Linux_虚拟内存机制
虚拟内存是如何工作的
我们的程序中使用的所有地址都是虚拟地址,但实际数据是从磁盘空间缓存在物理内存中,读的还是内存中的数据,所以每次CPU的访存操作都会先将虚拟内存交给CPU中的MMU硬件,利用存在主存(实际也可能在高速缓存或快表中)中的查询表进行动态翻译,将其转化成实际的物理地址,再进行访存
地址翻译
我们将虚拟内存以一定大小(如4KB)进行分割,称为虚拟页;类似的,我们将物理内存也以相同大小进行分割,称为物理页(页帧),之后便以页为单位进行二者的映射
我们会为虚拟内存空间维护一个用于映射的数组,这个数组我们称为页表,数组元素称为页表项(PTE),页表项中存着物理页的下标和一些标记位,通过页表可以从虚拟页映射的物理页
假设我们的虚拟地址空间是一个32位的地址空间,即共有4GB大小,一个虚拟页为4KB,所以这个虚拟地址可分割为220 = 1M个页,也就是说我们的页表需要有1M个数组元素
模拟一次地址转化:
假设我们此时有一个32位的虚拟地址:0x12345678,需要翻译为物理地址,我们将这32位地址分为两部分:
- 页内偏移量(如果一个页是4K,则是地址的低12位)
- 虚拟页号(剩余的32-12 = 20位)
此时我们提取高20位:0x12345,作为虚拟页号(页表数组下标),在页表中找到对应的页表条目(PTE),其中存储着物理页号,假设是0x0000a,将这个物理页下标与前面的页内偏移量组合,生成物理地址,这个物理地址就是0x0000a78
后面为了方便,我们将不会反复重复这个分割、索引、重组地址的过程,会直接说虚拟地址通过页表获得物理地址
作为缓存工具
每一个运行中的进程都会维护一个自己的页表,也就是说在每个进程的视角下,自己都有一个完整的4GB空间
当我们编译好一个程序,这个程序就是一个普通的二进制文本,存储在磁盘上;当我们启动一个程序,磁盘上的程序数据也不会一下全缓存到内存空间中,而是一个运行中动态加载的方式,而虚拟内存机制成就了这种运行时加载的方式
我们假设每个PTE都有两个标记位:是否使用、是否已缓存
如果一个虚拟页未被使用,则当前页表项不会映射任何实际数据
一个被使用的页又可以是两种情况
- 已缓存:数据已经从磁盘缓存到了物理内存中,PTE中存的是物理页下标
- 未缓存:数据还未被缓存到物理内存,PTE存的是磁盘上的页表位置
此时我们就可以把虚拟页面分为三种:
- 未使用
- 缓存的
- 未缓存的
缺页
当MMU拿到虚拟地址,到页表中索引到对应的PTE,
- 如果未使用,则会引发段错误异常,表示这个虚拟地址有问题。
- 如果当前页已缓存到了物理内存,则直接拿着PTE中的物理地址进行访存即可
- 如果当前页没有缓存到物理内存,则会引发缺页异常
缺页异常处理:
缺页异常会调用内存中的缺页异常处理程序,该程序会
- 选择一个牺牲页,它的PTE中标记着该页是否有内容被修改过,如果修改过,则将这个页复制回磁盘
- 通过被载入页的PTE中的磁盘上的页表位置,在磁盘中拿取数据,覆盖牺牲页
- 更新这个PTE后返回
异常处理结束后会重新执行引发异常的那条指令(即CPU访存的指令),再次将虚拟地址交给MMU,MMU此时再访问页表的时候就不会发生缺页,可以顺利从PTE获取到物理地址,然后访存
像这种不命中时才换入页面的策略称为按需页面调度
其中牺牲页的选择涉及到一些如最近最少用、先进先出、时钟算法、最不常用等页面调度算法此处我们暂不讨论
分配页面
在程序运行过程中,也有新增页面的事件发生,如调用malloc申请堆空间的时候,可能会需要在物理内存申请一块空间,在页表中找合适的PTE将有效位设为1,指向物理块。具体堆空间申请等内容后面还会细讲。
虚拟内存作为内存保护工具
内存中的数据的访问一定是由由一定安全限制的,如不允许一个进程读写其它进程的非共享内存,不允许对只读数据进行修改,不允许对内核代码进行读写…
而虚拟内存这种地址翻译机制刚好可以以一种自然的方式扩展到更好的访问控制
我们可以在PTE中添加一些权限许可位,如:
SUP:如果设为1,只有在内核模式下才能访问当前块
READ:当前块是否可读
WRITE:当前块是否可写
进行地址翻译时,首先通过虚拟地址找到PTE,然后读取其中的权限许可位,若一条指令违反了某些许可条件,则会触发一个一般保护故障,将控制传递给内核的异常处理程序,Linux Shell通常将这样的异常称为“段错误”。
高速缓存和TLB
我们将存储器层次由慢到快分为这样几层:
- 磁盘
- 内存(DRAM)
- 高速缓存(SRAM)
- [TLB]:只有地址翻译会用到
- 寄存器:一般和CPU放在一起
上面的存储器由上到下一般:容量递减、造价递增、速度递增、距离CPU越来越近,TLB是一个专门为MMU提供服务的存储空间
磁盘比内存慢大约100 000倍,内存比高速缓存慢大约10倍
我们要做的就是想尽办法让使用频率高的数据尽量离CPU近
然后我们还要知道,页表条目作为一种高频使用的数据,可以出现在内存,也可以出现在高速缓存,当然,最好出现在专门为它准备的物理存储器—TLB中
什么是TLB?
许多系统在MMU中包含一个关于PTE的小缓存称为快表(TLB)
如果PTB仅在内存中,则地址翻译会造成多一次访存、代价是消耗几十到几百个周期,如果恰好数据在高速缓存,则可以下降到一到两个周期,为了消除这样的开销,如果PTB在TLB中,则可以消除这样的开销
当MMU拿到一个虚拟地址,首先会到快表中寻找对应的PTE,若命中,则直接拿物理地址进行访存
若未命中,则到高速缓存中查找,将新取出的PTE放到快表(可能会覆盖已存在的条目),然后进行访存
若高速缓存还未命中,再去内存中找,并更新高速缓存
通过物理地址进行访存时,数据也可能同时存在与高速缓存与内存当中
在这样的多级存储结构中,同样的数据可能会出现在多个地方,比如高速缓存中的数据往往是内存中数据的一个拷贝,而且既然存储着那块内存中的数据,也就意味着这块高速缓存同时也代表着那块内存
