Hadoop3.0大数据处理学习4(案例:数据清洗、数据指标统计、任务脚本封装、Sqoop导出Mysql)
案例需求分析
直播公司每日都会产生海量的直播数据,为了更好地服务主播与用户,提高直播质量与用户粘性,往往会对大量的数据进行分析与统计,从中挖掘商业价值,我们将通过一个实战案例,来使用Hadoop技术来实现对直播数据的统计与分析。下面是简化的日志文件,详细的我会更新在Gitee hadoop_study/hadoopDemo1 · Huathy/study-all/
{"id":"1580089010000","uid":"12001002543","nickname":"jack2543","gold":561,"watchnumpv":1697,"follower":1509,"gifter":2920,"watchnumuv":5410,"length":3542,"exp":183}
{"id":"1580089010001","uid":"12001001853","nickname":"jack1853","gold":660,"watchnumpv":8160,"follower":1781,"gifter":551,"watchnumuv":4798,"length":189,"exp":89}
{"id":"1580089010002","uid":"12001003786","nickname":"jack3786","gold":14,"watchnumpv":577,"follower":1759,"gifter":2643,"watchnumuv":8910,"length":1203,"exp":54}
原始数据清洗代码
- 清理无效记录:由于原始数据是通过日志方式进行记录的,在使用日志采集工具采集到HDFS后,还需要对数据进行清洗过滤,丢弃缺失字段的数据,针对异常字段值进行标准化处理。
- 清除多余字段:由于计算时不会用到所有的字段。
编码
DataCleanMap
package dataClean;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author Huathy* @date 2023-10-22 22:15* @description 实现自定义map类,在里面实现具体的清洗逻辑*/
public class DataCleanMap extends Mapper<LongWritable, Text, Text, Text> {/*** 1. 从原始数据中过滤出来需要的字段* 2. 针对核心字段进行异常值判断** @param key* @param value* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String valStr = value.toString();// 将json字符串数据转换成对象JSONObject jsonObj = JSON.parseObject(valStr);String uid = jsonObj.getString("uid");// 这里建议使用getIntValue(返回0)而不是getInt(异常)。int gold = jsonObj.getIntValue("gold");int watchnumpv = jsonObj.getIntValue("watchnumpv");int follower = jsonObj.getIntValue("follower");int length = jsonObj.getIntValue("length");// 过滤异常数据if (StringUtils.isNotBlank(valStr) && (gold * watchnumpv * follower * length) >= 0) {// 组装k2,v2Text k2 = new Text();k2.set(uid);Text v2 = new Text();v2.set(gold + "\t" + watchnumpv + "\t" + follower + "\t" + length);context.write(k2, v2);}}
}
DataCleanJob
package dataClean;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** @author Huathy* @date 2023-10-22 22:02* @description 数据清洗作业* 1. 从原始数据中过滤出来需要的字段* uid gold watchnumpv(总观看)、follower(粉丝关注数量)、length(总时长)* 2. 针对以上五个字段进行判断,都不应该丢失或为空,否则任务是异常记录,丢弃。* 若个别字段丢失,则设置为0.* <p>* 分析:* 1. 由于原始数据是json格式,可以使用fastjson对原始数据进行解析,获取指定字段的内容* 2. 然后对获取到的数据进行判断,只保留满足条件的数据* 3. 由于不需要聚合过程,只是一个简单的过滤操作,所以只需要map阶段即可,不需要reduce阶段* 4. 其中map阶段的k1,v1的数据类型是固定的<LongWritable,Text>,k2,v2的数据类型是<Text,Text>k2存储主播ID,v2存储核心字段* 中间用\t制表符分隔即可*/
public class DataCleanJob {public static void main(String[] args) throws Exception {System.out.println("inputPath => " + args[0]);System.out.println("outputPath => " + args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration = new Configuration();// 创建jobJob job = Job.getInstance(configuration, "wordCountJob");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类job.setJarByClass(DataCleanJob.class);// 指定输入文件FileInputFormat.setInputPaths(job, new Path(path));FileOutputFormat.setOutputPath(job, new Path(path2));// 指定map相关配置job.setMapperClass(DataCleanMap.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);// 指定reduce 数量0,表示禁用reducejob.setNumReduceTasks(0);// 提交任务job.waitForCompletion(true);}
}
运行
## 运行命令
[root@cent7-1 hadoop-3.2.4]# hadoop jar hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar dataClean.DataCleanJob hdfs://cent7-1:9000/data/videoinfo/231022 hdfs://cent7-1:9000/data/res231022
inputPath => hdfs://cent7-1:9000/data/videoinfo/231022
outputPath => hdfs://cent7-1:9000/data/res231022
2023-10-22 23:16:15,845 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2023-10-22 23:16:16,856 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2023-10-22 23:16:17,041 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1697985525421_0002
2023-10-22 23:16:17,967 INFO input.FileInputFormat: Total input files to process : 1
2023-10-22 23:16:18,167 INFO mapreduce.JobSubmitter: number of splits:1
2023-10-22 23:16:18,873 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1697985525421_0002
2023-10-22 23:16:18,874 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-10-22 23:16:19,157 INFO conf.Configuration: resource-types.xml not found
2023-10-22 23:16:19,158 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-10-22 23:16:19,285 INFO impl.YarnClientImpl: Submitted application application_1697985525421_0002
2023-10-22 23:16:19,345 INFO mapreduce.Job: The url to track the job: http://cent7-1:8088/proxy/application_1697985525421_0002/
2023-10-22 23:16:19,346 INFO mapreduce.Job: Running job: job_1697985525421_0002
2023-10-22 23:16:31,683 INFO mapreduce.Job: Job job_1697985525421_0002 running in uber mode : false
2023-10-22 23:16:31,689 INFO mapreduce.Job: map 0% reduce 0%
2023-10-22 23:16:40,955 INFO mapreduce.Job: map 100% reduce 0%
2023-10-22 23:16:43,012 INFO mapreduce.Job: Job job_1697985525421_0002 completed successfully
