云服务器安装Hbase
文章目录
- 1. HBase安装部署
- 2.HBase服务的启动
- 3.HBase部署高可用(可选)
- 4. HBase整合Phoenix
- 4.1 安装Phoenix
- 4.2 **Phoenix Shell** 操作
- 4.3 表的映射
- 4.4 Phoenix二级索引
- 4.4.1 全局索引(global index)
- 4.4.2 包含索引(covered index)
- 4.4.3 本地索引(local index)
- 5. HBase和Hive集成
1. HBase安装部署
-
集群配置
s1 s2 s3 s4 gracal HBase HMaster HRegionServer HRegionServer HMaster(备用) HRegionServer HRegionServer HRegionServer -
保证Zookeeper以及Hadoop处于部署并且正常启动的状态
#脚本启动hadoop myhadoop.sh start #脚本启动Zookeeper zk.sh start -
解压HBase安装包到/opt/module目录
-
配置环境变量并分发
[gaochuchu@s1 module]$ sudo vim /etc/profile.d/my_env.sh #HBASE_HOME export HBASE_HOME=/opt/module/hbase-2.4.11 export PATH=$PATH:$HBASE_HOME/bin -
修改配置文件hbase-env.sh
[gaochuchu@s1 conf]$ cd /opt/module/hbase-2.4.11/conf [gaochuchu@s1 conf]$ vim hbase-env.sh export HBASE_MANAGES_ZK=false其最后添加:export HBASE_MANAGES_ZK=false;关闭由HBase管理自身的Zookeeper实例
-
修改base-site.xml内容:
[gaochuchu@s1 conf]$ vim hbase-site.xml <property><name>hbase.zookeeper.quorum</name><value>s1,s2,s3,s4,gracal</value><description>The directory shared by RegionServers.</description></property> <!-- <property>--> <!-- <name>hbase.zookeeper.property.dataDir</name>--> <!-- <value>/export/zookeeper</value>--> <!-- <description> 记得修改 ZK 的配置文件 --> <!-- ZK 的信息不能保存到临时文件夹--> <!-- </description>--> <!-- </property>--><property><name>hbase.rootdir</name><value>hdfs://s1:8020/hbase</value><description>The directory shared by RegionServers.</description></property><property><name>hbase.cluster.distributed</name><value>true</value></property> -
配置RegionServers
[gaochuchu@s1 conf]$ vim regionservers s1 s2 s3 s4 gracal -
解决HBase和Hadoop的log4j兼容性问题,修改HBase的jar包,使用Hadoop的jar包
[gaochuchu@s1 conf]$ mv /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase-2.4.11/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak -
分发HBase
2.HBase服务的启动
-
单点启动和停止
[gaochuchu@s1 hbase-2.4.11]$ bin/hbase-daemon.sh start master [gaochuchu@s1 hbase-2.4.11]$ bin/hbase-daemon.sh start regionserver -
群启和停止(推荐)
