Mysql 索引原理和优化方式
一、索引原理
什么是索引
索引是存储引擎用于快速找到记录的一种数据结构。可以联想到字典中的目录。
索引的分类
(1) Hash 索引
Hash 索引是比较常见的一种索引,他的单条记录查询的效率很高,时间复杂度为1。但是,Hash索引并不是最常用的数据库索引类型,尤其是我们常用的Mysql Innodb引擎就是不支持hash索引的。主要有以下原因:
Hash索引适合精确查找,但是范围查找不适合,因为存储引擎都会为每一行计算一个hash码,hash码都是比较小的,并且不同键值行的hash码通常是不一样的,hash索引中存储的就是Hash码,hash 码彼此之间是没有规律的;
且 Hash 操作并不能保证顺序性,所以值相近的两个数据,Hash值相差很远,被分到不同的桶中。这就是为什么hash索引只能进行全职匹配的查询,因为只有这样,hash码才能够匹配到数据。
(2) 二叉树
先来介绍下最经典的二叉树的特点:
- 二叉树的时间复杂度为 O(n)
- 一个节点只能有两个子节点。即度不超过2
- 左子节点 小于 本节点,右子节点 大于 本节点
但是在极端情况下会出现链化的情况,即节点一直在某一边增加。
平衡二叉树(Balanced Binary Tree,简称 ABT)是一种特殊的二叉树,其中每个节点的左右子树的高度之差的绝对值不超过1,并且它的左子树和右子树都是平衡二叉树。平衡二叉树的特点:
- 根节点会随着数据的改变而变更
- 数据量越多,遍历次数越多,IO次数就越多,就越慢(磁盘的IO由树高决定)
(3)B-树
B-树是一棵多路平衡查找树,对于一棵M阶的B-树有以下的性质:
- 根节点至少有两个子女.
- 每个节点包含k-1个元素和k个孩子,其中m/2 <= k <= m.
- 每一个叶子节点都包含k-1个元素,其中m/2 <= k <= m.
- 所有的叶子节点位于同一层.
- 每个节点中的元素从小到大排列,那么k-1个元素正好是k个孩子包含的值域的划分.
可以将B-树理解为一棵更加矮胖的二叉搜索树.
二叉搜索树(Binary Search Tree,简称 BST),是一种特殊的二叉树,其中每个节点的左子树的值都小于该节点的值,而每个节点的右子树的值都大于该节点的值。
(4)B+树
MySQL 中最常用的索引的数据结构是 B+ 树。B+树是B-树的进阶版本,在B-树的基础上又做了如下的限制:
- 每个中间节点不保存数据,只用来索引,也就意味着所有非叶子节点的值都被保存了一份在叶子节点中.
- 叶子节点之间根据自身的顺序进行了链接.
这样可以带来什么好处呢?
- 中间节点不保存数据,那么就可以保存更多的索引,树的层级更少,减少数据库磁盘IO的次数.
- 因为中间节点不保存数据,所以每一次的查找都会命中到叶子节点,而叶子节点是处在同一层的,因此查询的性能更加的稳定.
- 所有的叶子节点按顺序链接成了链表,因此可以方便的话进行范围查询.
聚簇索引
聚簇索引不是一种索引类型,而是一种存储数据的方式。Innodb的聚簇索引是在同一个数据结构中同时保存了索引和数据.
mysql中,主键索引页+数据页组成的B+树就是聚簇索引。聚簇索引中数据页记录的是一条记录的完整的记录。
MySQL 在存储数据的时候是以数据页为最小单位的,且数据在数据页中的存储是连续的,数据页中的数据是按照主键排序的(没有主键是由 MySQL自己维护的 ROW_ID 来排序的),数据页和数据页之间是通过双向链表来关联的,数据与数据时间是通过单向链表来关联的。
也就是说有一个在每个数据页中,他必然就有一个最小的主键,然后每个数据页的页号和最小的主键会组成一个主键目录,假设现在要查找主键为 2 的数据,通过二分查找法最后确定下主键为 2 的记录在数据页 1 中,此时就会定位到数据页 1 接着再去定位主键为 2 的记录。
假设上面的主键目录中的记录是非常非常多的,此时MySQL 会将索引里面的记录拆分到不同的索引页中,最终演变成这个样子:

来自:https://zhuanlan.zhihu.com/p/394429932
刚刚上面是说的其实可以理解为是主键索引,主键索引也是最简单的最基础的索引。所以说建立了主键查询就能变快了。
如何查看索引的一些相关信息?
(1)索引信息
在mysql中,可以使用show create table table_name来查看建表语句,其中包含创建索引的语句:
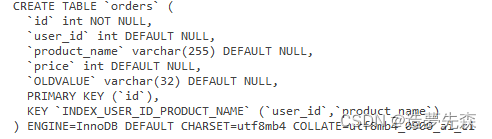
可以使用show index from table_name来查看某个表上的索引,它将会有如下的输出:

可以看到,第一行默认使用了id 作为主索引。B+树在新增数据时,会根据主索引进行重整,影响性能,因此InnoDB推荐以自增id作为主索引:自增且连续,在插入的时候只需要不断的在数据后面追加即可。
后两行使用了联合索引,使用联合索引可以在多个列上进行快速的筛选和排序,特别适用于需要同时查询多个列的情况。
在创建联合索引时,需要注意以下几点:
- 列的顺序很重要:联合索引的效果与列的顺序有关。通常,将最常用于查询的列放在前面可以提高索引的效率。
- 列的选择要合理:不是所有的列都适合创建联合索引,只有在经常用于查询和筛选的列上创建索引才能发挥最大的作用。
- 索引的大小要控制:联合索引的大小会影响插入和更新的性能,因此需要根据实际情况控制索引的大小。
如果需要查询的字段不在联合索引中,MySQL 就需要进行回表查询了,如:
SELECT user_id,product_name,price FROM orders WHERE user_id='2' and product_name='Apple watch';
此时 MySQL 会再次根据主键从聚簇索引的根节点开始查找,这个过程就叫回表。
另外,每建立1个索引,MySQL 就会多维护1个B+树,所以不能建立太多索引,因为索引也会占用空间。
(2)索引大小
在5.0以后的版本中,我们可以通过查看information_schema.TABLES表中的数据来获取更加详细的数据.
该表各字段的含义如下表:
我们可以通过一些查询语句来获取详细的信息,比如:
// 查看当前MySQL服务器所有索引的大小(以MB为单位,默认是字节)
SELECT CONCAT(ROUND(SUM(index_length)/(1024*1024), 2), ' MB') AS 'Total Index Size' FROM TABLES
// 查看某一个库的所有大小
SELECT CONCAT(ROUND(SUM(index_length)/(1024*1024), 2), ' MB') AS 'Total Index Size' FROM TABLES WHERE table_schema = 'XXX';
// 查看某一个表的索引大小
SELECT CONCAT(ROUND(SUM(index_length)/(1024*1024), 2), ' MB') AS 'Total Index Size' FROM TABLES WHERE table_schema = 'yyyy' and table_name = "xxxxx";
// 汇总查看一个库中的数据大小及索引大小
SELECT CONCAT(table_schema,'.',table_name) AS 'Table Name', CONCAT(ROUND(table_rows/1000000,4),'M') AS 'Number of Rows', CONCAT(ROUND(data_length/(1024*1024*1024),4),'G') AS 'Data Size', CONCAT(ROUND(index_length/(1024*1024*1024),4),'G') AS 'Index Size', CONCAT(ROUND((data_length+index_length)/(1024*1024*1024),4),'G') AS'Total'FROM information_schema.TABLES WHERE table_schema LIKE 'xxxxx';
