pytorch 入门 (五)案例三:乳腺癌识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章
- 🍨 本文为🔗小白入门Pytorch中的学习记录博客
- 🍦 参考文章:【小白入门Pytorch】乳腺癌识别
- 🍖 原作者:K同学啊
在本案例中,我将带大家探索一下深度学习在医学领域的应用–完成乳腺癌识别,乳腺癌是女性最常见的癌症形式,浸润性导管癌 (IDC) 是最常见的乳腺癌形式。准确识别和分类乳腺癌亚型是一项重要的临床任务,利用深度学习方法识别可以有效节省时间并减少错误。 我们的数据集是由多张以 40 倍扫描的乳腺癌 (BCa) 标本的完整载玻片图像组成。
关于环境配置请看我之前缩写博客:https://blog.csdn.net/qq_33489955/article/details/132890434?spm=1001.2014.3001.5501
数据集:链接:https://pan.baidu.com/s/1xkqsqsRRwlBOl5L9t_U0UA?pwd=vgqn
提取码:vgqn
–来自百度网盘超级会员V4的分享
目录
- 一、 前期准备
- 1. 设置GPU
- 2. 导入数据
- 3. 划分数据集
- 二、手动搭建VGG-16模型
- 1. 搭建模型
- 2. 查看模型详情
- 三、 训练模型
- 1. 编写训练函数
- 3. 编写测试函数
- 3. 正式训练
- 四、 结果可视化
- 1. Loss与Accuracy图
- 2. 指定图片进行预测
- 3. 模型评估
一、 前期准备
import torchprint(torch.__version__) # 查看pytorch版本
2.0.1+cu118
1. 设置GPU
如果设备上支持GPU就使用GPU,否则使用CPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore") #忽略警告信息device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
2. 导入数据
import os,PIL,random,pathlibdata_dir = './data/2-data/'
data_dir = pathlib.Path(data_dir)
提问:已经有路径不是直接使用就可以了吗,为什么还要将其转化为路径对象。
回答:当我们使用传统的字符串来表示文件路径时,确实可以工作,但pathlib提供的对象方法对于文件路径的操作更为简洁和直观。
以下是使用pathlib的一些优点:
- 跨平台兼容性:
pathlib自动处理不同操作系统的路径分隔符问题。例如,Windows使用\,而Unix和Mac使用/。使用pathlib,你不需要关心这些细节。 - 链式操作:你可以方便地使用链式方法来处理路径。例如,
path.parent返回父目录,path.stem返回文件的基本名称(不带扩展名)等。 - 读写简便:
pathlib.Path对象有read_text(),write_text(),read_bytes(), 和write_bytes()等方法,可以直接读写文件,而无需再使用open函数。 - 创建和删除目录:使用
pathlib, 你可以很容易地创建 (mkdir()) 或删除 (rmdir()) 目录。
以下是一个简单的例子来比较两者:
使用传统的os模块:
import os
file_path = os.path.join("folder1", "folder2", "myfile.txt")
使用pathlib:
from pathlib import Path
file_path = Path("folder1") / "folder2" / "myfile.txt"
所以,虽然直接使用字符串路径是可以的,但使用pathlib可以使代码更加简洁、可读和跨平台兼容。
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])test_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
total_data
Dataset ImageFolderNumber of datapoints: 13403Root location: data\2-dataStandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=warn)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
total_data.class_to_idx
{'0': 0, '1': 1}
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
(<torch.utils.data.dataset.Subset at 0x14191aec850>,<torch.utils.data.dataset.Subset at 0x141c3e693d0>)
batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=8)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=8)
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
提问:为什么结果只输出一次,是因为测试数据集只有一个批次,即32张图片吗
回答:不,结果只输出一次是因为您的代码中包含了一个 break 语句。这个 break 会在第一次迭代后立即退出 for 循环,因此您只看到了第一个批次的输出。
如果您想确认 test_dl 中有多少批次,您可以尝试以下代码:
num_batches = len(test_dl)
print("Number of batches in test_dl:", num_batches)
这将告诉您 test_dl 中有多少个批次。如果这个数字是1,那么确实只有32张图片。但是,如果这个数字大于1,那么 test_dl 会包含更多的图片。每个批次都有32张图片(除了可能的最后一个批次,它可能包含少于32张图片,取决于数据集的总数)。
二、手动搭建VGG-16模型
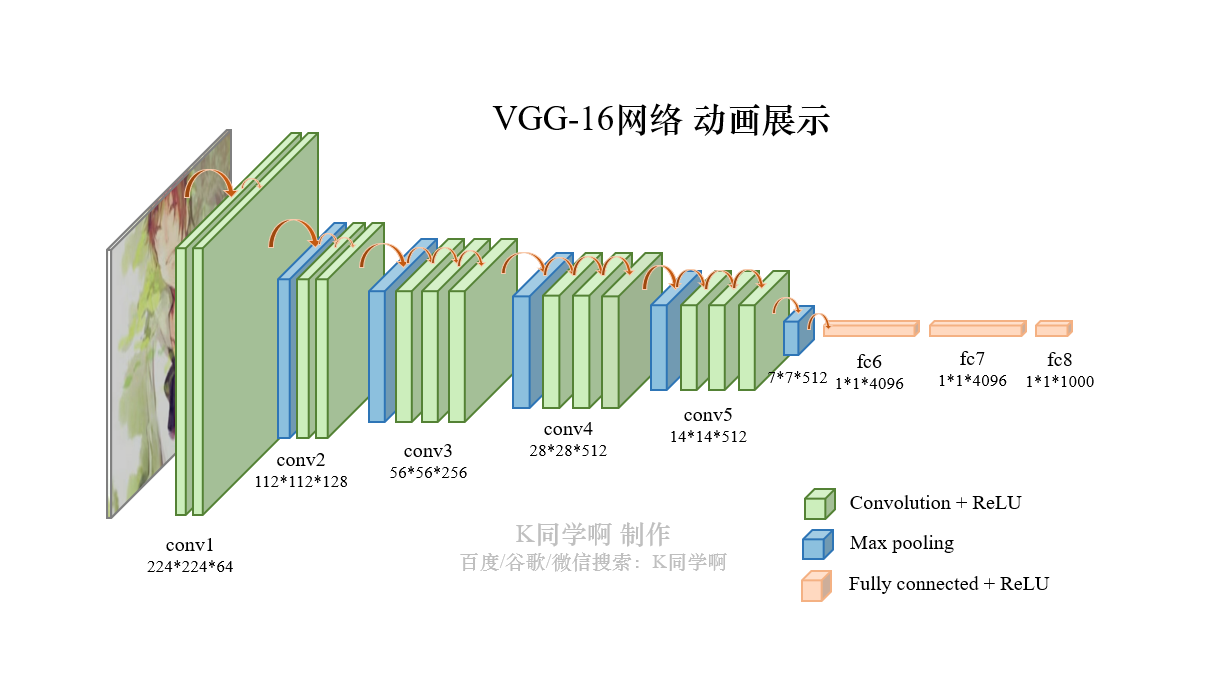
VGG-16结构说明:
- 13个卷积层(Convolutional Layer),分别用
blockX_convX表示; - 3个全连接层(Fully connected Layer),用
classifier表示; - 5个池化层(Pool layer)。
