【数据挖掘实战】——中医证型的关联规则挖掘(Apriori算法)

目录
一、背景和挖掘目标
1、问题背景
2、传统方法的缺陷
3、原始数据情况
4、挖掘目标
二、分析方法和过程
1、初步分析
2、总体过程
第1步:数据获取
第2步:数据预处理
第3步:构建模型
三、思考和总结
项目地址:Datamining_project: 数据挖掘实战项目代码
一、背景和挖掘目标
1、问题背景
- 中医药治疗乳腺癌有着广泛的适应证和独特的优势。从整体出发,调整机体气血、阴阳、脏腑功能的平衡,根据不同的临床证候进行辨证论治。确定“先证而治”的方向:即后续证侯尚未出现之前,需要截断恶化病情的哪些后续证侯。
- 找出中医症状间的关联关系和诸多症状间的规律性,并且依据规则分析病因、预测病情发展以及为未来临床诊治提供有效借鉴。能够帮助乳腺癌患者手术后体质的恢复、生存质量的改善,有利于提高患者的生存机率。
2、传统方法的缺陷
- 中医辨证极为灵活,虽能够处理患者的复杂多变的临床症状,体现出治疗优势。但缺乏统一的规范,难以做到诊断的标准化。
- 疾病的复杂性和体质的差异性,造成病人大多是多种证素兼夹复合。临床医师可能会被自身的经验所误导,单纯对症治疗,违背了中医辨证论治的原则。
- 同一种疾病的辨证分型,往往都有不同见解,面对临床症状不典型的患者,初学者很难判断。
3、原始数据情况

患者信息数据:包含患者的基本信息以及病理症状等。

4、挖掘目标
- 借助三阴乳腺癌患者的病理信息,挖掘患者的症状与中医证型之间的关联关系;
- 对截断治疗提供依据,挖掘潜性证素。
二、分析方法和过程
1、初步分析
- 针对乳腺癌患者,可运用中医截断疗法进行治疗,在辨病的基础上围绕各个病程的特殊证候先证而治型;
- 依据医学指南,将乳腺癌辨证统一化,为六种证型。且患者在围手术期、围化疗期、围放疗期和内分泌治疗期等各个病程阶段,基本都会出现特定的临床症状。
- 通过关联规则算法,挖掘各中医证素与乳腺癌TNM分期之间的关系。探索不同分期阶段的三阴乳腺癌患者的中医证素分布规律,以及截断病变发展、先期干预的治疗思路,指导三阴乳腺癌的中医临床治疗。
2、总体过程
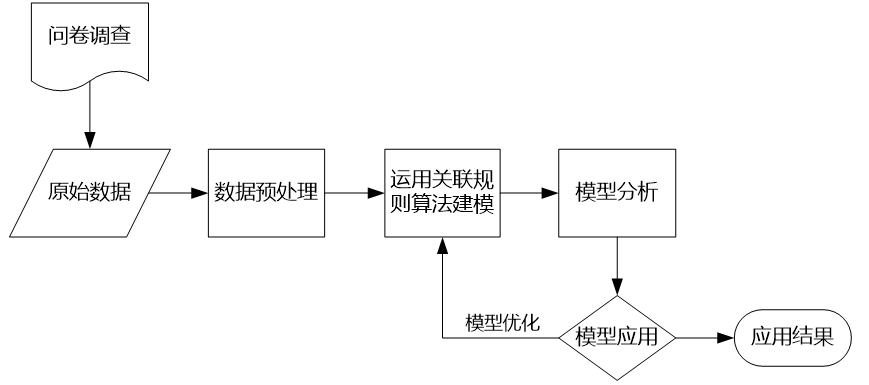
第1步:数据获取
- 拟定调查问卷表并形成原始指标表;
- 定义纳入标准与排除标准;
- 将收集回来的问卷表整理成原始数据。
- 问卷信息采集者均要求有中医诊断学基础,能准确识别病人的舌苔脉象,用通俗的语言解释医学术语,并确保患者信息填写准确;
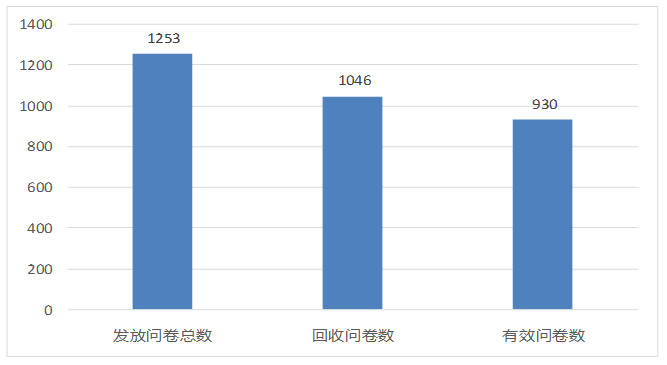
- 问卷调查对象必须是三阴乳腺癌患者,他们是某省中医院以及肿瘤医院等各大医院各病程阶段1253位三阴乳腺癌患者。
拟定调查问卷表并形成原始指标表:
定义纳入标准与排除标准:
| 标准 | 详细信息 |
| 纳入标准 | 病理诊断为乳腺癌。 病历完整,能提供既往接受检查、治疗等相关信息, 包括发病年龄、月经状态、原发肿瘤大小、区域淋巴结状态、 组织学类型、组织学分级、P53表达、VEGF表达等, 作为临床病理及肿瘤生物学的特征指标。 没有精神类疾病,能自主回答问卷调查者。 |
| 排除标准 | 本研究中临床、病理、肿瘤生物学指标不齐全者。 存在第二肿瘤(非乳腺癌转移)。 精神病患者或不能自主回答问卷调查者。 不愿意参加本次调查者或中途退出本次调查者。 填写的资料无法根据诊疗标准进行分析者。 |
第2步:数据预处理
2.属性规约:删除不相关属性,选取其中六种证型得分、患者编号和TNM分期属性。
| 患者 编号 | 肝气郁结证得分 | 热毒蕴结证得分 | 冲任失调证得分 | 气血两虚证得分 | 脾胃虚弱证得分 | 肝肾阴虚证得分 | TNM分期 |
| 20140001 | 7 | 30 | 7 | 23 | 18 | 17 | H4 |
| 20140179 | 12 | 34 | 12 | 16 | 19 | 5 | H4 |
| …… | …… | …… | …… | …… | …… | …… | …… |
| 20140930 | 4 | 4 | 12 | 12 | 7 | 15 | H4 |