2023-10-22 23:16:43,153 INFO mapreduce.Job: Counters: 33File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=238970FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=24410767HDFS: Number of bytes written=1455064HDFS: Number of read operations=7HDFS: Number of large read operations=0HDFS: Number of write operations=2HDFS: Number of bytes read erasure-coded=0Job Counters Launched map tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=7678Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=7678Total vcore-milliseconds taken by all map tasks=7678Total megabyte-milliseconds taken by all map tasks=7862272Map-Reduce FrameworkMap input records=90000Map output records=46990Input split bytes=123Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=195CPU time spent (ms)=5360Physical memory (bytes) snapshot=302153728Virtual memory (bytes) snapshot=2588925952Total committed heap usage (bytes)=214958080Peak Map Physical memory (bytes)=302153728Peak Map Virtual memory (bytes)=2588925952File Input Format Counters Bytes Read=24410644File Output Format Counters Bytes Written=1455064
[root@cent7-1 hadoop-3.2.4]# ## 统计输出文件行数
[root@cent7-1 hadoop-3.2.4]# hdfs dfs -cat hdfs://cent7-1:9000/data/res231022/* | wc -l
46990
## 查看原始数据记录数
[root@cent7-1 hadoop-3.2.4]# hdfs dfs -cat hdfs://cent7-1:9000/data/videoinfo/231022/* | wc -l
90000
数据指标统计
- 对数据中的金币数量,总观看PV,粉丝关注数量,视频总时长等指标进行统计(涉及四个字段为了后续方便,可以自定义Writable)
- 统计每天开播时长最长的前10名主播以及对应的开播时长
自定义Writeable代码实现
由于原始数据涉及多个需要统计的字段,可以将这些字段统一的记录在一个自定义的数据类型中,方便使用
package videoinfo;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;/*** @author Huathy* @date 2023-10-22 23:32* @description 自定义数据类型,为了保存主播相关核心字段,方便后期维护*/
public class VideoInfoWriteable implements Writable {private long gold;private long watchnumpv;private long follower;private long length;public void set(long gold, long watchnumpv, long follower, long length) {this.gold = gold;this.watchnumpv = watchnumpv;this.follower = follower;this.length = length;}public long getGold() {return gold;}public long getWatchnumpv() {return watchnumpv;}public long getFollower() {return follower;}public long getLength() {return length;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(gold);dataOutput.writeLong(watchnumpv);dataOutput.writeLong(follower);dataOutput.writeLong(length);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.gold = dataInput.readLong();this.watchnumpv = dataInput.readLong();this.follower = dataInput.readLong();this.length = dataInput.readLong();}@Overridepublic String toString() {return gold + "\t" + watchnumpv + "\t" + follower + "\t" + length;}
}
基于主播维度 videoinfo
VideoInfoJob
package videoinfo;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** @author Huathy* @date 2023-10-22 23:27* @description 数据指标统计作业* 1. 基于主播进行统计,统计每个主播在当天收到的总金币数量,总观看PV,总粉丝关注量,总视频开播市场* 分析* 1. 为了方便统计主播的指标数据吗,最好是把这些字段整合到一个对象中,这样维护方便* 这样就需要自定义Writeable* 2. 由于在这里需要以主播维度进行数据的聚合,所以需要以主播ID作为KEY,进行聚合统计* 3. 所以Map节点的<k2,v2>是<Text,自定义Writeable>* 4. 由于需要聚合,所以Reduce阶段也需要*/
public class VideoInfoJob {public static void main(String[] args) throws Exception {System.out.println("inputPath => " + args[0]);System.out.println("outputPath => " + args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration = new Configuration();// 创建jobJob job = Job.getInstance(configuration, "VideoInfoJob");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类job.setJarByClass(VideoInfoJob.class);// 指定输入文件FileInputFormat.setInputPaths(job, new Path(path));FileOutputFormat.setOutputPath(job, new Path(path2));// 指定map相关配置job.setMapperClass(VideoInfoMap.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 指定reducejob.setReducerClass(VideoInfoReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 提交任务job.waitForCompletion(true);}
}
VideoInfoMap
package videoinfo;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author Huathy* @date 2023-10-22 23:31* @description 实现自定义Map类,在这里实现核心字段的拼接*/
public class VideoInfoMap extends Mapper<LongWritable, Text, Text, VideoInfoWriteable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 读取清洗后的每一行数据String line = value.toString();String[] fields = line.split("\t");String uid = fields[0];long gold = Long.parseLong(fields[1]);long watchnumpv = Long.parseLong(fields[1]);long follower = Long.parseLong(fields[1]);long length = Long.parseLong(fields[1]);// 组装K2 V2Text k2 = new Text();k2.set(uid);VideoInfoWriteable v2 = new VideoInfoWriteable();v2.set(gold, watchnumpv, follower, length);context.write(k2, v2);}
}
VideoInfoReduce
package videoinfo;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author Huathy* @date 2023-10-22 23:31* @description 实现自定义Map类,在这里实现核心字段的拼接*/
public class VideoInfoReduce extends Reducer<Text, VideoInfoWriteable, Text, VideoInfoWriteable> {@Overrideprotected void reduce(Text key, Iterable<VideoInfoWriteable> values, Context context) throws IOException, InterruptedException {// 从v2s中把相同key的value取出来,进行累加求和long goldSum = 0;long watchNumPvSum = 0;long followerSum = 0;long lengthSum = 0;for (VideoInfoWriteable v2 : values) {goldSum += v2.getGold();watchNumPvSum += v2.getWatchnumpv();followerSum += v2.getFollower();lengthSum += v2.getLength();}// 组装k3 v3VideoInfoWriteable videoInfoWriteable = new VideoInfoWriteable();videoInfoWriteable.set(goldSum, watchNumPvSum, followerSum, lengthSum);context.write(key, videoInfoWriteable);}
}
基于主播的TOPN计算
VideoInfoTop10Job
package top10;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** @author Huathy* @date 2023-10-23 21:27* @description 数据指标统计作业* 需求:统计每天开播时长最长的前10名主播以及时长信息* 分析:* 1. 为了统计每天开播时长最长的前10名主播信息,需要在map阶段获取数据中每个主播的ID和直播时长* 2. 所以map阶段的k2 v2 为Text LongWriteable* 3. 在reduce阶段对相同主播的时长进行累加求和,将这些数据存储到一个临时的map中* 4. 在reduce阶段的cleanup函数(最后执行)中,对map集合的数据进行排序处理* 5. 在cleanup函数中把直播时长最长的前10名主播信息写出到文件中* setup函数在reduce函数开始执行一次,而cleanup在结束时执行一次*/