但由于数据可能存在与多处,对于多个进程共享内存的情况,应该及时处理好数据的写回,避免数据不同步
多级页表
目前为止,我们都是假设系统中只有一个单独的页表进行地址翻译,但是一个32位的地址空间,如果一页4KB,则需要1M个页表条目,如果一个条目时4B,那一个页表就是4MB,也就是说,一个进程至少需要额外耗费4MB的空间用于维护虚拟地址空间,如果说还可以接收,那对与64位地址空间,问题将变得更复杂。
为了解决这样的问题,通常使用层次结构的页表
假设当前使用一个两层的页表,一级页表并非直接指向目标物理页的地址,而是一个指向二级页表的基地址(这个地址也是物理地址,存放二级页表的地址),二级页表指向的才是物理页。
假设一级页表有210个页表条目,也就是可以指向1K个二级页表,那么对于一个32位地址空间,如果一页4KB,那么一个二级页表只需要210 = 1K个页表条目
程序刚加载的时候只需为一级页表初始化空间,然后将其所有的页表条目都初始化为未缓存,直到发生访存,需要访问某个物理页的数据时,才初始化那个页的以及所属的二级页表
在翻译过程中,则需要多级寻址,按照上述的二级页表案例,只需将虚拟地址分为三部分:
- 高10位:作为一级页表的索引下标,找到二级页表基地址
- 中间10位:作为二级页表的索引下标,找到物理页的基地址,或者说用来组成物理地址
- 最后12位;作为在一个4K页中的偏移量,用于组成物理地址
实际情况中可能会有更多级页表,
这里引出了一个小点:
既然二级页表的基地址在一级页表中,那一级页表的基地址呢?
事实上,这个物理地址在进程刚启动的时候,被初始化到进程控制块的某个字段,进程被调度后会加载到某个寄存器(如CR3)中,具体哪个寄存器会根据处理器架构而异,当我们拿着虚拟地址去内存中页表的时候,首先会从寄存器拿到页表基地址+虚拟地址中截取的页表下标,组成的这个物理地址就是目标PTE的首地址
虚拟内存是如何被管理的
Linux虚拟内存系统
Linux的每个进程单独维护一个自己的虚拟内存空间
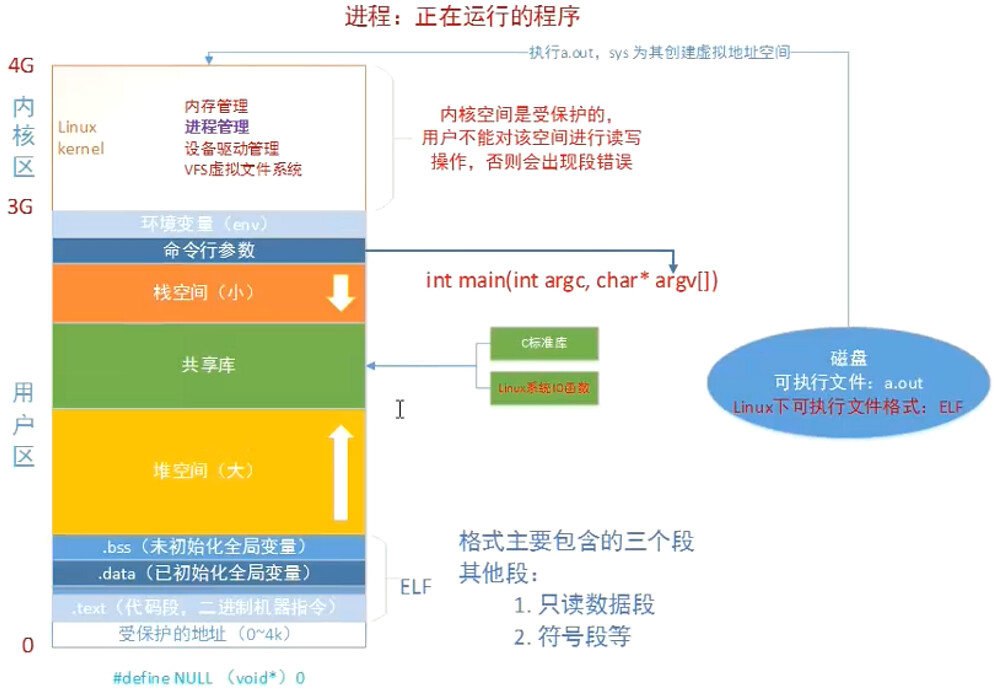
在内核区,有些内容是每个进程不相同的,如:与进程相关的数据结构,如:页表,task结构,mm结构,内核栈;
也有每个进程都相同的内容,如内核代码和数据,这部分的物理页是被所有进程共享的
Linux虚拟内存区域
Linux将已分配的虚拟内存组织成一些区域(也叫段),每个区域是由多个已被分配的连续虚拟页组成的,例如:代码段、数据段、堆、共享库段
每个段中的虚拟页一定是已经被分配的,任何一个已经被分配的段一定属于某个段
且段和段之间允许存在空隙
在进程概念一文中,我们用一个进程数据结构(task_struct)描述一个进程,其中有进程运行所需要的所有信息(如:PID、指向用户栈的指针、可执行文件的名字、程序计数器),有一个条目指向mm_struct,它描述虚拟内存的当前状态,我们主要关注两个字段,pgd和mmap,其中pgd指向一级页表的基址(物理地址),当前进程被调度后pgd会存放到CR3寄存器中;mmap指向一个vm_area_struct(区域结构)的链表,每个vm_area_struct描述当前虚拟地址空间的一个区域
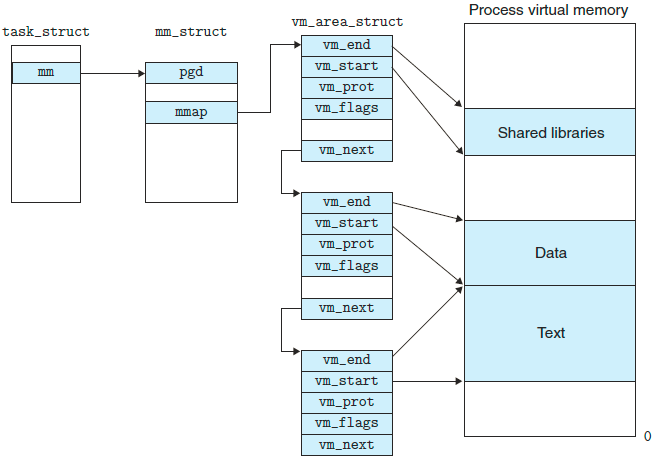
- vm_start:指向这片区域的起始位置(虚拟地址)
- vm_end:指向这片区域的结束位置(虚拟地址)
- vm_prot:当前区域的所有页的读写许可权限
- vm_flag:描述一些信息,如:当前区域页面是否与其它进程共享
- vm_next:指向下一个链表节点
注意,上图的左边三列是实实在在存在与物理内存中的数据,而最有一列是对虚拟内存空间的具象描述,可以认为是整个页表的划分
Linux缺页异常处理
当缺页异常触发,控制转移到内核的缺页异常程序后,会执行以下步骤:
-
遍历vm_area_struct链表,判断此虚拟地址是否在任意一个节点的vm_start和vm_end之间,若否,则触发段错误,进程终止
(因为一个进程可以手动新建任意个区域,所以链表节点可能会很多,Linux为了提高索引效率,会维护一棵树)
-
判断操作是否符合读写许可权限
-
进行页面替换
再看内存映射
操作系统通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化虚拟内存区域的内容,这个过程称为内存映射。可以映射到的文件可以分为两种
- Linux文件系统中的普通文件;起初在数据还未从磁盘加载到内存时,页表条目会存储磁盘上的页表位置,我们前面谈到的都是普通文件
- 匿名文件:当一个区域映射到一个匿名文件,内核会在我们第一次引用这块空间,调用缺页中断时,内核会选择一个牺牲页,选择性写回磁盘,然后将这个物理页初始化为全0,供用户使用。这块空间不代表磁盘上的任何实际文件,且此页面会被设置驻留内存的标记,一般不会作为牺牲页。
交换空间
之所以会有页面调度发生,一定是因为有一定的数据结构对其进行管理,且这块空间是有限的
内核会为我们维护专门的交换文件(也叫交换空间、交换区域),页的替换实际是利用交换空间中完成的。任何时候,交换空间控制着当前运行的进程能够分配的虚拟页面总数。
用户级内存映射
Linux提供接口,允许用户创建新的虚拟内存区域,为其映射普通文件或匿名文件
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);//为进程创建新区域(段)
int munmap(void *addr, size_t length);//删除某个区域
- 返回值:区域的
vm_start; - addr:区域的
vm_start,通常设置为NULL,表示由操作系统决定 - length:区域的大小
