mindspore的MLP模型(多层感知机)
导入模块
import hashlib
import os
import tarfile
import zipfile
import requests
import numpy as np
import pandas as pd
import mindspore
import mindspore.dataset as ds
from mindspore import nn
import mindspore.ops as ops
import mindspore.numpy as mnp
from mindspore import Tensor
from IPython import display
from matplotlib import pyplot as plt
数据预处理
数据下载:https://www.kaggle.com/datasets/ahsan81/hotel-reservations-classification-dataset
train_data = pd.read_csv("Hotel Reservations_train.csv")
test_data = pd.read_csv("Hotel Reservations_test.csv")print(train_data.shape)
print(test_data.shape)
(30000, 20)
(6275, 20)
# 可去掉第0列与第1列的信息
print(train_data.iloc[0:4, [0, 1, 2, -3, -2, -1]])
Unnamed: 0 Booking_ID no_of_adults avg_price_per_room \
0 0 INN00001 2 65.00
1 1 INN00002 2 106.68
2 2 INN00003 1 60.00
3 3 INN00004 2 100.00 no_of_special_requests booking_status
0 0 Not_Canceled
1 1 Not_Canceled
2 0 Canceled
3 0 Canceled
# 将train_data和test_data合并,后面做数据预处理方便
all_features = pd.concat((train_data.iloc[:, 2:-1], test_data.iloc[:, 2:-1]))all_features
| no_of_adults | no_of_children | no_of_weekend_nights | no_of_week_nights | type_of_meal_plan | required_car_parking_space | room_type_reserved | lead_time | arrival_year | arrival_month | arrival_date | market_segment_type | repeated_guest | no_of_previous_cancellations | no_of_previous_bookings_not_canceled | avg_price_per_room | no_of_special_requests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 0 | 1 | 2 | Meal Plan 1 | 0 | Room_Type 1 | 224 | 2017 | 10 | 2 | Offline | 0 | 0 | 0 | 65.00 | 0 |
| 1 | 2 | 0 | 2 | 3 | Not Selected | 0 | Room_Type 1 | 5 | 2018 | 11 | 6 | Online | 0 | 0 | 0 | 106.68 | 1 |
| 2 | 1 | 0 | 2 | 1 | Meal Plan 1 | 0 | Room_Type 1 | 1 | 2018 | 2 | 28 | Online | 0 | 0 | 0 | 60.00 | 0 |
| 3 | 2 | 0 | 0 | 2 | Meal Plan 1 | 0 | Room_Type 1 | 211 | 2018 | 5 | 20 | Online | 0 | 0 | 0 | 100.00 | 0 |
| 4 | 2 | 0 | 1 | 1 | Not Selected | 0 | Room_Type 1 | 48 | 2018 | 4 | 11 | Online | 0 | 0 | 0 | 94.50 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6270 | 3 | 0 | 2 | 6 | Meal Plan 1 | 0 | Room_Type 4 | 85 | 2018 | 8 | 3 | Online | 0 | 0 | 0 | 167.80 | 1 |
| 6271 | 2 | 0 | 1 | 3 | Meal Plan 1 | 0 | Room_Type 1 | 228 | 2018 | 10 | 17 | Online | 0 | 0 | 0 | 90.95 | 2 |
| 6272 | 2 | 0 | 2 | 6 | Meal Plan 1 | 0 | Room_Type 1 | 148 | 2018 | 7 | 1 | Online | 0 | 0 | 0 | 98.39 | 2 |
| 6273 | 2 | 0 | 0 | 3 | Not Selected | 0 | Room_Type 1 | 63 | 2018 | 4 | 21 | Online | 0 | 0 | 0 | 94.50 | 0 |
| 6274 | 2 | 0 | 1 | 2 | Meal Plan 1 | 0 | Room_Type 1 | 207 | 2018 | 12 | 30 | Offline | 0 | 0 | 0 | 161.67 | 0 |
36275 rows × 17 columns
# 将所有缺失的值替换为相应特征的平均值。 通过将特征重新缩放到零均值和单位方差来标准化数据# 先将为数字类型的列取出来,dtypes[all_features.dtypes != 'object'].index 返回类型是数字的列的索引
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
# 之后对其应用apply方法 apply中对每列进行了标准化(Z-score标准化方法)
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# 处理离散值。我们用独热编码替换它们
# 独热编码:例如,“MSZoning”包含值“RL”和“Rm”。 我们将创建两个新的指示器特征“MSZoning_RL”和“MSZoning_RM”,其值为0或1。print(all_features.shape)# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)print(all_features.shape)
(36275, 17)
(36275, 33)
all_labels = pd.concat((train_data.iloc[:,-1], test_data.iloc[:, -1]))change = {'Not_Canceled':1,'Canceled':0}
all_labels = all_labels.map(change)
all_labels
0 1
1 1
2 0
3 0
4 0..
6270 1
6271 0
6272 1
6273 0
6274 1
Name: booking_status, Length: 36275, dtype: int64
n_train = train_data.shape[0] # 提取训练样本数
train_features = all_features[:n_train].values.astype(np.float32) # 注意要统一数据的类型:np.float32
test_features = all_features[n_train:].values.astype(np.float32)
train_labels = all_labels.iloc[:n_train].values.astype(np.int64)
test_labels = all_labels.iloc[n_train:].values.astype(np.int64)
