Flink几个性能调优
1 配置内存
操作场景
Flink是依赖内存计算,计算过程中内存不够对Flink的执行效率影响很大。可以通过监控GC(Garbage Collection),评估内存使用及剩余情况来判断内存是否变成性能瓶颈,并根据情况优化。
监控节点进程的YARN的Container GC日志,如果频繁出现Full GC,需要优化GC。
GC的配置:在客户端的“conf/flink-conf.yaml”配置文件中,在“env.java.opts”配置项中添加参数:“
-Xloggc:<LOG_DIR>/gc.log
-XX:+PrintGCDetails
-XX:-OmitStackTraceInFastThrow
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=20
-XX:GCLogFileSize=20M
此处默认已经添加GC日志。
操作步骤
-
优化GC。
调整老年代和新生代的比值。在客户端的“conf/flink-conf.yaml”配置文件中,在“env.java.opts”配置项中添加参数:“-XX:NewRatio”。如“ -XX:NewRatio=2”,则表示老年代与新生代的比值为2:1,新生代占整个堆空间的1/3,老年代占2/3。
-
开发Flink应用程序时,优化DataStream的数据分区或分组操作。
- 当分区导致数据倾斜时,需要考虑优化分区。
- 避免非并行度操作,有些对DataStream的操作会导致无法并行,例如WindowAll。
- keyBy尽量不要使用String。
补充:
-Xloggc:<LOG_DIR>/gc.log
#GC详情
-XX:+PrintGCDetails
-XX:-OmitStackTraceInFastThrow
#打印GC时间信息
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=20
-XX:GCLogFileSize=20M。
#表示老年代与新生代的比值为2:1,新生代占整个堆空间的1/3,老年代占2/3。
#设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:NewRatio=2
======================================================================================================堆设置
-Xms :初始堆大小
-Xmx :最大堆大小
-XX:NewSize=n :设置年轻代大小
-XX:NewRatio=n: 设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n :年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n :设置持久代大小
收集器设置
-XX:+UseSerialGC :设置串行收集器
-XX:+UseParallelGC :设置并行收集器
-XX:+UseParalledlOldGC :设置并行年老代收集器
-XX:+UseConcMarkSweepGC :设置并发收集器
垃圾回收统计信息
-XX:+PrintHeapAtGC GC的heap详情
-XX:+PrintGCDetails GC详情
-XX:+PrintGCTimeStamps 打印GC时间信息
-XX:+PrintTenuringDistribution 打印年龄信息等
-XX:+HandlePromotionFailure 老年代分配担保(true or false)
并行收集器设置
-XX:ParallelGCThreads=n :设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n :设置并行收集最大暂停时间
-XX:GCTimeRatio=n :设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode :设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n :设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数
2 设置并行度
操作场景
- 并行度控制任务的数量,影响操作后数据被切分成的块数。调整并行度让任务的数量和每个任务处理的数据与机器的处理能力达到最优。
- 查看CPU使用情况和内存占用情况,当任务和数据不是平均分布在各节点,而是集中在个别节点时,可以增大并行度使任务和数据更均匀的分布在各个节点。增加任务的并行度,充分利用集群机器的计算能力,一般并行度设置为集群CPU核数总和的2-3倍。
操作步骤
任务的并行度可以通过以下四种层次(按优先级从高到低排列)指定,用户可以根据实际的内存、CPU、数据以及应用程序逻辑的情况调整并行度参数。
- 算子层次
一个算子、数据源和sink的并行度可以通过调用setParallelism()方法来指定,例如
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> text = [...]
DataStream<Tuple2<String, Integer>> wordCounts = text.flatMap(new LineSplitter()).keyBy(0).timeWindow(Time.seconds(5)).sum(1).setParallelism(5);wordCounts.print();env.execute("Word Count Example");
- 执行环境层次
Flink程序运行在执行环境中。执行环境为所有执行的算子、数据源、data sink定义了一个默认的并行度。
执行环境的默认并行度可以通过调用setParallelism()方法指定。例如:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3);DataStream<String> text = [...]DataStream<Tuple2<String, Integer>> wordCounts = [...]wordCounts.print();env.execute("Word Count Example");
- 客户端层次
并行度可以在客户端将job提交到Flink时设定。对于CLI客户端,可以通过“-p”参数指定并行度。例如:./bin/flink run -p 10 ../examples/*WordCount-java*.jar - 系统层次
在系统级可以通过修改Flink客户端conf目录下的“flink-conf.yaml”文件中的“parallelism.default”配置选项来指定所有执行环境的默认并行度。
3.配置进程参数
操作场景
-
Flink on YARN模式下,有JobManager和TaskManager两种进程。在任务调度和运行的过程中,JobManager和TaskManager承担了很大的责任。
-
因而JobManager和TaskManager的参数配置对Flink应用的执行有着很大的影响意义。用户可通过如下操作对Flink集群性能做优化。
操作步骤
1.配置JobManager内存。
- JobManager负责任务的调度,以及TaskManager、RM之间的消息通信。当任务数变多,任务平行度增大时,JobManager内存都需要相应增大。
您可以根据实际任务数量的多少,为JobManager设置一个合适的内存。
•在使用yarn-session命令时,添加“-jm MEM”参数设置内存。
•在使用yarn-cluster命令时,添加“-yjm MEM”参数设置内存。
2.配置TaskManager个数。
每个TaskManager每个核同时能跑一个task,所以增加了TaskManager的个数相当于增大了任务的并发度。在资源充足的情况下,可以相应增加TaskManager的个数,以提高运行效率。
•在使用yarn-session命令时,添加“-n NUM”参数设置TaskManager个数。
•在使用yarn-cluster命令时,添加“-yn NUM”参数设置TaskManager个数。
3.配置TaskManager Slot数。
每个TaskManager多个核同时能跑多个task,相当于增大了任务的并发度。但是由于所有核共用TaskManager的内存,所以要在内存和核数之间做好平衡。
•在使用yarn-session命令时,添加“-s NUM”参数设置SLOT数。
•在使用yarn-cluster命令时,添加“-ys NUM”参数设置SLOT数。
4.配置TaskManager内存。
TaskManager的内存主要用于任务执行、通信等。当一个任务很大的时候,可能需要较多资源,因而内存也可以做相应的增加。
•将在使用yarn-sesion命令时,添加“-tm MEM”参数设置内存。
•将在使用yarn-cluster命令时,添加“-ytm MEM”参数设置内存。
相关文章:

Flink几个性能调优
1 配置内存 操作场景 Flink是依赖内存计算,计算过程中内存不够对Flink的执行效率影响很大。可以通过监控GC(Garbage Collection),评估内存使用及剩余情况来判断内存是否变成性能瓶颈,并根据情况优化。 监控节点进程的…...

后端工程进阶| 青训营笔记
这是我参与「第五届青训营 」伴学笔记创作活动的第 2 天 并发编程 协程Goroutine通道Channel锁Lock 并发基础 串行程序与并发程序:串行程序特指只能被顺序执行的指令列表,并发程序则是可以被并发执行的两个及以上的串行程序的综合体。并发程序与并行程序…...
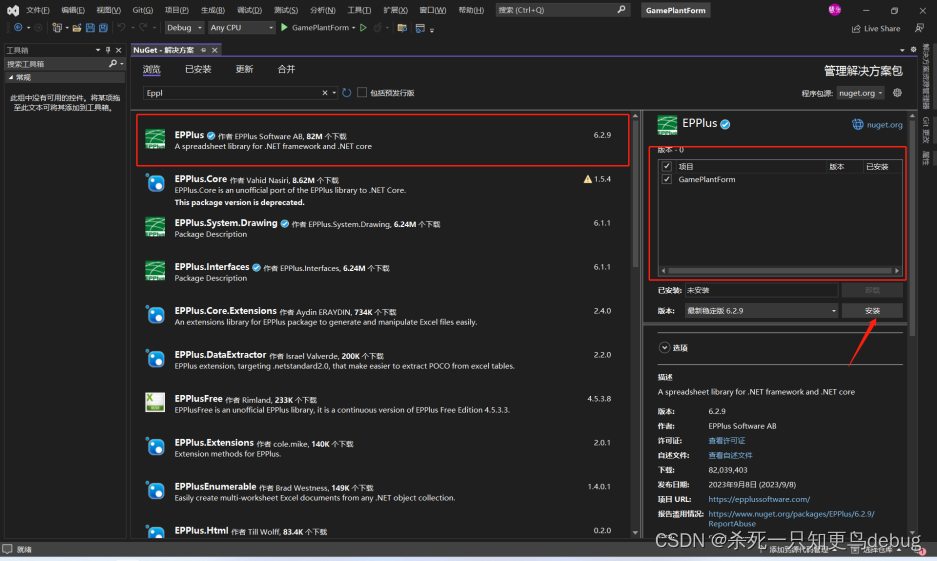
EPPlus库的安装和使用 C# 中 Excel的导入和导出
安装 工具栏->NuGet 包管理器->管理解决方案的NuGet程序包 安装到当前项目中 使用 将 DataGridView 数据导出为Excel 首先,需要将数据DataGridView对象转换为DataTable private void btnExport_Click(object sender, EventArgs e) {// 1.