python爬虫request和BeautifulSoup使用
request使用
1.安装request
pip install request
2.引入库
import requests
3.编写代码
发送请求
我们通过以下代码可以打开豆瓣top250的网站
response = requests.get(f"https://movie.douban.com/top250")
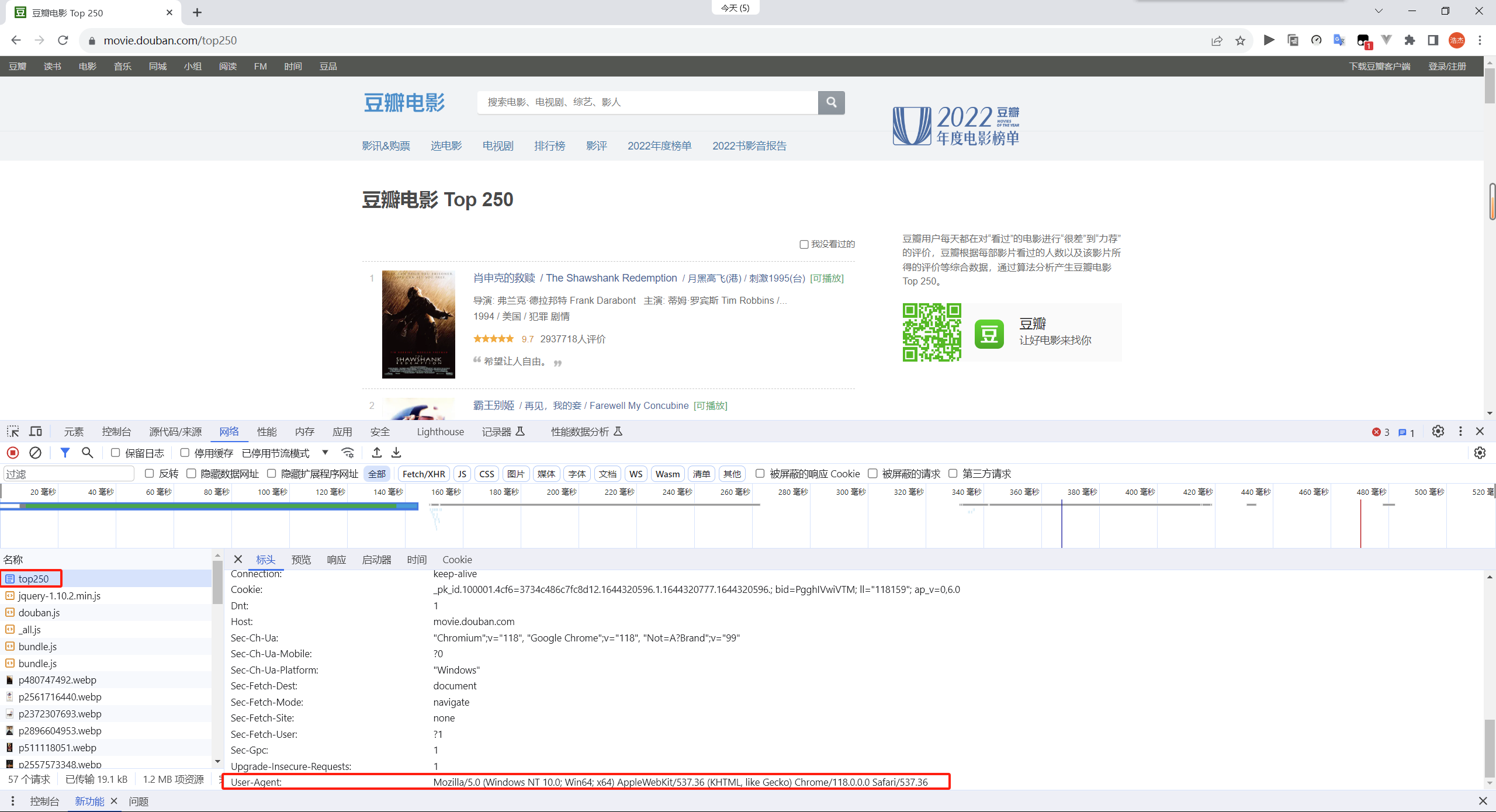
但因为该网站加入了反爬机制,所以我们需要在我们的请求报文的头部加入User-Agent的信息
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}response = requests.get(f"https://movie.douban.com/top250",headers=headers)
User-Agent可以通过访问网站时按f12查看获取
我们可以通过response的ok属性判断是否请求成功
import requests
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:print("请求成功!")
else:print("请求失败!")
此时如果请求成功,控制台就会打印请求成功!