注意:上面的表格是有缓存的,当更新数据库索引之后,最好执行analyze table xxxx,然后再进行查看.MySQL会在表格数据发生较大的变化时才更新此表(大小变化超过1/16或者插入20亿行).
(3) 索引碎片
在索引的创建删除过程中,不可避免的会产品索引碎片,当然还有数据碎片,我们可以通过执行optimize table xxx来重新整理索引及数据,对于不支持此命令的存储引擎来说,可以通过一条无意义的alter语句来触发整理,比如:将表的存储引擎更换为当前的引擎,alter table xxxx engine=innodb.
二、优化方式
1,系统优化
-
硬件:使用好的硬件,更快的硬盘、大内存、多核CPU,专业的存储服务器(NAS、SAN)
-
架构:设计合理架构,如果 MySQL 访问频繁,考虑 Master/Slave 读写分离;数据库分表、数据库切片(分布式),也考虑使用相应缓存服务帮助 MySQL 缓解访问压力
数据库瓶颈
-
IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 --> 分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 --> 分库。 -
CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 --> SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -->水平分表。
分库分表
-
垂直分库
垂直分库是将一个大型数据库按照不同的业务功能或数据类型进行拆分,每个拆分出来的数据库只包含特定的数据表和相关的业务逻辑。这种方式适用于业务复杂、数据结构不同的场景,可以提高数据库的性能和可扩展性。以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。 -
水平分库
水平分库是将一个大型数据库按照数据行进行拆分,将数据行分散到多个数据库中,每个数据库只包含部分数据行。这种方式适用于数据量大、访问频繁的场景,可以提高数据库的并发处理能力和响应速度。比如,根据数据的某个属性(如用户 ID)来分库,将一个大库按某个属性划分为多个小库。 -
垂直分表
垂直分表是将一张表按照列的方式进行分割,将不同的列存储在不同的表中。这种方式适用于表中某些列的访问频率较低,或者某些列的数据量较大,可以将这些列单独存储在一个表中,以减少查询时的数据量和提高查询效率。 -
水平分表
水平分表是将一张表按照行的方式进行分割,将不同的行存储在不同的表中。这种方式适用于表中数据量较大,查询时需要扫描大量数据的情况,可以将数据按照某个条件(如时间、地区等)进行分割,以减少查询时的数据量和提高查询效率。
垂直切分方案适用场景:
数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰、低耦合,那么规则简单明了、容易实施的垂直切分必是首选。
水平切分方案适用场景:
数据库中的表并不多,但单表的数据量很大、或数据热度很高,这种情况之下就应该选择水平切分,水平切分比垂直切分要复杂一些,它将原本逻辑上属于一体的数据进行了物理分割,除了在分割时要对分割的粒度做好评估,考虑数据平均和负载平均,后期也将对项目人员及应用程序产生额外的数据管理负担。比如可以在Mybatis中写一个拦截器,动态的更改表名
分库分表中间件技术选型总结:https://blog.csdn.net/u013898617/article/details/79615427
2, 服务优化
(1)配置合理的MySQL服务器,尽量在应用本身达到一个MySQL最合理的使用
(2)针对 InnoDB 等不同引擎进行不同定制性配置
(3)针对不同的应用情况进行合理配置
公共选项:
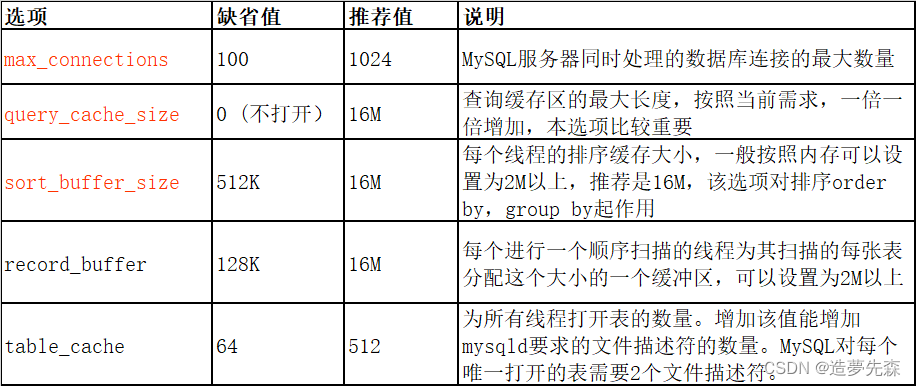
Innodb选项:
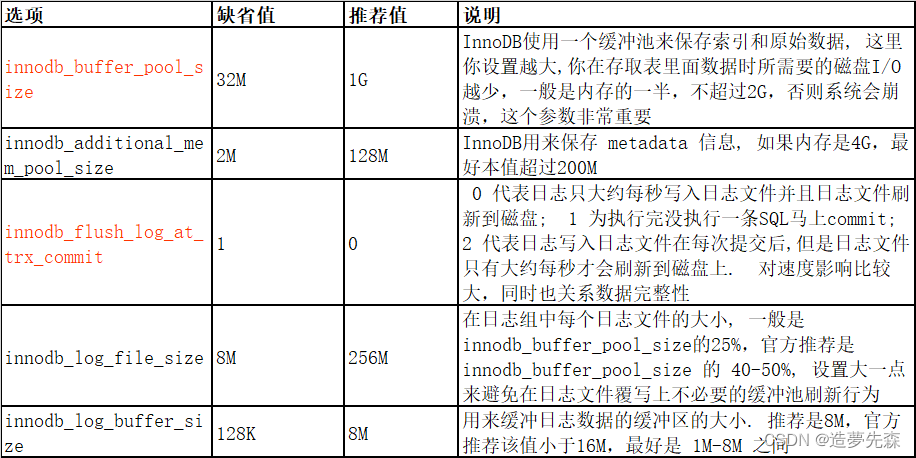