VGG-16包含了16个隐藏层(13个卷积层和3个全连接层),故称为VGG-16
1. 搭建模型
import torch.nn.functional as Fclass vgg16(nn.Module):def __init__(self):super(vgg16, self).__init__()# 卷积块1self.block1 = nn.Sequential( # # 这定义了一个名为block1的属性。nn.Sequential是一个容器,它按照它们被添加到容器中的顺序执行其中的层或操作。nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), # 这添加了一个2D卷积层。它接受3个通道的输入(例如RGB图像),并产生64个通道的输出。它使用3x3的卷积核,步长为1,和1的填充。nn.ReLU(), # 这添加了一个ReLU激活函数。它将所有的负值变为0,其他值保持不变。nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), # 这是另一个2D卷积层。它接受上一个卷积层的64个通道的输出,并产生64个通道的输出。nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)) # # 这添加了一个2D最大池化层。它使用2x2的窗口和2的步长来减少每个通道的尺寸的一半。)# 卷积块2self.block2 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 卷积块3self.block3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 卷积块4self.block4 = nn.Sequential(nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 卷积块5self.block5 = nn.Sequential(nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),nn.ReLU(),nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)))# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=512*7*7, out_features=4096),nn.ReLU(),nn.Linear(in_features=4096, out_features=4096),nn.ReLU(),nn.Linear(in_features=4096, out_features=2))def forward(self, x):x = self.block1(x)x = self.block2(x)x = self.block3(x)x = self.block4(x)x = self.block5(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = vgg16().to(device)
model
Using cuda device
vgg16((block1): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block2): Sequential((0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block3): Sequential((0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(5): ReLU()(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block4): Sequential((0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(5): ReLU()(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(block5): Sequential((0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(5): ReLU()(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU()(2): Linear(in_features=4096, out_features=4096, bias=True)(3): ReLU()(4): Linear(in_features=4096, out_features=2, bias=True))
)
2. 查看模型详情
!pip install torchsummary
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: torchsummary in c:\users\cheng\appdata\roaming\python\python310\site-packages (1.5.1)
# 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 224, 224] 1,792ReLU-2 [-1, 64, 224, 224] 0Conv2d-3 [-1, 64, 224, 224] 36,928ReLU-4 [-1, 64, 224, 224] 0MaxPool2d-5 [-1, 64, 112, 112] 0Conv2d-6 [-1, 128, 112, 112] 73,856ReLU-7 [-1, 128, 112, 112] 0Conv2d-8 [-1, 128, 112, 112] 147,584ReLU-9 [-1, 128, 112, 112] 0MaxPool2d-10 [-1, 128, 56, 56] 0Conv2d-11 [-1, 256, 56, 56] 295,168ReLU-12 [-1, 256, 56, 56] 0Conv2d-13 [-1, 256, 56, 56] 590,080ReLU-14 [-1, 256, 56, 56] 0Conv2d-15 [-1, 256, 56, 56] 590,080ReLU-16 [-1, 256, 56, 56] 0MaxPool2d-17 [-1, 256, 28, 28] 0Conv2d-18 [-1, 512, 28, 28] 