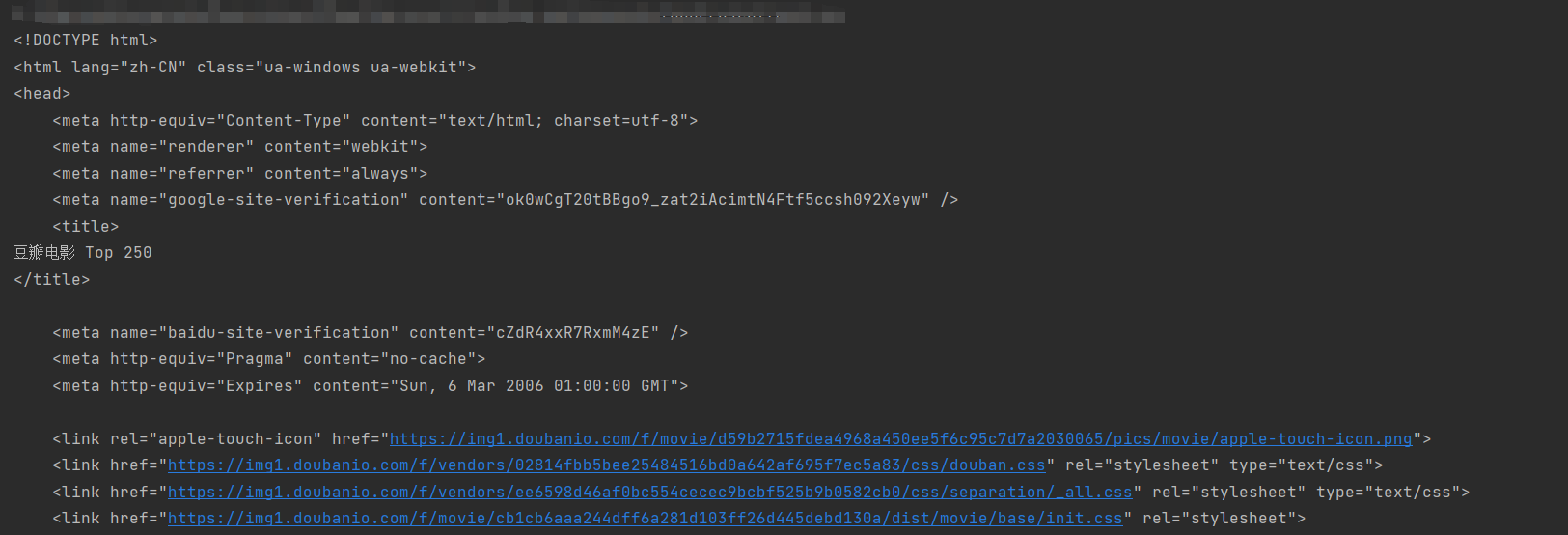
获取网页的html
我们可以通过response的text的属性来获取网页的html
import requests
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:html = response.textprint(html)
else:print("请求失败!")
此时请求成功就会打印页面的html了
BeautifulSoup使用
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
简单的说,我们可以拿他来解析html页面,来获取html的元素
1.安装BeautifulSoup
要使用BeautifulSoup4需要先安装lxml,再安装bs4
pip install bs4
pip install bs4
2.引入库
from bs4 import BeautifulSoup
3.编写代码
获取元素
我们通过BeautifulSoup()就可以得到解析后的soup对象
soup = BeautifulSoup(html, "html.parser")
使用findAll函数就可以找到我们想要的元素,例如:我们想找到span标签中,class为title的元素
all_titls = soup.findAll("span", attrs={"class": "title"})
此时我们代码如下
from bs4 import BeautifulSoup
import requests
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:html = response.textsoup = BeautifulSoup(html, "html.parser")all_titls = soup.findAll("span", attrs={"class": "title"})print(all_titls)
else:print("请求失败!")
运行结果
元素处理
我们虽然找到了span标签中,class为title的元素,但我们不需要span标签中的内容,所以我们需要对他进行处理
首先我们发现,all_titls其实是一个数组,所以我们可以遍历他,这样就可以得到每一个span元素,通过string的属性就可以得到span标签中间的内容
from bs4 import BeautifulSoup
import requests
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:html = response.textsoup = BeautifulSoup(html, "html.parser")all_titls = soup.findAll("span", attrs={"class": "title"})for title in all_titls:title_string = title.stringprint(title_string)
else:print("请求失败!")
此时我们发现,我们虽然得到span标签中间的内容,但其中含有电影名字的英文名这是我们不需要的
通过观察我们发现,每个英文名前都是带有/的,所以我们可以判断其是否含有"/"来进行过滤
from bs4 import BeautifulSoup
import requests
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}response = requests.get(f"https://movie.douban.com/top250",headers=headers)
if response.ok:html = response.textsoup = BeautifulSoup(html, "html.parser")all_titls = soup.findAll("span", attrs={"class": "title"})for title in all_titls:title_string = title.stringif "/" not in title_string:print(title_string)
else:print("请求失败!")

