ElasticSearch:实现高效数据搜索与分析的利器!项目中如何应用落地,让我带你实操指南。
1.难点解答
收集到几个问题:
- elasticsearch是单独建一个项目,作为全文搜索使用,还是直接在项目中直接用?
ES 服务器是要单独部署的,你可以把 ES 理解为 Redis。
- 新增数据时,插入到mysql中,需不需要同时插入到es中?
一般情况下,新增数据的时候,很少有采取双写的方案,同时写入 MySQL 和 ES 中的。主流的技术方案,都是通过 Canal 或 DataBus 监听 MySQL 的 binlog,来把数据同步到 ES 中的。
- 搜索时直接返回es搜索的结果,还是需要根据es的结果中的id,回mysql中重新查一遍?如果不用回mysql中查,那么mysql还有什么用,直接存es中,查也使用es,mysql难道只是做备份的吗?
一般情况下,能直接通过 ES 返回搜索结果的,不会再去 MySQL 重新查一遍。MySQL 存在的意义在于其关系型数据存储、简单查询的实时性,以及其具备事务特性。
- 更多知识原理内容见:
https://blog.csdn.net/sinat_39620217/article/details/134011021
- 更多项目实战见:
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源)
2.面试常见问题(模拟对白)
面试官:说说你对 ElasticSearch 的理解,这应该是一个非常高频的面试问题。
- 面试场景一:
我:“请说下你对 ES 的理解。”
候选人:“ES 的性能非常好,我们的订单中心的订单数据就会往 ES 中同步一份。然后,所有的查询请求都走 ES。”
我:“对实时性要求很高的 by id 查询也走 ES 吗?”
候选人有些慌:“这个。。。呵呵,我觉得都可以吧。”
我:“为什么 ES 叫近实时搜索引擎,请问‘近实时’三个字如何体现的?”
候选人:“这个。。。”
- 面试场景二:
我:“请说下你对 ES 的理解。”
候选人口若悬河:“ES 是一个基 Lucene 的 Java
开发的搜索引擎,是一个分布式、可扩展、实时的搜索与数据分析引擎,可以解决项目中的多维搜索问题。”我:“那可以说说,ES 不适合做什么吗?”
候选人:“这个。。。”
- 面试场景三:
我:“刚才你说的,你们系统线上环境的峰值 QPS 是 3000,那如果 QPS 再增加十倍,你打算如何优化?”
候选人:“现在系统中主要用的 MySQL 和 Redis,如果 QPS 高了,可以再增加 ES。”
我:“为什么用 ES 就可以顶住更高的 QPS,你分析过你系统请求的类型吗?”
候选人:“这个。。。”
- 形象比喻热水化,然后我在想,ES 对于很多经验尚浅的同学来说,是不是有点儿渣男语录中的 “热水化”。
- 肚子疼,多喝热水 ——> QPS 高,用 ES
- 玩累了,多喝热水 ——> 性能不好,用 ES
- 心情不好,多喝热水 ——> 数据量大,用 ES
- 感冒了,多喝热水 ——> 懒得分表,用 ES
其实,摆脱热水化,接近事实真相并不困难。下面我们还是通过现象倒推本质,去深入浅出地理解一下 ES。
3.应用场景