- prot:虚拟内存区域的访问权限
- PROT_EXEC:页面由可执行代码组成
- PROT_READ:区域的页面可读
- PROT_WRITE:区域的页面可写
- PROT_NONE:此区域页面不能被访问
- flag:描述被映射的对象
- MAP_ANON:匿名对象
- MAP_PRIVATE:私有的写时复制的对象
- MAP_SHARED:共享对象
- fd:文件描述符
- offset:从距文件开始处偏移offset字节的地方开始
让内核创建一个新的包含size字节的只读、私有、请求二进制零的虚拟内存区域
char* bufp = mmap(NULL, size, PROT_READ, MAP_PRIVATE|MAP_ANON, 0, 0);
动态内存分配
动态内存分配器维护着堆空间,这块空间向上生长,对于每个进程,内核维护着一个变量brk(读作break),它指向堆顶
分配器将堆视为一组不同大小的块,每个块由连续的虚拟内存片组成,这些内存片可以是已分配的,可以是空闲的
对于块的分配都是显式的,但对块的释放由分配器种类决定
- 显式分配器:要求程序员主动释放任何已分配的块,如C/C++的
malloc-free、new-delete - 隐式分配器:也称垃圾收集器,申请的块由分配器检测并自动释放,如Lisp、ML、Java之类的高级语言依赖垃圾回收器释放已分配的块
这里我们只讨论显式分配器的设计和实现
malloc和free
C标准库提供了一个称为malloc程序包的显式分配器
#include <stdlib.h>void *malloc(size_t size);
void free(void *ptr);
void *calloc(size_t nmemb, size_t size);
void *realloc(void *ptr, size_t size);
具体使用方式相信大家在C语言学习中了如指掌了
malloc则可以通过使用我们前面用户级内存映射所描述的mmap系统调用接口或者显式地分配和释放堆空间,或者还可以使用sbrk接口
#include <unistd.h>void *sbrk(intptr_t increment);
此函数可以通过将内核地brk指针增加increment(可正、可负、可0)来扩展和收缩堆,如果成功则返回brk的旧值,否则返回-1,errno设置为ENOMEN
分配器的目标
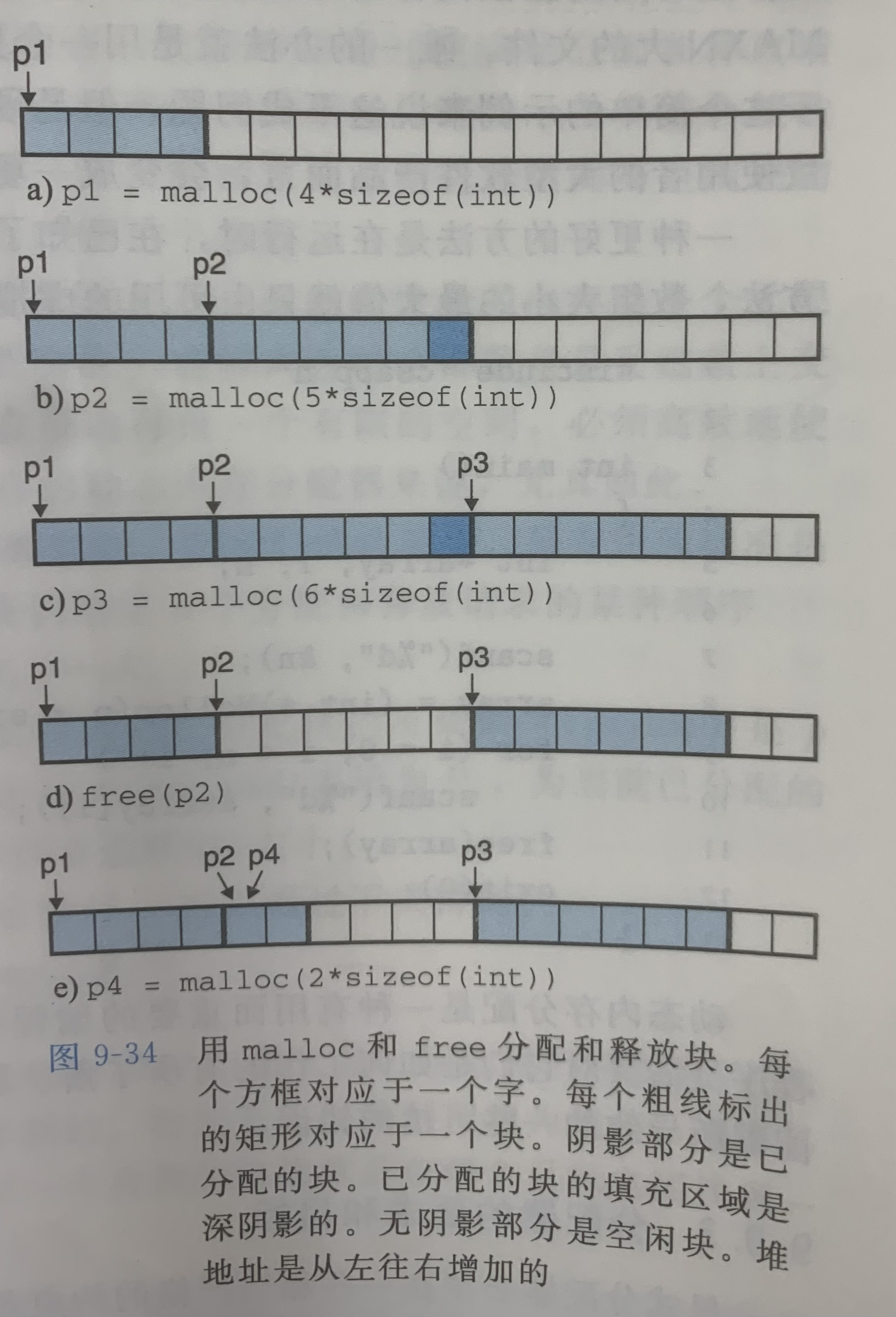
如上,展示了malloc和free如何管理一个16字的堆空间,每个小方格代表一个四字节的字
起始时,堆由一个16字的、双字(8字节)对齐的空闲块组成
请求过程:
- 程序请求4字的块(p1)
- 请求一个5字的块(p2),实际分配了一个6字的块,为了保证双字对齐,malloc在块里多填充了一个字
- 程序请求一个6字的块(p3)
- 释放p2
- 申请2字的块,利用的是当初p2的空间
这个过程,分配器需要需要关注两个问题
- 尽快找到合适的连续空间供申请,尽快找到需要释放的空间,在单位时间内完成尽量多的请求
- 最大化空间的利用率
这二者相互制衡,分配器设计的挑战就是找到一个适当的平衡
内存碎片
造成空间利用率低的主要原因是一种称为碎片的现象,有两种形式的碎片:
-
内部碎片:在上面的第2步操作中请求了一个5字的块,我们将其称为有效载荷,实际分配了6个字,称为已分配块
所谓内部碎片就是已分配块 - 有效载荷
有很多原因造成内部碎片:
- 有些分配器为申请的块强制要求一个最小大小,如果申请的块小于这个大小则需要额外填充;
- 或者因为如上的对其要求而产生的1字额外填充块
-
外部碎片:如果第5步结束后再申请6字的块,则需要向内核申请额外的虚拟内存,即使当前的堆空间还有6个空闲字
像这样分布在已分配块中间但无法使用的块称为外部碎片
外部碎片的量化比内部碎片困难的多,它取决于当前请求的模式和分配器的实现方式,还取决与将来的请求模式。
因为这种难以量化与与可预测,分配器通常要采用启发式策略来试图维护少量、大空间的块
需要考虑的因素
知道了分配器的目标和内存碎片的存在,我们就可以考虑一个分配器实现需要考虑的问题
- 空闲块的组织:需要特定的数据结构维护这些空闲块
- 适配策略:当出现一个请求,如何挑选合适的块用来分配
- 分割:选了一个空闲块,如果用不了这么多,如何处理剩下的
- 合并:当一个块释放了,何时、如何将其与前后紧挨着的空闲块进行合并
下面,我们将就这些角度谈谈动态内存分配器的设计
堆空间的数据结构
隐式空闲链表
分配器需要一些数据结构组织已分配的块、空闲块,大多数分配器将这些信息嵌入块本身
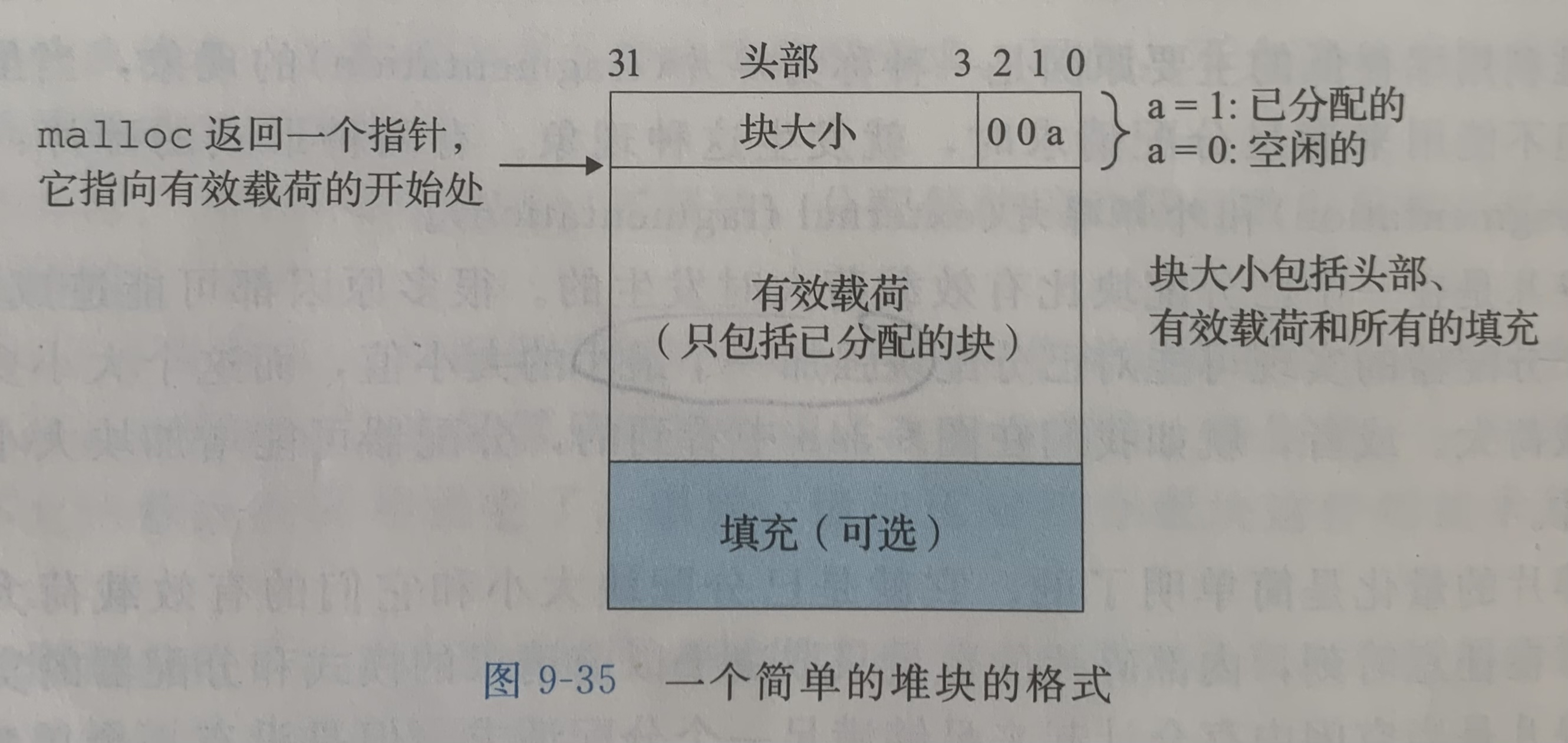
每个块包含一个字的头部,包含块的大小和一些标记位
如果我们给块的分配一个双字约束,块的大小则一定是8的倍数,此时块大小的低三位一定是0,因此我们只需要高29位,于是用剩余的3位来编码其它信息,其中最低位用来表示当前块是否已分配
假设我们有一个已分配的24(0x18)字节的块
则它的头部就是:
0x18 | 0x1 = 0x19解释头部,获取块大小的方法:
0x19 >>= 3 <<=3 = 0x18
这样的一个个块在虚拟空间中紧密排列,当获取到一个块的头部,就能通过其中的块大小字段跳跃到下一个块的头部,从而形成链式结构
只要遍历堆中所有的块,即可从中筛选出空闲块集合
这样的结构优点是简单;缺点是所有的操作都需要线性遍历块,效率低
显式空闲链表
利用上面的隐式空闲链表,块的分配与块的总数(包含已分配和未分配的)成线性关系,对于通用的分配器效率有些低
于是我们给空闲块添加两个指针,分别指向另外两个空闲块,让所有空闲块形成一个双向链表,通过链表即可获得所有的空闲块,不在需要从两种块中筛选

