Python爬虫实战(六)——使用代理IP批量下载高清小姐姐图片(附上完整源码)
文章目录
- 一、爬取目标
- 二、实现效果
- 三、准备工作
- 四、代理IP
- 4.1 代理IP是什么?
- 4.2 代理IP的好处?
- 4.3 获取代理IP
- 4.4 Python获取代理IP
- 五、代理实战
- 5.1 导入模块
- 5.2 设置翻页
- 5.3 获取图片链接
- 5.4 下载图片
- 5.5 调用主函数
- 5.6 完整源码
- 5.7 免费代理不够用怎么办?
- 六、总结
一、爬取目标
本次爬取的目标是某网站4K高清小姐姐图片:

二、实现效果
实现批量下载指定关键词的图片,存放到指定文件夹中:

三、准备工作
Python:3.10
编辑器:PyCharm
第三方模块,自行安装:
pip install requests # 网页数据爬取
pip install lxml # 提取网页数据
四、代理IP
4.1 代理IP是什么?
代理IP是一种安全功能,可以充当网络中间平台,使得用户电脑可以先访问代理IP,然后由代理IP访问目标网站页面,从而起到防火墙的作用。代理IP具有多种类型,包括HTTP代理、HTTPS代理、SOCKS代理等,分别适用于不同的网络通信需求。使用代理IP可以提高访问速度、保护隐私信息、突破下载限制以及作为防火墙保护网络安全。
4.2 代理IP的好处?
使用代理IP的好处有以下几个方面:
-
隐藏真实IP地址:使用代理IP可以将您的真实IP地址隐藏起来,确保您的在线活动更加匿名和隐私保护。这对于保护个人隐私和防止追踪非常重要。
-
绕过网络限制:有些地区或网络环境可能存在访问限制,如某些网站、社交媒体平台或在线服务被屏蔽。通过使用代理IP,可以绕过这些限制,访问被封锁的内容或服务。
-
提高访问速度:代理IP可以缓存和压缩网络数据,从而提高网页加载速度和下载速度。这对于访问速度较慢的网站或在网络拥堵时特别有用。
-
数据采集和爬虫应用:代理IP可以用于数据采集和爬虫应用,通过使用不同的代理IP地址,可以避免被目标网站识别和封禁,从而更好地进行数据采集和爬虫操作。
-
地理位置伪装:有时候需要在网站或应用中模拟不同的地理位置,以获取特定的服务或信息。使用代理IP可以实现地理位置的伪装,使网站或应用认为您位于不同的地理位置。
4.3 获取代理IP
博主最近写爬虫,发现了一款不错的代理IP,响度速度快,代理质量高,有免费试用也有超值套餐:云立方代理IP

