AB试验(七)利用Python模拟A/B试验
AB试验(七)利用Python模拟A/B试验
到现在,我相信大家理论已经掌握了,轮子也造好了。但有的人是不是总感觉还差点什么?没错,还缺了实战经验。对于AB实验平台完善的公司 ,这个经验不难获得,但有的同学或多或少总有些原因无法接触到AB实验。所以本文就告诉大家,如何利用Python完整地进行一次A/B试验模拟。
现在,前面造好的轮子ABTestFunc.py就起到关键作用了
from faker import Faker
from faker.providers import BaseProvider, internet
from random import randint
from scipy.stats import bernoulli
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from scipy import stats
from collections import defaultdict
import toad
import matplotlib.pyplot as plt
import seaborn as sns
import math# 绘图初始化
%matplotlib inline
sns.set(style="ticks")
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 导入自定义模块
import sys
sys.path.append("/Users/heinrich/Desktop/Heinrich-blog/数据分析使用手册")
from ABTestFunc import *
上述自定义模块
ABTestFunc如果有需要的同学可关注公众号HsuHeinrich,回复【AB试验-自定义函数】自动获取~
均值类指标实验模拟
实验前准备
- 背景:某app想通过优化购物车来提高用户的人均消费,遂通过AB实验检验优化效果。
- 实验前设定
- 实验为双尾检验
- 实验分流为50%/50%
- 显著性水平为5%
- 检验功效为80%
# 实验设定
alpha=0.05
power=0.8
beta=1-power
确定目标和假设
- 目标:提高人均消费
- 假设:选择商品时,醒目提示各商品优惠金额,并按照优惠截止日期排序,提高紧促感。
确定指标
- 评价指标:人均购买金额
- 护栏指标:样本比例、特征分布一致
确定实验单位
- 用户ID
样本量估算
- 模拟历史样本
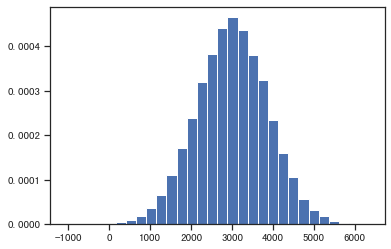
# 假设用户的购买金额服从正态分布
# 模拟过去一段时间的用户购买金额
np.random.seed(0)
pays=np.random.normal(2999, 876, 50000)
plt.hist(pays, 30, density=True)
plt.show()
# 输出当前消费金额的均值
print(pays.mean())
# 输出当前消费金额的方差
print(np.std(pays, ddof=1))
# 计算历史数据的波动区间,并假设此次提升高于最大波动上限
print(numbers_cal_ci(pays))
2995.676447900933
873.0773017854648
[2988.0237285541257, 3003.3291672477403]
- 依据提升情况计算样本量
# 当前消费均值为2996,方差为873,波动上限为3003。
# 假设此次实验能提高消费金额至3050元
u1=2996
u2=3050
s=np.std(pays, ddof=1)n1=n2=numbers_cal_sample_third(u1, u2, s)
print(2*n1)
8210
随机分组
- CR法
测试时间的估算
# 假设每天用户流量680,且用户在周终于周末的购买行为不一致,因此至少包含一周的时间
test_time=max(math.ceil(2*n1/680), 7)
print(test_time)
13
实施测试
- 测试过程无明显异常
- 模拟实验数据产生,并在结束时收集数据
# 自定义数据
fake = Faker('zh_CN')
class MyProvider(BaseProvider):def myCityLevel(self):cl = ["一线", "二线", "三线", "四线+"]return cl[randint(0, len(cl) - 1)]def myGender(self):g = ['F', 'M']return g[randint(0, len(g) - 1)]def myDevice(self):d = ['Ios', 'Android']return d[randint(0, len(d) - 1)]
fake.add_provider(MyProvider)# 构造假数据,模拟实验过程产生的样本数据的特征
uid=[]
cityLevel=[]
gender=[]
device=[]
age=[]
activeDays=[]
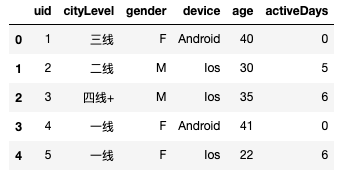
