【pandas技巧】group by+agg+transform函数
目录
1. group by+单个字段+单个聚合
2. group by+单个字段+多个聚合
3. group by+多个字段+单个聚合
4. group by+多个字段+多个聚合
5. transform函数
| students | grade | sex | score | money | |
|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 |
| 1 | 小猫 | 小学部 | male | 93 | 836 |
| 2 | 小鸭 | 初中部 | male | 83 | 854 |
| 3 | 小兔 | 小学部 | female | 90 | 931 |
| 4 | 小花 | 小学部 | male | 81 | 853 |
| 5 | 小草 | 小学部 | male | 80 | 991 |
| 6 | 小狗 | 初中部 | female | 81 | 854 |
| 7 | 小猫 | 小学部 | male | 93 | 886 |
| 8 | 小鸭 | 小学部 | male | 88 | 983 |
| 9 | 小兔 | 小学部 | male | 86 | 891 |
| 10 | 小花 | 初中部 | male | 92 | 830 |
| 11 | 小草 | 初中部 | male | 84 | 948 |
1. group by+单个字段+单个聚合
1.1 方法一
# 求每个人的总金额:
total_money=df.groupby("students")["money"].sum().reset_index()
total_money1.2 方法二(使用agg)
df.groupby("students").agg({"money":"sum"}).reset_index()
#或者
df.groupby("students").agg({"money":np.sum}).reset_index()| students | money | |
|---|---|---|
| 0 | 小兔 | 1820 |
| 1 | 小狗 | 1711 |
| 2 | 小猫 | 1670 |
| 3 | 小花 | 1861 |
| 4 | 小草 | 1825 |
| 5 | 小鸭 | 1719 |
2. group by+单个字段+多个聚合
2.1 方法一(使用group by+merge)
mean_money = df.groupby("students")["money"].mean().reset_index()
mean_money.columns = ["students","mean_money"]
mean_money
total_mean = total_money.merge(mean_money)
total_mean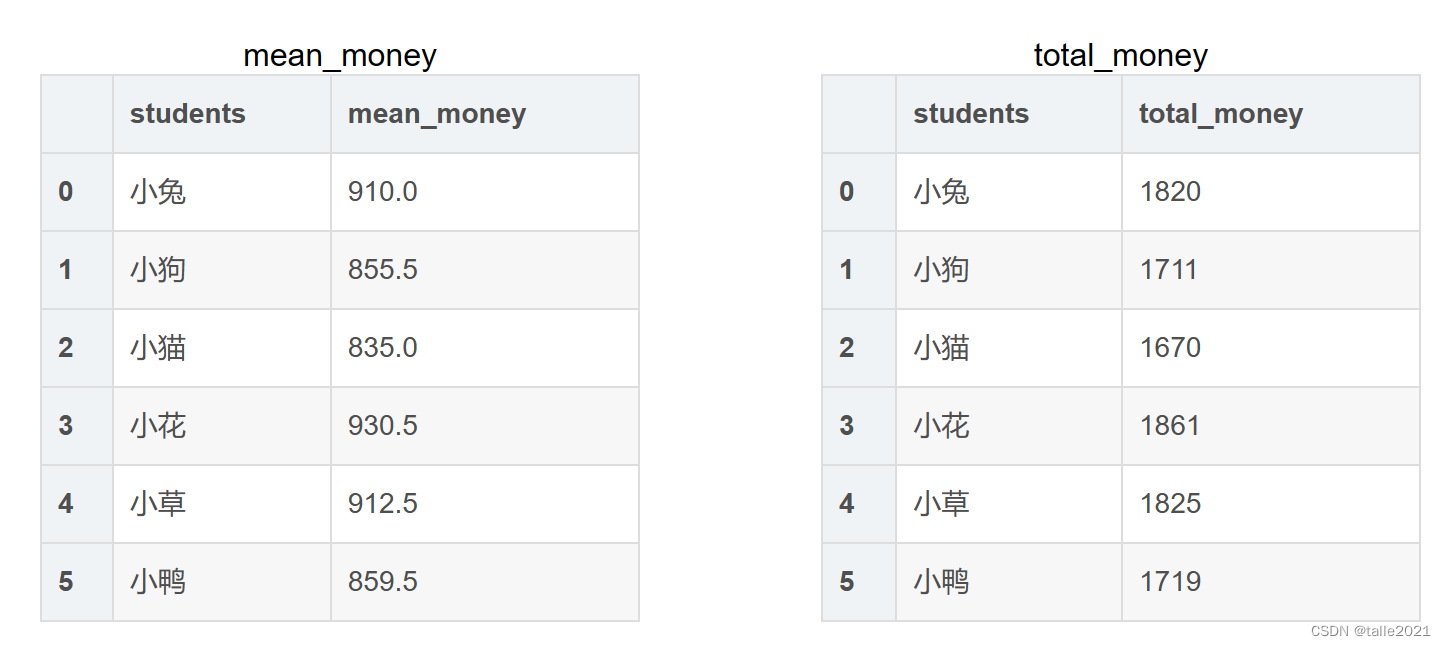
total_mean = total_money.merge(mean_money)
total_mean| students | total_money | mean_money | |
|---|---|---|---|
| 0 | 小兔 | 1820 | 910.0 |
| 1 | 小狗 | 1711 | 855.5 |
| 2 | 小猫 | 1670 | 835.0 |
| 3 | 小花 | 1861 | 930.5 |
| 4 | 小草 | 1825 | 912.5 |
| 5 | 小鸭 | 1719 | 859.5 |
2.2 方法二(使用group by+agg)
total_mean = df.groupby("students").agg(total_money=("money", "sum"),mean_money=("money", "mean")).reset_index()
total_mean| students | total_money | mean_money | |
|---|---|---|---|
| 0 | 小兔 | 1820 | 910.0 |
| 1 | 小狗 | 1711 | 855.5 |
| 2 | 小猫 | 1670 | 835.0 |
| 3 | 小花 | 1861 | 930.5 |
| 4 | 小草 | 1825 | 912.5 |
| 5 | 小鸭 | 1719 | 859.5 |
3. group by+多个字段+单个聚合
3.1 方法一
df.groupby(["students","grade"])["money"].sum().reset_index()| students | grade | money | |
|---|---|---|---|
| 0 | 小兔 | 初中部 | 1820 |