数据离散化:Apriori关联规则算法无法处理连续性数值变量,对数据进行离散化。本例采用聚类算法对各个证型系数进行离散化处理,将每个属性聚成四类。
聚类离散化,最后的result的格式为:
1 2 3 4 A 0 0.178698 0.257724 0.351843 An 240 356.000000 281.000000 53.000000 即(0, 0.178698]有240个,(0.178698, 0.257724]有356个,依此类推。
from __future__ import print_function
import pandas as pd
from sklearn.cluster import KMeans # 导入K均值聚类算法datafile = '../data/data.xls' # 待聚类的数据文件
processedfile = '../tmp/data_processed.xls' # 数据处理后文件
typelabel = {u'肝气郁结证型系数': 'A', u'热毒蕴结证型系数': 'B', u'冲任失调证型系数': 'C', u'气血两虚证型系数': 'D',u'脾胃虚弱证型系数': 'E', u'肝肾阴虚证型系数': 'F'}
k = 4 # 需要进行的聚类类别数# 读取数据并进行聚类分析
data = pd.read_excel(datafile) # 读取数据
keys = list(typelabel.keys())
result = pd.DataFrame()if __name__ == '__main__': # 判断是否主窗口运行,如果是将代码保存为.py后运行,则需要这句,如果直接复制到命令窗口运行,则不需要这句。for i in range(len(keys)):# 调用k-means算法,进行聚类离散化print(u'正在进行“%s”的聚类...' % keys[i])kmodel = KMeans(n_clusters=k, n_jobs=4) # n_jobs是并行数,一般等于CPU数较好kmodel.fit(data[[keys[i]]].as_matrix()) # 训练模型r1 = pd.DataFrame(kmodel.cluster_centers_, columns=[typelabel[keys[i]]]) # 聚类中心r2 = pd.Series(kmodel.labels_).value_counts() # 分类统计r2 = pd.DataFrame(r2, columns=[typelabel[keys[i]] + 'n']) # 转为DataFrame,记录各个类别的数目r = pd.concat([r1, r2], axis=1).sort(typelabel[keys[i]]) # 匹配聚类中心和类别数目r.index = [1, 2, 3, 4]r[typelabel[keys[i]]] = pd.rolling_mean(r[typelabel[keys[i]]], 2) # rolling_mean()用来计算相邻2列的均值,以此作为边界点。r[typelabel[keys[i]]][1] = 0.0 # 这两句代码将原来的聚类中心改为边界点。result = result.append(r.T)result = result.sort() # 以Index排序,即以A,B,C,D,E,F顺序排result.to_excel(processedfile)第3步:构建模型
1、中医证型关联模型:

import pandas as pd
from sklearn.cluster import KMeansdatafile = 'data.xls' # 待聚类的数据文件
processedfile = 'data_processed.xlsx' # 处理后的文件
typelabel = {'肝气郁结证型系数':'A', '热毒蕴结证型系数':'B', '冲任失调证型系数':'C', '气血两虚证型系数':'D', '脾胃虚弱证型系数':'E','肝肾阴虚证型系数':'F'}
k = 4 # 需要的聚类类别数# 读取数据并且进行聚类
data = pd.read_excel(datafile)
keys = list(typelabel.keys())
result = pd.DataFrame()if __name__ == '__main__': # 判断是否主窗口运行'''当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。'''for i in range(len(keys)): # 调用k-means算法,进行聚类离散化print('正在进行 "%s" 的聚类...' % keys[i])kmodel = KMeans(n_clusters=k)kmodel.fit(data[[keys[i]]].values) # 训练模型r1 = pd.DataFrame(kmodel.cluster_centers_, columns=[typelabel[keys[i]]]) # 聚类中心r2 = pd.Series(kmodel.labels_).value_counts() # 分类统计r2 = pd.DataFrame(r2, columns=[typelabel[keys[i]]+'n']) # 转为DataFrame,记录各个类别的数目r = pd.concat([r1, r2], axis=1).sort_values(by= typelabel[keys[i]]) # 匹配聚类中心和类别数目,并按值排序r.index = [1, 2, 3, 4]r[typelabel[keys[i]]] = r[typelabel[keys[i]]].rolling(2).mean() # rolling().mean()用来计算相邻2列的均值,以此作为边界点r[typelabel[keys[i]]][1] = 0.0 # 将原来的聚类中心改为边界点result = result.append(r.T)result = result.sort_index() # 以index排序,即以ABCDEF排序result.to_excel(processedfile)
 聚类之后的结果:
聚类之后的结果:
Apriori关联规则算法
#-*- coding: utf-8 -*-
from __future__ import print_function
import pandas as pd#自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):x = list(map(lambda i:sorted(i.split(ms)), x))l = len(x[0])r = []for i in range(len(x)):for j in range(i,len(x)):if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))return r#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果support_series = 1.0*d.sum()/len(d) #支持度序列column = list(support_series[support_series > support].index) #初步根据支持度筛选k = 0while len(column) > 1:k = k+1print(u'\n正在进行第%s次搜索...' %k)column = connect_string(column, ms)print(u'数目:%s...' %len(column))sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).Tsupport_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选support_series = support_series.append(support_series_2)column2 = []for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?i = i.split(ms)for j in range(len(i)):column2.append(i[:j]+i[j+1:]+i[j:j+1])cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列for i in column2: #计算置信度序列cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选result[i] = 0.0result[i]['confidence'] = cofidence_series[i]result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出print(u'\n结果为:')print(result)return result首先设置建模参数最小支持度、最小置信度,输入建模样本数据。然后采用Apriori关联规则算法对建模的样本数据进行分析,以模型参数设置的最小支持度、最小置信度以及分析目标作为条件,如果所有的规则都不满足条件,则需要重新调整模型参数,否则输出关联规则结果。
import pandas as pd
# from apriori import * # 导入自行编写的高效的Apriori函数
import time # 导入时间库用来计算用时inputfile = 'apriori.txt' # 输入事务集文件
data = pd.read_csv(inputfile, header=None, dtype=object)start = time.perf_counter() # 计时开始(新版本不支持clock,用time.perf_counter()替换)
print('\n转换原始数据至0-1矩阵')
ct = lambda x : pd.Series(1, index=x[pd.notnull(x)]) # 转换0-1矩阵的过渡函数,即将标签数据转换为1
b = map(ct, data.values) # 用map方式执行# Dataframe参数不能是迭代器
c = list(b)
data = pd.DataFrame(c).fillna(0) # 实现矩阵转换,除了1外,其余为空,空值用0填充
end = time.perf_counter() # 计时结束
print('\n转换完毕,用时:%0.2f秒' % (end-start))
del b # 删除中间变量b,节省内存support = 0.06 # 最小支持度
confidence = 0.75 # 最小置信度
ms = '---' # 连接符,默认'--',用来区分不同元素,如A--B,需要保证原始表格不含有该字符start = time.perf_counter() # 计时开始
print('\n开始搜索关联规则')
find_rule(data, support, confidence, ms)
end = time.perf_counter() # 计时结束
print('\n转换完毕,用时:%0.2f秒' % (end-start))
2、模型分析
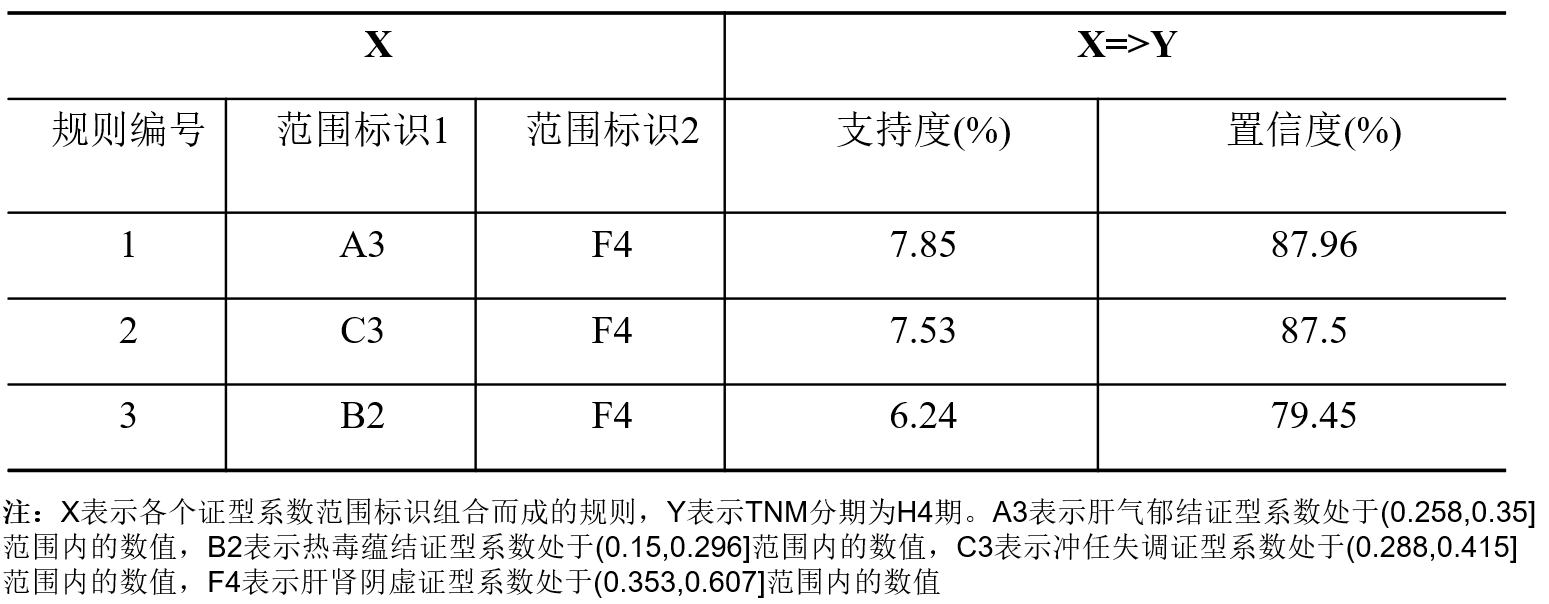
TNM分期为H4期的三阴乳腺癌患者证型主要为肝肾阴虚证、热毒蕴结证、肝气郁结证和冲任失调,H4期患者肝肾阴虚证和肝气郁结证的临床表现较为突出,其置信度最大达到87.96%。
3、模型应用
根据关联结果,结合实际情况,为患者未来的症治提供有效的帮助。
a)IV期患者出现肝肾阴虚证之表现时,应当以滋养肝肾为补,清热解毒为攻,攻补兼施,截断热毒蕴结证的出现。
b)患者多有肝气郁结证的表现,治疗时须重视心理调适,对其进行身心一体的综合治疗。
三、思考和总结
1、Python的流行库中都没有自带的关联规则函数,相应的关联规则函数,函数依赖于Pandas库。该函数是很高效的(就实现Apriori算法而言),可作为工具函数在需要时使用。
- 2、Apriori算法的关键两步为找频繁集与根据置信度筛选规则,明白这两步过程后,才能清晰的编写相应程序。
- 3、本案例采用聚类的方法进行数据离散化,其他的离散化方法如:等距、等频、决策树、基于卡方检验等,试比较各个方法的优缺点。
相关文章:
【数据挖掘实战】——中医证型的关联规则挖掘(Apriori算法)
目录 一、背景和挖掘目标 1、问题背景 2、传统方法的缺陷 3、原始数据情况 4、挖掘目标 二、分析方法和过程 1、初步分析 2、总体过程 第1步:数据获取 第2步:数据预处理 第3步:构建模型 三、思考和总结 项目地址:Data…...
一些硬件学习的注意事项与快捷方法
xilinx系列软件 系统适用版本 要安装在Ubuntu系统的话,要注意提前看好软件适用的版本,不要随便安好了Ubuntu系统又发现对应版本的xilinx软件不支持。 如下图,发行说明中会说明这个版本的软件所适配的系统版本。 下载 vivado vitis这些都可以…...
【Tomcat】Tomcat安装及环境配置
文章目录什么是Tomcat为什么我们需要用到Tomcattomcat下载及安装1、进入官网www.apache.org,找到Projects中的project List2、下载之后,解压3、找到tomcat目录下的startup.bat文件,双击之后最后结果出现多少多少秒,表示安装成功4、…...
负载均衡:LVS 笔记(二)
文章目录LVS 二层负载均衡机制LVS 三层负载均衡机制LVS 四层负载均衡机制LVS 调度算法轮叫调度(RR)加权轮叫调度(WRR)最小连接调度(LC)加权最小连接调度(WLC)基于局部性的最少链接调…...
SEO优化:干货技巧分享,包新站1-15天100%收录首页
不管是老域名还是新域名,不管是多久没有收录首页的站,此法周期7-30天,包首页收录!本人不喜欢空吹牛逼不实践的理论,公布具体操作:假如你想收录的域名是a.com,那么准备如下材料1.购买5-10个最便宜…...