for i in range(8225):uid.append(i+1)cityLevel.append(fake.myCityLevel())gender.append(fake.myGender())device.append(fake.myDevice())age.append(fake.random_int(min=18, max=45)) # 年龄分布activeDays.append(fake.random_int(min=0, max=7)) # 近7日活跃分布raw_data= pd.DataFrame({'uid':uid,'cityLevel':cityLevel,'gender':gender,'device':device,'age':age,'activeDays':activeDays,})raw_data.head()
# 数据随机切分,模拟实验分流
test, control= train_test_split(raw_data.copy(), test_size=.5, random_state=0)
# 模拟用户购买金额
np.random.seed(1)
test['pays']=np.random.normal(3049, 850, test.shape[0])
control['pays']=np.random.normal(2999, 853, control.shape[0])
# 数据拼接,模拟数据收集结果
test['flag'] = 'test'
control['flag'] = 'control'
df = pd.concat([test, control])
分析测试结果
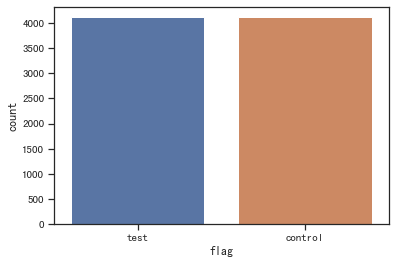
- 样本比例合理性检验
# 查看样本比例
sns.countplot(x='flag', data=df)
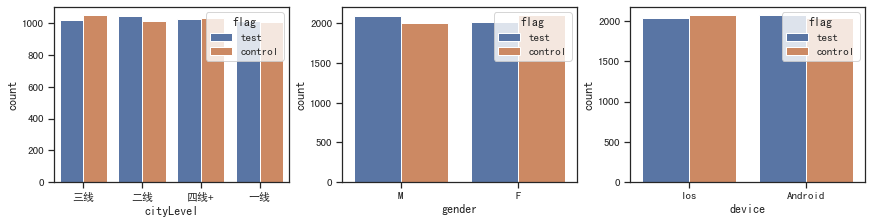
plt.show()# 查看离散变量的分布
fig, ax =plt.subplots(1, 3, constrained_layout=True, figsize=(12, 3))
for i, x in enumerate(['cityLevel', 'gender', 'device']):sns.countplot(x=x, data=df, hue='flag', ax=ax[i])
plt.show()# 查看连续变量的分布
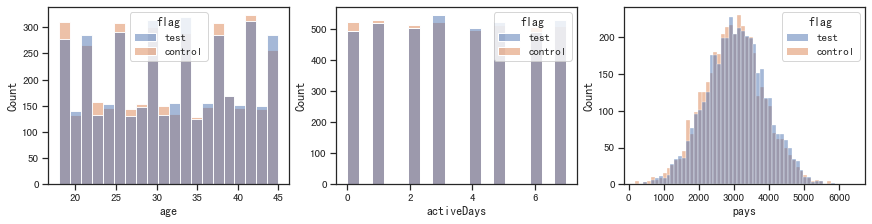
fig, ax =plt.subplots(1, 3, constrained_layout=True, figsize=(12, 3))
for i, x in enumerate(['age', 'activeDays', 'pays']):sns.histplot(x=x, data=df, hue='flag', ax=ax[i])
plt.show()
# 检验样本比例一致性
n1=control.size
n2=test.size
p1=p2=0.5
two_sample_proportion_test(n1, n2, p1, p2)
两样本比例校验: 通过
- 样本特征一致性校验
# 检验特征分布一致性
cols=['cityLevel', 'gender', 'device', 'age', 'activeDays']
feature_dist_ks(cols, test, control)
cityLevel: 相似
gender: 相似
device: 相似
age: 相似
activeDays: 相似
- 显著性校验
# 显著性检验
numbers_cal_significant(test['pays'], control['pays'])
方差齐性校验结果:方差相同(3.1882855769529668,0.0014365540563265368,[23.101471736420166, 96.85309892416026])
p值小于5%,置信区间不包含0且最小提升为23,明显高于自然波动的上线。因此可以认为此次购物车优化实验有助于提高用户的人均消费
- 拓展-维度下钻分析
# 进行维度下钻分析,采用BH法进行多重检验校正
feature=[]
value=[]
pvaules=[]
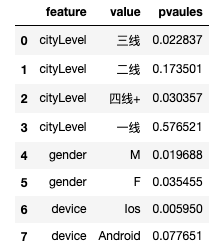
for x in ['cityLevel', 'gender', 'device']:for i in df[x].unique():feature.append(x)value.append(i)# 构造细分维度的样本te=test[test[x]==i]co=control[control[x]==i]# 计算细分维度的p值p=numbers_cal_significant(te['pays'], co['pays'], levene_print=False)[1]pvaules.append(p)df_multiple=pd.DataFrame({'feature':feature,'value':value,'pvaules':pvaules})
df_multiple
# 多重检验校正
print(multiple_tests_adjust(df_multiple['pvaules']))
