【自然语言处理】Topic Coherence You Need to Know(主题连贯度详解)
Topic Coherence You Need to Know
皮皮,京哥皮皮,京哥皮皮,京哥CommunicationUniversityofChinaCommunication\ University\ of\ ChinaCommunication University of China
在大多数关于主题建模的文章中,常用主题连贯度(Topic Coherence,主题一致性)或主题连贯度指标(Topic Coherence Metrics)来表示整体主题的可解释性,用于评估主题的质量。
但是,该指标到底指什么?它是如何衡量主题的可解释性的?该值是否越大越好?本文将就这些问题做出解答。
1.主题建模
主题建模将文本数据集分解为主题和单词这两个分布来进行解释。一般基于以下假设:
- 一个文档由几个主题组成
- 一个主题由一组单词组成
因此,可以将主题建模算法理解为一种数学上的统计模型,用于推断哪些主题更能代表数据。
简单来说,主题可以被描述为单词的集合,例如 [ball, cat, house] 和 [airplane, clouds]。但实际上,算法要做的是为我们词汇表中的每个单词分配一个给定主题的参与值。具有高参与值的单词可以被视为该主题的代表。

2.评估主题
主题建模算法基于数学和统计学。但站在人的视角,数学上最优的主题并不一定是最好的主题。
例如,根据主题建模算法得到以下两个主题:
- Topic 1:
cat,dog,home,toy(可能是个好的主题) - Topic 2:
super,nurse,brick(可能是个比较糟的主题)
从人的视角来看,第一个主题要比第二个主题更连贯,但对于算法而言,它们可能拥有相同的指标。
构建的主题应该是易于理解的。因此,盲目地遵循主题模型算法背后的数学原理可能会误导我们,并生成无意义的主题。
正因如此,主题评估工作通常需要人工参与,例如阅读每个主题中最重要的单词,查看与每个文档相关的主题。但是,对于具有数千个主题的大规模数据集,此任务可能非常耗时且不切实际。它还需要有关数据集领域的先验知识,并且可能需要专家意见。
主题连贯度试图以 独特、客观且易于评估的数字 来代表对主题的 高质量人类感知。
3.如何计算主题连贯性
通常,连贯性指的是 合作特征。如果一组论点相互印证,我们可以认为它们是连贯的。
此处,主题连贯性指的是文本集(称为参考语料库,reference corpus)支持 主题的程度。它从参考语料中提取统计数据和概率,并特别关注单词的上下文,计算主题连贯性分数。这也说明主题连贯性度量不仅取决于主题本身,还取决于参考语料。

Röder, M. 等人在论文《Exploring the Space of Topic Coherence Measures》中提出了主题连贯性度量的一般结构如下:

该结构由不同的独立模块组合而成,每个模块都执行特定的任务。
可以把计算主题连贯性度量看做是一个管道(Pipeline),它接收主题和参考语料作为输入,并输出一个代表 整体主题连贯性 的值。该过程模拟了人类对主题进行评估。
3.1 Segmentation
该模块负责创建用来评估主题连贯性的单词子集。
假设 WWW 包含了主题 ttt 的前 nnn 个最重要的单词 {w1,w2,…,wn}\{w_1, w_2, …, w_n\}{w1,w2,…,wn},对 WWW 的进行分割,得到子集对 SSS。

W∗W^*W∗ 用于对 W′W^{'}W′ 进行确认。下一小节将会结合实例对此进行介绍。简单来说,分割可以理解为如何 混合 主题中的单词,以进行后面的评估步骤。
例如,S-one-one 表示对不同的词进行配对。此种模式下,模型对主题中任意两个词之间的关系感兴趣。所以,若 WWW 为 {‘cat’,‘dog’,‘toy’}\{‘cat’, ‘dog’, ‘toy’\}{‘cat’,‘dog’,‘toy’},则有:

而 S-one-all 则表示将每个词与其他所有词配对。此种模式下,连贯性分数将基于单个词与主题中其余词之间的关系。应用于 WWW,则有:

