Java基础篇 | Java8流式编程

✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉
🍎个人主页:Leo的博客
💞当前专栏: Java从入门到精通
✨特色专栏: MySQL学习
🥭本文内容:Java基础篇 | Java8流式编程
🖥️个人小站 :个人博客,欢迎大家访问
📚个人知识库: 知识库,欢迎大家访问
大家好,我是Leo🫣🫣🫣,上周一直在忙于Spring系列文章的更迭,一直没有时间系列去更其他系列博文,也是耽搁了很久,今天1024,Leo提前祝大家节日快乐,今天我们主要学习一下关于JavaStream流相关的知识点,好了,话不多说让我们开始吧😎😎😎。
1.认识流式编程
1.1流式编程的概念和作用
Java 流(Stream)是一连串的元素序列,可以进行各种操作以实现数据的转换和处理。流式编程的概念基于函数式编程的思想,旨在简化代码,提高可读性和可维护性。
Java Stream 的主要作用有以下几个方面:
-
简化集合操作:使用传统的 for 循环或迭代器来处理集合数据可能会导致冗长而复杂的代码。而使用流式编程,能够用更直观、更简洁的方式对集合进行过滤、映射、排序、聚合等操作,使代码变得更加清晰易懂。
-
延迟计算:流式操作允许你在处理数据之前定义一系列的操作步骤,但只在需要结果时才会实际执行。这种延迟计算的特性意味着可以根据需要动态调整数据处理的操作流程,提升效率。
-
并行处理:Java Stream 提供了并行流的支持,可以将数据分成多个块进行并行处理,从而充分利用多核处理器的性能优势,提高代码的执行速度。
-
函数式编程风格:流式编程鼓励使用函数式编程的思想,通过传递函数作为参数或使用 Lambda 表达式来实现代码的简化和灵活性。这种函数式的编程模式有助于减少副作用,并使代码更易测试和调试。
1.2流式编程可以提高代码可读性和简洁性
-
声明式编程风格:流式编程采用了一种声明式的编程风格,你只需描述你想要对数据执行的操作,而不需要显式地编写迭代和控制流语句。这使得代码更加直观和易于理解,因为你可以更专注地表达你的意图,而无需关注如何实现。
-
链式调用:流式编程使用方法链式调用的方式,将多个操作链接在一起。每个方法都返回一个新的流对象,这样你可以像“流水线”一样在代码中顺序地写下各种操作,使代码逻辑清晰明了。这种链式调用的方式使得代码看起来更加流畅,减少了中间变量和临时集合的使用。
-
操作的组合:流式编程提供了一系列的操作方法,如过滤、映射、排序、聚合等,这些方法可以按照需要进行组合使用。你可以根据具体的业务需求将这些操作串联起来,形成一个复杂的处理流程,而不需要编写大量的循环和条件语句。这种组合操作的方式使得代码更加模块化和可维护。
-
减少中间状态:传统的迭代方式通常需要引入中间变量来保存中间结果,这样会增加代码的复杂度和维护成本。而流式编程将多个操作链接在一起,通过流对象本身来传递数据,避免了中间状态的引入。这种方式使得代码更加简洁,减少了临时变量的使用。
-
减少循环和条件:流式编程可以替代传统的循环和条件语句的使用。例如,可以使用 filter() 方法进行元素的筛选,使用 map() 方法进行元素的转换,使用 reduce() 方法进行聚合操作等。这些方法可以用一行代码完成相应的操作,避免了繁琐的循环和条件逻辑,使得代码更加简洁明了。
2.流的基础示例
2.1 环境搭建
我们首先创建一个演员类。
package com.trs.stream;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;/*** @author : Leo* @version 1.0* @date 2023-10-24 9:42* @description : 示例*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Actor {/*编写一个演员类 有 演员id演员名称和演员年龄 演员作品 */private Integer id;private String name;private Integer age;private String works;
}基于这个类,我们初始化一个演员集合:
package com.trs.stream;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
/*** @author : Leo* @version 1.0* @date 2023-10-24 9:42* @description : 示例*/public class StreamTest01 {public static final List<Actor> actorList =Arrays.asList( new Actor(1001, "张三", 30, "演员"),new Actor(1002, "李四", 70, "演员"),new Actor(1003, "王五", 40, "演员"),new Actor(1004, "赵六", 53, "演员"),new Actor(1005, "莉莉", 35, "演员"),new Actor(1006, "杨晓雪", 12, "演员"),new Actor(1007, "李师傅", 55, "演员"),new Actor(1008, "王胖子", 40, "演员"),new Actor(1009, "齐肩发", 45, "演员"));
}
2.2 使用Java8之前的做法
/*** 用于测试: 使用Java8之前的做法*/@Testpublic void test1() {List<Actor> ageList = new ArrayList<>();//筛选演员年龄小于40岁的for (Actor actor : actorList) {if (actor.getAge() <40){ageList.add(actor);}}//按照升序进行排序List<String> lowActoresName = new ArrayList<>();Collections.sort(ageList, new Comparator<Actor>() {public int compare(Actor c1, Actor c2) {return Integer.compare(c1.getId(), c2.getId());}});//存入string列表for (Actor d : ageList) {lowActoresName.add(d.getName());}//输出for (Actor lowCaloricActor : ageList) {System.out.println(lowCaloricActor);}}
对应输出结果如下,张三,莉莉,杨晓雪,符合我们的预期:

2.3 使用流式编程
/*** 用于测试: 流式编程*/@Testpublic void test2() {actorList.stream()// 过滤演员年龄小于40的.filter(c -> c.getAge() <40)// 用id进行排序.sorted(comparing(Actor::getId))// 合并map,拿到名字相同的去作用于各个演员.map(Actor::getName)// 转为list.collect(toList())// 输入.forEach(System.out::println);}
结果同样符合我们的预期