| 1 | 小狗 | 初中部 | 843 |
| 2 | 小狗 | 小学部 | 868 |
| 3 | 小猫 | 小学部 | 1670 |
| 4 | 小花 | 初中部 | 910 |
| 5 | 小花 | 小学部 | 951 |
| 6 | 小草 | 初中部 | 1825 |
| 7 | 小鸭 | 初中部 | 1719 |
3.2 方法二(使用agg)
df.groupby(["students","grade"]).agg({"money":"sum"}).reset_index()| students | grade | money | |
|---|---|---|---|
| 0 | 小兔 | 初中部 | 1820 |
| 1 | 小狗 | 初中部 | 843 |
| 2 | 小狗 | 小学部 | 868 |
| 3 | 小猫 | 小学部 | 1670 |
| 4 | 小花 | 初中部 | 910 |
| 5 | 小花 | 小学部 | 951 |
| 6 | 小草 | 初中部 | 1825 |
| 7 | 小鸭 | 初中部 | 1719 |
4. group by+多个字段+多个聚合
agg函数的使用的方法是:agg(新列名=("原列名", "统计函数"))
df.groupby(["students","grade"]).agg(total_money=("money", "sum"),mean_money=("money", "mean"),total_score=("score", "sum")).reset_index()| students | grade | total_money | mean_money | total_score | |
|---|---|---|---|---|---|
| 0 | 小兔 | 初中部 | 1820 | 910.0 | 192 |
| 1 | 小狗 | 初中部 | 843 | 843.0 | 88 |
| 2 | 小狗 | 小学部 | 868 | 868.0 | 93 |
| 3 | 小猫 | 小学部 | 1670 | 835.0 | 178 |
| 4 | 小花 | 初中部 | 910 | 910.0 | 95 |
| 5 | 小花 | 小学部 | 951 | 951.0 | 98 |
| 6 | 小草 | 初中部 | 1825 | 912.5 | 184 |
| 7 | 小鸭 | 初中部 | 1719 | 859.5 | 173 |
5. transform函数
5.1 方法一(使用groupby + merge)
df_1 = df.groupby("grade")["score"].mean().reset_index()
df_1.columns = ["grade", "average_score"]
df_1| grade | average_score | |
|---|---|---|
| 0 | 初中部 | 85.00 |
| 1 | 小学部 | 88.25 |
df_new1 = pd.merge(df, df_1, on="grade")
df_new1| students | grade | sex | score | money | average_score | |
|---|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 | 88.25 |
| 1 | 小猫 | 小学部 | male | 93 | 836 | 88.25 |
| 2 | 小兔 | 小学部 | female | 90 | 931 | 88.25 |
| 3 | 小花 | 小学部 | male | 81 | 853 | 88.25 |
| 4 | 小草 | 小学部 | male | 80 | 991 | 88.25 |
| 5 | 小猫 | 小学部 | male | 93 | 886 | 88.25 |
| 6 | 小鸭 | 小学部 | male | 88 | 983 | 88.25 |
| 7 | 小兔 | 小学部 | male | 86 | 891 | 88.25 |
| 8 | 小鸭 | 初中部 | male | 83 | 854 | 85.00 |
| 9 | 小狗 | 初中部 | female | 81 | 854 | 85.00 |
| 10 | 小花 | 初中部 | male | 92 | 830 | 85.00 |
| 11 | 小草 | 初中部 | male | 84 | 948 | 85.00 |
5.2 方法二(使用groupby + map)
dic = df.groupby("grade")["score"].mean().to_dict()
dic{'初中部': 85.0, '小学部': 88.25}
df_new1["average_map_score"] = df["grade"].map(dic)