显式链表的排序策略有两种:
- 后进先出:维护一个尾部块的指针,有块释放即从尾部插入,对块的申请也从后向前查找合适的块。释放块在常数时间内完成,如果有脚部字段,合并也可在常数时间完成。
- 按照地址顺序:按照虚拟地址的大小对空闲块排序。释放时需要线性时间在隐式链表中找合适的空闲块前驱;优势在于这种情况下的首次适配会有更高的内存利用率。
分离的空闲链表
虽然使用显性链表分配块时排除了查找过程中的已分配块,但需寻找合适块依然是线性的,一种流行的减少分配时间的方法俗称分离存储。
分配器会维护一个空闲链表数组,数组的每个元素指向一条链表,每条链表的块大小大致相同,于是就需要将所有可能的款大小分成一些等价类(也叫大小类),有很多种划分方式,例如,可以使用2的幂来划分:
{1},{2},{3,4},{5 ~ 8},…,{4097 ~ ∞};
适配策略
应用程序请求一个k字节的块时,分配器需要搜索空闲链表搜索一个足够大的空闲块,搜索的方式由放置策略决定
放置策略:
- 首次适配:从头开始搜索合适大小的块
- 下一次适配:从上一次查询结束的地方开始搜索
- 最佳适配:对所有块遍历,找到最合适的
下一次适配相较首次适配更快,首次适配的内存利用率更高
最佳适配时间效率太低
分割空闲块
如果分配器找到一个空闲块,必须做另一个决策
- 直接用整个空闲块,这种方式简单快捷,但会造成内部碎片,如果放置策略趋向产生好的匹配,内部碎片可以接受
- 将空间非为两部分,一部分变成分配块,剩余
- 变成新的空闲块
获得额外的内存空间块
当程序请求了一块空间时,分配器首先检查是否有合适的空闲块,若找不到
- 合并哪些相邻的空闲块来创建更大的空闲块(下一节)
- 如果已经做大程度合并了,则需要调用sbrk,向内核请求额外的堆内存
合并空闲块
当分配器释放一个已分配的块,可能有其它空闲块与它相邻,这些相邻的空间可能引起一种假象,叫做假碎片,为了防止一个实际上连续的空闲块被分割为小的、无法使用的空间块,分配器往往要对其进行合并,合并的时机也有两种:
- 立即合并:每次释放一个块时,检查这个块的前面和后面是否为空闲块,进而合并
- 推迟合并:等到分配请求失败的时候,扫描整个堆,合并所有空闲块
快速的分配器通常会选择某种形式的推迟合并。
带边界标记的合并
前面我们说,块的头部标记了当前块的大小
那么如果需要在释放当前块时进行合并,那么则可以通过当前头部字段知道下一个块的头部位置,从而判断下一个块是否为空闲块,并结合下一个块的大小将两者合并
那么如何得知上一个块的标记呢?获得上一个块的头部。
那如何获得上一个块的头部呢?此时只能从头开始线性查找
为了能够在常数时间内得知上一个块的大小,我们在每个块的尾部添加一个脚部字段,与头部字段类似