public class VideoInfoTop10Job {public static void main(String[] args) throws Exception {System.out.println("inputPath => " + args[0]);System.out.println("outputPath => " + args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration = new Configuration();// 从输入路径来获取日期String[] fields = path.split("/");String tmpdt = fields[fields.length - 1];System.out.println("日期:" + tmpdt);// 生命周期的配置configuration.set("dt", tmpdt);// 创建jobJob job = Job.getInstance(configuration, "VideoInfoTop10Job");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类job.setJarByClass(VideoInfoTop10Job.class);// 指定输入文件FileInputFormat.setInputPaths(job, new Path(path));FileOutputFormat.setOutputPath(job, new Path(path2));job.setMapperClass(VideoInfoTop10Map.class);job.setReducerClass(VideoInfoTop10Reduce.class);// 指定map相关配置job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 指定reducejob.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 提交任务job.waitForCompletion(true);}
}
VideoInfoTop10Map
package top10;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author Huathy* @date 2023-10-23 21:32* @description 自定义map类,在这里实现核心字段的拼接*/
public class VideoInfoTop10Map extends Mapper<LongWritable, Text, Text, LongWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 读取清洗之后的每一行数据String line = key.toString();String[] fields = line.split("\t");String uid = fields[0];long length = Long.parseLong(fields[4]);Text k2 = new Text();k2.set(uid);LongWritable v2 = new LongWritable();v2.set(length);context.write(k2, v2);}
}
VideoInfoTop10Reduce
package top10;import cn.hutool.core.collection.CollUtil;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.collections.MapUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.*;/*** @author Huathy* @date 2023-10-23 21:37* @description*/
public class VideoInfoTop10Reduce extends Reducer<Text, LongWritable, Text, LongWritable> {// 保存主播ID和开播时长Map<String, Long> map = new HashMap<>();@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {String k2 = key.toString();long lengthSum = 0;for (LongWritable v2 : values) {lengthSum += v2.get();}map.put(k2, lengthSum);}/*** 任务初始化的时候执行一次,一般在里面做一些初始化资源连接的操作。(mysql、redis连接操作)** @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void setup(Context context) throws IOException, InterruptedException {System.out.println("setup method running...");System.out.println("context: " + context);super.setup(context);}/*** 任务结束的时候执行一次,做关闭资源连接操作** @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void cleanup(Context context) throws IOException, InterruptedException {// 获取日期Configuration configuration = context.getConfiguration();String date = configuration.get("dt");// 排序LinkedHashMap<String, Long> sortMap = CollUtil.sortByEntry(map, new Comparator<Map.Entry<String, Long>>() {@Overridepublic int compare(Map.Entry<String, Long> o1, Map.Entry<String, Long> o2) {return -o1.getValue().compareTo(o2.getValue());}});Set<Map.Entry<String, Long>> entries = sortMap.entrySet();Iterator<Map.Entry<String, Long>> iterator = entries.iterator();// 输出int count = 1;while (count <= 10 && iterator.hasNext()) {Map.Entry<String, Long> entry = iterator.next();String key = entry.getKey();Long value = entry.getValue();// 封装K3 V3Text k3 = new Text(date + "\t" + key);LongWritable v3 = new LongWritable(value);// 统计的时候还应该传入日期来用来输出统计的时间,而不是获取当前时间(可能是统计历史)!context.write(k3, v3);count++;}}
}
任务定时脚本封装
任务依赖关系:数据指标统计(top10统计以及播放数据统计)依赖数据清洗作业
将任务提交命令进行封装,方便调用,便于定时任务调度
编写任务脚本,并以debug模式执行:sh -x data_clean.sh
任务执行结果监控
针对任务执行的结果进行检测,如果执行失败,则重试任务,同时发送告警信息。
#!/bin/bash
# 建议使用bin/bash形式
# 判读用户是否输入日期,如果没有则默认获取昨天日期。(需要隔几天重跑,灵活的指定日期)
if [ "x$1" = "x" ]; thenyes_time=$(date +%y%m%d --date="1 days ago")
elseyes_time=$1
fijobs_home=/home/jobs
cleanjob_input=hdfs://cent7-1:9000/data/videoinfo/${yes_time}
cleanjob_output=hdfs://cent7-1:9000/data/videoinfo_clean/${yes_time}
videoinfojob_input=${cleanjob_output}
videoinfojob_output=hdfs://cent7-1:9000/res/videoinfoJob/${yes_time}
top10job_input=${cleanjob_output}
top10job_output=hdfs://cent7-1:9000/res/top10/${yes_time}# 删除输出目录,为了兼容脚本重跑
hdfs dfs -rm -r ${cleanjob_output}
# 执行数据清洗任务
hadoop jar ${jobs_home}/hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar \dataClean.DataCleanJob \${cleanjob_input} ${cleanjob_output}# 判断数据清洗任务是否成功
hdfs dfs -ls ${cleanjob_output}/_SUCCESS
# echo $? 可以获取上一个命令的执行结果0成功,否则失败
if [ "$?" = "0" ]; thenecho "clean job execute success ...."# 删除输出目录,为了兼容脚本重跑hdfs dfs -rm -r ${videoinfojob_output}hdfs dfs -rm -r ${top10job_output}# 执行指标统计任务1echo " execute VideoInfoJob ...."hadoop jar ${jobs_home}/hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar \videoinfo.VideoInfoJob \${videoinfojob_input} ${videoinfojob_output}hdfs dfs -ls ${videoinfojob_output}/_SUCCESSif [ "$?" != "0" ]thenecho " VideoInfoJob execute failed .... "fi# 指定指标统计任务2echo " execute VideoInfoTop10Job ...."hadoop jar ${jobs_home}/hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar \top10.VideoInfoTop10Job \${top10job_input} ${top10job_output}hdfs dfs -ls ${top10job_output}/_SUCCESSif [ "$?" != "0" ]thenecho " VideoInfoJob execute failed .... "fi
elseecho "clean job execute failed ... date time is ${yes_time}"# 给管理员发送短信、邮件# 可以在while进行重试
fi
使用Sqoop将计算结果导出到MySQL
Sqoop可以快速的实现hdfs-mysql的导入导出
快速安装Sqoop工具