class SyntheticData(): def __init__(self,features,labels):self.features, self.labels = features , labelsdef __getitem__(self, index): # __getitem__(self, index) 一般用来迭代序列(常见序列如:列表、元组、字符串)return self.features[index], self.labels[index]def __len__(self):return len(self.labels)
# 数据集
train_dataset= ds.GeneratorDataset(source=SyntheticData(train_features, train_labels), column_names=['features', 'label'],python_multiprocessing=False)test_dataset= ds.GeneratorDataset(source=SyntheticData(test_features, test_labels ), column_names=['features', 'label'],python_multiprocessing=False)
构建模型
class Accumulator: """累加器"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
def accuracy(y_hat, y): """计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # 判断y_hat是不是矩阵y_hat = y_hat.argmax(axis=1) # 得到每样本预测概率最大所属分类的下标cmp = y_hat.asnumpy() == y.asnumpy() # y_hat.asnumpy() == y.asnumpy()返回的是一个布尔数组return float(cmp.sum())def evaluate_accuracy(net, data_iter): """计算在指定数据集上模型的精度"""metric = Accumulator(2) # 累加器,metric[0]记录正确预测数,metric[1]记录预测总数for X, y in data_iter:metric.add(accuracy(net(X), y), y.size)return metric[0] / metric[1] # 正确预测数 / 预测总数
def train_epoch( train_iter, learning_rate, weight_decay, batch_size): """训练模型一个迭代周期"""net = nn.SequentialCell([nn.Dense(all_features.shape[1], 32),nn.ReLU(),nn.Dense(32, 16),nn.ReLU(),nn.Dense(16, 2)]) loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')#optim = nn.SGD(net.trainable_params(), learning_rate = learning_rate, weight_decay = weight_decay)optim = nn.Adam(net.trainable_params(), learning_rate = learning_rate, weight_decay = weight_decay) net_with_loss = nn.WithLossCell(net, loss) net_train = nn.TrainOneStepCell(net_with_loss, optim) metric = Accumulator(3)for X, y in train_iter:l = net_train(X, y)y_hat = net(X)metric.add(float(l.sum().asnumpy()), accuracy(y_hat, y), y.size)return metric[0] / metric[2], metric[1] / metric[2] ,net # 误差 / 预测总数 ,正确预测数 / 预测总数
def trainer( train_iter, test_iter, num_epochs, learning_rate, weight_decay, batch_size, train_acc_plot, test_acc_plot): """训练模型"""train_iter = train_iter.batch(batch_size = batch_size, num_parallel_workers=1)test_iter = test_iter.batch(batch_size = batch_size, num_parallel_workers=1)for epoch in range(num_epochs):train_metrics = train_epoch(train_iter, learning_rate, weight_decay, batch_size)train_loss, train_acc, net = train_metricstest_acc = evaluate_accuracy(net, test_iter)train_acc_plot.append(float(train_acc))test_acc_plot.append(float(test_acc))print('最终训练集精度:', train_acc, '最终测试集精度:',test_acc )# 检测assert train_loss < 0.6, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc
训练
num_epochs, weight_decay, batch_size =20, 0, 64# 动态学习率
learning_rate = 0.1
end_learning_rate = 0.05
decay_steps = 6
power = 0.5
learning_rate = nn.PolynomialDecayLR(learning_rate, end_learning_rate, decay_steps, power)train_acc_plot=[]
test_acc_plot=[]
trainer( train_dataset, test_dataset, num_epochs, learning_rate, weight_decay, batch_size, train_acc_plot, test_acc_plot)
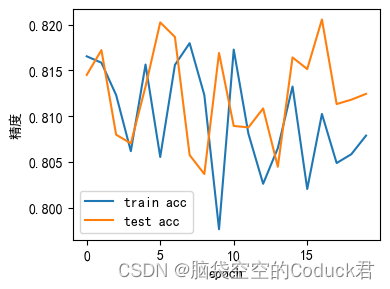
最终训练集精度: 0.8078666666666666 最终测试集精度: 0.8124302788844622
# 构建loss-step曲线可了解loss随epoch的变化情况plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=Falsex=np.linspace(0, num_epochs-1,num_epochs)plt.figure(figsize=(4,3))
plt.xlabel(u"epoch")
plt.ylabel(u"精度")
plt.plot(x, train_acc_plot, label='train acc')
plt.plot(x, test_acc_plot, label='test acc')
plt.legend(loc="best")
plt.tight_layout(rect = [0,0,1,1])
相关文章:
mindspore的MLP模型(多层感知机)
导入模块 import hashlib import os import tarfile import zipfile import requests import numpy as np import pandas as pd import mindspore import mindspore.dataset as ds from mindspore import nn import mindspore.ops as ops import mindspore.numpy as mnp from …...