目前在互联网和电商方向,有很多同学都是用 ES 为 MySQL 去补齐短板的。最最典型的是两个应用场景:全文检索 和 复杂查询
尤其是复杂查询,因为 MySQL 的底层是通过 B+ Tree 实现的索引,如果把每个搜索项都建上索引,会非常影响 MySQL 的写入操作的性能。
如果业务主表的数据量过于庞大,MySQL 不得已做了分库分表方案的话,那会对 MySQL 的查询产生进一步的影响。因为查询条件里面如果不将分库分表键带入的话,就只能将 MySQL 已分的全部库表全部查询一遍,才会获取全部数据结果。基本上在互联网或电商领域引入 ES,80% 都是为了解决这种场景的问题。
那么,为什么 ES 处理这种场景就游刃有余呢?四个字 —— 倒排索引。
4.倒排索引
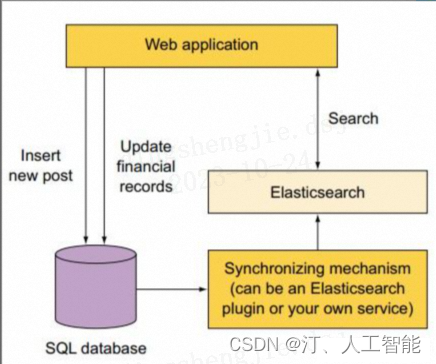
索引的初衷,是为了从一个海量数据集中快速找出某个字段等于确定值所对应的记录,索引分为正排索引和倒排索引两种。
- 正排索引,也叫正向索引(Forward Index),是通过文档 ID 去查找关键词(文档内容)。
- 倒排索引,也叫反向索引(Inverted Index),是通过关键词查找文档 ID。
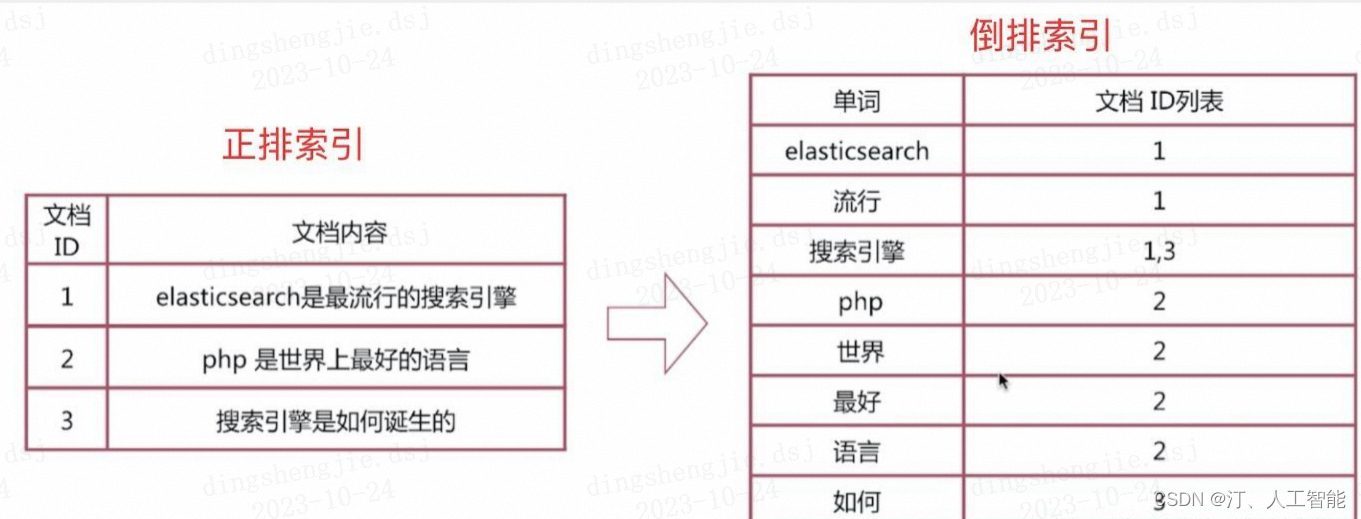
如果通过正排索引查找关键词 elasticsearch 时,需要遍历所有文档,查找出这个关键词所在的文档。如果文档数量非常庞大的话,正排索引的弊端就是查询效率太低。
而倒排索引的玩法就完全不一样了,通过倒排索引获得 “elasticsearch” 对应的文档 id 列表 1,再通过正排索引查询 1 所对应的文档,这样就可以了。
倒排索引包括两部分:词典(Term Dictionary) + 倒排列表(Posting List)。
单词词典(Term Dictionary):记录了所有文档的单词与倒排列表的关联关系,单词词典会比较大,一般通过 B + 树来实现,以满足高性能的插入与查询。
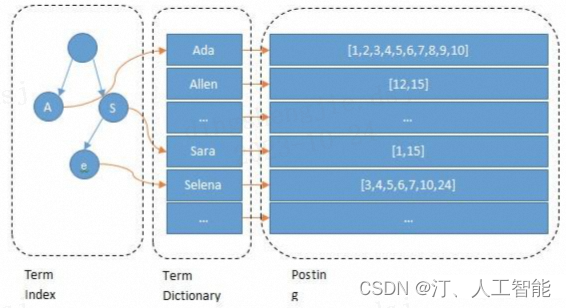
- 倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项组成,包括:
- 文档 ID,等同于数据库主键;
- 词频(Term Frequency),该单词在文档中出现的次数,主要是用于打分;
- 位置(Positon),单词在文档中分词的位置,用于语句搜索;
- 偏移(Offset),记录单词的的位置;
默认情况下,ES 的 JSON 文档中的每个字段,都有自己的倒排索引,这也其在复杂查询上优于 MySQL 的原因。
5.分词器
是的,说到倒排索引,就不得不提分词器。因为没有分词器的话,就没有词典,也就构建不了倒排索引了。
分词器的主要工作是,把用户输入的一段文本,按照一定的逻辑,转换成一系列单词。
当然,仅仅这些还不够,因为单词中肯定是有重复的,接下来要做事情就是去重,以及去重之后的排序,这样便于搜索。
整体步骤如下:
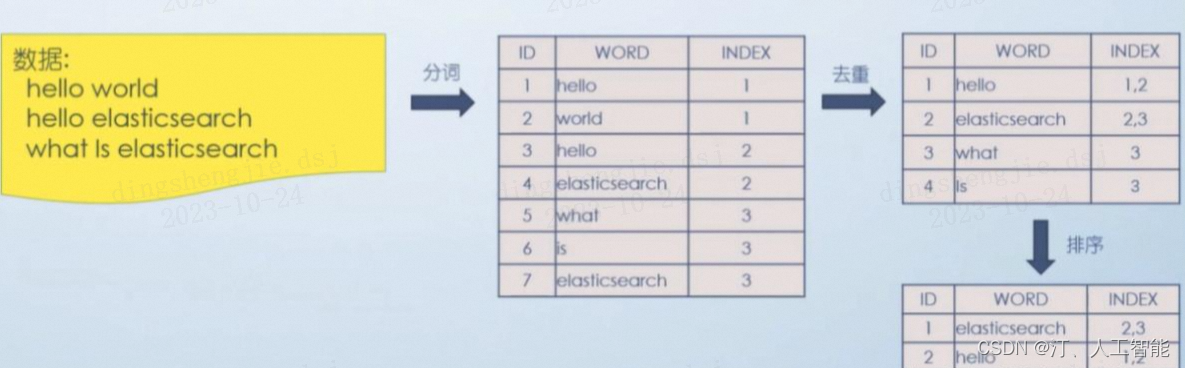
分词器一般由三个部分组成:
- 字符过滤器(Character Filters),对原始文本进行处理,最常见的就是第一种 ;