1,180,160ReLU-19 [-1, 512, 28, 28] 0Conv2d-20 [-1, 512, 28, 28] 2,359,808ReLU-21 [-1, 512, 28, 28] 0Conv2d-22 [-1, 512, 28, 28] 2,359,808ReLU-23 [-1, 512, 28, 28] 0MaxPool2d-24 [-1, 512, 14, 14] 0Conv2d-25 [-1, 512, 14, 14] 2,359,808ReLU-26 [-1, 512, 14, 14] 0Conv2d-27 [-1, 512, 14, 14] 2,359,808ReLU-28 [-1, 512, 14, 14] 0Conv2d-29 [-1, 512, 14, 14] 2,359,808ReLU-30 [-1, 512, 14, 14] 0MaxPool2d-31 [-1, 512, 7, 7] 0Linear-32 [-1, 4096] 102,764,544ReLU-33 [-1, 4096] 0Linear-34 [-1, 4096] 16,781,312ReLU-35 [-1, 4096] 0Linear-36 [-1, 2] 8,194
================================================================
Total params: 134,268,738
Trainable params: 134,268,738
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.52
Params size (MB): 512.19
Estimated Total Size (MB): 731.29
----------------------------------------------------------------
三、 训练模型
1. 编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
3. 编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
3. 正式训练
1. model.train()
model.train()的作用是启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
2. model.eval()
model.eval()的作用是不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
import copyoptimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数epochs = 10train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)print('Done')
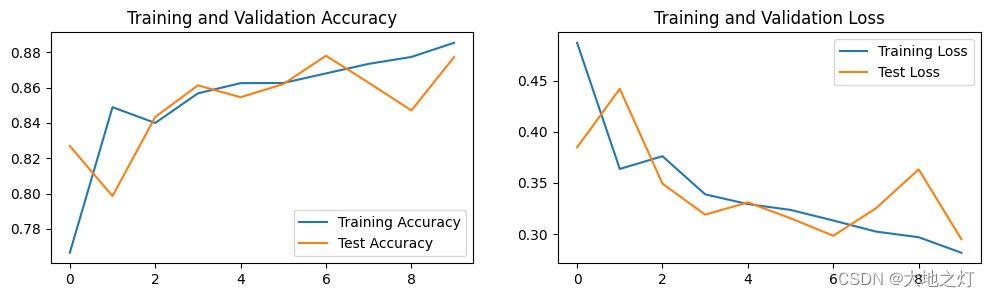
Epoch: 1, Train_acc:76.6%, Train_loss:0.487, Test_acc:82.7%, Test_loss:0.385, Lr:1.00E-04
Epoch: 2, Train_acc:84.9%, Train_loss:0.364, Test_acc:79.9%, Test_loss:0.442, Lr:1.00E-04
Epoch: 3, Train_acc:84.0%, Train_loss:0.376, Test_acc:84.3%, Test_loss:0.349, Lr:1.00E-04
Epoch: 4, Train_acc:85.7%, Train_loss:0.339, Test_acc:86.1%, Test_loss:0.319, Lr:1.00E-04
Epoch: 5, Train_acc:86.3%, Train_loss:0.329, Test_acc:85.5%, Test_loss:0.331, Lr:1.00E-04
Epoch: 6, Train_acc:86.3%, Train_loss:0.324, Test_acc:86.2%, Test_loss:0.315, Lr:1.00E-04
Epoch: 7, Train_acc:86.8%, Train_loss:0.313, Test_acc:87.8%, Test_loss:0.298, Lr:1.00E-04
Epoch: 8, Train_acc:87.3%, Train_loss:0.302, Test_acc:86.3%, Test_loss:0.325, Lr:1.00E-04
Epoch: 9, Train_acc:87.7%, Train_loss:0.297, Test_acc:84.7%, Test_loss:0.363, Lr:1.00E-04
Epoch:10, Train_acc:88.5%, Train_loss:0.282, Test_acc:87.7%, Test_loss:0.295, Lr:1.00E-04
Done
四、 结果可视化
1. Loss与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2. 指定图片进行预测
from PIL import Image classes = ["正常细胞", "乳腺癌细胞"]def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
# 预测训练集中的某张照片
predict_one_image(image_path='./data/2-data/0/8863_idx5_x451_y501_class0.png', model=model, transform=train_transforms, classes=classes)
预测结果是:正常细胞
3. 模型评估
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss
(0.8780305856023871, 0.29799242158021244)
# 查看是否与我们记录的最高准确率一致
epoch_test_acc
0.8780305856023871
相关文章:
pytorch 入门 (五)案例三:乳腺癌识别-VGG16实现
本文为🔗小白入门Pytorch内部限免文章 🍨 本文为🔗小白入门Pytorch中的学习记录博客🍦 参考文章:【小白入门Pytorch】乳腺癌识别🍖 原作者:K同学啊 在本案例中,我将带大家探索一下深…...