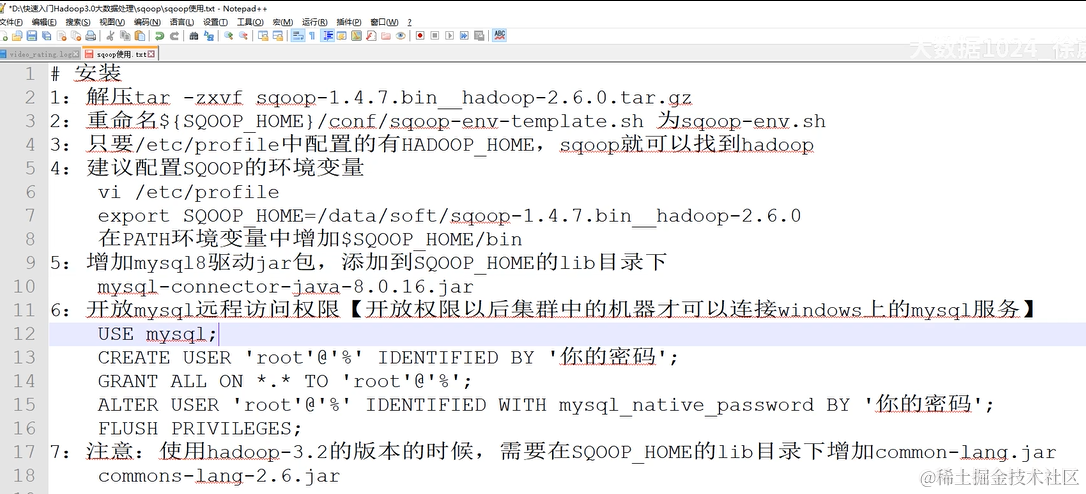
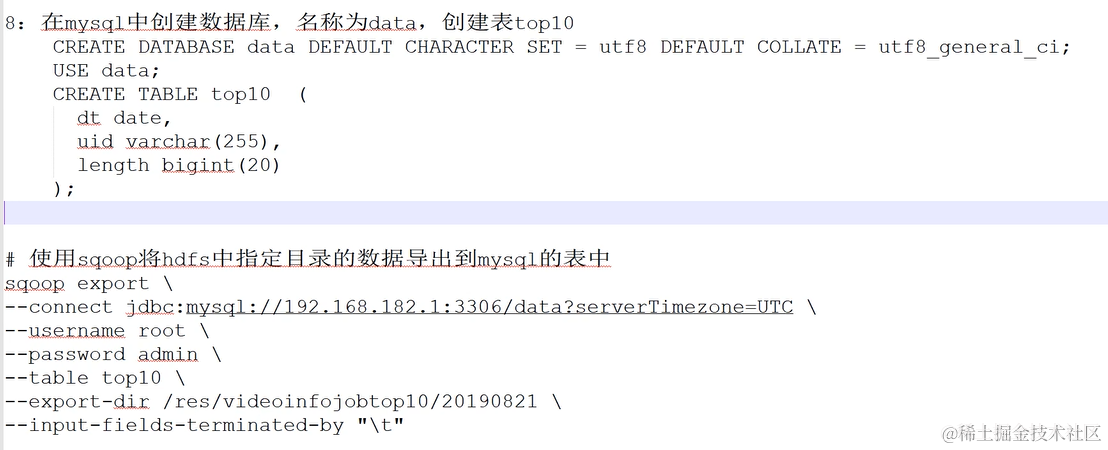
数据导出功能开发,使用Sqoop将MapReduce计算的结果导出到Mysql中
- 导出命令
sqoop export \
--connect 'jdbc:mysql://192.168.56.101:3306/data?serverTimezone=UTC&useSSL=false' \
--username 'hdp' \
--password 'admin' \
--table 'top10' \
--export-dir '/res/top10/231022' \
--input-fields-terminated-by "\t"
- 导出日志
[root@cent7-1 sqoop-1.4.7.bin_hadoop-2.6.0]# sqoop export \
> --connect 'jdbc:mysql://192.168.56.101:3306/data?serverTimezone=UTC&useSSL=false' \
> --username 'hdp' \
> --password 'admin' \
> --table 'top10' \
> --export-dir '/res/top10/231022' \
> --input-fields-terminated-by "\t"
Warning: /home/sqoop-1.4.7.bin_hadoop-2.6.0//../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/sqoop-1.4.7.bin_hadoop-2.6.0//../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2023-10-24 23:42:09,452 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2023-10-24 23:42:09,684 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2023-10-24 23:42:09,997 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
2023-10-24 23:42:10,022 INFO tool.CodeGenTool: Beginning code generation
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
2023-10-24 23:42:10,921 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `top10` AS t LIMIT 1
2023-10-24 23:42:11,061 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `top10` AS t LIMIT 1
2023-10-24 23:42:11,084 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop-3.2.4
注: /tmp/sqoop-root/compile/6d507cd9a1a751990abfd7eef20a60c2/top10.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2023-10-24 23:42:23,932 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/6d507cd9a1a751990abfd7eef20a60c2/top10.jar
2023-10-24 23:42:23,972 INFO mapreduce.ExportJobBase: Beginning export of top10
2023-10-24 23:42:23,972 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2023-10-24 23:42:24,237 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2023-10-24 23:42:27,318 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
2023-10-24 23:42:27,325 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-10-24 23:42:27,326 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2023-10-24 23:42:27,641 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2023-10-24 23:42:29,161 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1698153196891_0015
2023-10-24 23:42:39,216 INFO input.FileInputFormat: Total input files to process : 1
2023-10-24 23:42:39,231 INFO input.FileInputFormat: Total input files to process : 1
2023-10-24 23:42:39,387 INFO mapreduce.JobSubmitter: number of splits:4
2023-10-24 23:42:39,475 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-10-24 23:42:40,171 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1698153196891_0015
2023-10-24 23:42:40,173 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-10-24 23:42:40,660 INFO conf.Configuration: resource-types.xml not found
2023-10-24 23:42:40,660 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-10-24 23:42:41,073 INFO impl.YarnClientImpl: Submitted application application_1698153196891_0015
2023-10-24 23:42:41,163 INFO mapreduce.Job: The url to track the job: http://cent7-1:8088/proxy/application_1698153196891_0015/
2023-10-24 23:42:41,164 INFO mapreduce.Job: Running job: job_1698153196891_0015
2023-10-24 23:43:02,755 INFO mapreduce.Job: Job job_1698153196891_0015 running in uber mode : false
2023-10-24 23:43:02,760 INFO mapreduce.Job: map 0% reduce 0%
2023-10-24 23:43:23,821 INFO mapreduce.Job: map 25% reduce 0%
2023-10-24 23:43:25,047 INFO mapreduce.Job: map 50% reduce 0%
2023-10-24 23:43:26,069 INFO mapreduce.Job: map 75% reduce 0%
2023-10-24 23:43:27,088 INFO mapreduce.Job: map 100% reduce 0%
2023-10-24 23:43:28,112 INFO mapreduce.Job: Job job_1698153196891_0015 completed successfully
2023-10-24 23:43:28,266 INFO mapreduce.Job: Counters: 33File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=993808FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=1297HDFS: Number of bytes written=0HDFS: Number of read operations=19HDFS: Number of large read operations=0HDFS: Number of write operations=0HDFS: Number of bytes read erasure-coded=0Job Counters Launched map tasks=4Data-local map tasks=4Total time spent by all maps in occupied slots (ms)=79661Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=79661Total vcore-milliseconds taken by all map tasks=79661Total megabyte-milliseconds taken by all map tasks=81572864Map-Reduce FrameworkMap input records=10Map output records=10Input split bytes=586Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=3053CPU time spent (ms)=11530Physical memory (bytes) snapshot=911597568Virtual memory (bytes) snapshot=10326462464Total committed heap usage (bytes)=584056832Peak Map Physical memory (bytes)=238632960Peak Map Virtual memory (bytes)=2584969216File Input Format Counters Bytes Read=0File Output Format Counters Bytes Written=0
2023-10-24 23:43:28,282 INFO mapreduce.ExportJobBase: Transferred 1.2666 KB in 60.9011 seconds (21.2968 bytes/sec)
2023-10-24 23:43:28,291 INFO mapreduce.ExportJobBase: Exported 10 records.
相关文章:
Hadoop3.0大数据处理学习4(案例:数据清洗、数据指标统计、任务脚本封装、Sqoop导出Mysql)
案例需求分析 直播公司每日都会产生海量的直播数据,为了更好地服务主播与用户,提高直播质量与用户粘性,往往会对大量的数据进行分析与统计,从中挖掘商业价值,我们将通过一个实战案例,来使用Hadoop技术来实…...