- 分词器(Tokenizer),顾名思义,将原始文本按照特定的规则切分为单词,默认的是 Standard Tokenizer;

- Token 过滤器(Token Filter),将切分的单词进行加工,如:大小写转换,去掉停用词,加入同义词,等等。

三者顺序为:
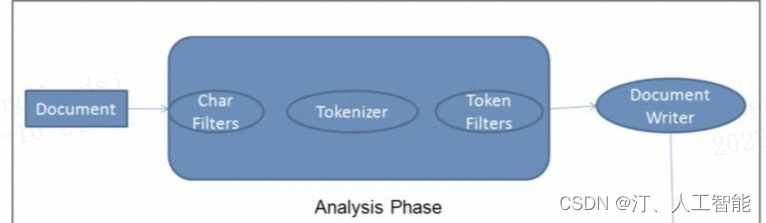
讲完倒排索引和分词,基本上大家对 ES 的运行机制有了一个宏观的了解,知道它为什么适合于进行全文检索关键字和多维复杂查询的场景了。
6. 准实时搜索
这块知识点是在面试中高频出现的问题。随着按段(per-segment)搜索的发展, 一个新的文档从索引到可被搜索的延迟显著降低了。新文档可做到在几分钟之内即可被检索,但这样依然不够快,不能满足于所有场景需求。
磁盘在这里成为了瓶颈。因为,提交(Commiting)一个新的段(Segment)到磁盘,需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。 但是,如果每次索引一个文档都去执行一次 fsync 的话,会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,在 ES 和磁盘之间是文件系统缓存。在内存索引缓冲区中的文档会被写入到一个新的段中,这里新段会被先写入到文件系统缓存(这一步代价会比较低),稍后再被刷新到磁盘(这一步代价比较高)。不过只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
我们都知道,ES 的底层实现是 Lucene。而 Lucene 允许新段被写入和打开,使其包含的文档在未进行一次完整提交时便对搜索可见。这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
通过如上实现方式,可将 ES 可被检索的时长从分钟级别,优化到了秒级别。
默认情况下,每个分片会每秒自动刷新(refresh)一次。这就是为什么我们说 ES 是近实时搜索。文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
refresh的相关 API 如下:
(1)刷新(Refresh)所有的索引POST /_refresh(2)只刷新(Refresh)blogs 索引POST /blogs/_refresh(3)每 30 秒刷新 my_index 索引PUT my_index/_settings
{
"index" : {
"refresh_interval" : "30s"
}
}另外,refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来。
(4)关闭自动刷新 my_index 索引,当内存缓冲区满了才进行 refresh 操作PUT my_index/_settings
{
"index" : {
"refresh_interval" : "-1"
}
}
7. 搜索类型(SearchType)
示例如下:
GET /_search?search_type=query_then_fetch共有四种搜索类型,包括:query and fetch、query then fetch(默认)、DFS query and fetch 和 DFS query then fetch。
7.1 query and fetch(本地)
向索引的所有分片(shard)都发出查询请求,各分片返回的时候把元素文档(document)和计算后的排名分值一起返回。
- 优点:快。
- 缺点:排名不准确(每个分片计算后的分值进行排序),同时各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。(数据量不准确)
7.2 query then fetch(默认)(本地)
先向所有的 shard发出请求,各分片只返回文档 id(注意,不包括文档 document)和排名分值(基于自己分片),然后按照各分片返回的文档的分数进行重新排名,取前 size 个文档。
根据文档 id 去相关的 shard 取 document,这种方式返回的 document 数量与用户要求的大小是相等的。