JavaWeb测试题
【第四小组】【姓名:郑梦飞】说明:上方【组】填入所在的组,上方【姓名】填入自己的真实姓名。答题方式,基于Word文档基础上答题编程题可利用工具编程完以后,复制到该文档内。答完以后,导成PDF。以姓名.PDF命…...
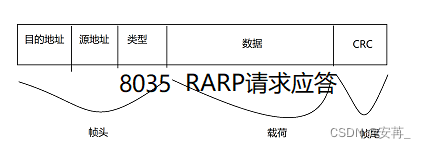
Java EE|TCP/IP协议栈之数据链路层协议详解
文章目录一、数据链路层协议感性认识数据链路层简介以太网简介特点二、以太网数据帧格式详解帧头不同类型对应的载荷三、关于MTU什么是MTUMTU有什么作用ip分片(了解)参考一、数据链路层协议感性认识 数据链路层简介 从上图可以看出 , 在TCP/…...
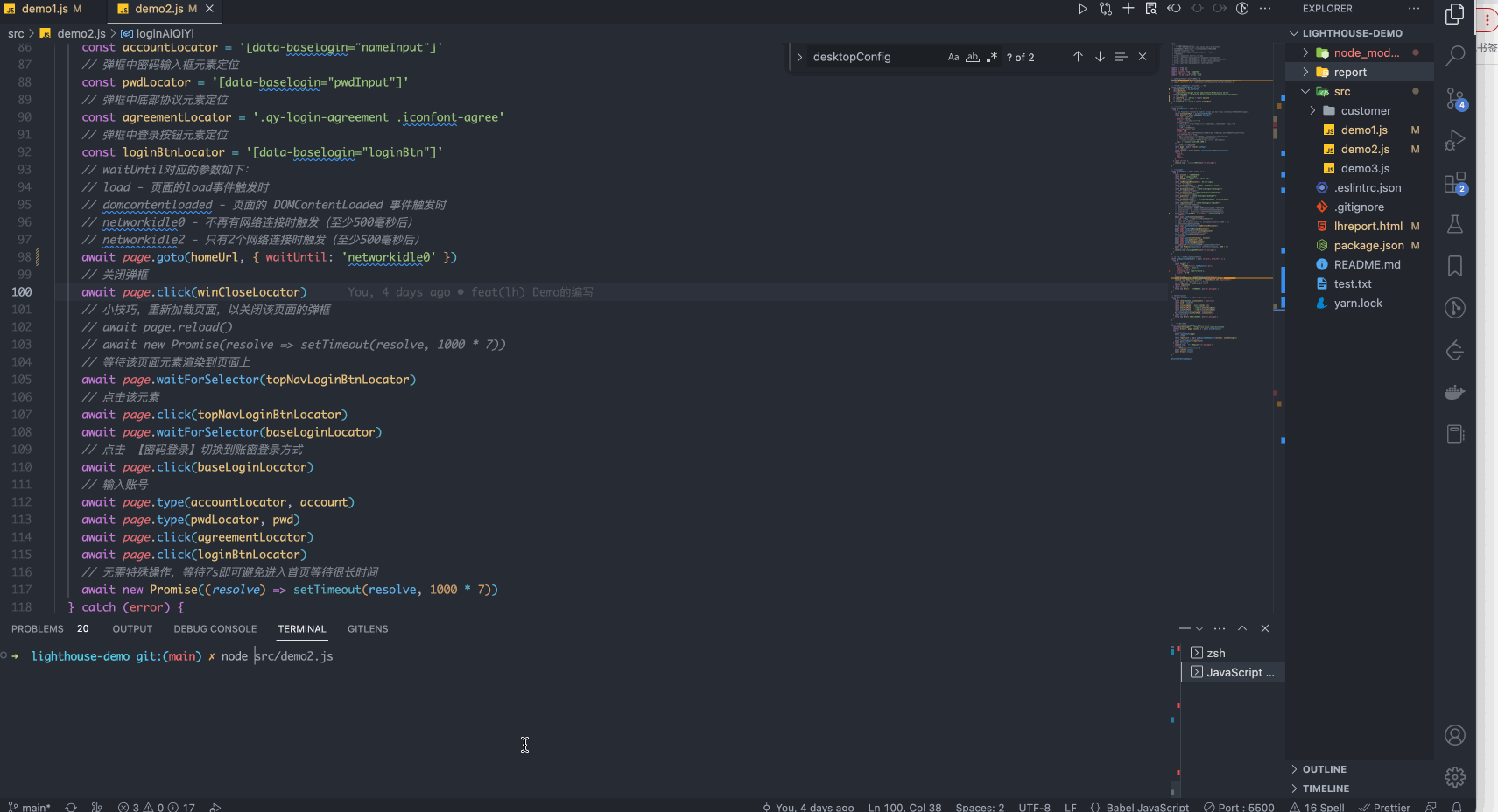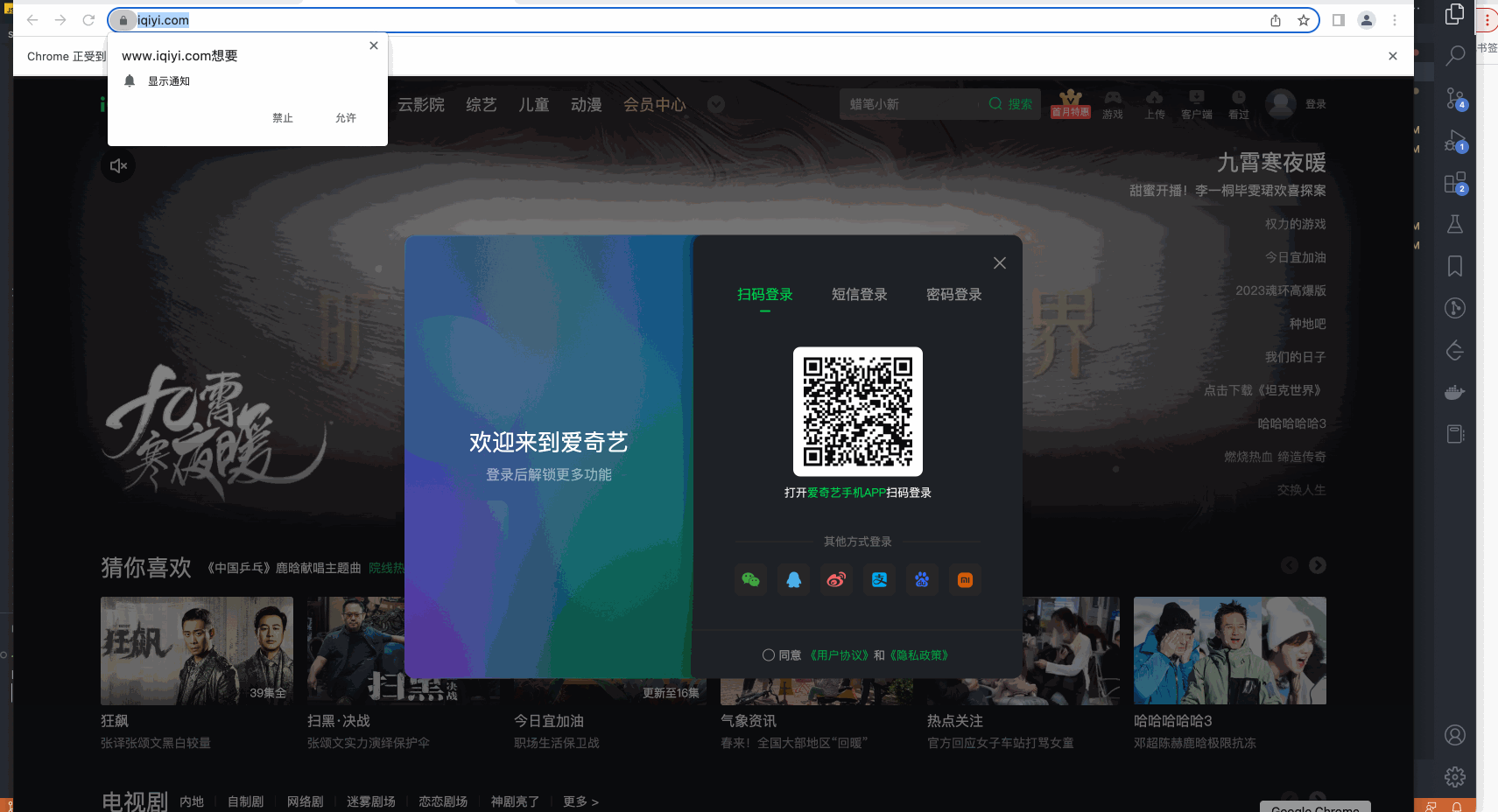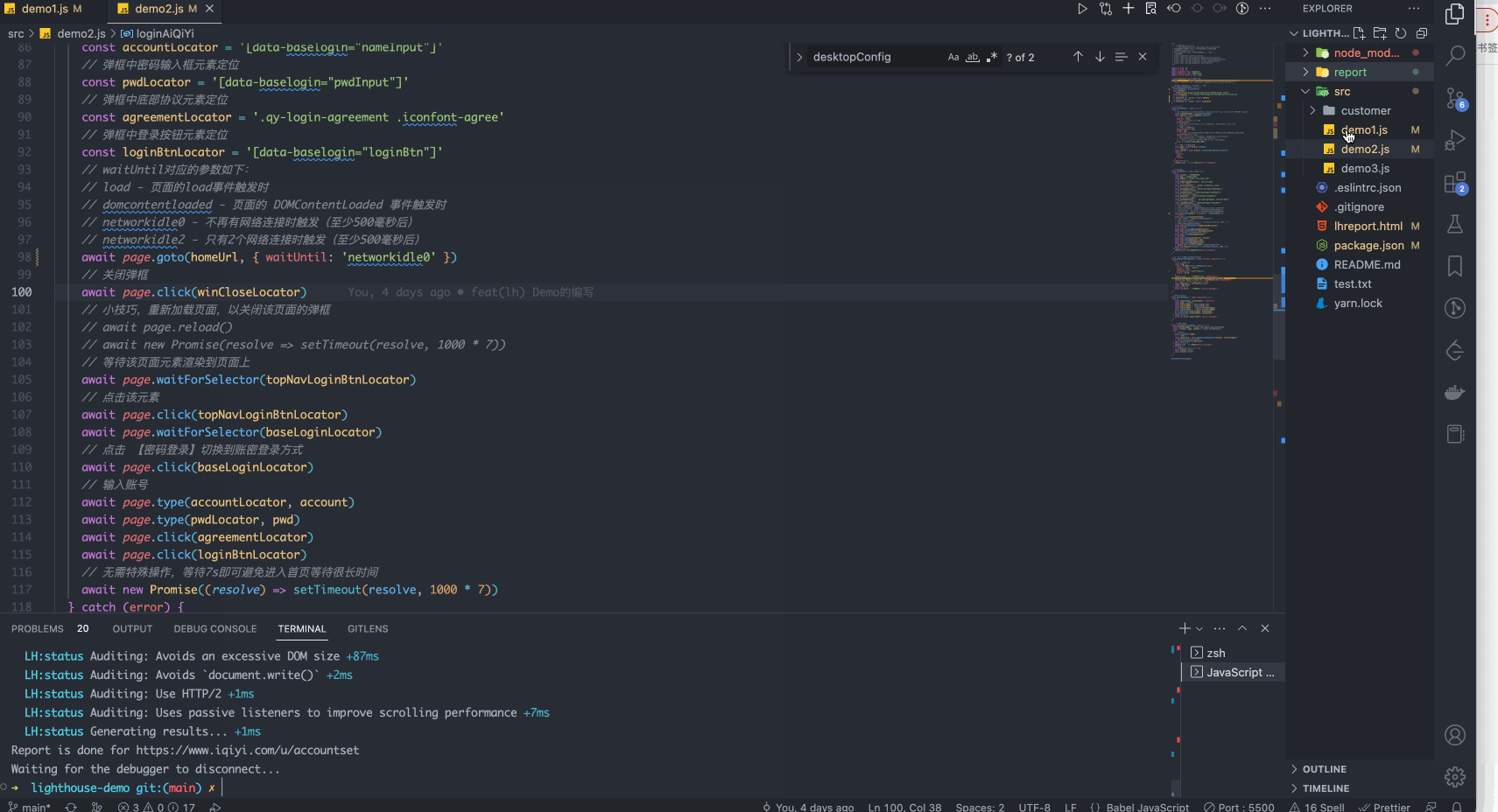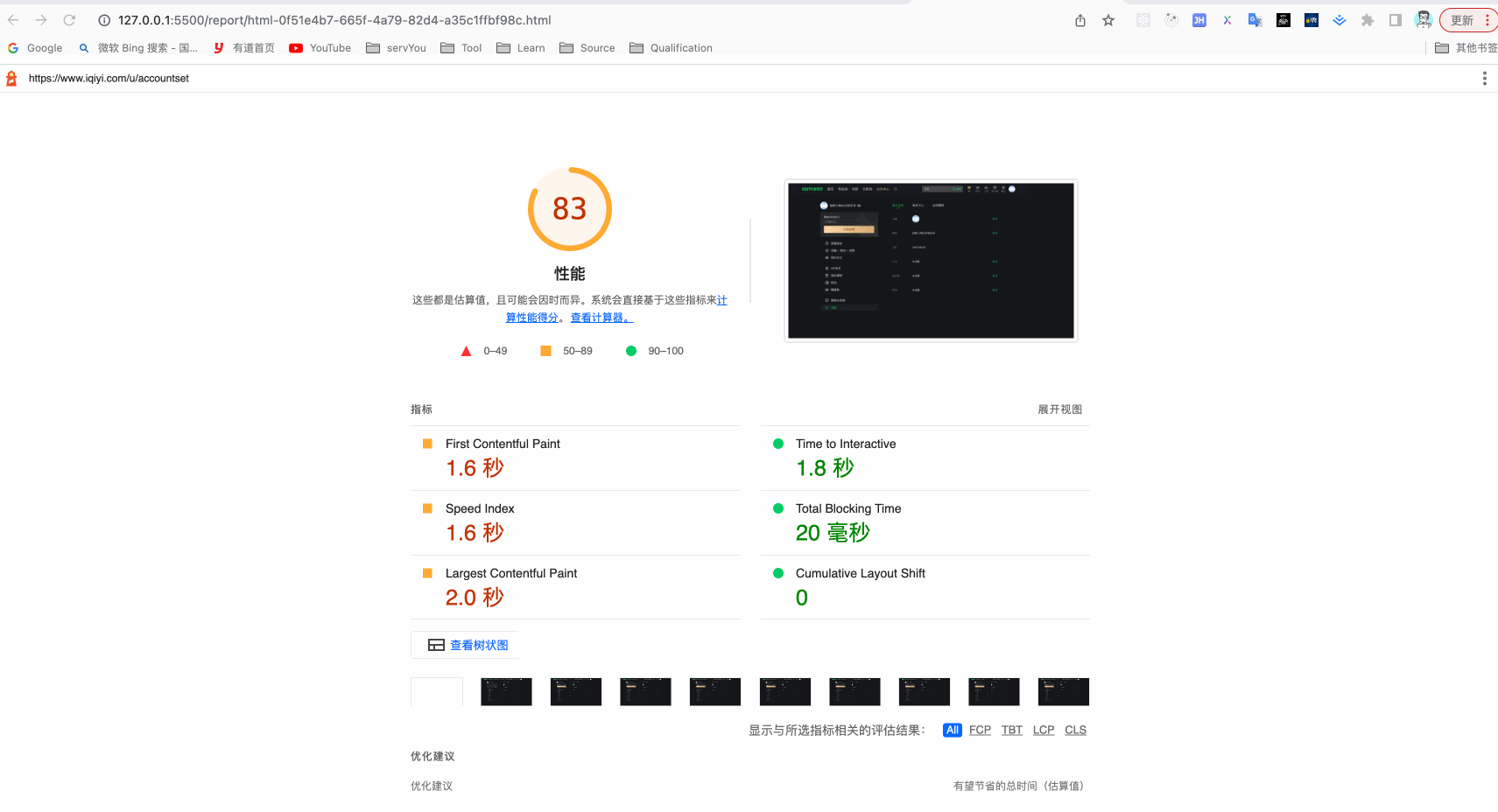
Lighthouse组合Puppeteer检测页面
如上一篇文章lighthouse的介绍和基本使用方法结尾提到的一样,我们在实际使用Lighthouse检测页面性能时,通常需要一定的业务前置条件,比如最常见的登录操作、如果没有登录态就没有办法访问其他页面。再比如有一些页面是需要进行一系列的操作&a…...