【论文极速读】VQ-VAE:一种稀疏表征学习方法
【论文极速读】VQ-VAE:一种稀疏表征学习方法 FesianXu 20221208 at Baidu Search Team 前言 最近有需求对特征进行稀疏编码,看到一篇论文VQ-VAE,简单进行笔记下。如有谬误请联系指出,本文遵循 CC 4.0 BY-SA 版权协议,…...

Flask-Blueprint
Flask-Blueprint 一、简介 概念: Blueprint 是一个存储操作方法的容器,这些操作在这个Blueprint 被注册到一个应用之后就可以被调用,Flask 可以通过Blueprint来组织URL以及处理请求 。 好处: 其本质上来说就是让程序更加松耦合…...

png图片转eps格式
下载latex工具后 在要转换的png图片文件夹路径下,打开命令行窗口,输入以下命令: bmeps -c fig图片名.png 图片名.eps...

English Learning - L2 语音作业打卡 Day2 2023.2.23 周四
English Learning - L2 语音作业打卡 Day2 2023.2.23 周四💌 发音小贴士:💌 当日目标音发音规则/技巧:🍭 Part 1【热身练习】🍭 Part2【练习内容】🍭【练习感受】🍓元音[ ɔ: ]&…...

低频量化之 可转债 配债 策略数据 - 全网独家
目录历史文章可转债配债数据待发转债(进展统计)待发转债(行业统计)待发转债(5证监会通过,PE排序)待发转债(5证监会通过,安全垫排序)待发转债(4发审…...

论文阅读_DALLE-2的unCLIP模型
论文信息 name_en: Hierarchical Text-Conditional Image Generation with CLIP Latents name_ch: 利用CLIP的层次化文本条件图像生成 paper_addr: http://arxiv.org/abs/2204.06125 doi: 10.48550/arXiv.2204.06125 date_read: 2023-02-12 date_publish: 2022-04-12 tags: [‘…...

软件测试5年,历经3轮面试成功拿下华为Offer,24K/16薪不过分吧
前言 转眼过去,距离读书的时候已经这么久了吗?,从18年5月本科毕业入职了一家小公司,到现在快5年了,前段时间社招想着找一个新的工作,前前后后花了一个多月的时间复习以及面试,前几天拿到了华为的…...