- 优点:返回的数据量是准确的。
- 缺点:性能一般,并且数据排名不准确。
7.3 DFS query and fetch(全局)
这种方式比第一种方式多了一个 DFS 步骤,有这一步,可以更精确控制搜索打分和排名。也就是在进行查询之前,先对所有分片发送请求,把所有分片中的词频率和文档频率等打分依据全部汇总到一块,再执行后面的操作。
- 优点:数据排名准确。
- 缺点:性能一般,返回的数据量不准确, 可能返回 (N * 分片数量) 的数据。
DFS query then fetch(全局)
比第 2 种方式多了一个 DFS 步骤。也就是在进行查询之前,先对所有分片发送请求,把所有分片中的词频率和文档频率等打分依据全部汇总到一块,再执行后面的操作。
- 优点:返回的数据量是准确的,数据排名准确。
- 缺点:性能最差
DFS 是一个什么样的过程?
多了一个初始化散发(initial scatter) 步骤,在进行真正的查询之前,先把各个分片的词频率和文档频率(排名信息)收集一下,然后进行词搜索的时候,各分片依据全局的词频率和文档频率进行搜索和排名。
- 检索词的频率
检索词 honeymoon在这个文档的 tweet 字段中出现的次数。
- 反向文档频率
检索词 honeymoon 在索引上所有文档的 tweet 字段中出现的次数。
在每一个分片上查询符合要求的数据,并根据全局的 Term 和 Document 的频率信息计算相关性得分构建一个优先级队列存储查询结果(包含分页、排序,等等),把查询结果的 metadata 返回给查询节点。
注意,真正的文档此时还并没有返回,返回的只是得分数据。
8. query 和 filter
ElasticSearch 中的 search 操作包括两种,查询(query)和过滤(filter)。
从使用场景的角度来看,全文检索以及任何使用相关性评分的场景使用 query 查询,除此之外的使用 filter 过滤器进行过滤。
示例如下:
GET /_search
{"query": { "bool": { "must": [{ "match": { "title": "Search" }}, { "match": { "content": "Elasticsearch" }} ],"filter": [ { "term": { "status": "published" }}, { "range": { "publish_date": { "gte": "2015-01-01" }}} ]}}
}- query:
此文档与此查询子句的匹配程度如何?以及 query 上下文的条件是用来给文档打分的,匹配越好 _score 越高。
即:全文搜索,评分排序,无法缓存,性能低。
- filter:
此文档和查询子句匹配吗?以及 filter 的条件只产生两种结果:符合与不符合,后者被过滤掉。
即:精确查询,是非过滤,可缓存,性能高。
Query 检索细化关注点
**是否包含,**确定文档是否应该成为结果的一部分。
**相关度得分,**除了确定文档是否匹配外,查询子句还计算了表示文档与其他文档相比匹配程度的_score。得分越高,相关度越高。更相关的文件,在搜索排名更高。
典型应用场景:
(1)全文检索——这种相关性的概念非常适合全文搜索,因为很少有完全正确的答案。
如:文档中存在字段
hotel_name:“上海浦东香格里拉酒店”,实际分词结果为:上海浦,上海,浦东,香格里拉,格里,里拉,酒店。也就是说,搜索以上关键词都能搜到:hotel_name:“上海浦东香格里拉酒店”的酒店。这些都是
“相关” 的。(2)包含单词 “run”, 但也匹配 “runs”, “running”, “jog” 或者 “sprint”。(都是奔跑的意思)
filter 过滤细化关注点
**是否包含,**确定是否包含在检索结果中,回答只有 “是” 或“否”。
**不涉及评分,**在搜索中没有额外的相关度排名。
**针对结构化数据,**适用于完全精确匹配,范围检索。
典型应用场景:
(1)时间戳 timestamp 是否在 2015 至 2016 年范围内?
(2)状态字段 status 是否设置为 “published”?