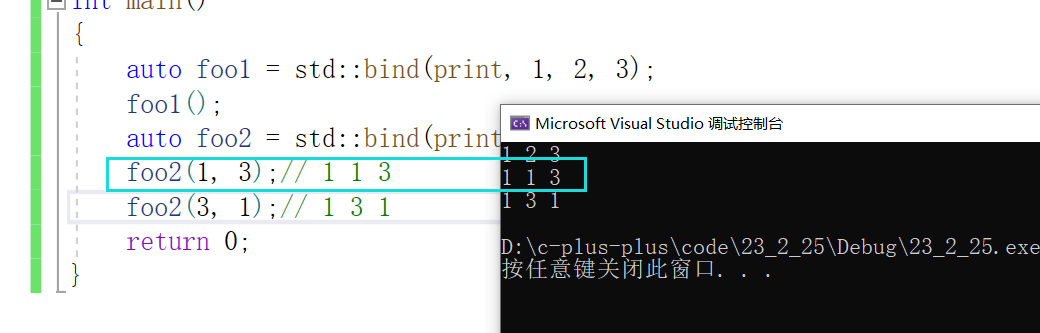
【C++】仿函数、lambda表达式、包装器
1.仿函数 仿函数是什么?仿函数就是类中的成员函数,这个成员函数可以让对象模仿函数调用的行为。 函数调用的行为:函数名(函数参数)C中可以让类实现:函数名(函数参数)调用函数 自己写一个仿函数: 重载()运算符 cla…...
)
二叉树(二)
二叉树——堆存储1.堆的初始化2. 堆的销毁3.堆的插入4.堆的删除5.堆的打印6.取堆顶的数据7.堆的数据个数8.堆的判空9.堆的构建10.向上调整11.向下调整12.使用堆进行排序13.交换14.完整代码🌟🌟hello,各位读者大大们你们好呀🌟&…...