当需要得知上一个块的标记位,只需从当前块的头部向前读一个字,即可拿到上一个块的尾部,从而得知上一个块是否空闲及其大小
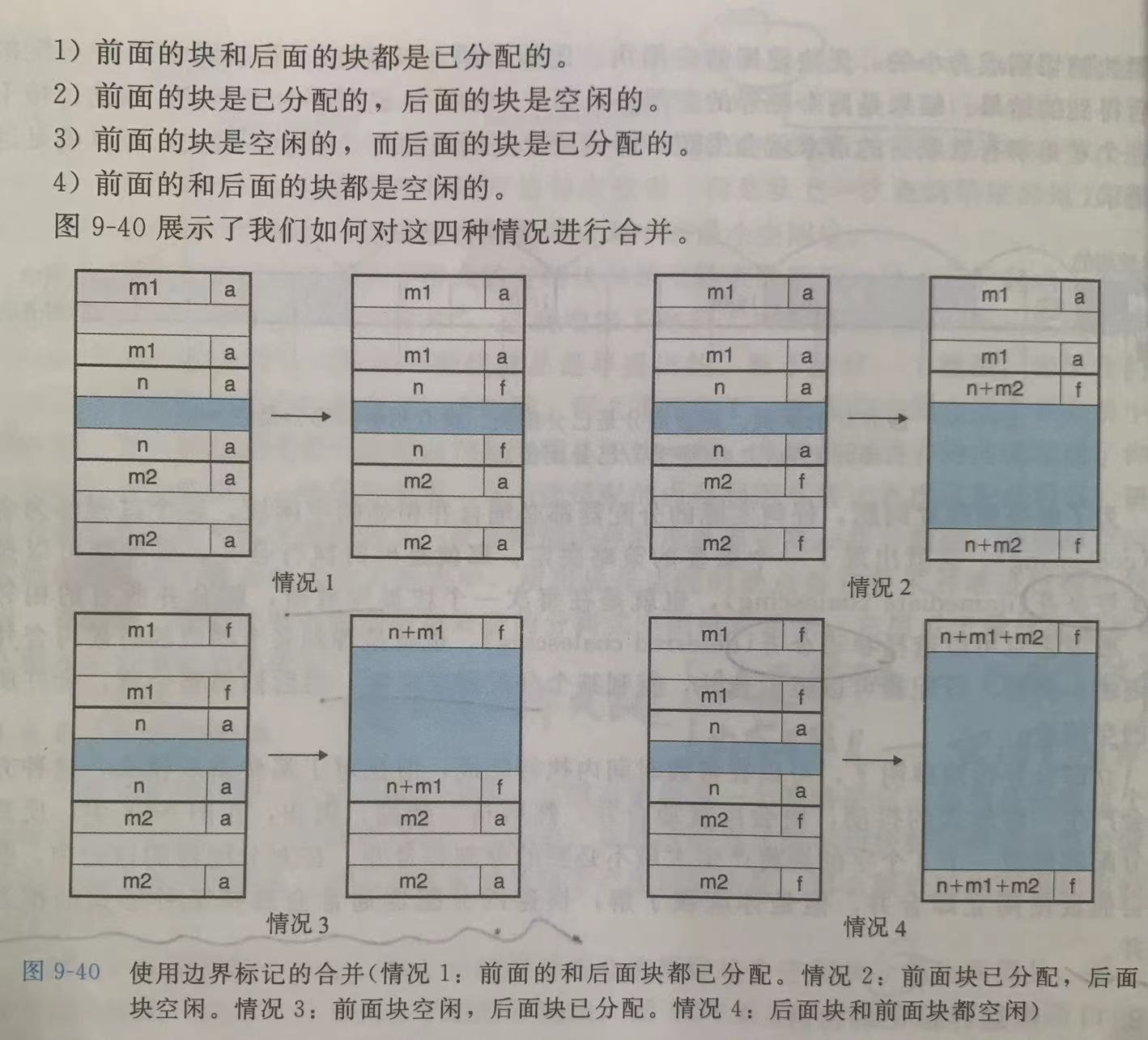
上图是四种情况下的合并,主要看合并时对中间的头部和脚部的清除,以及更新新块的头部和脚部
总结
虚拟内存是对主存的一个抽象
提供三个重要的功能:
- 在主存中主动缓存最近使用的存在磁盘上的虚拟地址空间内容
- 简化了内存管理,进而简化了链接、进程间共享内存、进程的内存分配以及程序加载
- 通过在页表条目加入保护位,简化了内存保护
通过将虚拟内存片和磁盘上的文件片关联起来,初始化虚拟内存,这个过程称为内存映射。内存映射为共享数据、创建新进程、加载程序提供了一种高效的机制。
相关文章:
Linux_虚拟内存机制
虚拟内存是如何工作的 我们的程序中使用的所有地址都是虚拟地址,但实际数据是从磁盘空间缓存在物理内存中,读的还是内存中的数据,所以每次CPU的访存操作都会先将虚拟内存交给CPU中的MMU硬件,利用存在主存(实际也可能在…...