华为云 RDS for MySQL参数调优建议:
https://support.huaweicloud.com/usermanual-rds/rds_08_00001.html
3, 应用优化
(1) 设计合理的数据表结构:适当的数据冗余
(2)对数据表建立合适有效的数据库索引
(3)数据查询:编写简洁高效的SQL语句
表结构设计原则
- 选择合适的数据类型:如果能够定长尽量定长
- 使用 ENUM 而不是 VARCHAR,ENUM类型是非常快和紧凑的,在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美 。
- 不要使用无法加索引的类型作为关键字段,比如 text类型
- 为了避免联表查询,有时候可以适当的数据冗余,比如 邮箱、姓名这些不容易更改的数据
- 选择合适的表引擎,有时候 MyISAM 适合,有时候 InnoDB适合
- 为保证查询性能,最好每个表都建立有 auto_increment 字段, 建立合适的数据库索引
- 最好给每个字段都设定 default 值
索引建立原则
- 一般针对数据分散的关键字进行建立索引,比如ID、QQ,像性别、状态值等等建立索引没有意义
- 字段唯一,最少,不可为null
- 对大数据量表建立聚集索引,避免更新操作带来的碎片。
- 尽量使用短索引,一般对int、char/varchar、date/time 等类型的字段建立索引
- 需要的时候建立联合索引,但是要注意查询SQL语句的编写
- 谨慎建立 unique 类型的索引(唯一索引)
- 大文本字段不建立为索引,如果要对大文本字段进行检索,可以考虑全文索引
- 频繁更新的列不适合建立索引
- order by 字句中的字段,where 子句中字段,最常用的sql语句中字段,应建立索引。
- 唯一性约束,系统将默认为改字段建立索引。
- 对于只是做查询用的数据库索引越多越好,但对于在线实时系统建议控制在5个以内。
- 索引不仅能提高查询SQL性能,同时也可以提高带where字句的update,Delete SQL性能。
- Decimal 类型字段不要单独建立为索引,但覆盖索引可以包含这些字段。
- 只有建立索引以后,表内的行才按照特地的顺序存储,按照需要可以是asc或desc方式。
- 如果索引由多个字段组成将最常用来查询过滤的字段放在前面可能会有更好的性能。
编写高效的 SQL
- 能够快速缩小结果集的 WHERE 条件写在前面,如果有恒量条件,也尽量放在前面
- 尽量避免使用 GROUP BY、DISTINCT 、OR、IN 等语句的使用,避免使用联表查询和子查询,因为将使执行效率大大下降
- 能够使用索引的字段尽量进行有效的合理排列,如果使用了联合索引,请注意提取字段的前后顺序
- 针对索引字段使用 >, >=, =, <, <=, IF NULL和BETWEEN 将会使用索引, 如果对某个索引字段进行 LIKE 查询,使用 LIKE ‘%abc%’ 不能使用索引,使用 LIKE ‘abc%’ 将能够使用索引
- 如果在SQL里使用了MySQL部分自带函数,索引将失效,同时将无法使用 MySQL 的 Query Cache,比如 LEFT(), SUBSTR(), TO_DAYS() DATE_FORMAT(), 等,如果使用了 OR 或 IN,索引也将失效
- 使用 Explain 语句来帮助改进我们的SQL语句
- 不要在where 子句中的“=”左边进行算术或表达式运算,否则系统将可能无法正确使用索引
- 尽量不要在where条件中使用函数,否则将不能使用索引
- 避免使用 select *, 只取需要的字段
- 对于大数据量的查询,尽量避免在SQL语句中使用order by 字句,避免额为的开销,替代为使用ADO.NET 来实现。
- 如果插入的数据量很大,用select into 替代 insert into 能带来更好的性能
- 采用连接操作,避免过多的子查询,产生的CPU和IO开销
- 只关心需要的表和满足条件的数据
- 适当使用临时表或表变量
- 对于连续的数值,使用between代替in