vue中electron与vue通信(fs.existsSync is not a function解决方案)
electron向vue发送消息 dist/main.js (整个文件配置在另一条博客里) win new BrowserWindow({width:1920,height:1080,webPreferences: {// 是否启用Node integrationnodeIntegration: true, // Electron 5.0.0 版本之后它将被默认false// 是否在独立 JavaScript 环境中运行…...

LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks翻译
论文《LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks》翻译 LSTM-Based Anomaly Detection of Process Instances Benchmark and Tweaks翻译...

文件类漏洞总结, 文件包含, 文件上传, 文件下载
文件类漏洞总结 一, 文件包含 1. 文件包含绕过 实际环境中不是都是像$_GET[file]; incude $file 这样直接把变量传入包含函数的。 在很多时候包含的变量文件不是完全可控的,比如下面这段代码指定了前缀和后缀: <?php $file S_GET[filename]; include /opt/…...

SpringBoot篇---第四篇
系列文章目录 文章目录 系列文章目录一、springboot常用的starter有哪些二、 SpringBoot 实现热部署有哪几种方式?三、如何理解 Spring Boot 配置加载顺序? 一、springboot常用的starter有哪些 spring-boot-starter-web 嵌入tomcat和web开发需要servlet…...
 -- 在不同版本SpringBoot,选用不同的Knife4j相关的jar包)
Knife4j使用教程(一) -- 在不同版本SpringBoot,选用不同的Knife4j相关的jar包
目录 1. Knife4j的项目背景 2. Knife4j的选择 2.1 选用 Spring Boot 版本在 2.4.0~3.0.0之间 2.2 选用 Spring Boot 版本在 3.0.0之上...
Octave Convolution学习笔记 (附代码)
论文地址:https://export.arxiv.org/pdf/1904.05049 代码地址:https://gitcode.com/mirrors/lxtgh/octaveconv_pytorch/overview?utm_sourcecsdn_github_accelerator 1.是什么? OctaveNet网络属于paper《Drop an Octave: Reducing Spatia…...
SpringSecurity 认证实战
一. 项目数据准备 1.1 添加依赖 <dependencies><!--spring security--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId></dependency><!--web起步依赖-…...
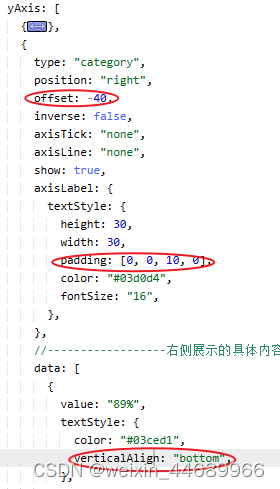
echarts中横向柱状图的数字在条纹上方
实现效果: 数字在条纹的上方 实现方法:这些数字是用新添加一个坐标轴来实现的 直接添加坐标轴数字显示是在条纹的正右边 所以需要配置一下偏移 完整代码 var option {grid: {left: "3%",right: "4%",bottom: "3%",cont…...