1、打开云立方的官网,点击代理IP:http://www.yunlifang.cn/dailiIP.asp
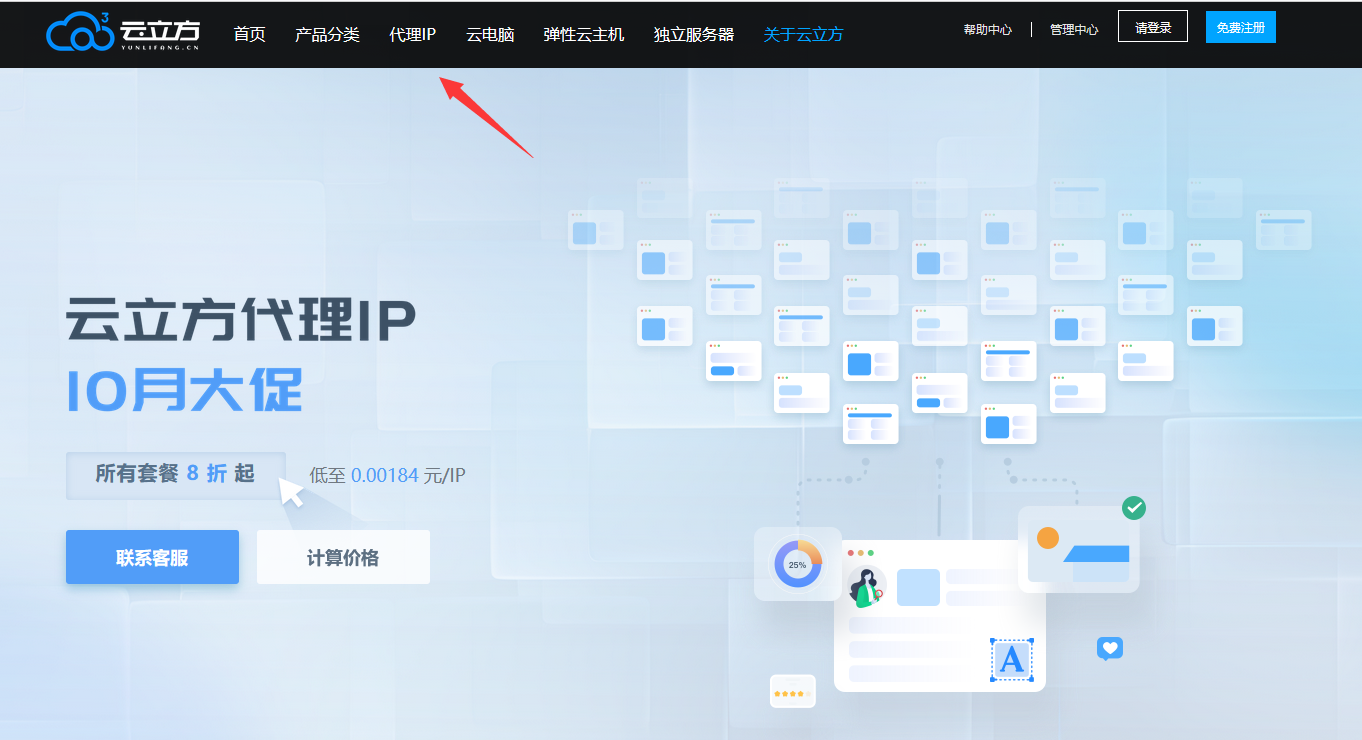
2、我们这里免费试用,测试一下效果:
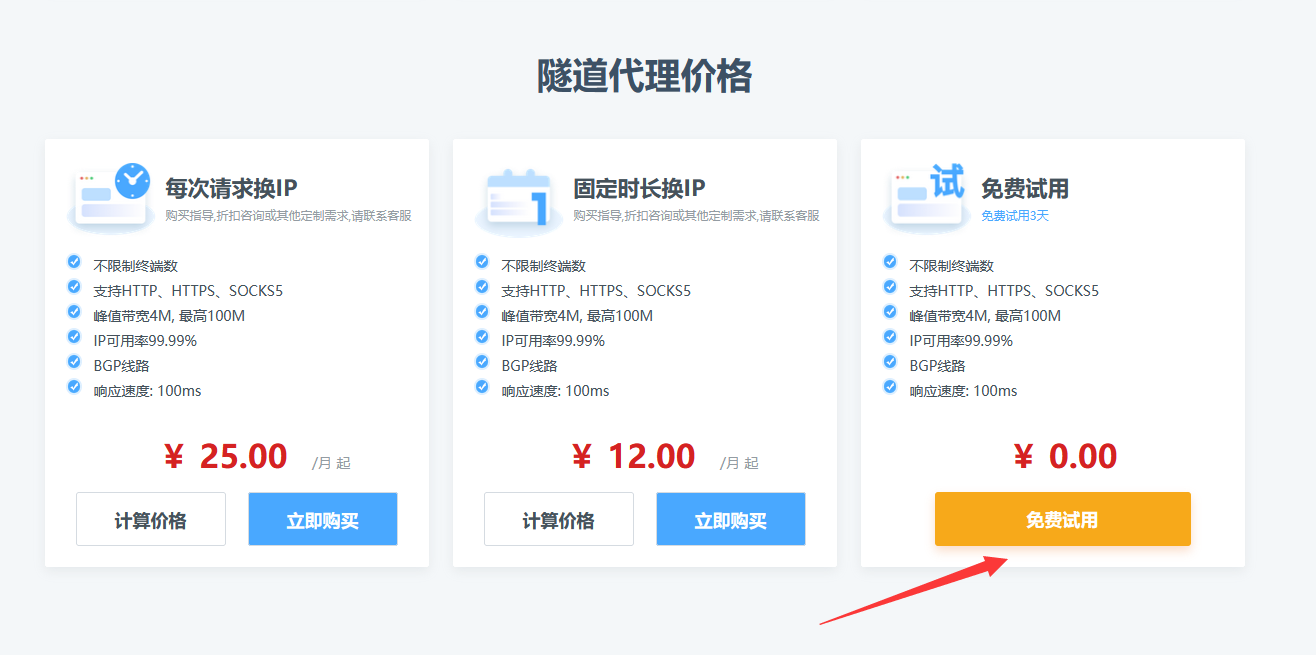
3、然后找客服说明免费试用一下,说明需要代理IP的时长、数量等信息:

然后客服给我们账号密码,请求地址和端口号:
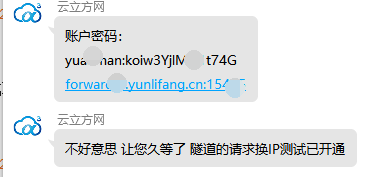
接下来就是使用Python去获取代理IP。
4.4 Python获取代理IP
我们用Python获取代理IP,注意将代码中的账号、密码、地址、端口替换为刚才客服给的账号信息:
def get_ip():"""获取代理IP"""# 这里替换为刚才客服给的账号信息proxyUser = "你的账号" # 账户proxyPass = "你的密码" # 密码proxyHost = "你的地址" # 地址proxyPort = "你的端口号" # 端口proxyMeta = f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"proxies = {"http": proxyMeta,"https": proxyMeta}print(proxies)return proxiesget_ip()
这里我用的隧道代理IP(隧道代理IP:是指下面那个账号链接每次去访问网页就会自动切换IP):

五、代理实战
5.1 导入模块
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
import os # 创建文件
5.2 设置翻页
首先我们来分析一下网站的翻页,一共有62页:

第一页链接:
https://pic.netbian.com/4kmeinv/index.html
第二页链接:
https://pic.netbian.com/4kmeinv/index_2.html
第三页链接:
https://pic.netbian.com/4kmeinv/index_3.html
可以看出每页只有index后面从第二页开始依次加上_页码,所以用循环来构造所有网页链接:
if __name__ == '__main__':# 页码page_number = 1# 循环构建每页的链接for i in range(1,page_number+1):# 第一页固定,后面页数拼接if i ==1:url = 'https://pic.netbian.com/4kmeinv/index.html'else:url = f'https://pic.netbian.com/4kmeinv/index_{i}.html'
5.3 获取图片链接
可以看到所有图片url都在 ul标签 > a标签 > img标签下:

我们创建一个get_imgurl_list(url)函数传入网页链接获取 网页源码,用xpath定位到每个图片的链接:
def get_imgurl_list(url,imgurl_list):"""获取图片链接"""# 请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}# 发送请求response = requests.get(url=url, headers=headers)# 获取网页源码html_str = response.text# 将html字符串转换为etree对象方便后面使用xpath进行解析html_data = etree.HTML(html_str)# 利用xpath取到所有的li标签li_list = html_data.xpath("//ul[@class='clearfix']/li")# 打印一下li标签个数看是否和一页的电影个数对得上print(len(li_list)) # 输出20,没有问题for li in li_list:imgurl = li.xpath(".//a/img/@src")[0]# 拼接urlimgurl = 'https://pic.netbian.com' +imgurlprint(imgurl)# 写入列表imgurl_list.append(imgurl)
运行结果:

点开一个图片链接看看:

OK没问题!!!
5.4 下载图片
图片链接有了,代理IP也有了,下面我们就可以下载图片。定义一个get_down_img(img_url_list)函数,传入图片链接列表,然后遍历列表,每下载一个图片切换一次代理,将所有图片下载到指定文件夹:
def get_down_img(imgurl_list):# 在当前路径下生成存储图片的文件夹os.mkdir("小姐姐")# 定义图片编号n = 0for img_url in imgurl_list:headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}# 调用get_ip函数,获取代理IPproxies = get_ip()# 每次发送请求换代理IP,获取图片,防止被封img_data = requests.get(url=img_url, headers=headers, proxies=proxies).content# 拼接图片存放地址和名字img_path = './小姐姐/' + str(n) + '.jpg'# 将图片写入指定位置with open(img_path, 'wb') as f:f.write(img_data)# 图片编号递增n = n + 1
5.5 调用主函数
这里我们可以设置需要爬取的页码:
if __name__ == '__main__':# 1. 设置获取的页数page_number = 63imgurl_list = [] # 用于存储所有的图片链接# 2. 循环构建每页的链接for i in range(1,page_number+1):# 第一页固定,后面页数拼接if i ==1:url = 'https://pic.netbian.com/4kmeinv/index.html'else:url = f'https://pic.netbian.com/4kmeinv/index_{i}.html'# 3. 获取图片链接get_imgurl_list(url,imgurl_list)# 4. 下载图片get_down_img(imgurl_list)
5.6 完整源码
注意将get_ip()函数代码中的账号、密码、地址、端口替换为刚才客服给的账号信息
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
import osdef get_ip():"""获取代理IP"""# 这里替换为刚才客服给的信息代理服务器proxyUser = "你的账号" # 账户proxyPass = "你的密码" # 密码proxyHost = "你的地址" # 地址proxyPort = "你的端口号" # 端口proxyMeta = f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"proxies = {"http": proxyMeta,"https": proxyMeta}print(proxies)return proxiesdef get_imgurl_list(url,imgurl_list):"""获取图片链接"""# 请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}# 发送请求response = requests.get(url=url, headers=headers)# 获取网页源码html_str = response.text# 将html字符串转换为etree对象方便后面使用xpath进行解析html_data = etree.HTML(html_str)# 利用xpath取到所有的li标签li_list = html_data.xpath("//ul[@class='clearfix']/li")# 打印一下li标签个数看是否和一页的电影个数对得上print(len(li_list)) # 输出20,没有问题for li in li_list:imgurl = li.xpath(".//a/img/@src")[0]# 拼接urlimgurl = 'https://pic.netbian.com' +imgurlprint(imgurl)# 写入列表imgurl_list.append(imgurl)def get_down_img(imgurl_list):# 在当前路径下生成存储图片的文件夹os.mkdir("小姐姐")# 定义图片编号n = 0for img_url in imgurl_list:headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}# 调用get_ip函数,获取代理IPproxies = get_ip()# 每次发送请求换代理IP,获取图片,防止被封img_data = requests.get(url=img_url, headers=headers, proxies=proxies).content# 拼接图片存放地址和名字img_path = './小姐姐/' + str(n) + '.jpg'# 将图片写入指定位置with open(img_path, 'wb') as f:f.write(img_data)# 图片编号递增n = n + 1if __name__ == '__main__':# 1. 设置获取的页数page_number = 50imgurl_list = [] # 用于存储所有的图片链接# 2. 循环构建每页的链接for i in range(1,page_number+1):# 第一页固定,后面页数拼接if i ==1:url = 'https://pic.netbian.com/4kmeinv/index.html'else:url = f'https://pic.netbian.com/4kmeinv/index_{i}.html'# 3. 获取图片链接get_imgurl_list(url,imgurl_list)# 4. 下载图片get_down_img(imgurl_list)
运行结果:

下载成功了没有报错,代理IP的质量还是不错的!!!
5.7 免费代理不够用怎么办?
免费的代理不够用可以看看云立方家的套餐还是蛮便宜的:http://www.yunlifang.cn/dailiIP.asp

六、总结
代理IP对于爬虫是密不可分的,代理IP可以帮助爬虫隐藏真实IP地址,有需要代理IP的小伙伴可以试试云立方家的代理IP:云立方代理IP

相关文章:
Python爬虫实战(六)——使用代理IP批量下载高清小姐姐图片(附上完整源码)
文章目录 一、爬取目标二、实现效果三、准备工作四、代理IP4.1 代理IP是什么?4.2 代理IP的好处?4.3 获取代理IP4.4 Python获取代理IP 五、代理实战5.1 导入模块5.2 设置翻页5.3 获取图片链接5.4 下载图片5.5 调用主函数5.6 完整源码5.7 免费代理不够用怎…...
【操作系统】考研真题攻克与重点知识点剖析 - 第 1 篇:操作系统概述
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...
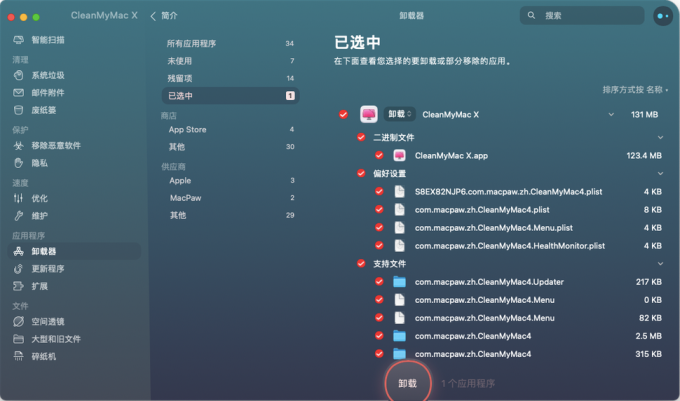
Mac删除照片快捷键ctrl加什么 Mac电脑如何批量删除照片
Mac电脑是很多人喜欢使用的电脑,它有着优美的设计、高效的性能和丰富的功能。如果你的Mac电脑上存储了很多不需要的照片,那么你可能会想要删除它们,以节省空间和提高速度。那么,Mac删除照片快捷键ctrl加什么呢?Mac电脑…...

数据安全认证:保护您的数据安全的关键步骤
随着信息技术的飞速发展,数据安全问题日益凸显。数据泄露、网络攻击等事件频发,给企业和个人带来极大的损失。因此,数据安全认证成为保护数据安全的重要措施。本文将探讨数据安全认证的重要性、认证流程和相关标准,以期帮助读者更…...
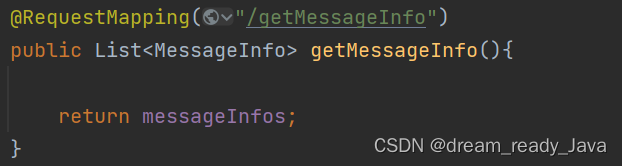
表白墙/留言墙 —— 初级SpringBoot项目,练手项目前后端开发(带完整源码) 全方位全步骤手把手教学
🧸欢迎来到dream_ready的博客,📜相信你对这篇博客也感兴趣o (ˉ▽ˉ;) 用户登录前后端开发(一个简单完整的小项目)——SpringBoot与session验证(带前后端源码)全方位全流程超详细教程 目录 项目前端页面展…...