华为机试题:HJ3 明明的随机数
目录 第一章、算法题1.1)题目描述1.2)解题思路与答案1.3)牛客链接 友情提醒: 先看文章目录,大致了解文章知识点结构,点击文章目录可直接跳转到文章指定位置。 第一章、算法题 1.1)题目描述 题目描述&…...

Python OpenCV将n×n的小图拼接成m×m的大图
Python OpenCV将nn的小图拼接成mm的大图 前言前提条件相关介绍实验环境n \times n的小图拼接成m \times m的大图代码实现 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多精彩内容,可点击进入Python日常小操作专栏、OpenCV-Python小…...
wkhtmltoimage/wkhtmltopdf 使用实践
1. 介绍 wkhtmltopdf/wkhtmltoimage 用于将简单的html页面转换为pdf或图片; 2.安装 downloads 2.1. mac os 下载64-bit 版本然后按照指示安装, 遇到 untrust developers 时,需要在 Settings -> Privacy 处信任下该安装包。 2.2. debian # 可用…...
Rclone连接Onedrive
一、Rclone介绍 Rclone是一款的命令行工具,支持在不同对象存储、网盘间同步、上传、下载数据。 我们这里连接的onedrive,其他网盘请查看官方文档。 注意: 需要先在Windows下配置好了,然后再将rclone配置文件复制到Linux的rclone配…...
RK356X/RK3588构建Ubuntu20.04根文件系统
文章目录 前言一、官网下载ubuntu-base二、挂载并构建文件系统2.1、配置构建文件系统环境2.2、编写挂载脚本mount.sh并安装相关工具2.3、轻量级的桌面环境 lubuntu-desktop2.4、卸载一些不必要的软件2.5、添加用户2.6 、允许root用户登录桌面2.7、串口自动登录2.8、添加分区释放…...