整合
虽然此时我们打印出了我们想要的数据,但这只是其中一页的,且只是打印,并没有存入数据库或者某个文件里
打印所有页
通过观察第二页的路径,我们发现在点击第二页时系统会传一个start的属性,这个属性除以25在加1就是我们需要的页数,反过来就是 (页数-1)*25 = start
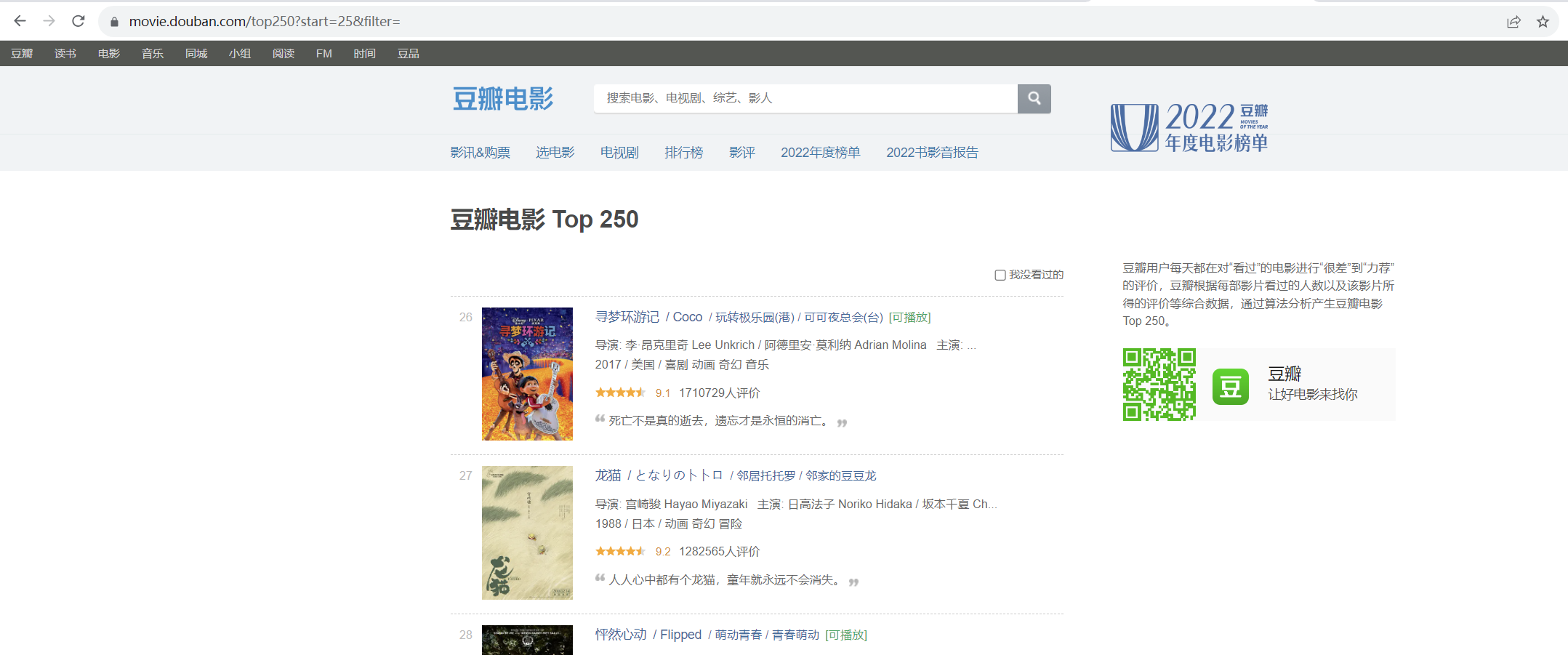
所以我们可以通过for循环,依次传入0,25,50…
from bs4 import BeautifulSoup
import requests
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}for start_num in range(0,250,25):response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)if response.ok:html = response.textsoup = BeautifulSoup(html,"html.parser")all_titls = soup.findAll("span",attrs={"class":"title"})for title in all_titls:title_string = title.stringif "/" not in title_string:print(title_string)else:print("请求失败!")
这样我们就得到了所有的电影名
存入txt
这里我们演示将数据存入记事本中,我们定义个数组,将所有电影的名字存入该数组,最后遍历数组写入txt文件即可
from bs4 import BeautifulSoup
import requests
headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
titles = []
for start_num in range(0,250,25):response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)if response.ok:html = response.textsoup = BeautifulSoup(html,"html.parser")all_titls = soup.findAll("span",attrs={"class":"title"})for title in all_titls:title_string = title.stringif "/" not in title_string:titles.append(title_string)else:print("请求失败!")
with open(r'豆瓣top250.txt', 'w') as f:for i in titles:f.write(i + '\n')

相关文章:
python爬虫request和BeautifulSoup使用
request使用 1.安装request pip install request2.引入库 import requests3.编写代码 发送请求 我们通过以下代码可以打开豆瓣top250的网站 response requests.get(f"https://movie.douban.com/top250")但因为该网站加入了反爬机制,所以…...