将当前页面的data…...
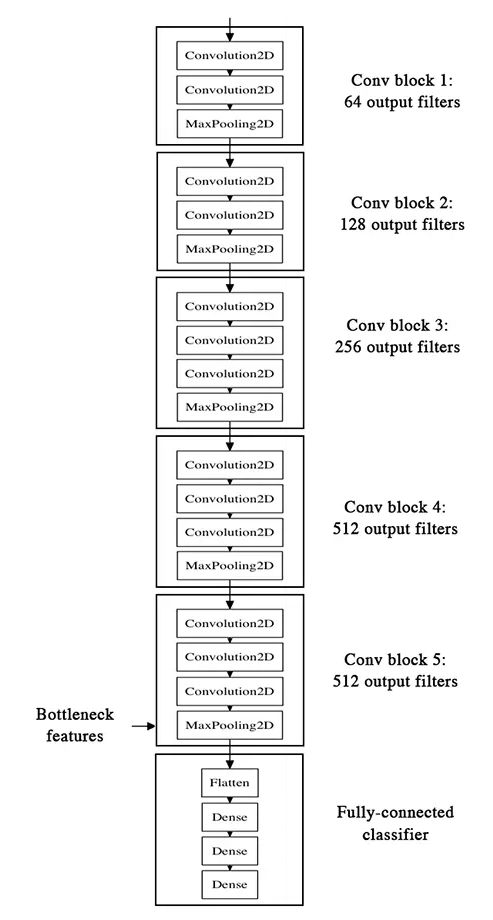
深度学习使用Keras进行迁移学习提升网络性能
上一篇文章我们用自己定义的模型来解决了二分类问题,在20个回合的训练之后得到了大约74%的准确率,一方面是我们的epoch太小的原因,另外一方面也是由于模型太简单,结构简单,故而不能做太复杂的事情,那么怎么提升预测的准确率了?一个有效的方法就是迁移学习。 迁移学习其…...
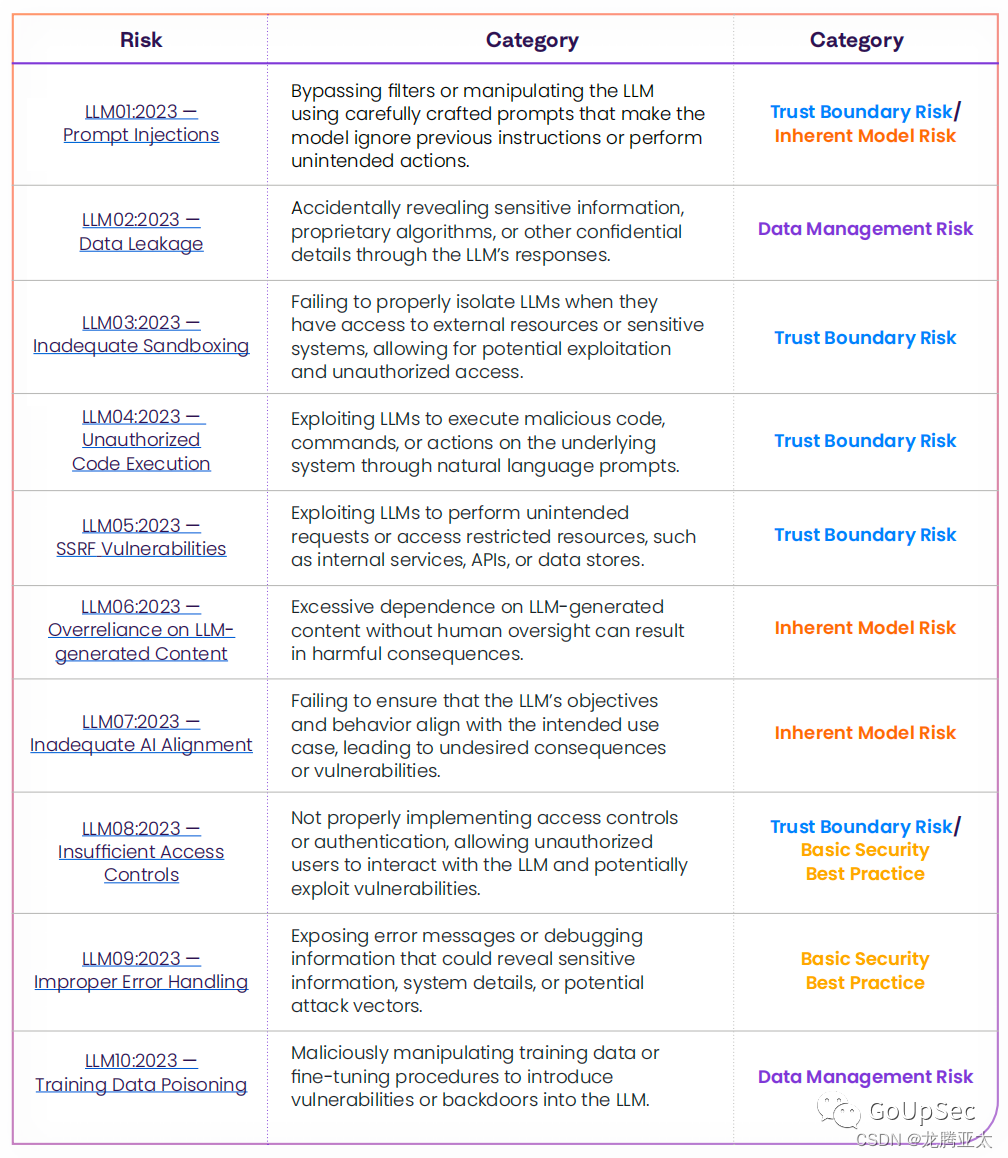
越流行的大语言模型越不安全
源自:GoUpSec “人工智能技术与咨询” 发布 安全研究人员用OpenSSF记分卡对GitHub上50个最流行的生成式AI大语言模型项目的安全性进行了评估,结果发现越流行的大语言模型越危险。 近日,安全研究人员用OpenSSF记分卡对GitHub上50个最流…...