3.2 Probability Calculation
例如,假设我们对两种不同的概率感兴趣:
- P(w)P(w)P(w):词 www 出现的概率
- P(w1andw2)P(w1\ and\ w2)P(w1 and w2):词 w1w1w1 和 w2w2w2 出现的概率
针对这些概率有不同的计算方法,例如:
- PbdPbdPbd(bdbdbd 代表
boolean document):P(w)P(w)P(w) 表示包含单词 www 的文档数除以文档总数,P(w1andw2)P(w1\ and\ w2)P(w1 and w2) 表示包含单词 w1w1w1 和 w2w2w2 的文档数除以文档总数。 - PbsPbsPbs(bsbsbs 代表
boolean sentence),该方法与 PbdPbdPbd 方法类似,但它考虑的是单词在句子中的出现次数,而不是文档中的出现次数。 - PswPswPsw(swswsw 代表
sliding window),它考虑的是单词在文本滑动窗口中出现的次数。
3.3 Confirmation Measure
该步骤是计算主题连贯性的核心。用从 PPP 中得到的概率在 SSS 上计算确认度量,即用从语料库计算的概率来量化两个子集之间的 关系。
此步骤会计算 W∗W^{*}W∗ 对 W′W^{'}W′ 的支持程度。因此,如果 W′W^{'}W′ 中的词与 W∗W^{*}W∗ 中的词相关联(例如,经常出现在同一文档中),则确认度会很高。

上图中,确认度量 mmm 应用于每一个子集对,并输出确认分数。有两种不同类型的确认措施:
- 直接确认措施:这些度量通过直接使用子集 W′W^{'}W′ 和 W∗W^{*}W∗ 以及概率来计算确认值。例如:



- 间接确认措施:间接确认措施不会直接根据 W′W^{'}W′ 和 W∗W^{*}W∗ 计算分数。它们计算 W′W^{'}W′ 中的单词和 WWW 中所有其他单词的直接确认度量 mmm,构建了一个度量向量,如下图所示。再对 W∗W^{*}W∗ 进行相同的处理。最后以这两个向量之间的相似性(例如,余弦相似性)作为最后的确认度量结果。

![]()
例如,为了计算 (‘cat’,‘dog’)(‘cat’,‘dog’)(‘cat’,‘dog’) 的确认度量,首先计算每个元素和主题中所有单词的确认度量 mmm ,创建一个确认度量向量。然后,最终的确认措施是这两个向量之间的相似性。

该过程表明了直接方法的一些缺点。例如,cat 和 dog 这两个词可能永远不会在我们的数据集中出现,但它们可能经常与 toy、pets 和 cute 这些词一起出现。使用直接方法,这两个词的确认分数较低,但使用间接方法,相似性可能会很突出,因为它们出现在相似的上下文中。
3.4 Aggregation
此处会将上一步计算的所有值聚合成一个值,即最终的主题连贯性分数。聚合方法可以是 算术平均数、中位数、几何平均数 等。

3.5 小结
回顾一下上述步骤。
- 有一个待评估的主题
- 选择一个参考语料库
- 找到主题中最重要的前 nnn 个词,记为 WWW
- 将 WWW 分割成子集对 SSS
- 利用参考语料库,使用技术 PPP 计算单词概率
- 使用确认度量 mmm 来评估每个子集对之间的关系
- 汇总得到一个最终数字,即主题连贯性得分

在多个主题的情况下,最终结果是单个主题连贯性的平均值。

4.Gensim中的模型
Gensim 提供了四种计算主题连贯性的方法:u_mass、c_v、c_uci、c_npmi。

在原论文中,作者已经详细说明了这些模型是如何构建的。

以 C_NPMI 为例:
Segmentation:采用S-one-one的方法,即在成对的词上计算确认度。Probability Calculation:使用方法 Psw(10)Psw(10)Psw(10)。滑动窗口的大小为 101010。Confirmation Measure:确认措施是归一化逐点互信息(NPMI)。