【海德教育】报考建筑八大员需要满足下列条件:
1 、初级(具备以下条塌氏件之一) ( 1 )本专业或相关专业中专以上学历竖陆。 ( 2 )从事本职业工作 2 年以上。 2 、中级(具备以下条件之一) ( 1 )本专业或相关专业大专以上学历。 ( 2 )连续从事本职业工作 4 年以上。 ( 3 )取得余衫顷本职业初级证书,从事本职业工作 …...
酷开科技,让家庭更有温度!
生活中总有一些瞬间,会让我们感到无比温暖和幸福。一个拥抱、一句问候、一杯热茶,都能让我们感受到家庭的温馨和关爱。酷开科技也用自己的方式为我们带来了独属于科技的温暖,通过全新的体验将消费者带进一个充满惊喜的世界,让消费…...
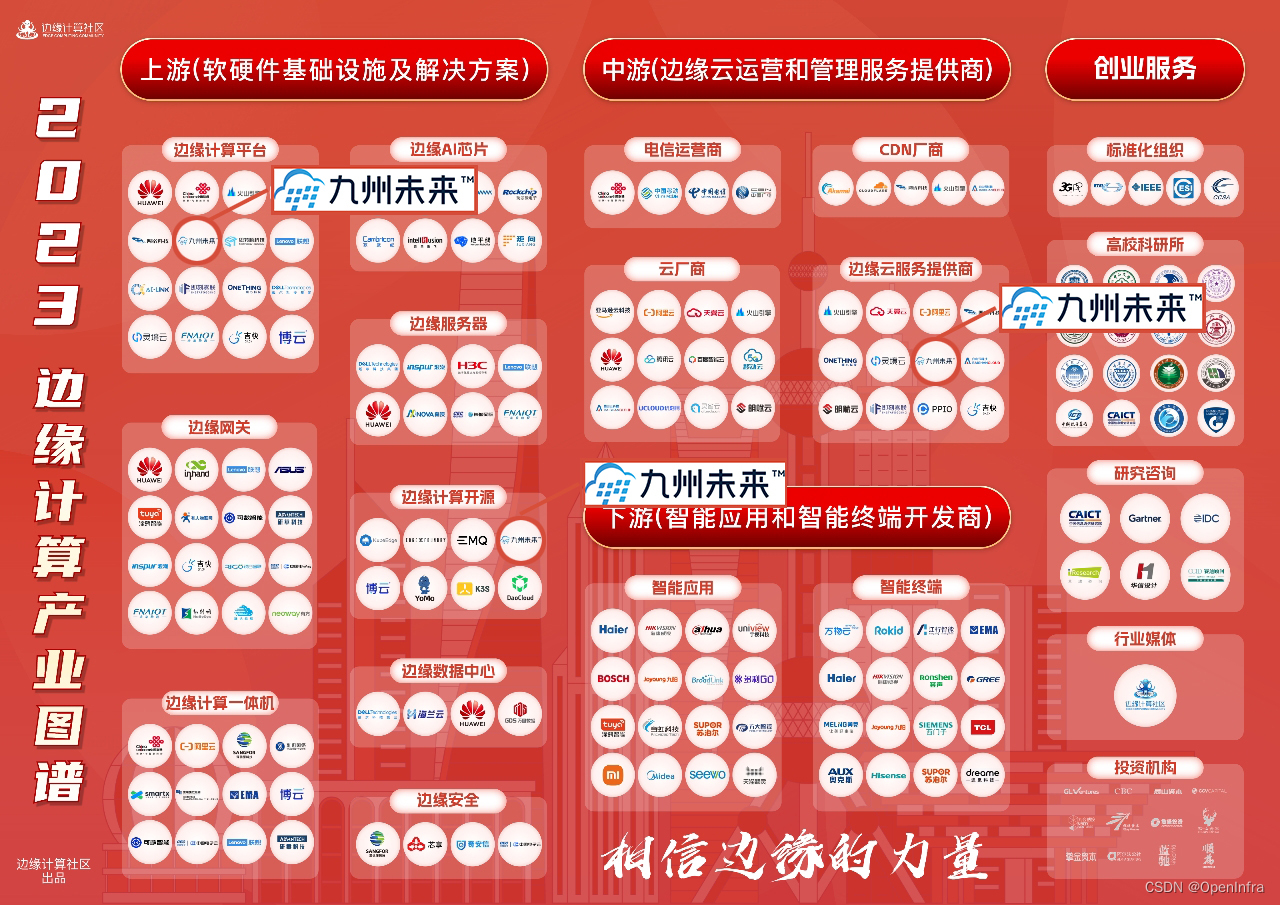
九州未来入选“2023边缘计算产业图谱”三大细分领域
10月26日,边缘计算社区正式发布《2023边缘计算产业图谱》,九州未来凭借深厚的技术积累、优秀的产品服务、完善的产品解决方案体系以及开源贡献,实力入选图谱——边缘计算平台、边缘计算开源、边缘云服务提供商三大细分领域,充分彰…...
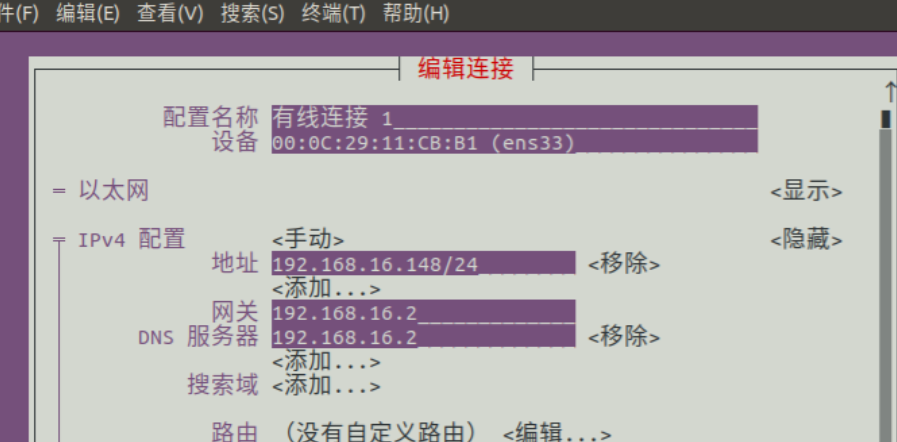
centos ubantu IP一直变化,远程连接不上问题
文章目录 一、为什么IP地址会变1.主机DHCP导致 二、解决IP地址变化1.centos2.ubantu 总结 虚拟机能连接为互联网,但下一次启动IP地址再发生变化,无法使用ssh远程连接 一、为什么IP地址会变 1.主机DHCP导致 虚拟机系统(ubantu,centos…)启动后会向本地申请IP地址租约,租聘的I…...