df_multiple['pvaules_correct']=multiple_tests_adjust(df_multiple['pvaules'])[1]
df_multiple['reject']=multiple_tests_adjust(df_multiple['pvaules'])[0]
df_multiple
(array([False, False, False, False, False, False, True, False]), array([0.05672733, 0.19828707, 0.05672733, 0.57652105, 0.05672733,0.05672733, 0.04760055, 0.10353442]), 0.00625)
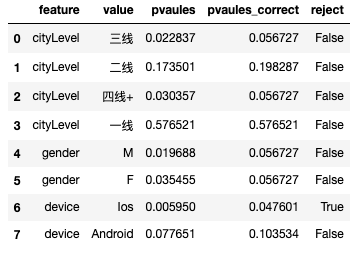
维度下钻发现,只有iOS设备的用户存在显著提升
实验报告
# 关键数据展示# 样本及均值
print('control:' ,f'sample {control.shape[0]} / mean:{control.pays.mean()}')
print('test:' ,f'sample {test.shape[0]} / mean:{test.pays.mean()}')
# 实验周期
print('times:', test_time)
# diff
print('diff:', test['pays'].mean()-control['pays'].mean())
# p值
print('p-value:', numbers_cal_significant(test['pays'], control['pays'], levene_print=False)[1])
# diff-置信区间
print('diff-ci:', numbers_cal_significant(test['pays'], control['pays'], levene_print=False)[2])
# 维度下钻结果
print('dim-result:')
for i,v in zip(df_multiple.value,df_multiple.reject):print(' '*2,f'{i}:{v}')
control: sample 4113 / mean:3000.5565990602113
test: sample 4112 / mean:3060.533884390513
times: 13
diff: 59.977285330301584
p-value: 0.0014365540563265368
diff-ci: [23.101471736420166, 96.85309892416026]
dim-result:三线:False二线:False四线+:False一线:FalseM:FalseF:FalseIos:TrueAndroid:False
- 实验13天,收集到实验组数据4112,对照组4113,共计8225。
- 实验过程无异常,实验组人均购买金额为3061元,较对照组提高60元
- 整体上,实验组的提升是显著的,且提升范围在
[23, 97]元之间- 通过维度下钻,发现实验组仅在Ios设备用户有显著提升
概率类指标实验模拟
实验前准备
- 背景:某音乐app想通过优化功能提示提高用户功能使用率。
- 实验前设定
- 实验为双尾检验
- 实验分流为50%/50%
- 显著性水平为5%
- 检验功效为80%
# 实验设定
alpha=0.05
power=0.8
beta=1-power
确定目标和假设
- 目标:提高【把喜欢的音乐加入收藏夹】功能的使用率
- 假设:用户从未使用过这个功能,且播放同一首歌到达4次时,在播放第5次进行弹窗提醒可以把喜欢的音乐加入收藏夹
确定指标
- 评价指标:【把喜欢的音乐加入收藏夹】功能的使用率
- 护栏指标:样本比例、特征分布一致
确定实验单位
- 用户ID
样本量估算
- 模拟历史样本
# 假设用户的购买金额服从正态分布
# 模拟过去一段时间的用户【把喜欢的音乐加入收藏夹】
np.random.seed(1)
collect=stats.bernoulli.rvs(0.02, size=20000, random_state=0)
plt.hist(collect, 30, density=True)
plt.show()
# 输出当前【把喜欢的音乐加入收藏夹】功能的使用率
print(collect.mean())
# 计算历史数据的波动区间,并假设此次提升高于最大波动上限
print(prob_cal_ci(0.02, 20000))
0.0197
[0.01805973464591045, 0.02194026535408955]
- 依据提升情况计算样本量
# 当前转化率为0.02,波动上限为0.0219。
# 假设此次实验能提高使用率至0.022
p1=0.02
p2=0.022n1=n2=prob_cal_sample_third(p1, p2)
print(2*n1)
161276
随机分组
- CR法
测试时间的估算
# 假设每天符合条件用户流量1.7w,且用户在周终于周末的听音乐行为不一致,因此至少包含一周的时间
test_time=max(math.ceil(2*n1/17000), 7)
print(test_time)
10
实施测试
- 测试过程无明显异常
- 模拟实验数据产生,并在结束时收集数据