爬虫知识简介
爬虫简介 爬虫与网络请求 网络爬虫是一个自动提取网页的程序,一般都分为3步:数据爬取,数据解析,数据存储。数据爬取就是模拟浏览器发送请求,所以需要对网络请求HTTP/HTTPS有一定了解 相关概念: H…...

2023年全国最新会计专业技术资格精选真题及答案6
百分百题库提供会计专业技术资格考试试题、会计考试预测题、会计专业技术资格考试真题、会计证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.下列各项中,企业根据本月“工资费用分配汇总表”分配所列财务部门…...

同时学习C++语言和C#语言好吗?
同时学习两门编程语言并不是不好的选择,尤其是对于初学者而言,这样做能够帮助你更好地理解编程语言的基本概念和原则。C和C#都是常用的编程语言,它们都有各自的优点和用途。同时学习这两门语言能够让你更好地理解它们之间的异同点,…...

Android8,source与lunch流程解析
source 流程 # build/make/envsetup.sh ---- # Execute the contents of any vendorsetup.sh files we can find. for f in test -d device && find -L device -maxdepth 4 -name vendorsetup.sh 2> /dev/null | sort \ test -d vendor && find -L vendo…...
大数据NiFi(二十):实时同步MySQL数据到Hive
文章目录 实时同步MySQL数据到Hive 一、开启MySQL的binlog日志 1、登录mysql查看MySQL是否开启binlog日志 2 、开启mysql binlog日志 3、重启mysql 服务,重新查看binlog日志情况 二、配置“CaptureChangeMySQL”处理器 1、创建“…...
mac 如何设置 oh my zsh 终端terminal 和添加主题powerlevel10k
Oh My Zsh 是什么 Oh My Zsh 是一款社区驱动的命令行工具,正如它的主页上说的,Oh My Zsh 是一种生活方式。它基于 zsh 命令行,提供了主题配置,插件机制,已经内置的便捷操作。给我们一种全新的方式使用命令行。 **Oh …...
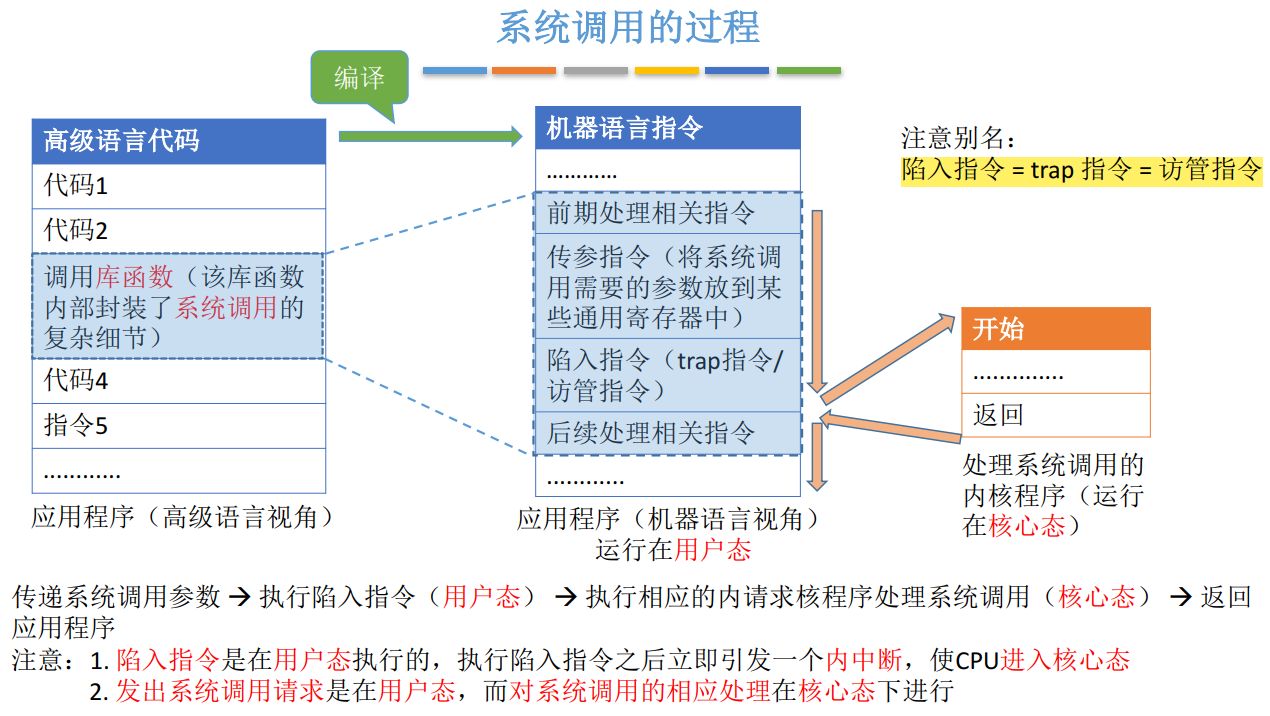
王道《操作系统》学习(一)——计算机系统概述
1.1 操作系统的概念、功能 1.1.1 操作系统的概念(定义) (1)操作系统是系统资源的管理者 (2)向上层用户、软件提供方便易用的服务 (3)是最接近硬件的一层软件 1.1.2 操作系统的功能…...