【仙逆】尸阴宗始祖现身,王林修得黄泉生窍诀,阿呆惊险逃生
【侵权联系删除】【文/郑尔巴金】 深度爆料最新集,王林终于成功筑基,这一集的《仙逆》动漫真是让人热血沸腾啊!在这个阶段,王林展现出了他的决心和毅力,成功地击杀了藤厉,并采取了夺基大法,从藤…...

C++二叉树剪枝
文章目录 C二叉树剪枝题目链接题目描述解题思路代码复杂度分析 C二叉树剪枝 题目链接 LCR 047. 二叉树剪枝 - 力扣(LeetCode) 题目描述 给定一个二叉树 根节点 root ,树的每个节点的值要么是 0,要么是 1。请剪除该二叉树中所有节…...
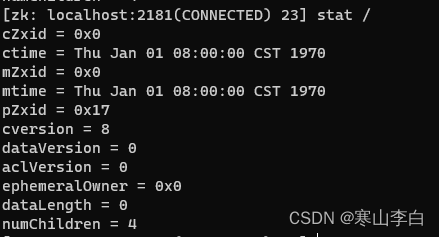
ZooKeeper中节点的操作命令(查看、创建、删除节点)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...
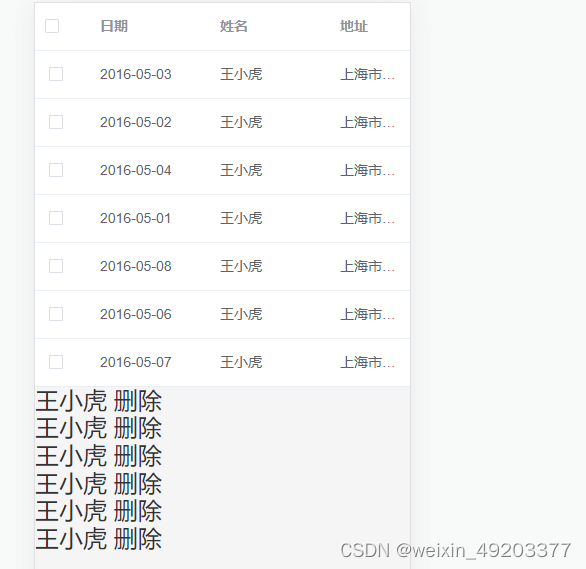
el-table多选表格 实现默认选中 删除选中列表取消勾选等联动效果
实现效果如下: 代码如下: <template><div><el-tableref"multipleTable":data"tableData"tooltip-effect"dark"style"width: 100%"selection-change"handleSelectionChange"><…...