【软件工程】课程作业(三道题目:需求分析、概要设计、详细设计、软件测试)
文章目录:故事的开头总是极尽温柔,故事会一直温柔……💜一、你怎么理解需求分析?1、需求分析的定义:2、需求分析的重要性:3、需求分析的内容:4、基于系统分析的方法分类:5、需求分析…...
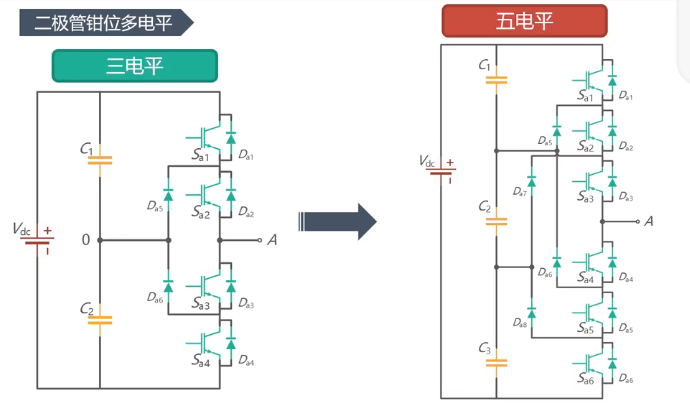
05 DC-AC逆变器(DCAC Converter / Inverter)简介
文章目录0、概述逆变原理方波变换阶梯波变换斩控调制方式逆变器分类逆变器波形指标1、方波变换器A 单相单相全桥对称单脉冲调制移相单脉冲调制单相半桥2、方波变换器B 三相180度导通120度导通(线、相的关系与180度相反)3、阶梯波逆变器独立直流源二极管钳…...

带你深层了解c语言指针
前言 🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻推荐专栏: 🍔🍟🌯 c语言进阶 🔑个人信条: 🌵知行合一 🍉本篇简介:>:介绍c语言中有关指针更深层的知识. 金句分享: ✨今天…...
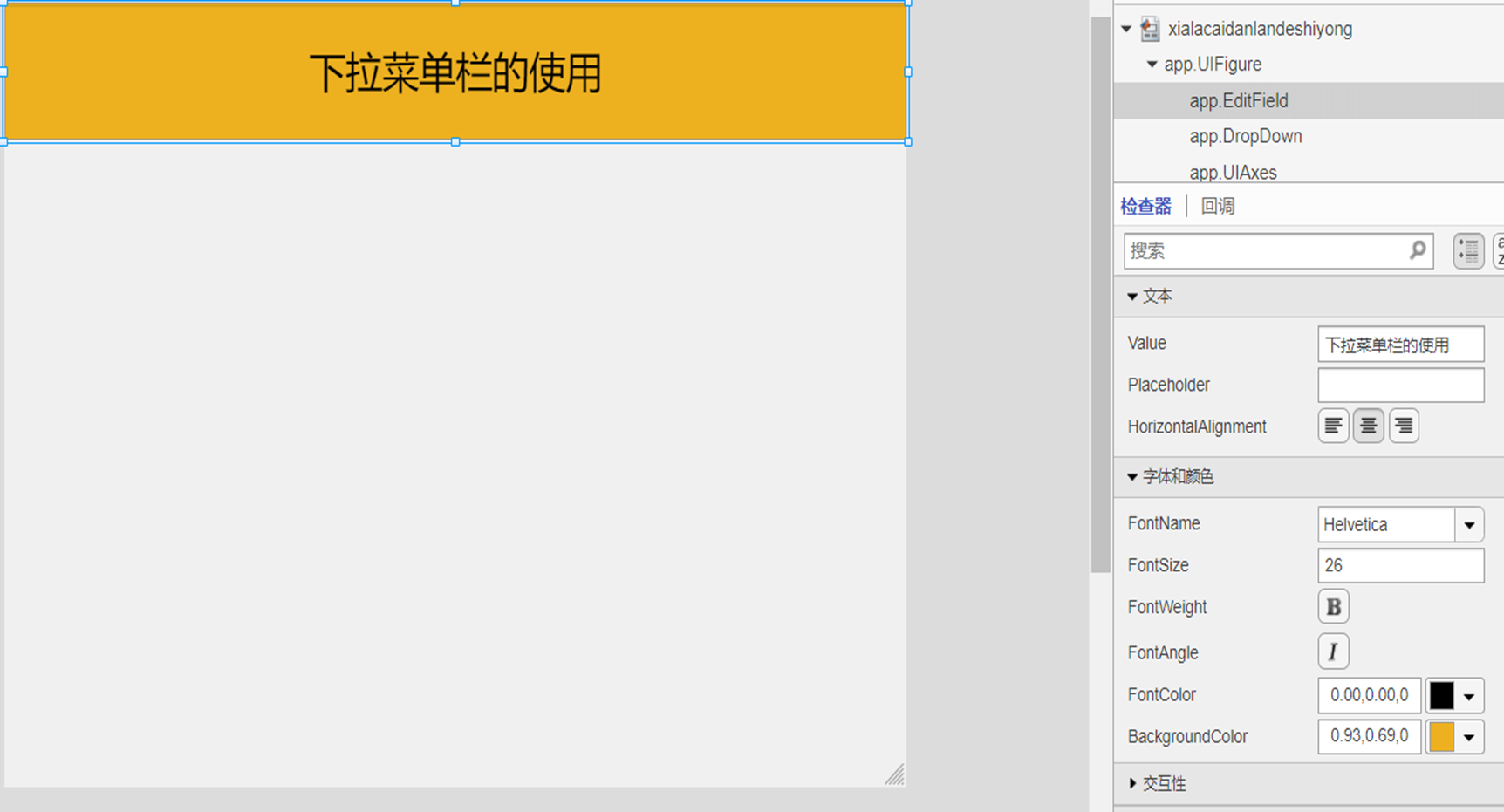
2-MATLAB APP Design-下拉菜单栏的使用
一、APP 界面设计展示 1.新建一个空白的APP,在此次的学习中,我们会用到编辑字段(文本框)、下拉菜单栏、坐标区,首先在界面中拖入一个编辑字段(文本框),在文本框中输入内容:下拉菜单栏的使用,调整背景颜色,字体的颜色为黑色,字体的大小调为26. 2.在左侧组件库常用栏…...