多线程---JUC
文章目录 什么是JUC?Callable接口ReentrantLockReentrantLock VS synchronized 原子类线程池信号量SemaphoreCountDownLatch 什么是JUC? JUC是:java.util.concurrent这个包名的缩写。它里面包含了与并发相关,即与多线程相关的很多…...

事务隔离级别
隔离级别 概念理解 事务的概念 事务是数据库管理系统中的一个基本单位,它代表了一组数据库操作。 事务是一个不可分割的工作单元,要么全部成功执行,要么全部失败回滚。 事务的目标是确保数据库的一致性、隔离性、持久性和原子性ÿ…...

centos7安装配置及Linux常用命令
目录 一.centos7的安装 1.1centos7的简介 1.2步骤 编辑 1.3登录 编辑 1.4MobaXterm使用 二.Linux常用命令&模式 1.1 常用命令 1.2 三种模式 命令模式 编辑模式 末行模式 1.3 命令使用&换源 换源 1.4 拍照备份 一.centos7的安装 1.1centos7的简…...

C语言调用lua
C语言是一种非常流行的编程语言,而Lua是一种基于C语言开发的脚本语言。相信大家都知道,Lua可以使用C语言来扩展其功能,进而实现更复杂的功能。而在Lua的各种实现中,luajit也是其中一种非常流行的实现。在本篇博客中,我…...
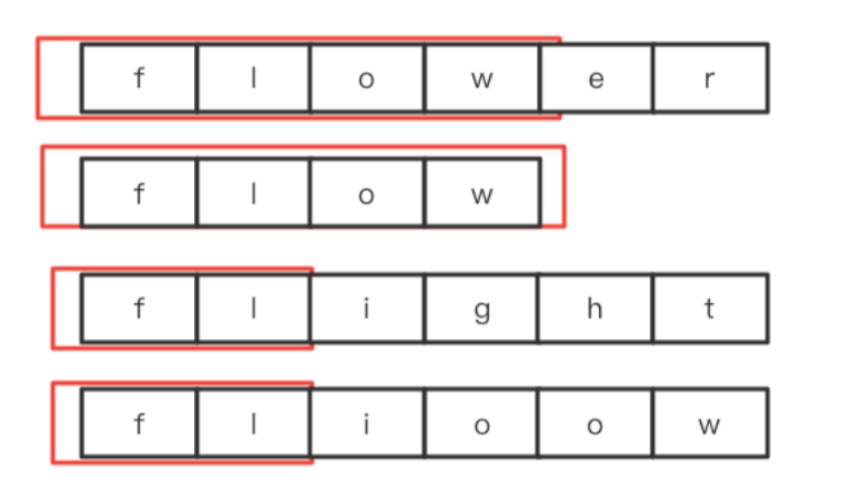
算法通关村第十二关黄金挑战——最长公共前缀问题解析
大家好,我是怒码少年小码。 最长公共前缀 LeetCode 14:编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例: 输入:strs [“flower”,“flow”,“flight”]输出ÿ…...