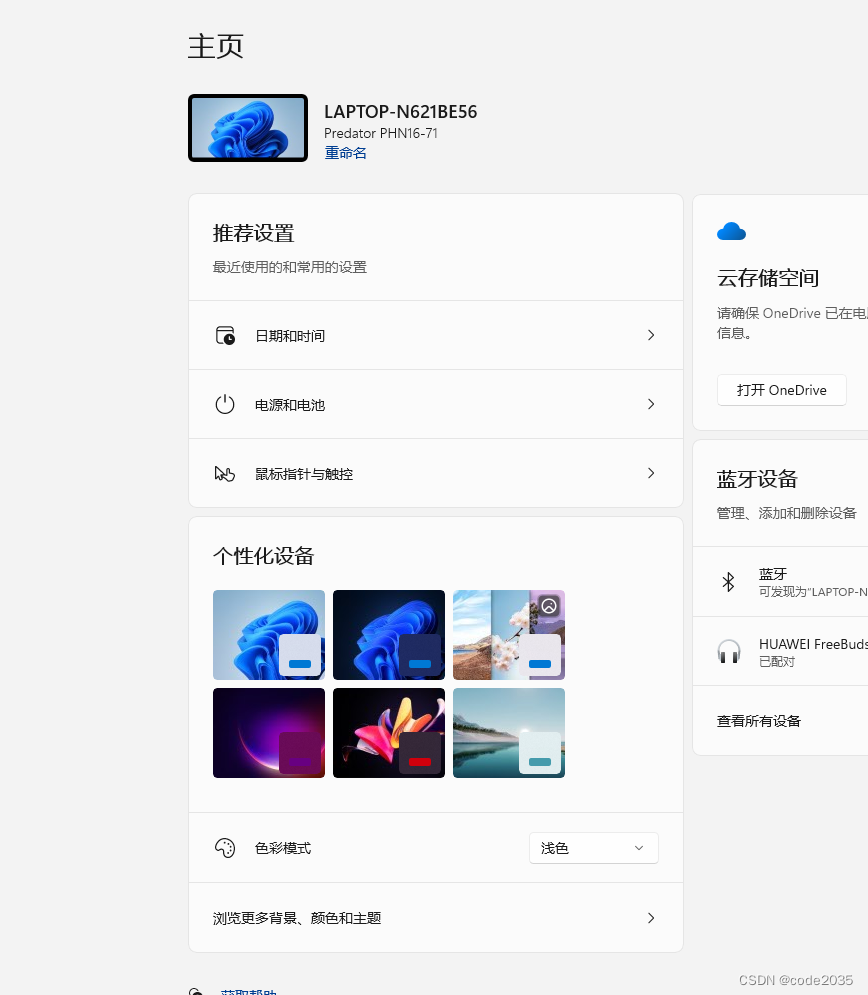
预安装win11的电脑怎么退回正版win10?
对于新购的笔记本 通常来讲预装的系统是全新安装的,是没有之前Windows10系统文件的,无法回退。 可以打开设置-----系统----恢复-----看下是否有该选项。 ------------------------------------------------------------------------------- 若是在上述…...
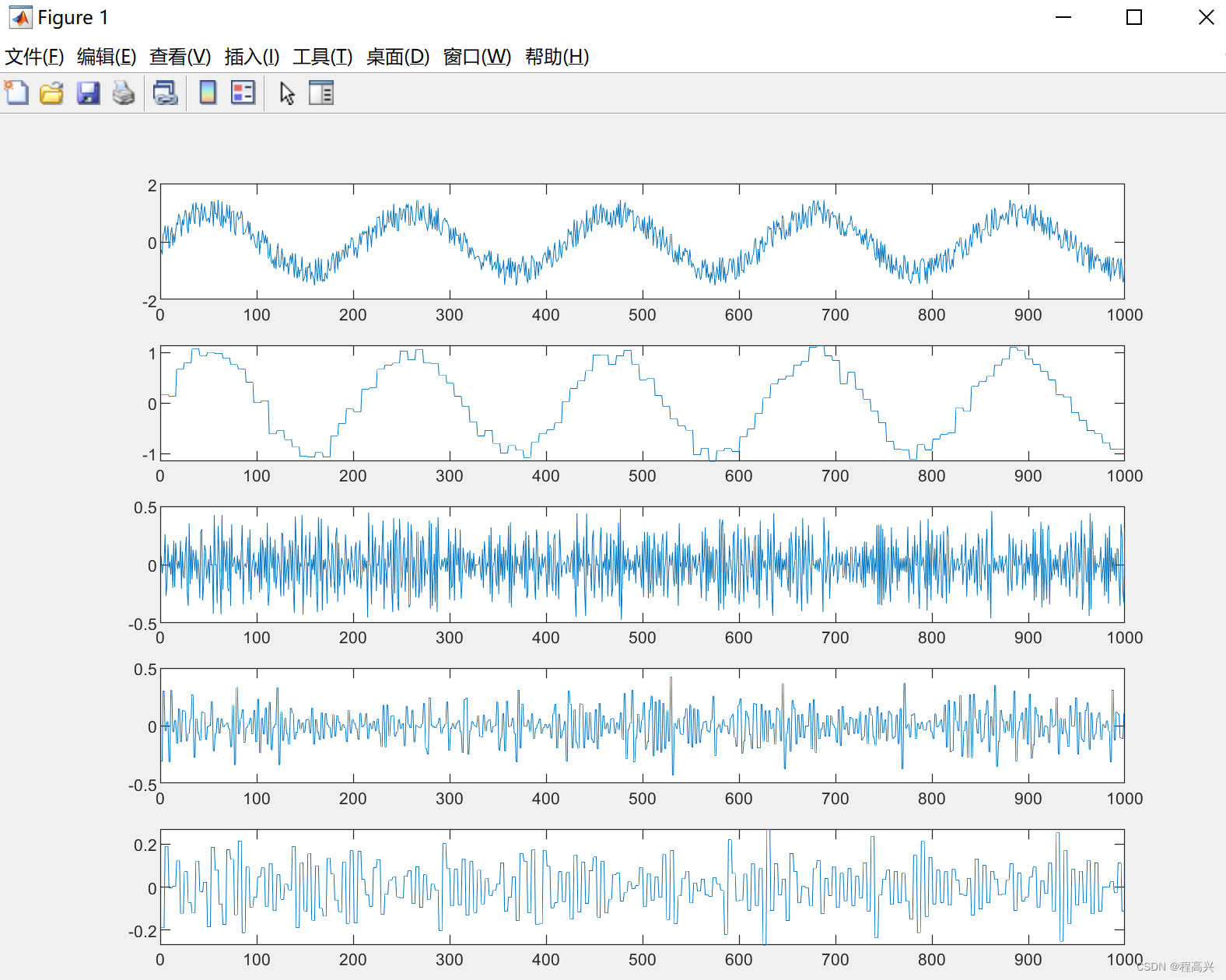
MATLAB——多层小波的重构
%% 学习目标:多层小波的重构 %% 程序1 clear all; close all; load noissin.mat; xnoissin; [C,L]wavedec(x,3,db1); %小波多层分解 ywaverec(C,L,db1); %重构,必须小波类型一致 emax(abs(x-y)) %重构的误差 %% 程序2 clear all;…...
解锁高效创作艺术!AI助力文章生成与精美插图搭配完美融合
在当今这个信息爆炸的时代,高效创作文章已经成为了一种必备的技能。然而,创作一篇高质量的文章并插入精美插图,往往需要耗费大量的时间和精力。现在,随着AI技术的发展,我们迎来了一个全新的文章创作时代——利用AI高效…...