# 自定义数据
fake = Faker('zh_CN')
class MyProvider(BaseProvider):def myCityLevel(self):cl = ["一线", "二线", "三线", "四线+"]return cl[randint(0, len(cl) - 1)]def myGender(self):g = ['F', 'M']return g[randint(0, len(g) - 1)]def myDevice(self):d = ['Ios', 'Android']return d[randint(0, len(d) - 1)]
fake.add_provider(MyProvider)# 构造假数据,模拟实验过程产生的样本数据的特征
uid=[]
cityLevel=[]
gender=[]
device=[]
age=[]
activeDays=[]
for i in range(161280):uid.append(i+1)cityLevel.append(fake.myCityLevel())gender.append(fake.myGender())device.append(fake.myDevice())age.append(fake.random_int(min=18, max=45)) # 年龄分布activeDays.append(fake.random_int(min=0, max=7)) # 近7日活跃分布raw_data= pd.DataFrame({'uid':uid,'cityLevel':cityLevel,'gender':gender,'device':device,'age':age,'activeDays':activeDays,})raw_data.head()
# 数据随机切分,模拟实验分流
test, control= train_test_split(raw_data.copy(), test_size=.5, random_state=0)
# 模拟用户收藏转化率
test['collect']=stats.bernoulli.rvs(0.023, size=test.shape[0], random_state=0)
control['collect']=stats.bernoulli.rvs(0.02, size=control.shape[0], random_state=0)
# 数据拼接,模拟数据收集结果
test['flag'] = 'test'
control['flag'] = 'control'
df = pd.concat([test, control])
分析测试结果
- 样本比例合理性检验
# 查看样本比例
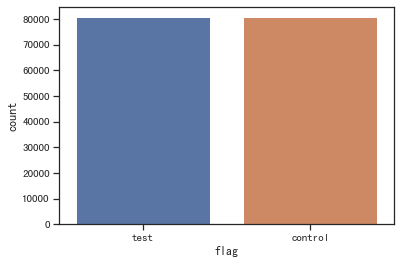
sns.countplot(x='flag', data=df)
plt.show()# 查看离散变量的分布
fig, ax =plt.subplots(1, 3, constrained_layout=True, figsize=(12, 3))
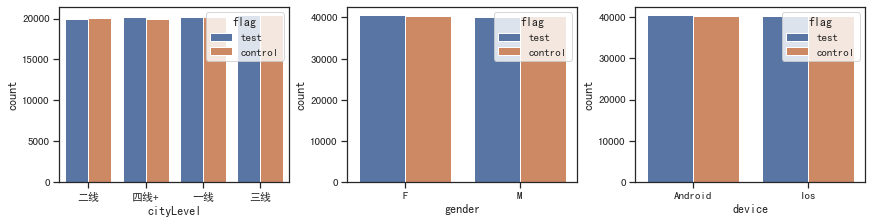
for i, x in enumerate(['cityLevel', 'gender', 'device']):sns.countplot(x=x, data=df, hue='flag', ax=ax[i])
plt.show()# 查看连续变量的分布
fig, ax =plt.subplots(1, 3, constrained_layout=True, figsize=(12, 3))
for i, x in enumerate(['age', 'activeDays', 'collect']):sns.histplot(x=x, data=df, hue='flag', ax=ax[i])
plt.show()
# 检验样本比例一致性
n1=control.size
n2=test.size
p1=p2=0.5
two_sample_proportion_test(n1, n2, p1, p2)
两样本比例校验: 通过
- 样本特征一致性校验
# 检验特征分布一致性
cols=['cityLevel', 'gender', 'device', 'age', 'activeDays']
feature_dist_ks(cols, test, control)
cityLevel: 相似
gender: 相似
device: 相似
age: 相似
activeDays: 相似
- 显著性检验
# 显著性检验
count1=test['collect'].sum()
nobs1=test['collect'].size
count2=control['collect'].sum()
nobs2=control['collect'].sizeprob_cal_significant(count1, nobs1, count2, nobs2)
(3.8761435754191123,0.00010612507775057984,[0.0013796298310413291, 0.004202600259759636])
- p值小于5%,置信区间不包含0。因此整体上可以认为此次优化有助于提高【把喜欢的音乐加入收藏夹】功能的使用率。