搜维尔科技:伦敦艺术家利用Varjo头显捕捉盲人隐藏的梦想
在伦敦举行的弗里泽艺术博览会上,与专业级虚拟现实/XR硬件和软件领域的全球领先者Varjo合作,展示一个突破性的混合现实艺术装置, 皇家国家盲人学会 (rnib),英国领先的视力丧失慈善机构。 这个名为"公共交通的私人生活"的装置是一个互动的声音和图像雕塑,旨在让有眼光…...

如何将html转化为pdf
html转换为pdf html2pdf.js库, 基于html2canvas和jspdf,只能打印2-3页pdf,比较慢,分页会截断html2canvas 只能打印2-3页pdf,比较慢,分页会截断 // canvasDom-to-image 不支持某些css属性Pdfmake html-to-p…...

ES6初步了解生成器
生成器函数是ES6提供的一种异步编程解决方案,语法行为与传统函数完全不同 语法: function * fun(){ } function * gen(){console.log("hello generator");}let iterator gen()console.log(iterator)打印: 我们发现没有打印”hello…...
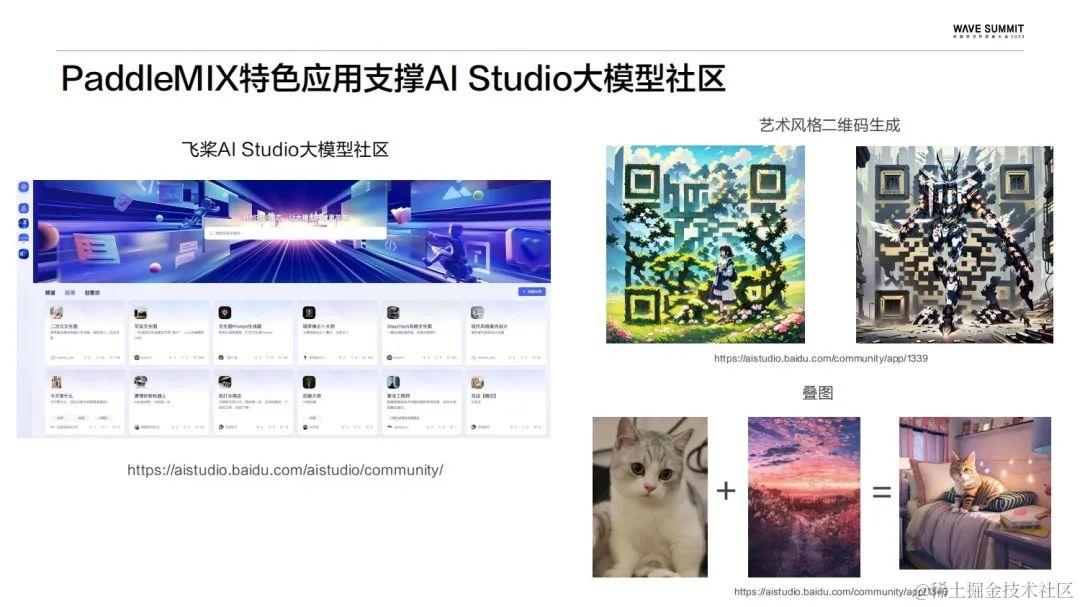
飞桨大模型套件:一站式体验,性能极致,生态兼容
在Wave Summit 2023深度学习开发者大会上,来自百度的资深研发工程师贺思俊和王冠中带来的分享主题是:飞桨大模型套件,一站式体验,性能极致,生态兼容。 大语言模型套件PaddleNLP 众所周知PaddleNLP并不是一个全新的模型…...