3.Stream流的基础知识
3.1 什么是 Stream
Stream(流)是 Java 8 引入的一个新的抽象概念,它代表着一种处理数据的序列。简单来说,Stream 是一系列元素的集合,这些元素可以是集合、数组、I/O 资源或者其他数据源。
Stream API 提供了丰富的操作方法,可以对 Stream 中的元素进行各种转换、过滤、映射、聚合等操作,从而实现对数据的处理和操作。Stream API 的设计目标是提供一种高效、可扩展和易于使用的方式来处理大量的数据。
Stream 具有以下几个关键特点:
-
数据源:Stream 可以基于不同类型的数据源创建,如集合、数组、I/O 资源等。你可以通过调用集合或数组的 stream() 方法来创建一个流。
-
数据处理:Stream 提供了丰富的操作方法,可以对流中的元素进行处理。这些操作可以按需求组合起来,形成一个流水线式的操作流程。常见的操作包括过滤(filter)、映射(map)、排序(sorted)、聚合(reduce)等。
-
惰性求值:Stream 的操作是惰性求值的,也就是说在定义操作流程时,不会立即执行实际计算。只有当终止操作(如收集结果或遍历元素)被调用时,才会触发实际的计算过程。
-
不可变性:Stream 是不可变的,它不会修改原始数据源,也不会产生中间状态或副作用。每个操作都会返回一个新的流对象,以保证数据的不可变性。
-
并行处理:Stream 支持并行处理,可以通过 parallel() 方法将流转换为并行流,利用多核处理器的优势来提高处理速度。在某些情况下,使用并行流可以极大地提高程序的性能。
通过使用 Stream,我们可以使用简洁、函数式的方式处理数据。相比传统的循环和条件语句,Stream 提供了更高层次的抽象,使代码更具可读性、简洁性和可维护性。它是一种强大的工具,可以帮助我们更有效地处理和操作集合数据。
3.2 Stream 的特性和优势
-
简化的编程模型:Stream 提供了一种更简洁、更声明式的编程模型,使代码更易于理解和维护。通过使用 Stream API,我们可以用更少的代码实现复杂的数据操作,将关注点从如何实现转移到了更关注我们想要做什么。
-
函数式编程风格:Stream 是基于函数式编程思想设计的,它鼓励使用不可变的数据和纯函数的方式进行操作。这种风格避免了副作用,使代码更加模块化、可测试和可维护。此外,Stream 还支持 Lambda 表达式,使得代码更加简洁和灵活。
-
惰性求值:Stream 的操作是惰性求值的,也就是说在定义操作流程时并不会立即执行计算。只有当终止操作被调用时,才会触发实际的计算过程。这种特性可以避免对整个数据集进行不必要的计算,提高了效率。
-
并行处理能力:Stream 支持并行处理,在某些情况下可以通过 parallel() 方法将流转换为并行流,利用多核处理器的优势来提高处理速度。并行流能够自动将数据划分为多个子任务,并在多个线程上同时执行,提高了处理大量数据的效率。
-
优化的性能:Stream API 内部使用了优化技术,如延迟执行、短路操作等,以提高计算性能。Stream 操作是通过内部迭代器实现的,可以更好地利用硬件资源,并适应数据规模的变化。
-
支持丰富的操作方法:Stream API 提供了许多丰富的操作方法,如过滤、映射、排序、聚合等。这些方法可以按需求组合起来形成一个操作流程。在组合多个操作时,Stream 提供了链式调用的方式,使代码更加简洁和可读性更强。
-
可以操作各种数据源:Stream 不仅可以操作集合类数据,还可以操作其他数据源,如数组、I/O 资源甚至无限序列。这使得我们可以使用相同的编程模型来处理各种类型的数据。
3.3 如何创建 Stream 对象
-
从集合创建:我们可以通过调用集合的
stream()方法来创建一个 Stream 对象。例如:List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); Stream<Integer> stream = numbers.stream(); -
从数组创建:Java 8 引入了
Arrays类的stream()方法,我们可以使用它来创建一个 Stream 对象。例如:String[] names = {"Alice", "Bob", "Carol"}; Stream<String> stream = Arrays.stream(names); -
通过 Stream.of() 创建:我们可以使用
Stream.of()方法直接将一组元素转换为 Stream 对象。例如:Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); -
通过 Stream.builder() 创建:如果我们不确定要添加多少个元素到 Stream 中,可以使用
Stream.builder()创建一个 Stream.Builder 对象,并使用其add()方法来逐个添加元素,最后调用build()方法生成 Stream 对象。例如:Stream.Builder<String> builder = Stream.builder(); builder.add("Apple"); builder.add("Banana"); builder.add("Cherry"); Stream<String> stream = builder.build(); -
从 I/O 资源创建:Java 8 引入了一些新的 I/O 类(如
BufferedReader、Files等),它们提供了很多方法来读取文件、网络流等数据。这些方法通常返回一个 Stream 对象,可以直接使用。例如:Path path = Paths.get("data.txt"); try (Stream<String> stream = Files.lines(path)) {// 使用 stream 处理数据 } catch (IOException e) {e.printStackTrace(); } -
通过生成器创建:除了从现有的数据源创建 Stream,我们还可以使用生成器来生成元素。Java 8 中提供了
Stream.generate()方法和Stream.iterate()方法来创建无限 Stream。例如:Stream<Integer> stream = Stream.generate(() -> 0); // 创建一个无限流,每个元素都是 0 Stream<Integer> stream = Stream.iterate(0, n -> n + 1); // 创建一个无限流,从 0 开始递增
需要注意的是,Stream 对象是一种一次性使用的对象,它只能被消费一次。一旦对 Stream 执行了终止操作(如收集结果、遍历元素),Stream 就会被关闭,后续无法再使用。因此,在使用 Stream 时,需要根据需要重新创建新的 Stream 对象。
3.4 常用的 Stream 操作方法
-
过滤(Filter):
filter()方法接受一个 Predicate 函数作为参数,用于过滤 Stream 中的元素。只有满足 Predicate 条件的元素会被保留下来。例如:Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); Stream<Integer> filteredStream = stream.filter(n -> n % 2 == 0); // 过滤出偶数 -
映射(Map):
map()方法接受一个 Function 函数作为参数,用于对 Stream 中的元素进行映射转换。对每个元素应用函数后的结果会构成一个新的 Stream。例如:Stream<String> stream = Stream.of("apple", "banana", "cherry"); Stream<Integer> mappedStream = stream.map(s -> s.length()); // 映射为单词长度` -
扁平映射(FlatMap):
flatMap()方法类似于map()方法,不同之处在于它可以将每个元素映射为一个流,并将所有流连接成一个流。这主要用于解决嵌套集合的情况。例如:List<List<Integer>> nestedList = Arrays.asList(Arrays.asList(1, 2),Arrays.asList(3, 4),Arrays.asList(5, 6) ); Stream<Integer> flattenedStream = nestedList.stream().flatMap(List::stream); // 扁平化为一个流 -
截断(Limit):
limit()方法可以限制 Stream 的大小,只保留前 n 个元素。例如:Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); Stream<Integer> limitedStream = stream.limit(3); // 只保留前 3 个元素 -
跳过(Skip):
skip()方法可以跳过 Stream 中的前 n 个元素,返回剩下的元素组成的新 Stream。例如:Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);java Stream<Integer> skippedStream = stream.skip(2); // 跳过前 2 个元素 -
排序(Sorted):
sorted()方法用于对 Stream 中的元素进行排序,默认是自然顺序排序。还可以提供自定义的 Comparator 参数来指定排序规则。例如:Stream<Integer> stream = Stream.of(5, 2, 4, 1, 3); Stream<Integer> sortedStream = stream.sorted(); // 自然顺序排序 -
去重(Distinct):
distinct()方法用于去除 Stream 中的重复元素,根据元素的equals()和hashCode()方法来判断是否重复。例如:Stream<Integer> stream = Stream.of(1, 2, 2, 3, 3, 3); Stream<Integer> distinctStream = stream.distinct(); // 去重 -
汇总(Collect):
collect()方法用于将 Stream 中的元素收集到结果容器中,如 List、Set、Map 等。可以使用预定义的 Collectors 类提供的工厂方法来创建收集器,也可以自定义收集器。例如:Stream<String> stream = Stream.of("apple", "banana", "cherry"); List<String> collectedList = stream.collect(Collectors.toList()); // 收集为 List -
归约(Reduce):
reduce()方法用于将 Stream 中的元素依次进行二元操作,得到一个最终的结果。它接受一个初始值和一个 BinaryOperator 函数作为参数。例如:Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5); Optional<Integer> sum = stream.reduce((a, b) -> a + b); // 对所有元素求和 -
统计(Summary Statistics):
summaryStatistics()方法可以从 Stream 中获取一些常用的统计信息,如元素个数、最小值、最大值、总和和平均值。例如:IntStream stream = IntStream.of(1, 2, 3, 4, 5); IntSummaryStatistics stats = stream.summaryStatistics(); System.out.println("Count: " + stats.getCount()); System.out.println("Min: " + stats.getMin()); System.out.println("Max: " + stats.getMax()); System.out.println("Sum: " + stats.getSum()); System.out.println("Average: " + stats.getAverage());
以上只是 Stream API 提供的一部分常用操作方法,还有许多其他操作方法,如匹配(Match)、查找(Find)、遍历(ForEach)等。
4.Steam流的中间操作
中间操作方法分类:
- filter()
- map()
- flatMap()
- distinct()
- sorted()
- peek()
- limit()
- skip()
终端操作方法分类:
- forEach()
- forEachOrdered()
- toArray()
- reduce()
- collect()
- min()
- max()
- count()
- anyMatch()
- allMatch()
- noneMatch()
- findFirst()
- findAny()
中间操作代码实例详解
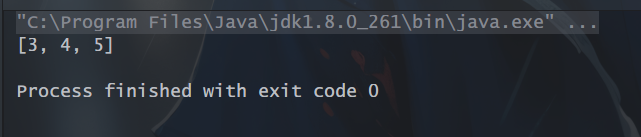
1、filter(): 返回结果生成新的流中只包含满足筛选条件的数据。
// 1、filter,返回大于2的元素集合List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5);List<Integer> result = nums.stream().filter(n -> n > 2).collect(Collectors.toList());System.out.println(result);
运行结果:
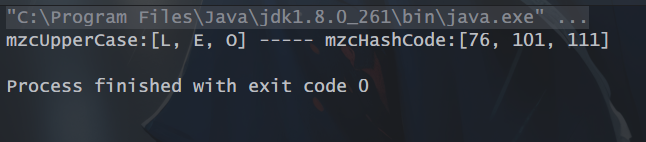
2、map():将流中的元素进行再次加工形成一个新流,流中的每一个元素映射为另外的元素。
// 2、map:返回元素的大写类型和哈希值List<String> mzc = Arrays.asList("L", "e", "o");List<String> mzcUpperCase = mzc.stream().map(n -> n.toUpperCase()).collect(Collectors.toList());List<Integer> mzcHashCode = mzc.stream().map(n -> n.hashCode()).collect(Collectors.toList());System.out.println("mzcUpperCase:"+mzcUpperCase+" ----- mzcHashCode:"+mzcHashCode);
运行结果:
示例场景:取出商品的所有id,就可以这样写(伪代码):
List productList = productService.selectAll();
List pIds = productList.stream().map(p->p.getId).collect(Collectors.toList());
这样就可以拿到所有商品id的集合。
3、flatMap():扁平化映射,它具体的操作是将多个stream连接成一个stream,这个操作是针对类似多维数组的,比如集合里面包含集合,相当于降维作用。
flatMap是将流中的每个元素都放到一个流中,最后将所有的流合并成一个新流,所有流对象中的元素都合并到这个新生成的流中返回。
// flatMap:将多层集合中的元素取出来,放到一个新的集合中去List<Integer> num1 = Arrays.asList(1, 2, 3);List<Integer> num2 = Arrays.asList(4, 5, 6);List<Integer> num3 = Arrays.asList(7, 8, 9);List<List<Integer>> lists = Arrays.asList(num1, num2, num3);Stream<Integer> outputStream = lists.stream().flatMap(l -> l.stream());List<Integer> flatMapResult = outputStream.sorted().collect(Collectors.toList());System.out.println(flatMapResult);
运行结果:

示例场景:取出所有部门人员的姓名,就可以这样写(伪代码):
// 1、取出所有部门
List departments = …;
// 2、这个时候可以利用flatMap先将所有部门的所有人员汇聚起来
List persons = departments.stream.flatMap(d->d.getPersonList()).collect(Collectors.toList());
// 3、再利用map()方法取出
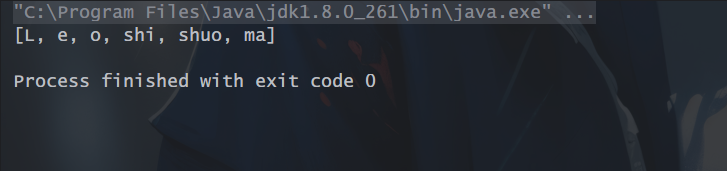
4、distinct():顾名思义,将流中的元素去重之后输出。
List<String> mzc = Stream.of("L","e","o","shi","shuo","ma").distinct().collect(Collectors.toList());
System.out.println(mzc);
运行结果:
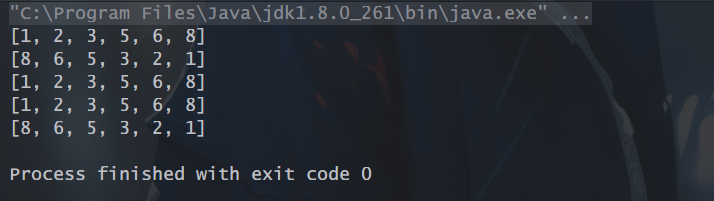
5、sorted():这个很简单了,顾名思义,将流中的元素按照自然排序方式进行排序。
// sorted:自然顺序排序List<Integer> nums = Arrays.asList(1, 3, 5, 6, 8, 2);List<Integer> sortedNum = nums.stream().sorted().collect(Collectors.toList());System.out.println(sortedNum);// sorted:降序排序List<Integer> sortedNum2 = nums.stream().sorted(Comparator.reverseOrder()).collect(Collectors.toList());System.out.println(sortedNum2);// sorted:使用ComparatorList<Integer> sortedNums3 = nums.stream().sorted(Comparator.comparing(n -> n)).collect(Collectors.toList());System.out.println(sortedNums3);// 不用stream直接顺序排序nums.sort(Comparator.comparing(Integer::intValue));System.out.println(nums);//不用stream直接降序排序nums.sort(Comparator.comparing(Integer::intValue).reversed());System.out.println(nums);
运行结果:
6、peek():对流中每个元素执行操作,并返回一个新的流,返回的流还是包含原来流中的元素。
// peek():String[] arr = new String[]{"a","b","c","d"};Arrays.stream(arr).peek(System.out::println) //a,b,c,d.count();// peek()+filter()Stream.of("L", "e", "o").filter(e -> e.length() > 2).peek(e -> System.out.println(e)).collect(Collectors.toList());
运行结果:
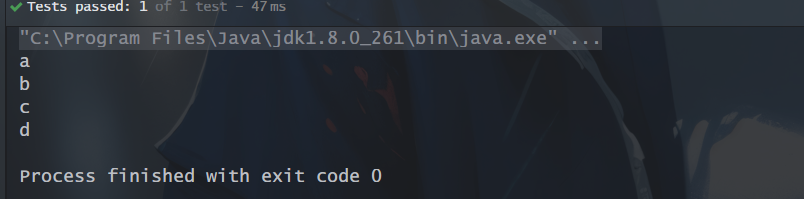
7、limit():顾名思义,返回指定数量的元素的流。返回的是Stream里前面的n个元素。
// limit():取出100中的前十个List<Integer> limitNum = IntStream.range(1,100).limit(10).boxed().collect(Collectors.toList());System.out.println(limitNum);// limit():取出前4个单词List<String> words = Arrays.asList("ma", "zhi", "chu", "wait", "you", "follow");List<String> limitWord = words.stream().limit(4).collect(Collectors.toList());System.out.println(limitWord);
运行结果:
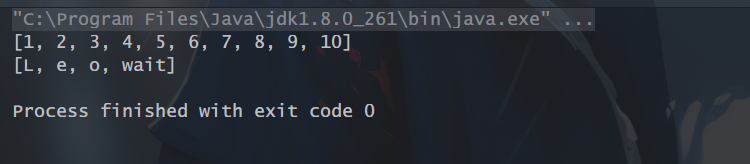
8、skip():和limit()相反,将前几个元素跳过(取出)再返回一个流,如果流中的元素小于或者等于n,就会返回一个空的流。
// skip():跳过前面三个单词再返回List<String> words = Arrays.asList("mg", "chi", "cldfkju", "wait", "you", "follow");List<String> skipWord = words.stream().limit(4).collect(Collectors.toList());System.out.println(skipWord);// skip():跳过全部单词再返回List<String> emptyWord = words.stream().skip(6).collect(Collectors.toList());System.out.println(emptyWord);// skip():跳过超过单词长度的数目再返回List<String> emptyWord2 = words.stream().skip(10).collect(Collectors.toList());System.out.println(emptyWord);
运行结果:

5.Stream流的终结操作
Stream流的终端操作主要有以下几种,我们来一一讲解。
- forEach()
- forEachOrdered()
- toArray()
- reduce()
- collect()
- min()
- max()
- count()
- anyMatch()
- allMatch()
- noneMatch()
- findFirst()
- findAny()
终端操作代码实例详解
1、forEach():遍历流中的每一个元素,按照指定的方法执行,执行顺序不一定按照流的顺序。
// foreach:遍历流中每一个元素,执行顺序按照流的顺序
Stream.of(1,2,3,4,5,6).forEach(System.out::println);
// foreach:遍历流中每一个元素,执行顺序不一定按照流的顺序,.parallel()表示创建一个并行流
Stream.of(1,2,3,4,5,6).parallel().forEach(System.out::println);
运行结果:
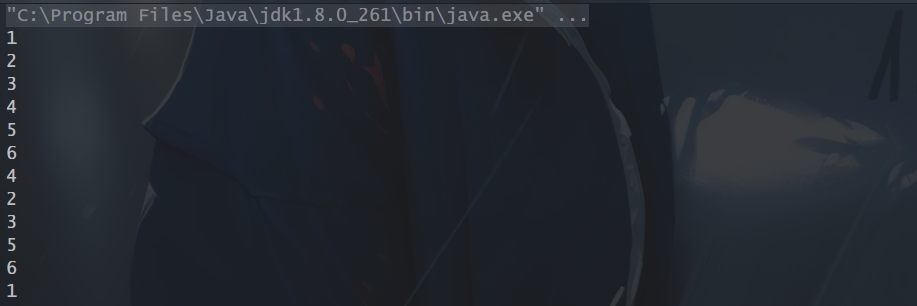
2、forEachOrdered():遍历流中的每一个元素,按照指定的方法执行,执行顺序按照流的顺序。
// forEachOrdered():遍历流中每一个元素,执行顺序按照流的顺序
Stream.of(1,2,3,4,5,6).forEachOrdered(System.out::println);
// forEachOrdered:遍历流中每一个元素,执行顺序按照流的顺序,.parallel()表示创建一个并行流
Stream.of(1,2,3,4,5,6).parallel().forEachOrdered(System.out::println);
运行结果:

3、toArray():将流中的元素放入到一个数组中
// toArray():将流中的元素放入到一个数组中
String[] strings = Stream.of("ma", "zhi", "chu").toArray(String[]::new);
System.out.println(Arrays.toString(strings));
运行结果:

4、reduce():这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。
// reduce():字符串拼接
String reduceStr1 = Stream.of("ma", "zhi", "chu").reduce("", String::concat);
String reduceStr2 = Stream.of("ma", "zhi", "chu").reduce("", (x,y)->x+y);
System.out.println(reduceStr1);
System.out.println(reduceStr2);
// reduce():求和,identity(起始值)为0
Integer total1 = Stream.of(1,2,3,4).reduce(0, Integer::sum);
Integer total2 = Stream.of(1,2,3,4).reduce(0, (x, y) -> x +y);
System.out.println(total1);
System.out.println(total2);
// 求和,sumValue = 10, 无起始值
Integer total3 = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
System.out.println(total3);
// reduce():求最小值
double minValue = Stream.of(-1.1, 8.8, -2.2, -6.6).reduce(Double.MAX_VALUE, Double::min);
System.out.println(minValue);
运行结果:
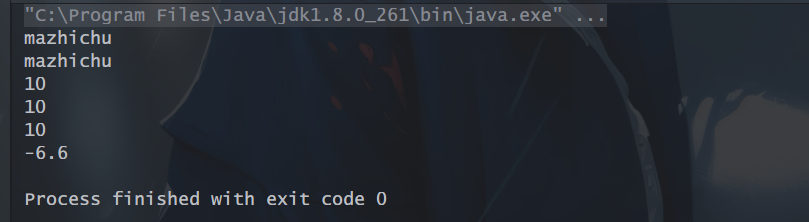
5、collect():是Stream的一个函数,负责收集流。前面我们说中间操作是将一个流转换成另一个流,这些操作是不消耗流的,但是终端操作会消耗流,产生一个最终结果,collect()就是一个规约操作,将流中的结果汇总。结果是由传入collect()中的Collector定义的。
// collect():负责收集流,将结果汇总,比如将下面的流中的结果汇总到一个集合中去
List<Integer> skipNum = IntStream.range(1,100).skip(90)
.boxed()
.collect(Collectors.toList());
System.out.println(skipNum);
运行结果:

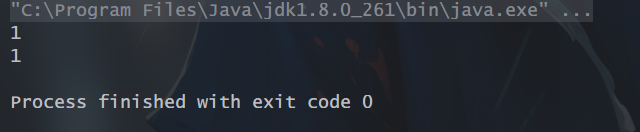
6、min():返回流中的最小值
// min():返回流中的最小值List<Integer> nums = Arrays.asList(1, 2, 3, 4, 5, 6);Integer minNum = nums.stream().min(Integer::compareTo).get();Integer min = nums.stream().min((x,y) -> x.compareTo(y)).get();System.out.println(minNum);System.out.println(min);
运行结果:
7、max():返回流中的最大值
// max():返回流中的最大值
List<Integer> num = Arrays.asList(1, 2, 3, 4, 5, 6);
Integer maxNum = num.stream().max(Integer::compareTo).get();
Integer max = num.stream().max(Comparator.comparing(Function.identity())).get();
System.out.println(maxNum);
System.out.println(max);
运行结果:

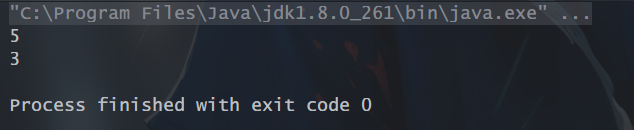
8、count():返回流中元素的数量
// count():返回流中元素的数量
List<Integer> ls = Arrays.asList(1,2,3,4,5);
long count = ls.stream().count();
long count1 = ls.stream().filter(l -> l > 2).count();
System.out.println(count);
System.out.println(count1);
运行结果:
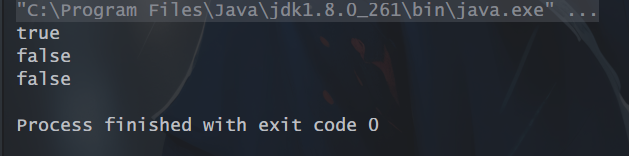
9、anyMatch():Stream 中只要有一个元素符合传入的断言,就返回 true,否则返回false。
// anyMatch():判断流中数据是否有一个复合断言
List<Integer> ins = Arrays.asList(1,2,3,4,5);
boolean b = ins.stream().anyMatch(l -> l > 2);
boolean b1 = ins.stream().anyMatch(l -> l > 5);
System.out.println(b);
System.out.println(b1);
// anyMatch():判断流中数据是否有一个复合断言,如果流为空,永远返回false
List<Integer> inss = Arrays.asList();
boolean b2 = inss.stream().anyMatch(l -> l > 2);
System.out.println(b2);
运行结果:
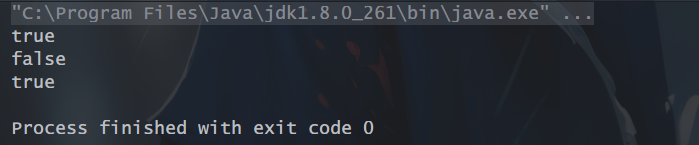
10、allMatch():Stream 中所有元素都符合传入的断言时返回 true,否则返回false,流为空时总是返回true。
// allMatch():判断流中元素是否都符合断言条件
List<Integer> ints = Arrays.asList(1,2,3,4,5);
boolean c = ints.stream().allMatch(l -> l > 0);
boolean c1 = ints.stream().allMatch(l -> l > 1);
System.out.println(c);
System.out.println(c1);
// allMatch():判断流中元素是否都符合断言条件,如果流为空,永远返回true
List<Integer> emptyList = new ArrayList<>();
boolean c2 = emptyList.stream().allMatch(e -> e > 1);
System.out.println(c2);
运行结果:
11、noneMatch():Stream 中所有元素都不满足传入的断言时返回 true,否则返回false。
// noneMatch():判断流中元素是否都不符合传入的断言条件
List<Integer> numList = Arrays.asList(1,2,3,4,5);
boolean d = numList.stream().noneMatch(l -> l > 6);
boolean d1 = numList.stream().noneMatch(l -> l > 1);
System.out.println(d);
System.out.println(d1);
// noneMatch():判断流中元素是否都不符合传入的断言条件,流为空时永远返回true
List<Integer> numist = Arrays.asList();
boolean d2 = numist.stream().noneMatch(l -> l > 6);
System.out.println(d2);
运行结果:
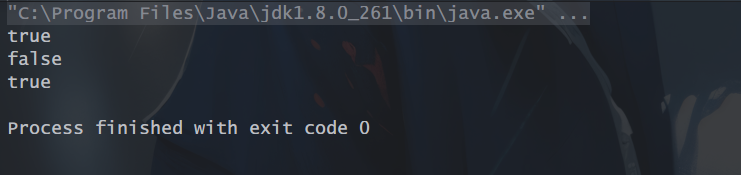
12、findFirst():总是返回流中的第一个元素,如果流为空,返回一个空的Optional.
// findFirst():返回流中的第一个元素
List<Integer> integers = Arrays.asList(1, 2, 3);
Optional<Integer> first = integers.stream().findFirst();
System.out.println(first);
System.out.println(first.isPresent()); // 判断是否不等于null,isPresent()相当于!=null的判断
System.out.println(first.get());
//findFirst():返回流中的第一个元素,如果流为空,返回一个空的Optional
List<Integer> lls = Collections.EMPTY_LIST;
Optional<Integer> first1 = lls.stream().findFirst();
System.out.println(first1);
System.out.println(first1.isPresent());
运行结果:
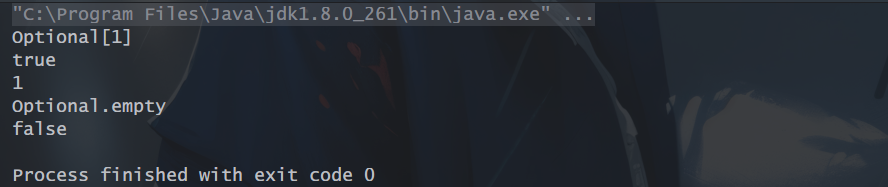
13、findAny():返回流中的任意一个元素即可,如果流为空,返回一个空的Optional.
// findAny():返回流中任意一个元素,
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
Optional<Integer> any = list.stream().findAny();
// 并行流下每次返回的结果会不同
// Optional<Integer> any = list.stream().parallel().findAny();
System.out.println(any);
System.out.println(any.isPresent());
System.out.println(any.get());
// findAny():返回流中任意一个元素,如果流为空,返回一个空的Optional
List<Integer> list1 = Arrays.asList();
Optional<Integer> any1 = list1.stream().findAny();
System.out.println(any1);
System.out.println(any1.isPresent());
运行结果:
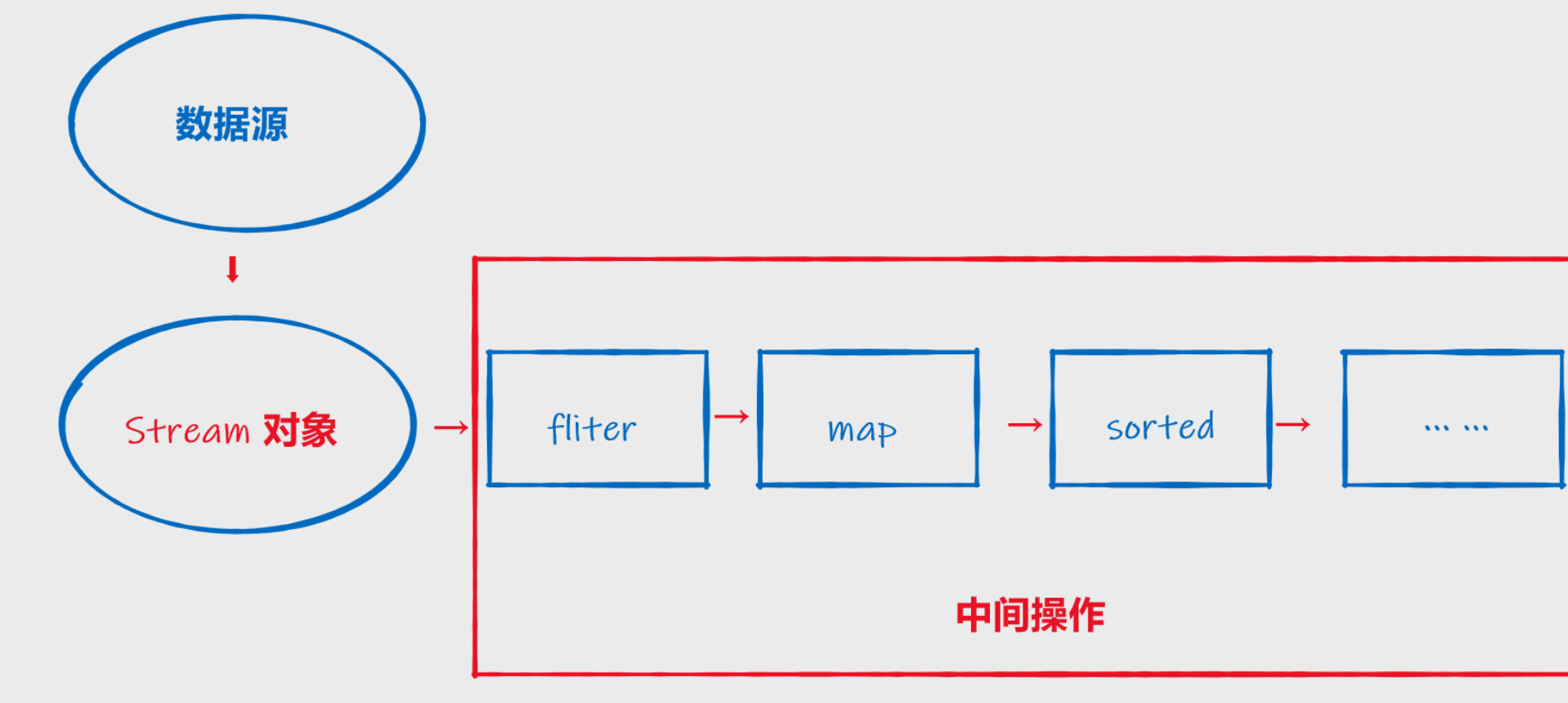
6.Stream操作三步曲
6.1 创建Stream
一个数据源(如:集合、数组),获取一个Stream流