Aggregation:利用算术平均值进行聚合。
C_V 方法同理:
Segmentation:采用S-one-set的方法,即确认度量将在一个词和集合 WWW 的对上计算。Probability Calculation:使用方法 Psw(110)Psw(110)Psw(110)。滑动窗口大小为 110110110。Confirmation Measure:该步使用间接确认措施。使用度量 mnlrm_{nlr}mnlr,将每对元素的单词与 WWW 的所有其他单词进行比较。最终得分是两个度量向量之间的余弦相似度。Aggregation:利用算术平均值进行聚合。
5.实践
import pandas as pd
import reimport matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_20newsgroupsfrom gensim.models.coherencemodel import CoherenceModel
from gensim.corpora.dictionary import Dictionary
texts, _ = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'), return_X_y=True )
tokenizer = lambda s: re.findall('\w+', s.lower() )
texts = [tokenizer(t) for t in texts]
在 Gensim 中计算 Coherence 非常简单,只需要创建一组主题并传递文本即可。
# Creating some random topics
topics = [ ['space', 'planet', 'mars', 'galaxy'],['cold', 'medicine', 'doctor', 'health', 'water'],['cats', 'health', 'keyboard', 'car', 'banana'],['windows', 'mac', 'computer', 'operating', 'system'] ]# Creating a dictionary with the vocabulary
word2id = Dictionary(texts)# Coherence model
cm = CoherenceModel(topics=topics, texts=texts,coherence='c_v', dictionary=word2id)coherence_per_topic = cm.get_coherence_per_topic()
.get_coherence_per_topic() 方法返回每个主题的连贯性值。
topics_str = ['\n '.join(t) for t in topics]
data_topic_score = pd.DataFrame(data=zip(topics_str, coherence_per_topic), columns=['Topic', 'Coherence'])
data_topic_score = data_topic_score.set_index('Topic')fig, ax = plt.subplots(figsize=(2,6))
ax.set_title("Topics coherence\n $C_v$")
sns.heatmap(data=data_topic_score, annot=True, square=True,cmap='Reds', fmt='.2f',linecolor='black', ax=ax )
plt.yticks(rotation=0)
ax.set_xlabel('')
ax.set_ylabel('')
fig.show()

6.总结
主题连贯性是衡量一个主题质量的重要标准。本文中,我们深入探讨了主题连贯性的基本结构和数学原理。通过 Segmentation、Probability Calculation、Confirmation Measure、Aggregation 等步骤计算主题连贯性。并通过代码实例了解了如何在 Gensim 中计算主题连贯性。
相关文章:
【自然语言处理】Topic Coherence You Need to Know(主题连贯度详解)
Topic Coherence You Need to Know皮皮,京哥皮皮,京哥皮皮,京哥CommunicationUniversityofChinaCommunication\ University\ of\ ChinaCommunication University of China 在大多数关于主题建模的文章中,常用主题连贯度ÿ…...