- 但是需要注意置信区间最小提升为0.0014,而在自然波动的最大提升是0.0019(0.0219-0.02),所以此次提升有可能在自然波动范围内,可能存在业务不显著,需要额外关注。
- 拓展-维度下钻分析
# 进行维度下钻分析,采用BH法进行多重检验校正
feature=[]
value=[]
pvaules=[]
for x in ['cityLevel', 'gender', 'device']:for i in df[x].unique():feature.append(x)value.append(i)# 构造细分维度的样本te=test[test[x]==i]co=control[control[x]==i]# 计算细分维度的p值c1=te['collect'].sum()n1=te['collect'].sizec2=co['collect'].sum()n2=co['collect'].sizep=prob_cal_significant(c1, n1, c2, n2)[1]pvaules.append(p)df_multiple=pd.DataFrame({'feature':feature,'value':value,'pvaules':pvaules})
df_multiple
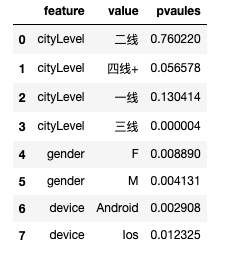
# 多重检验校正
print(multiple_tests_adjust(df_multiple['pvaules']))
df_multiple['pvaules_correct']=multiple_tests_adjust(df_multiple['pvaules'])[1]
df_multiple['reject']=multiple_tests_adjust(df_multiple['pvaules'])[0]
df_multiple
(array([False, False, False, True, True, True, True, True]), array([7.60220226e-01, 7.54367218e-02, 1.49044597e-01, 3.53217899e-05,1.77798888e-02, 1.10151024e-02, 1.10151024e-02, 1.97199451e-02]), 0.00625)
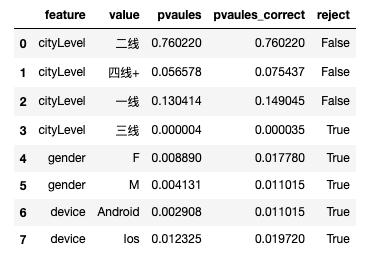
维度下钻发现,一线、二线和四线+城市提升不显著
实验报告
# 关键数据展示# 样本及均值
print('control:' ,f'sample {control.shape[0]} / mean:{control.collect.mean()}')
print('test:' ,f'sample {test.shape[0]} / mean:{test.collect.mean()}')
# 实验周期
print('times:', test_time)
# diff
print('diff:', test['collect'].mean()-control['collect'].mean())
# p值
print('p-value:', prob_cal_significant(count1, nobs1, count2, nobs2)[1])
# diff-置信区间
print('diff-ci:', prob_cal_significant(count1, nobs1, count2, nobs2)[2])
# 维度下钻结果
print('dim-result:')
for i,v in zip(df_multiple.value,df_multiple.reject):print(' '*2,f'{i}:{v}')
control: sample 80640 / mean:0.019952876984126983
test: sample 80640 / mean:0.022743055555555555
times: 10
diff: 0.002790178571428572
p-value: 0.00010612507775057984
diff-ci: [0.0013796298310413291, 0.004202600259759636]
dim-result:二线:False四线+:False一线:False三线:TrueF:TrueM:TrueAndroid:TrueIos:True
- 实验10天,收集到实验组数据80640,对照组80640,共计161280。
- 实验过程无异常,实验组人均收藏率为0.023,较对照组提高0.003
- 整体上,实验组的提升是显著的,且提升范围在
[0.001, 0.004]之间。但可能存在业务不显著,需要额外关注- 通过维度下钻,发现实验组在一线、二线和四线+城市提升不显著
总结
现在,关于均值类和概率类的所有实验细节和模拟实战都已结束,相信大家对如何科学地进行A/B试验已经了然于胸了吧~
共勉~
相关文章:
AB试验(七)利用Python模拟A/B试验
AB试验(七)利用Python模拟A/B试验 到现在,我相信大家理论已经掌握了,轮子也造好了。但有的人是不是总感觉还差点什么?没错,还缺了实战经验。对于AB实验平台完善的公司 ,这个经验不难获得&#…...

