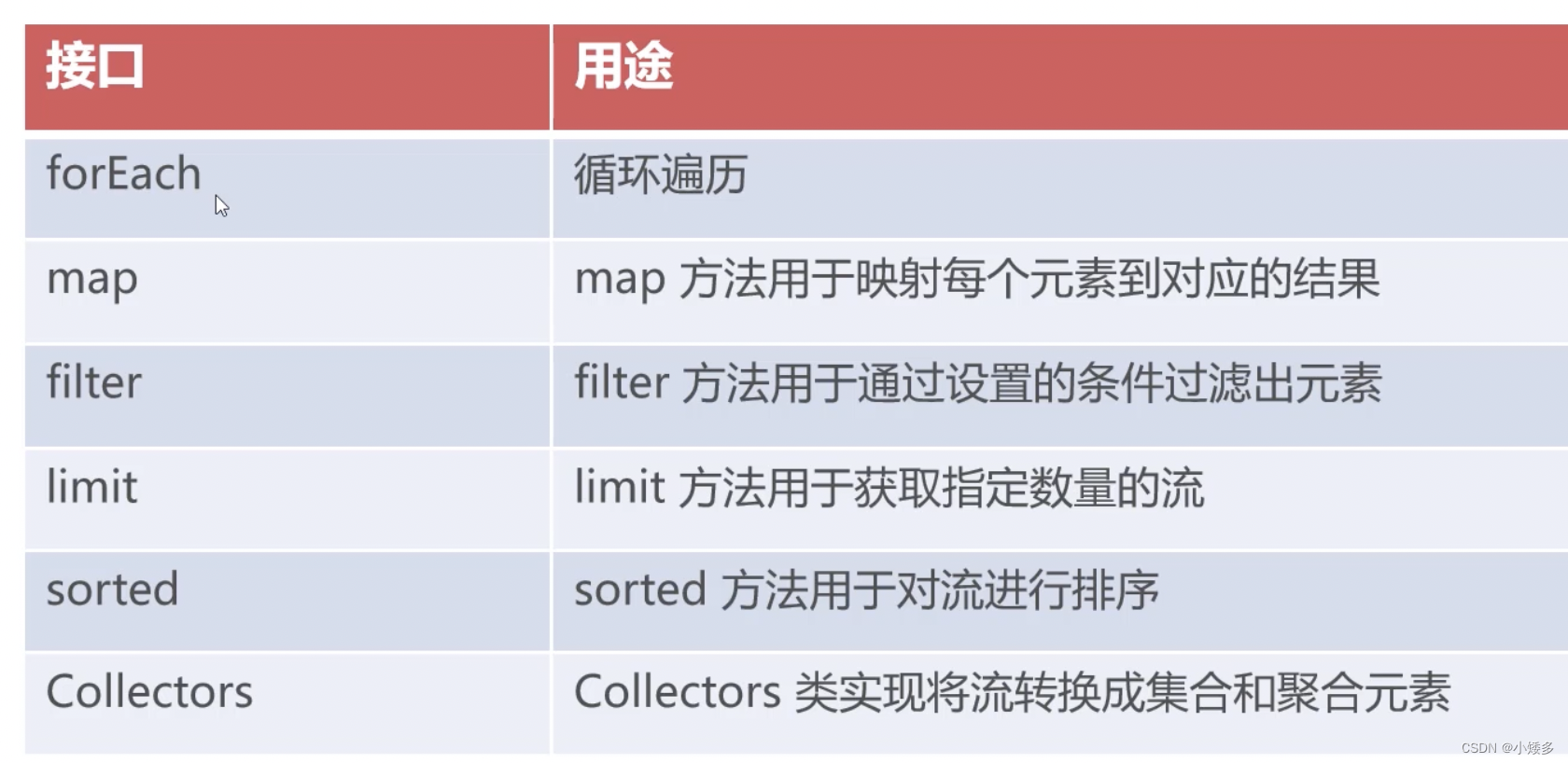
Stream流式处理
Stream流式处理: 建立在Lambda表达式基础上的多数据处理技术。 可以对集合进行迭代、去重、筛选、排序、聚合等处理,极大的简化了代码量。 Stream常用方法 Stream流对象的五种创建方式 //基于数组 String[] arr {"a","b","c…...