【C++入门到精通】哈希 (STL) _ unordered_map _ unordered_set [ C++入门 ]
阅读导航 前言一、unordered系列容器二、unordered_map1. unordered_map简介⭕函数特点 2. unordered_map接口- 构造函数- unordered_map的容量- unordered_map的迭代器- unordered_map的元素访问- unordered_map的修改操作- unordered_map的桶操作 三、unordered_set1. unorde…...
创建 Edge 浏览器扩展教程(上)
创建 Edge 浏览器扩展教程(上) 介绍开始之前后续步骤开始之前1:创建清单 .json 文件2 :添加图标3:打开默认弹出对话框 介绍 在如今日益数字化的时代,浏览器插件在提升用户体验、增加功能以及改善工作流程方…...

container_of解析及应用
container_of是一个C语言中比较少见,但实际经常用到的宏,在Linux kernel中也有大范围的应用。...

搜维尔科技:Varjo-最自然和最直观的互动
创建真实生活虚拟设计 Varjo让你沉浸在最自然的混合和虚拟现实环境中。 世界各地的设计团队可以聚集在一个摄影现实的虚拟空间中,以真实的准确性展示新的概念-实时的讨论和迭代。这是一个充满无限创造潜力的新时代,加速了人类前所未有的想象力。 虚拟现实、自动反应和XR设计的…...
Postman环境配置
Postman环境配置 安装Postman安装node.js安装newman安装htmlextra安装git注册163邮箱用163邮箱注册gitee在pycharm中安装gitee详细文档 安装Postman 网址:https://www.postman.com/downloads/ 注册一个账号即可 安装node.js 安装newman npm install -g newman …...