6.2 中间操作
在流的传输过程中,对Stream流进行处理

1.查询

2.筛选与切片

3.映射

4.排序

comparable:自然排序
终端操作:终止操作返回的是一个结果,就是所有中间操作做完之后进行的操作,比如汇总、遍历输出、求和等等
下图展示了Stream的执行流程:
6.3 终结操作

7.并行流
并行流是 Java 8 Stream API 中的一个特性。它可以将一个流的操作在多个线程上并行执行,以提高处理大量数据时的性能。
在传统的顺序流中,所有的操作都是在单个线程上按照顺序执行的。而并行流则会将流的元素分成多个小块,并在多个线程上并行处理这些小块,最后将结果合并起来。这样可以充分利用多核处理器的优势,加快数据处理的速度。
要将一个顺序流转换为并行流,只需调用流的 parallel() 方法即可。示例代码如下所示:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream().parallel().forEach(System.out::println);
在这个示例中,我们创建了一个包含整数的 List,并通过 stream() 方法将其转换为流。接着调用 parallel() 方法将流转换为并行流,然后使用 forEach 方法遍历流中的元素并输出。
需要注意的是,并行流的使用并不总是适合所有情况。并行流的优势主要体现在数据量较大、处理时间较长的场景下。对于小规模数据和简单的操作,顺序流可能更加高效。在选择使用并行流时,需要根据具体情况进行评估和测试,以确保获得最佳的性能。
此外,还需要注意并行流在某些情况下可能引入线程安全的问题。如果多个线程同时访问共享的可变状态,可能会导致数据竞争和不确定的结果。因此,在处理并行流时,应当避免共享可变状态,或采用适当的同步措施来确保线程安全。
7.1 如何使用并行流提高性能
使用并行流可以通过利用多线程并行处理数据,从而提高程序的执行性能。下面是一些使用并行流提高性能的常见方法:
-
创建并行流:要创建一个并行流,只需在普通流上调用
parallel()方法。List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); Stream<Integer> parallelStream = numbers.parallelStream(); -
利用任务并行性:并行流会将数据分成多个小块,并在多个线程上并行处理这些小块。这样可以充分利用多核处理器的优势。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); numbers.parallelStream().map(n -> compute(n)) // 在多个线程上并行处理计算.forEach(System.out::println);在这个示例中,使用
map方法对流中的每个元素进行计算。由于并行流的特性,计算操作会在多个线程上并行执行,提高了计算的效率。 -
避免共享可变状态:在并行流中,多个线程会同时操作数据。如果共享可变状态(如全局变量)可能导致数据竞争和不确定的结果。因此,避免在并行流中使用共享可变状态,或者采取适当的同步措施来确保线程安全。
-
使用合适的操作:一些操作在并行流中的性能表现更好,而另一些操作则可能导致性能下降。一般来说,在并行流中使用基于聚合的操作(如
reduce、collect)和无状态转换操作(如map、filter)的性能较好,而有状态转换操作(如sorted)可能会导致性能下降。List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); // good performance int sum = numbers.parallelStream().reduce(0, Integer::sum); // good performance List<Integer> evenNumbers = numbers.parallelStream().filter(n -> n % 2 == 0).collect(Collectors.toList()); // potential performance degradation List<Integer> sortedNumbers = numbers.parallelStream().sorted().collect(Collectors.toList());在这个示例中,