本地新建项目如何推到码云上去
1.先在码云上建立一个空仓库,正常步骤就行。建立完成有readme.md. 2.然后本地建立项目文件,正常脚手架搭建VUE\REACT等。记得要项目git init一下。 3.本地改好的内容commit 一下。 4.本地文件与远端仓库建立连接。git remote add origin https://gite…...
加密解密)
RSAUtil 前端 JavaScript JSEncrypt 实现 RSA (长文本)加密解密
文章归档:https://www.yuque.com/u27599042/coding_star/cl4dl599pdmtllw1 依赖 import JSEncrypt from ‘jsencrypt’ pnpm i jsencryptimport {stringIsNull} from “/utils/string_utils.js”:https://www.yuque.com/u27599042/coding_star/slncupw…...
uniapp map polygons 区域填充色(fillColor)在ios显示正常,但在安卓手机显示是黑色的,怎么解决?
uniapp map polygons 区域填充色(fillColor)在ios显示正常,但在安卓手机显示是黑色的,怎么解决? <MapPage :longitude"item.centerCoord[0]" :latitude"item.centerCoord[1]":polygons"[{ points: it…...

OSCAR数据库上锁问题如何排查
关键字 oscar lock 问题描述 oscar 数据库上锁问题如何排查 解决问题思路 准备数据 create table lock_test(name varchar(10),age varchar(10));insert into lock_test values(ff,10); insert into lock_test values(yy,20); insert into lock_test values(ll,30);sessio…...