- where 字句中尽量不要使用CASE条件
- 尽量不用触发器,特别是在大数据表上
- 更新触发器如果不是所有情况下都需要触发,应根据业务需要加上必要判断条件
- 使用union all 操作代替OR操作,注意此时需要注意一点查询条件可以使用聚集索引,如果是非聚集索引将起到相反的结果
- 当只要一行数据时使用 LIMIT 1
- 尽可能的使用 NOT NULL填充数据库
- 拆分大的 DELETE 或 INSERT 语句
- 批量提交SQL语句
常用技巧
- 使用 Explain/ DESC 来分析SQL的执行情况
- 使用 SHOW PROCESSLIST 来查看当前MySQL服务器线程执行情况,是否锁表,查看相应的SQL语句
- 设置 my.cnf 中的 long-query-time 和 log-slow-queries 能够记录服务器那些SQL执行速度比较慢
- 另外有用的几个查询:SHOW VARIABLES、SHOW STATUS、SHOW ENGINES
- 使用 DESC TABLE xxx 来查看表结构,使用 SHOW INDEX FROM xxx 来查看表索引
- 使用 LOAD DATA 导入数据比 INSERT INTO 快多了
- SELECT COUNT(*) FROM Tbl 在 InnoDB 中将会扫描全表
- Explain 使用。 语法:EXPLAIN SELECT select_options
Type: 类型,是否使用了索引还是全表扫描, const,eg_reg,ref,range,index,ALL
Key: 实际使用上的索引是哪个字段
Ken_len: 真正使用了哪些索引,不为 NULL 的就是真实使用的索引
Ref: 显示了哪些字段或者常量被用来和 key 配合从表中查询记录出来
Rows: 显示了MySQL认为在查询中应该检索的记录数
Extra: 显示了查询中MySQL的附加信息,关心Using filesort 和 Using temporary,性能杀手
三、Spring Boot如何支持高并发
1. 线程池
线程池是一种重要的并发控制机制,它可以减少线程的创建和销毁开销。Spring Boot提供了很多线程池的实现,包括:
ThreadPoolTaskExecutor
ConcurrentTaskExecutor
SimpleAsyncTaskExecutor
开发人员可以根据自己的需求选择合适的线程池实现
2. 异步处理
异步处理是一种重要的提高并发的机制,它可以将一些耗时的操作交给其他线程去处理,从而提高系统的并发能力。Spring Boot提供了很多异步处理的方式,包括:
DeferredResult
Callable
DeferredResult
使用这些方式可以将一些耗时的操作异步处理,从而提高系统的并发能力。
3. 缓存
缓存是一种重要的提高系统性能的机制,它可以将一些经常使用的数据缓存到内存中,从而减少数据库的访问次数。Spring Boot提供了很多缓存的实现,包括:
EhCache
Redis
Guava
使用这些缓存实现可以将一些经常使用的数据缓存到内存中,从而提高系统的并发能力。
4. 负载均衡
负载均衡是一种重要的提高系统并发能力的机制,它可以将请求分配到多个服务器上,从而提高系统的并发能力。Spring Boot提供了很多负载均衡的实现,包括:
Ribbon
Eureka
Consul
使用这些负载均衡实现可以将请求分配到多个服务器上,从而提高系统的并发能力。
参考:
https://zhuanlan.zhihu.com/p/394429932
https://zhuanlan.zhihu.com/p/76355753
https://blog.csdn.net/jam_yin/article/details/131392905
相关文章:
Mysql 索引原理和优化方式
一、索引原理 什么是索引 索引是存储引擎用于快速找到记录的一种数据结构。可以联想到字典中的目录。 索引的分类 (1) Hash 索引 Hash 索引是比较常见的一种索引,他的单条记录查询的效率很高,时间复杂度为1。但是,…...