淘宝官方开放平台API接口获得店铺的所有商品、商品id、商品标题、销量参数调用示例
在电商平台中,获取店铺所有商品是一个非常常见的需求。这个功能允许用户一次性获取指定店铺中的所有商品信息,方便用户对店铺的商品进行浏览和筛选。下面将对获取店铺所有商品接口的功能进行介绍。 获取全部商品信息:通过调用获取店铺所有商…...

Java Spring 通过 AOP 实现方法参数的重新赋值、修改方法参数的取值
AOP 依赖 我创建的项目项目为 SpringBoot 项目 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.3</version></parent><dependency><groupId…...
Real3D FlipBook jQuery Plugin 3.41 Crack
Real3D FlipBook 和 PDF 查看器 jQuery 插件 - CodeCanyon 待售物品 实时预览 截图 视频预览 Real3D Flipbook jQuery 插件 - 1 Real3D Flipbook jQuery 插件 - 2 Real3D Flipbook jQuery 插件 - 3 新功能 – REAL3D FLIPBOOK JQUERY 插件的 PDF 到图像转换器 一款用于将…...
Pytorch:model.train()和model.eval()用法和区别,以及model.eval()和torch.no_grad()的区别
1 model.train() 和 model.eval()用法和区别 1.1 model.train() model.train()的作用是启用 Batch Normalization 和 Dropout。 如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一…...