Go语言入门-流程控制语句
流程控制 Go语言中有以下几种常见的流程控制语句: 条件语句(Conditional Statements): if语句:用于根据条件执行代码块。else语句:在if条件不满足时执行的语句块。else if语句:用于在多个条件之…...

深入探究ASEMI肖特基二极管MBR60100PT的材质
编辑-Z 在电子零件领域中,肖特基二极管MBR60100PT因其出色的性能和广泛的应用而显得尤为关键。理解其材质不仅有助于我们深入理解其运作原理,也有助于我们做出更合适的电子设计。那么,肖特基二极管MBR60100PT是什么材质呢? 首先,…...

python类模拟“对战游戏”
Game类含玩家昵称、生命值、攻击力(整数),暴击率、闪避率(小数),在魔术方法init定义;attack方法中实现两个Game实例对战模拟。 (本笔记适合初通Python类class的coder翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.py…...

Maven第二章:Maven基本概念与生命周期
Maven第二章:Maven基本概念与生命周期 前言 本章主要内容,介绍Maven基本概念,包括maven坐标含义,命名规则,继承与聚合、了解与理解生命周期,如何通过Maven进行依赖和版本管理。 什么是Maven的坐标…...

<蓝桥杯软件赛>零基础备赛20周--第3周--填空题
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周(读者可以按…...

【Linux】VM及WindowsServer安装
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《微信小程序开发实战》。🎯Ἲ…...

【实用教程】MySQL内置函数
1 背景 在MySQL查询等操作过程中,我们需要根据实际情况,使用其提供的内置函数。今天我们就来一起来学习下这些函数,在之后的使用过程中更加得心应手。 2 MySQL函数 2.1 字符串函数 常用的函数如下: concat(s1,s2,…sn)字符串…...

第十二节——ref
一、概念 ref 被用来给DOM元素或子组件注册引用信息。引用信息会根据父组件的 $refs 对象进行注册。如果在普通的DOM元素上使用,引用信息就是元素; 如果用在子组件上,引用信息就是组件实例。 注意:只要想要在Vue中直接操作DOM元素ÿ…...