Ubuntu安装VM TOOLS解决虚拟机无法和WINDOWS粘贴复制问题
1:首先使用VMware Workstation安装一个Ubuntu的系统。 2:现在已经不建议安装VM TOOLS。建议安装OPEN-VM-TOOLS。 3:进入系统使用下面的命令安装。 sudo apt install open-vm-tools 4:提示下面错误,Package open-vm…...
【Docker】Docker Swarm介绍与环境搭建
为什么不建议在生产环境中使用Docker Compose 多机器如何管理?如何跨机器做scale横向扩展?容器失败退出时如何新建容器确保服务正常运行?如何确保零宕机时间?如何管理密码,Key等敏感数据? Docker Swarm介…...

国产CAN总线收发芯片DP1042 兼容替换TJA1042
说明 1 简述 DP1042是一款应用于 CAN 协议控制器和物理总线之间的接口芯片,可应用于卡车、公交、小汽车、工业控制等领域,支持 5Mbps CAN FD 灵活数据速率,具有在总线与 CAN 协议控制器之间进行差分信号传输的能力,完全兼容“ISO…...

[架构之路-243]:目标系统 - 纵向分层 - 架构是表面轮廓、内部骨架、未来蓝图,企业组织架构、信息系统架构、软件架构、应用程序就架构
目录 一、什么是架构 1.1 架构是表面轮廓 1.2 架构是内部骨架 1.3 架构是蓝图,是愿景 1.4 架构是数据流、控制流、管理流、同步流 1.5 数据、控制、同步、管理的比较 二、架构的层级 2.1 企业组织架构 2.2 企业系统架构 2.2 信息系统架构 2.3 软件架构 …...

【接口技术】定时计数器习题
1:8253芯片有______个端口地址。 【可选】 2 3 4 6 解答:4 2:8253芯片有______种工作方式。 【可选】 3 4 5 6 解答:6 3: 8253芯片内部有完全独立的______。 【可选】 6个16位计数通道 3个16位计数通道 6个8位计…...

DC电源模块的的散热结构合理布局
BOSHIDA DC电源模块的的散热结构合理布局 DC电源模块在工业控制、通讯、汽车电子等领域广泛应用。然而,随着功率密度不断提高,DC电源模块产生的热量也越来越大,散热问题变得越来越突出。为了保障电路的稳定性和可靠性,必须采取合…...

Fedora Linux 38下安装音频与视频的解码器和播放器
Fedora Linux 38 操作系统安装好后,默认是没有音频与视频的解码器的,音频与视频的播放体验非常差劲。但是第三方的软件源中有解码器和播放器的软件,需要我们自己手动安装。、 连接互联网,打开Shell命令行: 1. sudo d…...

边缘计算:云计算的延伸
云计算已经存在多年,并已被证明对大大小小的企业都有好处;然而,直到最近边缘计算才变得如此重要。它是指发生在网络边缘的一种数据处理,更接近数据的来源地。 这将有助于提高效率并减少延迟以及设备和云之间的数据传输成本。边缘…...
【经验分享】在Kylin桌面版操作系统中配置openGauss的ODBC数据源
引言 openGauss是一款开源的关系型数据库管理系统,它提供了强大的功能和性能,可以满足各种企业级应用的需求。与此同时,ODBC(Open Database Connectivity)是一个标准的数据库访问接口,它允许应用程序通过统…...
WSL——ubuntu中anaconda换源(conda、pip)
1、conda 打开Ubuntu,输入下列命令。 conda config --set show_channel_urls yes 在文件管理器地址栏,输入:\\wsl$。打开Ubuntu根路径,其中显示了.condarc文件。 以文本形式打开,并输入要换的源,保存即可。…...