记录--vue3实现excel文件预览和打印
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 在前端开发中,有时候一些业务场景中,我们有需求要去实现excel的预览和打印功能,本文在vue3中如何实现Excel文件的预览和打印。 预览excel 关于实现excel文档在…...
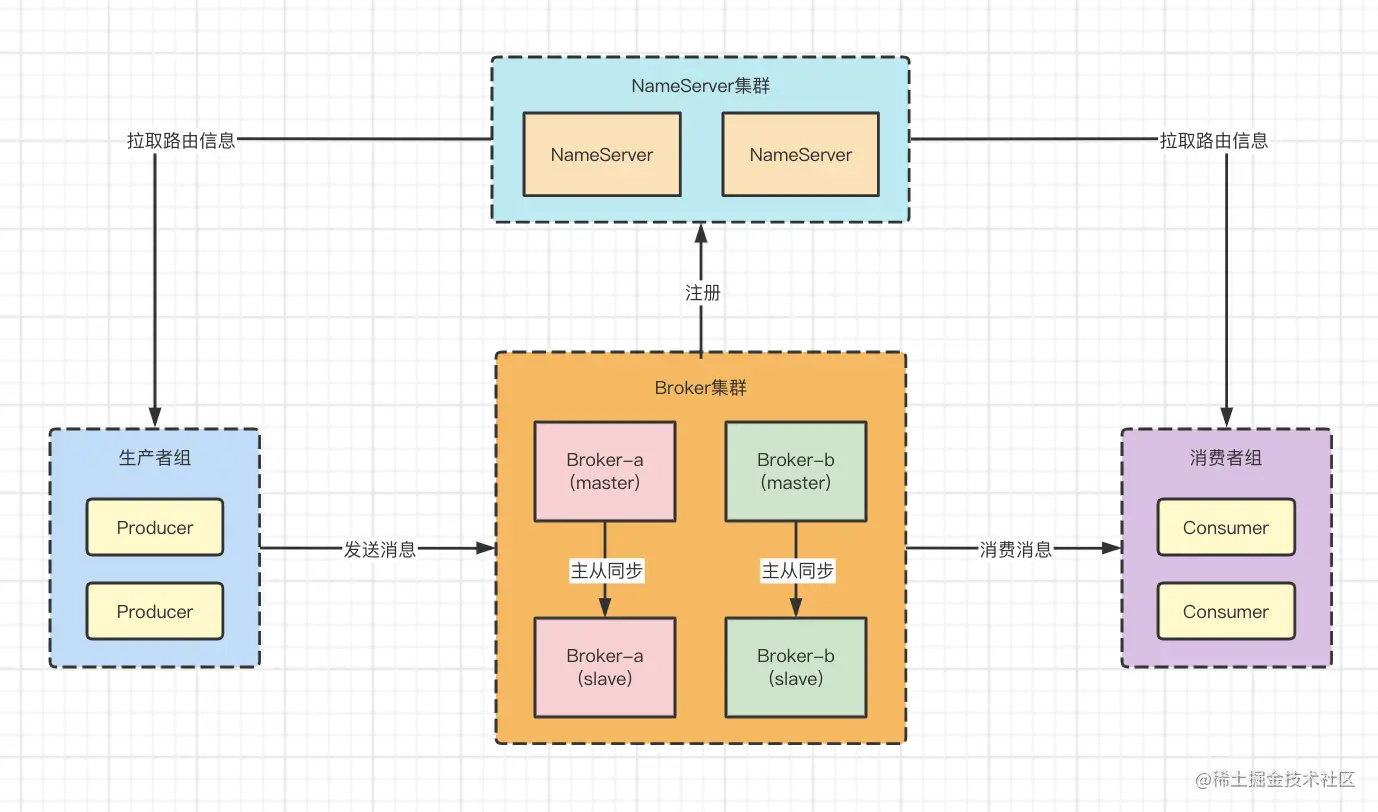
消息队列中间件面试笔记总结RabbitMQ,Kafka,RocketMQ
文章目录 (一) Rabbit MQRabbitMQ 核心概念消息队列的作用Exchange(交换器)Broker(消息中间件的服务节点)如何保证消息的可靠性如何保证 RabbitMQ 消息的顺序性如何保证 RabbitMQ 高可用的?如何解决消息队列的延时以及过期失效问题消息堆积问…...
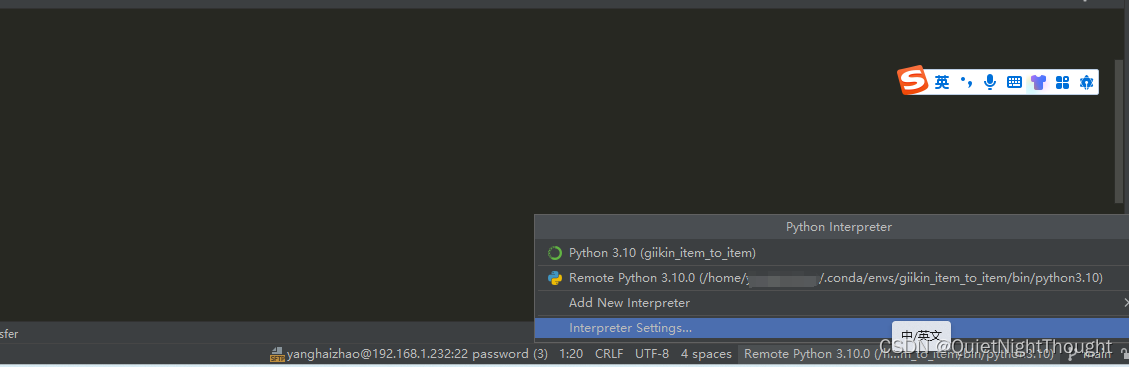
pycharm远程连接Linux服务器
文章目录 一:说明二:系统三:实现远程连接方式一: 直接连接服务器不使用服务器的虚拟环境步骤一:找到配置服务器的地方步骤二:进行连接配置步骤三:进行项目文件映射操作步骤四:让文件…...
全屏显示隐藏状态栏和导航栏)
Android应用开发(38)全屏显示隐藏状态栏和导航栏
Android应用开发学习笔记——目录索引 protected void onCreate(Bundle savedInstanceState) {/* 添加代码 */requestWindowFeature(Window.FEATURE_ACTION_BAR_OVERLAY);getWindow().addFlags(WindowManager.LayoutParams.FLAG_FULLSCREEN);WindowManager.LayoutParams lp ge…...
日本IT Week秋季展丨美格智能以技术创新共建美好数字生活
10月25日至27日,日本国际IT消费电子展览会(Japan IT Week 2023秋季展)在日本千叶幕张国际展览中心举行。日本IT周是日本IT市场的标杆,涵盖软件开发、大数据管理、嵌入式系统、数据存储、信息安全、数据中心、云计算、物联网&#…...

centos7 install postgres-15
env centos7 1.更新包,避免安装时出错 yum update 2. PostgreSQL: Linux downloads (Red Hat family) sudo yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm sudo yum install -y post…...

JVM常见的垃圾回收器(详细)
1、Young为年轻代出发的垃圾回收器。 2、Old为老触发的垃圾回收器。 3、连线代表的是垃圾回收器的组合。CMS 和Serial Old连线代表CMS一旦不行了,Serial Old上场。 首先了解一个概念:STW 1、什么是STW? STW是Stop-The-World缩写: 是在垃圾回…...