FPGA与人工智能泛谈-01
文章目录 前言一、FPGA(Field Programmable Gate Array)是什么?二、与GPU的对比1.GPU特点2. FPGA的优势三、人工智能实现的基础架构总结前言 人工智能技术的快速发展正从各个方面改变人类的生活、工作及教育等各个方面,其中人工智能算法的演进又是其中的关键一步,其中会涉及…...
【VASP】POTCAR文件
【VASP】POTCAR文件 POTCAR 文件的介绍qvasp 生成POTCARvaspkit 生成POTCAR再来认识一下各种赝势如何区分US、PAW、LDA、GGA、PW91 前言 一、4个常用的输入文件INCAR、POSCAR、POTCAR、KPOINTS INCAR: 计算任务类型是什么?怎么计算? KPOINTS: 包含了倒易…...

棒球俱乐部青少年成长体系·棒球1号位
棒球俱乐部青少年成长体系介绍 1. 培养理念 简要介绍棒球俱乐部的宗旨和培养青少年的目标 棒球俱乐部是一个致力于培养青少年棒球运动员的体育组织,其宗旨是通过提供专业的棒球训练和比赛机会,帮助青少年提高身体素质、培养团队合作精神和塑造积极向上…...
折叠式菜单怎么做编程,初学编程系统化教程初级1上线
中文编程系统化教程,不需英语基础,学习链接——入门篇课程 https://edu.csdn.net/course/detail/39036中文编程系统化教程,不需英语基础,学习链接—— 初级1课程 https://edu.csdn.net/course/detail/39061 ——————————…...

与AI对话,如何写好prompt?
玩转AIGC,优质的Prompt提示词实在是太重要了!同样的问题,换一个问法,就会得到差别迥异的答案。你是怎样和AI进行对话交流的呢?我来分享几个: 请告诉我…我想知道…对于…你有什么看法?帮我解决…...
基于YOLOv8模型和UA-DETRAC数据集的车辆目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOv8模型和UA-DETRAC数据集的车辆目标检测系统可用于日常生活中检测与定位汽车(car)、公共汽车(bus)、面包车(vans)等目标,利用深度学习算法可实现图片、视频、摄像头等方…...
)
0037【Edabit ★☆☆☆☆☆】【修改Bug 2】Buggy Code (Part 2)
0037【Edabit ★☆☆☆☆☆】【修改Bug 2】Buggy Code (Part 2) bugs language_fundamentals Instructions Fix the code in the code tab to pass this challenge (only syntax errors). Look at the examples below to get an idea of what the function should do. Exampl…...