IP地址在网络安全中的关键作用
IP地址(Internet Protocol Address)是互联网世界中的重要标识符,它在网络安全领域发挥着至关重要的作用。这些地址不仅帮助设备在网络上找到彼此,还在多个方面有助于维护网络的完整性、机密性和可用性。本文将探讨IP地址在网络安全…...

Android.mk 中覆盖应用包名
项目场景: 一般来讲应用包名都是配置在 AndroidManifest.xml 中的,但遇到特殊情况,需要修改源码中应用包名 通常都会先去改 AndroidManifest.xml package 但改为后编译发现一顿错误,原因是 java 类中已经指定了 R 文件包名&…...

如何最有效地使用ChatGPT:提问技巧与策略
前言 在如今信息技术高速发展的时代,像ChatGPT这样的大型自然语言处理模型为我们提供了一个强大的工具,以获取各种信息和答案。然而,要充分利用这一工具,您需要掌握一些提问技巧与策略,以确保获得最准确和有用的回答。…...
【JAVA学习笔记】40 - 抽象类、模版设计模式(抽象类的使用)
项目代码 https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter10/src/com/yinhai/abstract_ 一、抽象类的引入 很多时候在创建类的时候有一个父类,比如animal类,他的子类会有各种方法,为了复用需要进行方法的重写&…...
如何通过在线培训考试系统进行远程教育
随着互联网技术的不断发展,远程教育正在成为一种新型的学习方式,它使学生能够在任何地点、任何时间通过在线培训考试系统接受教育。 利用在线培训考试系统进行远程教育具有很大的灵活性。学生可以根据自己的时间和需求自由选择课程,无需受制…...
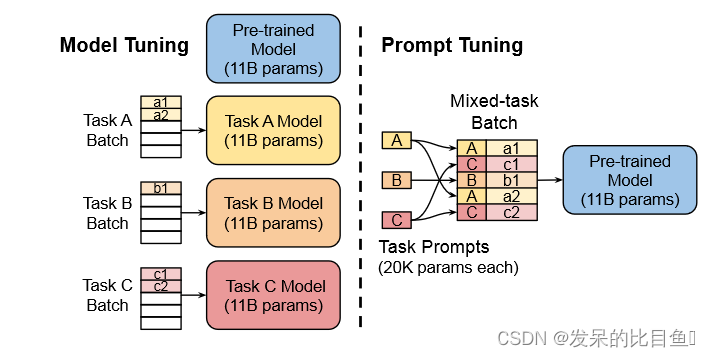
2021-arXiv-The Power of Scale for Parameter-Efficient Prompt Tuning
2021-arXiv-The Power of Scale for Parameter-Efficient Prompt Tuning Paper: https://arxiv.org/abs/2104.08691 Code: https://github.com/google-research/ text-to-text-transfer-transformer/ blob/main/released_checkpoints.md# lm-adapted-t511lm100k 在这项工作中&…...

计算机视觉与深度学习 | 非线性优化理论:图优化、高斯牛顿法和列文伯格-马夸尔特算法
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 计算机视觉与深度学习 | SLAM国内外研究现状 计算机视觉与深度学习 | 视…...

一文说尽零售数据分析指标体系
零售的本质业务模式是通过在各种渠道上吸引客户来购买我们的商品来实现盈利,其实就是客户-渠道-商品,也就是我们常说的“人、场、货”,除此之外还有供应链、财务等起到重要的辅助作用。因此如果要构建起系统化的零售数据分析指标体系…...
)
AT2659一款卫星导航低噪声放大器芯片(LNA)
产品介绍 AT2659 是一款专门针对中国 BDS(北斗卫星导航系统),美国的 GPS,俄罗斯的 GLONASS 和欧盟的 GALILEO 导航系统应用而设计的高增益、低噪声系数射频放大器。 AT2659 具有 23dB 高增益和 0.71dB 的低噪声系数。芯片支持 …...