acwing 5283. 牛棚入住
题目 - 点击直达 1. 5283. 牛棚入住1. 题目详情1. 原题链接2. 题目要求3. 基础框架 2. 解题思路1. 思路分析2. 时间复杂度3. 代码实现 1. 5283. 牛棚入住 1. 题目详情 贝茜经营的牛棚旅店中有 a 个可供一头牛入住的小牛栏和 b 个可供两头牛入住的大牛栏。 初始时,…...
)
Qt触摸屏双指缩放和单指移动界面(支持嵌入式设备)
本文介绍的QGraphicsView的双指缩放,QWidget更简单,可以参考当前内容。 方法一:(QTouchEvent事件实现) 使用场景:适用于paintevent绘制下的界面。 优点:不需要代码设置中心锚点(锚点…...
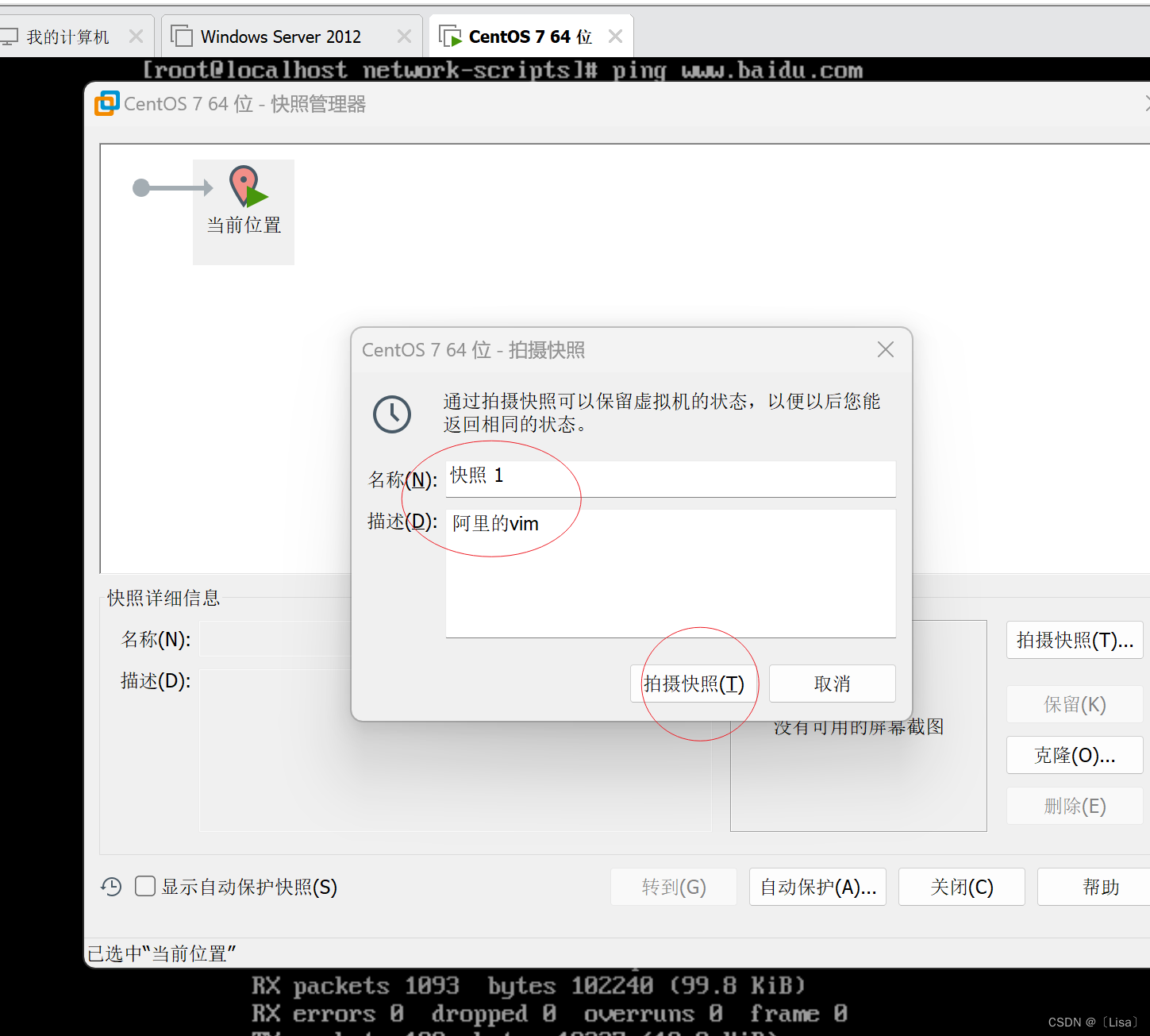
【Linux】虚拟机安装Linux、客户端工具,MobaXterm的使用,Linux常用命令
目录 一,安装Linux的centos7版本 具体安装步骤: 二,Linux常见的命令: 三、安装客户端工具 1、介绍 2、安装MobaXterm 3、换源 四、拍照功能 一,安装Linux的centos7版本 介绍: 具体安装步骤&#…...
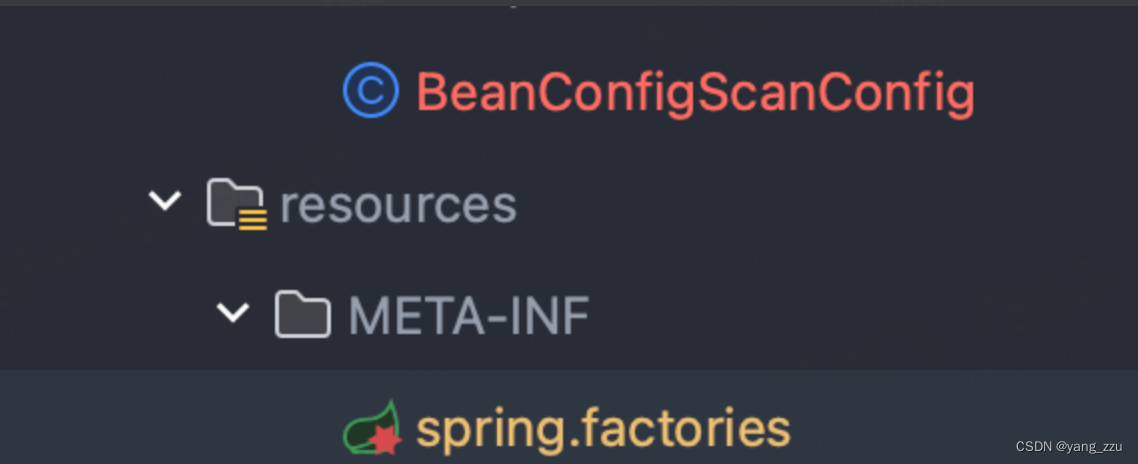