七、HTTPTomcatServlet
1,Web概述 1.1 Web和JavaWeb的概念 Web是全球广域网,也称为万维网(www),能够通过浏览器访问的网站。 在我们日常的生活中,经常会使用浏览器去访问百度、京东、传智官网等这些网站,这些网站统称为Web网站。如下就是通…...

LeetCode 热题 C++ 198. 打家劫舍
力扣198 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个房屋存…...
C语言学习笔记——程序环境和预处理
目录 前言 一、程序环境 1. 翻译环境 1.1 主要过程 1.2 编译过程 2. 运行环境 二、预处理 1. 预定义符号 2. #define 2.1 #define定义标识符 2.2 #define定义宏 2.3 命名约定和移除定义 3. 条件编译 4. 文件包含 结束语 前言 每次我们写完代码运行的时候都…...

「JVM 高效并发」Java 内存模型
Amdahl 定律代替摩尔定律成为了计算机性能发展的新源动力,也是人类压榨计算机运算能力的最有力武器; 摩尔定律,描述处理器晶体管数量与运行效率之间的发展关系;Amdahl 定律,描述系统并行化与串行化的比重与系统运算加…...

C语言刷题(2)——“C”
各位CSDN的uu们你们好呀,今天小雅兰来复习一下之前所学过的内容噢,复习的方式,那当然是刷题啦,现在,就让我们进入C语言的世界吧 当然,题目还是来源于牛客网 完完全全零基础 编程语言初学训练营_在线编程题…...