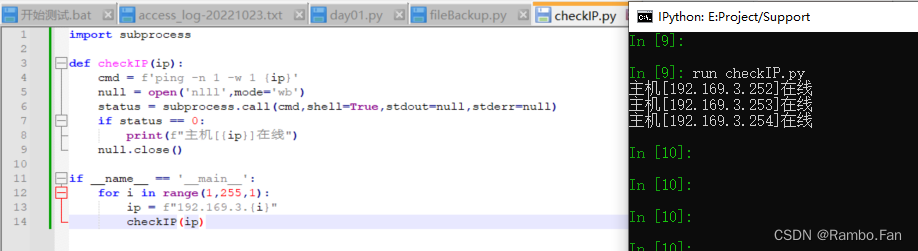
Python运维学习Day02-subprocess/threading/psutil
文章目录 1. 检测网段在线主机2. 获取系统变量的模块 psutil 1. 检测网段在线主机 import subprocessdef checkIP(ip):cmd fping -n 1 -w 1 {ip}null open(nlll,modewb)status subprocess.call(cmd,shellTrue,stdoutnull,stderrnull)if status 0:print(f"主机[{ip}]在…...

开源库存管理系统InvenTree的安装
本文是应网友 shijie880500 要求折腾的; 什么是 InvenTree ? InvenTree 是一个开源的库存管理系统,提供强大的低级别库存控制和零件跟踪。InvenTree 系统的核心是 Python/Django 数据库后端,它提供了一个管理界面(基于…...
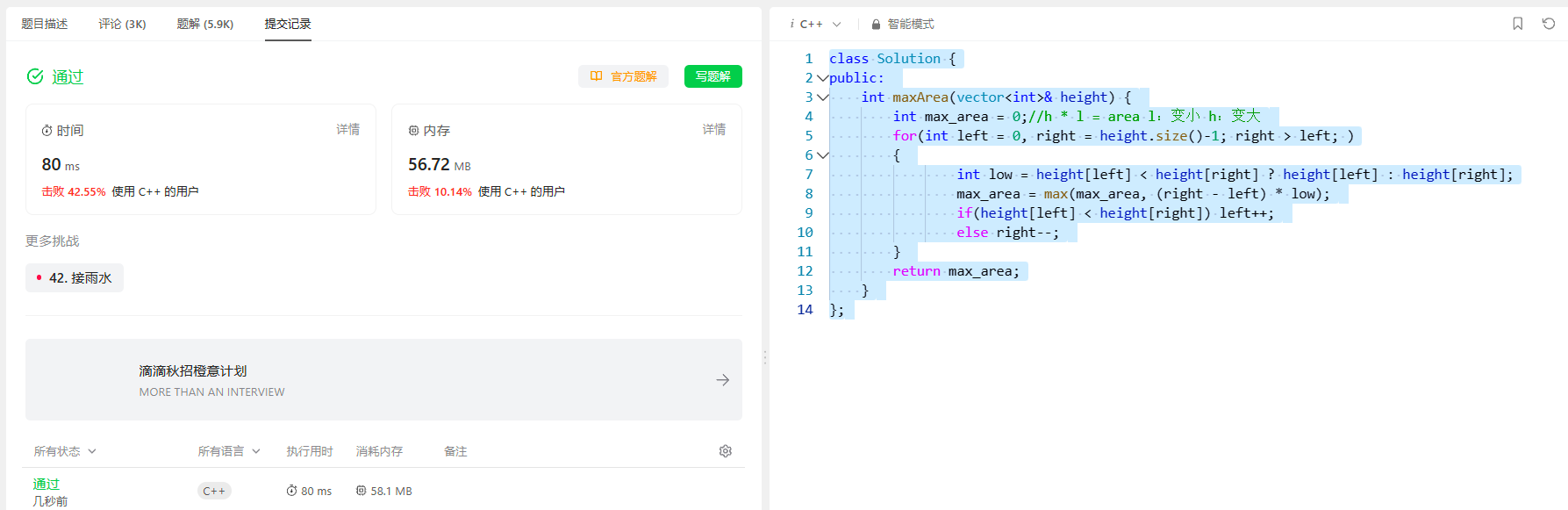
[双指针] (二) LeetCode 202.快乐数 和 11.盛最多水的容器
[双指针] (二) LeetCode 202.快乐数 和 11.盛最多水的容器 快乐数 202. 快乐数 题目解析 (1) 判断一个数是不是快乐数 (2) 快乐数的定义:将整数替换为每个位上的和;如果最终结果为1,就是快乐数 (3) 这个数可能变为1,也可能无…...
)
前端、HTTP协议(重点)
什么是前端 前端是所有跟用户直接打交道的都可以称之为是前端 比如:PC页面、手机页面、平板页面、汽车显示屏、大屏幕展示出来的都是前端内容 能够用肉眼看到的都是前端 为什么要学前端 学了前端以后我们就可以做全栈工程师(会后端、会前端、会DB、会运维等) 咱…...