df_new1| students | grade | sex | score | money | average_score | average_map_score | |
|---|---|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 | 88.25 | 88.25 |
| 1 | 小猫 | 小学部 | male | 93 | 836 | 88.25 | 88.25 |
| 2 | 小兔 | 小学部 | female | 90 | 931 | 88.25 | 85.00 |
| 3 | 小花 | 小学部 | male | 81 | 853 | 88.25 | 88.25 |
| 4 | 小草 | 小学部 | male | 80 | 991 | 88.25 | 88.25 |
| 5 | 小猫 | 小学部 | male | 93 | 886 | 88.25 | 88.25 |
| 6 | 小鸭 | 小学部 | male | 88 | 983 | 88.25 | 85.00 |
| 7 | 小兔 | 小学部 | male | 86 | 891 | 88.25 | 88.25 |
| 8 | 小鸭 | 初中部 | male | 83 | 854 | 85.00 | 88.25 |
| 9 | 小狗 | 初中部 | female | 81 | 854 | 85.00 | 88.25 |
| 10 | 小花 | 初中部 | male | 92 | 830 | 85.00 | 85.00 |
| 11 | 小草 | 初中部 | male | 84 | 948 | 85.00 | 85.00 |
5.3 方法三(使用transform一步到位)
df_new1["average_trans_score"] = df.groupby("grade")["score"].transform("mean")
df_new1| students | grade | sex | score | money | average_score | average_map_score | average_trans_score | |
|---|---|---|---|---|---|---|---|---|
| 0 | 小狗 | 小学部 | female | 95 | 844 | 88.25 | 88.25 | 88.25 |
| 1 | 小猫 | 小学部 | male | 93 | 836 | 88.25 | 88.25 | 88.25 |
| 2 | 小兔 | 小学部 | female | 90 | 931 | 88.25 | 85.00 | 85.00 |
| 3 | 小花 | 小学部 | male | 81 | 853 | 88.25 | 88.25 | 88.25 |
| 4 | 小草 | 小学部 | male | 80 | 991 | 88.25 | 88.25 | 88.25 |
| 5 | 小猫 | 小学部 | male | 93 | 886 | 88.25 | 88.25 | 88.25 |
| 6 | 小鸭 | 小学部 | male | 88 | 983 | 88.25 | 85.00 | 85.00 |
| 7 | 小兔 | 小学部 | male | 86 | 891 | 88.25 | 88.25 | 88.25 |
| 8 | 小鸭 | 初中部 | male | 83 | 854 | 85.00 | 88.25 | 88.25 |
| 9 | 小狗 | 初中部 | female | 81 | 854 | 85.00 | 88.25 | 88.25 |
| 10 | 小花 | 初中部 | male | 92 | 830 | 85.00 | 85.00 | 85.00 |
| 11 | 小草 | 初中部 | male | 84 | 948 | 85.00 | 85.00 | 85.00 |
相关文章:
【pandas技巧】group by+agg+transform函数
目录 1. group by单个字段单个聚合 2. group by单个字段多个聚合 3. group by多个字段单个聚合 4. group by多个字段多个聚合 5. transform函数 studentsgradesexscoremoney0小狗小学部female958441小猫小学部male938362小鸭初中部male838543小兔小学部female909314小花小…...
一文解读WordPress网站的各类缓存-老白博客
缓存是一种重要的WordPress优化手段,用于提高网站的性能和加载速度。减少计算量,有效提升响应速度,让有限的资源服务更多的用户。本文老白博客便从自己的使用简单给大家介绍下WordPress的缓存,包括 站点缓存(Page Cach…...