C++入门:模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。模板是创建泛型类或函数的蓝图或公式。库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用了模板的概念。每个容器都有一个单一的定义,…...
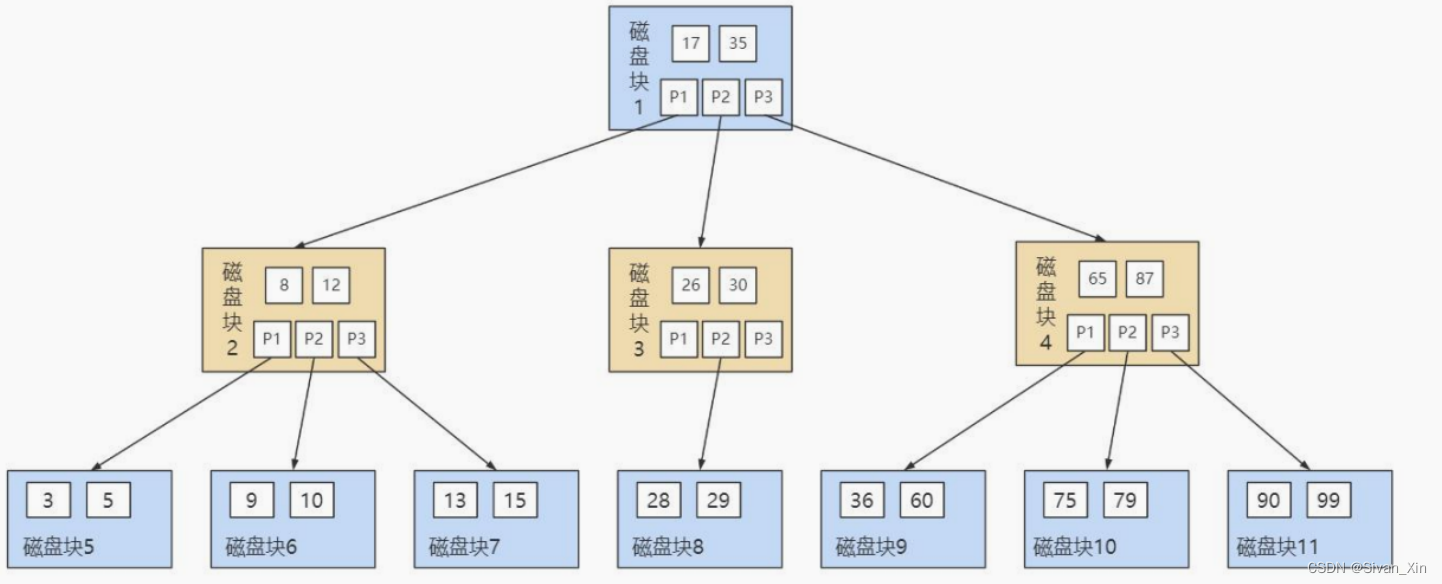
【MySQL】索引常见面试题
文章目录索引常见面试题什么是索引索引的分类什么时候需要 / 不需要创建索引?有什么优化索引的方法?从数据页的角度看B 树InnoDB是如何存储数据的?B 树是如何进行查询的?为什么MySQL采用B 树作为索引?怎样的索引的数…...

【Web逆向】万方数据平台正文的逆向分析(上篇--加密发送请求)—— 逆向protobuf
【Web逆向】万方数据平台正文的逆向分析(上篇--加密发送请求)—— 逆向protobuf声明一、了解protobuf协议:二、前期准备:二、目标网站:三、开始分析:我们一句句分析:先for循环部分:后…...

Amazon S3 服务15岁生日快乐!
2021年3月14日,作为第一个发布的服务,Amazon S3 服务15周岁啦!在中国文化里,15岁是个临界点,是从“舞勺之年”到“舞象之年”的过渡。相信对于 Amazon S3 和其他的云服务15周岁也将是其迎接更加美好未来的全新起点。亚…...

【python】函数详解
注:最后有面试挑战,看看自己掌握了吗 文章目录基本函数-function模块的引用模块搜索路径不定长参数参数传递传递元组传递字典缺陷,容易改了原始数据,可以用copy()方法避免变量作用域全局变量闭包closurenonlocal 用了这个声明闭包…...

AoP-@Aspect注解处理源码解析
对主类使用EnableAspectJAutoProxy注解后会导入组件, Import(AspectJAutoProxyRegistrar.class) public interface EnableAspectJAutoProxy {AspectJAutoProxyRegistrar类实现了ImportBeanDefinitionRegistrar接口中的registerBeanDefinitions()方法,此…...
宝塔搭建实战php悟空CRM前后端分离源码-vue前端篇(二)
大家好啊,我是测评君,欢迎来到web测评。 上一期给大家分享了悟空CRM server端在宝塔部署的方式,但是由于前端是用vue开发的,如果要额外开发新的功能,就需要在本地运行、修改、打包重新发布到宝塔才能实现功能更新&…...
FastASR+FFmpeg(音视频开发+语音识别)
想要更好的做一件事情,不仅仅需要知道如何使用,还应该知道一些基础的概念。 一、音视频处理基本梳理 1.多媒体文件的理解 1.1 结构分析 多媒体文件本质上可以理解为一个容器 容器里有很多流 每种流是由不同编码器编码的 在众多包中包含着多个帧(帧在音视…...