reduce和filter的操作在并行流中具有良好的性能,而sorted操作可能导致性能下降。
除了上述方法,还应根据具体情况进行评估和测试,并行流是否能够提高性能。有时候,并行流的开销(如线程的创建和销毁、数据切割和合并等)可能超过了其带来的性能提升。因此,在选择使用并行流时,应该根据数据量和操作复杂度等因素进行综合考虑,以确保获得最佳的性能提升。
7.2 并行流的适用场景和注意事项
-
大规模数据集:当需要处理大规模数据集时,使用并行流可以充分利用多核处理器的优势,提高程序的执行效率。并行流将数据切分成多个小块,并在多个线程上并行处理这些小块,从而缩短了处理时间。
-
复杂的计算操作:对于复杂的计算操作,使用并行流可以加速计算过程。由于并行流能够将计算操作分配到多个线程上并行执行,因此可以有效地利用多核处理器的计算能力,提高计算的速度。
-
无状态转换操作:并行流在执行无状态转换操作(如
map、filter)时表现较好。这类操作不依赖于其他元素的状态,每个元素的处理是相互独立的,可以很容易地进行并行处理。
并行流的注意事项包括:
-
线程安全问题:并行流的操作是在多个线程上并行执行的,因此需要注意线程安全问题。如果多个线程同时访问共享的可变状态,可能会导致数据竞争和不确定的结果。在处理并行流时,应避免共享可变状态,或者采用适当的同步措施来确保线程安全。
-
性能评估和测试:并行流的性能提升并不总是明显的。在选择使用并行流时,应根据具体情况进行评估和测试,以确保获得最佳的性能提升。有时,并行流的开销(如线程的创建和销毁、数据切割和合并等)可能超过了其带来的性能提升。
-
并发操作限制:某些操作在并行流中的性能表现可能较差,或者可能导致结果出现错误。例如,在并行流中使用有状态转换操作(如
sorted)可能导致性能下降或结果出现错误。在使用并行流时,应注意避免这类操作,或者在需要时采取适当的处理措施。 -
内存消耗:并行流需要将数据分成多个小块进行并行处理,这可能导致额外的内存消耗。在处理大规模数据集时,应确保系统有足够的内存来支持并行流的执行,以避免内存溢出等问题。
8.总结
以上便是本文的全部内容,本人才疏学浅,文章有什么错误的地方,欢迎大佬们批评指正!我是Leo,一个在互联网行业的小白,立志成为更好的自己。
如果你想了解更多关于Leo,可以关注公众号-程序员Leo,后面文章会首先同步至公众号。
相关文章:
Java基础篇 | Java8流式编程
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: Java从入门到精通 ✨特色专栏…...
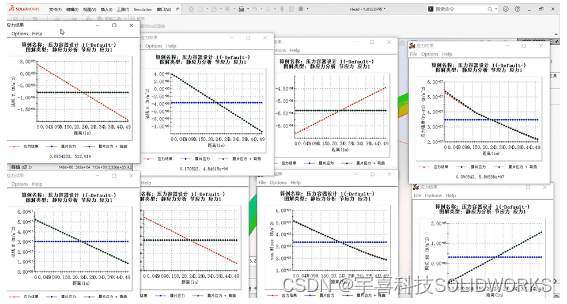
SolidworksSimulation完成对压力容器的强度分析
如何通过使用SolidworksSimulation完成对压力容器的分析并查看实 体的膜片应力强度以及弯曲应力强度,操作简单易学,让我们进入到操作界面。 我们以罐体底部实体模型为例,这里已经提前设置好了材料。 点击新算例,选择静应力分析 由…...
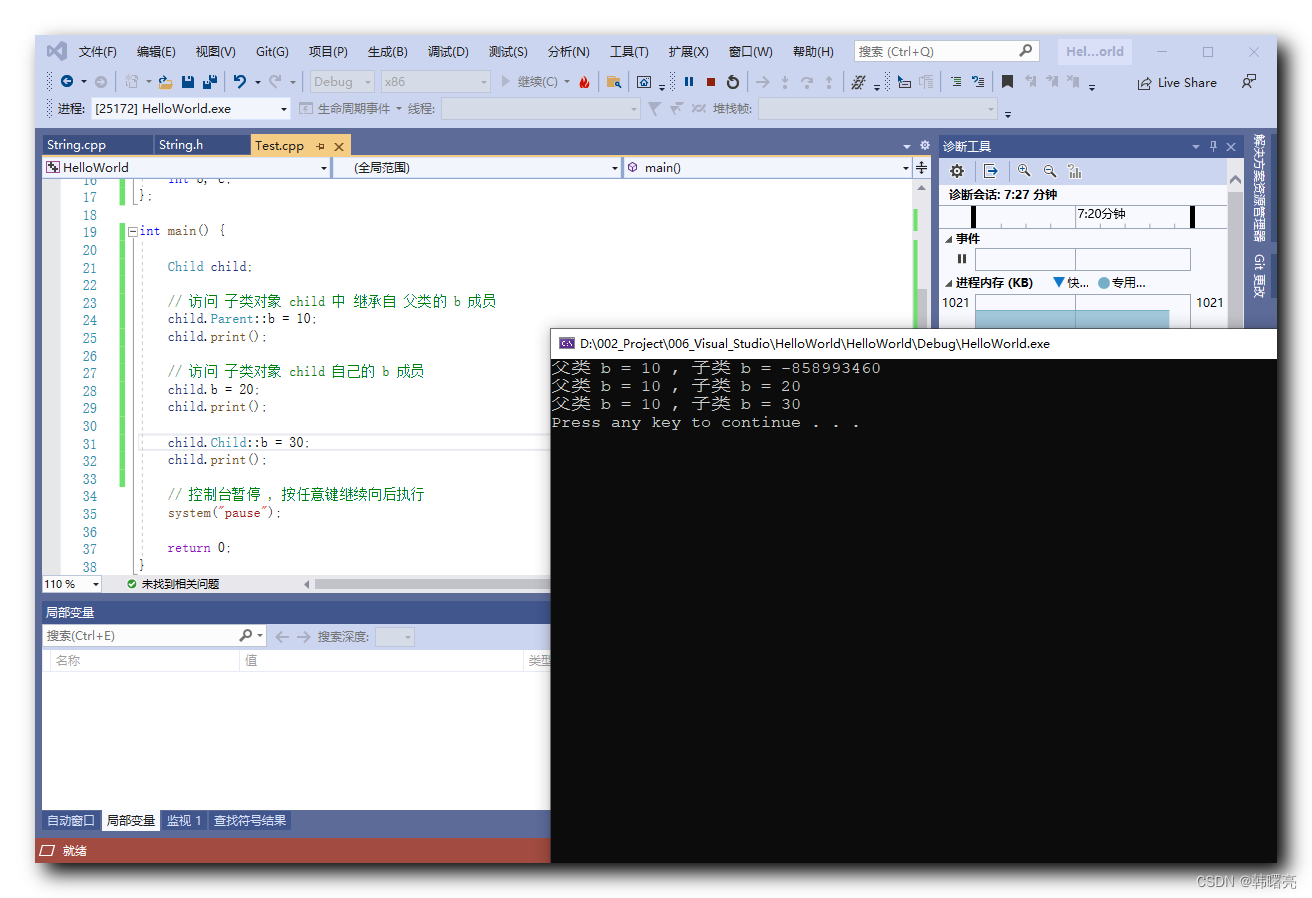
【C++】继承 ⑨ ( 继承中成员变量同名的处理方案 )
文章目录 一、继承中成员变量同名的处理方案1、继承中成员变量同名的场景说明2、使用域作用符区分同名成员变量 二、代码示例 - 继承中成员变量同名的处理方案 一、继承中成员变量同名的处理方案 1、继承中成员变量同名的场景说明 子类 继承 父类 的 成员 , 如果 子类 中定义了…...
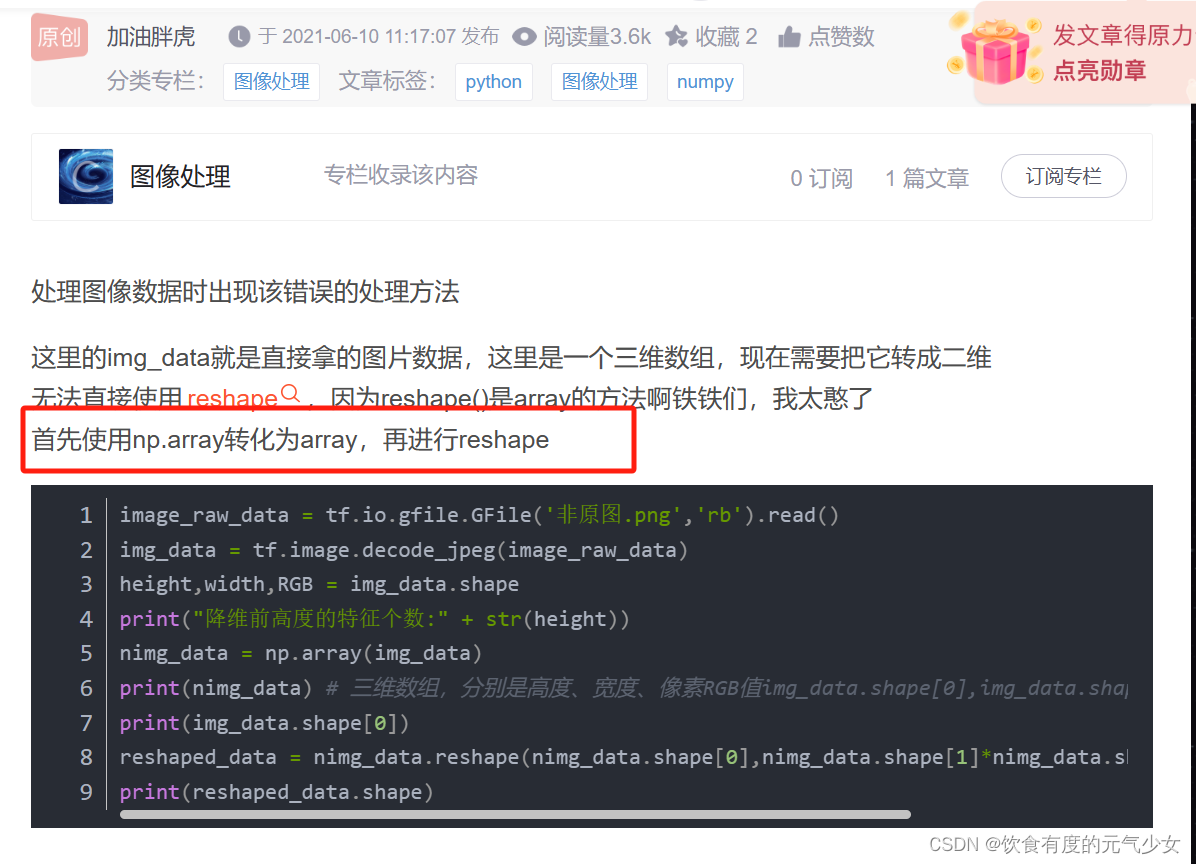
Python报错:‘EagerTensor‘ object has no attribute ‘reshape‘
在使用RPython时,发现python代码部分报错:‘EagerTensor‘ object has no attribute ‘reshape‘ 如何解决? 使用np.array 转换为array,再进行reshape 参考: ‘EagerTensor‘ object has no attribute ‘reshape‘处…...