springboot-scanBasePackages包扫描
目录 原因: 方式一: 方式二: 原因: 由于对rocketMq进行了一次封装,mq模块里面引用了RocketMQTemplate的bean,如果只引入jar包的依赖,启动的时候不会报错,但是在调用到 RocketMQT…...
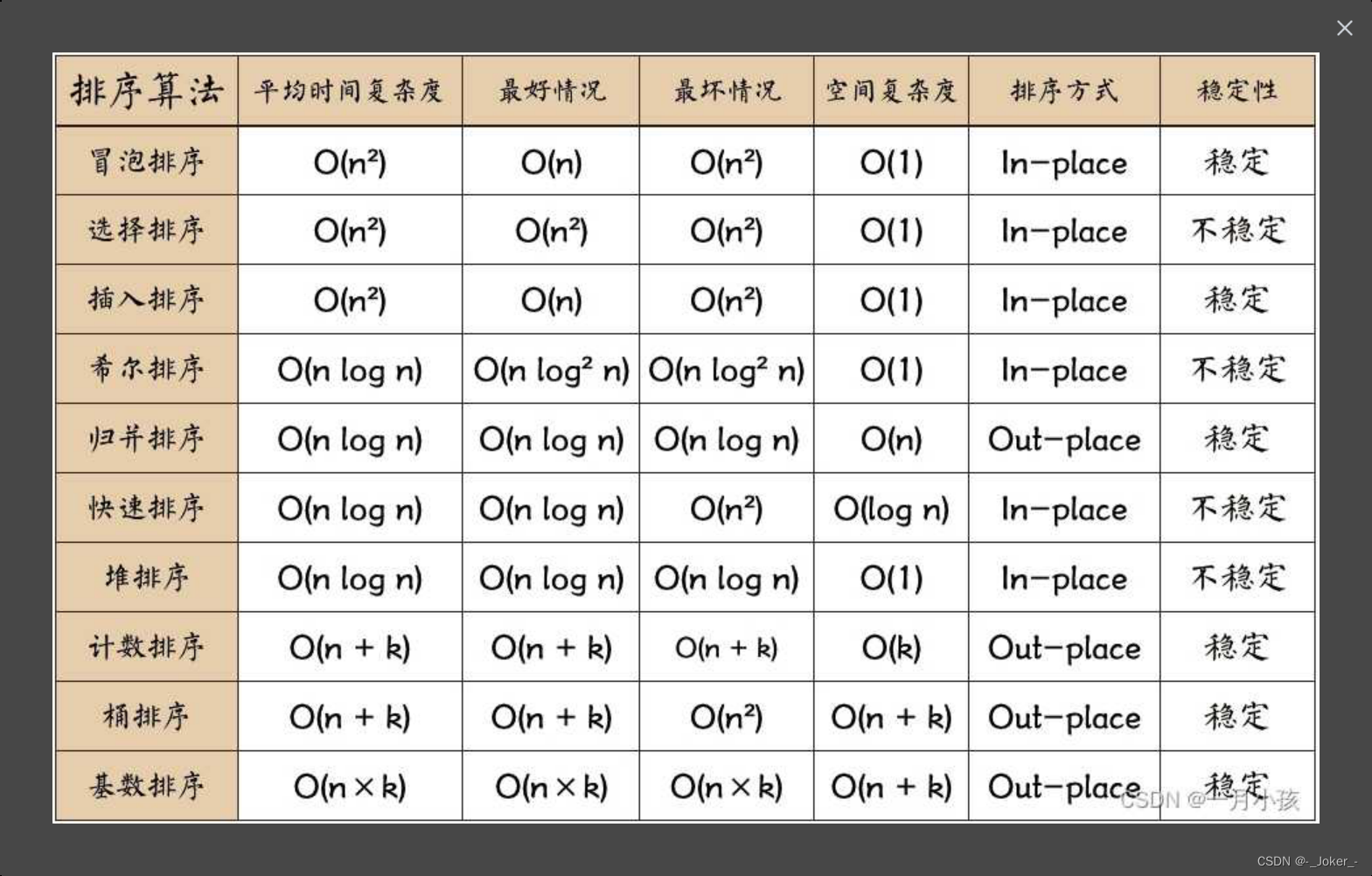
【C语言数据结构——————排序(1万字)】
文章目录 排序的概念 常见排序算法分类冒泡排序 时间复杂度稳定性 原理实现插入排序 时间复杂度稳定性实现选择排序 时间复杂度稳定性实现希尔排序 时间复杂度稳定性希尔排序的算法思想实现 优化快速排序 时间复杂度空间复杂度稳定性实现 三数取中优化归并排序 时间复杂度空间复…...
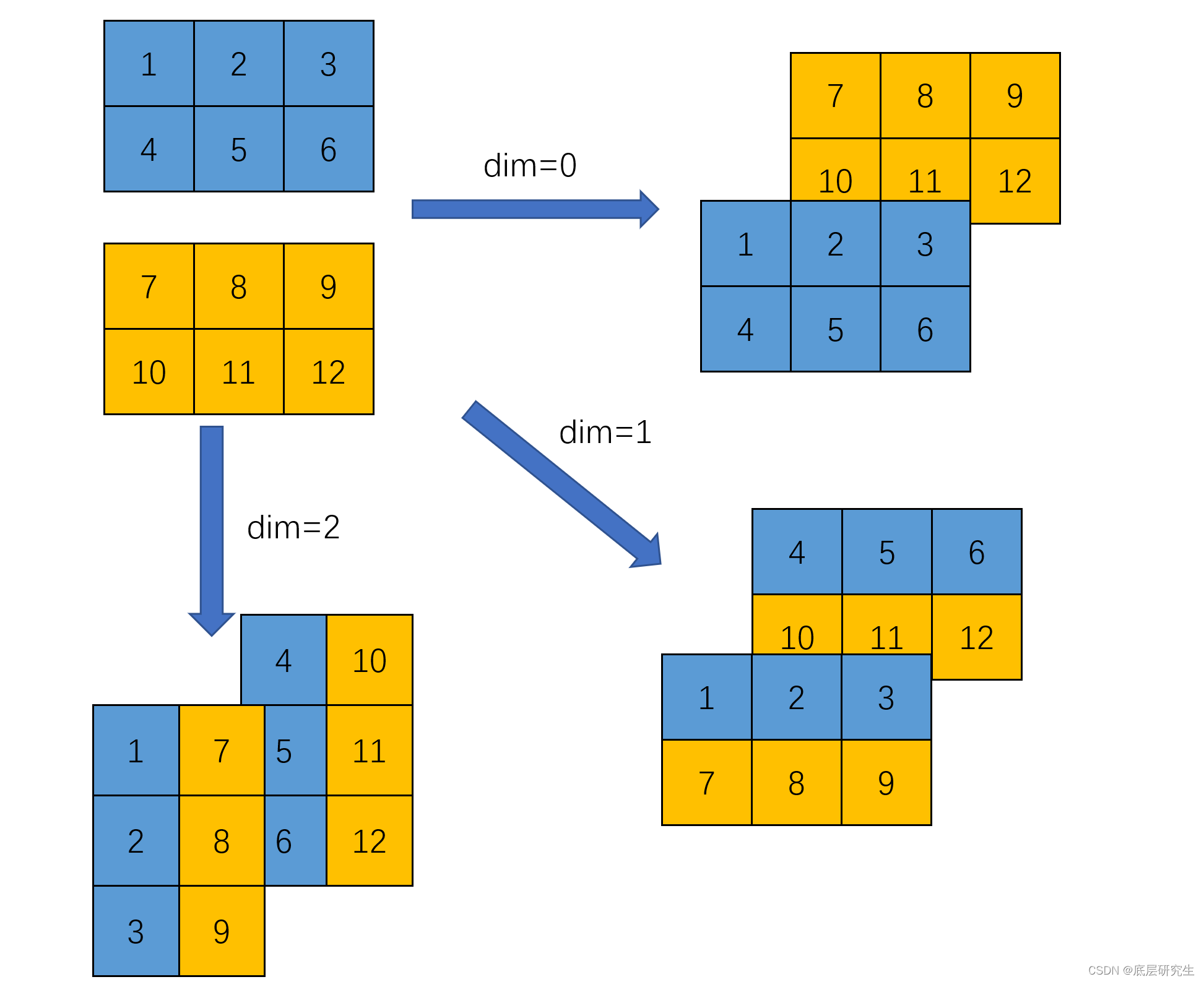
PyTorch基础(18)-- torch.stack()方法
一、方法详解 首先,看一下stack的直观解释,动词可以简单理解为:把……放成一堆、把……放成一摞。 有了对stack方法的直观感受,接下来,我们正式解析torch.stack方法。 PyTorch torch.stack() method joins (concaten…...