二分查找的实现代码JAVA
二分查找一、思路二、实现代码(普通版)三、整数溢出问题四、改进代码一、思路 1.前提: 有已排序数组A (假设已经做好) 2.定义左边界L、 右边界R,确定搜索范围,循环执行二分查找(3、4两步) 3.获取中间索引 M Floor((LR) 1/2) 4.中间素索引的值…...

cesium: 设置skybox透明并添加背景图 ( 003 )
第003个 点击查看专栏目录 本示例的目的是介绍如何在vue+cesium中设置skybox透明并添加背景图。 我们不想要黑乎乎的背景,想自定义一个背景图,然后前面显示地球。 直接复制下面的 vue+cesium源代码,操作2分钟即可运行实现效果. 文章目录 示例效果配置方式示例源代码(共70…...
【python】类的详解
注:最后有面试挑战,看看自己掌握了吗 文章目录PO verses OOPOOO当一个类很复杂的时候,考虑多弄一个类的改造私有类的模块化静态类verses动态类动态类查看模块源代码对象机制的基石 PyObjectPO verses OO PO PO耦合性高,很多过程…...

西安银行就业总结
引 进银行性价比最高的时刻是本科,研究生的话可以去需要研究生较多的银行,比如邮储或者证券类的中信建投。中信建投很香,要求本硕西电。研究生学历的话,一般情况下银行不会卡本科,只看最高学历,部分银行需…...

JavaScript Window
文章目录JavaScript Window浏览器对象模型 (BOM)Window 对象Window 尺寸其他 Window 方法JavaScript Window 浏览器对象模型 (BOM) 使 JavaScript 有能力与浏览器"对话"。 浏览器对象模型 (BOM) 浏览器对象模型(Browser Object Model (BOM))…...

那些开发过程中需要遵守的开发规范
入职公司三天,没干啥其他活,基本在配置本地环境和阅读相关文档。技术方面公司基本用的是主流的技术体系,入职后需要先阅读阿里的开发规范和其他的一些产研文档。今天整理一些平时需要关注的阿里规约和数据库开发规范,方便今后在开…...