第一个 Spring MVC 注解式开发案例(初学必看)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
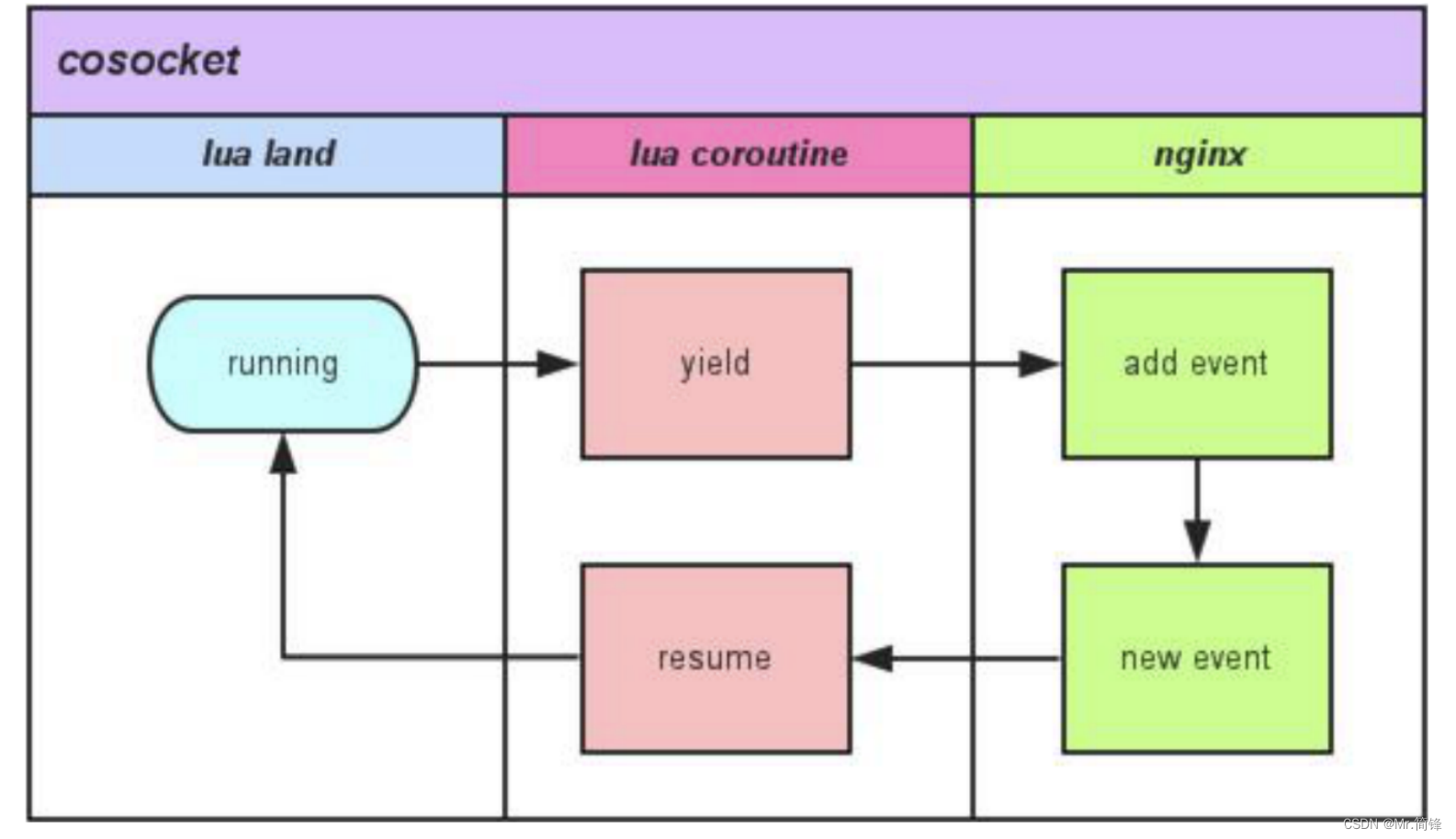
openresty学习笔记
openresty 简介 openresty 是一个基于 nginx 与 lua 的高性能 web 平台,其内部 集成了大量精良的 lua 库、第三方模块以及大数的依赖项。用于 方便搭建能够处理超高并发、扩展性极高的动态 web 应用、 web 服务和动态网关。 openresty 通过汇聚各种设计精良的 ngi…...