为什么 filter 比 query 更快?
因为,经常使用的过滤器将被 ES 自动缓存,以提高性能。只确定是否包括结果中,不需要考虑得分。
更多推荐
- 更多知识原理内容见:
https://blog.csdn.net/sinat_39620217/article/details/134011021
- 更多项目实战见:
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源)
相关文章:
ElasticSearch:实现高效数据搜索与分析的利器!项目中如何应用落地,让我带你实操指南。
1.难点解答 收集到几个问题: elasticsearch是单独建一个项目,作为全文搜索使用,还是直接在项目中直接用? ES 服务器是要单独部署的,你可以把 ES 理解为 Redis。 新增数据时,插入到mysql中,需不…...
2023了,是时候使用pnpm了!
2023了,是时候使用pnpm了! Excerpt 2023了,是时候使用pnpm了! 什么是pnpm pnpm代表performant npm(高性能的npm),同npm和Yarn,都属于Javascript包管理安装工具,它较npm和…...
asp.net文档管理系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net文档管理系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语言开发 asp.net文档管理系统 二、功能介绍 (1…...

Parallels Client for Mac:改变您远程控制体验的革命性软件
在当今数字化的世界中,远程控制软件已经成为我们日常生活和工作中不可或缺的一部分。在众多远程控制软件中,Parallels Client for Mac以其独特的功能和出色的性能脱颖而出,让远程控制变得更加简单、高效和灵活。 Parallels Client for Mac是…...

Julia数组详解
文章目录 向量数列矩阵特殊数组数组函数 Julia系列:编程初步 向量 Julia中有两种向量,一种是类型统一的,另一种则可包含不同类型的变量,例如下面两个向量都是允许存在的 aNum [1,2,3] # 类型为 3-element Vector{Int64} aAny…...

用事务代码查看视图的函数
文章目录 1 Introduction2 Code 1 Introduction If we continue to see view with T-code. We can use the function for it . 2 Code REPORT z_websrv_con.CALL FUNCTION VIEW_MAINTENANCE_CALLEXPORTINGaction U "操作类型:U修改…...
--libcoap - coap数据处理)
LuatOS-SOC接口文档(air780E)--libcoap - coap数据处理
libcoap.new(code, uri, headers, payload) 创建一个coap数据包 参数 传入值类型 解释 int coap的code, 例如libcoap.GET/libcoap.POST/libcoap.PUT/libcoap.DELETE string 目标URI,必须填写, 不需要加上/开头 table 请求头,类似于http的headers,可选 string 请求体…...

js控制checkbox单选,获取checkbox的值,选中checkbox
声明:网上的资料杂七杂八的搞得我一个不熟悉前端的后端开发者弄起来贼难受,现在将实现了的做一个整合,希望能给你们带来点帮助(主要还是帮助我自己(●ˇ∀ˇ●),防止丢失) html代码组件示例 <div styl…...