从lc560“和为 K 的子数组“带你认识“前缀和+哈希表“的解题思路
1 前缀和哈希表解题的几道题目:建议集中练习 560. 和为 K 的子数组:https://leetcode.cn/problems/subarray-sum-equals-k/ 1248. 统计「优美子数组」: https://leetcode.cn/problems/count-number-of-nice-subarrays/ 1249. 和可被 K 整除的子数组(利用…...

c:变参函数:汇编解析;va_list;marco 宏:__VA_ARGS__
文章目录 参考gcc 内部的宏定义代码汇编调用在 SEI CERT C Coding Standard 这个标准里示例实例宏里的使用 参考 https://git.sr.ht/~gregkh/presentation-security/blob/3547183843399d693c35b502cf4a313e256d0dd8/security-stuff.pdf gcc 内部的宏定义 宏定义:…...
eclipse安装教程(2021版)
第一步:下载JDK (下载地址) Java SE - Downloads 第二步 根据自己电脑的系统,选择相应的版本x64代表64位,x86代表32位。点击相应的JDK进行下载 点击之后会出现一个对话框 同意之后下载。(记住下载到哪,打…...
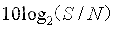
计算机网络重点概念整理-第二章 物理层【期末复习|考研复习】
第二章 物理层 【期末复习|考研复习】 计算机网络系列文章传送门: 第一章 计算机网络概述 第二章 物理层 第三章 数据链路层 第四章 网络层 第五章 传输层 第六章 应用层 第七章 网络安全 计算机网络整理-简称&缩写 文章目录 第二章 物理层 【期末复习|考研复习…...
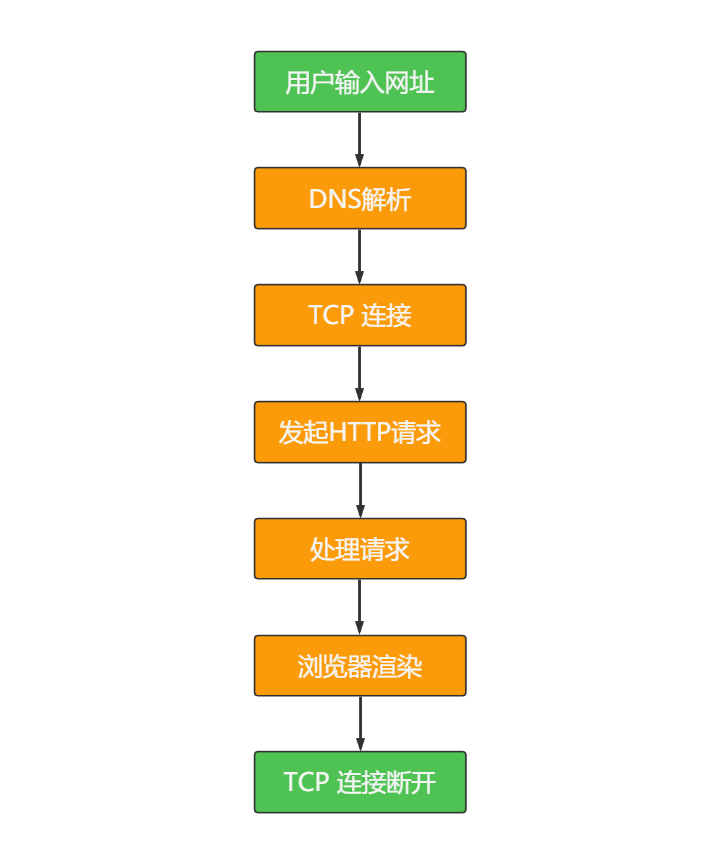
【计算机网络】从输入URL到页面都显示经历了什么??
文字总结 ① DNS 解析:当用户输入一个网址并按下回车键的时候,浏览器获得一个域名,而在实际通信过程中,我们需要的是一个 IP 地址,因此我们需要先把域名转换成相应 IP 地址。浏览器会首先从缓存中找是否存在域名&…...