Linux CentOS 8(firewalld的配置与管理)
Linux CentOS 8(firewalld的配置与管理) 目录 一、firewalld 简介二、firewalld 工作概念1、预定义区域(管理员可以自定义修改)2、预定义服务 三、firewalld 配置方法1、通过firewall-cmd配置2、通过firewall图形界面配置 四、配置…...

C复习-指针
参考: 里科《C和指针》 指针存储的是一个地址,实际就是一个值。 如果像下面一样对未初始化的指针进行赋值,如果a的初始值是非法地址,那么会报错。UNIX会提示段错误segmentation violation,或内存错误memory fault&…...
方法)
Runnable和Thread的区别,以及如何调用start()方法
Runnable和Thread都是Java多线程编程中的核心概念,它们之间存在以下主要差异: Runnable是一个接口,而Thread是一个类。这意味着我们可以通过实现Runnable接口来创建线程,或者直接继承Thread类并重写其方法。Runnable只包含一个ru…...

云音乐Android Cronet接入实践
背景 网易云音乐产品线终端类型广泛,除了移动端(IOS/安卓)之外,还有PC、MAC、Iot多终端等等。移动端由于上线时间早,用户基数大,沉淀了一些端侧相对比较稳定的网络策略和网络基础能力。然而由于各端在基础…...

Linux dup和dup2
Linux dup和dup2函数,他们有什么区别,什么场景下会用到,使用它们有什么注意事项 dup和dup2都是Linux系统中的系统调用,用于复制文件描述符。它们的主要区别在于如何指定新的文件描述符以及处理新文件描述符的方式。 dup函数 #i…...
Spring Boot实战 | 如何整合高性能数据库连接池HikariCP
专栏集锦,大佬们可以收藏以备不时之需 Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html Logback 详解专栏:https:/…...

Spring依赖注入
依赖注入底层原理流程图: https://www.processon.com/view/link/5f899fa5f346fb06e1d8f570 Spring中有两种依赖注入的方式 首先分两种: 手动注入自动注入 手动注入 在XML中定义Bean时,就是手动注入,因为是程序员手动给某个属…...

Linux下Jenkins自动化部署SpringBoot应用
Linux下Jenkins自动化部署SpringBoot应用 1、 Jenkins介绍 官方网址:https://www.jenkins.io/ 2、安装Jenkins 2.1 centos下命令行安装 访问官方,点击文档: 点击 Installing Jenkins: 点击 Linux: 选择 Red Hat/…...