EFCore 基础入门教程
一、EFCore 基础入门教程EF 框架的简介、发展历史;ORM框架概念学习地址:https://blog.csdn.net/u011127019/article/details/129212786?spm1001.2014.3001.5502EFCore 安装,引入、支持的数据库学习地址:https://www.cnblogs.com/…...
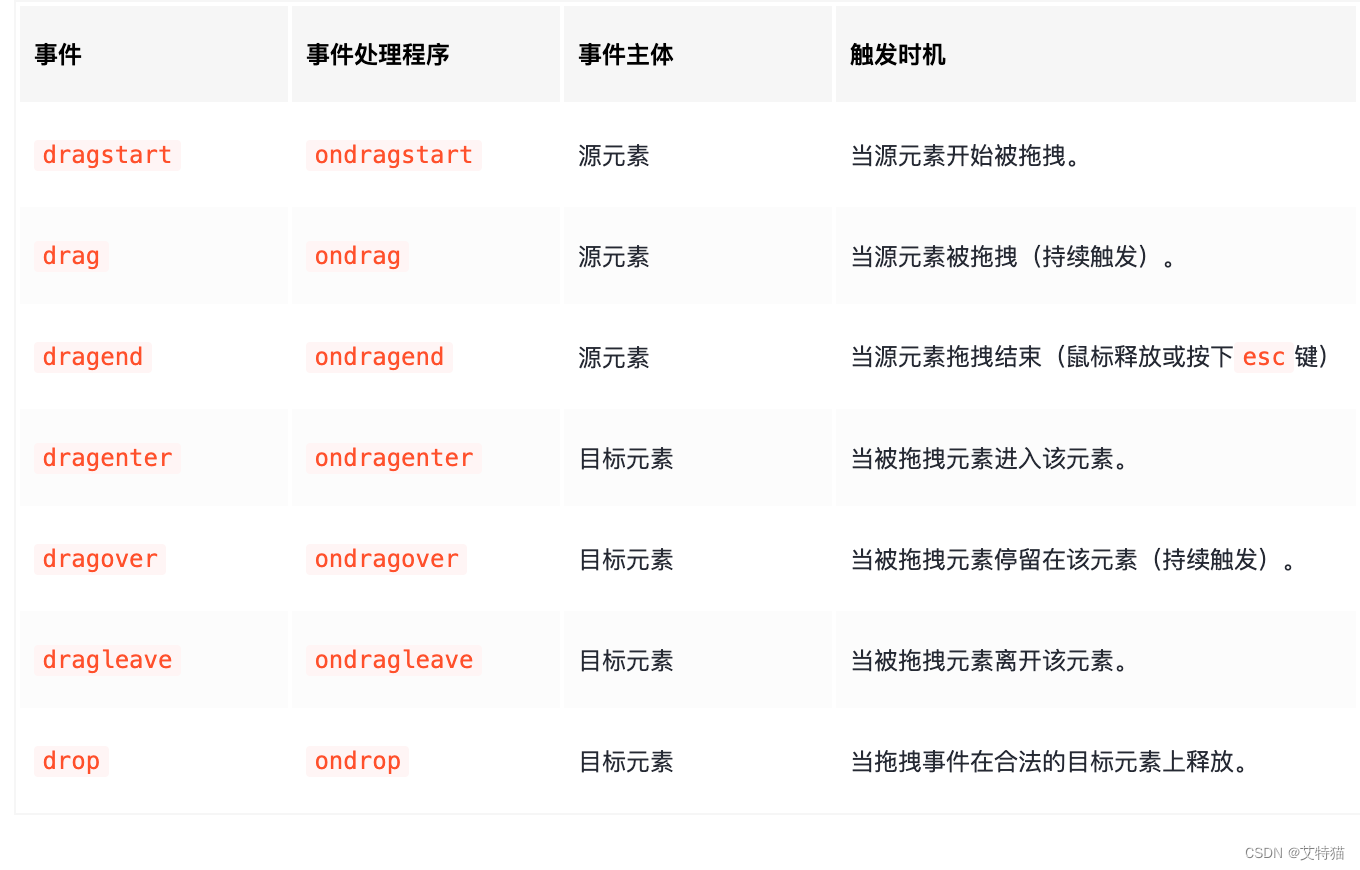
HTML5 Drag and Drop
这是2个组合事件 dom对象分源对象和目标对象 绑定的事件也是分别区分源对象和目标对象 事件绑定 事件顺序 被拖拽元素,事件触发顺序是 dragstart->drag->dragend; 对于目标元素,事件触发的顺序是 dragenter->dragover->drop/…...
惠普m1136打印机驱动程序安装教程
惠普m113打印机是一款功能强大的多功能打印机,它能够打印、复印、扫描和传真等。如果你要使用这款打印机,你需要下载并安装驱动程序,以确保它能够在你的计算机上正常工作。在本文中,我们将介绍如何下载和安装惠普m1136打印机驱动程…...

数据增强,扩充了数据集,增加了模型的泛化能力
数据增强(Data Augmentation)是在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值。 其原理是,通过对原始数据融入先验知识,加工…...

MySQL/Oracle获取当前时间几天/分钟前的时间
获取当前时间 要想获取当前时间几天/分钟前的时间,首先要知道怎么获取当前时间; 对于MySQL和Oracle获取当前时间的方法是不一样的; MySQL: select NOW(); 示例: Oracle: select sysdate from dual; 示…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...
)
别再用SonarQube凑数了!DeepSeek原生圈复杂度引擎的6大颠覆性能力(含GitHub私有部署密钥)
更多请点击: https://kaifayun.com 第一章:DeepSeek圈复杂度分析的底层原理与范式革命 DeepSeek圈复杂度分析并非传统McCabe度量的简单复刻,而是基于控制流图(CFG)动态重构与语义感知路径裁剪的双重机制构建的新范式。…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

基于Netburner NANO54415构建工业级嵌入式Web服务器:从硬件选型到广域监控实战
1. 项目概述:一个为广域与本地监控而生的嵌入式Web服务器如果你正在寻找一个能部署在野外、工厂角落或者任何需要远程数据采集与控制场景下的嵌入式Web服务器方案,并且对市面上那些要么性能孱弱、要么开发门槛极高的开发板感到厌倦,那么这个基…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...