[gaochuchu@s1 hbase-2.4.11]$ bin/start-hbase.sh [gaochuchu@s1 hbase-2.4.11]$ bin/stop-hbase.sh -
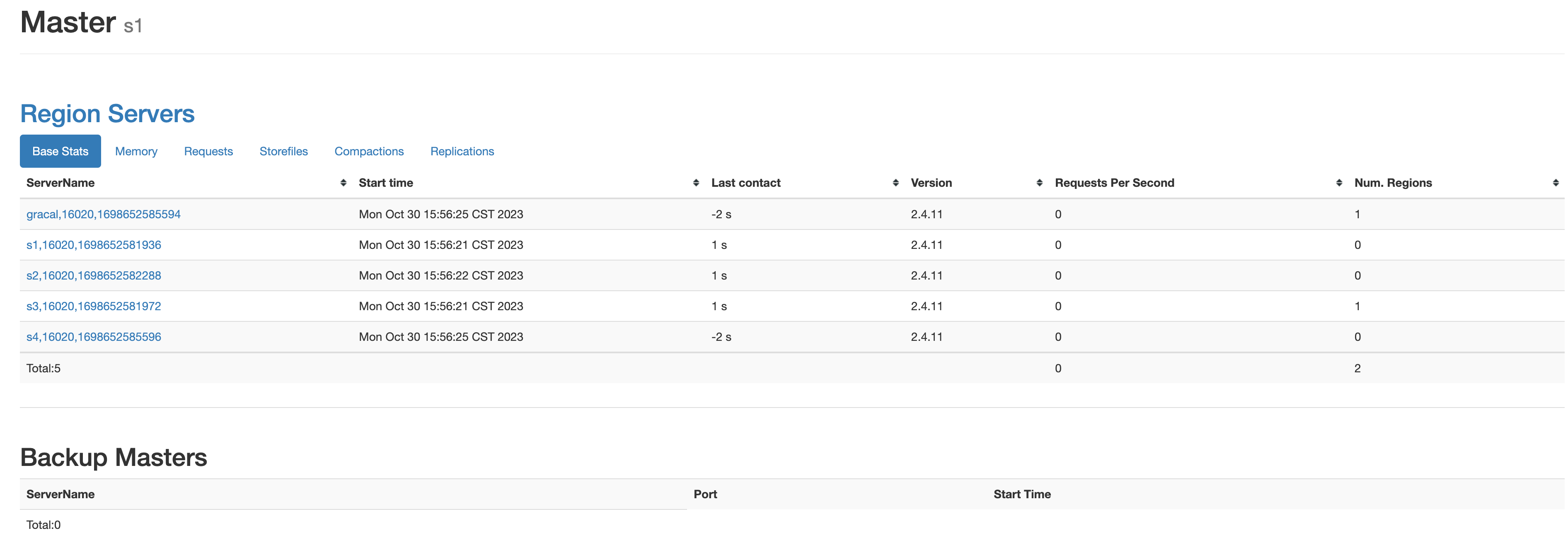
查看HBase的Web页面
启动成功后,通过访问http://s1:16010查看HBase的管理页面
3.HBase部署高可用(可选)
-
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载,如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
#conf目录下创建backup-masters文件 [gaochuchu@s1 hbase-2.4.11]$ touch conf/backup-masters #在backup-masters文件配置高可用节点 [gaochuchu@s1 hbase-2.4.11]$ vim conf/backup-masters s3 #将conf目录分发 [gaochuchu@s1 conf]$ xsync backup-masters -
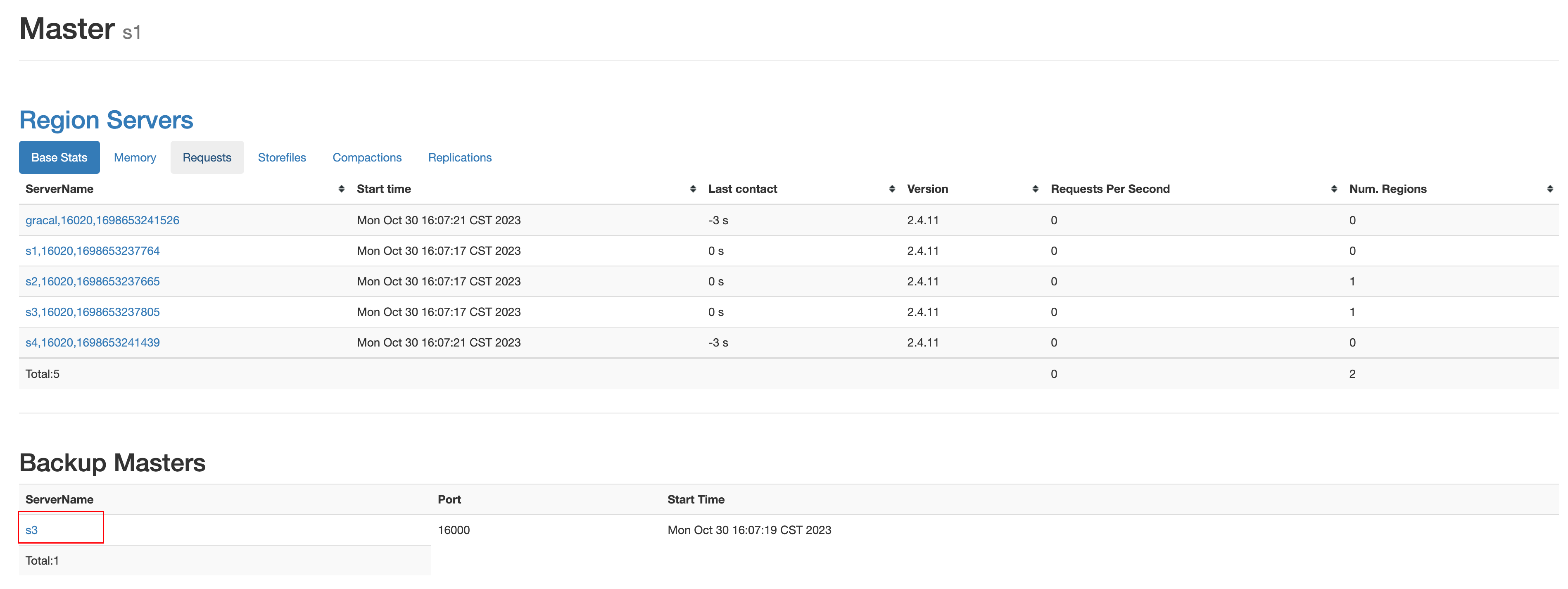
此时重新启动HBase,访问http://s1:16010,可以看到多了备用master节点
4. HBase整合Phoenix
- Phoenix 是 HBase 的开源 SQL 皮肤。可以使用标准 JDBC API 代替 HBase 客户端 API来创建表,插入数据和查询 HBase 数据
- 为什么使用Phoenix
- 官方给的解释为:在 Client 和 HBase 之间放一个 Phoenix 中间层不会减慢速度,因为用户编写的数据处理代码和 Phoenix 编写的没有区别,不仅如此Phoenix 对于用户输入的 SQL 同样会有大量的优化手段(就像 hive 自带 sql 优化器一样)。
- 其能将用户编写的SQL语句改写为HBase的API
4.1 安装Phoenix
-
安装Phoenix
#上传并解压Phoenix安装包到/opt/module [gaochuchu@s1 softs]$ tar -zxvf phoenix-hbase-2.4-5.1.2-bin.tar.gz -C /opt/module/ #改名为phoenix [gaochuchu@s1 module]$ mvphoenix-hbase-2.4-5.1.2-bin/ phoenix #复制phoenix的server包并且拷贝到各个节点中 [gaochuchu@s1 phoenix]$ cp phoenix-server-hbase-2.4-5.1.2.jar /opt/module/hbase-2.4.11/lib/ [gaochuchu@s1 phoenix]$ xsync /opt/module/hbase-2.4.11/lib/phoenix-server-hbase-2.4-5.1.2.jar #配置环境变量 [gaochuchu@s1 module]$ sudo vim /etc/profile.d/my_env.sh #phoenix export PHOENIX_HOME=/opt/module/phoenix export PHOENIX_CLASSPATH=$PHOENIX_HOME export PATH=$PATH:$PHOENIX_HOME/bin [gaochuchu@s1 module]$ source /etc/profile #重启HBase [gaochuchu@s1 module]$ stop-hbase.sh [gaochuchu@s1 module]$ start-hbase.sh -
连接Phoenix
[gaochuchu@s1 phoenix]$ bin/sqlline.py s1,s2,s3,s4,gracal:2181
4.2 Phoenix Shell 操作
-
显示表
0: jdbc:phoenix:s1,s2,s3,s4,gracal:2181> !table 0: jdbc:phoenix:s1,s2,s3,s4,gracal:2181> !tables -
创建表:直接指定单个列作为RowKey,相当于sql中的主键
CREATE TABLE IF NOT EXISTS student( id VARCHAR primary key, name VARCHAR, age BIGINT, addr VARCHAR);在 phoenix 中,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
执行上述语句,查看表,发现表名为大写