【git 学习】--- ubuntu18.04 搭建本地git服务器
在Ubuntu18.04 上简单创建自己的git服务器~ 环境配置 Ubuntu: 18.04git服务器搭建步骤: ##1.安装git sudo apt-get install git##2.添加用户 sudo adduser test_git //test_git -- git用户名##3. 在Git用户的home目录下创建文件夹,作为裸仓库 sudo…...
JAVA电商平台免费搭建 B2B2C商城系统 多用户商城系统 直播带货 新零售商城 o2o商城 电子商务 拼团商城 分销商城
涉及平台 平台管理、商家端(PC端、手机端)、买家平台(H5/公众号、小程序、APP端(IOS/Android)、微服务平台(业务服务) 2. 核心架构 Spring Cloud、Spring Boot、Mybatis、Redis …...

Android 13 Framework 裁剪
裁剪应用 1. 修改 build/core/product.mk 添加PRODUCT_DEL_PACKAGES变量的声明 新增一行_product_single_value_vars PRODUCT_DEL_PACKAGES # The first API level this product shipped with _product_single_value_vars PRODUCT_SHIPPING_API_LEVEL _product_single_val…...

【Axios封装示例Vue2】
文章目录 为什么要封装axios?如何封装axios在Vue组件中使用封装的axios 为什么要封装axios? 在Vue 2项目中,直接在组件中使用axios可能会导致以下问题: 代码重复:每个组件都需要导入axios并编写相似的请求代码&#…...

k8s-----20、持久化存储--PV/PVC
PV/PVC 1、概念1.1 基本定义1.2 生命周期1.3 PV 卷阶段状态 2、 示例2.1 创建pod和PVC 与PV2.2 绑定PV2.3 强制删除pv,pvc2.4 测试 1、概念 1.1 基本定义 PersistentVolume(PV)是集群中由管理员配置的一段网络存储。 它是集群中的资源,就像…...

python matplotlib 生成矢量图
import matplotlib.pyplot as plt plt.savefig(r"xxx.svg", format"svg")注意: plt.savefig(r"xxx.svg", format"svg") 需要放在 plt.show()前面 原因:如果在 plt.show()调用后, 实际上已经创建了一…...

机器学习中常见的特征工程处理
一、特征工程 特征工程(Feature Engineering)对特征进行进一步分析,并对数据进行处理。 常见的特征工程包括:异常值处理、缺失值处理、数据分桶、特征处理、特征构造、特征筛选及降维等。 1、异常值处理 具体实现 from scipy.s…...

AI智能体技能开发实战:从awesome-agent-skills到高效智能体构建
1. 项目概述:从技能清单到智能体构建的实战指南最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个名字:awesome-agent-skills。这个由VoltAgent维护的开源项目,乍一看就是个GitHub上常见的“Awesome”…...

智能识别整理会议内容,让开会后怎么列待办更清晰更省事
作为经常跑客户、开会议的销售,此前我常被整理沟通内容、梳理待办的工作困扰,不仅耗时久,还容易漏记客户需求、搞错时间节点。结合大半年的实测体验,整理出一套AI整理方法,能快速清晰梳理待办,节省大量时间…...
)
深入浅出:STM32 USB BOS描述符与WCID配置详解(以WinUSB免驱为例)
STM32 USB BOS描述符与WCID配置实战解析:从协议到代码实现 在嵌入式开发领域,USB设备与主机系统的无缝对接一直是开发者关注的重点。传统USB设备在Windows平台上通常需要安装专用驱动程序,这不仅增加了用户使用门槛,也提高了开发维…...

Scroll Reverser终极指南:轻松解决macOS多设备滚动冲突
Scroll Reverser终极指南:轻松解决macOS多设备滚动冲突 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser Scroll Reverser是一款专为macOS用户设计的开源工具ÿ…...

如何用3步快速上手英雄联盟Akari助手:终极智能游戏伴侣完整指南
如何用3步快速上手英雄联盟Akari助手:终极智能游戏伴侣完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁…...

Claude Code提示词入门:CLAUDE.md编写完全指南
目录Claude Code提示词入门:CLAUDE.md编写完全指南 🎯📌 目录1. 什么是CLAUDE.md2. 为什么CLAUDE.md这么重要2.1 没有CLAUDE.md会怎样?2.2 有了CLAUDE.md会怎样?2.3 核心价值3. CLAUDE.md的加载机制3.1 加载优先级3.2 …...

英雄联盟回放播放器:ROFL-Player让历史比赛重现生机
英雄联盟回放播放器:ROFL-Player让历史比赛重现生机 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟客户端更…...

【Claude Redis缓存方案实战白皮书】:20年架构师亲授高并发场景下99.99%命中率的5层缓存协同设计
更多请点击: https://intelliparadigm.com 第一章:Claude Redis缓存方案的演进逻辑与设计哲学 Claude 系统在高并发对话场景下对低延迟、强一致性的缓存层提出严苛要求。其 Redis 缓存方案并非简单封装客户端,而是围绕“语义感知缓存生命周期…...

半小时搞定C#开发
前言 此篇发出的原因有两点 致敬C#开篇 - 孤独战士,一篇包含雄心壮志的开篇,便无疾而终,时隔这么多年回关,内心莫名欣慰,感谢曾经的自己,就像文章标题所说,做一个无谓的孤独战士。笔者看到现在…...

从原理到实战:压敏电阻关键参数解析与精准选型指南
1. 压敏电阻的本质:电路中的"电压保险丝" 第一次接触压敏电阻时,我把它当成了普通电阻,结果在电源防护设计上栽了跟头。这种蓝色圆片状的小器件,实际上是电子工程师最常用的过压保护元件之一。它的工作原理很像保险丝&a…...