从零开始:开发直播商城APP的技术指南
时下,直播商城APP已经成了线上购物、电子商务的核心组成,本文将为您提供一个全面的技术指南,帮助您从零开始开发一个直播商城APP。我们将涵盖所有关键方面,包括技术堆栈、功能模块、用户体验和安全性。 第一部分:技术…...
GZ035 5G组网与运维赛题第6套
2023年全国职业院校技能大赛 GZ035 5G组网与运维赛项(高职组) 赛题第6套 一、竞赛须知 1.竞赛内容分布 竞赛模块1--5G公共网络规划部署与开通(35分) 子任务1:5G公共网络部署与调试(15分) …...

分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matla…...

【Qt】QString怎么转成int
2023年10月29日,周日晚上 第一种方法 这种方法会尝试将 QString 对象转换为 int 类型。如果转换成功,将返回转换后的 int 值;如果转换失败(例如,字符串中包含非数字字符),则返回 0。 QString…...

ubuntu 22.04 安装python-pcl
ubuntu 22.04 安装python-pcl 安装python-pcl修复bug 由于python-pcl库基本已经停止维护,所以Ubuntu22.04 在使用pip install python-pcl安装的时候会出现版本不适配的原因 安装python-pcl 使用Ubuntu22系统自带python3安装python-pcl,随后将下载的包拷…...

【题解】[GenshinOI Round 3 ]P9817 lmxcslD
题目传送门 分析 看到这道题我一开始是有点懵的,但是看了看数据范围,发现有几个点有 n 为质数 的特殊性质,结论先行,大胆猜测是不是可以贪心,所以先打了一个最傻的代码上去试试. void solve(){cin >> n >&…...
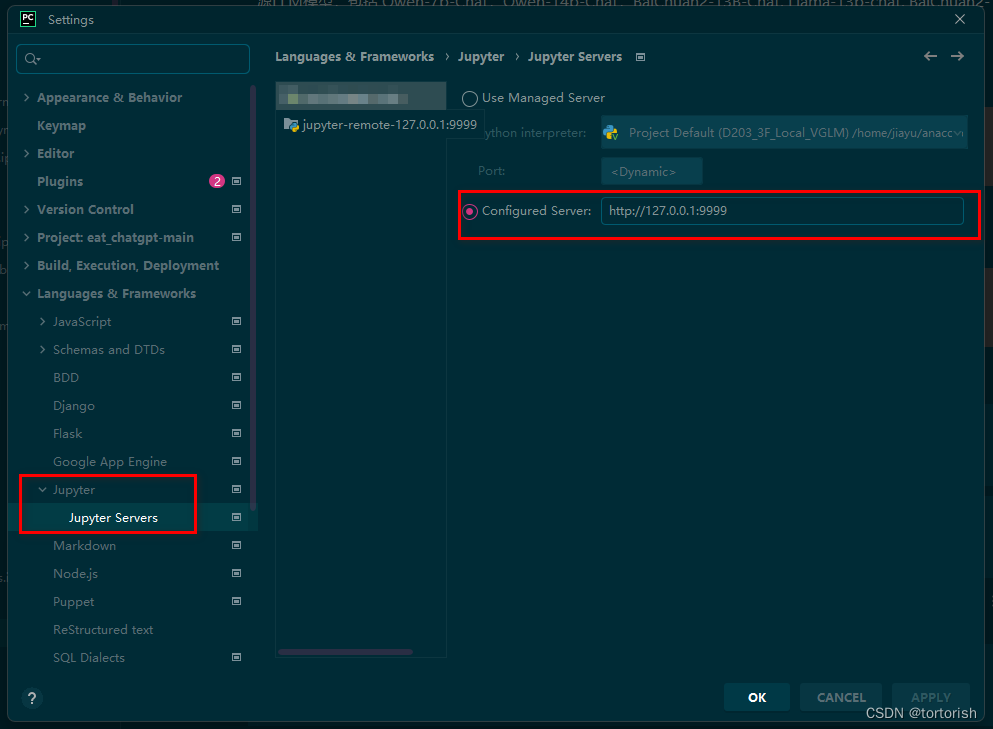
在pycharm中,远程操作服务器上的jupyter notebook
一、使用场景 现在我们有两台电脑,一台是拥有高算力的服务器,另一台是普通的轻薄笔记本电脑。如何在服务器上运行jupyter notebook,同时映射到笔记本电脑上的pycharm客户端中进行操作呢? 二、软件 pycharm专业版,jupy…...