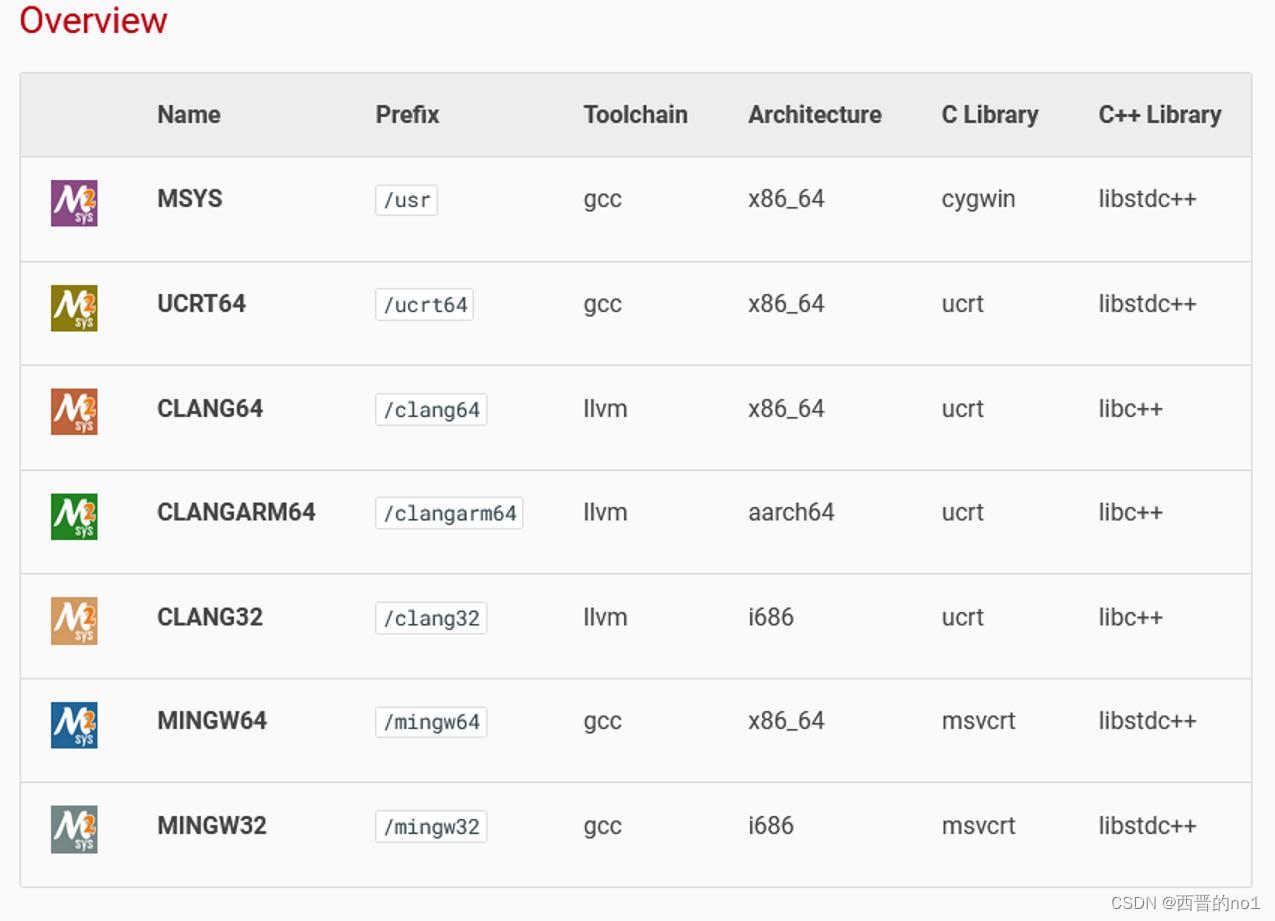
Windows下Eclipse C/C++开发环境配置教程
1.下载安装Eclipse 官网下载eclipse-installer(eclipse下载器),或者官方下载对应版本zip。 本文示例: Eclipse IDE for C/C Developers Eclipse Packages | The Eclipse Foundation - home to a global community, the Eclipse ID…...

深入 Maven:构建杰出的软件项目的完美工具
掌握 Meven:构建更强大、更智能的应用程序的秘诀 Maven1.1 初识Maven1.1.1 什么是Maven1.1.2 Maven的作用 02. Maven概述2.1 Maven介绍2.2 Maven模型2.3 Maven仓库2.4 Maven安装2.4.1 下载2.4.2 安装步骤 03. IDEA集成Maven3.1 配置Maven环境3.1.1 当前工程设置3.1.…...

一文了解企业云盘和大文件传输哪个更适合企业传输
文件传输是企业工作中必不可少的环节,无论是内部协作还是外部沟通,都需要高效、安全、稳定地传输各种类型和大小的文件。然而,市面上的文件传输工具众多,如何选择合适的工具呢?本文将从两种常见的文件传输工具——企业…...
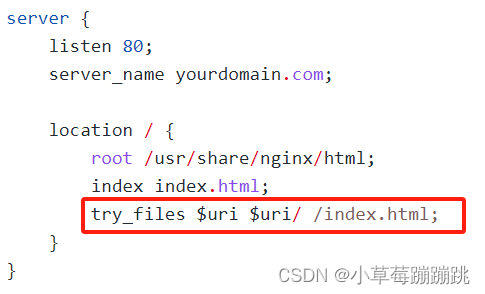
在 history 模式下,为什么刷新页面会出现404?
1、原因 因为浏览器在刷新页面时,它会向服务器发送 GET 请求,但此时服务器并没有配置相应的资源来匹配这个请求,因此返回 404 错误。 2、解决方案 为了解决这个问题,我们需要在服务器端进行相关配置,让所有的路由都指…...