-
创建表:直接指定多个列的联合为RowKey
CREATE TABLE IF NOT EXISTS student1 ( id VARCHAR NOT NULL, name VARCHAR NOT NULL, age BIGINT, addr VARCHAR CONSTRAINT my_pk PRIMARY KEY (id, name));-
注:Phoenix 中建表,会在 HBase 中创建一张对应的表。为了减少数据对磁盘空间的占用,Phoenix 默认会对 HBase 中的列名做编码处理。具体规则可参考官网链接:https://phoenix.apache.org/columnencoding.html,若不想对列名编码,可在建表语句末尾加上 COLUMN_ENCODED_BYTES = 0;
-
可以看到,这里的列名没有显示对应的string,而是做了编码处理

-
-
插入数据
upsert into student values('1001','gcc', 23, 'changsha'); -
查询记录
select * from student; select * from student where id='1001'; -
删除记录
delete from student where id='1001'; -
删除表
drop table student; -
退出命令行
!quit
4.3 表的映射
-
表的关系
默认情况下, HBase 中已存在的表,通过 Phoenix 是不可见的。如果要在 Phoenix 中操作 HBase 中已存在的表,可以在 Phoenix 中进行表的映射。映射方式有两种:视图映射和表映射
-
在HBase的shell命令行创建test表格
RowKey info1 info2 Id name Address create 'test','info1','info2'put 'test','1001','info1:name','gcc'put 'test','1001','info1:address','changsha' -
视图映射
Phoenix 创建的视图是只读的,所以只能用来做查询,无法通过视图对数据进行修改等操作,即删除视图对原数据无影响。在 phoenix 中创建关联 test 表的视图
#创建视图 create view "test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar); #查看视图,小写的表名需要加双引号 select * from "test"; #删除视图,小写的表名需要加双引号 drop view "test"; -
表映射
在 Pheonix 创建表去映射 HBase 中已经存在的表,是可以修改删除 HBase 中已经存在的数据的。而且,删除 Phoenix 中的表,那么 HBase 中被映射的表也会被删除。
特别注意:进行表映射时,不能使用列名编码,需将 column_encoded_bytes 设为 0。因为编码会导致Pheonix的表无法和HBase映射
create table"test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar)column_encoded_bytes=0; -
关于数字类型说明
HBase 中的数字,底层存储为补码,而 Phoenix 中的数字,底层存储为在补码的基础上,将符号位反转。故当在 Phoenix 中建表去映射 HBase 中已存在的表,当 HBase 中有数字类型的字段时,会出现解析错误的现象。
常见的解决方案:
- Phoenix 种提供了 unsigned_int,unsigned_long 等无符号类型,其对数字的编码解码方式和 HBase 是相同的,如果无需考虑负数,那在 Phoenix 中建表时采用无符号类型是最合适的选择。
- 如需考虑负数的情况,则可通过 Phoenix 自定义函数,将数字类型的最高位,即符号位反转即可,自定义函数可参考如下链接:https://phoenix.apache.org/udf.html
-
4.4 Phoenix二级索引
-
HBase是没有二级索引的概念的,利用Phoenix中间层,可以为其建立二级索引
-
需要添加如下配置到HBase的HRegionServer节点的hbase-site.xml
[gaochuchu@s1 hbase-2.4.11]$ vim conf/hbase-site.xml <!-- phoenix regionserver 配置参数--> <property><name>hbase.regionserver.wal.codec</name> <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value> </property> [gaochuchu@s1 hbase-2.4.11]$ xsync conf/hbase-site.xml #Hbase重启 [gaochuchu@s1 hbase-2.4.11]$ stop-hbase.sh [gaochuchu@s1 hbase-2.4.11]$ start-hbase.sh