微信小程序DAY3
文章目录一、页面导航1-1、声明式导航1-2、编程式导航1-3、声明式导航传参1-4、编程式导航传参1-5、获取导航传递的参数二、页面事件2-1、下拉刷新事件2-1-1、启用下拉刷新2-1-2、配置下拉刷新2-1-3、监听页面下拉刷新事件2-2、上拉触底事件2-2-1、事件触发2-2-1、事件配置三、…...

终极指南:5分钟掌握Piper鼠标地图组件与SVG渲染核心技术
终极指南:5分钟掌握Piper鼠标地图组件与SVG渲染核心技术 【免费下载链接】piper GTK application to configure gaming devices 项目地址: https://gitcode.com/gh_mirrors/pip/piper Piper是一款功能强大的GTK应用程序,专为配置游戏设备而设计。…...

PyMobileDevice3 高效异步架构解析:深入理解iOS设备通信协议栈实现
PyMobileDevice3 高效异步架构解析:深入理解iOS设备通信协议栈实现 【免费下载链接】pymobiledevice3 Pure python3 implementation for working with iDevices (iPhone, etc...). 项目地址: https://gitcode.com/gh_mirrors/py/pymobiledevice3 PyMobileDev…...

手把手教你用DrissionPage搭建个人新闻聚合器:自动抓取百度热搜并保存到Excel
用DrissionPage打造智能新闻聚合器:从百度热搜抓取到Excel自动化分析 每天手动刷新闻不仅耗时,还容易错过重要信息。想象一下,如果有个私人助手能自动收集全网热点,整理成结构化的报告,甚至生成直观的可视化图表——这…...
)
GESP三级语法知识(六、string 入门与基础操作)
🌟 第一课:《string 入门与基础操作》🏰 第一章:string 是什么?(升级版小火车)1、🎯 故事以前我们用的是:👉 char数组 小火车 🚂(要自…...

筑牢数据安全底座!百度智能云数据库GaiaDB分布式版通过『国密认证』
近日,百度智能云自研的关系型数据库GaiaDB分布式版获得由国家密码管理局商用密码检测认证中心颁发的《商用密码产品认证证书》,通过GM/T 0028《密码模块安全技术要求》安全等级第二级认证。这一认证标志着GaiaDB分布式版密码模块在密码安全设计、密钥管理…...

从零开始:基于 Chroma+Ollama 的本地知识库搭建与智能问答实战指南
1. 为什么选择 ChromaOllama 组合? 如果你正在寻找一个既轻量又强大的本地知识库解决方案,Chroma 和 Ollama 的组合绝对值得考虑。我最初接触这个组合是因为需要一个完全离线的知识管理系统,经过多次对比测试后发现,这对搭档在易用…...

动态链接库emp.dll详解:从原理到实战修复
动态链接库emp.dll深度解析:技术原理与高效修复指南 引言:动态链接库的现代价值 在Windows系统的软件生态中,动态链接库(DLL)如同建筑中的预制构件,通过代码复用机制显著提升了开发效率和系统资源利用率。emp.dll作为其中一员&…...

单片机电源电路设计:从3.3V到5V系统详解
1. 单片机电源电路设计基础 作为一名电子工程师,我深知电源电路设计在单片机系统中的重要性。电源就像人体的心脏,为整个系统提供稳定可靠的能量供应。在多年的项目实践中,我发现很多初学者往往忽视了电源设计的重要性,导致系统不…...
)
别再只用DoDragDrop了!手把手教你用WPF实现一个能拖拽合并数据的自定义控件(附完整源码)
WPF高级拖拽交互实战:从原生API局限到自定义控件设计 在构建现代桌面应用时,流畅自然的拖拽交互往往能极大提升用户体验。WPF虽然提供了基础的DoDragDrop API,但当我们需要实现复杂场景如卡片合并、动态数据交换时,原生方案就显得…...
之 图像处理进阶 - 像素操作与批量保存)
Labview 机器视觉(4)之 图像处理进阶 - 像素操作与批量保存
1. 像素操作:从入门到精通的实战指南 在工业自动化领域,图像处理的核心往往在于对像素级别的精准控制。LabVIEW作为一款强大的图形化编程工具,提供了丰富的像素操作函数,让工程师能够像搭积木一样构建复杂的视觉处理流程。 我第一…...