少儿编程 2023年9月中国电子学会图形化编程等级考试Scratch编程四级真题解析(判断题)
2023年9月scratch编程等级考试四级真题 判断题(共10题,每题2分,共20分) 11、运行程序后,变量"result"的值是6 答案:对 考点分析:考查积木综合使用,重点考查自定义积木的使用 图中自定义积木实现的功能是获取两个数中最大的那个数并存放在result变量中,左…...

【设计模式三原则】
设计模式三原则 单一职责原则开放封闭原则依赖倒转原则里氏代换原则 我们在进行程序设计的时候,要尽可能地保证程序的可扩展性、可维护性和可读性,所以需要使用一些设计模式,这些设计模式都遵循了以下三个原则,下面来依次为大家介…...

600MW发电机组继电保护自动装置的整定计算及仿真
摘要 随着科技的发展,电力已成为最重要的资源之一,如何保证电力的供应对于国民经济发展和人民生活水平的提高都有非常重要的意义。在电能输送过程中,发电机组是整个过程中最重要的一个基本元素,在电力系统中的输送和分配中被广泛应…...
#atcoder324C~E题)
【蓝桥每日一题]-字符串(保姆级教程 篇1)#atcoder324C~E题
今天来讲字符串题型 目录 题目:atcoder324C题 思路: 题目:atcoder324D题 思路: 题目:atcoder324E题 思路: 题目:atcoder324C题 给一个T字符串,然后给出n个S串,对…...

4.2.1 SQL语句、索引、视图、存储过程
怎么执行一条select语句 1.连接器 接收连接-》管理连接-》校验用户信息 2.查询缓存 kv存储,命中直接返回,否则继续执行 8.0已经删除 3.分析器 词法句法分析生成语法树 4.优化器 指定执行计划,选择查询成本最小的计划 5.执行器 根据执行计划&a…...
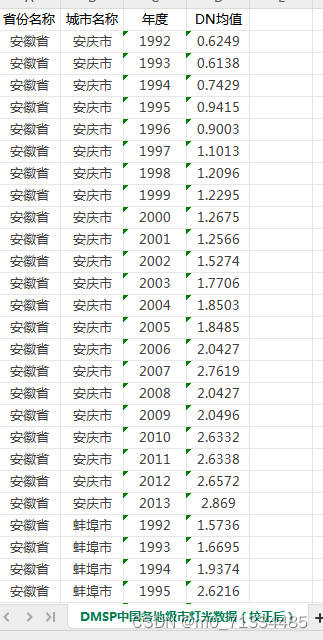
1992-2021年全国各地级市经过矫正的夜间灯光数据(GNLD、VIIRS)
1992-2021年全国各地级市经过矫正的夜间灯光数据(GNLD、VIIRS) 1、时间:1992-2021年3月,其中1992-2013年为年度数据,2013-2021年3月为月度数据 2、来源:DMSP、VIIRS 3、范围:分区域汇总&…...

机器人的触发条件有什么区别,如何巧妙的使用
简介 维格机器人触发条件,分为3个,分别是: 有新表单提交时、有记录满足条件时、有新的记录创建时 。 看似3个,其实是能够满足我们非常多的使用场景。 本篇将先介绍3个条件的触发条件,然后再列举一些复杂的触发条件如何用现有的触发条件来满足 注意: 维格机器人所有的…...

【Qt6】QStringList
2023年10月31日,周二上午 QStringList 是 Qt 中的一个类,用于存储一组字符串。它提供了一些方便的方法来操作和管理字符串列表。 QStringList 可以用于存储任意数量的字符串,并提供了一些常用的操作,例如添加、删除、查找、排序等…...

代码随想录算法训练营第五十三天|309.最佳买卖股票时机含冷冻期 ● 714.买卖股票的最佳时机含手续费
309. 买卖股票的最佳时机含冷冻期 int maxProfit(int* prices, int pricesSize){int len pricesSize;int dp[len][4];dp[0][0] -prices[0];dp[0][1] 0;dp[0][2] 0;dp[0][3] 0;for (int i 1; i < pricesSize; i){dp[i][0] fmax(dp[i-1][0], fmax(dp[i-1][1] - prices…...