4.4.1 全局索引(global index)
-
Global Index 是默认的索引格式,创建全局索引时,会在 HBase 中建立一张新表。也就是说索引数据和数据表是存放在不同的表中的,因此全局索引适用于多读少写的业务场景。写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗
-
在读数据的时候 Phoenix 会选择索引表来降低查询消耗的时间。
-
创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);-
举例
create index my_index on student1(age);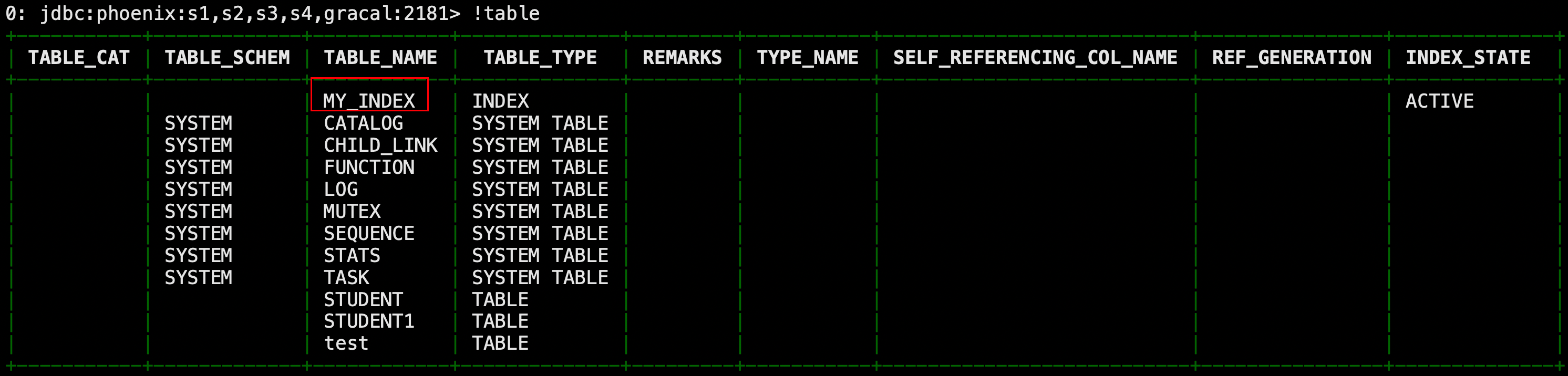
-
此时创建了MY_INDEX的单独的索引表,保存相关的索引信息
-
-
查看二级索引是否有效:执行explainPlan计划,有二级索引会变为范围扫描
explain select id,name from student1 where age = 10;
注意:如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
explain select id,name,addr from student1 where age = 10;
因为id,name是主键构成的联合索引,age是全局索引,addr不是索引,因此这时候查询是全表扫描
-
删除索引
DROP INDEX my_index ON my_table-
举例
drop index my_index on student1;
-
4.4.2 包含索引(covered index)
-
创建携带其他字段的全局索引(本质还是全局索引)。
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);-
举例
create index my_index on student1(age) include (addr); -
此时我们仍运行4.4.1中原本走全表扫描的例子
explain select id,name,addr from student1 where age = 10;
此时走了范围查询,因为age为全局索引,其携带了addr字段
-
4.4.3 本地索引(local index)
-
Local Index 适用于写操作频繁的场景。索引数据和数据表的数据是存放在同一张表中(且是同一个 Region),避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。
CREATE LOCAL INDEX my_index ON my_table (my_column); #其中my_column可以是多个,类似于组合索引本地索引会将所有的信息存在一个影子列族中,虽然读取的时候也是范围扫描,但是没有全局索引快,优点在于不用写多个表了。
-
举例
0: jdbc:phoenix:s1,s2,s3,s4,gracal:2181> drop index my_index on student1; CREATE LOCAL INDEX my_index ON student1 (age,addr); -
此时我们执行执行计划
explain select id,name,addr from student1 where age = 10;
-
5. HBase和Hive集成
-
如果大量的数据已经存放在 HBase 上面,需要对已经存在的数据进行数据分析处理,那么 Phoenix 并不适合做特别复杂的 SQL 处理,此时可以使用 hive 映射 HBase 的表格,之后写 HQL 进行分析处理。
-
在hive-site.xml中添加zookeeper的属性:
[gaochuchu@s1 conf]$ vim hive-site.xml <property><name>hive.zookeeper.quorum</name><value>s1,s2,s4,s4,gracal</value> </property> <property><name>hive.zookeeper.client.port</name><value>2181</value> </property> #启动Hive客户端 [gaochuchu@s1 hive-3.1.2]$ hive -
实例1
-
目标:建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
-
在Hive中创建表同时关联HBase
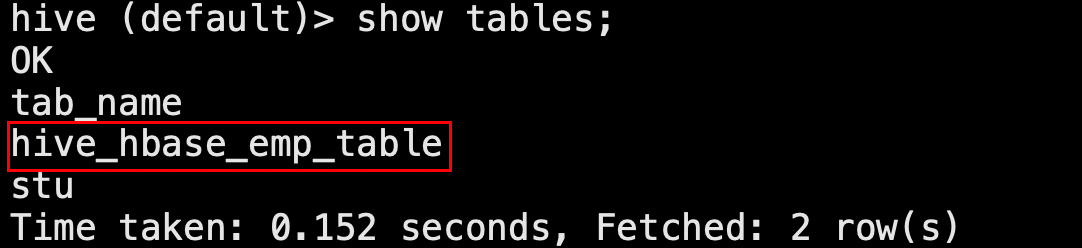
CREATE TABLE hive_hbase_emp_table(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int )STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");此时在Hive中出现这个表:
同时在Hbase中也出现了这个表:

-
在Hive中创建临时中间表,用于load文件中的数据
注意不能将数据直接load进Hive所关联HBase的那张表中,因为创建的Hive表格和HBase关联,结构比较复杂
CREATE TABLE emp(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int ) row format delimited fields terminated by '\t'; -
向Hive临时表中load 数据
hive> load data local inpath '/opt/softs/emp.txt' into table emp; -
通过insert命令将中间表中的数据导入Hive关联的Hbase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp; -
查看Hive以及相关联的HBase表中是否已经成功同步插入了数据
hive> select * from hive_hbase_emp_table;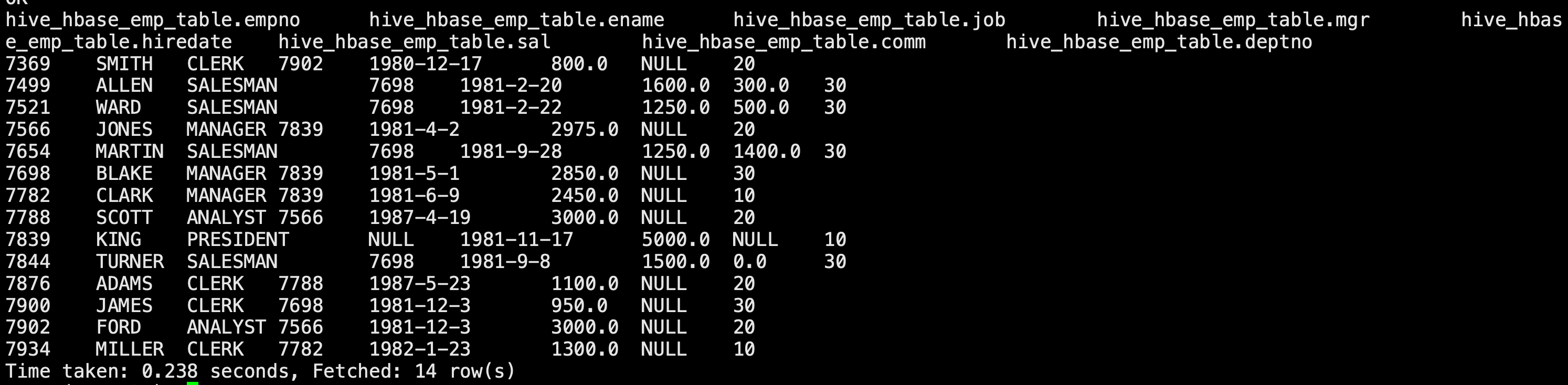
Hbase> scan 'hbase_emp_table'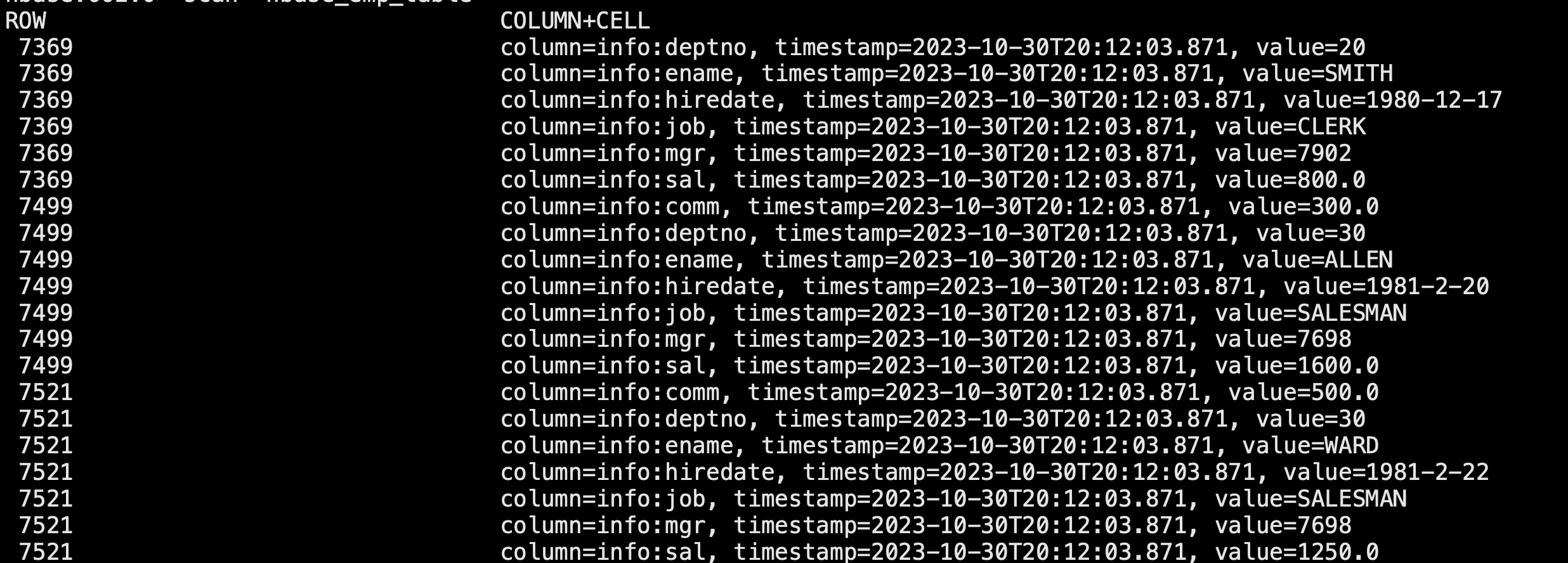
-
-
实例2
目标:在 HBase 中已经存储了某一张表 hbase_emp_table,然后在 Hive 中创建一个外部表来关联 HBase 中的 hbase_emp_table 这张表,使之可以借助 Hive 来分析 HBase 这张表中的数据。
-
Hive中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int )STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table"); -
关联后就可以使用Hive函数进行一些分析操作如
hive (default)> select deptno,avg(sal) monery from relevance_hbase_emp group by deptno ;
-
相关文章:
云服务器安装Hbase
文章目录 1. HBase安装部署2.HBase服务的启动3.HBase部署高可用(可选)4. HBase整合Phoenix4.1 安装Phoenix4.2 **Phoenix Shell** 操作4.3 表的映射4.4 Phoenix二级索引4.4.1 全局索引(global index)4.4.2 包含索引(covered index…...
黑豹程序员-架构师学习路线图-百科:PowerDesigner数据库建模的行业标准
PowerDesigner最初由Xiao-Yun Wang(王晓昀)在SDP Technologies公司开发完成。 目前PowerDesigner是Sybase的企业建模和设计解决方案,采用模型驱动方法,将业务与IT结合起来,可帮助部署有效的企业体系架构,并…...
)
Iterator 和 ListIterator 的区别(简要说明)
Iterator 和 ListIterator 的区别 ListIterator有add()方法,可以向List中添加对象,而Iterator不能 ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法&am…...