docker-compose手册
大家好,我叫徐锦桐,个人博客地址为www.xujintong.com。平时记录一下学习计算机过程中获取的知识,还有日常折腾的经验,欢迎大家访问。 前言 一些自己经常用到的docker-compose知识。 一、运行和启动项目 1.1、docker-compose运行…...
)
【珠峰 WEB 前端架构师课程】学习笔记 100 篇(完结)
该课程是珠峰姜文老师讲的,个人觉得讲的很不错,一路在 b 站学习下来做了 100 篇的学习笔记,收获颇丰。 该课程主要讲了高阶函数、函数柯里化、发布订阅模式、观察者模式、从 0 到 1 实现一个 promise,co 库的实现、eventloop 执行…...
、wait()、yield()、join()方法的使用)
Java线程中sleep()、wait()、yield()、join()方法的使用
1.sleep() sleep(): sleep 方法属于 Thread 类,该行为中线程不会释放锁,只阻塞线程,让出cpu给其他线程,当达到指定的时间后会自动恢复运行状态继续运行。 2.wait() wait(): 该方法属于 Object 类,在这个过程里线程会…...

【机器学习】数据均衡学习笔记
文章目录 序言1. 样本不均衡2. 样本不均衡的影响以及样本均衡的意义3. 什么时候需要进行样本均衡/数据均衡4. 数据不均衡的解决办法 序言 数据集制作过程中需要关注样本均衡问题,学习笔记,简单记录 1. 样本不均衡 分类任务中不同类别样本数差别很大的…...

【软件教程】如何用C++交叉编译出能在Android运行的ELF程序或so动态库
一、配置NDK交叉编译平台 1. 打开Android的官方ndk下载链接https://developer.android.com/ndk/downloads?hlzh-cn,下载windows 64位ndk环境包。 2. 解压后将具有以下文件的路径加入到系统环境变量。 3. 配置好环境变量,如下图所示,Path中存…...
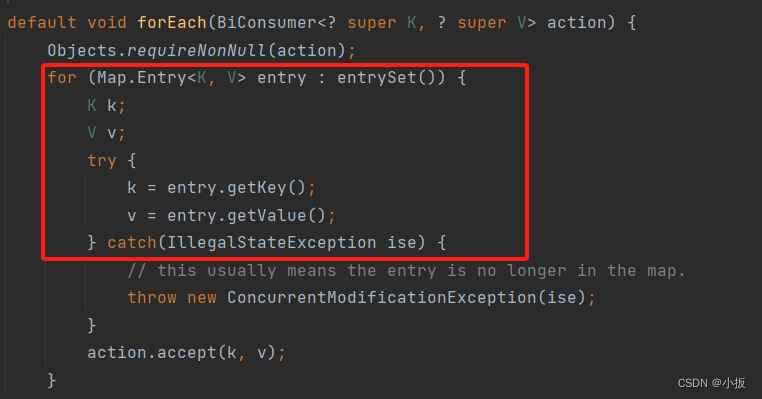
进阶JAVA篇- Map 系列集合的遍历方法与常用API
目录 1.0 Map 集合的说明 1.1 Map 集合的常用方法 1.2 Map 系列集合的特点 2.0 Map 系列集合的遍历方法(三种方法) 2.1 使用 keySet() 方法遍历 2.2 使用 entrySet() 方法遍历 2.3 使用 forEach() 方法遍历(Java 8) 1.0 Map 集合的…...

Auth.js:多合一身份验证解决方案 | 开源日报 No.60
nodejs/node Stars: 96.2k License: NOASSERTION Node.js 是一个开源的、跨平台的 JavaScript 运行时环境。它具有以下关键特性和核心优势: 强大:Node.js 提供了强大且高效的服务器端运行能力,可以处理并发请求,并支持异步编程…...
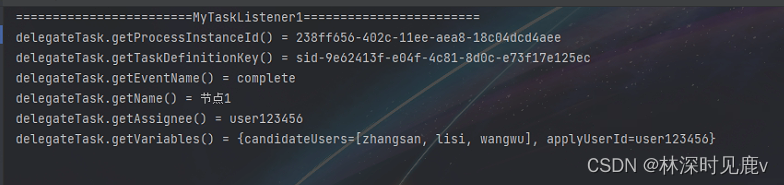
SpringBoot整合Activiti7——任务监听器(七)
文章目录 一、任务监听器事件类型配置方式(选)代码实现xml文件创建监听器class方式expression方式delegateExpression 测试流程部署流程启动流程完成任务 一、任务监听器 任务监听器可以在任务创建、任务分配、任务完成、任务删除发生时触发,从而执行相应的逻辑。 事…...
电解电容寿命与哪些因素有关?
电解电容在各类电源及电子产品中是不可替代的元器件,这些电子产品中由于应用环境的原因,使它成为最脆弱的一环,所以,电解电容的寿命也直接影响了电子产品的使用寿命。 一、电解电容失效模式与因素概述 铝电解电容器正极、负极引出…...
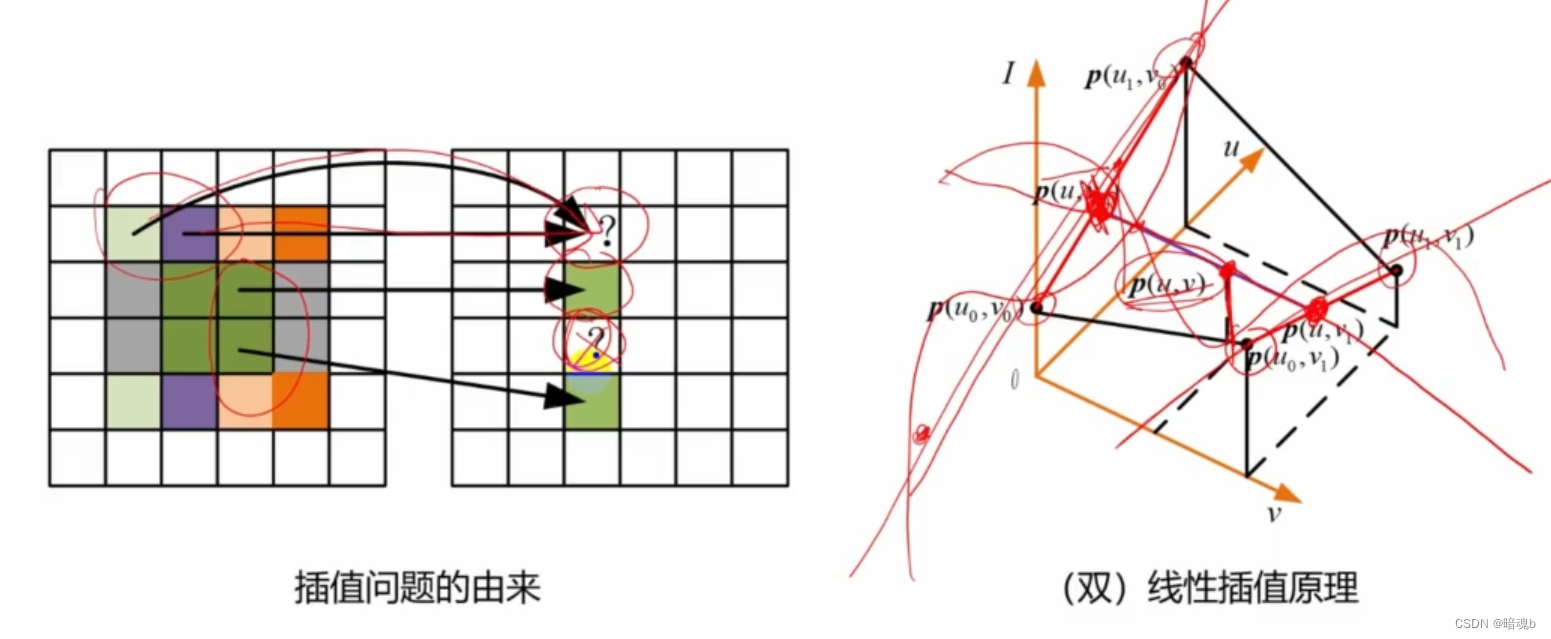
Opencv-图像插值与LUT查找表
图像像素的比较 白色是255,黑色是0 min(InputArray src1,InputArray src2,OutputArray dst) max(InputArray src1,InputArray src2,OutpurArray dstsrc1:第一个图像矩阵,通道数任意src2:第二个图像矩阵,尺寸和通道数以及数据类型…...