MYSQL(事务+锁+MVCC+SQL执行流程)理解(2)
一)MYSQL中的锁(知识补充) 可以通过In_use字段来进行判断是否针对于表进行加了锁 1)对于undo log日志来说:新增类型的,在事务提交之后就可以清除掉了,修改类型的,事务提交之后不能立即清除掉这些日志会用于mvcc只有当没有事务用到该版本信息时…...
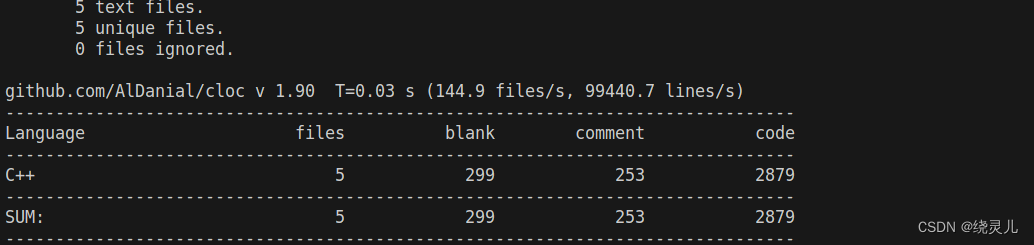
ubuntu tools
1 cloc calculate lines of your code sudo apt-get install cloccloc ./file...

LeetCode 155. 掷骰子等于目标和的方法数:动态规划
【LetMeFly】1155.掷骰子等于目标和的方法数:动态规划 力扣题目链接:https://leetcode.cn/problems/number-of-dice-rolls-with-target-sum/ 这里有 n 个一样的骰子,每个骰子上都有 k 个面,分别标号为 1 到 k 。 给定三个整数 …...

PostgreSQL数据库从入门到精通系列之五:安装时序数据库TimescaleDB的详细步骤
PostgreSQL数据库从入门到精通系列之五:安装时序数据库TimescaleDB的详细步骤 一、下载PostgreSQL数据库yum源二、创建TimescaleDB存储库三、更新本地存储库列表四、安装TimescaleDB五、初始化PostgreSQL数据库六、启动Postgresql数据库服务七、以超级用户身份连接到PostgreSQ…...
软件测试(五)自动化 selenium
文章目录 自动化测试单元测试:单元测试:UI自动化 selenium工具定义特点:原理:seleniumjava环境搭建SeleniumAPI获取测试结果:添加等待浏览器操作键盘事件鼠标事件多层框架/窗口定位下拉框处理弹窗处理上传文件操作关闭…...

Android grantUriPermission的使用场景和方式
#grantUriPermission 作用 临时授权。 背景:FileProvider引入后应用之间想访问文件,都需要使用此接口。特别是两个独立的应用之间互通数据的时候。例如我们应用从图库获取文件的uri,显示在应用内的ImageView中。 #grantUriPermission 使用方…...

2023高频前端面试题-vue
1. 什么是 M V VM Model-View-ViewModel 模式 Model 层: 数据模型层 通过 Ajax、fetch 等 API 完成客户端和服务端业务模型的同步。 View 层: 视图层 作为视图模板存在,其实 View 就是⼀个动态模板。 ViewModel 层: 视图模型层 负责暴露数据给 View 层&…...

03初始Docker
一、初始Docker 1.什么是Docker 问题 ①大型项目组件复杂,运行环境复杂,部署时依赖复杂,出现兼容性问题。 ②开发,测试,生产环境有差异。不同的环境操作系统不同 解决 ①Docket将应用、依赖、函数库、配置一起打…...

1.1、Python基础-注释、变量声明及命名规则、数据类型
1.1、Python基础 Python基础1、注释2、变量3、数据类型 Python基础 1、注释 注释是给程序员看的,为了让程序员方便阅读代码,解释器会忽略注释。使用自己熟悉的语言,适当的对代 码进行注释说明是一种良好的编码习惯。 注释写法 #我是单行注…...

Python第三方库安装——使用vscode、pycharm安装Python第三方库
[TOC](Python第三方库安装——使用vscode、pycharm安装Python第三方库) # 前言 在这里介绍vscode、Pycharm安装python第三方库的方法。 操作系统:windows10 专业版 环境如下: Pycharm Comunity 2022.3 Visual Studio Code 2019 Python 3.8 pipÿ…...

【vue】组件通选方式
父子传值 props $emit 这是最基本的父子组件通讯方式。通过 props 属性将数据从父组件传递给子组件,而子组件通过触发事件($emit)将数据发送回父组件。 $children $parent 通过 $parent 属性可以访问父组件的实例,通过 $child…...

java 使用策略模式减少if
使用多态:通过使用面向对象的多态特性,可以将不同的逻辑封装到不同的类中,避免大量的 if 语句。使用继承和接口来定义通用的方法,并让具体的实现类实现这些方法。 使用设计模式:使用设计模式可以更好地组织和管理代码逻…...