SQL 运算符
SQL 运算符 运算符是保留字或主要用于 SQL 语句的 WHERE 子句中的字符,用于执行操作,例如:比较和算术运算。 这些运算符用于指定 SQL 语句中的条件,并用作语句中多个条件的连词。 常见运算符有以下几种: 算术运算符比…...

中间件安全-CVE 复现K8sDockerJettyWebsphere漏洞复现
目录 服务攻防-中间件安全&CVE 复现&K8s&Docker&Jetty&Websphere中间件-K8s中间件-Jetty漏洞复现CVE-2021-28164-路径信息泄露漏洞CVE-2021-28169双重解码信息泄露漏洞CVE-2021-34429路径信息泄露漏洞 中间件-Docker漏洞复现守护程序 API 未经授权访问漏洞…...

系列九、什么是Spring bean
一、什么是Spring bean 一句话,被Spring容器管理的bean就是Spring bean。...

轻量封装WebGPU渲染系统示例<4>-CubeMap/天空盒(源码)
当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/version-1.01/src/voxgpu/sample/ImgCubeMap.ts 此示例渲染系统实现的特性: 1. 用户态与系统态隔离。 2. 高频调用与低频调用隔离。 3. 面向用户的易用性封装。 4. 渲染数据和渲染机制分离。 5. 用户…...

Linux 环境变量 二
目录 获取环境变量的后两种方法 环境变量具有全局属性 内建命令 和环境变量相关的命令 c语言访问地址 重新理解地址 地址空间 获取环境变量的后两种方法 main函数的第三个参数 :char* env[ ] 也是一个指针数组,我们可以把它的内容打印出来看看。 …...
Beyond Compare4 30天试用到期的解决办法
相信很多小伙伴都有在使用Beyond Compare 4软件,如果我们没有激活该软件,就只有30天的评估使用期,那么过了这30天后我们怎么继续使用呢?下面小编就来为大家介绍方法。 打开Beyond Compare4,提示已经超出30天试用期限制…...
sentinel规则持久化-规则同步nacos-最标准配置
官方参考文档: 动态规则扩展 alibaba/Sentinel Wiki GitHub 需要修改的代码如下: 为了便于后续版本集成nacos,简单讲一下集成思路 1.更改pom 修改sentinel-datasource-nacos的范围 将 <dependency><groupId>com.alibaba.c…...

【Linux】tail命令使用
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。 语法 tail [参数] [文件] tail命令 -Linux手册页 著者 由保罗鲁宾、大卫麦肯齐、伊恩兰斯泰勒和吉姆梅耶林撰写。 命令选项及作用 执行令 tail --help 执行命令结果 参…...

【数据结构】面试OJ题——时间复杂度2
目录 一:移除元素 思路: 二:删除有序数组中的重复项 思路: 三:合并两个有序数组 思路1: 什么?你不知道qsort() 思路2: 一:移除元素 27. 移…...
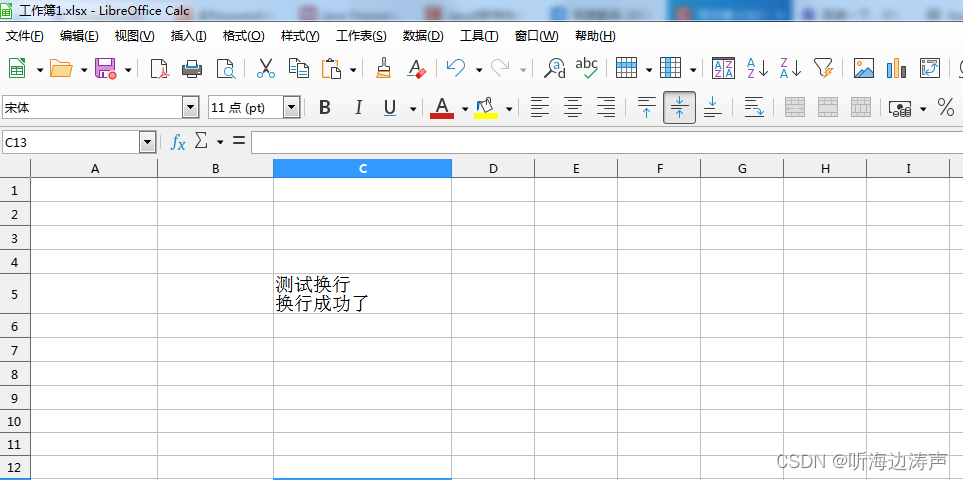
LibreOffice编辑excel文档如何在单元格中输入手动换行符
用WPS编辑excel文档的时候,要在单元格中输入手动换行符,可以先按住Alt键,然后回车。 而用LibreOffice编辑excel文档,要在单元格中输入手动换行符,可以先按住Ctrl键,然后回车。例如:...
ideaSSM在线商务管理系统VS开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 SSM 在线商务管理系统是一套完善的信息管理系统,结合SSM框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码 和数据库,系统主…...