[C++]——带你学习类和对象
类和对象——上 目录:一、面向过程和面向对象二、类的概念三、类的访问限定符和封装3.1 访问限定符3.2 封装 四、类的作用域五、类的实例化六、类的对象大小的计算七、类成员函数this指针7.1 this指针的引用7.2 this 指针的特性 目录: 类和对象是很重要…...

天际模组编排师:用LOOT主列表告别游戏崩溃的智能解决方案
天际模组编排师:用LOOT主列表告别游戏崩溃的智能解决方案 【免费下载链接】skyrimse The TES V: Skyrim Special Edition masterlist. 项目地址: https://gitcode.com/gh_mirrors/sk/skyrimse 你是否曾因《上古卷轴V:天际 特别版》模组冲突而烦恼…...

独立开发者如何利用Taotoken的Token Plan套餐有效控制月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的Token Plan套餐有效控制月度预算 作为一名独立开发者,项目预算通常有限,而AI…...
)
DeepSeek负载均衡方案竟被90%团队忽略的3个致命盲区:长连接保活、gRPC流式重试、Token级会话粘滞(附Checklist)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek负载均衡方案的演进与核心挑战 DeepSeek作为高性能开源大语言模型推理框架,其负载均衡方案经历了从静态路由到动态感知、从单层代理到多级协同的持续演进。早期版本依赖Nginx反向代…...

AI代理实战能力评估:MLE-Bench基准测试深度解析与工程启示
1. 项目概述与核心价值最近在跟进AI代理(AI Agent)领域的发展,特别是它们在自动化复杂工作流方面的潜力。作为一个在机器学习工程一线摸爬滚打了十来年的从业者,我深知从数据清洗、特征工程、模型调优到实验管理的全流程ÿ…...

OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如
OBS高级计时器插件:6种专业模式让你的直播时间管理轻松自如 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时间控制而烦恼吗?OBS Advanced Timer计时器插件是你的直播时间管理…...

FanControl终极指南:5分钟实现Windows风扇智能控制,告别散热噪音烦恼
FanControl终极指南:5分钟实现Windows风扇智能控制,告别散热噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitco…...

2026年10款论文降AIGC软件实测:从90%降至10%的宝藏之选
现在学校对 AIGC 的检测越来越严格,降低 AI 率成了毕业季最让人抓狂的问题。我当初写论文的时候也踩了大坑,AI 率直接飙到 80% 多,改得我头发都快掉没了。熬夜一遍遍地调整语句,结果 AI 率没降下来,查重率反而越改越高…...

揭秘AI教材写作技巧!低查重AI工具助力,3天完成50万字教材!
教材创作中AI工具的应用与优势 在教材编写的过程中,确保原创性与合规性的平衡是一个至关重要的问题。一方面,借鉴已有教材的优秀内容时,创作者往往会担心查重率超标;另一方面,自主进行原创知识点的阐释,又…...

如何快速掌握Poppins字体:免费开源的多语言设计终极指南
如何快速掌握Poppins字体:免费开源的多语言设计终极指南 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 还在为多语言项目寻找完美的字体解决方案而烦恼吗ÿ…...

GTA5线上小助手:终极方案助你高效称霸洛圣都
GTA5线上小助手:终极方案助你高效称霸洛圣都 【免费下载链接】GTA5OnlineTools GTA5线上小助手 项目地址: https://gitcode.com/gh_mirrors/gt/GTA5OnlineTools 厌倦了在GTA5线上模式中重复枯燥的刷钱任务?想要快速解锁所有服装和载具却不知从何入…...