我为什么写博客?写博客给我带来了什么?
1、写博客的契机 (1)刚开始接触CSDN,是大三的时候开始学习嵌入式开发,经常需要到网上百度查资料,由此经常游览CSDN上的博客; (2)在嵌入式的过程中,需要总结学习过的知识。…...

jdk11的HttpClient
我们都知道在jdk11之前都在用okhttp或者org.apache.httpcomponents 其实早在jdk9的时候这个方案就在孵化中 上面的截图来自openjdk的官网,注:openjdk是个开源项目,不存在侵权现象 这是openjdk的官网:JEP 110: HTTP/2 Client (In…...

Redis的优势
高性能 Redis是一种基于内存的数据存储系统,读写性能非常高,因此适用于对性能要求较高的应用场景。 数据结构丰富 Redis支持多种数据结构,如字符串、列表、集合、散列、有序集合等,可以满足不同的业务需求。还有一些特殊数据结…...
C++ string 类的其他操作
4.3.2 string 类的其他操作 在C新增string类之前,程序员也需要完成诸如给字符串赋值等工作。对于C语言式的字符串,程 序员使用C语言库中的函数来完成这些任务。头文件cstring(以前为string.h)提供了这些函数。例如,可 以使用函数 strcpy()将字符串复制到字符数组中,使用函数…...
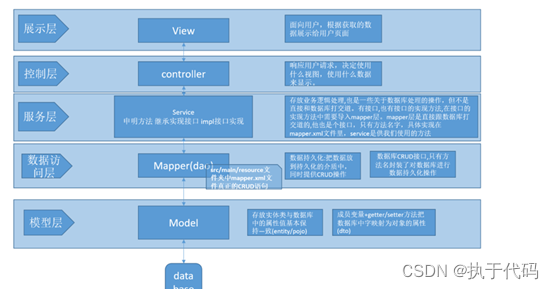
structs2 重构成SpringBoot架构
# 目录 structs2 重构成SpringBoot架构 1.1 structs2架构: 1.2 springboot 架构 1.3 演化要点: 1.基于前端的展示层不需要修改 2.HttpServlet 将会有SpringBoot annotation 来处理 3.构建前置的Structs url 转发器,适配 4.ActionSupport将由…...
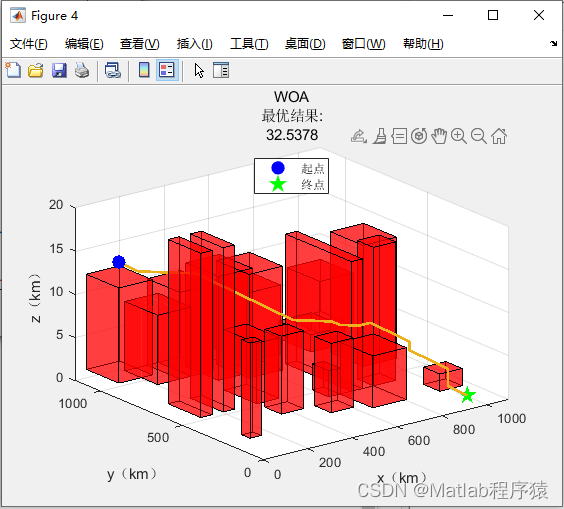
【MATLAB源码-第56期】基于WOA白鲸优化算法和PSO粒子群优化算法的三维路径规划对比。
操作环境: MATLAB 2022a 1、算法描述 1.粒子群算法(Particle Swarm Optimization,简称PSO)是一种模拟鸟群觅食行为的启发式优化方法。以下是其详细描述: 基本思想: 鸟群在寻找食物时,每只鸟都…...

统一游戏模组管理:如何用XXMI Launcher告别多工具切换的烦恼
统一游戏模组管理:如何用XXMI Launcher告别多工具切换的烦恼 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 你是否曾经为了管理不同游戏的模组而需要在多个工具间来…...

【深度学习新浪潮】OpenClaw架构与技术关键点全解析:为什么它能成功,而前代框架纷纷折戟?
引言 在AI Agent从概念走向落地的过程中,AutoGPT、LangChain早期版本、BabyAGI等框架一度掀起热潮,但始终难以实现规模化、稳定化的实际生产落地。OpenClaw作为MIT主导开源的本地优先AI执行网关,上线后迅速成为现象级开源项目,其核…...
-适用于电厂运行数据预测及Ex...)
ACO-KELM回归预测算法MATLAB代码(主程序+清晰注释)-适用于电厂运行数据预测及Ex...
ACO蚁群算法优化KELM核极限学习机(ACO-KELM)回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,容易上手。 (电厂运行数据为例)老铁们今天带大家玩点硬核的——用蚂蚁找食物的…...

技术赋能旧设备:OpenCore Legacy Patcher让Mac重获新生
技术赋能旧设备:OpenCore Legacy Patcher让Mac重获新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当您的Mac设备被苹果官方系统升级列表排除…...

深入解析gqlalchemy的唯一性约束
在使用gqlalchemy的对象图映射(OGM)和Cypher查询时,如何正确处理节点属性的唯一性约束是一个常见但易混淆的问题。本文将通过一个具体的供应链实体建模的实例,详细解释这些约束的应用和可能遇到的坑。 背景介绍 假设我们正在构建一个供应链管理系统,其中包含制造商、供应…...

会呼吸的防水:如何告别“闷热背包”的尴尬?
传统防水背包常被诟病为“塑料雨衣”——外部雨水进不来,内部汗气出不去。现代防水技术的真正突破,在于实现了“防水”与“透气”的完美平衡。这背后,是一场关于微孔薄膜的智慧博弈。 透气性原理:分子尺度的精妙设计优质防水膜的关…...

告别暴力搜索!用DiffDock的扩散模型5分钟搞定分子对接,效率提升12倍
5分钟颠覆传统:DiffDock如何用扩散模型重构分子对接效率天花板 在药物研发的漫长链条中,分子对接就像一把精准的钥匙开锁过程——需要找到小分子配体与靶标蛋白最契合的三维结合方式。传统方法如同盲人摸象,耗费数小时在亿万种可能中暴力搜索…...

正式支持 Spring Boot 4、新增 Jackson3/Snack4 插件适配
目前最新版本 v1.45.0 已推送至 Maven 中央仓库 🎉,大家可以通过如下方式引入: <!-- Sa-Token 权限认证 --> <dependency><groupId>cn.dev33</groupId><artifactId>sa-token-spring-boot4-starter</artifa…...
)
JLink V9固件烧写实战:从拆解到短接的完整操作手册(含DFU模式驱动安装)
JLink V9固件烧写实战:从拆解到短接的完整操作手册(含DFU模式驱动安装) 当你的JLink V9调试器突然"罢工",指示灯不再亮起,很可能是固件损坏导致的。这种情况在频繁使用或不当操作后并不罕见。本文将带你一步…...

终极Windows 11优化指南:如何用Win11Debloat让电脑提速70%的完整教程
终极Windows 11优化指南:如何用Win11Debloat让电脑提速70%的完整教程 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to de…...