什么是自适应平台服务?
总目录链接==>> AutoSAR入门和实战系列总目录 文章目录 什么是自适应平台服务?1.1 自适应平台服务包含哪些功能簇呢?1.1.1 ara::sm 状态管理 (SM)1.1.2 ara::diag 诊断管理 (DM)1.1.3 ara::s2s 信号到服务映射1.1.4 ara::nm 网络管理 (NM)1.1.5 ara::ucm 更新和配置管…...

QML Image and Text(图像和文字)
Image(图片) 图像类型显示图像。 格式: Image {source: "资源地址" } source:指定资源的地址 自动检测文件拓展名:source中的URL 指示不存在的本地文件或资源,则 Image 元素会尝试自动检测文件…...
图解LeetCode——剑指 Offer 25. 合并两个排序的链表
一、题目 输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。 二、示例 2.1> 示例1: 【输入】1->2->4, 1->3->4 【输出】1->1->2->3->4->4 限制: 0 < 链表长度 < 1000 三、…...

Speechless微博备份工具:3分钟学会完整导出PDF的终极指南
Speechless微博备份工具:3分钟学会完整导出PDF的终极指南 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 你是否曾担心珍贵的微博回忆突然…...

革命性HTTP API设计指南:Heroku实战经验全解析
革命性HTTP API设计指南:Heroku实战经验全解析 【免费下载链接】http-api-design HTTP API design guide extracted from work on the Heroku Platform API 项目地址: https://gitcode.com/gh_mirrors/ht/http-api-design GitHub 加速计划 / ht / http-api-d…...

【职业发展】程序员成长路径:从初级到架构师的进阶指南
【职业发展】程序员成长路径:从初级到架构师的进阶指南 引言 程序员的职业发展是一个持续学习和成长的过程。从初级程序员成长为技术架构师,需要经历多个阶段的积累和蜕变。本文将详细分析程序员成长的各个阶段,帮助你规划职业发展路径。 …...

DRAM计算内存的电源传输网络优化策略
1. DRAM计算内存中的电源传输网络挑战与优化在数据密集型应用爆炸式增长的今天,传统冯诺依曼架构面临严峻的"内存墙"挑战。计算内存(Compute-in-Memory, CIM)技术通过在内存内部执行计算任务,从根本上改变了数据处理范式…...

开源数字白板the-board:基于React+Fabric.js的实时协作技术解析
1. 项目概述:一个开源的“数字白板”能做什么?最近在GitHub上看到一个挺有意思的项目,叫the-board。乍一看名字,可能觉得平平无奇,但点进去你会发现,它其实是一个功能相当完整的在线白板应用。简单来说&…...

Cloudflare + PlanetScale:在边缘运行全栈应用,数据库也不例外
全栈开发者面对的一道老难题 Cloudflare Workers 解决了计算层的全球分发问题——你的代码跑在 Cloudflare 遍布全球的 300 多个数据中心里,离用户近,启动快,不需要管理任何服务器。 但数据不一样。 数据库天然是"有状态的"&#x…...
)
MATLAB图像处理实战:用imfindcircles函数搞定工业零件瑕疵检测(附完整代码)
MATLAB图像处理实战:工业零件瑕疵检测的精准圆识别技术 在工业自动化质检领域,圆形特征的精准检测直接关系到产品质量控制的可靠性。轴承、垫片、齿轮等标准件上的孔洞缺失或尺寸偏差,往往预示着潜在的产品缺陷。传统人工检测不仅效率低下&am…...

硬件工程师实战指南:工业物联网安全、无线充电与TSN网络设计解析
1. 项目概述:一场面向硬件工程师的线上技术盛宴最近在整理行业资料时,翻到了EE Times几年前发布的一个“即将到来的线上技术活动”汇总页面。虽然发布时间是2018年,但里面提到的几个技术主题——工业物联网安全、硬件身份认证、工业以太网演进…...

Windows风扇控制终极指南:5分钟学会FanControl智能调校
Windows风扇控制终极指南:5分钟学会FanControl智能调校 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

计算机人别卷开发了!这个方向让我毕业年入_20_万,兼职还能赚8K
一、我那 “躺赢” 的同学:从找不到工作到 offer 拿到手软 去年毕业季,我们班一半人在死磕 LeetCode 求开发岗,月薪 8K 都要抢破头;而隔壁宿舍的阿凯,没卷一道算法题,却拿到了 3 家企业的安全岗 offer&…...