【算法中的Java】— 判断语句
📒博客首页:Sonesang的博客 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 ❤️ :热爱Java与算法学习,期待一起交流! 🙏作者水平很有限,如果发现错误…...

【单例模式】饿汉式,懒汉式?JAVA如何实现单例?线程安全吗?
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 单例设计模式 Java单例设计模式 Java单例设计模…...
Spark_SQL-DataFrame数据写出以及读写数据库(以MySQl为例)
一、数据写出 (1)SparkSQL统一API写出DataFrame数据 二、写出MySQL数据库 一、数据写出 (1)SparkSQL统一API写出DataFrame数据 统一API写法: 常见源写出: # cording:utf8from pyspark.sql import SparkSes…...

【权威认证|Pydantic v2+Starlette v1.12+FastAPI 2.0深度兼容报告】:为什么你的async generator在/ai/chat接口里静默失败?
第一章:FastAPI 2.0 异步 AI 流式响应 避坑指南FastAPI 2.0 对异步流式响应(StreamingResponse)的底层行为进行了关键调整,尤其在事件循环绑定、响应体缓冲策略及客户端断连检测方面与 1.x 版本存在显著差异。若沿用旧版流式生成器…...
)
滴滴盖亚计划ETA数据集实战:如何用Python处理智能交通数据(附完整代码)
滴滴盖亚ETA数据集实战:Python智能交通数据处理全流程解析 引言:智能交通时代的ETA技术价值 在早高峰的深圳深南大道上,网约车司机王师傅刚接单就面临抉择:系统推荐的三条路线中,哪一条能最快到达乘客上车点…...

AI辅助开发实战:如何高效对接智能客服系统并优化对话流程
最近在项目中对接智能客服系统,发现这事儿比想象中要复杂不少。接口文档动辄几十页,对话状态管理起来像一团乱麻,更别提还要优化对话流程提升用户体验了。好在现在有AI辅助开发工具,能帮我们省不少力气。今天就来分享一下…...

手把手教你用XTTS v2克隆自己的声音:从录音到生成的完整避坑指南
零基础玩转XTTS v2语音克隆:从录音到生成的保姆级实战手册 1. 语音克隆技术的前世今生 语音合成技术(TTS)的发展已经走过了数十年的历程。从早期的机械式发音到如今的神经网络语音合成,技术的进步让语音克隆变得越来越自然。XTTS …...

Python调用SM9遭遇“Unknown curve”?紧急修复手册:从OpenSSL 3.0.7到国密SM9曲线OID映射全对照
第一章:Python调用SM9遭遇“Unknown curve”问题的根源定位当使用 Python(如通过 cryptography 或 gmssl 库)实现国密 SM9 算法时,常见报错 ValueError: Unknown curve 并非源于椭圆曲线参数缺失,而是因底层密码学库未…...

MediaPipe Pose镜像测评:高精度姿态估计,舞蹈健身场景实测
MediaPipe Pose镜像测评:高精度姿态估计,舞蹈健身场景实测 1. 引言:为什么选择MediaPipe Pose进行姿态估计 在计算机视觉领域,人体姿态估计技术正变得越来越重要。从健身指导到舞蹈教学,从虚拟试衣到安防监控&#x…...

OpenClaw配置文件详解:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF性能调优全参数解析
OpenClaw配置文件详解:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF性能调优全参数解析 1. 为什么需要手动调优OpenClaw配置 第一次看到OpenClaw的配置文件时,我和大多数开发者一样,直接选择了默认的QuickStart模式。直到某个深夜…...

母版设置、讲义母版、模板设置
母版设置、讲义母版、模板设置一. 母版设置1.1 插入母版及版式1.2 重命名母版及版式1.3 版式设置1.4 例题二. 讲义母版2.1 讲义母版设置三. 模板设置3.1 导入模板3.2 例题一. 母版设置 1.1 插入母版及版式 插入母版 插入版式,先点击一下母版 1.2 重命名母版及版…...

BEV感知算法实战:从Mono3D到PointPillars的自动驾驶3D目标检测全解析
BEV感知算法实战:从Mono3D到PointPillars的自动驾驶3D目标检测全解析 自动驾驶技术的核心挑战之一是如何让车辆准确理解周围环境。在众多感知方案中,鸟瞰图(BEV)感知因其独特的空间表示优势,正在成为行业主流技术路线。…...

OpenClaw团队协作版:ollama-QwQ-32B支持多用户任务隔离实践
OpenClaw团队协作版:ollama-QwQ-32B支持多用户任务隔离实践 1. 为什么我们需要团队协作版的OpenClaw 去年我带领一个5人内容团队时,遇到了一个典型问题:每个人都想用AI自动化处理日常工作,但共享同一套系统会导致文件混乱、任务…...