TypeScript - 函数 - 剩余参数
什么是剩余参数 剩余参数就是 一个数组。剩余参数有什么注意事项 剩余参数必须放在所有参数的最后! 剩余参数必须放在所有参数的最后! 剩余参数必须放在所有参数的最后! 【无论是普通参数、可选参数、有默认值的参数,剩余参数都…...

Python之前端
标签的分类 1. 单标签img br hr <img /> 2. 双标签a h p div <a></a> 3. 按照标签属性分类1. 块儿标签# 自己独自占一行h1-h6 p div2. 行内(内联)标签# 自身文本有多大就占多大a span u i b s div标签和span标签 这两个标签它是没有任意意义的,主…...
iOS iGameGuardian修改器检测方案
一直以来,iOS 系统的安全性、稳定性都是其与安卓竞争的主力卖点。这要归功于 iOS 系统独特的闭源生态,应用软件上架会经过严格审核与测试。所以,iOS端的作弊手段,总是在尝试绕过 App Store 的审查。 常见的 iOS 游戏作弊…...

显示一个文件夹下所有图片的直方图之和
针对3D图像的,因为所有3D图像的2D切片都在一个文件夹里,所以要进行直方图各个像素值数量的累加。 import sys import cv2 import numpy as np import os, glob from skimage import data,io import matplotlib.pyplot as plt np.set_printoptions(thres…...
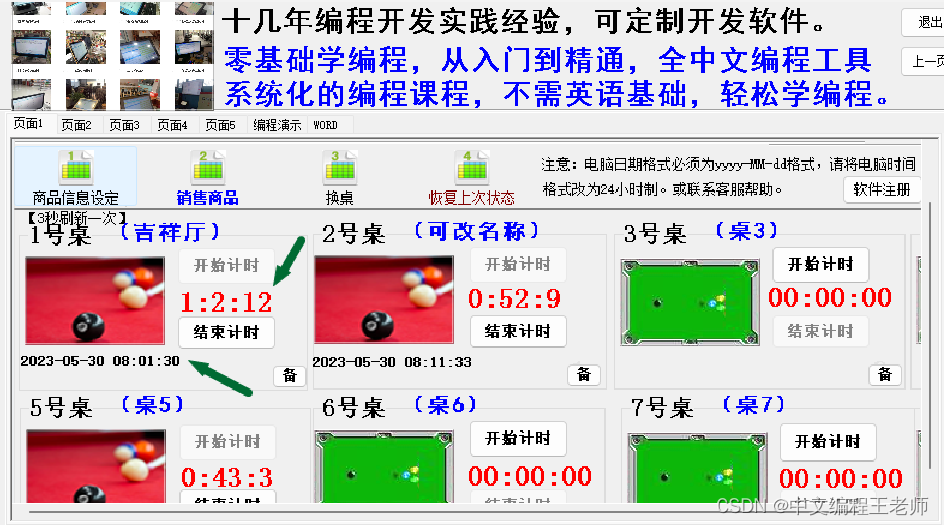
编程实例:操作简单的台球计时计费软件推荐,可以连接灯控硬件设备以及灯控器布线图编程
编程实例:操作简单的台球计时计费软件推荐,可以连接灯控硬件设备以及灯控器布线图编程 1、计时计费功能 :开台时间和所用的时长直观显示,每3秒即可刷新一次时间。 2、销售商品功能 :商品可以绑定桌子最后一起结账&…...
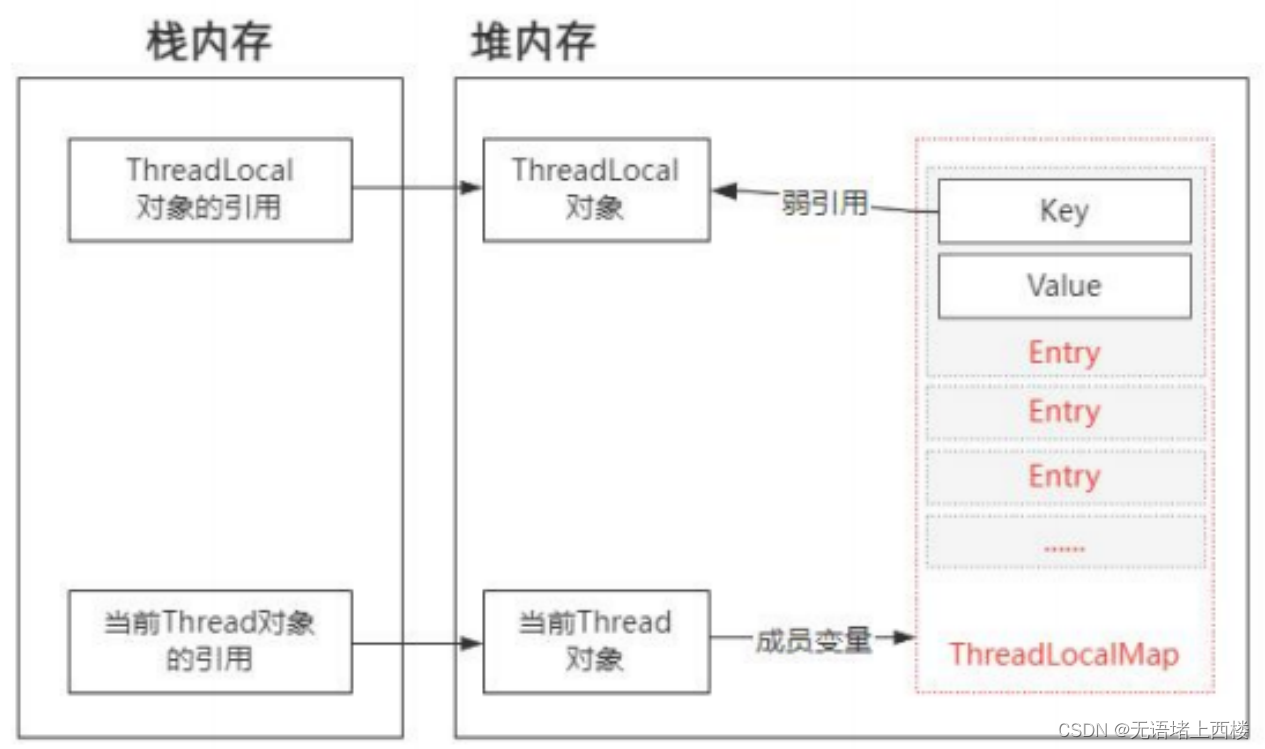
ThreadLocal 会出现内存泄漏吗?
ThreadLocal ThreadLocal 是一个用来解决线程安全性问题的工具。它相当于让每个线程都开辟一块内存空间,用来存储共享变量的副本。然后每个线程只需要访问和操作自己的共享变量副本即可,从而避免多线程竞争同一个共享资源。它的工作原理很简单࿰…...