软件开发项目文档系列之六概要设计:构建可靠系统的蓝图
概要设计是软件开发项目中至关重要的阶段,它为整个系统提供了设计蓝图和技术方向。它的重要性在于明确项目目标、规划系统结构、确定技术选择、识别风险、以及为团队提供共同的视角,确保项目在后续开发阶段按计划进行。概要设计的主要内容包括项目的背景…...

[C++]命名空间等——喵喵要吃C嘎嘎
希望你开心,希望你健康,希望你幸福,希望你点赞! 最后的最后,关注喵,关注喵,关注喵,大大会看到更多有趣的博客哦!!! 喵喵喵,你对我真的…...

UG许可排队严重?研发软件许可共享,盘活企业资产
我干IT这十年,见过太多公司因为许可证管理不当,堵在路上的效率和成本。2026年咱们行业平均许可证利用率只有42%,烂尾的项目不少,换算成直接损失,一个中型研发团队每年光工时浪费就抵得上一整个外包团队的薪酬。许可证到…...

体验Taotoken多模型路由带来的高稳定性与低延迟响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型路由带来的高稳定性与低延迟响应 在构建依赖大模型能力的应用时,开发者最关心的两个核心指标往往是…...

离散数学自然推理系统通关秘籍:从零开始手把手教你搞定Educoder所有证明题
离散数学自然推理系统通关秘籍:从零到精通的实战指南 1. 自然推理系统入门基础 对于初次接触离散数学自然推理系统的学习者来说,那些复杂的符号和规则往往让人望而生畏。但请记住,每个专家都曾是初学者。自然推理系统本质上是一种形式化的逻…...

长期项目使用Taotoken聚合API在稳定性与成本上的综合感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期项目使用Taotoken聚合API在稳定性与成本上的综合感受 在最近一个持续数月的实际开发项目中,我们选择将Taotoken作为…...

CANN/cann-bench MHA算子API描述
MHA 算子 API 描述 【免费下载链接】cann-bench 评测AI在处理CANN领域代码任务的能力,涵盖算子生成、算子优化等领域,支撑模型选型、训练效果评估,统一量化评估标准,识别Agent能力短板,构建CANN领域评测平台࿰…...
)
手把手教你搞定Windows下的NAMD和VMD安装(附最新版下载与注册避坑指南)
Windows平台NAMD与VMD安装全攻略:从零开始玩转分子动力学模拟 当第一次接触分子动力学模拟时,软件安装往往是新手面临的第一个挑战。NAMD和VMD作为该领域最常用的工具组合,它们的安装过程看似简单,实则暗藏诸多细节。本文将带你从…...

为汉语辩护,彰显中华文字的生命力与优越性
为汉语辩护,彰显中华文字的生命力与优越性上世纪初,一批所谓“新文化人”竟提出废除汉字的主张,他们盲目推崇拉丁文,认为汉语是落后的语言,却不知这是对中华文字深厚底蕴的无知与曲解。如今回望,汉字的独特…...
)
PTA数据结构天梯赛L2-001:手把手教你用Dijkstra算法搞定双权值最短路径(附C语言完整代码)
PTA数据结构天梯赛L2-001:双权值最短路径的Dijkstra算法实战解析 在算法竞赛和数据结构课程中,图论问题一直是考察重点和难点。面对PTA天梯赛L2-001这类需要同时考虑时间和距离两个权值的最短路径问题,传统的单权值Dijkstra算法需要经过巧妙…...

【Perplexity专利搜索黄金法则】:20年资深IP专家首度公开3大反直觉检索技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity专利搜索黄金法则的底层逻辑 Perplexity 作为基于语言模型的智能搜索工具,其在专利检索场景中的卓越表现并非源于简单关键词匹配,而是植根于对专利文本结构化语义、法…...

Android MediaCodec解码实战:从H.264文件到ImageView,同步与异步模式代码对比与避坑指南
Android MediaCodec解码实战:同步与异步模式深度解析与性能优化 在移动端视频处理领域,Android MediaCodec作为系统级硬件加速接口,一直是开发者实现高效视频解码的首选方案。但面对同步与异步两种工作模式的选择,许多中高级开发者…...