✔ ★【备战实习(面经+项目+算法)】 10.29学习
✔ ★【备战实习(面经项目算法)】 坚持完成每天必做如何找到好工作1. 科学的学习方法(专注!效率!记忆!心流!)2. 每天认真完成必做项,踏实学习技术 认真完成每天必做&…...

微服务-Ribbon负载均衡
文章目录 负载均衡原理流程原理源码分析负载均衡流程 负载均衡策略饥饿加载总结 负载均衡原理 流程 原理 LoadBalanced 标记RestTemplate发起的http请求要被Ribbon进行拦截和处理 源码分析 ctrlshiftN搜索LoadBalancerInterceptor,进入。发现实现了ClientHttpRequ…...
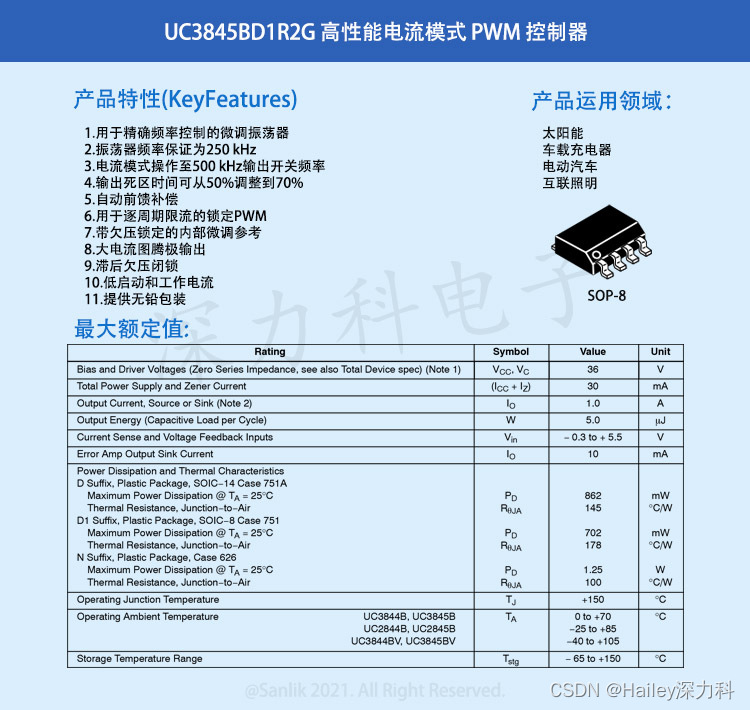
UC3845BD1R2G一款专门针对离线和 DC-DC 转换器应用 高性能电流模式PWM控制器
UC3845BD1R2G为高性能固定频率电流模式控制器。专门针对离线和 DC-DC 转换器应用而设计,提供了外部部件极少的成本高效方案。这些集成电路具有振荡器、温度补偿参考、高增益误差放大器、电流传感比较器和高电流图腾柱输出,适用于驱动功率 MOSFET。还包括…...