第二证券:“华为概念股”,怒刷13连板
大盘颤动时,“妖股”出生日。 到10月24日收盘,圣龙股份连续第13个生意日以涨停报收,区间涨幅抵达245.62%,总市值89亿元;公司13个生意日成交额抵达90亿元,总换手率达159%。 此外,圣龙股份还在暴…...
黑豹程序员-架构师学习路线图-百科:API接口测试工具Postman
文章目录 1、为什么要使用Postman?2、什么是Postman? 1、为什么要使用Postman? 目前我们开发项目大都是前后端分离项目,前端采用h5cssjsvue基于nodejs,后端采用java、SpringBoot、SSM,大型项目采用SpringC…...

独立开发者如何借助Taotoken多模型能力优化个人项目成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力优化个人项目成本 对于独立开发者和小型项目而言,在探索大模型应用时࿰…...

【亲测免费】 TSK UF系列Prober操作手册下载
TSK UF系列Prober操作手册下载 【下载地址】TSKUF系列Prober操作手册下载 本仓库提供TSK UF系列Prober的操作手册下载,具体为UF190/UF200系列的manual。TSK UF系列Prober是半导体厂针测的重要设备,该手册详细介绍了设备的各项功能、操作步骤以及维护保养…...

3步掌握B站视频转文字神器:为什么你需要这个效率提升10倍的工具
3步掌握B站视频转文字神器:为什么你需要这个效率提升10倍的工具 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾经为了整理一个精彩的B站…...

从 SAP Easy Access Menu 到 FLP 一体化入口:重新理解经典事务在 SAP Fiori 中的价值
在很多企业的数字化项目里,SAP Fiori 往往被理解为一套全新的体验层,而 SAP GUI 则被视为必须逐步替换掉的传统界面。这个判断只说对了一半。真正成熟的 Fiori 落地,不是把旧世界一刀切掉,而是让新旧能力在同一个入口里顺滑协作。SAP Easy Access Menu 的意义,恰恰就在这里…...

【教育研究者的AI外脑】:NotebookLM如何72小时内重构文献综述工作流?
更多请点击: https://codechina.net 第一章:【教育研究者的AI外脑】:NotebookLM如何72小时内重构文献综述工作流? 教育研究者长期面临文献爆炸与认知过载的双重压力:平均每位博士生需精读300篇中英文文献,…...

系统安全加固实战:在统信UOS与麒麟KOS中精准禁用指定网卡
1. 为什么需要精准禁用网卡? 在企业办公环境或高安全需求的服务器场景中,网络接口就像房子的门窗。你可能需要关闭某些不常用的出入口来防止入侵——比如禁用员工电脑的无线网卡来防止连接外部热点,或者在服务器上关闭非必要的物理网口来减少…...

算法工程师简历封神指南:项目细节 + 论文 / 竞赛成果缺一不可
引言:算法岗简历的“死亡三连”,你中了吗? “熟悉CNN、Transformer、大模型微调,掌握PyTorch、TensorFlow”——当面试官第88次看到这句“算法词典式”技能描述时,已经开始默默划走简历。2026年算法岗卷到什么程度?智联招聘数据显示,硕士学历算法岗平均竞争比达300:1,…...

从FFT到CZT:解锁频谱细化的精准分析新维度
1. 为什么我们需要频谱细化? 在信号处理的世界里,傅里叶变换(FFT)就像是一把瑞士军刀,几乎每个工程师都会用它来分析信号的频率成分。但当你面对两个频率非常接近的信号时,FFT就显得力不从心了。我曾在一次…...
)
瑞萨RA系列MCU入门实战:用e2 studio和FSP库5分钟点灯(从安装到烧录)
瑞萨RA系列MCU五分钟极速入门:从零点亮LED的全流程解析 当一块全新的瑞萨RA系列开发板第一次在你手中亮起LED时,那种"Hello World"式的成就感往往能瞬间点燃学习热情。不同于传统教程按部就班的软件安装介绍,本文将带您体验实战驱…...

思科CCNA认证备考:从题库到实战,这11个章节的易错点你踩过几个?
思科CCNA认证通关指南:11大核心章节的深度避坑策略 从题库到实战的认知跃迁 当您翻开CCNA的备考资料时,是否曾感到困惑——即使熟记题库答案,在实际操作和模拟考试中仍频频出错?这种现象在认证考生中极为普遍。问题的根源往往不在…...