如何借助内网穿透工具实现WinSCP跨系统远程文件管理的稳定连接
1. 为什么需要内网穿透实现WinSCP远程文件管理 作为开发者或运维人员,我经常需要在Windows和Linux服务器之间传输文件。最初我尝试用U盘或网盘中转,但效率太低;后来改用WinSCP直连局域网,又遇到跨地域办公的难题。直到发现内网穿透…...

解决Qt中使用qmqtt连接ONENet MQTT服务端的版本兼容性问题
1. 问题背景:当qmqtt遇上ONENet 最近在做一个物联网项目,需要用Qt开发一个MQTT客户端连接ONENet平台。按照官方文档,我选择了emqx/qmqtt这个第三方库,结果连接时直接报错。代码明明照着示例写的,参数也都检查过&#x…...

基于国标12190-2021的电磁屏蔽箱多频段测试优化方案
1. 电磁屏蔽箱测试的核心挑战与国标12190-2021的价值 当你第一次接触电磁屏蔽箱测试时,可能会被各种专业术语和复杂的测试流程搞得晕头转向。我刚开始做这行时,最头疼的就是如何确保测试结果既全面又准确——特别是在不同频段下,屏蔽效能差异…...

告别OpenAI依赖:用智谱AI与轻量本地模型构建RAG评估实战
1. 为什么需要替代OpenAI的RAG评估方案 当我们在构建RAG(检索增强生成)系统时,评估环节至关重要。传统的Ragas框架默认使用OpenAI的GPT模型进行评估,但这会带来几个实际问题: 首先是访问稳定性问题。由于网络环境差异…...

Fish Speech 1.5开源大模型落地:为乡村学校定制方言普通话双语教学语音
Fish Speech 1.5开源大模型落地:为乡村学校定制方言普通话双语教学语音 想象一下,在偏远山区的教室里,孩子们正跟着一个亲切的“本地老师”学习普通话。这位老师不仅能说一口标准的普通话,还能用孩子们熟悉的家乡方言进行解释和互…...

TouchGal:一站式Galgame社区解决方案终极指南
TouchGal:一站式Galgame社区解决方案终极指南 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next 还在为寻找Galgame资源而四…...

【Django 实验三】个人主页开发实战
【Django 实验三】个人主页开发实战 作者:刘静怡 | 学号:F23016208 | 完成日期:2026年3月29日 目录 环境准备项目创建数据模型设计视图函数编写模板系统Admin 后台配置页面美化功能完善总结 一、环境准备 1.1 环境要求 Python: 3.10Django…...

AI净界-RMBG-1.4入门指南:理解Alpha通道、PNG透明度与导出规范
AI净界-RMBG-1.4入门指南:理解Alpha通道、PNG透明度与导出规范 你是不是也遇到过这样的烦恼?拍了一张不错的照片,想换个背景发朋友圈,或者做电商需要把商品图抠出来,结果发现边缘抠得跟狗啃的一样,头发丝和…...

告别VirtualBox默认20G!保姆级教程:从创建到动态扩容,打造你的专属开发环境
从零规划VirtualBox磁盘空间:开发环境搭建的黄金法则 刚接触VirtualBox的新手开发者们,是否曾在项目进行到一半时突然发现磁盘空间不足?那种被迫中断工作流程去处理存储问题的体验,足以毁掉一天的开发效率。本文将带你从源头规避这…...

别再傻傻匀速拖滑块了!用Python模拟真人鼠标轨迹,轻松过Geetest验证码
突破验证码防线:Python模拟人类行为轨迹的实战艺术 验证码系统正变得越来越智能,Geetest等平台已经能够通过分析用户行为模式来区分人类和机器。传统的匀速滑块操作在这些系统面前几乎无所遁形。本文将带你深入理解现代验证码系统的工作原理,…...