vivo自研AI大模型即将问世,智能手机行业加速迈向AI时代
当前,以大模型为代表的人工智能技术已发展为新一轮科技革命和产业变革的重要驱动力量,被视作推动经济社会发展的关键增长极。 AI大模型潮起,千行百业走向百舸争流的AI创新应用期,前沿信息技术向手机、PC、车机等消费级终端加速渗…...

Jimeng LoRA企业落地案例:设计公司LoRA训练-测试-选型一体化流程
Jimeng LoRA企业落地案例:设计公司LoRA训练-测试-选型一体化流程 1. 项目简介 今天给大家分享一个特别实用的企业级AI应用案例——如何为设计公司搭建一套完整的LoRA模型训练、测试和选型流程。这个项目基于Jimeng(即梦)系列LoRA模型&#…...

ASP.NET Core 认证鉴权实战:JWT、Policy 与权限边界怎么落地
实现场:一个后台退款接口原本只允许财务角色调用,但线上排查发现,普通运营账号只要拿到有效 token,也能调用成功。根因并不复杂:接口加了 [Authorize]系统只校验“是否登录”没有继续校验角色、权限和资源归属结果就是…...

UICKeyChainStore常见问题解答:解决开发者遇到的典型问题
UICKeyChainStore常见问题解答:解决开发者遇到的典型问题 【免费下载链接】UICKeyChainStore UICKeyChainStore is a simple wrapper for Keychain on iOS, watchOS, tvOS and macOS. Makes using Keychain APIs as easy as NSUserDefaults. 项目地址: https://gi…...

如何彻底告别网盘限速?八大平台直链解析工具全攻略
如何彻底告别网盘限速?八大平台直链解析工具全攻略 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用,去推广…...

如何快速掌握深度学习调参技巧:tuning_playbook_zh_cn完全解析
如何快速掌握深度学习调参技巧:tuning_playbook_zh_cn完全解析 【免费下载链接】tuning_playbook_zh_cn 一本系统地教你将深度学习模型的性能最大化的战术手册。 项目地址: https://gitcode.com/gh_mirrors/tu/tuning_playbook_zh_cn tuning_playbook_zh_cn是…...

10分钟重塑Windows体验:Win11Debloat系统优化完全指南
10分钟重塑Windows体验:Win11Debloat系统优化完全指南 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改以简化和改…...

Simulink模型加密二选一:是选‘受保护模型’还是自己写S-Function?一份给嵌入式代码生成者的选择指南
Simulink模型加密实战:受保护模型与S-Function的深度技术选型 在嵌入式系统开发中,Simulink模型往往承载着核心算法和知识产权。当需要与团队协作或交付给客户时,如何在保证模型可用性的同时防止核心逻辑被窥探或篡改?这成为每个嵌…...

避坑指南:CentOS虚拟机重启报rdsosreport.txt错误时,为什么xfs_repair有时需要-L参数?
CentOS虚拟机XFS文件系统修复实战:为什么-L参数是最后的救命稻草? 当你深夜加班部署服务,突然虚拟机异常断电,重启后屏幕上赫然出现"generating /run/initramfs/rdsosreport.txt"的报错——这个场景足以让任何Linux管理…...

鲁棒估计与5点算法求解本质矩阵
发散,无法保证找到全局正确的解。鉴于5点算法的代数复杂性和实现难度(涉及高次多项式求根、病态方程处理等),并且考虑到本系列文章的核心主题是数值优化而非代数几何,我们在此不展开其繁琐的数学推导和代码实现细节。感…...

SDMatte新手入门:交互式点选,让复杂抠图变简单
SDMatte新手入门:交互式点选,让复杂抠图变简单 1. 什么是SDMatte? SDMatte是一款基于扩散模型的交互式图像抠图工具,由vivoCameraResearch团队开发。它通过简单的点选操作,就能实现专业级的图像抠图效果,…...