Hyper-V虚拟机文件迁移避坑指南:从C盘挪走Ubuntu,释放系统盘空间
Hyper-V虚拟机文件迁移实战:安全释放C盘空间的完整方案 当你在Windows系统上使用Hyper-V运行Ubuntu虚拟机时,是否注意到C盘空间正在被悄悄吞噬?许多技术爱好者初次接触Hyper-V时,往往直接采用默认设置,将所有虚拟机文件…...

Matlab 2020a老版本用户福音:手把手教你配置MinGW 6.3.0并集成第三方EXR工具
Matlab 2020a兼容性解决方案:MinGW 6.3.0与EXR工具链深度整合指南 对于长期依赖Matlab 2020a进行科研或工程开发的用户来说,遇到需要处理EXR图像文件的需求时往往会陷入两难——既无法放弃经过验证的稳定开发环境,又需要扩展功能支持。本文将…...
)
别再傻傻分不清了!给硬件工程师的SI、PI、EMI关系速查手册(附高频PCB设计实例)
硬件工程师实战指南:SI、PI、EMI的三角关系与高频PCB设计避坑 当你第一次面对DDR4布线导致的EMI测试失败时,可能会陷入这样的困惑:明明是信号完整性问题,为什么整改方案却是调整电源层的去耦电容?这种看似跨领域的因果…...

Cursor + Claude Code 双栈协作:3 种项目级配置同步方案落地实录
1. 项目级配置同步不是“配完就跑”,而是让 AI 真正理解你的项目语义 大多数人把 Cursor + Claude Code 当成一个“更聪明的自动补全”,装完插件、填个 API Key、点几下设置,就以为双栈协作完成了。我试过三个不同规模的项目——一个 2000 行的 Python 数据处理脚本集、一个…...

启动我进入数据科学的那一个思维方式转变
原文:towardsdatascience.com/the-one-mindset-change-that-launched-me-into-data-science-3f72bd1df46f?sourcecollection_archive---------2-----------------------#2024-10-19 让它成为现实:微小的改变帮助你进入数据科学或任何梦想职业 https://…...

WinSW实战:除了开机自启,这样配置还能监控你的Nacos服务状态与日志
WinSW进阶实战:构建Nacos服务的全方位监控体系 对于许多使用Nacos作为注册中心和配置中心的团队来说,确保其稳定运行是系统可靠性的基石。虽然通过WinSW将Nacos注册为Windows服务并实现开机自启解决了基础问题,但真正的挑战在于服务运行后的状…...

NoFences:重新定义Windows桌面管理的开源革命
NoFences:重新定义Windows桌面管理的开源革命 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否也曾为杂乱无章的Windows桌面而烦恼?图标散落各处…...

RKNN Model Zoo实战:MobileSAM图像分割在瑞芯微平台的完整部署指南
RKNN Model Zoo实战:MobileSAM图像分割在瑞芯微平台的完整部署指南 【免费下载链接】rknn_model_zoo 项目地址: https://gitcode.com/gh_mirrors/rk/rknn_model_zoo 在边缘计算和嵌入式AI应用场景中,图像分割技术正成为智能监控、工业质检和AR/V…...

避坑指南:Teamcenter 13四层架构安装中,Weblogic域创建与部署的那些“坑”
Teamcenter 13四层架构部署实战:Weblogic域创建与部署全流程避坑指南 在工业PLM领域,Teamcenter的四层架构部署一直是系统管理员的技术试金石。特别是Weblogic中间件层的配置,往往成为项目推进道路上的"拦路虎"。我曾参与过多个汽…...
)
别再只用Leaflet了!Mapbox GL JS加载本地MVT矢量瓦片保姆级教程(附避坑点)
从Leaflet到Mapbox GL JS:解锁MVT矢量瓦片的进阶玩法 当传统WebGIS开发者第一次看到Mapbox GL JS渲染的矢量瓦片地图时,那种震撼感不亚于从黑白电视切换到4K HDR。Leaflet就像一把可靠的瑞士军刀,而Mapbox GL JS则像一套专业厨房设备——当你…...