Linux 下使用 Docker 安装 Redis
1、下载 redis docker pull redis:6.2.62、提前创建挂载目录 mkdir -p /mydata/redis/conf mkdir -p /mydata/redis/data mkdir -p /mydata/redis/log touch /mydata/redis/conf/redis.conf touch /mydata/redis/log/redis.log chmod 777 /mydata/redis/log/redis.log3、启动…...
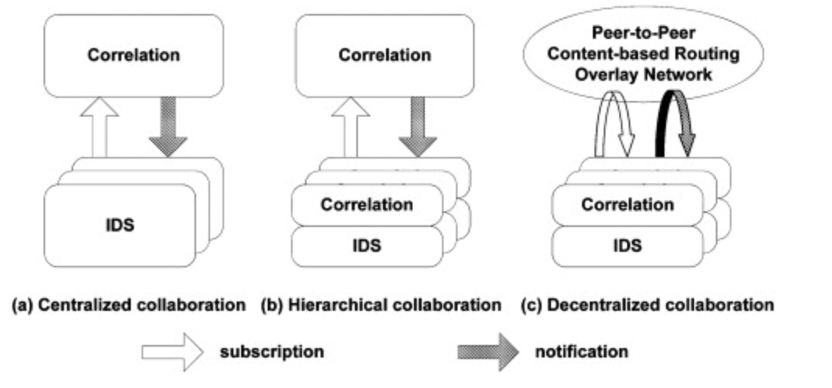
协同网络入侵检测CIDS
协同网络入侵检测CIDS 1、概念2、CIDS的分类3、解决办法4、CIDS模型5、挑战与不足 ⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计2598字,阅读大概需要3分钟 🌈更多学习内容&…...
PC端自动化测试-C#微信接收消息并自动回复)
(13)PC端自动化测试-C#微信接收消息并自动回复
本篇文章实现了微信自动接收最新的实时聊天信息,并对当前实时的聊天信息做出对应的回复。 可以自行接入人工智能或者结合自己的业务来做出自动回复。 下面视频是软件实际效果 自动接收消息并回复 实现的逻辑是实时监控微信的聊天面板中UI对象来判断是否有最新的消…...

企业金蝶KIS软件服务器中了locked勒索病毒怎么办,勒索病毒解密
最近一段时间,网络上的locked勒索病毒又开始了新一波的攻击,给企业的正常生产生活带来了严重影响。经过最近一段时间云天数据恢复中心对locked勒索病毒的解密,为大家整理了以下有关locked勒索病毒的相关信息。近期locked勒索病毒主要攻击金蝶…...

2023年阿里云双11优惠来了,单笔最高可省2400元!
2023年阿里云双11活动终于来了,阿里云推出了金秋云创季活动,新用户、老用户、企业用户均可领取金秋上云礼包,单笔最高立减2400元! 一、活动时间 满减券领取时间:2023年10月27日0点0分0秒-2023年11月30日23点59分59秒 …...

k8s资源调度
默认的情况下,一个pod在哪个node节点上运行,是由scheduler组件采取对应的算法计算出来的,这个过程是不受人工控制的,在实际的使用过程中,这不能够满足客观的场景,针对这样的情况,k8s 提供了四大…...
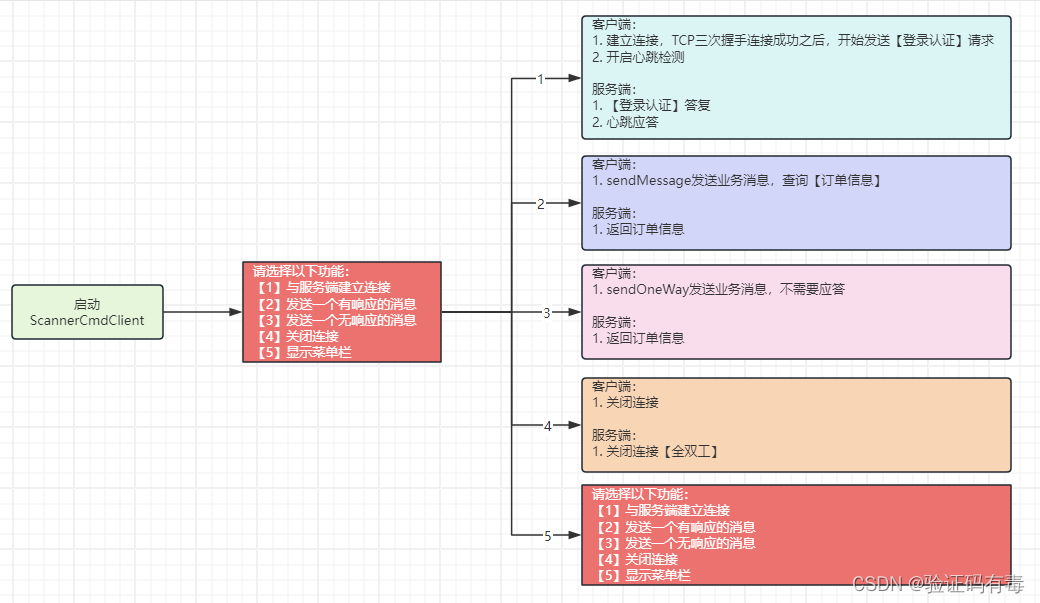
【Netty专题】用Netty手写一个远程长连接通信框架
目录 前言阅读对象阅读导航前置知识课程内容一、使用Netty实现一个通信框架需要考虑什么问题二、通信框架功能设计2.1 功能描述2.2 通信模型2.3 消息体定义2.4 心跳机制2.5 重连机制*2.6 Handler的组织顺序2.7 交互式调试 三、代码实现:非必要。感兴趣的自行查看3.1…...