重塑AI代理的数据智能:Wren AI如何构建开放上下文层
重塑AI代理的数据智能:Wren AI如何构建开放上下文层 【免费下载链接】WrenAI Turn any AI Agents into world-class data analysts through the open context layer that gives AI agents grounded, governed memory, context, SQL across 20 data sources, that he…...

如何让老款Mac重获新生:OpenCore Legacy Patcher完全指南
如何让老款Mac重获新生:OpenCore Legacy Patcher完全指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为苹果官方停止支持的老款Mac无法升…...

N_m3u8DL-CLI-SimpleG:一键下载M3U8视频的终极图形界面工具
N_m3u8DL-CLI-SimpleG:一键下载M3U8视频的终极图形界面工具 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 你是否曾经想要保存在线视频却因为复杂的M3U8格式而束手无…...

java springboot-vue的婚庆服务平台的功能设计
目录同行可拿货,招校园代理 ,本人源头供货商功能模块设计技术架构亮点特色创新点项目定位项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 功能模块设计 后端&am…...

短信验证码5大常见漏洞与防御实战
1. 这不是“绕过”,而是对验证码机制的深度体检你有没有遇到过这样的场景:在测试一个新上线的注册流程时,输入手机号、点击“获取验证码”,页面立刻弹出“验证码已发送成功”,但手机却迟迟没收到短信;再点一…...

淮南家长必看:淮南哪里学少儿编程靠谱?原来这样选才不踩坑。
说实话,很多淮南家长送孩子学编程,心里是没底的。因为编程不像钢琴、画画,能当场弹一首或画一张给你看。孩子到底学了啥、学得怎么样,家长往往两眼一抹黑。今天我不推荐任何一家机构,只跟你分享三个普通人一眼就能看懂…...

数据结构——带懒标记的线段树
一、什么是线段树?线段树是一种二叉树数据结构,用于高效地处理区间查询和区间更新操作。核心思想:将数组分成若干个区间(线段),每个节点代表一个区间,通过合并子节点的信息来得到父节点的信息。…...

CANN-ATB多卡推理-昇腾NPU上Llama70B怎么切到8张卡
CANN-ATB多卡推理-昇腾NPU上Llama70B怎么切到8张卡 Llama2-70B 的权重 140GB,单张 Atlas 800I A2 的 64GB 显存放不下。ATB 的多卡推理用 Tensor Parallel 把模型切到多张 NPU 上,每张卡只存 1/N 的权重和 KV Cache。 Tensor Parallel 的切法 Llama2-70B…...
)
别再手搓动画了!用PS搞定微信小程序GIF单次播放(附2022版安装包)
微信小程序GIF动画高效制作指南:从PS设计到开发落地全流程 在微信小程序开发中,动画效果的实现往往让开发者陷入两难选择:要么花费大量时间手写Canvas动画代码,要么寻找更高效的视觉呈现方案。当遇到需要精确控制播放次数的动画需…...

广州市认定广东专利奖的条件有哪些?如何准备广东专利奖申报?
一、奖项设置与省级奖励标准广东专利奖设四类奖项,省级直接奖励标准如下:广东专利金奖:不超过20项,每项30万元广东专利银奖:不超过40项,每项20万元广东专利优秀奖:不超过60项,每项10…...