ROG STRIX GS-AX5400 使用笔记
1. 技术支持 咨询京东(因为是在京东购买的) 2. 增强信号设置 Note:关于设置的具体步骤,请参考教程《华硕路由器地区如何改成澳大利亚》。 操作路径:打开主页<192.168.50.1> ⇒ 输入用户名和密码后选择登录 ⇒ …...
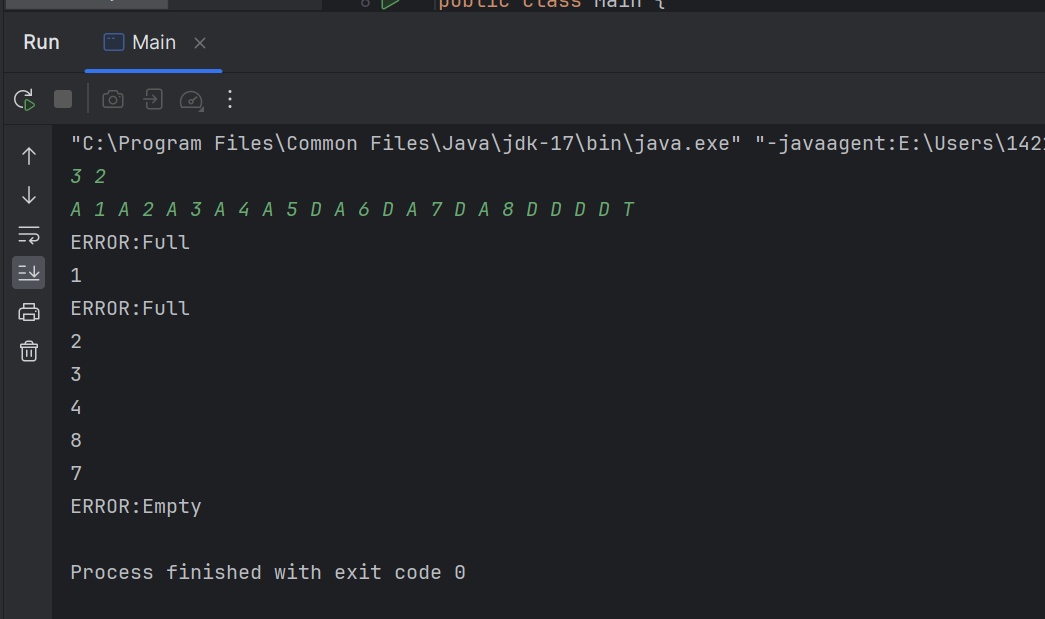
【刷题-PTA】堆栈模拟队列(代码+动态图解)
【刷题-PTA】堆栈模拟队列(代码动态图解) 文章目录 【刷题-PTA】堆栈模拟队列(代码动态图解)题目输入格式:输出格式:输入样例:输出样例: 分析题目区分两栈解题思路伪代码动图演示代码测试 题目 题目描述 : 设已知有两个堆栈S1和S2,请用这两个堆栈模拟出一个队列Q。 …...
FileUpload控件上传文件时出现 不支持给定路径的格式.的解决方法
正常代码,部署到server 2012时,在上传音频mp3文件时,显示错误“不支持给定路径的格式”,上传控件使用FileUpload控件: 因为程序之前是正常的,因此应该不是程序的问题。 上传时,发现在选择文件时…...

这两天的一些碎碎念
一直以来我都不算是一个非常热爱运维岗位的一个人,其实本行工作对于我来说只是一个工作。运维的广度很大,说什么工作了7年了,可最终总感觉还曾是一窍不通。 什么shell啊,什么python啊,什么大数据啊,7年里&a…...

C++的std--ranges等价
C的std::ranges等价:现代算法的新范式 C20引入的std::ranges库彻底改变了传统算法的编写方式,其中“等价”(equivalence)概念是理解范围操作的核心之一。与传统的“相等”(equality)不同,等价关…...

LDC1101嵌入式驱动开发:电感-数字转换器SPI控制与实时优化
1. LDC1101嵌入式驱动库深度解析:高精度电感-数字转换器的底层控制实践LDC1101是德州仪器(TI)推出的一款高分辨率、高速度电感-数字转换器(Inductance-to-Digital Converter),专为非接触式位置检测、金属物…...

视频下载重命名全攻略,VS Code 使用 Chrome DevTools MCP 实现浏览器自动化。
视频下载与重命名方法 手动下载 打开浏览器访问课程平台,找到目标视频《计算机网络技术》。点击下载按钮选择保存路径,等待下载完成。右键点击文件选择“重命名”,输入新名称如“人工智能-03-04_20250920_计算机网络技术.mp4”。 Python自动化…...

ModTheSpire终极指南:5个技巧让杀戮尖塔模组加载零烦恼
ModTheSpire终极指南:5个技巧让杀戮尖塔模组加载零烦恼 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 厌倦了每次想体验新模组都要手动修改游戏文件的繁琐操作吗ÿ…...

Sanitizer工具集:高效检测内存与线程问题的实战指南
1. Sanitizer工具集概述Sanitizer是由Google发起的一套开源运行时检测工具集,专门用于帮助开发者发现程序中的各类隐藏缺陷。作为一名嵌入式开发者,我深刻体会到调试内存泄漏、线程竞争等问题时的痛苦。传统的调试手段往往需要耗费大量时间在复现和定位问…...

专业级反爬突破:实战解析开源Wenshu_Spider技术架构与完整解决方案
专业级反爬突破:实战解析开源Wenshu_Spider技术架构与完整解决方案 【免费下载链接】Wenshu_Spider :rainbow:Wenshu_Spider-Scrapy框架爬取中国裁判文书网案件数据(2019-1-9最新版) 项目地址: https://gitcode.com/gh_mirrors/wen/Wenshu_Spider 中国裁判文…...

综合强度信息的激光雷达去拖尾算法解析和源码实现
1. 内容本文主要介绍基于几何特征与信号强度的去拖尾算法,和程序实现。2. 激光雷达的常见误差类型2.1 拖尾(Trailing)拖尾是指当激光束照射到高反射率物体(如反光条、玻璃、镜子、路面标志等)时,在真实目标…...

突破百度网盘限速:BaiduPCS-Web技术普惠解决方案
突破百度网盘限速:BaiduPCS-Web技术普惠解决方案 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 在数字化时代,云存储已成为个人与企业数据管理的基础设施,而百度网盘作为国内用户基数最大…...

救命!这些毕设太好抄了,3000+毕设案例推荐第1027期
271、基于Java的建材租赁智慧管理系统的设计与实现(论文+代码+PPT)建材租赁智慧管理系统主要功能包括:会员操作、客户资料、建材管理、计量单位、建材损坏收费标准、租赁合同、租费标准、租出登记、归还登记、丢赔管理、入库登记、租金计算、…...

Node-RED 4.0.2连接Oracle数据库避坑指南:从模组选择到环境变量配置全流程
Node-RED 4.0.2连接Oracle数据库全流程实战:从环境搭建到高效查询 在物联网和自动化流程开发领域,Node-RED因其可视化编程特性而广受欢迎。当需要将Node-RED与Oracle数据库集成时,许多开发者会遇到各种环境配置和连接问题。本文将详细介绍如何…...