注册商标被宣告为无效的5种情形
1.与已注册商标过于相似:商标法规定商标应具备独立性和显著性,能够与已注册商标有效区分开来。如果新申请商标与已注册商标过于相似,可能会导致商标无效。相似性包括外观形状、字母组合、发音或含义等方面的相似度。 2.缺乏独特性和显著性&am…...

C#在类中申明成员数组变量的格式
在C#中,在类中申明成员数组变量的格式如下: 访问修饰符 数据类型[] 变量名; 其中: 访问修饰符表示该成员变量的访问权限,可以是public、private、protected、internal等修饰符之一;数据类型表示数组元素的类型&…...

通俗易懂理解CNN卷积神经网络模型的参数量和计算量
一、参考资料 神经网络参数量、计算量(FLOPS)、内存访问量(MAC)计算详解 5种方法获取Torch网络模型参数量计算量等信息 二、参数量与计算量相关介绍 1. 为什么要统计模型参数量和计算量 好的网络模型不仅要求精度准࿰…...

npm工具使用方法介绍
npm 使用方法 文章目录 npm 使用方法安装 npm初始化项目安装依赖更新依赖卸载依赖发布包其他命令下载相关 npm 是 Node.js 的包管理工具,用于管理 Node.js 项目的依赖关系。npm 提供了丰富的命令和功能,可以帮助开发者快速构建和部署 Node.js 应用程序。…...
TranslateGemma高可用部署:健康检查、监控与自动恢复策略
TranslateGemma高可用部署:健康检查、监控与自动恢复策略 1. 为什么高可用部署对TranslateGemma至关重要 TranslateGemma作为企业级神经机器翻译系统,在生产环境中面临着724小时不间断服务的严苛要求。不同于开发测试环境,生产部署必须考虑…...

从数据孤岛到智能协作:DeerFlow如何重构AI研究范式
从数据孤岛到智能协作:DeerFlow如何重构AI研究范式 【免费下载链接】deer-flow DeerFlow is a community-driven framework for deep research, combining language models with tools like web search, crawling, and Python execution, while contributing back t…...

如何完整备份QQ空间历史说说:GetQzonehistory终极使用指南
如何完整备份QQ空间历史说说:GetQzonehistory终极使用指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 想要永久保存QQ空间里那些珍贵的青春记忆吗?GetQzoneh…...

突破难关:AI专著撰写工具应用技巧,助你快速著书立说
学术专著写作困境与AI工具的崛起 对许多研究人员来说,撰写学术专著最大的挑战,就是“有限的精力”与“无尽的需求”之间的矛盾。专著的写作过程通常需要三到五年,甚至更长的时间,而研究者们在日常工作中还要应对教学、研究项目和…...

RMBG-2.0场景应用:广告素材制作,快速分离主体与背景
RMBG-2.0场景应用:广告素材制作,快速分离主体与背景 1. 广告设计中的背景移除痛点 在广告设计领域,背景移除是最常见也最耗时的任务之一。设计师们经常面临这样的困境: 时间成本高:一张普通商品图手动抠图需要5-10分…...
)
别再让数据‘偏心’了:用Python给图像数据做零均值化预处理(以PyTorch为例)
别再让数据‘偏心’了:用Python给图像数据做零均值化预处理(以PyTorch为例) 当你第一次训练图像分类模型时,可能会遇到一个奇怪的现象:损失函数下降得特别慢,甚至反复震荡。这很可能是因为你的数据在"…...

如何突破硬件限制?探索SwiftShader的高性能图形渲染革命
如何突破硬件限制?探索SwiftShader的高性能图形渲染革命 【免费下载链接】swiftshader SwiftShader is a high-performance CPU-based implementation of the Vulkan graphics API. Its goal is to provide hardware independence for advanced 3D graphics. 项目…...

G-Helper:开源硬件控制工具的性能优化实践指南
G-Helper:开源硬件控制工具的性能优化实践指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址: http…...
)
三相逆变器LCL滤波设计实战:从建模到仿真避坑指南(附仿真文件)
三相逆变器LCL滤波设计实战:从建模到仿真避坑指南 在电力电子领域,三相逆变器的性能优化一直是工程师们关注的焦点。LCL滤波器作为逆变器与电网之间的关键接口,其设计质量直接影响系统稳定性、谐波抑制效果和电磁兼容性。本文将带您深入实战&…...

格式排版改到崩溃?高校教授说用这几个AI论文写作工具
论文写作总让人头大?格式排版改到崩溃、文献检索效率低、逻辑结构不清晰……这些痛点你是不是也遇到过?其实,只要用对 AI 工具、走对流程,就能事半功倍。资深教授建议,从选题到降重,全程使用专业工具辅助&a…...