厚黑学笔记
厚黑学 我现在的情况就是在听书听到一半,但在软件上看书已经看完了,厚黑学要讲的东西大概已经摸清楚了。 总体来说,厚黑学里面的章节内容有一点沾边的嫌疑(看完后的想法),但这本书还是有值得阅读的,但主讲…...

IDEA MyBatisX插件介绍
一、前言 前几年写代码的时候,要一键生成DAO、XML、Entity基础代码会采用第三方工具,比如mybatis-generator-gui等,现在IDEA或Eclipse都有对应的插件,像IDEA中MyBatisX就是一个比较好用的插件。 二、MyBatisX安装配置使用 MyBa…...
)
从‘代码打架’到‘和谐共舞’:用Gogs实战演练多人Git协作全流程(附冲突解决脚本)
从‘代码打架’到‘和谐共舞’:用Gogs实战演练多人Git协作全流程(附冲突解决脚本) 在团队开发中,Git冲突就像两个程序员同时修改同一行代码时的"拳脚相加",而解决冲突的过程则是让代码重新"和谐共舞&q…...

AwesomeQRCode源码阅读笔记:深入理解二维码渲染核心技术
AwesomeQRCode源码阅读笔记:深入理解二维码渲染核心技术 【免费下载链接】AwesomeQRCode An awesome QR code generator for Android. 项目地址: https://gitcode.com/gh_mirrors/aw/AwesomeQRCode 想要为你的Android应用添加炫酷的二维码生成功能吗…...

ARM架构TLB管理机制与RVALE1指令详解
1. ARM架构中的TLB管理机制解析在ARMv8/ARMv9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,承担着加速虚拟地址到物理地址转换的关键任务。当CPU需要访问内存时,T…...

iPhone 5c中国遇冷复盘:产品定价、市场预期与战略博弈的深度解析
1. 项目概述:一次关于市场预期的“误判”复盘2013年秋天,苹果公司发布了被外界普遍视为“专为新兴市场打造”的iPhone 5c。这款拥有多彩聚碳酸酯外壳的手机,在发布前就被贴上了“廉价iPhone”的标签,尤其是针对像中国这样庞大且正…...

数字信号处理实战:从零极点图到系统特性分析
1. 零极点图:数字信号处理的"X光片" 第一次接触零极点图时,我完全不明白这些散落在复平面上的小圆圈和叉叉有什么用。直到有次调试音频滤波器,当我把一个极点的位置向单位圆外移动了0.1,喇叭里立刻传出刺耳的啸叫声——…...

极简终端AI聊天工具gptcli:单文件Python脚本实现OpenAI API兼容客户端
1. 项目概述:一个极简的终端AI聊天工具如果你和我一样,经常需要在终端里和AI模型对话,但又觉得官方网页版太重、第三方客户端功能太杂,那么这个项目可能就是你的菜。gptcli是一个用单个Python脚本实现的、功能纯粹的终端聊天客户端…...

基于PyTorch的图像分类实战:从数据增强到模型微调全流程解析
1. 项目概述:一个基于深度学习的开源图像识别工具最近在整理个人项目库时,翻到了一个挺有意思的仓库,叫jyao97/xylocopa。乍一看这个名字,可能有点摸不着头脑,但如果你对昆虫学或者开源项目命名有点了解,就…...

Void Memory:为AI智能体构建持久记忆的轻量级解决方案
1. 项目概述:为AI智能体构建持久记忆的“记忆锚”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手并肩作战,一定对那个令人沮丧的瞬间不陌生:你花了半小时向它详细解释了一个复杂项目的架构、你的编码偏好、刚刚踩过的坑…...

docker-maven-plugin 源码解析:深入理解插件架构与实现原理
docker-maven-plugin 源码解析:深入理解插件架构与实现原理 【免费下载链接】docker-maven-plugin Maven plugin for running and creating Docker images 项目地址: https://gitcode.com/gh_mirrors/doc/docker-maven-plugin 一、插件核心架构概览 docker-…...

CANN/asc-devkit向量减法ReLU函数
asc_sub_relu 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...